
Intelligent Optimization Design of Distillation Columns Using Surrogate Models Based on GA-BP

Abstract
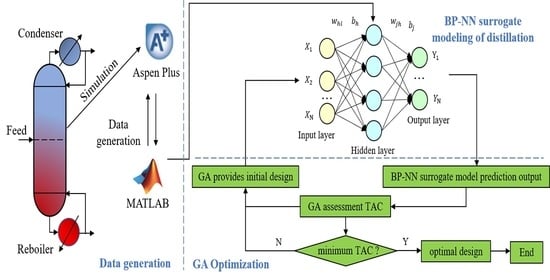
:
1. Introduction
2. Previous Research on Distillation Column Design
3. Modeling
3.1. Data Generation
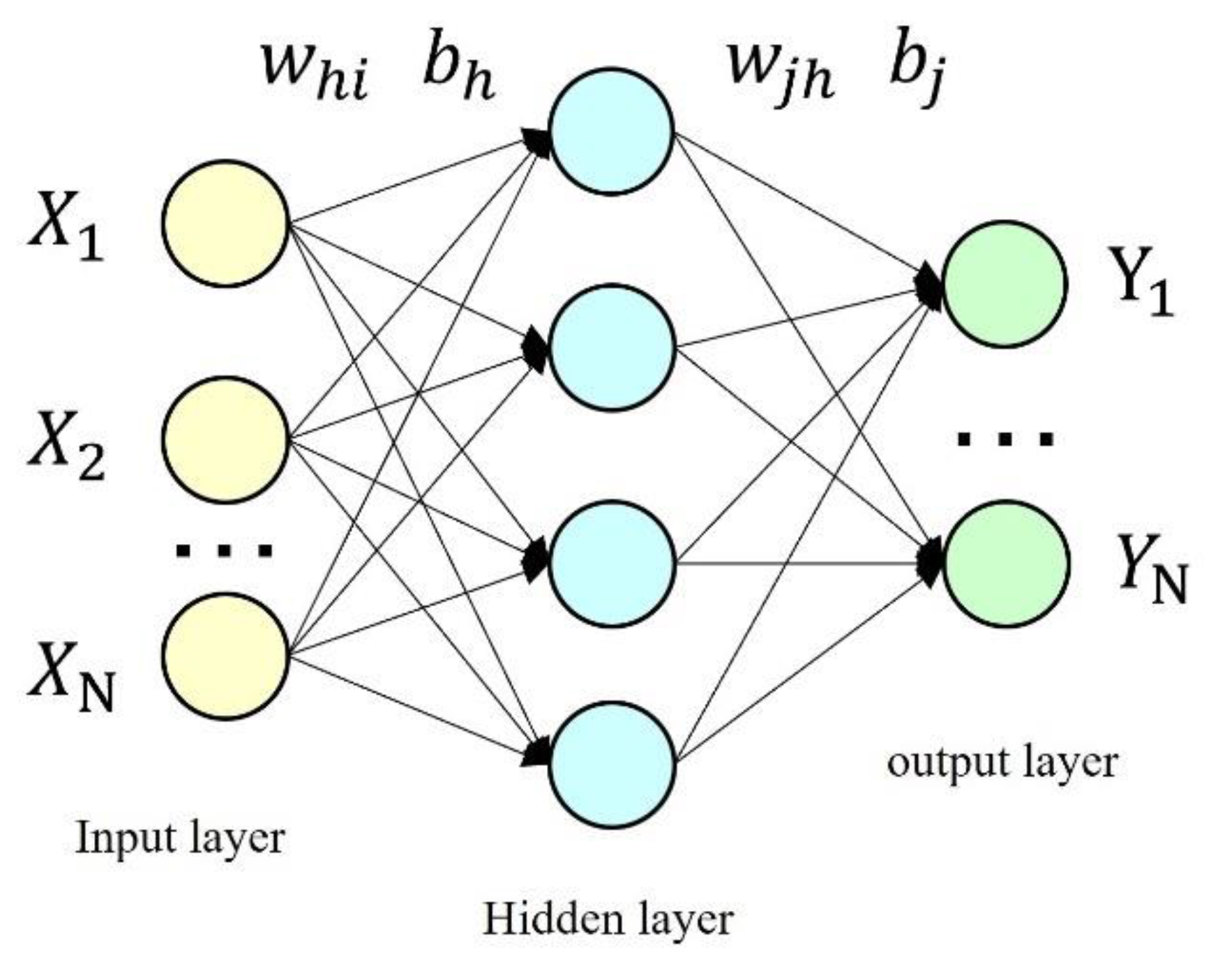
3.2. Surrogate Modeling of Distillation Columns
3.3. Training of Surrogate Model
3.4. Optimization Process
3.5. Life Cycle Assessment
- Heat exchanger mass calculation:
- 2.
