
Integrated Data-Driven Framework for Forecasting Tight Gas Production Based on Machine Learning Algorithms, Feature Selection and Fracturing Optimization


 , ,
, ,
Abstract
:1. Introduction
- This framework introduces machine learning-based predictions for tight gas development and provides new insights into the key features that influence tight gas production. By integrating machine learning algorithms, feature selection, production prediction and fracturing parameter optimization, it can effectively develop tight gas resources.
- A distinctive aspect of the study is the in-depth comparison of feature-selection techniques. The framework combines six methods (i.e., XGBoost, RF, GBDT, ANN, LightGBM and ET) with six machine learning models to provide a comprehensive assessment and comparative understanding. The most effective machine learning algorithm, along with the most significant factors, is identified.
- The most important aspect of this research is the optimization of fracturing parameters based on the best-performing machine learning model. Operational plans are fine-tuned to maximize productivity by adjusting the fracturing fluid injection and proppant mass using the optimal algorithm.
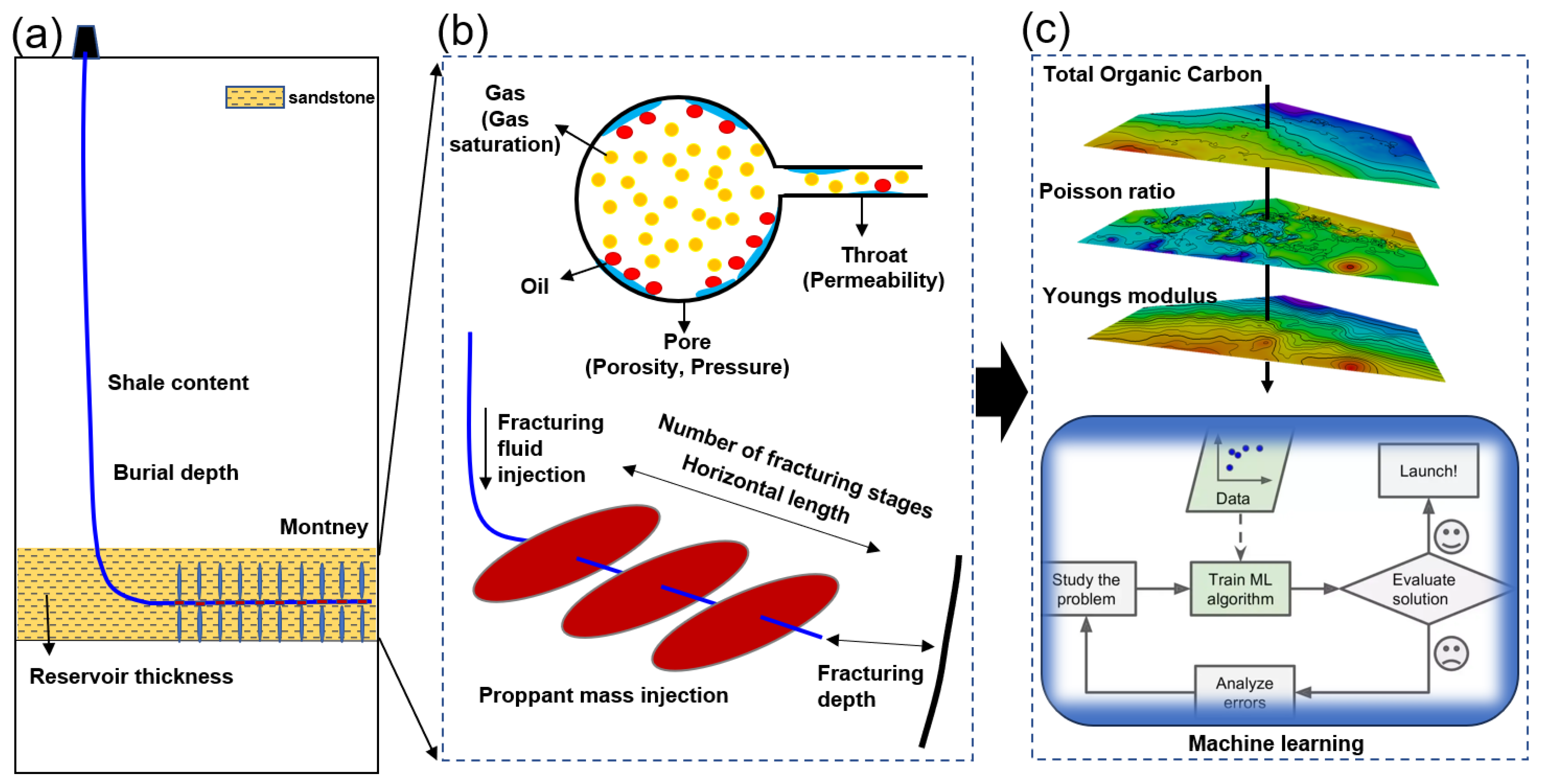
2. Field Background
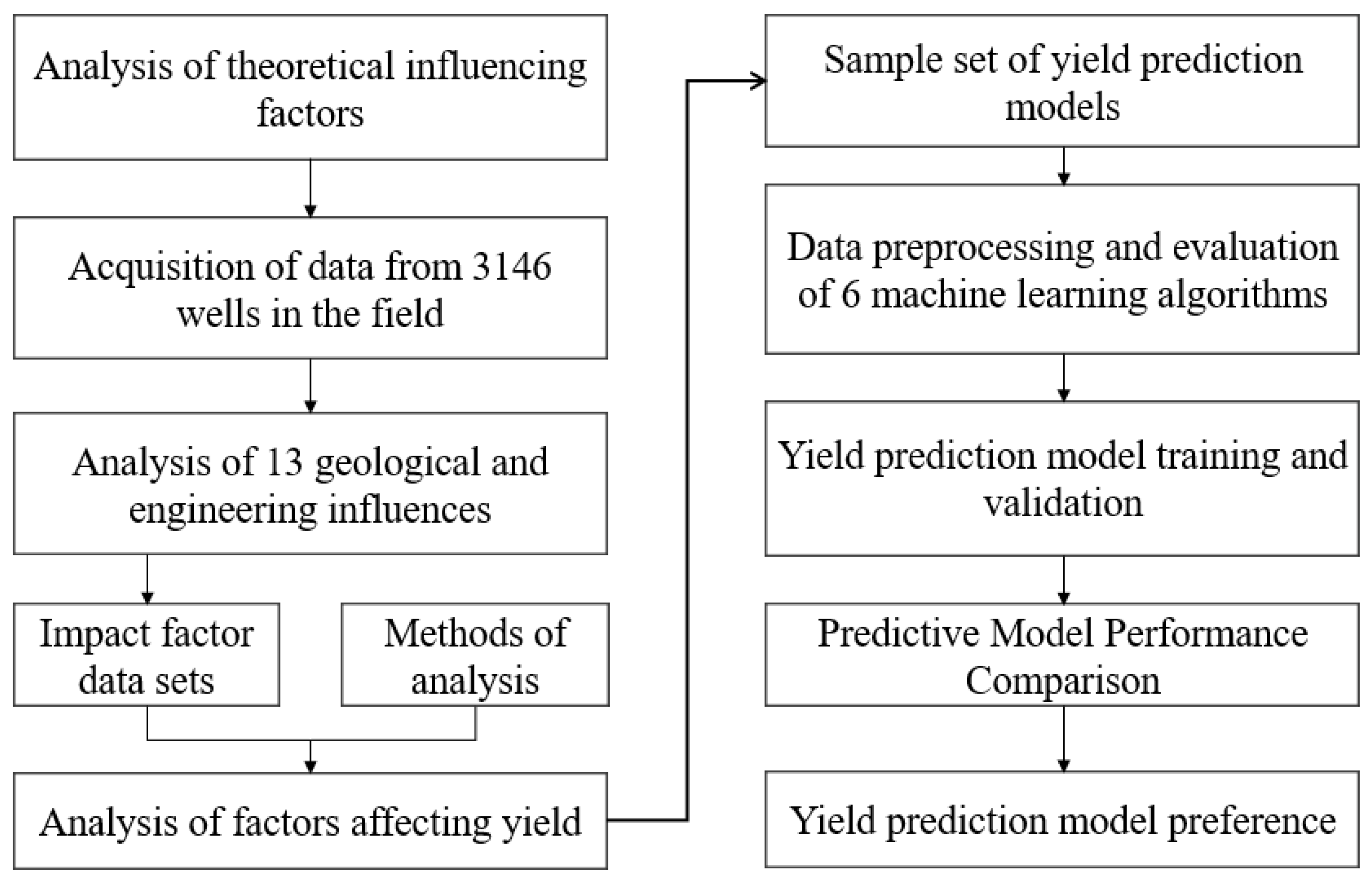
3. Methodology
3.1. Parameter Characterization and Selection
3.1.1. Parameter Characterization
- (1)
- Geological factors
- (2)
- Engineering factors
3.1.2. Parameter Correlation Analysis
- (1)
- Correlation analysis expressions
- (2)
- Classification of the degree of correlation
3.2. Machine Learning Methods
3.2.1. Data Preprocessing
- (1)
- Dataset division
- (2)
- Data normalization
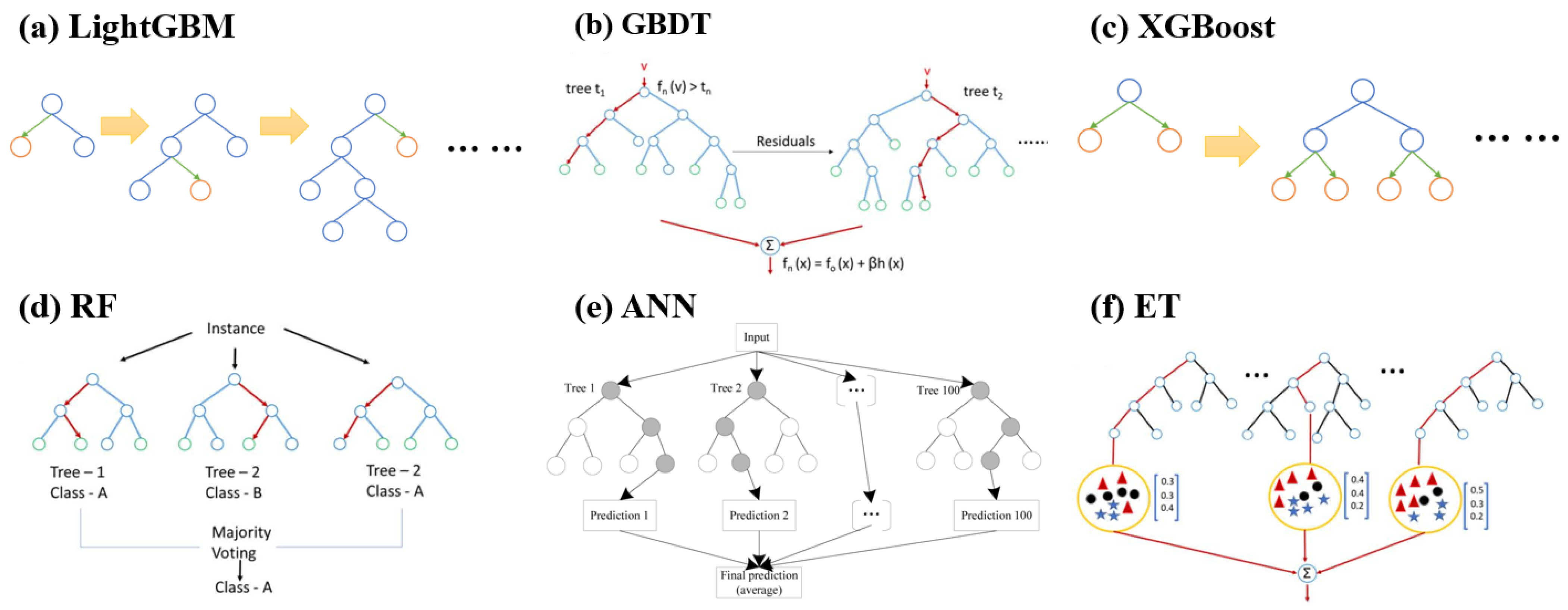
3.2.2. Machine Learning Algorithms
- (1)
- Extreme Gradient Boosting Tree (XGBoost)
- (2)
- Random Forest (RF)
- (3)
- Gradient Boosting Decision Tree (GBDT)
- (4)
- Artificial Neural Network (ANN)
- Input data: are the input data of the model, which can be formulated as .
