



Monitoring and Predicting Air Quality with IoT Devices



Abstract
:1. Introduction
- RO1: Identifying hotspot areas from the air and noise pollution point of view by developing an IoT system (the hardware and software components) responsible for data gathering, reading sensors’ values, and uploading them on the cloud/web server;
- RO2: Developing the software application (data analytics level of IoT system) for continuous information about indoor and outdoor environment quality, possible threats, and advice;
- RO3: Implementing the prediction algorithms of weather parameters and pollutant trends;
- RO4: Implementing the module for data visualization and proposing suggestions for decision-makers.
2. Related Work
3. Proposed Solution
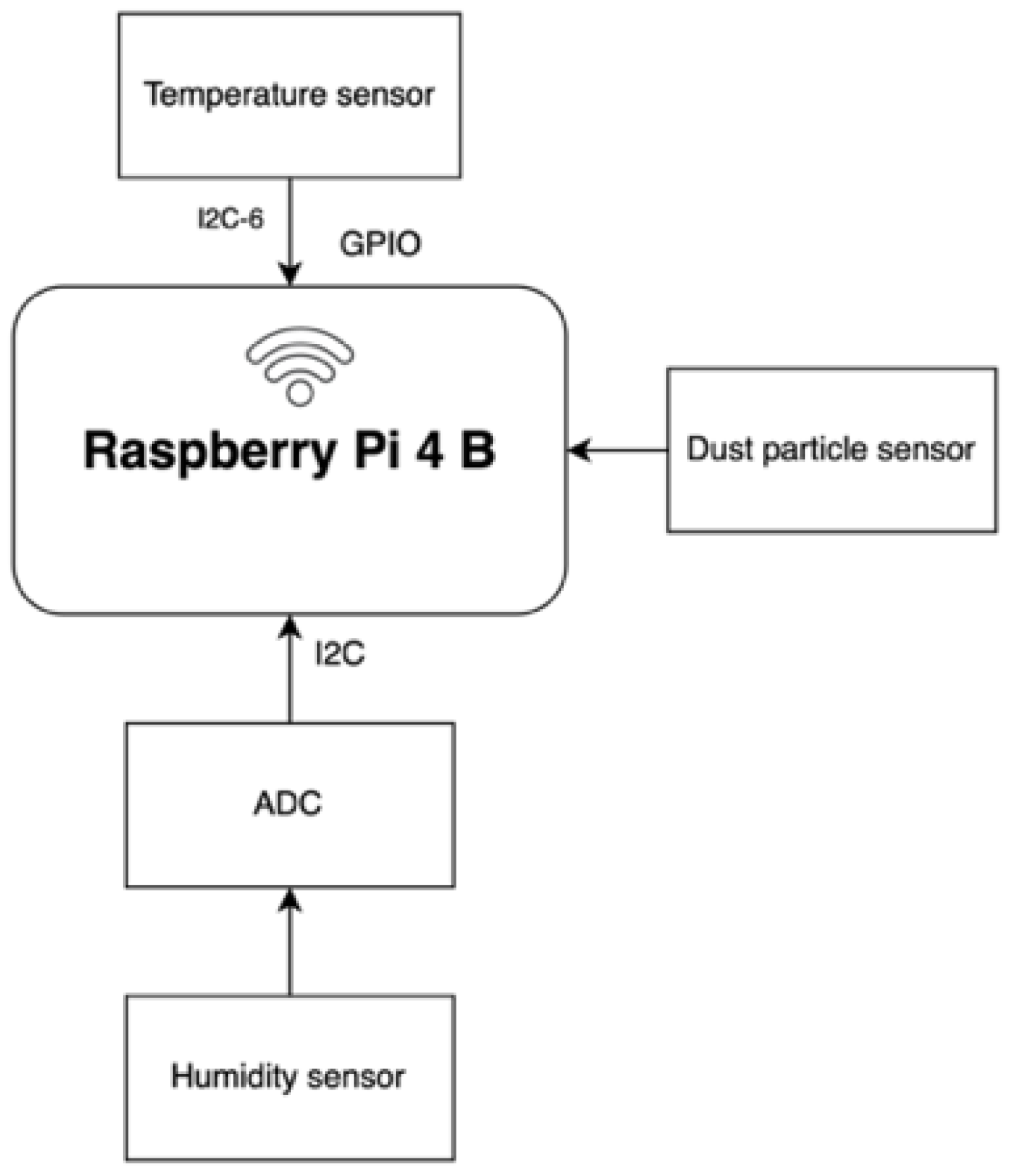
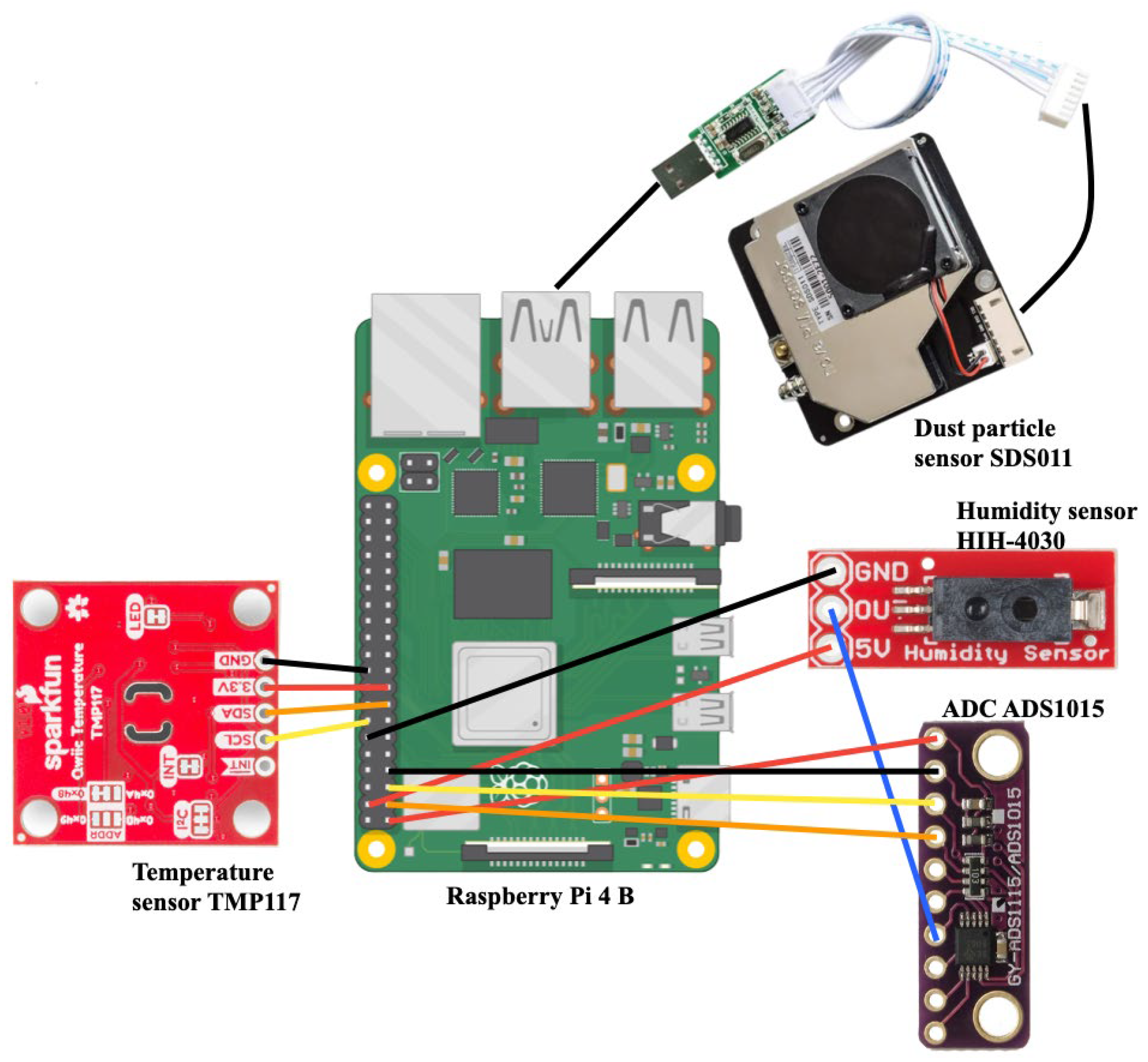
3.1. Hardware Part
3.1.1. Raspberry Pi 4 B
3.1.2. Temperature Sensor TMP117
3.1.3. Humidity Sensor HIH-4030
3.1.4. Analog–Digital Converter ADS1015
3.1.5. Dust Particle Sensor SDS011
3.2. Software Part
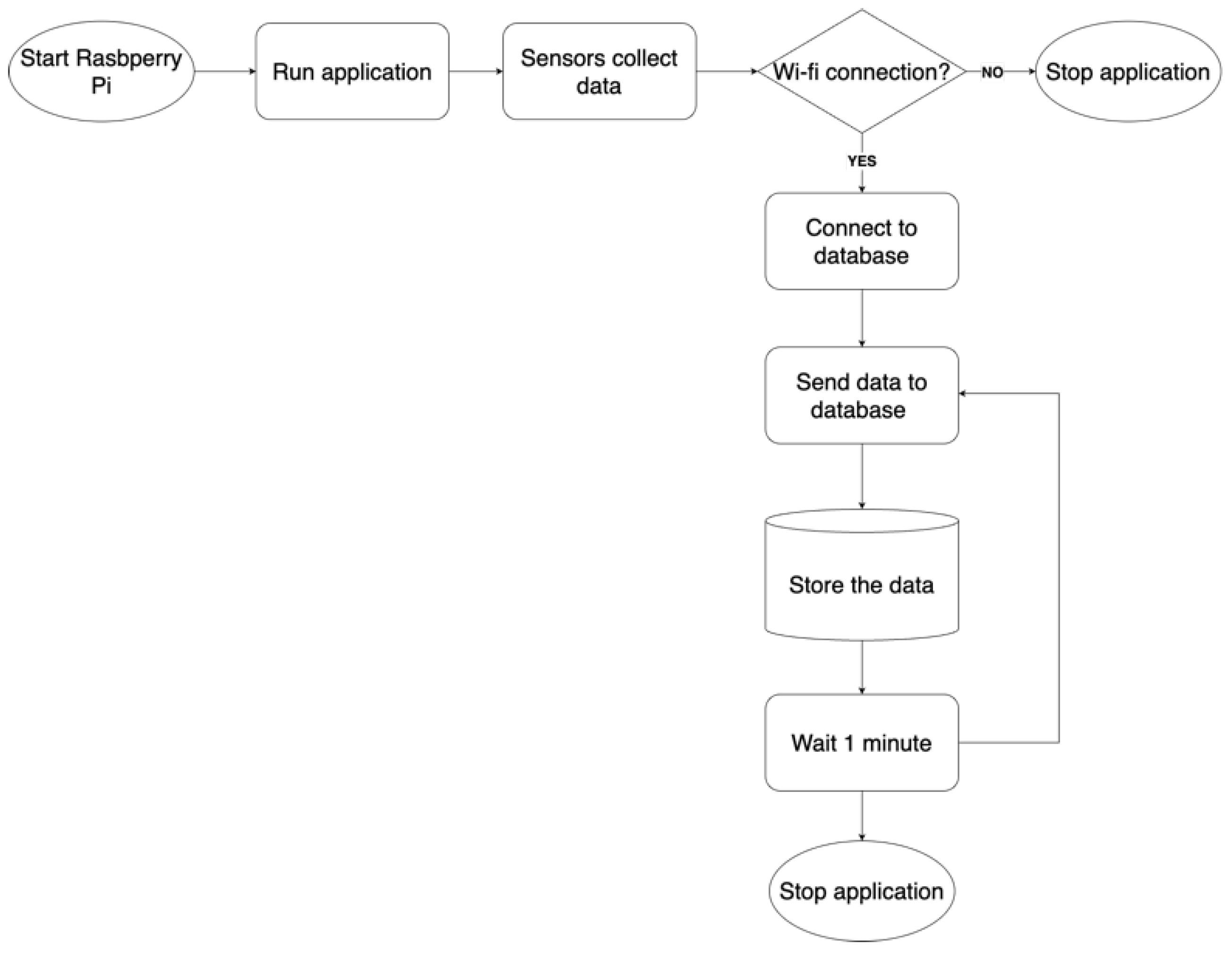
3.2.1. Acquisition of Data by Sensors