- Electricity consumption of the pump:
- 3.
- Carbon emissions generated per 1 t of raw material processed:
4. Case Study
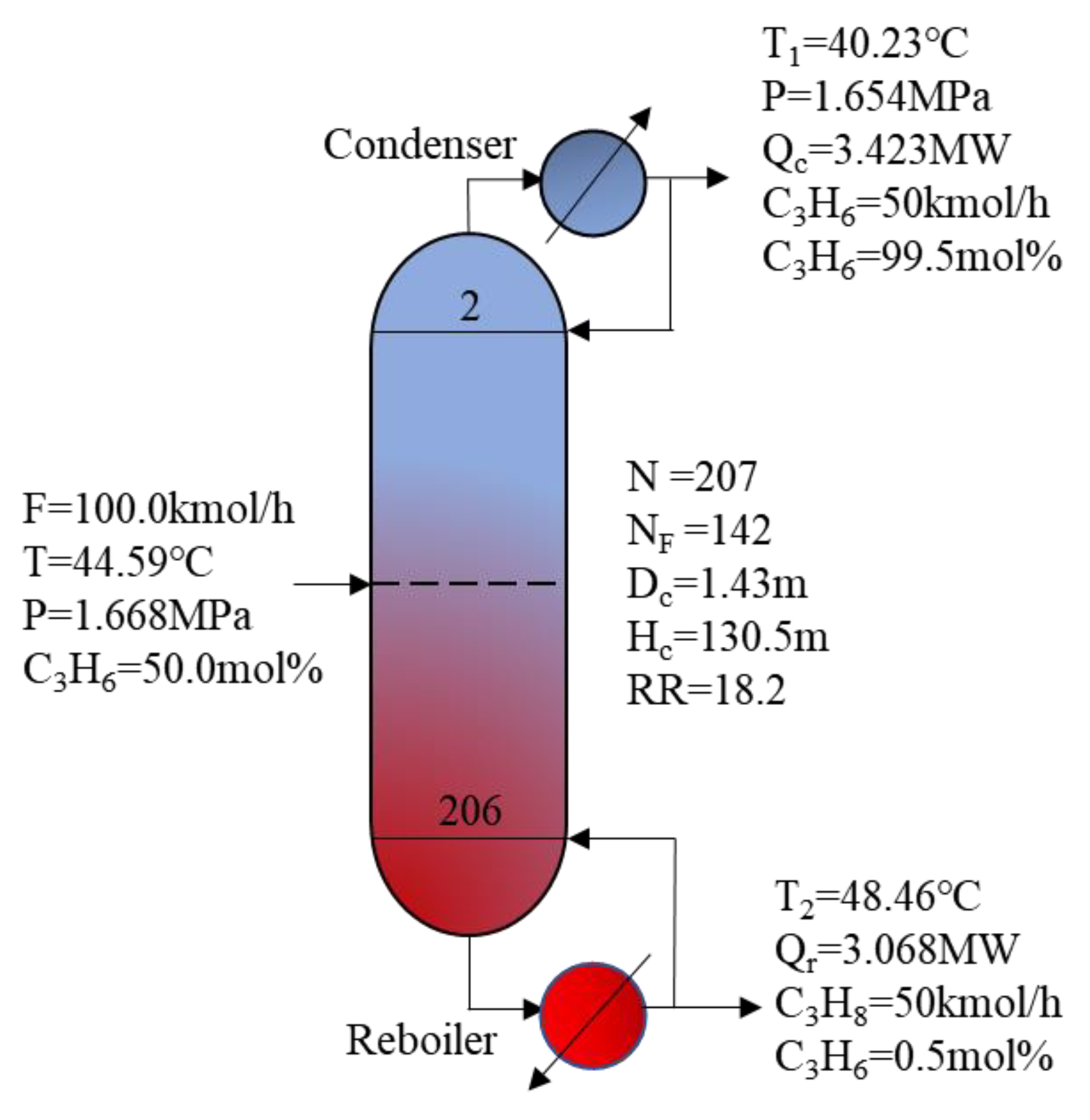
4.1. Problem Description
4.2. GA-BP Modeling
4.3. GA-BP Optimization Results
4.4. Environmental Assessment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Dc | Column diameter | m |
| F | Feed flow rate | kmol/h |
| Hc | Column height | m |
| N | Total number of plates | |
| N1 | Distillation section | |
| N2 | Stripping section | |
| NF | Feed position | |
| P | Operating pressure | MPa |
| Qc | Condenser duty | MW |
| Qr | Reboiler duty | MW |
| R | Specified reflux ratio | |
| Rc | Calculated reflux ratio | |
| T1 | Column top temperature | ℃ |
| T2 | Bottom temperature | ℃ |
| g | Gravitational acceleration | m/s2 |
| h | Head of delivery | m |
| Ne | Effective power | |
| Np | Shaft power | |
| Pt | Payback period | a |
| ql | Flow | m3/s |
| ρl | Product density | kg/m³ |
| ρstill | Carbon steel density | g/cm3 |
| Superscript | ||
| A | Heat exchange area | m2 |
| C | Cost | USD |
| f | Emission factors | kgCO2 |
| ECP | Carbon emissions per 1 ton of raw material processed | kgCO2/t |
| GHG | Carbon emission | kgCO2 |
| m | Consumption | t |
| Subscripts | ||
| c | Column | |
| CAP | Equipment investment | |
| co | Condenser | |
| HEX | Heat exchanger | |
| OPE | Operate | |
| P-co2 | Equipment manufacturing stage | |
| R-co2 | Operate stage | |
| re | Reboiler | |
| s | Raw material |
References
- Zhu, J.; Chen, L.; Liu, Z.; Hao, L.; Wei, H. Synergy of electrification and energy efficiency improvement via vapor recompression heat pump and heat exchanger network to achieve decarbonization of extractive distillation. Sep. Purif. Technol. 2022, 293, 121065. [Google Scholar] [CrossRef]
- Barttfeld, M.; Aguirre, P.A.; Grossmann, I.E. Alternative representations and formulations for the economic optimization of multicomponent distillation columns. Comput. Chem. Eng. 2003, 27, 363–383. [Google Scholar] [CrossRef]
- Costa, A.L.H.; Bagajewicz, M.J. 110th Anniversary: On the departure from heuristics and simplified models toward globally optimal design of process equipment. Ind. Eng. Chem. Res. 2019, 58, 18684–18702. [Google Scholar] [CrossRef]
- Chiang, L.H.; Braun, B.; Wang, Z.; Castillo, I. Towards artificial intelligence at scale in the chemical industry. AlChE J. 2022, 68, e17644. [Google Scholar] [CrossRef]
- Sahinidis, N.V. Optimization under uncertainty: State-of-the-art and opportunities. Comput. Chem. Eng. 2004, 28, 971–983. [Google Scholar] [CrossRef] [Green Version]
- Sinnott, R.; Towler, G. Separation columns (distillation, absorption and extraction). In Chemical Engineering Design; Elsevier: Amsterdam, The Netherlands, 2020; pp. 645–772. [Google Scholar]
- Gilliland, E.R. Multicomponent rectification estimation of the number of theoreticalplates as a function of the reflux ratio. Ind. Eng. Chem. Res. 1940, 32, 1220–1223. [Google Scholar] [CrossRef]