- Connection weights: is the connection weights of the model, which is the parameter for linear mapping, where b is the bias. The connection weights can reflect the connection strength between neurons. A positive weight indicates that the neuron is stimulated, while a negative weight means it is inhibited. During the model training, the connection weights are updated according to the loss function and learning rate until the loss function converges and the model achieves better performance.
- Processing unit: This is used to calculate the weighted sum of each input signal.
- Activation function: The activation function plays the role of nonlinear mapping in neural networks, constraining the output value range to a reasonable interval. Sigmoid function, tanh function, ReLU function and Softmax function are several commonly used activation functions.
- Output: This is the final result obtained after the input data undergoes linear and nonlinear mapping computations.
- (5)
- Lightweight Gradient Boosting Tree (LightGBM)
- (6)
- Extreme Random Tree (ET)
3.2.3. Hyperparameter Tuning and Evaluation Criteria
- (1)
- Coefficient of determination (R2)
- (2)
- Mean Absolute Percentage Error (MAPE)
- (3)
- Mean Square Error (MSE)
4. Results and Discussion
4.1. Results of Parameter Characterization and Selection
4.1.1. Parameter-Characterization Results
4.1.2. Correlation Analysis Results
4.2. Machine Learning-Based Production Prediction
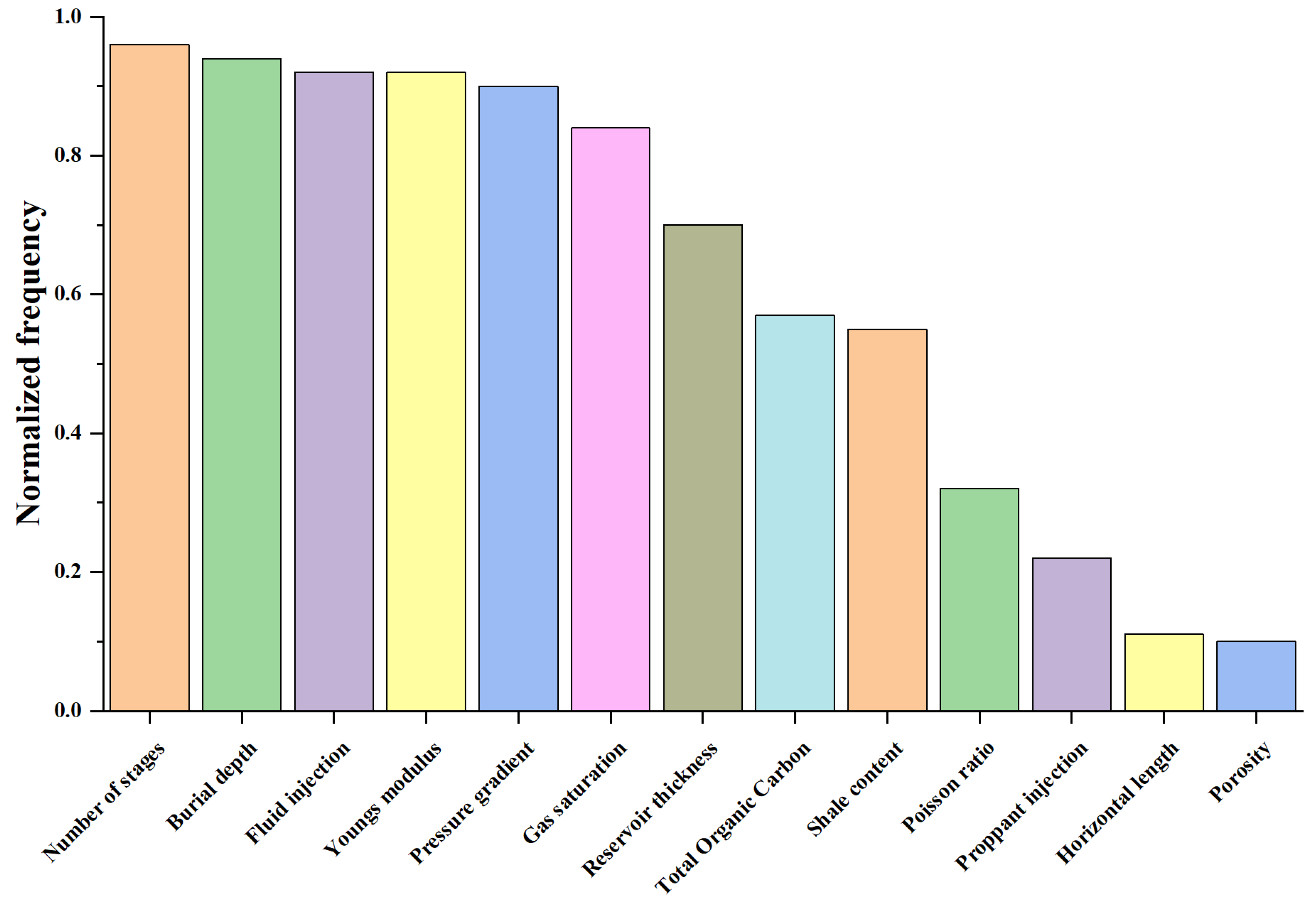
4.2.1. Feature Importance
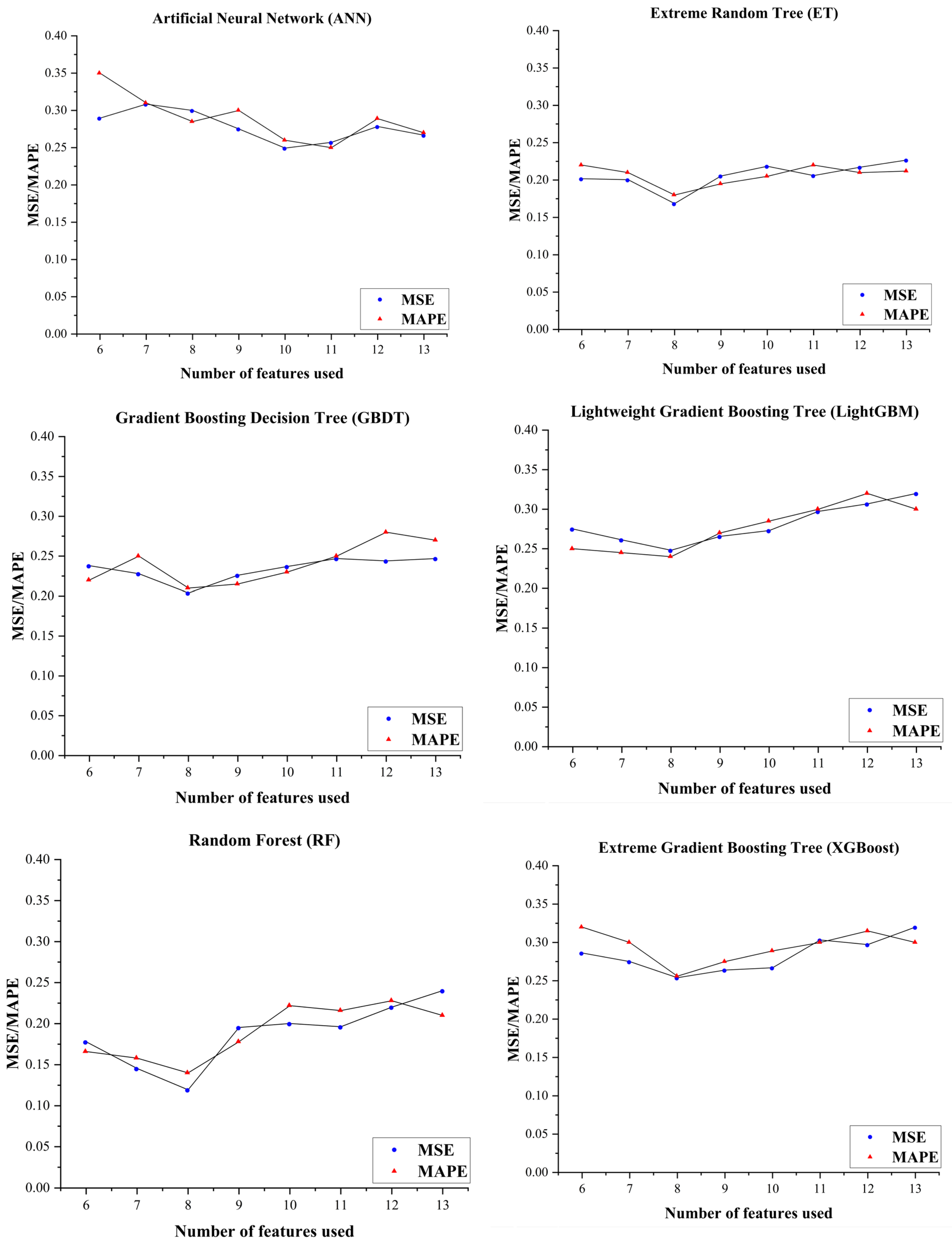
4.2.2. Comparison of Different Models
4.2.3. Prediction of Long-Term Production
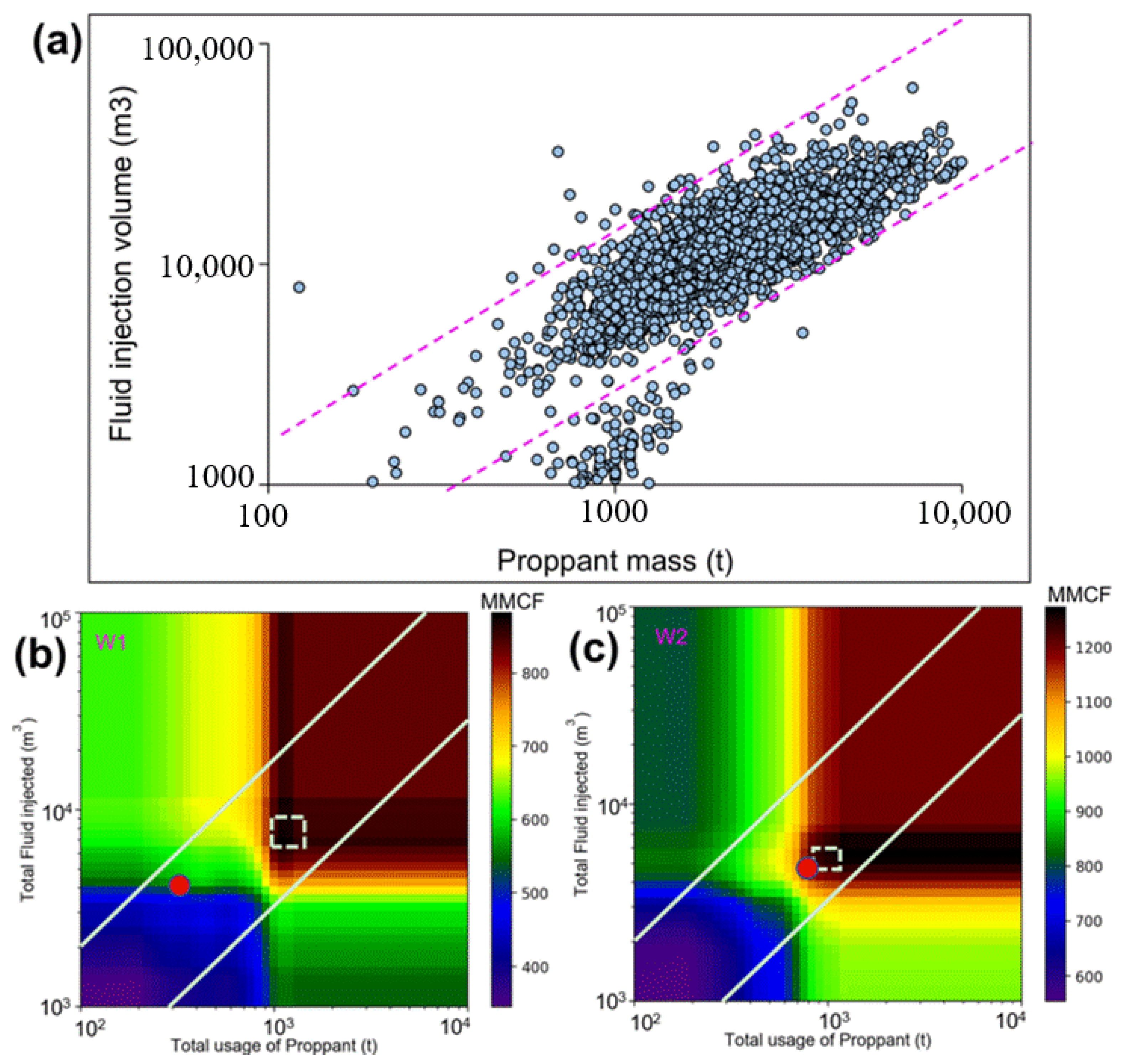
4.2.4. Optimization of Fracturing Parameters
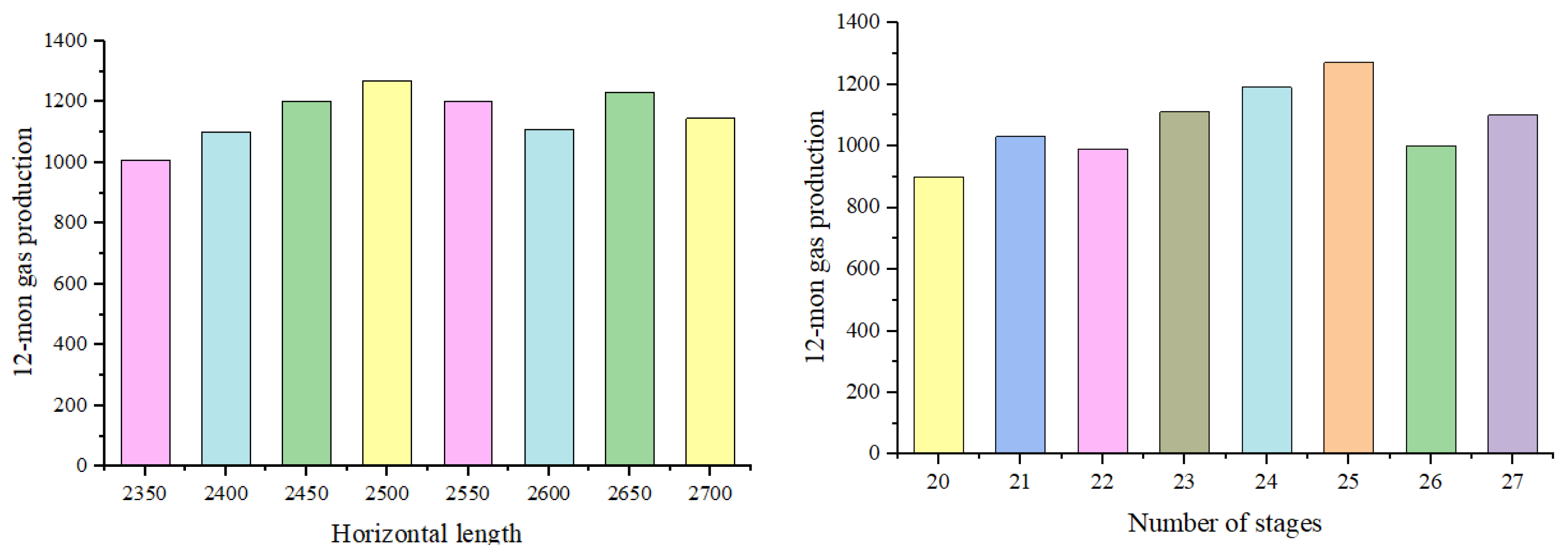
4.2.5. Sensitivity Analysis of Fracturing Parameters
5. Conclusions
- (1)
- The six machine learning algorithms selected eight parameters of the highest R2 values. These parameters include fracturing fluid injection, burial depth, number of fractured sections, Young’s modulus, formation pressure, saturation, sandstone thickness and total organic carbon (TOC) content and emerged as the key variables for tight gas production.
- (2)
- After evaluating six machine learning algorithms, the Random Forest method was found to have the largest coefficient of determination, with an R2 value of 0.886. A prediction model based on Random Forest was then developed to estimate tight gas productivity, which can be used to guide the well site selection for effective tight gas development.
- (3)
- A case study of test wells demonstrated that the model can be used for fracturing parameter sensitivity analysis. By analyzing the impact of single- or multi-factor variations on production, it enables the optimal design of single or multiple parameters. Ultimately, increasing the fracturing fluid injection by 97.5% can nearly double the natural gas production. This work has provided accurate, evidence-based suggestions for optimizing the development plan.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McGlade, C.; Speirs, J.; Sorrell, S. Unconventional Gas—A Review of Regional and Global Resource Estimates. Energy 2013, 55, 571–584. [Google Scholar] [CrossRef]