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Daily AQI Color | Levels of Concern | Values of Index | Description of Air Quality |
|---|---|---|---|
| Green | Air quality is satisfactory, | ||
| Good | 0 to 50 | and air pollution poses | |
| little or no risk. | |||
| Yellow | Air quality is acceptable. However, there may be a risk for some people, | ||
| Moderate | 51 to 100 | particularly those who are usually | |
| sensitive to air pollution. | |||
| Orange | Members of sensitive groups | ||
| Unhealthy for Sensitive Groups | 101 to 150 | may experience health effects. The public is less likely to be affected. | |
| Red | Some members of the general | ||
| Unhealthy | 151 to 200 | public may experience health effects: members of sensitive groups may experience more serious health effects. | |
| Purple | Health alert: The risk to health | ||
| Very Unhealthy | 201 to 300 | effects is increased for everyone. | |
| Maroon | Health warning of emergency | ||
| Hazardous | 301 and higher | conditions: everyone is more | |
| likely to be affected. |
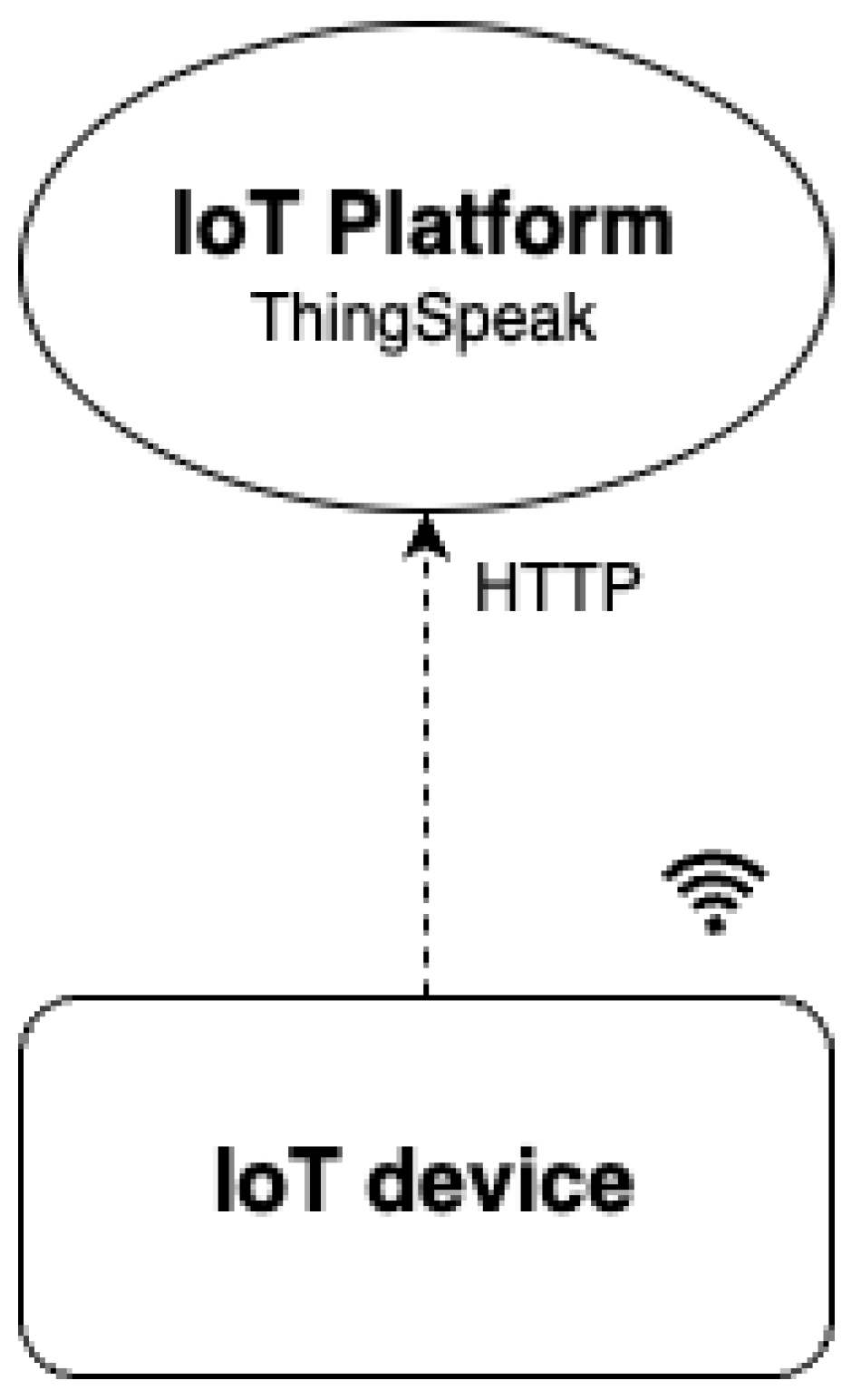
3.2.2. ThingSpeak Cloud Computing Platform
3.2.3. Making Predictions
- Air quality dataset collection
- 2.