- Underwood, A. Fractional Distillation of Multicomponent Mixtures. Ind. Eng. Chem. Res. 2002, 41, 2844–2847. [Google Scholar] [CrossRef]
- Fenske, M.; Quiggle, D.; Tongberg, C. Composition of straight-run pennsylvania gasoline. Ind. Eng. Chem. Res. 1949, 24, 408–418. [Google Scholar] [CrossRef]
- Dragomir, R.M.; Jobson, M. Conceptual design of single-feed hybrid reactive distillation columns. Chem. Eng. Sci. 2005, 60, 4377–4395. [Google Scholar] [CrossRef]
- Adiche, C.; Vogelpohl, A. Short-cut methods for the optimal design of simple and complex distillation columns. Chem. Eng. Res. Des. 2011, 89, 1321–1332. [Google Scholar] [CrossRef]
- Uwitonze, H.; Han, S.; Kim, S.; Hwang, K.S. Structural design of fully thermally coupled distillation column using approximate group methods. Chem. Eng. Process. Process Intensif. 2014, 85, 155–167. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Z.; Zhou, T. Rigorous design of reaction-separation processes using disjunctive programming models. Comput. Chem. Eng. 2018, 111, 16–26. [Google Scholar] [CrossRef]
- Viswanathan, J.; Grossmann, I.E. A combined penalty function and outer-approximation method for MINLP optimization. Comput. Chem. Eng. 1990, 14, 769–782. [Google Scholar] [CrossRef]
- Yeomans, H.; Grossmann, I.E. Optimal design of complex distillation columns using rigorous tray-by-tray disjunctive programming models. Ind. Eng. Chem. Res. 2000, 39, 4326–4335. [Google Scholar] [CrossRef]
- Jackson, J.R.; Grossmann, I.E. A disjunctive programming approach for the optimal design of reactive distillation columns. Comput. Chem. Eng. 2001, 25, 1661–1673. [Google Scholar] [CrossRef]
- Caballero, J.A.; Milán-Yañez, D.; Grossmann, I.E. Rigorous design of distillation columns: Integration of disjunctive programming and process simulators. Ind. Eng. Chem. Res. 2005, 44, 6760–6775. [Google Scholar] [CrossRef]
- Tsatse, A.; Oudenhoven, S.R.G.; ten Kate, A.J.B.; Sorensen, E. Optimal design and operation of reactive distillation systems based on a superstructure methodology. Chem. Eng. Res. Des. 2021, 170, 107–133. [Google Scholar] [CrossRef]
- Pattison, R.C.; Baldea, M. Equation-oriented flowsheet simulation and optimization using pseudo-transient models. AlChE J. 2014, 60, 4104–4123. [Google Scholar] [CrossRef]
- Pattison, R.C.; Gupta, A.M.; Baldea, M. Equation-oriented optimization of process flowsheets with dividing-wall columns. AlChE J. 2015, 62, 704–716. [Google Scholar] [CrossRef]
- Ma, Y.; Luo, Y.; Yuan, X. Towards the really optimal design of distillation systems: Simultaneous pressures optimization of distillation systems based on rigorous models. Comput. Chem. Eng. 2019, 126, 54–67. [Google Scholar] [CrossRef]
- Yeoh, K.P.; Hui, C.W. Rigorous NLP distillation models for simultaneous optimization to reduce utility and capital costs. Cleaner Eng. Technol. 2021, 2, 100066. [Google Scholar] [CrossRef]