- Wang, H.; Ma, F.; Tong, X.; Liu, Z.; Zhang, X.; Wu, Z.; Li, D.; Wang, B.; Xie, Y.; Yang, L. Assessment of Global Unconventional Oil and Gas Resources. Pet. Explor. Dev. 2016, 43, 925–940. [Google Scholar] [CrossRef]
- Sun, L.; Zou, C.; Jia, A.; Wei, Y.; Zhu, R.; Wu, S.; Guo, Z. Development Characteristics and Orientation of Tight Oil and Gas in China. Pet. Explor. Dev. 2019, 46, 1073–1087. [Google Scholar] [CrossRef]
- Di, C.; Wei, Y.; Wang, K.; Deng, P.; Chen, B.; Shen, L.; Chen, Z. The Impact of Pressurization-Induced Decrease of Capillary Pressure and Residual Saturation on Geological Carbon Dioxide Storage. J. Clean. Prod. 2025, 486, 144573. [Google Scholar] [CrossRef]
- Hui, G.; Chen, S.; He, Y.; Wang, H.; Gu, F. Machine Learning-Based Production Forecast for Shale Gas in Unconventional Reservoirs via Integration of Geological and Operational Factors. J. Nat. Gas Sci. Eng. 2021, 94, 104045. [Google Scholar] [CrossRef]
- Chen, J.; Wang, L.; Wang, C.; Yao, B.; Tian, Y.; Wu, Y.S. Automatic Fracture Optimization for Shale Gas Reservoirs Based on Gradient Descent Method and Reservoir Simulation. Adv. Geo-Energy Res. 2021, 5, 191–201. [Google Scholar] [CrossRef]
- Hui, G.; Chen, Z.; Schultz, R.; Chen, S.; Song, Z.; Zhang, Z.; Song, Y.; Wang, H.; Wang, M.; Gu, F. Intricate Unconventional Fracture Networks Provide Fluid Diffusion Pathways to Reactivate Pre-Existing Faults in Unconventional Reservoirs. Energy 2023, 282, 128803. [Google Scholar] [CrossRef]
- Weng, X.; Kresse, O.; Chuprakov, D.; Cohen, C.E.; Prioul, R.; Ganguly, U. Applying Complex Fracture Model and Integrated Workflow in Unconventional Reservoirs. J. Pet. Sci. Eng. 2014, 124, 468–483. [Google Scholar] [CrossRef]
- Awoleke, O.; Lane, R. Analysis of Data from the Barnett Shale Using Conventional Statistical and Virtual Intelligence Techniques. SPE Reserv. Eval. Eng. 2011, 14, 544–556. [Google Scholar] [CrossRef]
- Wang, Y.-F.; Xu, S.; Hao, F.; Liu, H.-M.; Hu, Q.-H.; Xi, K.-L.; Yang, D. Machine Learning-Based Grayscale Analyses for Lithofacies Identification of the Shahejie Formation, Bohai Bay Basin, China. Pet. Sci. 2025, 22, 42–54. [Google Scholar] [CrossRef]
- Ozowe, W.; Daramola, G.O.; Ekemezie, I.O. Recent Advances and Challenges in Gas Injection Techniques for Enhanced Oil Recovery. Magna Sci. Adv. Res. Rev. 2023, 9, 168–178. [Google Scholar] [CrossRef]
- Hui, G.; Chen, Z.; Wang, Y.; Zhang, D.; Gu, F. An Integrated Machine Learning-Based Approach to Identifying Controlling Factors of Unconventional Shale Productivity. Energy 2023, 266, 126512. [Google Scholar] [CrossRef]
- Mohammed, A.I.; Bartlett, M.; Oyeneyin, B.; Kayvantash, K.; Njuguna, J. An Application of FEA and Machine Learning for the Prediction and Optimisation of Casing Buckling and Deformation Responses in Shale Gas Wells in an In-Situ Operation. J. Nat. Gas Sci. Eng. 2021, 95, 104221. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, C. An Integrated Mass Balance Approach for Assessing Hydrocarbon Resources in a Liquid-Rich Shale Resource Play: An Example from Upper Devonian Duvernay Formation, Western Canada Sedimentary Basin. J. Earth Sci. 2020, 31, 1259–1272. [Google Scholar] [CrossRef]
