
Integrating MILP, Discrete-Event Simulation, and Data-Driven Models for Distributed Flow Shop Scheduling Using Benders Cuts


Abstract
1. Introduction
2. Literature
2.1. Distributed Flow Shop Optimization
2.2. Benders Decomposition
3. Methodology
3.1. Benders Decomposition with Heterogeneous Subproblems
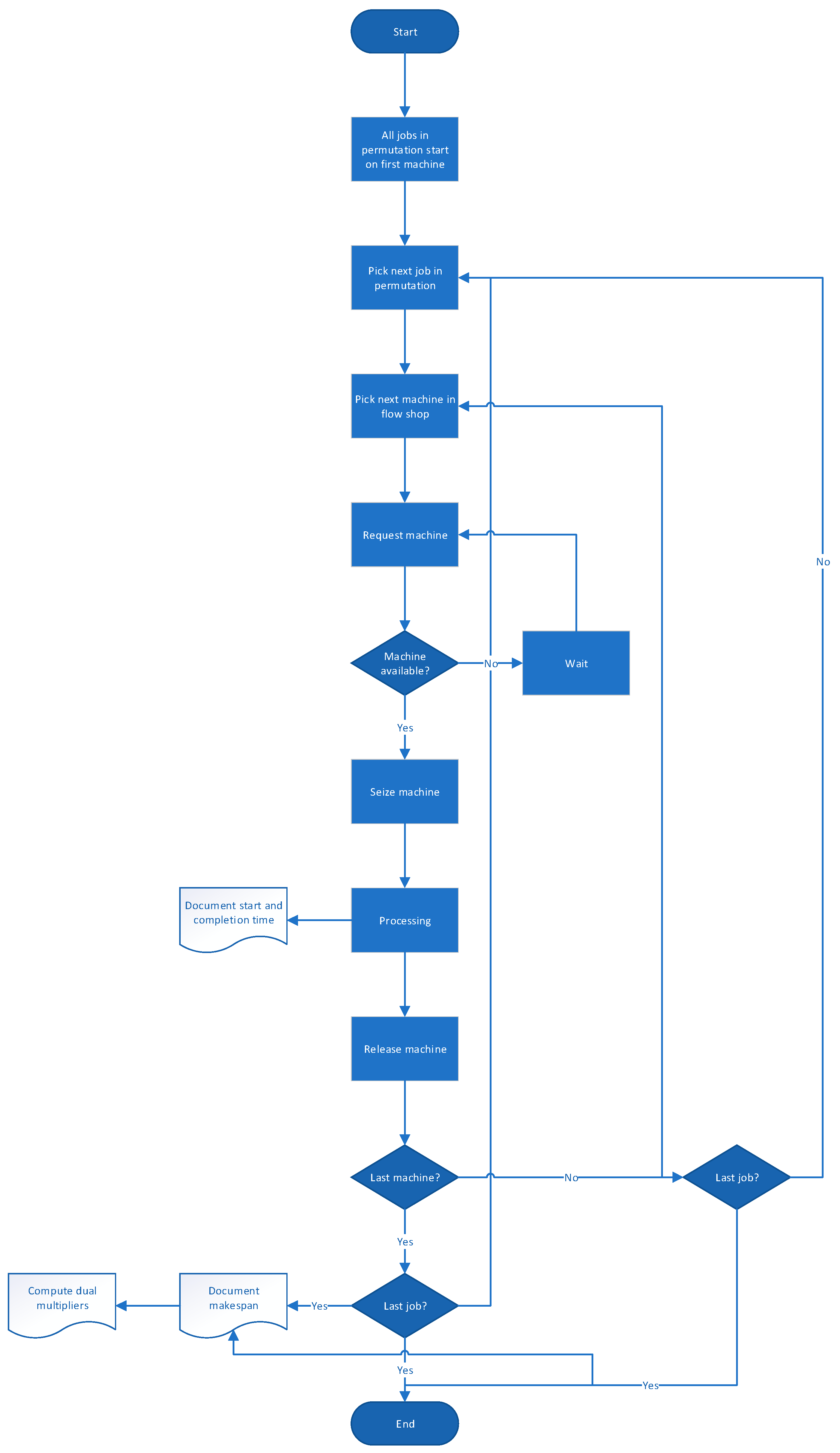
3.2. Application to the DPFSP
| Algorithm 1: Benders Algorithm. | |||
| Input: DPFSP featuring MILP, DES, and DD subproblem | |||
| Output: Makespan-optimized schedule ( containing job assignments and job sequences Initialize: , , t | |||
| while ( < maximum iterations and < timeout and > 0) do | |||
| solve Benders master problem and obtain | |||
| solve subproblems with current master solution | |||
| obtain makespan derive dual multipliers , and parameters | |||
| build Benders cut for MILP, DES, and DD subproblem add Benders cuts to the master problem | |||
| if () do | |||
| update upper bound: ← | |||
| update current gap: ← | |||
| increment and | |||
4. Computational Studies
5. Discussion and Practical Examples
6. Ethical Considerations
6.1. Data Usage
6.2. Model Assumptions
6.3. Potential Impact on Stakeholders
7. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Number of factories | |
| Number of machines | |
| Number of jobs | |
| Continuous decision variables | |
| Binary decision variables | |
| Generic objective function | |
| Generic objective function coefficient vector | |
| Generic constraint coefficient matrices and right-hand sides | |
| Generic objective function of Benders master problem | |
| Generic dual multiplier | |
| Set of specific dual vectors of optimality cuts of Benders master problem | |
| Set of all dual vectors of optimality cuts of Benders master problem | |
| Set of specific dual vectors of feasibility cuts of Benders master problem | |
| Set of all dual vectors of feasibility cuts of Benders master problem | |
| Specific subproblem of all considered subproblems | |
| Function notation of a specific subproblem | |
| Logic-based Benders cuts parameters from DD subproblem | |
| Job sequence variable | |
| Job assignment variable | |
| Big-M factor | |
| Number of jobs assigned to DD subproblem | |
| Completion time of a job | |
| Processing time of a job | |
| Current optimality gap |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | Literature Name |
|---|---|
| 81 | l_3_10_5_1.txt |
