1. Introduction
Energy optimization has become a critical issue in reducing CO
2 emissions. By the end of 2017 non-renewable electricity generation still accounted for around 73.5%, despite significant investment in the renewable energy sector; the investment in the renewable energy amounted to
$274 billion and 279.8 billion USD in 2016 and 2017, respectively [
1]. Compared to renewable hydro power capacity of around 1114 GW, solar and wind power generation still take small portions of 1.9% and 5.6%, respectively [
1]. In view of the current low energy provision from renewable sources, other methods of saving natural resources—including better management of electricity energy consumption (whether renewable or non-renewable)—are as important as improving and increasing the renewable supply. With growing urbanization, building energy consumption has also increased gradually. Electricity consumption in buildings has been predicted to drastically increase to 35% of total energy consumption by 2020 in China [
2].
Most building electricity consumptions have been controlled in consideration of the surrounding local environmental factors such as working day, temperature, or humidity. Additionally, improving electricity consumption efficiency remains challenging from a micro-grid electricity management viewpoint. Hence, the study of building electricity energy prediction has become an important area of study, not only for efficient building energy control but also regarding smart city organization. There have been a lot of researches dedicated to the energy optimization, prediction, and decision-making methodologies for the building blocks [
3,
4,
5,
6,
7,
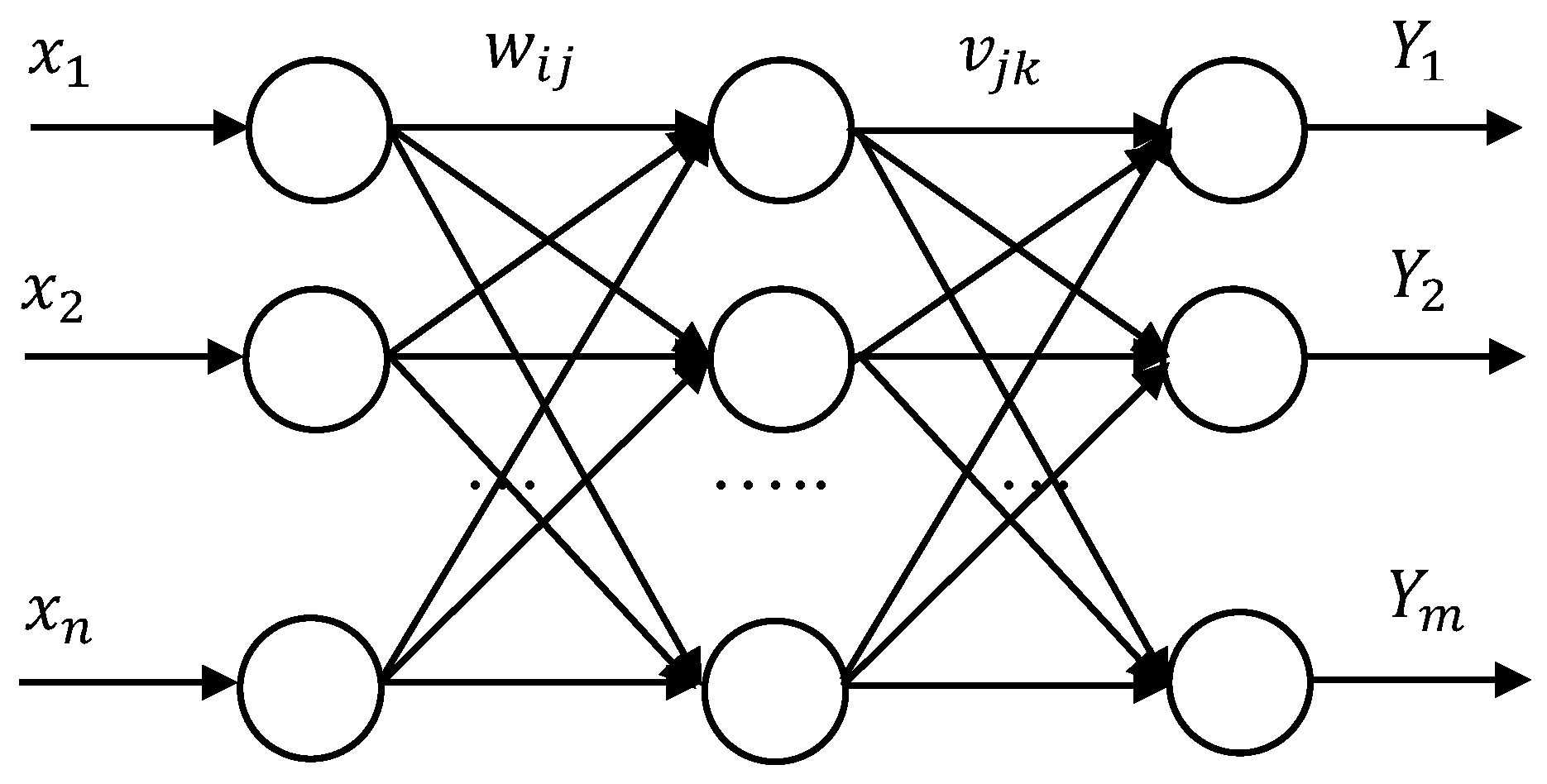
8]. Because of the large and complex building structures, modelling based on neural networks (NN) has recently been used to analyze the electricity consumption in buildings [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Note that the low efficiency, slow convergence, fluctuations, and oscillation during the training process of NN-based modeling were overcome by the Levenberg–Marquardt Back Propagation (LM-BP) algorithm by Ye and Kim [
14].