- Kalantari-Dahaghi, A.; Mohaghegh, S.; Esmaili, S. Coupling Numerical Simulation and Machine Learning to Model Shale Gas Production at Different Time Resolutions. J. Nat. Gas Sci. Eng. 2015, 25, 380–392. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Javadpour, F.; Sahimi, M. Data Mining and Machine Learning for Identifying Sweet Spots in Shale Reservoirs. Expert Syst. Appl. 2017, 88, 435–447. [Google Scholar] [CrossRef]
- Meng, J.; Zhou, Y.; Ye, T.; Xiao, Y.; Lu, Y.; Zheng, A.W.; Liang, B. Hybrid Data-Driven Framework for Shale Gas Production Performance Analysis via Game Theory, Machine Learning, and Optimization Approaches. Pet. Sci. 2023, 20, 277–294. [Google Scholar] [CrossRef]
- Saporetti, C.; Fonseca, D.; Oliveira, L.; Pereira, E.; Goliatt, L. Hybrid Machine Learning Models for Estimating Total Organic Carbon from Mineral Constituents in Core Samples of Shale Gas Fields. Mar. Pet. Geol. 2022, 143, 105783. [Google Scholar] [CrossRef]
- Vikara, D.; Remson, D.; Khanna, V. Machine Learning-Informed Ensemble Framework for Evaluating Shale Gas Production Potential: Case Study in the Marcellus Shale. J. Nat. Gas Sci. Eng. 2020, 84, 103679. [Google Scholar] [CrossRef]
- Mehana, M.; Guiltinan, E.; Vesselinov, V.; Middleton, R.; Hyman, J.D.; Kang, Q.; Viswanathan, H. Machine-Learning Predictions of the Shale Wells’ Performance. J. Nat. Gas Sci. Eng. 2021, 88, 103819. [Google Scholar] [CrossRef]
- Xiao, C.; Wang, G.; Zhang, Y.; Deng, Y. Machine-Learning-Based Well Production Prediction under Geological and Hydraulic Fracture Parameters Uncertainty for Unconventional Shale Gas Reservoirs. J. Nat. Gas Sci. Eng. 2022, 106, 104762. [Google Scholar] [CrossRef]
- Yi, J.; Qi, Z.; Li, X.; Liu, H.; Zhou, W. Spatial Correlation-Based Machine Learning Framework for Evaluating Shale Gas Production Potential: A Case Study in Southern Sichuan Basin, China. Appl. Energy 2024, 357, 122483. [Google Scholar] [CrossRef]
- Bachu, S.; Burwash, R.A. Regional-Scale Analysis of the Geothermal Regime in the Western Canada Sedimentary Basin. Geothermics 1991, 20, 387–407. [Google Scholar] [CrossRef]
- González, P.; Furlong, C.; Gingras, M.; Playter, T.; Zonneveld, J. Depositional Framework and Trace Fossil Assemblages of the Lower Triassic Montney Formation, Northeastern British Columbia, Western Canada Sedimentary Basin. Mar. Pet. Geol. 2022, 143, 105822. [Google Scholar] [CrossRef]
- Hui, G.; Chen, S.; Gu, F. Strike-Slip Fault Reactivation Triggered by Hydraulic-Natural Fracture Propagation during Fracturing Stimulations near Clark Lake, Alberta. Energy Fuels 2024, 38, 18547–18555. [Google Scholar] [CrossRef]
- Egbobawaye, E. Sedimentology and Ichnology of Upper Montney Formation Tight Gas Reservoir, Northeastern British Columbia, Western Canada Sedimentary Basin. IJG 2016, 07, 1357–1411. [Google Scholar] [CrossRef]
- Bao, P.; Hui, G.; Hu, Y.; Song, R.; Chen, Z.; Zhang, K.; Pi, Z.; Li, Y.; Ge, C.; Yao, F.; et al. Comprehensive Characterization of Hydraulic Fracture Propagations and Prevention of Pre-existing Fault Failure in Duvernay Shale Reservoirs. Eng. Fail. Anal. 2025, 173, 109461. [Google Scholar] [CrossRef]
- Hui, G.; Yao, F.; Pi, Z.; Bao, P.; Wang, W.; Wang, M.; Wang, H.; Gu, F. Tight Gas Production Prediction in the Southern Montney Play Using Machine Learning Approaches. In Proceedings of the SPE Canadian Energy Technology Conference and Exhibition, Calgary, AB, Canada, 13 March 2024; p. D011S009R001. [Google Scholar]