| 82 | l_3_10_5_2.txt |
| 85 | l_3_10_5_3.txt |
| 86 | l_3_10_5_4.txt |
| 87 | l_3_10_5_5.txt |
Appendix B
| Parameter | Value |
|---|---|
| CPU cores | 64 |
| CPU speed | Intel Xenon Gold 6338 @ 2.00 GHz |
| RAM | 256 GB |
| Operating system | Windows 11 Enterprise |
References
- Hooker, J. Integrated Methods for Optimization; Springer Nature: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Azevedo, B.F.; Rocha, A.M.A.C.; Pereira, A.I. Hybrid approaches to optimization and machine learning methods: A systematic literature review. Mach. Learn. 2024, 113, 4055–4097. [Google Scholar]
- Figueira, G.; Almada-Lobo, B. Hybrid simulation–optimization methods: A taxonomy and discussion. Simul. Model. Pract. Theory 2014, 46, 118–134. [Google Scholar]
- García-Flores, R.; Wang, X.Z. A multi-agent system for chemical supply chain simulation and management support. OR Spectr. 2002, 24, 343–370. [Google Scholar]
- Luthra, S.; Govindan, K.; Kannan, D.; Mangla, S.K.; Garg, C.P. An integrated framework for sustainable supplier selection and evaluation in supply chains. J. Clean. Prod. 2017, 140, 1686–1698. [Google Scholar]
- Marques, C.M.; Moniz, S.; de Sousa, J.P.; Barbosa-Povoa, A.P.; Reklaitis, G. Decision-support challenges in the chemical-pharmaceutical industry: Findings and future research directions. Comput. Chem. Eng. 2020, 134, 106672. [Google Scholar]
- Wallrath, R.; Franke, M.B. Integration of MILP and Discrete-Event Simulation for Flow Shop Scheduling Using Benders Cuts. Comput. Chem. Eng. 2024, 189, 108809. [Google Scholar]
- Zhang, M.; Matta, A.; Alfieri, A.; Pedrielli, G. A simulation-based benders’ cuts generation for the joint workstation, workload and buffer allocation problem. In Proceedings of the 13th IEEE Conference on Automation Science and Engineering (CASE), Xi’an, China; 2017; pp. 1067–1072. [Google Scholar] [CrossRef]
- Forbes, M.; Harris, M.; Jansen, H.; van der Schoot, F.; Taimre, T. Combining optimisation and simulation using logic-based Benders decomposition. Eur. J. Oper. Res. 2024, 312, 840–854. [Google Scholar] [CrossRef]
- Naderi, B.; Ruiz, R. The distributed permutation flowshop scheduling problem. Comput. Oper. Res. 2010, 37, 754–768. [Google Scholar]
- Perez-Gonzalez, P.; Framinan, J.M. A review and classification on distributed permutation flowshop scheduling problems. Eur. J. Oper. Res. 2024, 312, 1–21. [Google Scholar]