- Data preprocessing
- Handling Missing Values: The method dropna(inplace = True) addresses missing values by removing the rows with any missing data. This ensures that the dataset used for training and testing does not contain null or missing entries.
- Outlier Detection and Removal using IQR: Outliers are detected using the Interquartile Range (IQR) method. The IQR is calculated by subtracting the first quartile (Q1) from the third quartile (Q3). Outliers are defined as values that lie below Q1−1.5IQR or above Q3 + 1.5IQR. These rows are removed from the dataset.
- Data Transformation: The PowerTransformer with the yeo–johnson method [39] is used to transform the selected numeric columns (temperature, humidity, pm10, and pm25). The Yeo–Johnson transformation is suitable for data that include both positive and negative values. It adjusts the distribution to be more Gaussian-like without losing information. By making the data more Gaussian-like, it can often improve the performance and stability of the machine learning models.
- Converting Data Types to Float: To ensure consistency in the data format, the numeric columns are converted to float. This is crucial for accurate computations, especially in machine learning models, which often require numeric input data in the float format.
- Normalization or Standardization: The code uses the StandardScaler method to standardize the feature values. This scales the data so that it has a mean of 0 and a standard deviation of 1, which helps certain machine learning models perform better, especially those that are sensitive to the scale of input data.
- 3.
- Splitting training and test dataset
- 4.
- Feature selection
- Correlation Analysis: Evaluating the correlation between each feature and the target variable.
- Feature Importance Scores: Using algorithms like random forests to rank feature importance.
- 5.
- Regression analysis
- Simplicity and Interpretability: Linear regression is a computationally efficient, simple, and easy-to-understand technique. The correlation between the variables is easily understood because the coefficients show the precise influence of each predictor.
- Low Variance: Compared to more complex models, linear regression is less prone to overfitting because it is based on a single model.
- Helpful for Small Datasets: It works effectively with smaller datasets with a linear relationship.
- Assumption of Linearity: Linear regression assumes a linear relationship between the independent and dependent variables, which limits its effectiveness in capturing complex patterns.
- Sensitivity to Outliers: Linear regression is sensitive to outliers, which can distort the model and affect its prediction accuracy.
- Limited in Handling Multicollinearity: Multicollinearity among predictor variables can impact the stability of the model coefficients.
- Robustness to Outliers and Noise: RF models are resilient to outliers and noise due to their ensemble approach, which averages out extreme predictions from individual trees.
- Ability to Capture Non-Linear Relationships: Unlike linear regression, random forests can model complex, non-linear relationships between the predictor and response variables.
- Feature Importance: RF can rank the importance of variables, providing insights into which predictors have the most influence on the outcome.
- Complexity and Interpretability: Unlike linear regression, RF models are complex and less interpretable, making it difficult to understand how individual predictions are made.
- Higher Computational Cost: RF requires more computational resources and time, especially with large datasets and many trees.
- Tendency to overfit: Although reduced by bagging, random forests can still overfit, particularly when too many trees are used or if not properly tuned.
- 6.
- Air quality prediction metrics
4. Results
5. Discussions
6. Conclusions and Further Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fahmi, N.; Prayitno, E.; Musri, T.; Supria, S.; Ananda, F. An Implementation Environmental Monitoring Real-time IoT Technology. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20 July 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Li, H.; Xu, X.L.; Dai, D.W.; Huang, Z.Y.; Ma, Z.; Guan, Y.J. Air pollution and temperature are associated with increased COVID-19 incidence: A time series study. Int. J. Infect. Dis. 2020, 97, 278–282. [Google Scholar] [CrossRef] [PubMed]
- HEPA (Health and Energy Platform of Action). Call to Action to Increase Climate Resilience of Health Care Facilities & Air Quality Through Sustainable Energy. 2022. Available online: https://www.who.int/publications/m/item/call-to-action-to-increase-climate-resilience-of-health-care-facilities---air-quality-through-sustainable-energy (accessed on 10 June 2024).
- Florea, A.; Berntzen, L.; Johannessen, M.R.; Stoica, D.; Naicu, I.S.; Cazan, V. Low cost mobile embedded system for air quality monitoring. In Proceedings of the Sixth International Conference on Smart Cities, Systems, Devices and Technologies (SMART), Venice, Italy, 25–29 June 2017; pp. 25–29. [Google Scholar]
- Ullo, S.L.; Sinha, G.R. Advances in Smart Environment Monitoring Systems Using IoT and Sensors. Sensors 2020, 20, 3113. [Google Scholar] [CrossRef] [PubMed]
- Laha, S.R.; Pattanayak, B.K.; Pattnaik, S. Advancement of Environmental Monitoring System Using IoT and Sensor: A Comprehensive Analysis. AIMS Environ. Sci. 2022, 9, 771–800. [Google Scholar] [CrossRef]
- Hassan, M.N.; Islam, M.R.; Faisal, F.; Semantha, F.H.; Siddique, A.H.; Hasan, M. An IoT based Environment Monitoring System. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; pp. 1119–1124. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, Y.; Jiang, X.; Jin, C.; Wu, S.; Zhou, X. Estimation of the PM2.5 and PM10 Mass Concentration over Land from FY-4A Aerosol Optical Depth Data. Remote Sens. 2021, 13, 4276. [Google Scholar] [CrossRef]
- Mokrani, H.; Lounas, R.; Bennai, M.T.; Salhi, D.E.; Djerbi, R. Air Quality Monitoring Using IoT: A Survey. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 127–134. [Google Scholar]