System performance is related to sensitivity, having a complementary characteristic [
16]. NN sensitivity analysis (SA) is closely related to weights between NN nodes and has been extensively investigated [
17,
18,
19,
20]. As discussed in [
21,
22], sensitivity analyses of NNs can be categorized into two approaches, i.e., the analytic approach defined by the partial derivative of the output with respect to the input variation [
17,
18] and the statistical approach proposed by Choi et. al [
19]. The two approaches have common difficulties in measuring expected output error with respect to overall input variations [
20]. Hence, Zeng and Yeung proposed a SA method by combining two approaches and derived an output variance equation based on the perturbation of inputs and weights. They also emphasized that the result aided in the selection of more weight sets with a low sensitivity level during training [
20].
In previous research [
23,
24], the mean impact value (MIV) was used to predict building electricity consumption and improve the prediction accuracy of building energy consumption, where we proposed a simplified neural network and verified its effectiveness. During the investigation, we applied several neural network algorithms, and compared their sensitivities. Finally, a neural network algorithm with a data-driven approach was selected and the result was well suited to building energy consumption prediction based on how each environmental element influences the electricity consumption in a building [
24]. It is recognized that understanding the sensitivity of building energy consumption models is important because the sensitivity is also closely related to the performance and robustness of the system [
16,
17,
18,
19]. In this research, we investigate how different environmental elements—such as temperature, humidity, working day, wind speed, and weather characteristics—influence actual electricity energy consumption in buildings using generated training data.
As previously mentioned, NN SA has been carried out by analyzing output variance with respect to the variation of inputs and connected weights [
21,
22]. Besides analytical SA, MIV is also applied to analyze the effect on the output by the variation of input variables [
23,
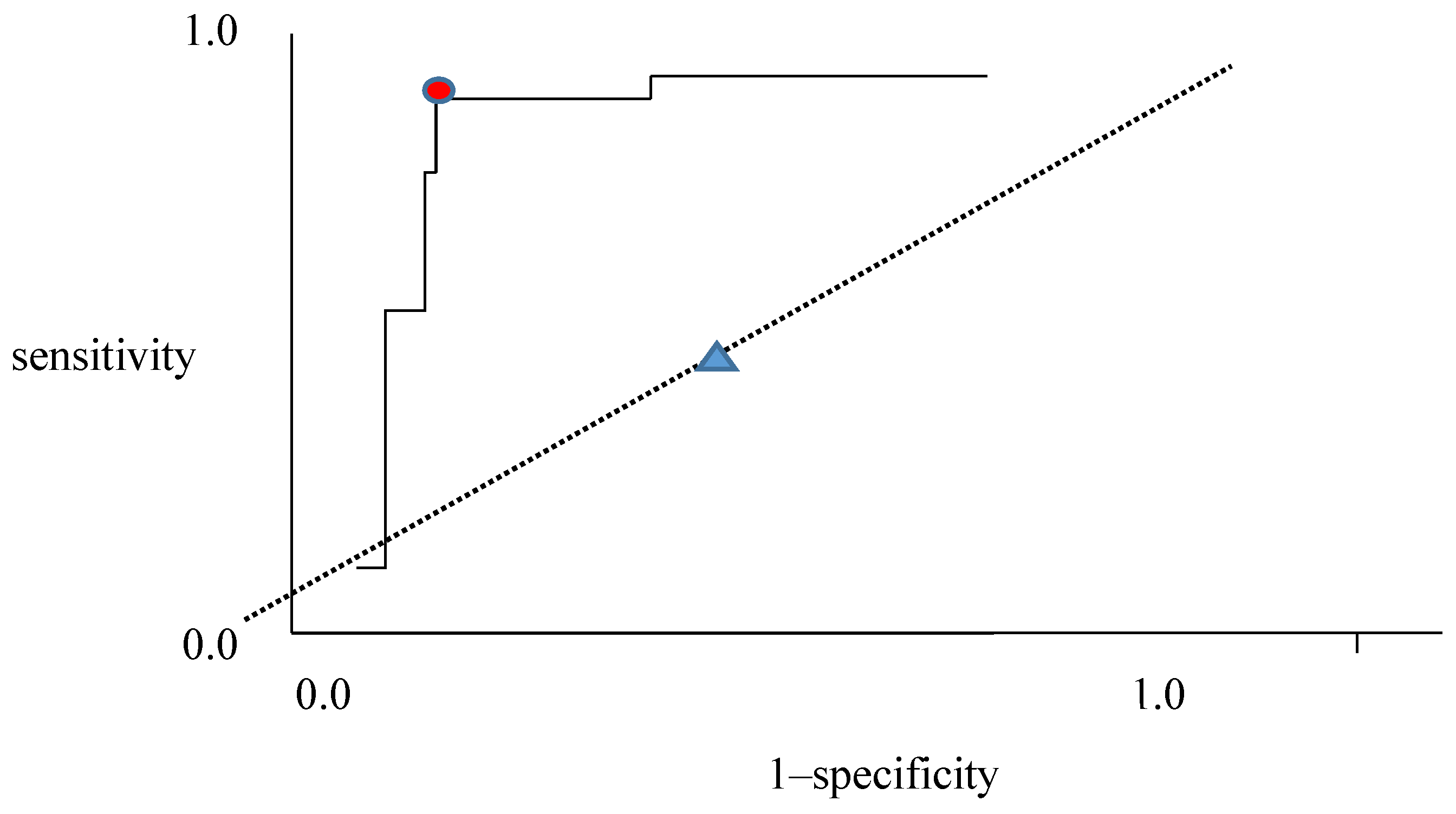