- Cao, D.; Chen, M. Parallel flowshop scheduling using Tabu search. Int. J. Prod. Res. 2003, 41, 3059–3073. [Google Scholar]
- McNaughton, R. Scheduling with Deadlines and Loss Functions. Manag. Sci. 1959, 6, 1–12. [Google Scholar]
- Unlu, Y.; Mason, S.J. Evaluation of mixed integer programming formulations for non-preemptive parallel machine scheduling problems. Comput. Ind. Eng. 2010, 58, 785–800. [Google Scholar]
- Vallada, E.; Ruiz, R. A genetic algorithm for the unrelated parallel machine scheduling problem with sequence dependent setup times. Eur. J. Oper. Res. 2011, 211, 612–622. [Google Scholar]
- Edis, E.B.; Oguz, C.; Ozkarahan, I. Parallel machine scheduling with additional resources: Notation, classification, models and solution methods. Eur. J. Oper. Res. 2013, 230, 449–463. [Google Scholar]
- Johnson, S.M. Optimal Two- and Three-Stage Production Schedules with Setup Times Included; Naval Research Logistics Quarterly; John Wiley & Sons: Hoboken, NJ, USA, 1954; Volume 1, pp. 61–68. [Google Scholar]
- Zheng, D.Z.; Wang, L. An Effective Hybrid Heuristic for Flow Shop Scheduling. Int. J. Adv. Manuf. Technol. 2003, 21, 38–44. [Google Scholar]
- Komaki, G.M.; Sheikh, S.; Malakooti, B. Flow shop scheduling problems with assembly operations: A review and new trends. Int. J. Prod. Res. 2019, 57, 2926–2955. [Google Scholar]
- Duan, J.; Wang, M.; Zhang, Q.; Qin, J. Distributed shop scheduling: A comprehensive review on classifications, models and algorithms. Math. Biosci. Eng. 2023, 20, 15265–15308. [Google Scholar] [PubMed]
- Mraihi, T.; Driss, O.B.; El-Haouzi, H.B. Distributed permutation flow shop scheduling problem with worker flexibility: Review, trends and model proposition. Expert Syst. Appl. 2023, 238, 121947. [Google Scholar]
- Gogos, C. Solving the Distributed Permutation Flow-Shop Scheduling Problem Using Constrained Programming. Appl. Sci. 2023, 13, 12562. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, E.E.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar]
- Gao, J.; Chen, R. An NEH-based heuristic algorithm for distributed permutation flowshop scheduling problems. Sci. Res. Essays 2011, 6, 3094–3100. [Google Scholar]
- Ruiz, R.; Stützle, T. A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur. J. Oper. Res. 2007, 177, 2033–2049. [Google Scholar]