- Grossmann, I.E.; Aguirre, P.A.; Barttfeld, M. Optimal synthesis of complex distillation columns using rigorous models. Comput. Chem. Eng. 2005, 29, 1203–1215. [Google Scholar] [CrossRef]
- Osuolale, F.N.; Zhang, J. Energy efficiency optimisation for distillation column using artificial neural network models. Energy 2016, 106, 562–578. [Google Scholar] [CrossRef] [Green Version]
- Javaloyes-Antón, J.; Ruiz-Femenia, R.; Caballero, J.A. Rigorous design of complex distillation columns using process simulators and the particle swarm optimization algorithm. Ind. Eng. Chem. Res. 2013, 52, 15621–15634. [Google Scholar] [CrossRef] [Green Version]
- Caballero, J.A. Logic hybrid simulation-optimization algorithm for distillation design. Comput. Chem. Eng. 2015, 72, 284–299. [Google Scholar] [CrossRef] [Green Version]
- Yusup, N.; Zain, A.M.; Hashim, S.Z.M. Evolutionary techniques in optimizing machining parameters: Review and recent applications. Expert Syst. Appl. 2012, 39, 9909–9927. [Google Scholar] [CrossRef]
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Escamilla-Salazar, I.G.; Torres-Trevi no, L.; Gonzalez-Ortiz, B. Intelligent parameter identification of machining Ti64 alloy. Int. J. Adv. Manuf. Technol. 2016, 86, 1997–2009. [Google Scholar] [CrossRef]
- Aydin, I.; Karakose, M.; Akin, E. A multi-objective artificial immune algorithm for parameter optimization in support vector machine. Appl. Soft Comput. 2011, 11, 120–129. [Google Scholar] [CrossRef]
- Li, M.; Cui, Y.; Shi, X.; Zhang, Z.; Zhao, X.; Zhu, X.; Gao, J. Simulated annealing-based optimal design of energy efficient ternary extractive dividing wall distillation process for separating benzene-isopropanol-water mixtures. Chin. J. Chem. Eng. 2021, 33, 203–210. [Google Scholar] [CrossRef]
- Christopher, C.C.E.; Dutta, A.; Farooq, S.; Karimi, I.A. Process synthesis and optimization of propylene/propane separation using vapor recompression and self-heat recuperation. Ind. Eng. Chem. Res. 2017, 56, 14557–14564. [Google Scholar] [CrossRef]
- Ibrahim, D.; Jobson, M.; Li, J.; Guillén-Gosálbez, G. Surrogate models combined with a support vector machine for the optimized design of a crude oil distillation unit using genetic algorithms. In Proceedings of the 27th European Symposium on Computer Aided Process Engineering, Computer Aided Chemical Engineering, Barcelona, Spain, 1–5 October 2017; Volume 3, pp. 481–486. [Google Scholar]
- Salehi, H.; Burgueño, R. Emerging artificial intelligence methods in structural engineering. Eng. Struct. 2018, 171, 170–189. [Google Scholar] [CrossRef]
- Ochoa-Estopier, L.M.; Jobson, M.; Smith, R. The use of reduced models for design and optimisation of heat-integrated crude oil distillation systems. Energy 2014, 75, 5–13. [Google Scholar] [CrossRef]
- Ochoa-Estopier, L.M.; Jobson, M. Optimization of heat-integrated crude oil distillation systems. Part I The distillation model. Ind. Eng. Chem. Res. 2015, 54, 4988–5000. [Google Scholar] [CrossRef]