24]. Due to the NN structure, which can be considered as a black box, we measure the output variation under perturbation in the input data set. Most research considers the importance of reliable data to guarantee system performance. When we are faced with a shortage of training data, reliable training data needs to be generated based on a rational methodology. Hence, here we attempt to generate effective training data based on the receiver operating characteristic (ROC) plot where there are not available sufficient training data [
25,
26]. ROC plots have been used for the purposes of signal or trial classification based on the statistical decision theory [
25]. Decisiveness is its threshold level in assigning true or false in a test. If the level is a precise value, its sensitivity is very high and conversely, 1–specificity is quite low. As a result, it provides the optimum tradeoff between false positives and false negatives [
26].
In the paper, we use actual electricity consumption data from a shopping mall in Dalian, China, to predict energy consumption [
27]. However, we face the issue of data insufficiency in applying NN prediction models; this could be an issue, too, when we use few reliable data from the plenty of available data [
24]. In order to overcome the issue of insufficient training data, therefore, we systematically generate more training data based on the ROC plot. Firstly, electricity consumption data of a shopping mall in Dalian, China, for 2 months are reordered, i.e., consumption ranged from 17,385 kWh to 7711 kWh, from 1 March to 29 April 2014 [
27]. With the help of the ROC plot, input values of temperature, humidity, working day, weather characteristics and electricity consumption are generated considering the quality of data: By choosing the maximal input and output, we generate data in a more conservative way, while the minimal values of input and output lead to more flexible data generation. Training data generation processes are described in more detail in
Section 3.3.
Next, we constitute a new training set from the original and generated data set and apply test data to verify the performance of the proposed NN in this paper, which is compared with that of the simplified NN from [
24]. Results show how the reliability of data affects the output performance. LM-BP is used despite the availability of insufficient real data, which would typically result in overfitting, since we are able to generate additional training data as described.