- Lin, S.W.; Ying, K.C.; Huang, C.Y. Minimising makespan in distributed permutation flowshops using a modified iterated greedy algorithm. Int. J. Prod. Res. 2013, 51, 5029–5038. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Framinan, J.M. A bounded-search iterated greedy algorithm for the distributed permutation flowshop scheduling problem. Int. J. Prod. Res. 2015, 53, 1111–1123. [Google Scholar]
- Ruiz, R.; Pan, Q.K.; Naderi, B. Iterated Greedy methods for the distributed permutation flowshop scheduling problem. Omega 2019, 83, 213–222. [Google Scholar]
- Naderi, B.; Ruiz, R. A scatter search algorithm for the distributed permutation flowshop scheduling problem. Eur. J. Oper. Res. 2014, 239, 323–334. [Google Scholar]
- Gao, J.; Chen, R.; Deng, W. An efficient tabu search algorithm for the distributed permutation flowshop scheduling problem. Int. J. Prod. Res. 2013, 51, 641–651. [Google Scholar]
- Gao, J.; Chen, R. A hybrid genetic algorithm for the distributed permutation flowshop scheduling problem. Int. J. Comput. Intell. Syst. 2011, 4, 497–508. [Google Scholar]
- Benders, J.F. Partitioning procedures for solving mixed-variables programming problems. Numer. Math. 1962, 4, 238–252. [Google Scholar]
- Hamzadayı, A. An effective benders decomposition algorithm for solving the distributed permutation flowshop scheduling problem. Comput. Oper. Res. 2020, 123, 105006. [Google Scholar]
- Bektaş, T.; Hamzadayı, A.; Ruiz, R. Benders decomposition for the mixed no-idle permutation flowshop scheduling problem. J. Sched. 2020, 23, 513–523. [Google Scholar]
- Pan, Q.Q.; Tasgetiren, M.F.; Liang, Y.C. A discrete differential evolution algorithm for the permutation flowshop scheduling problem. In Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, UK, 11 July 2007; pp. 126–133. [Google Scholar]
- Hooker, J.; Ottosson, G. Logic-based Benders decomposition. Math. Program. Ser. A 2003, 96, 33–60. [Google Scholar]
- Li, H.; Womer, K. Scheduling projects with multi-skilled personnel by a hybrid MILP/CP benders decomposition algorithm. J. Sched. 2009, 12, 281–298. [Google Scholar]
- Emde, S.; Polten, L.; Gendreau, M. Logic-based benders decomposition for scheduling a batching machine. Comput. Oper. Res. 2020, 113, 104777. [Google Scholar]
- Juvin, C.; Houssin, L.; Lopez, P. Logic-based Benders decomposition for the preemptive flexible job-shop scheduling problem. Comput. Oper. Res. 2023, 152, 106156. [Google Scholar]