- Fang, M.; Shi, H.; Li, H.; Liu, T. Application of Machine Learning for Productivity Prediction in Tight Gas Reservoirs. Energies 2024, 17, 1916. [Google Scholar] [CrossRef]
- Mao, S.; Chen, B.; Malki, M.; Chen, F.; Morales, M.; Ma, Z.; Mehana, M. Efficient Prediction of Hydrogen Storage Performance in Depleted Gas Reservoirs Using Machine Learning. Appl. Energy 2024, 361, 122914. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hui, G.; Chen, Z.; Wang, H.; Song, Z.; Wang, S.; Zhang, H.; Zhang, D.M.; Gu, F. A Machine Learning-Based Study of Multifactor Susceptibility and Risk Control of Induced Seismicity in Unconventional Reservoirs. Pet. Sci. 2023, 20, 2232–2243. [Google Scholar] [CrossRef]
- Deng, Y.; Wang, W.; Su, Y.; Sun, S.; Zhuang, X. An Unsupervised Machine Learning Based Double Sweet Spots Classification and Evaluation Method for Tight Reservoirs. J. Energy Res. Technol. 2023, 145, 072602. [Google Scholar] [CrossRef]
- Pawley, S.; Schultz, R.; Playter, T.; Corlett, H.; Shipman, T.; Lyster, S.; Hauck, T. The Geological Susceptibility of Induced Earthquakes in the Duvernay Play. Geophys. Res. Lett. 2018, 45, 1786–1793. [Google Scholar] [CrossRef]
- Brantson, E.T.; Ju, B.; Omisore, B.O.; Wu, D.; Selase, A.E.; Liu, N. Development of Machine Learning Predictive Models for History Matching Tight Gas Carbonate Reservoir Production Profiles. J. Geophys. Eng. 2018, 15, 2235–2251. [Google Scholar] [CrossRef]
- Zou, C.; Yang, Z.; He, D.; Wei, Y.; Li, J.; Jia, A.; Chen, J.; Zhao, Q.; Li, Y.; Li, J.; et al. Theory, Technology and Prospects of Conventional and Unconventional Natural Gas. Pet. Explor. Dev. 2018, 45, 604–618. [Google Scholar] [CrossRef]
- Song, N.; Li, S.; Zeng, B.; Duan, R.; Yang, Y. A Novel Grey Prediction Model with Four-Parameter and Its Application to Forecast Natural Gas Production in China. Eng. Appl. Artif. Intell. 2024, 133, 108431. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, J.; Zhang, J.; Meng, S.; Li, J. Modeling of Scale-Dependent Perforation Geometrical Fracture Growth in Naturally Layered Media. Eng. Geol. 2024, 336, 107499. [Google Scholar] [CrossRef]
- Song, R.; Liu, J.; Yang, C.; Sun, S. Study on the Multiphase Heat and Mass Transfer Mechanism in the Dissociation of Methane Hydrate in Reconstructed Real-Shape Porous Sediments. Energy 2022, 254, 124421. [Google Scholar] [CrossRef]
- Su, X.; Zhou, D.; Wang, H.; Xu, J. Research on the Scaling Mechanism and Countermeasures of Tight Sandstone Gas Reservoirs Based on Machine Learning. Processes 2024, 12, 527. [Google Scholar] [CrossRef]
- Hui, G.; Chen, Z.; Chen, S.; Gu, F. Hydraulic Fracturing-Induced Seismicity Characterization through Coupled Modeling of Stress and Fracture-Fault Systems. Adv. Geo-Energy Res. 2022, 6, 269–270. [Google Scholar] [CrossRef]
- Cao, L.; Jiang, F.; Chen, Z.; Gao, Y.; Huo, L.; Chen, D. Data-Driven Interpretable Machine Learning for Prediction of Porosity and Permeability of Tight Sandstone Reservoir. Adv. Geo-Energy Res. 2025, 16, 21–35. [Google Scholar] [CrossRef]
- Xie, C.; Du, S.; Wang, J.; Lao, J.; Song, H. Intelligent Modeling with Physics-Informed Machine Learning for Petroleum Engineering Problems. Adv. Geo-Energy Res. 2023, 8, 71–75. [Google Scholar] [CrossRef]