- Tran, Q.; Dang, Q.; Le, T.; Nguyen, H.-T.; Tan, L. Air Quality Monitoring and Forecasting System using IoT and Machine Learning Techniques. In Proceedings of the 2022 6th International Conference on Green Technology and Sustainable Development (GTSD 2022), Nha Trang City, Vietnam, 29 July 2022; pp. 786–792. [Google Scholar]
- Lalitha, K.V.; Naveen, A.V.; Supriya, A.S.V.; Nagalakshmi, P.S.R.; Kantham, P.S. Realtime Air Quality Evaluator Using Iot and Machine Learning. Int. J. Eng. Res. Technol. 2024, 13. [Google Scholar] [CrossRef]
- Khanna, A.; Kaur, S. Internet of Things (IoT), Applications and Challenges: A Comprehensive Review. Wirel. Pers Commun. 2020, 114, 1687–1762. [Google Scholar] [CrossRef]
- Saini, J.; Dutta, M.; Marques, G. Indoor Air Quality Monitoring Systems Based on Internet of Things: A Systematic Review. Int. J. Environ. Res. Public Health 2020, 17, 4942. [Google Scholar] [CrossRef] [PubMed]
- Abdulmalek, S.; Nasir, A.; Jabbar, W.A.; Almuhaya, M.A.M.; Bairagi, A.K.; Khan, M.A.; Kee, S.H. IoT-Based Healthcare-Monitoring System towards Improving Quality of Life: A Review. Healthcare 2022, 10, 1993. [Google Scholar] [CrossRef] [PubMed]
- Gangwar, A.; Singh, S.; Mishra, R.; Prakash, S. The State-of-the-Art in Air Pollution Monitoring and Forecasting Systems Using IOT, Big Data, and Machine Learning. Wirel. Pers. Commun. 2023, 130, 1699–1729. [Google Scholar] [CrossRef]
- Sai, K.B.K.; Mukherjee, S.; Sultana, H.P. Low Cost IoT Based Air Quality Monitoring Setup Using Arduino and MQ Series Sensors with Dataset Analysis. Procedia Comput. Sci. 2019, 165, 322–327. [Google Scholar] [CrossRef]
- Karnati, H. IoT-Based Air Quality Monitoring System with Machine Learning for Accurate and Real-time Data Analysis. arXiv 2023, arXiv:2307.00580. [Google Scholar] [CrossRef]
- Cincinelli, A.; Martellini, T. Indoor Air Quality and Health. Int. J. Env. Res. Public Health 2017, 14, 1286. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Al Horr, Y.; Arif, M.; Katafygiotou, M.; Mazroei, A.; Kaushik, A.; Elsarrag, E. Impact of indoor environmental quality on occupant well-being and comfort: A review of the literature. Int. J. Sustain. Built Environ. 2016, 5, 1–11. [Google Scholar] [CrossRef]
- Zhang, L.; Ou, C.; Magana-Arachchi, D.; Vithanage, M.; Vanka, K.S.; Palanisami, T.; Masakorala, K.; Wijesekara, H.; Yan, Y.; Bolan, N.; et al. Indoor Particulate Matter in Urban Households: Sources, Pathways, Characteristics, Health Effects, and Exposure Mitigation. Int. J. Environ. Res. Public Health 2021, 18, 11055. [Google Scholar] [CrossRef]
- Pope, C.A., 3rd; Dockery, D.W. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- Gope, S.; Dawn, S.; Das, S.S. Effect of Covid-19 Pandemic on Air Quality: A Study Based on Air Quality Index. Environ. Sci. Pollut. Res. 2021, 28, 35564–35583. [Google Scholar] [CrossRef] [PubMed]
- Sarmadi, M.; Rahimi, S.; Rezaei, M.; Sanaei, D.; Dianatinasab, M. Air quality index variation before and after the onset of COVID-19 pandemic: A comprehensive study on 87 capital, industrial and polluted cities of the world. Environ. Sci. Eur. 2021, 33, 134. [Google Scholar] [CrossRef]
- Vadrevu, K.P.; Eaturu, A.; Biswas, S.; Lasko, K.; Sahu, S.; Garg, J.K.; Justice, C. Spatial and temporal variations of air pollution over 41 cities of India during the COVID-19 lockdown period. Sci. Rep. 2020, 10, 16574. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, S.; Zhang, Y. A review of IoT applications in healthcare. Neurocomputing 2024, 565, 127017. [Google Scholar] [CrossRef]
- Sofia, D.; Giuliano, A.; Gioiella, F.; Barletta, D.; Poletto, M. Modeling of an air quality monitoring network with high space-time resolution. Comput. Aided Chem. Eng. 2018, 43, 193–198. [Google Scholar]
- Himeur, Y.; Elnour, M.; Fadli, F.; Meskin, N.; Petri, I.; Rezgui, Y.; Bensaali, F.; Amira, A. AI-big data analytics for building automation and management systems: A survey, actual challenges and future perspectives. Artif. Intell. Rev. 2023, 56, 4929–5021. [Google Scholar] [CrossRef] [PubMed]
- Raspberry Pi Trading Ltd. Raspberry Pi 4 Computer Model B. Available online: https://www.raspberrypi.com/products/raspberry-pi-4-model-b/specifications/ (accessed on 11 June 2024).
- Texas Instruments. TMP117 High-Accuracy, Low-Power, Digital Temperature Sensor with SMBusTM- and I2C-Compatible Interface. Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/1083213/TI1/TMP117.html (accessed on 16 September 2022).
- Honeywell. HIH-4030 Datasheet(PDF). Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/1242920/HONEYWELL/HIH-4030.html (accessed on 12 June 2024).
- Texas Instruments. “ADS1015 Datasheet(PDF)”. Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/541221/TI1/ADS1015.html (accessed on 12 June 2024).
- Microcontrollerslab. Nova PM SDS011 Dust Particle Sensor for Air Quality Measurement. Available online: https://microcontrollerslab.com/nova-pm-sds011-dust-sensor-pinout-working-interfacing-datasheet/#2D_Model (accessed on 12 June 2024).
- Pypi. Python-aqi 0.6.1. Available online: https://pypi.org/project/python-aqi/ (accessed on 12 June 2024).
- United States Environmental Protection Agency. Technical Assistance Document for the Reporting of Daily Air Quality—The Air Quality Index (AQI). EPA 454/B-18-007. 2018. Available online: https://www.airnow.gov/sites/default/files/2020-05/aqi-technical-assistance-document-sept2018.pdf (accessed on 13 June 2024).
- United States Environmental Protection Agency. Final Reconsideration of the National Ambient Air Quality Standards for Particulate Matter. 2024. Available online: https://www.epa.gov/pm-pollution/final-reconsideration-national-ambient-air-quality-standards-particulate-matter-pm (accessed on 13 June 2024).
- Maureira, M.A.G.; Oldenhof, D.; Teernstra, L. ThingSpeak—An API and Web Service for the Internet of Things. 2014. Available online: https://staas.home.xs4all.nl/t/swtr/documents/wt2014_thingspeak.pdf (accessed on 13 June 2024).
- Ahlawat, S. Introduction to TensorFlow. In Reinforcement Learning for Finance; Apress: Berkeley, CA, USA, 2023; pp. 5–137. [Google Scholar] [CrossRef]
- Aarthi, A.; Gayathri, P.; Gomathi, N.R.; Kalaiselvi, S.; Gomathi, V. Air quality prediction through regression model. Int. J. Sci. Technol. Res. 2020, 9, 923–928. Available online: http://www.ijstr.org/final-print/mar2020/Air-Quality-Prediction-Through-Regression-Model.pdf (accessed on 14 June 2024).