- Tan, Y.; Terekhov, D. Logic-Based Benders Decomposition for Two-Stage Flexible Flow Shop Scheduling with Unrelated Parallel Machines. In Advances in Artificial Intelligence; Bagheri, E., Cheung, J., Eds.; Canadian AI 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10832. [Google Scholar]
- Gendron, B.; Scutellà, M.G.; Garroppo, R.G.; Nencioni, G.; Tavanti, L. A Branch-and-Benders-Cut Method for Nonlinear Power Design in Green Wireless Local Area Networks. Eur. J. Oper. Res. 2016, 255, 151–162. [Google Scholar] [CrossRef]
- Codato, G.; Fischetti, M. Combinatorial Benders’ cuts for mixed-integer linear programming. Oper. Res. 2006, 54, 756–766. [Google Scholar]

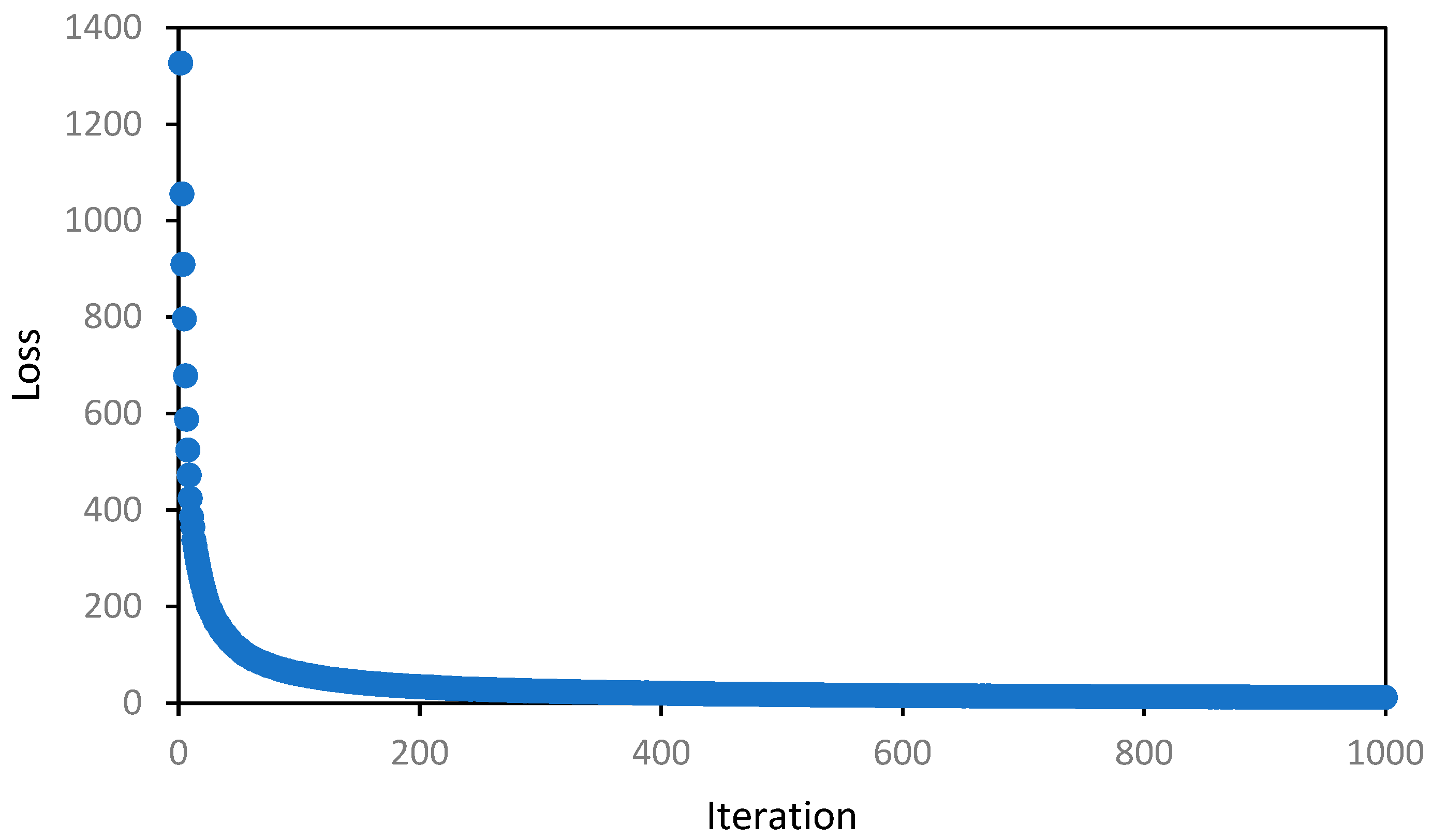

| Parameter | Value |
|---|---|
| Gurobi version | 9.5.2 |
| Gurobi hyperparameters | standard settings |
| Implementation environment | Gurobipy 11.0.1 |
| Python version | 3.7.6 |
| Parameter | Value |
|---|---|
| DES modeling package | SimPy 4.1.1 |
| SimPy modules used | Resource, Container, Process, timeout, event |
| Python version | 3.7.6 |
| Parameter | Value |
|---|---|
| Input | job permutation |
| Output | makespan |
| Data source | DES model evaluations |
| Python modeling package | sklearn.neural_network (1.5.0), MLPRegressor |
| Number of samples | 400,000 |
| Sampling mode | random uniform |
| Number of hidden layers | 5 |
| Number of nodes in hidden layers | 600, 500, 400, 300, 100 |
| max_iter | 1000 |
| Instance | |
|---|---|
| 81 | 0.29 |
| 82 | 0.35 |
| 85 | 0.36 |
| 86 | 0.44 |
| 87 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wallrath, R.; Franke, M.B. Integrating MILP, Discrete-Event Simulation, and Data-Driven Models for Distributed Flow Shop Scheduling Using Benders Cuts. Processes 2024, 12, 1772. https://doi.org/10.3390/pr12081772
Wallrath R, Franke MB. Integrating MILP, Discrete-Event Simulation, and Data-Driven Models for Distributed Flow Shop Scheduling Using Benders Cuts. Processes. 2024; 12(8):1772. https://doi.org/10.3390/pr12081772
Chicago/Turabian StyleWallrath, Roderich, and Meik B. Franke. 2024. "Integrating MILP, Discrete-Event Simulation, and Data-Driven Models for Distributed Flow Shop Scheduling Using Benders Cuts" Processes 12, no. 8: 1772. https://doi.org/10.3390/pr12081772
APA StyleWallrath, R., & Franke, M. B. (2024). Integrating MILP, Discrete-Event Simulation, and Data-Driven Models for Distributed Flow Shop Scheduling Using Benders Cuts. Processes, 12(8), 1772. https://doi.org/10.3390/pr12081772