- Keßler, T.; Kunde, C.; McBride, K.; Mertens, N.; Michaels, D.; Sundmacher, K.; Kienle, A. Global optimization of distillation columns using explicit and implicit surrogate models. Chem. Eng. Sci. 2019, 197, 235–245. [Google Scholar] [CrossRef]
- Quirante, N.; Javaloyes, J.; Caballero, J.A. Rigorous design of distillation columns using surrogate models based on Kriging interpolation. AlChE J. 2015, 61, 2169–2187. [Google Scholar] [CrossRef] [Green Version]
- Nentwich, C.; Engell, S. Application of surrogate models for the optimization and design of chemical processes. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1291–1296. [Google Scholar]
- Yao, H.; Chu, J. Operational optimization of a simulated atmospheric distillation column using support vector regression models and information analysis. Chem. Eng. Res. Des. 2012, 90, 2247–2261. [Google Scholar] [CrossRef]
- López, C.D.C.; Hoyos, L.J.; Mahecha, C.A.; Arellano-Garcia, H.; Wozny, G. Optimization model of crude oil distillation units for optimal crude oil blending and operating conditions. Ind. Eng. Chem. Res. 2013, 52, 12993–13005. [Google Scholar] [CrossRef]
- Liau, L.C.-K.; Yang, T.C.-K.; Tsai, M.-T. Expert system of a crude oil distillation unit for process optimization using neural networks. Expert Syst. Appl. 2004, 26, 247–255. [Google Scholar] [CrossRef]
- Tgarguifa, A.; Bounahmidi, T.; Fellaou, S. Optimal design of the distillation process using the artificial neural networks method. In Proceedings of the 2020 1st International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 16–19 April 2020. [Google Scholar]
- Ibrahim, D.; Jobson, M.; Li, J.; Guillén-Gosálbez, G. Optimization-based design of crude oil distillation units using surrogate column models and a support vector machine. Chem. Eng. Res. Des. 2018, 134, 212–225. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, D.; Jobson, M.; Li, J.; Guillén-Gosálbez, G. Optimal design of flexible heat-integrated crude oil distillation units using surrogate models. Chem. Eng. Res. Des. 2021, 165, 280–297. [Google Scholar] [CrossRef]
- Peng, H.; Zhou, L.; Liu, G. Thermodynamics-based neural network and the optimization of ethylbenzene production process. J. Cleaner Prod. 2021, 296, 126615. [Google Scholar] [CrossRef]
- Gutiérrez-Antonioa, C.; Briones-Ramírez, A. Multiobjective stochastic optimization of dividing-wall distillation columns using a surrogate model based on neural networks. Chem. Biochem. Eng. Q. 2016, 29, 491–504. [Google Scholar] [CrossRef]
- Schweidtmann, A.M.; Mitsos, A. Deterministic Global Optimization with Artificial Neural Networks Embedded. J. Optim. Theory Appl. 2018, 180, 925–948. [Google Scholar] [CrossRef] [Green Version]
- Schöneberger, J.C.; Aker, B.; Fricke, A. Explaining and integrating machine learning models with rigorous simulation. Chem. Ing. Tech. 2021, 93, 1998–2009. [Google Scholar] [CrossRef]
