
Parametric Dueling DQN- and DDPG-Based Approach for Optimal Operation of Microgrids

Abstract
:1. Introduction
2. System Model
2.1. Photovoltaic Power Model
2.2. Wind Energy Model
2.3. Micro Gas Turbine Model
2.4. Storage Battery Model
3. Optimal Scheduling Model for Microgrids Based on Parametric Dueling DQN and DDPG
- Binary constraint: The binary constraint is used to make decisions about the activation and deactivation of distributed energy sources. Its importance lies in the ability to promptly shut down wind turbines when wind speeds are excessively high, thereby preventing equipment damage. Furthermore, when the generation from renewable energy sources can fully cover the current electricity demand, the gas turbine can be deactivated to reduce operational costs.where is a binary decision, such as starting or stopping the gas turbine.
- Load constraint: The power provided to the load by the microgrid needs to satisfy its power demand, and the output power of the distributed power supply is limited to values between its minimum output power and maximum output power:where represents the minimum permissible output power of the distributed generation source, and denotes the maximum allowable output power of the distributed generation source.
- Energy storage constraints: To guarantee the longevity of the energy storage system, constraints are imposed on the depth of charge and discharge, as well as the output power of the energy storage device, which is constrained according to Equations (11) and (12):where SOC represents the state of charge of the energy storage system, and and denote the minimum and maximum permissible states of charge, respectively. Additionally, symbolizes the output power of the energy storage system, with and representing the minimum and maximum allowable output power limits, respectively.
3.1. A Scheduling Method Based on DRL
3.2. Parameterized Dueling DQN and DDPG Algorithms
- Time Slot Division: The entire operation period of the microgrid is divided into discrete time slots, each of length . This discretization allows for the modeling of microgrid dynamics and decision-making at specific intervals.
- Network Initialization: The neural network parameters are initialized, which includes setting up the weights of the Dueling DQN and DDPG networks. An experience replay buffer is also initialized to store past experiences (state, action, reward, next state) for use in training.
- Initial State Observation: The initial state of the microgrid is observed. This state typically includes information about the current load demand, renewable energy generation, storage levels, and other relevant factors affecting the microgrid’s operation.
- Discrete Action Selection: Based on the current state, the Dueling DQN selects a discrete action. This discrete action could represent high-level operational decisions, such as switching on or off certain distributed energy resources or selecting between predefined operational modes.
- Action Space Parameterization: The selected discrete action is parameterized to include corresponding continuous actions. These continuous actions represent finer-grained control, such as adjusting the power output of distributed energy resources or modulating the charge/discharge rates of storage devices.
- Network Strategy Evaluation: The DDPG algorithm evaluates the strategy of the Dueling DQN network by calculating the Q-values for each action in the parameterized action space. This evaluation involves assessing how well the selected actions are expected to perform in terms of the reward signal.
- Continuous Action Output: The DDPG algorithm then outputs deterministic values for the continuous actions. These values are precise control signals that specify the exact level of adjustment required for the distributed energy resources and other controllable elements within the microgrid.
- Action Vector Formation: The discrete actions selected by the Dueling DQN and the continuous actions determined by the DDPG are combined to form a complete action vector. This vector represents the full set of operational decisions to be implemented in the microgrid during the current time slot.
- Reward and State Transition: After the action vector is executed, the microgrid environment transitions to a new state. The immediate reward is obtained based on the operational cost, efficiency, and reliability of the microgrid in the new state. The reward reflects how well the microgrid is performing according to the optimization objectives.
- Gradient Calculation: A random batch of past experiences is sampled from the experience replay buffer. The gradient of the loss function is calculated using this batch, which helps in reducing the temporal difference error between the predicted Q-values and the target Q-values.
- Network Weight Update: The calculated gradients are used to update the weights of the Dueling DQN and DDPG networks. This weight update process enables the networks to improve their performance over time as they learn from the cumulative experience stored in the replay buffer.