- Weisberg, S. Yeo-Johnson Power Transformations; Department of Applied Statistics, University of Minnesota: St. Paul, MN, USA, 2001. [Google Scholar]
- Aityan, S.K. Linear Regression. In Business Research Methodology; Springer: Berlin/Heidelberg, Germany, 2022; pp. 359–394. [Google Scholar] [CrossRef]
- Chen, L.; Gamage, P.W.; Ryan, J. Debias random forest regression predictors. J. Stat. Res. 2023, 56, 115–131. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, K.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Foong, N.; Chin, L.H.; Hoe, Q.S. Mean squared error—A tool to evaluate the accuracy of parameter estimators in regression. J. Qual. Meas. Anal. 2008, 4, 71–80. [Google Scholar]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 2016, 32, 669–679. [Google Scholar] [CrossRef]
- Jadon, A.; Patil, A.; Jadon, S. A Comprehensive Survey of Regression-Based Loss Functions for Time Series Forecasting. In Data Management, Analytics and Innovation, Proceedings of the International Conference on Data Management, Analytics & Innovation, Vellore, India, 19–21 January 2024; Springer: Singapore, 2024; Volume 998, pp. 117–147. [Google Scholar]
- Kreinovich, V.; Nguyen, H.T.; Ouncharoen, R. How to Estimate Forecasting Quality: A System-Motivated Derivation of Symmetric Mean Absolute Percentage Error (SMAPE) and Other Similar Characteristics; University of Texas at El Paso: El Paso, TX, USA, 2014. [Google Scholar]



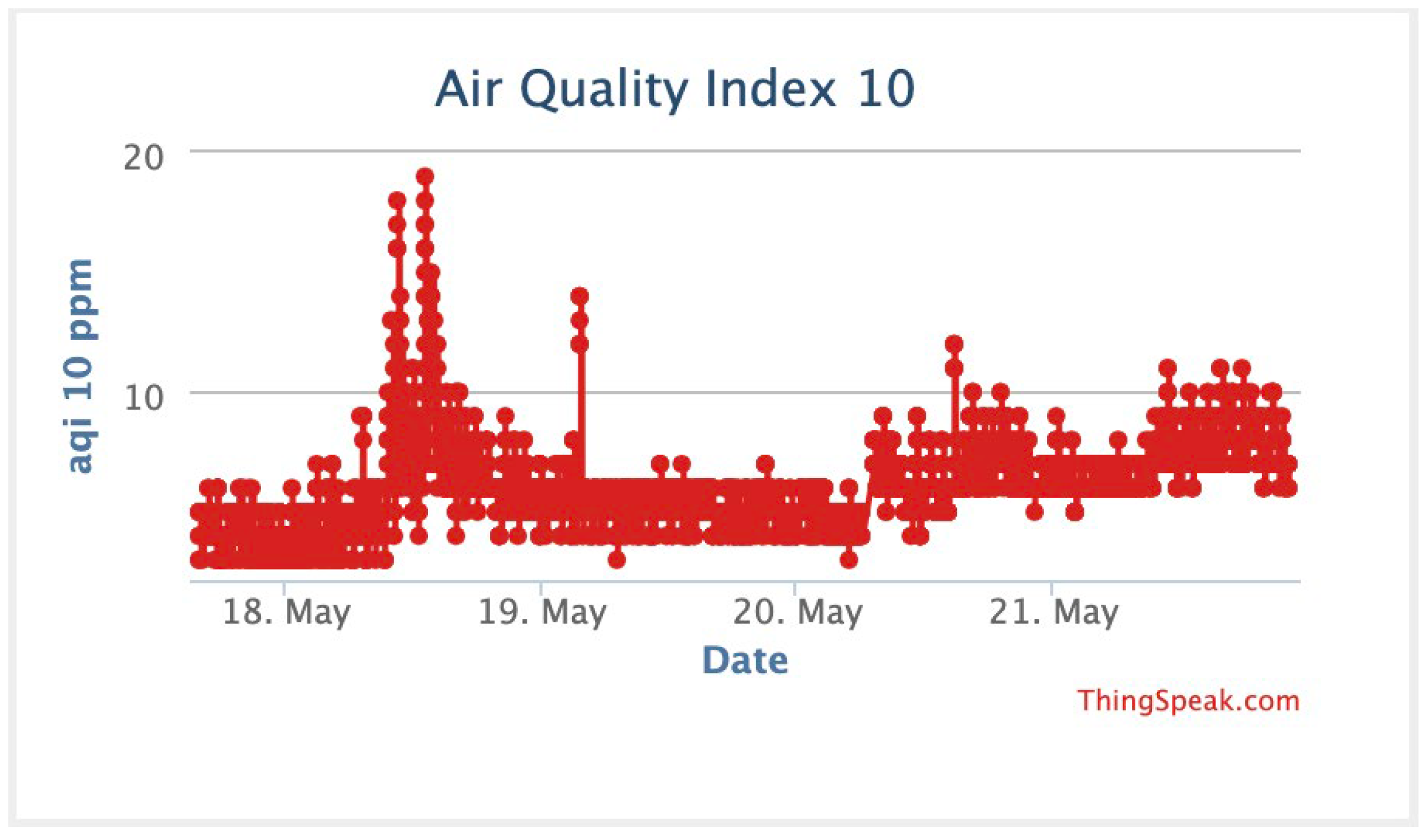
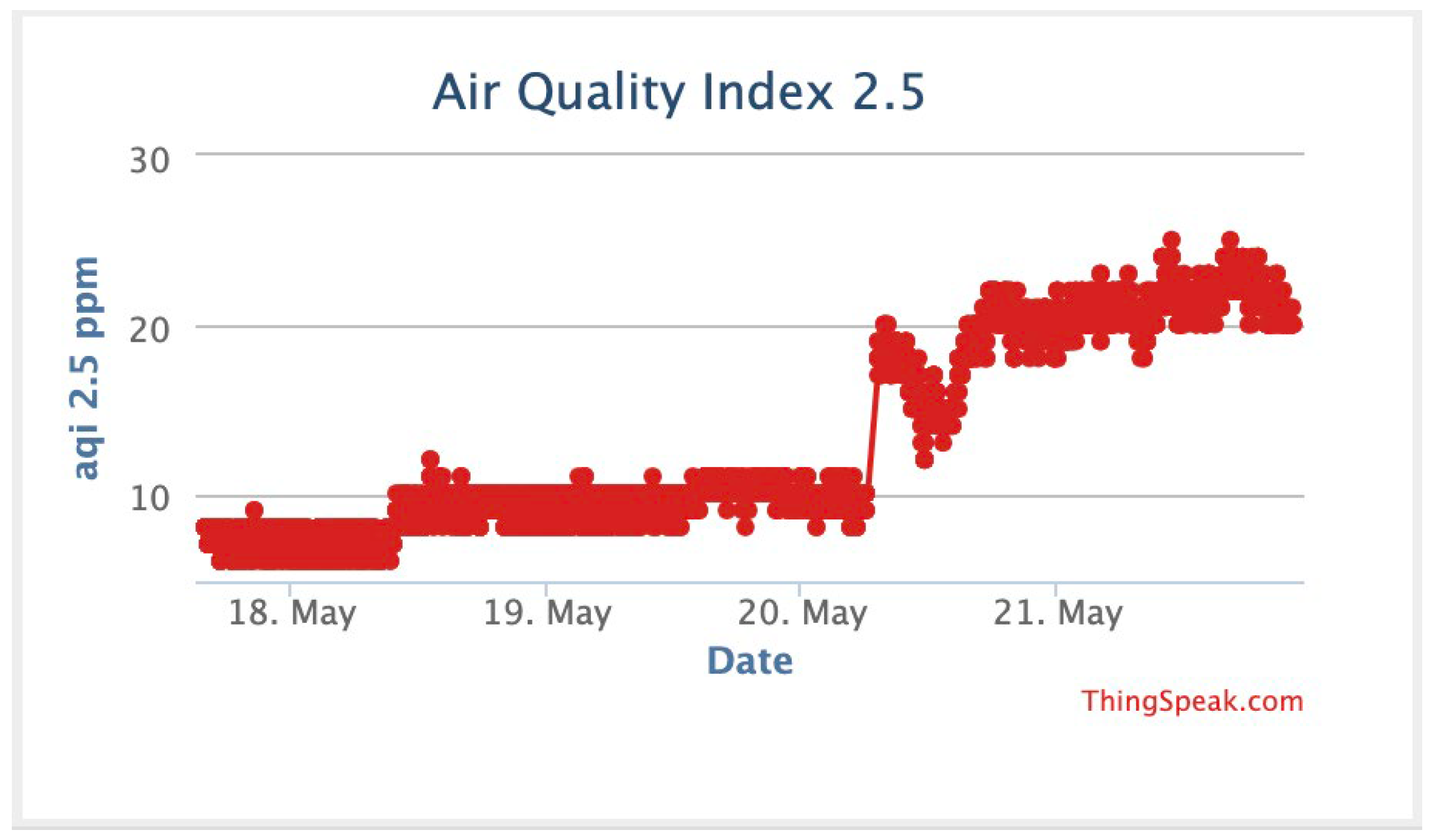
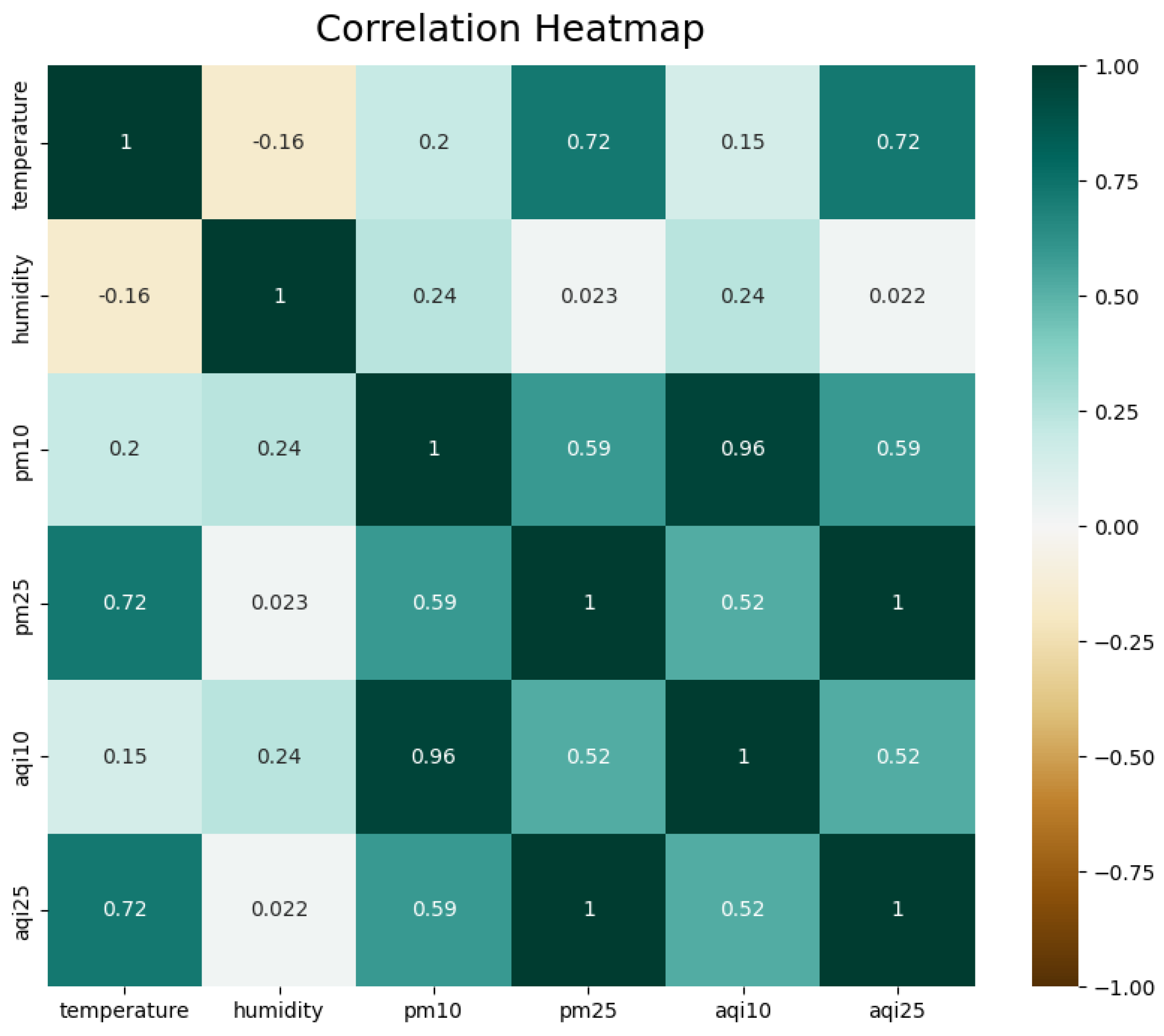
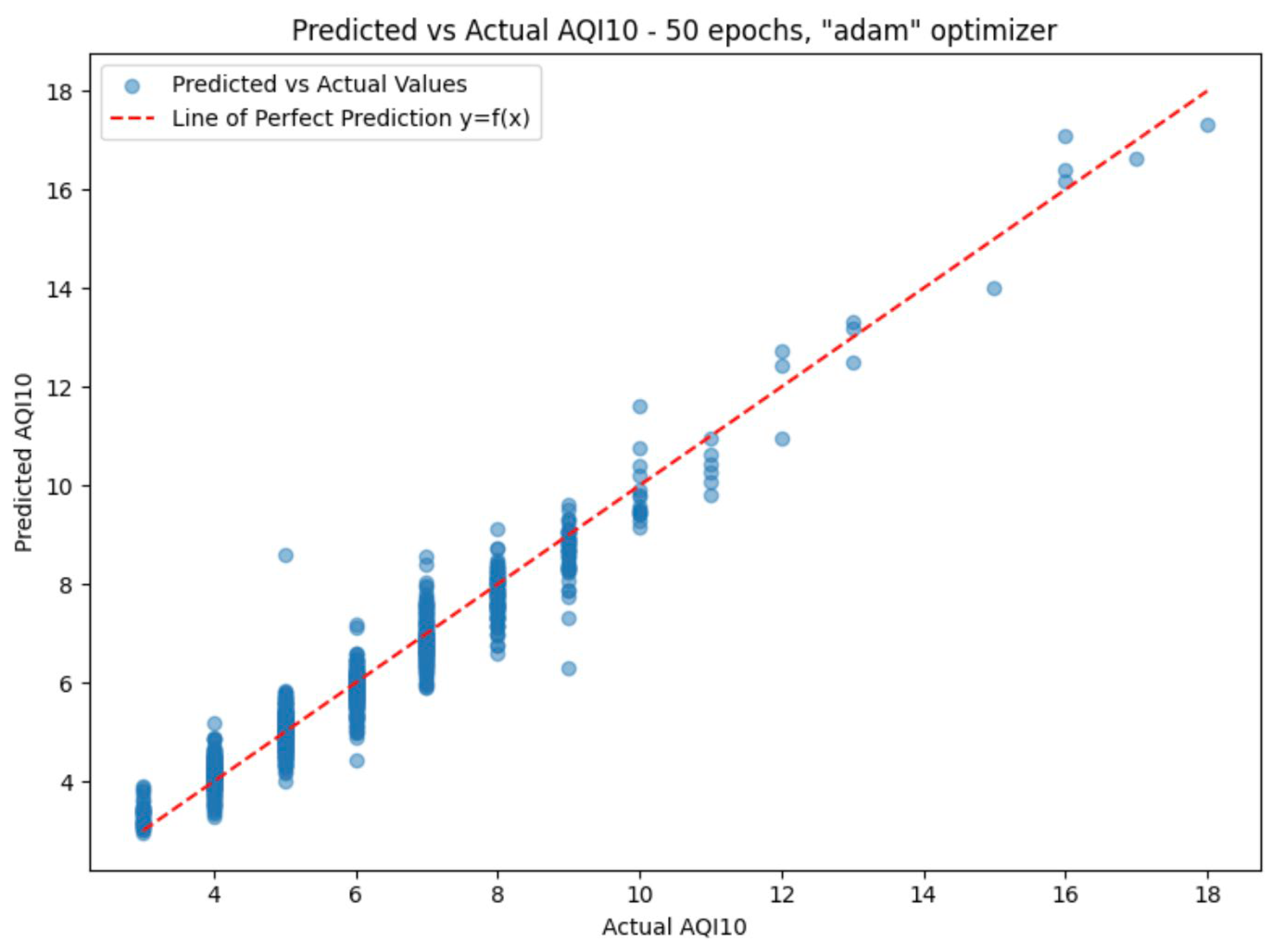
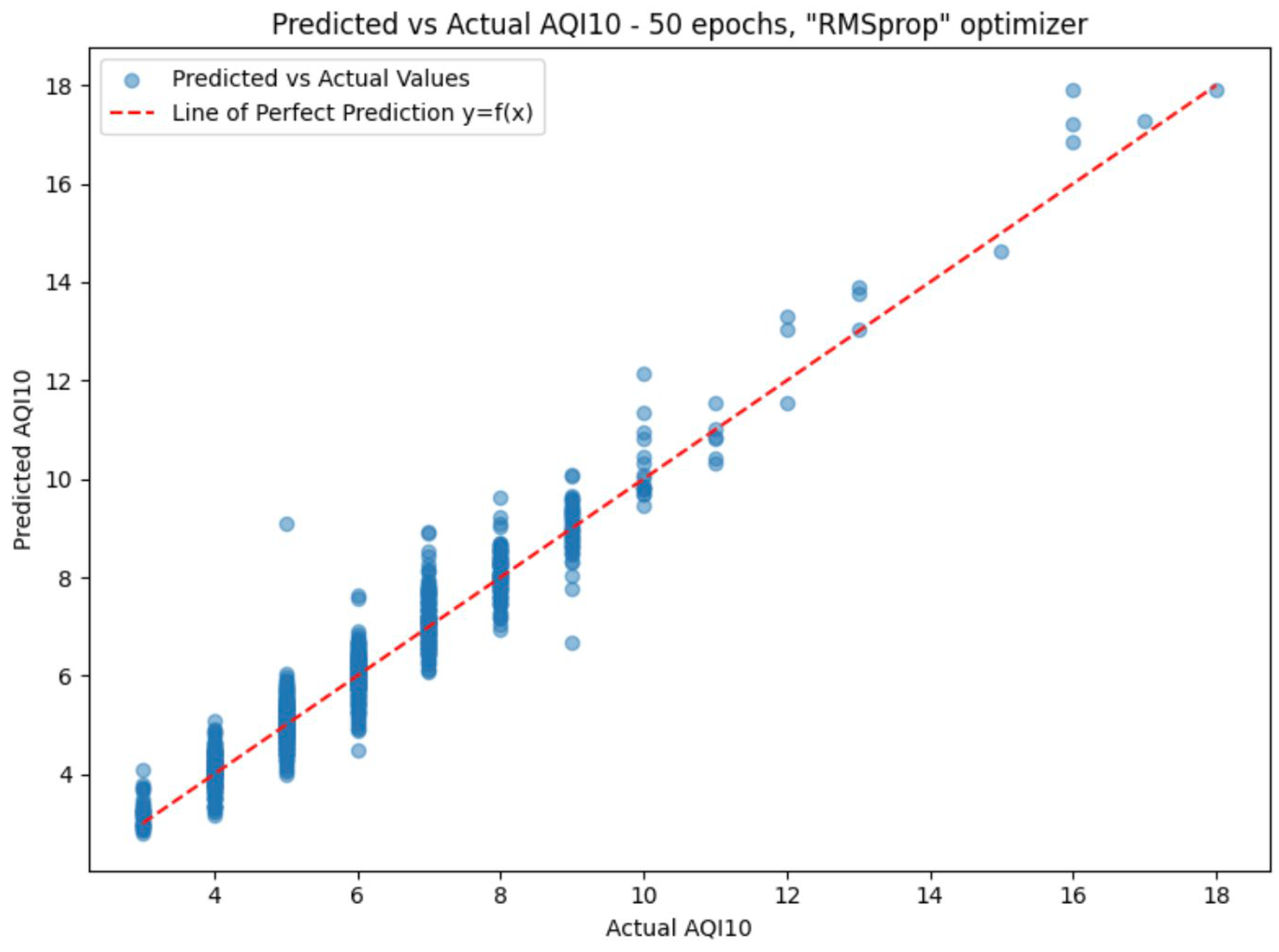

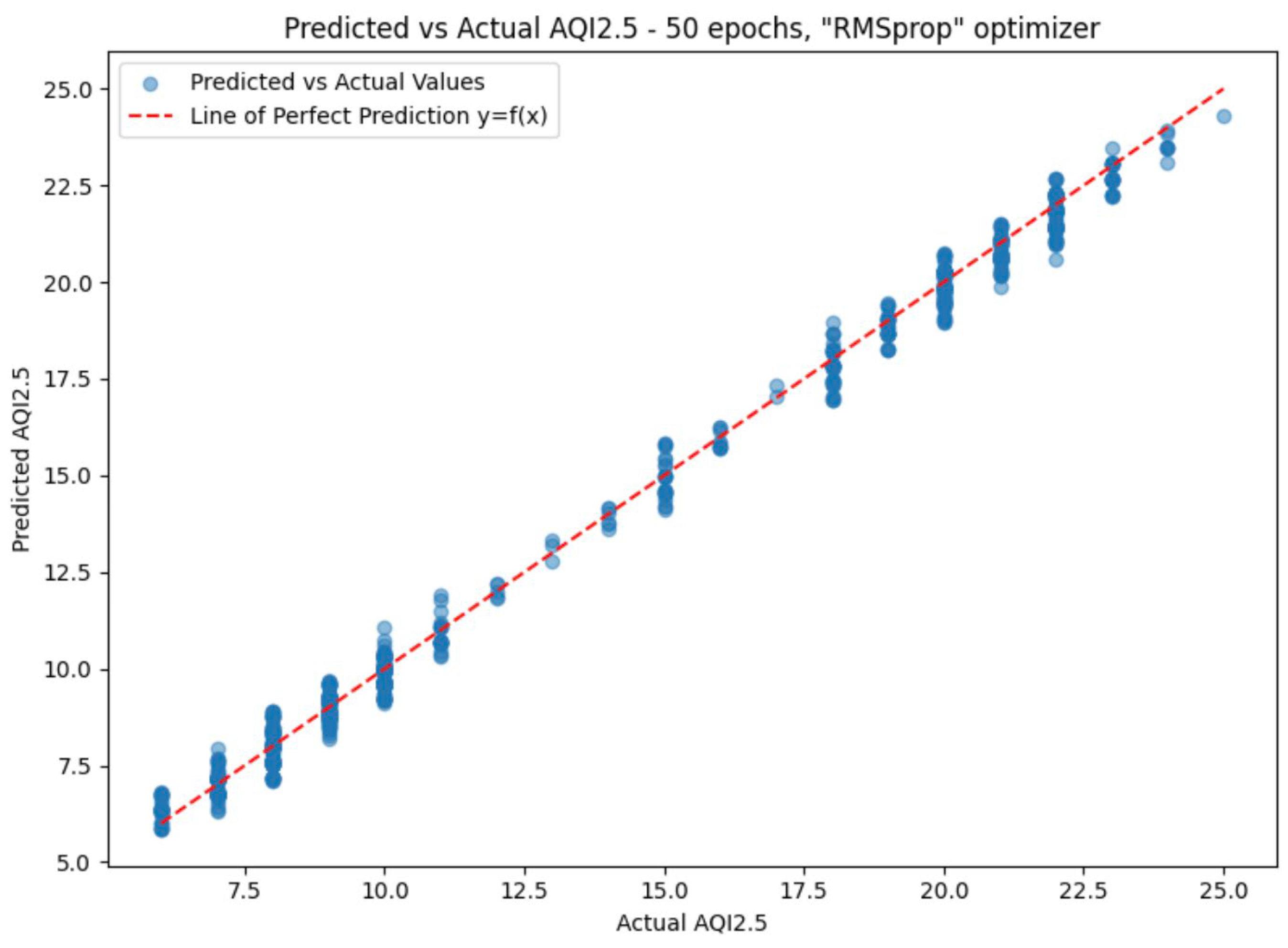

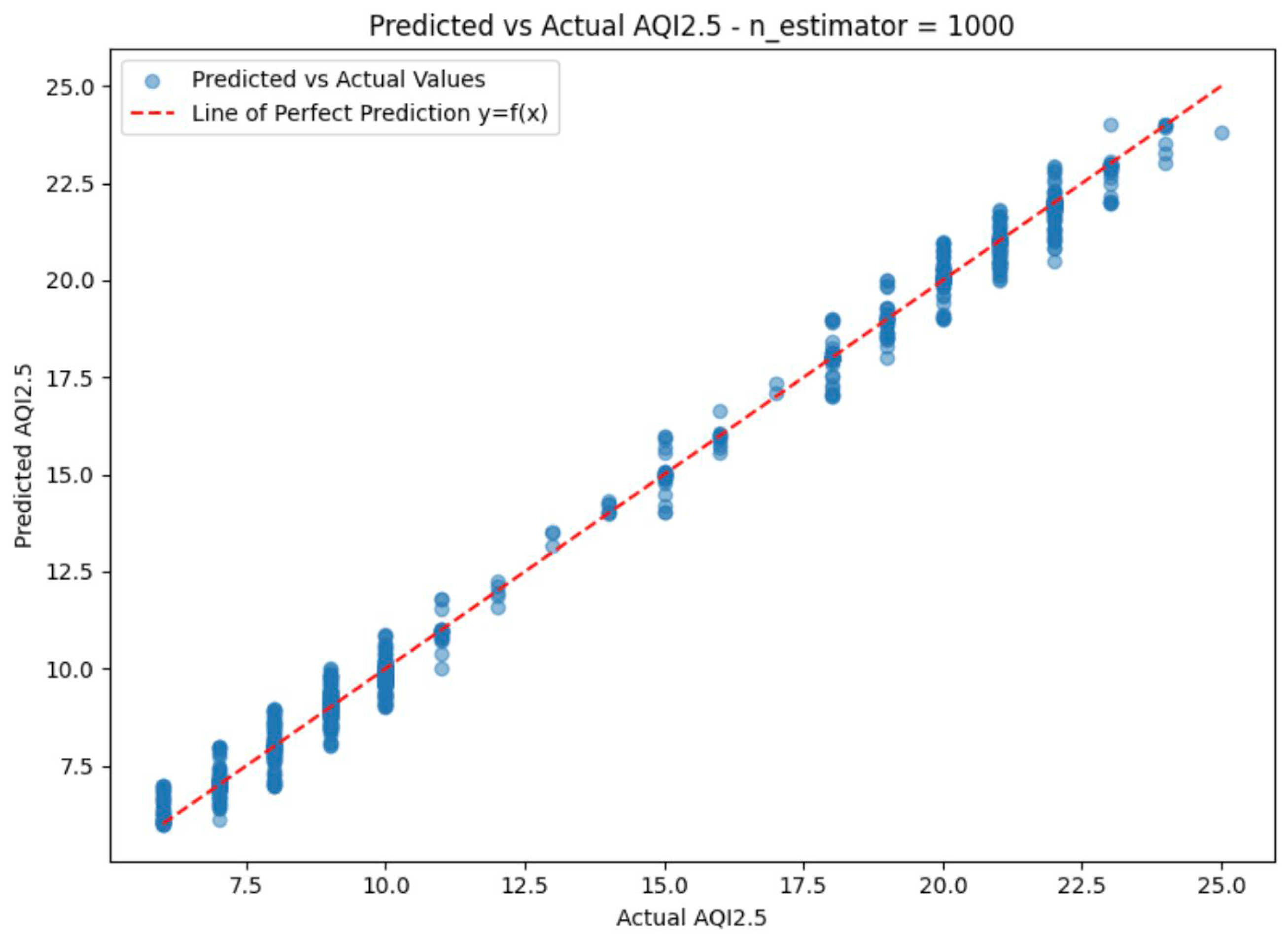
| Prediction Model | Epochs | AQI 10 | AQI 2.5 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 | ||
| ‘adam’ optimizer | 50 | 0.3289 | 0.1968 | 0.4437 | 0.9383 | 0.3205 | 0.1557 | 0.3946 | 0.9953 |
| 100 | 0.3276 | 0.1972 | 0.4440 | 0.9382 | 0.3211 | 0.1573 | 0.3966 | 0.9952 | |
| 500 | 0.3246 | 0.2032 | 0.4508 | 0.9363 | 0.3247 | 0.1622 | 0.4028 | 0.9951 | |
| 1000 | 0.3174 | 0.2102 | 0.4585 | 0.9341 | 0.3145 | 0.1494 | 0.3865 | 0.9955 | |
| ‘RMSprop’ optimizer | 50 | 0.3550 | 0.2202 | 0.4693 | 0.9309 | 0.3283 | 0.1678 | 0.4096 | 0.9949 |