- Omidkar, A.; Alagumalai, A.; Li, Z.; Song, H. Machine Learning Assisted Techno-Economic and Life Cycle Assessment of Organic Solid Waste Upgrading under Natural Gas. Appl. Energy 2024, 355, 122321. [Google Scholar] [CrossRef]
- Wang, S.; Chen, S. Insights to Fracture Stimulation Design in Unconventional Reservoirs Based on Machine Learning Modeling. J. Pet. Sci. Eng. 2019, 174, 682–695. [Google Scholar] [CrossRef]
- Naghizadeh, A.; Jafari, S.; Norouzi-Apourvari, S.; Schaffie, M.; Hemmati-Sarapardeh, A. Multi-Objective Optimization of Water-Alternating Flue Gas Process Using Machine Learning and Nature-Inspired Algorithms in a Real Geological Field. Energy 2024, 293, 130413. [Google Scholar] [CrossRef]
- Liu, L.; Kang, W.; Wang, Y.; Zeng, L. Design of Tool Wear Monitoring System in Bone Material Drilling Process. Coatings 2024, 14, 812. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.; Tuleau-Malot, C.; Villa-Vialaneix, N. Random Forests for Big Data. Big Data Res. 2017, 9, 28–46. [Google Scholar] [CrossRef]
- Bakouregui, A.; Mohamed, H.; Yahia, A.; Benmokrane, B. Explainable Extreme Gradient Boosting Tree-Based Prediction of Load-Carrying Capacity of FRP-RC Columns. Eng. Struct. 2021, 245, 112836. [Google Scholar] [CrossRef]
- Lawal, A.; Yang, Y.; He, H.; Baisa, N.L. Machine Learning in Oil and Gas Exploration: A Review. IEEE Access 2024, 12, 19035–19058. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, Z.; Xie, J.; Meng, S.; Xu, J.; Ehlig-Economides, C.; Liu, H. Re-Evaluation of CO2 Storage Capacity of Depleted Fractured-Vuggy Carbonate Reservoir. Innov. Energy 2024, 1, 100019-1–100019-11. [Google Scholar] [CrossRef]
- Wang, Z.-Y.; Lu, S.-F.; Zhou, N.-W.; Liu, Y.-C.; Lin, L.-M.; Shang, Y.-X.; Wang, J.; Xiao, G.-S. Complementary Testing and Machine Learning Techniques for the Characterization and Prediction of Middle Permian Tight Gas Sandstone Reservoir Quality in the Northeastern Ordos Basin, China. Pet. Sci. 2024, 21, 2946–2968. [Google Scholar] [CrossRef]
- Hu, X.; Meng, Q.; Guo, F.; Xie, J.; Hasi, E.; Wang, H.; Zhao, Y.; Wang, L.; Li, P.; Zhu, L.; et al. Deep Learning Algorithm-Enabled Sediment Characterization Techniques to Determination of Water Saturation for Tight Gas Carbonate Reservoirs in Bohai Bay Basin, China. Sci. Rep. 2024, 14, 12179. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Li, C. Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs. Processes 2023, 11, 3159. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, X.; Chen, W.; Liu, M.; Yao, Y.; Wang, H.; Zhang, H.; Yao, G. Quantitative Classification and Prediction of Diagenetic Facies in Tight Gas Sandstone Reservoirs via Unsupervised and Supervised Machine Learning Models: Ledong Area, Yinggehai Basin. Nat. Resour. Res. 2023, 32, 2685–2710. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typology | Influencing Factors | Data Sources | Representative Wells |
|---|---|---|---|
| Geological factors | Preservation conditions (burial depth, pressure and thickness) | Well-logging, well-completion and monitoring data | 15-16-78-18 |
| Sandstone porosity and gas saturation Shale content, total organic carbon Poisson ratio, Young’s modulus | Core analysis | 6-26-78-18 | |