- Iteration: The process from step (3) to step (11) is repeated iteratively. This loop continues until the network converges (i.e., when the Q-values stabilize and the reward no longer significantly improves) or until a maximum number of training iterations is reached. Convergence indicates that the network has effectively learned the optimal control strategy for the microgrid.
4. Simulation and Result Analysis
4.1. Simulation Parameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Size of the experience pool | 20,000 |
| Batch size | 128 |
| 0.95 | |
| Maximum iterations | 20,000 |
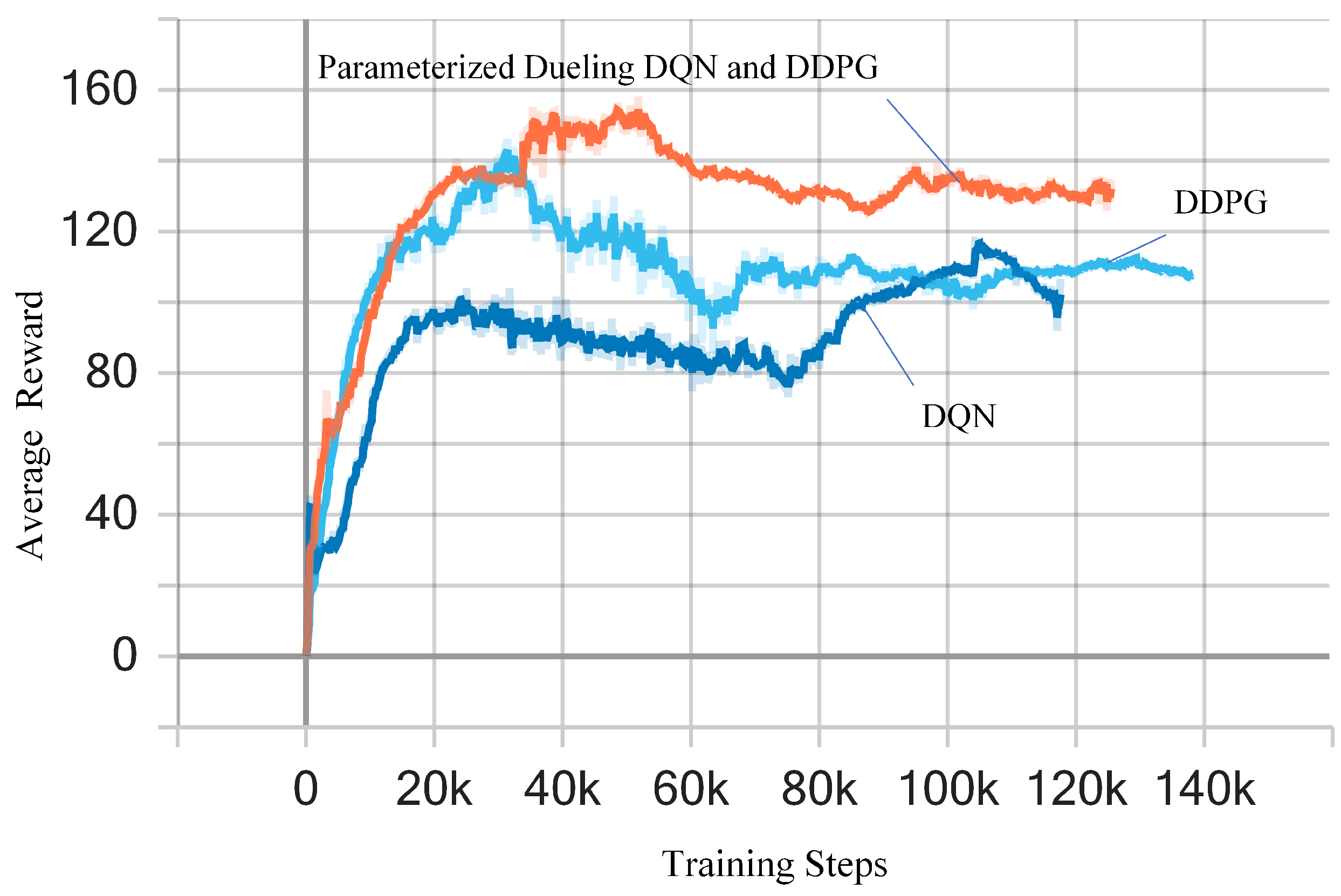
4.2. Discussion and Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, D.; Dragicevic, T.; Vasquez, J.C.; Guerrero, J.M.; Guan, Y. Secondary coordinated control of islanded microgrids based on consensus algorithms. In Proceedings of the 2014 IEEE Energy Conversion Congress and Exposition (ECCE), Pittsburgh, PA, USA, 14–18 September 2014; pp. 4290–4297. [Google Scholar] [CrossRef]
- Chen, B.; Jiang, J.; Shao, Y. Integrated Scheduling and Control System of Microgrid Based on Dynamic Programming Algorithm. In Proceedings of the 2023 IEEE International Conference on Integrated Circuits and Communication Systems (ICICACS), Raichur, India, 24–25 February 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Dai, X.; Tang, Y.; Yao, S. Application of genetic algorithm and particle swarm algorithm in microgrid dispatch model considering energy storage. In Proceedings of the 2023 IEEE 6th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 15–17 December 2023; pp. 850–854. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Zhao, K.; Deng, H.; Wang, F.; Zhuo, F. PEDF (Photovoltaics, Energy Storage, Direct Current, Flexibility) Microgrid Cost Optimization Based on Improved Whale Optimization Algorithm. In Proceedings of the 2023 IEEE 14th International Symposium on Power Electronics for Distributed Generation Systems (PEDG), Shanghai, China, 9–12 June 2023; pp. 598–603. [Google Scholar] [CrossRef]
- Ghavifekr, A.A.; Mohammadzadeh, A.; Ardashir, J.F. Optimal Placement and Sizing of Energy-related Devices in Microgrids Using Grasshopper Optimization Algorithm. In Proceedings of the 2021 12th Power Electronics, Drive Systems, and Technologies Conference (PEDSTC), Tabriz, Iran, 2–4 February 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Wan, L.; Liu, L.; Cai, D.; Chen, R.; Rao, Y.; Liu, H.; Xie, L. Load frequency control of isolated microgrid based on soft actor-critic algorithm. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; pp. 710–715. [Google Scholar] [CrossRef]