| 100 | 0.3142 | 0.1901 | 0.4360 | 0.9404 | 0.3432 | 0.1795 | 0.4237 | 0.9946 | |
| 500 | 0.3145 | 0.1995 | 0.4467 | 0.9374 | 0.3222 | 0.1581 | 0.3976 | 0.9952 | |
| 1000 | 0.3088 | 0.2018 | 0.4492 | 0.9367 | 0.3361 | 0.1690 | 0.4111 | 0.9949 | |
| n_estimator | |||||||||
| Random Forest | 100 | 0.2785 | 0.2095 | 0.4577 | 0.9343 | 0.2483 | 0.1516 | 0.3894 | 0.9954 |
| 1000 | 0.2778 | 0.2086 | 0.4568 | 0.9346 | 0.2482 | 0.1503 | 0.3877 | 0.9955 | |
| Prediction Model | Epochs | AQI 10 | AQI 2.5 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | RMSLE | SMAPE | MDA | MedAE | MAPE | RMSLE | SMAPE | MDA | MedAE | ||
| ‘adam’ optimizer | 50 | 5.8233 | 0.0641 | 2.8391 | 0.8181 | 0.2574 | 2.9556 | 0.0350 | 1.4827 | 0.8973 | 0.3009 |
| 100 | 5.7407 | 0.0651 | 2.8698 | 0.8172 | 0.2519 | 3.0036 | 0.0349 | 1.4933 | 0.8973 | 0.2807 | |
| 500 | 5.6104 | 0.0639 | 2.7885 | 0.8163 | 0.2472 | 2.8540 | 0.0335 | 1.4272 | 0.9019 | 0.2716 | |
| 1000 | 5.5584 | 0.0643 | 2.7145 | 0.8154 | 0.2268 | 2.8293 | 0.0333 | 1.4046 | 0.9001 | 0.2645 | |
| ‘RMSprop’ optimizer | 50 | 5.7068 | 0.0644 | 2.8106 | 0.8154 | 0.2501 | 3.0410 | 0.0360 | 1.5331 | 0.8992 | 0.3048 |