The rest of the paper is organized as follows: In
Section 2, SA and least square (LS) are introduced. In
Section 3, the use of ROC plot for the data classification is introduced, and the reliable data generation procedures based on the ROC plot are described. In
Section 4, a comparative analysis of the performance of the proposed NN trained with training data derived from the ROC with that of the simplified NN in [
24] is carried out based on simulation experiments. And the analysis for each of the data generation methods is discussed. Finally,
Section 5 concludes our work in this paper and provides directions for future research.
5. Conclusions
A study on the prediction of energy consumption in the building environment has been carried out in this paper. The design of a building model is important to the prediction of the energy consumption and operation scheduling. In NN modelling, the preparation/generation of input training data is the key to its performance and reliability. In our previous work, we used the MIV to screen out insignificant input variables based on the sensitivity analysis and demonstrated its effectiveness [
24]. One major issue in the use of MIV, however, is that, because insignificant variables are completely removed during the training data generation and thereby simplified/reduced the structure of NN, all the available information from the original data cannot be fully taken into account in constructing NN.
In order to overcome the issue of data insufficiency in the MIV method, therefore, we generate the training data based on the ROC plot and the statistics of the original data in this work, where boundaries for the selection of input data are decided based on several methods, including successive or combination for two or three data are considered to choose input data. Minimum electric consumption guarantees conservative viewpoint, whereas maximum consumption allows progressive one. We use LM-BP NN structure, which has an advantage in smaller training data. After training data generation, test results are compared with those based on the original (without generation) data.
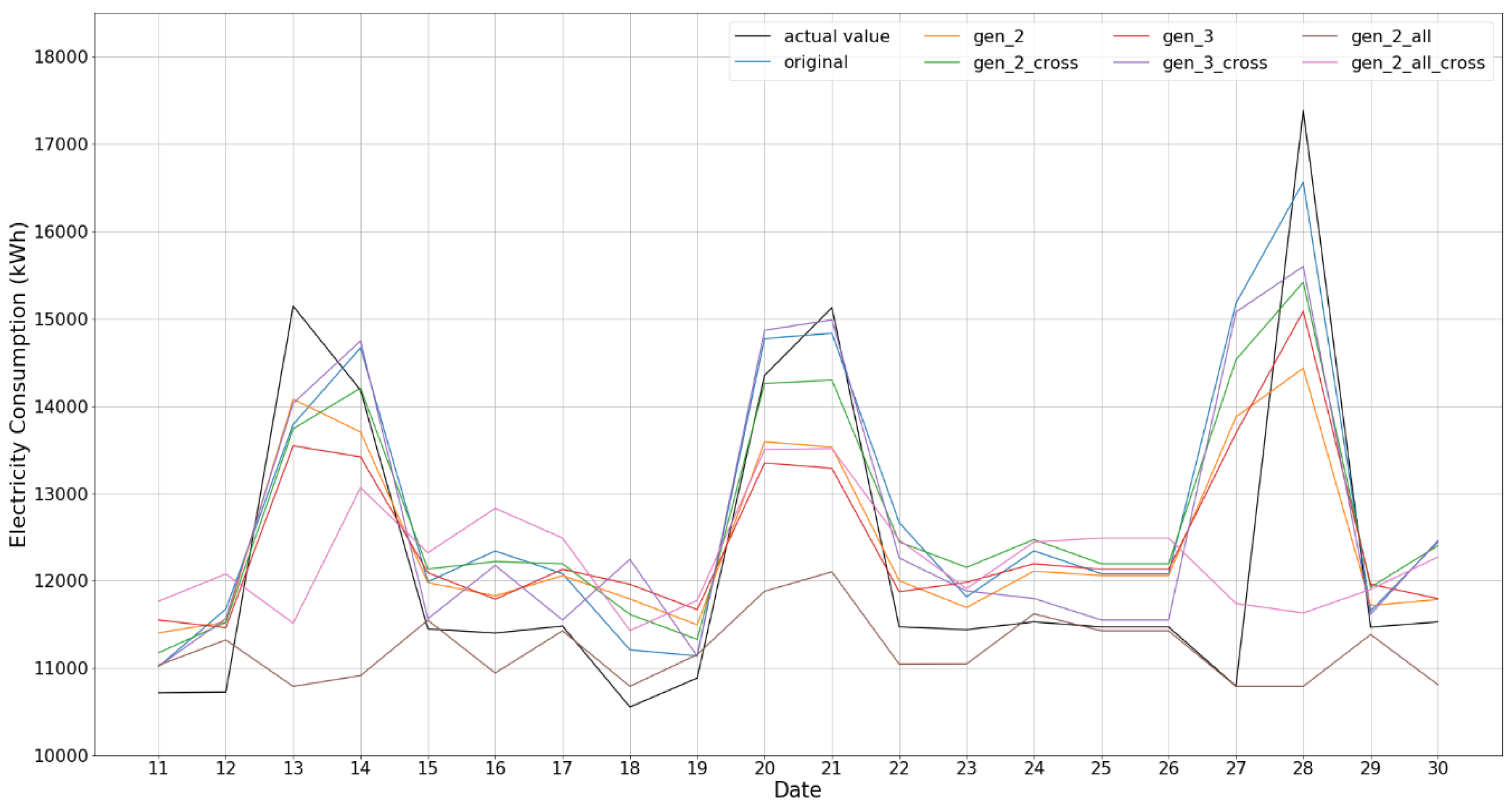
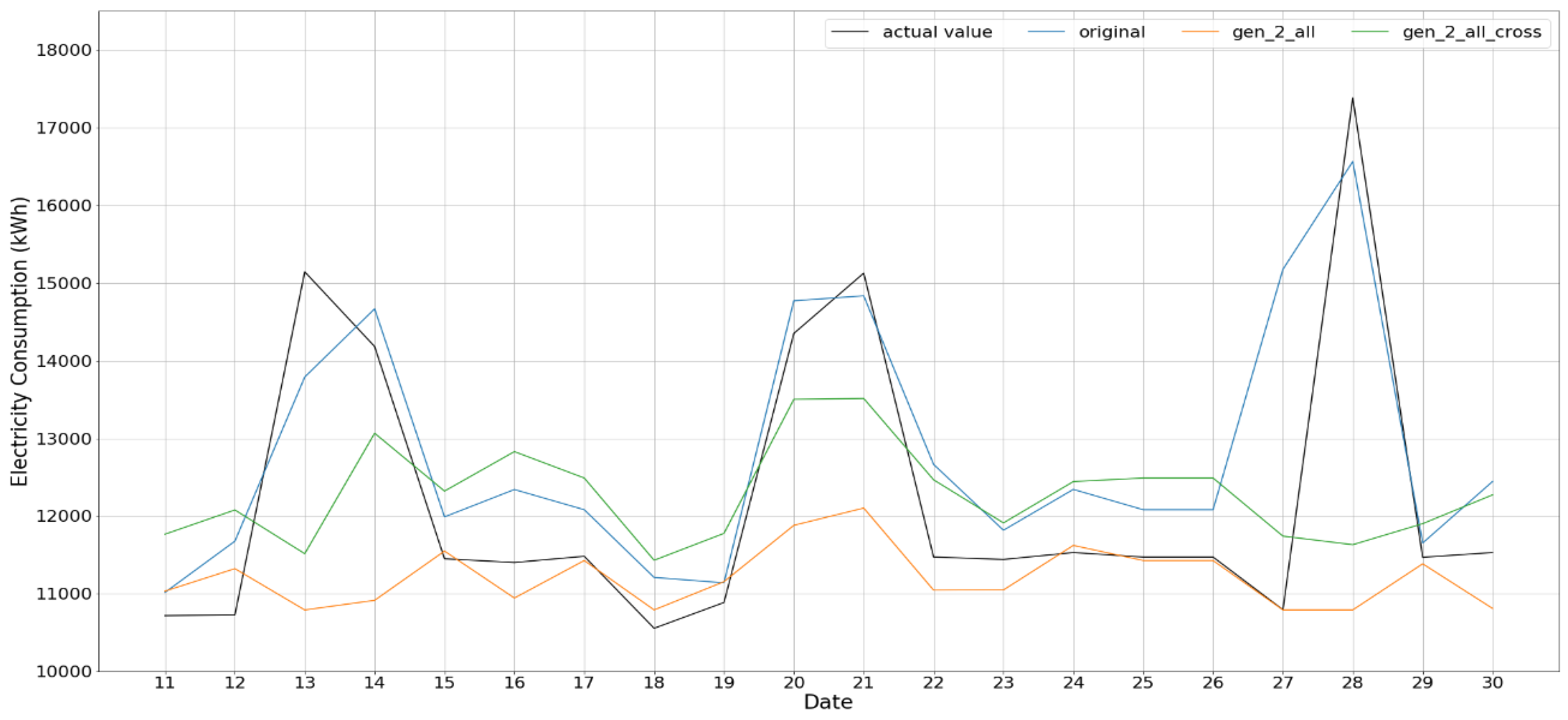
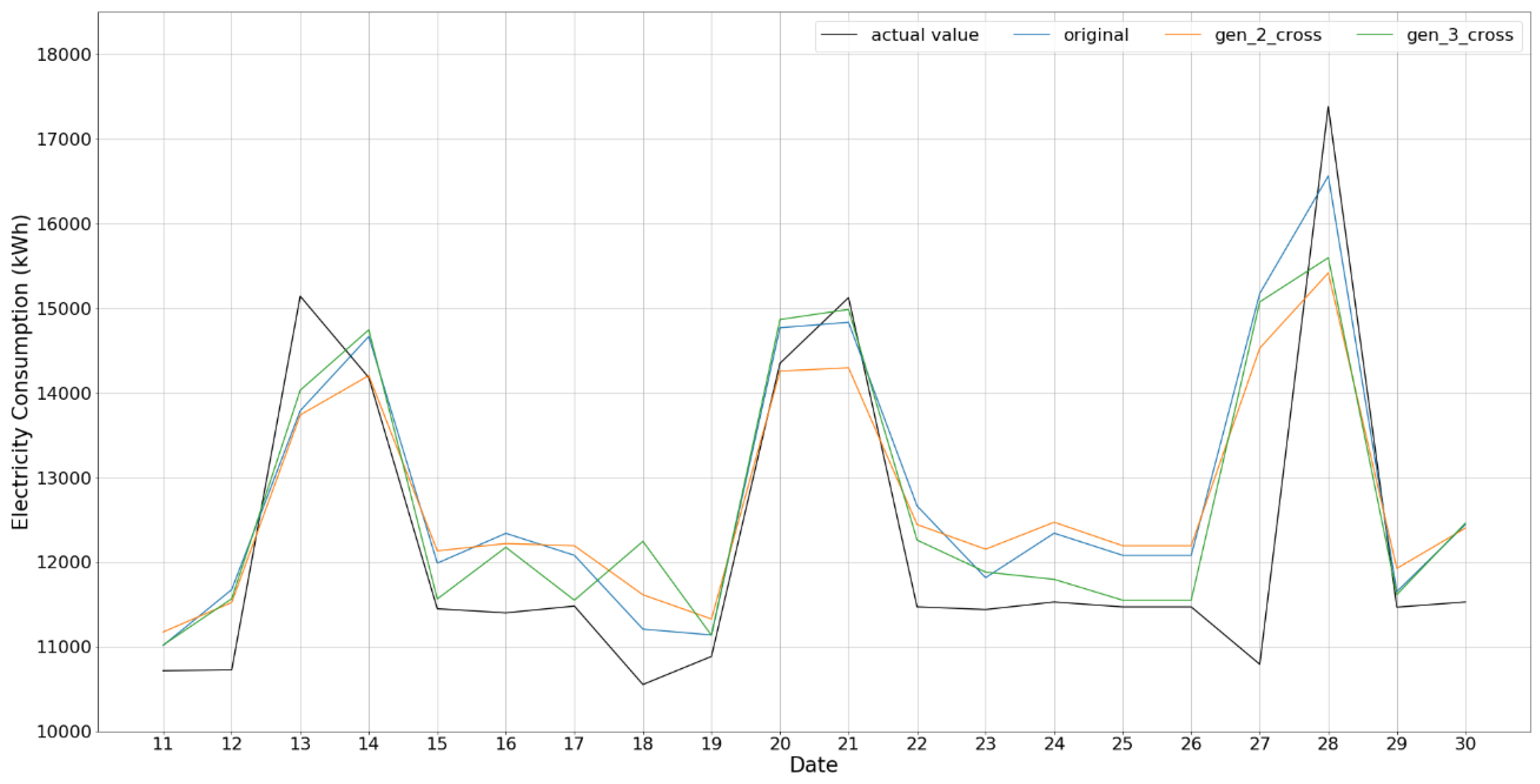
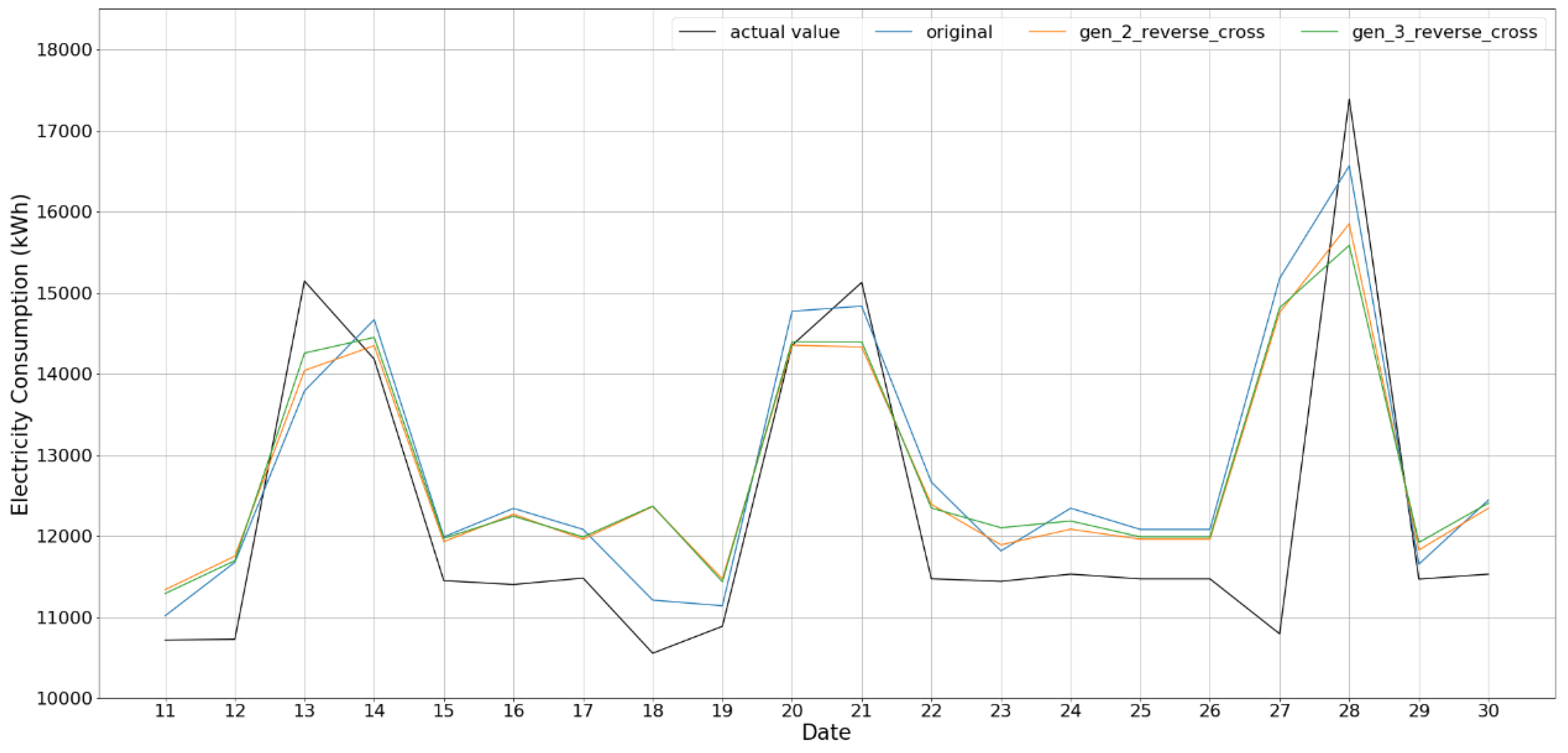
The experimental results demonstrate that data generation with ROC is more reliable and can overcome the data insufficiency issue of the MIV method, which results in a more efficient and reliable NN model for the prediction of building energy consumption. Specifically, the results with successive data show rather relevant output together with training results. However, two or three data combination case does not follow the consumption phase, that is, a rather conservative prediction; specifically, the results for Gen_2_all and Gen_2_all_cross show a difference of 390~950 kWh and 600~900 kWh for training and test with respect to the reference case of the original data, respectively.
Note that the results from this work can be extend and applied to other research areas, including the construction of NN models with insufficient data set.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