- Wu, J.; Birong, X.; Shulei, D. Dynamic Economic Dispatch of MicroGrid Using Improved Imperialist Competitive Algorithm. In Proceedings of the 2015 8th International Conference on Intelligent Computation Technology and Automation (ICICTA), Nanchang, China, 14–15 June 2015; pp. 397–401. [Google Scholar] [CrossRef]
- Vergara, P.P.; Torquato, R.; da Silva, L.C.P. Towards a real-time Energy Management System for a Microgrid using a multi-objective genetic algorithm. In Proceedings of the 2015 IEEE Power & Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Shuai, H.; Li, F.; Pulgar-Painemal, H.; Xue, Y. Branching Dueling Q-Network-Based Online Scheduling of a Microgrid with Distributed Energy Storage Systems. IEEE Trans. Smart Grid 2021, 12, 5479–5482. [Google Scholar] [CrossRef]
- Fan, Z.; Zhang, W.; Liu, W. Multi-Agent Deep Reinforcement Learning-Based Distributed Optimal Generation Control of DC Microgrids. IEEE Trans. Smart Grid 2023, 14, 3337–3351. [Google Scholar] [CrossRef]
- Chen, W.; Wu, N.; Huang, Y. Real-Time Optimal Dispatch of Microgrid Based on Deep Deterministic Policy Gradient Algorithm. In Proceedings of the 2021 International Conference on Big Data and Intelligent Decision Making (BDIDM), Guilin, China, 23–25 July 2021; pp. 24–28. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Dasgupta, S. A Distributed Control in Islanded DC Microgrid based on Multi-Agent Deep Reinforcement Learning. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 2359–2363. [Google Scholar] [CrossRef]
- Islam, S.; Mostaghim, S.; Hartmann, M. A Survey on Multi-Objective Optimization in Microgrid Systems. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Bjerland, S.; Del Granado, P.C.; GrØttum, H.; Nokandi, E. TSO-DSO Coordination Under Wind and Solar Power Uncertainty: A Two-Stage Stochastic Programming Approach. In Proceedings of the 2024 20th International Conference on the European Energy Market (EEM), Istanbul, Turkiye, 10–12 June 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Song, K.; Feng, J.; Ying, Z. Optimized operation of microgrid based on improved honey badger algorithm. In Proceedings of the 2024 3rd International Conference on Energy, Power and Electrical Technology (ICEPET), Chengdu, China, 17–19 May 2024; pp. 654–660. [Google Scholar] [CrossRef]