- Abdolrasol, M.G.M.; Hussain, S.M.S.; Ustun, T.S.; Sarker, M.R.; Hannan, M.A.; Mohamed, R.; Ali, J.A.; Mekhilef, S.; Milad, A. Artificial neural networks based optimization techniques: A review. Electronics 2021, 10, 2689. [Google Scholar] [CrossRef]
- Liu, L.; Chen, J.; Xu, L. Realization and application research of BP neural network based on MATLAB. In Proceedings of the 2008 International Seminar on Future BioMedical Information Engineering 2008, Wuhan, China, 18–18 December 2008; pp. 130–133. [Google Scholar] [CrossRef]
- Subramanyan, K.; Diwekar, U.; Zitney, S.E. Stochastic modeling and multi-objective optimization for the APECS system. Comput. Chem. Eng. 2011, 35, 2667–2679. [Google Scholar] [CrossRef]
- Kůrková, V. Kolmogorov’s theorem and multilayer neural networks. Neural Networks 1992, 5, 501–506. [Google Scholar] [CrossRef]
- Brahim, A.O.; Abderafi, S.; Bounahmidi, T. Optimization of the distillation column of qetroleum gractions using ANN method. In Proceedings of the 2018 6th International Renewable and Sustainable Energy Conference (IRSEC), Rabat, Morocco, 5–8 December 2018. [Google Scholar]
- Luyben, W.L. Design and control of the cumene process. Ind. Eng. Chem. Res. 2010, 49, 719–734. [Google Scholar] [CrossRef]
- Cui, C.; Liu, S.; Sun, J. Optimal selection of operating pressure for distillation columns. Chem. Eng. Res. Des. 2018, 137, 291–307. [Google Scholar] [CrossRef]
- Abdul-Rahman, O.A.; Munetomo, M.; Akama, K. An adaptive resolution hybrid binary-real coded genetic algorithm. Artif Life Robotics 2011, 16, 121–124. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimedia Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Wang, S.; Liu, C.; Ren, J.; Liu, L.; Li, Q.; Huo, E. Carbon footprint analysis of organic rankine cycle system using zeotropic mixtures considering leak of fluid. J. Clean. Prod. 2019, 239, 118095. [Google Scholar] [CrossRef]
- Yang, A.; Su, Y.; Teng, L.; Jin, S.; Zhou, T.; Shen, W. Investigation of energy-efficient and sustainable reactive/pressure-swing distillation processes to recover tetrahydrofuran and ethanol from the industrial effluent. Sep. Purif. Technol. 2020, 250, 117210. [Google Scholar] [CrossRef]
- Chen, D.; Yuan, X.; Xu, L.; Yu, K.T. Comparison between different configurations of internally and externally heat-integrated distillation by numerical simulation. Ind. Eng. Chem. Res. 2013, 52, 5781–5790. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Advantages | Disadvantages | |
|---|---|---|---|
| Simplified models | FUG McCabe-Thiele |
|
|
| Rigorous models | MINLP/NLP GDP PTC Aspen |
|
|
| Surrogate models | ANN Kriging degree polynomial |
|
|
| Algorithm | Advantages | Disadvantages | |
|---|---|---|---|
| Deterministic algorithm | SQP LBOA BB GBD |
|
|
| Stochastic algorithm | GA SA PSO IA ACO |
|
|
| Stage | Material | f kgCO2/t |
|---|---|---|
| Equipment Manufacturing | Carbon steel | 720 [60] |
| Operation | Circulating water | 0.30 |
| 3.5 MPa steam | 262.64 | |
| 1.0 MPa steam | 226.82 | |
| 0.35 MPa steam | 196.98 |