| 100 | 5.9537 | 0.0656 | 2.8735 | 0.8145 | 0.2581 | 3.0137 | 0.0357 | 1.4772 | 0.8973 | 0.2952 | |
| 500 | 5.5275 | 0.0633 | 2.7228 | 0.8127 | 0.2385 | 3.0861 | 0.0357 | 1.5194 | 0.9001 | 0.2990 | |
| 1000 | 5.6649 | 0.0665 | 2.7507 | 0.8108 | 0.2193 | 3.0040 | 0.0357 | 1.5155 | 0.9000 | 0.3023 | |
| n_estimator | |||||||||||
| Random Forest | 100 | 4.8627 | 0.0662 | 4.7675 | 0.8151 | 0.1300 | 2.3673 | 0.0351 | 2.3568 | 0.8997 | 0.1100 |
| 1000 | 4.8703 | 0.0662 | 4.7767 | 0.8099 | 0.1340 | 2.3608 | 0.0348 | 2.3490 | 0.8971 | 0.1140 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banciu, C.; Florea, A.; Bogdan, R. Monitoring and Predicting Air Quality with IoT Devices. Processes 2024, 12, 1961. https://doi.org/10.3390/pr12091961
Banciu C, Florea A, Bogdan R. Monitoring and Predicting Air Quality with IoT Devices. Processes. 2024; 12(9):1961. https://doi.org/10.3390/pr12091961
Chicago/Turabian StyleBanciu, Claudia, Adrian Florea, and Razvan Bogdan. 2024. "Monitoring and Predicting Air Quality with IoT Devices" Processes 12, no. 9: 1961. https://doi.org/10.3390/pr12091961