- Wang, X.; Vinel, A. Cross learning in deep q-networks. arXiv 2020, arXiv:2009.13780. [Google Scholar]
- Lin, N.; Tang, H.; Zhao, L.; Wan, S.; Hawbani, A.; Guizani, M. A PDDQNLP Algorithm for Energy Efficient Computation Offloading in UAV-Assisted MEC. IEEE Trans. Wirel. Commun. 2023, 22, 8876–8890. [Google Scholar] [CrossRef]
- Molotov, P.; Vaskov, A.; Tyagunov, M. Modeling Processes in Microgrids with Renewable Energy Sources. In Proceedings of the 2018 International Ural Conference on Green Energy (UralCon), Chelyabinsk, Russia, 4–6 October 2018; pp. 203–208. [Google Scholar] [CrossRef]
- Quan, D.; Tang, L.; Wang, X.; Xie, H. Battery-storage-centered Microgrids: Modelling and Simulation Demonstration. In Proceedings of the 2023 IEEE Sustainable Power and Energy Conference (iSPEC), Chongqing, China, 29–30 November 2023; pp. 1–6. [Google Scholar] [CrossRef]





| Maximum Capacity/kW·h | Minimum Capacity/kW·h | Maximum Charging Power/kW | Maximum Charging Power/kW | Charge/Discharge Factor |
|---|---|---|---|---|
| 200 | 200 | 20 | 20 | 0.9 |
| Maximum Output Power/kW | Electrical Efficiency |
|---|---|
| 100 | 28% |
| Network | Batch Size | Learning Rate | Memory Size | Input Layer | Hidden Layer | Output Layer |
|---|---|---|---|---|---|---|
| DDPG (actor) | 128 | 2000 | + | [256, 128, 64] | a(t).dim | |
| Dueling DQN (critic, V) | 128 | 2000 | [256, 128, 64] | 1 | ||
| Dueling DQN (critic, A) | 128 | 2000 | [256, 128, 64] | a(t).dim |
| Algorithm | Average Reward | Convergence Variance |
|---|---|---|
| Parameterized Dueling DQN and DDPG | 157.65 | 0.254 |
| DDPG | 131.89 | 0.185 |
| DQN | 109.45 | 0.148 |
| Greedy algorithm | 85.32 | 0.076 |
| Genetic algorithm | 94.43 | 0.463 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Li, Q.; Jiang, Y.; Lu, X. Parametric Dueling DQN- and DDPG-Based Approach for Optimal Operation of Microgrids. Processes 2024, 12, 1822. https://doi.org/10.3390/pr12091822
Huang W, Li Q, Jiang Y, Lu X. Parametric Dueling DQN- and DDPG-Based Approach for Optimal Operation of Microgrids. Processes. 2024; 12(9):1822. https://doi.org/10.3390/pr12091822
Chicago/Turabian StyleHuang, Wei, Qing Li, Yuan Jiang, and Xiaoya Lu. 2024. "Parametric Dueling DQN- and DDPG-Based Approach for Optimal Operation of Microgrids" Processes 12, no. 9: 1822. https://doi.org/10.3390/pr12091822