| Engineering factors | Cumulative fluid injection, cumulative proppant injection | Fracturing construction information | 6-10-79-15 |
| Number of stages, horizontal length | Fracturing construction information | 15-2-80-16 |
| Pearson Correlation Coefficient | Level of Relevance |
|---|---|
| 0.00 << 0.20 | Extremely weak correlation |
| 0.21 << 0.40 | Weak correlation |
| 0.41 < < 0.60 | Moderately relevant |
| 0.61 << 0.80 | Strong correlation |
| 0.81 << 1.00 | Extremely Relevant |
| Type | Parameters | Unit | Minimum | Maximum | Average |
|---|---|---|---|---|---|
| Output variable | 6-month gas production | MMCF | 1.2 | 4847.1 | 629.3 |
| 12-month gas production | MMCF | 1.5 | 6765.2 | 1201.9 | |
| 18-month gas production | MMCF | 2.4 | 9403.8 | 1609.2 | |
| Input geological parameters | Formation pressure gradient | MPa/km | 10.3 | 14.7 | 12.5 |
| Reservoir thickness | m | 119.6 | 263.6 | 191.6 | |
| Burial depth | m | 1700.9 | 2874.9 | 2287.9 | |
| Porosity | 0.04 | 0.26 | 0.15 | ||
| Gas saturation | % | 15.9 | 95.3 | 57.6 | |
| Shale content | 0.41 | 0.66 | 0.54 | ||
| Total organic carbon | 0.46 | 0.89 | 0.68 | ||
| Poisson ratio | 0.21 | 0.25 | 0.23 | ||
| Youngs modulus | GPa | 38.58 | 58.75 | 48.57 | |
| Input operational parameters | Horizontal length | m | 179.0 | 4636.5 | 2407.8 |
| Number of stages | 4 | 88 | 44.5 | ||
| Cumulative fluid injection | m3 | 17.3 | 43,307.6 | 12,407 | |
| Cumulative proppant injection | t | 25.6 | 14,133.2 | 2367 |
| Well | Original Parameters | Optimal Parameters | Parameter Comparison | |||||
|---|---|---|---|---|---|---|---|---|
| 12 Mo Prod (MMCF) | Fluid Volume (m3) | Proppant Mass (t) | 12 Mo Prod (MMCF) | Fluid Volume (m3) | Proppant Mass (t) | Fluid Increment (%) | Proppant Increment (%) | |
| W1 | 480 | 4000 | 320 | 890 | 7900 | 1100 | 97.5 | 243.8 |
| W2 | 1150 | 4700 | 800 | 1270 | 5300 | 1000 | 12.8 | 25.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, F.; Hui, G.; Meng, D.; Ge, C.; Zhang, K.; Ren, Y.; Li, Y.; Zhang, Y.; Yang, X.; Zhang, Y.; et al. Integrated Data-Driven Framework for Forecasting Tight Gas Production Based on Machine Learning Algorithms, Feature Selection and Fracturing Optimization. Processes 2025, 13, 1162. https://doi.org/10.3390/pr13041162
Yao F, Hui G, Meng D, Ge C, Zhang K, Ren Y, Li Y, Zhang Y, Yang X, Zhang Y, et al. Integrated Data-Driven Framework for Forecasting Tight Gas Production Based on Machine Learning Algorithms, Feature Selection and Fracturing Optimization. Processes. 2025; 13(4):1162. https://doi.org/10.3390/pr13041162
Chicago/Turabian StyleYao, Fuyu, Gang Hui, Dewei Meng, Chenqi Ge, Ke Zhang, Yili Ren, Ye Li, Yujie Zhang, Xing Yang, Yujie Zhang, and et al. 2025. "Integrated Data-Driven Framework for Forecasting Tight Gas Production Based on Machine Learning Algorithms, Feature Selection and Fracturing Optimization" Processes 13, no. 4: 1162. https://doi.org/10.3390/pr13041162
APA StyleYao, F., Hui, G., Meng, D., Ge, C., Zhang, K., Ren, Y., Li, Y., Zhang, Y., Yang, X., Zhang, Y., Bao, P., Pi, Z., Wu, D., & Gu, F. (2025). Integrated Data-Driven Framework for Forecasting Tight Gas Production Based on Machine Learning Algorithms, Feature Selection and Fracturing Optimization. Processes, 13(4), 1162. https://doi.org/10.3390/pr13041162