| Parameter | Value |
|---|---|
| Feed composition (mol %) | |
| Propane | 0.5 |
| Propylene | 0.5 |
| Feed flow rate (kmol/h) | 100 |
| Distillate molar flow rate(kmol/h) | 50 |
| Feed temperature (°C) | 44.59 |
| Distillate specification (mol %) propylene | 99.5 |
| Bottom specification (mol %) propylene | 1.1 |
| Feed pressure (MPa) | 1.7 |
| N | 201 |
| NF | 137 |
| Overhead pressure (MPa) | 1.6789 |
| Bottom pressure (MPa) | 1.6989 |
| Input Variables | lower Bound | Upper Bound |
|---|---|---|
| Feed temperature (°C) | — | |
| Feed propylene and propane component (mol%) | — | |
| Feed flow rate (kmol/h) | — | |
| D/F | — | |
| N | 150 | 230 |
| NF | 80 | 170 |
| R | 15 | 22 |
| P | 1.65 | 2.2 |
| Parameter | |
|---|---|
| Input layer | 9 |
| Hidden layer | 11 |
| Output layer | 7 |
| Hidden layer transfer function | tansig |
| Output layer transfer function | purelin |
| Training function | trainlm |
| Training error | 0.0001 |
| Training times | 2000 |
| Learning rate | 0.1 |
| Training algorithm | Levenberg–Marquardt |
| Run | TAC (USD/a) |
|---|---|
| 1 | 1,331,609.71 |
| 2 | 1,325,233.37 |
| 3 | 1,324,611.42 |
| 4 | 1,326,403.67 |
| 5 | 1,328,464.11 |
| Cost | Figure 6a | Figure 6b | GA-BP |
|---|---|---|---|
| Utility requirements | |||
| Hot utility (MW) | 3.10837 | 3.10837 | 3.068 |
| Cold utility (MW) | 3.414 | 3.10837 | 3.423 |
| Annualized operating cost (USD/a) | 799,462 | 728,165 | 718,649 |
| Annualized capital cost (USD/a) | 611,307 | 646,932 | 605,962 |
| Total annualized cost (USD/a) | 1,410,834 | 1,375,097 | 1,324,611 |
| Output | GA-BP | Aspen Plus | Relative Error |
|---|---|---|---|
| T1 (°C) | 40.23 | 40.15 | 1.99 × 10−3 |
| T2 (°C) | 48.46 | 48.7 | 4.93 × 10−3 |
| Qc (MW) | 3.423 | 3.432 | 2.62 × 10−3 |
| Qr (MW) | 3.068 | 3.078 | −3.25 × 10−3 |
| C3H6 (mol/%) | 99.5 | 99.5 | 0 |
| Dc (m) | 1.43 | 1.44 | −6.94 × 10−3 |
| Rc | 18.2 | 18.2 | 0 |
| Equipment Manufacturing Stage | Operation Stage | |||||
|---|---|---|---|---|---|---|
| Column t | Condenser t | Reboiler t | Steam t/h | Circulating Water t/h | Electricity kW·h | |
| Figure 6a | 208.09 | 0.37 | 2.08 | 5.89 | 10.37 | 5.87 |
| Figure 6b | 226.49 | 0.34 | 1.89 | 5.36 | 9.45 | 6.91 |
| GA-BP | 208.28 | 0.33 | 2.08 | 5.29 | 10.40 | 6.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, L.; Zhang, N.; Li, G.; Gu, D.; Lu, J.; Lou, Y. Intelligent Optimization Design of Distillation Columns Using Surrogate Models Based on GA-BP. Processes 2023, 11, 2386. https://doi.org/10.3390/pr11082386
Ye L, Zhang N, Li G, Gu D, Lu J, Lou Y. Intelligent Optimization Design of Distillation Columns Using Surrogate Models Based on GA-BP. Processes. 2023; 11(8):2386. https://doi.org/10.3390/pr11082386
Chicago/Turabian StyleYe, Lixiao, Nan Zhang, Guanghui Li, Dungang Gu, Jiaqi Lu, and Yuhang Lou. 2023. "Intelligent Optimization Design of Distillation Columns Using Surrogate Models Based on GA-BP" Processes 11, no. 8: 2386. https://doi.org/10.3390/pr11082386