ELM-Based AFL–SLFN Modeling and Multiscale Model-Modification Strategy for Online Prediction

Abstract
:1. Introduction
- (1)
- This paper combines ELM and AFL–SLFN. This allows the activation function of ELM to change adaptively. It is convenient for pruning to obtain a simpler network structure. In general, a single model does not perform well. Then, a hybrid model with adaptive weights is established by using the AFL–SLFN as a sub-model, which improves the prediction accuracy.
- (2)
- To track the process dynamics and maintain the generalization ability of the model, a multiscale model-modification strategy is proposed. That is, small-, medium-, and large-scale modification is performed in accordance with the degree and the causes of the decrease in model accuracy. In the small-scale modification, the just-in-time learning model can quickly reflect the change of working conditions. In order to improve the prediction accuracy of the just-in-time learning model, the spatial distance and cosine value between the input sample point and the historical sample point are fully considered to calculate their similarity and to improve the quality of the just-in-time dataset. In the medium-scale modification, the Morris method is improved by redefining the elementary effect (EE)-based Morris, where the model input parameters are mapped to a new interval and, therefore, its scope of application is expanded. Simulation results obtained using industrial data from a flotation process are presented and analyzed.
2. ELM and AFL–SLFN-Based Adaptive Hybrid Modeling Methodology
2.1. ELM-Based AFL–SLFN
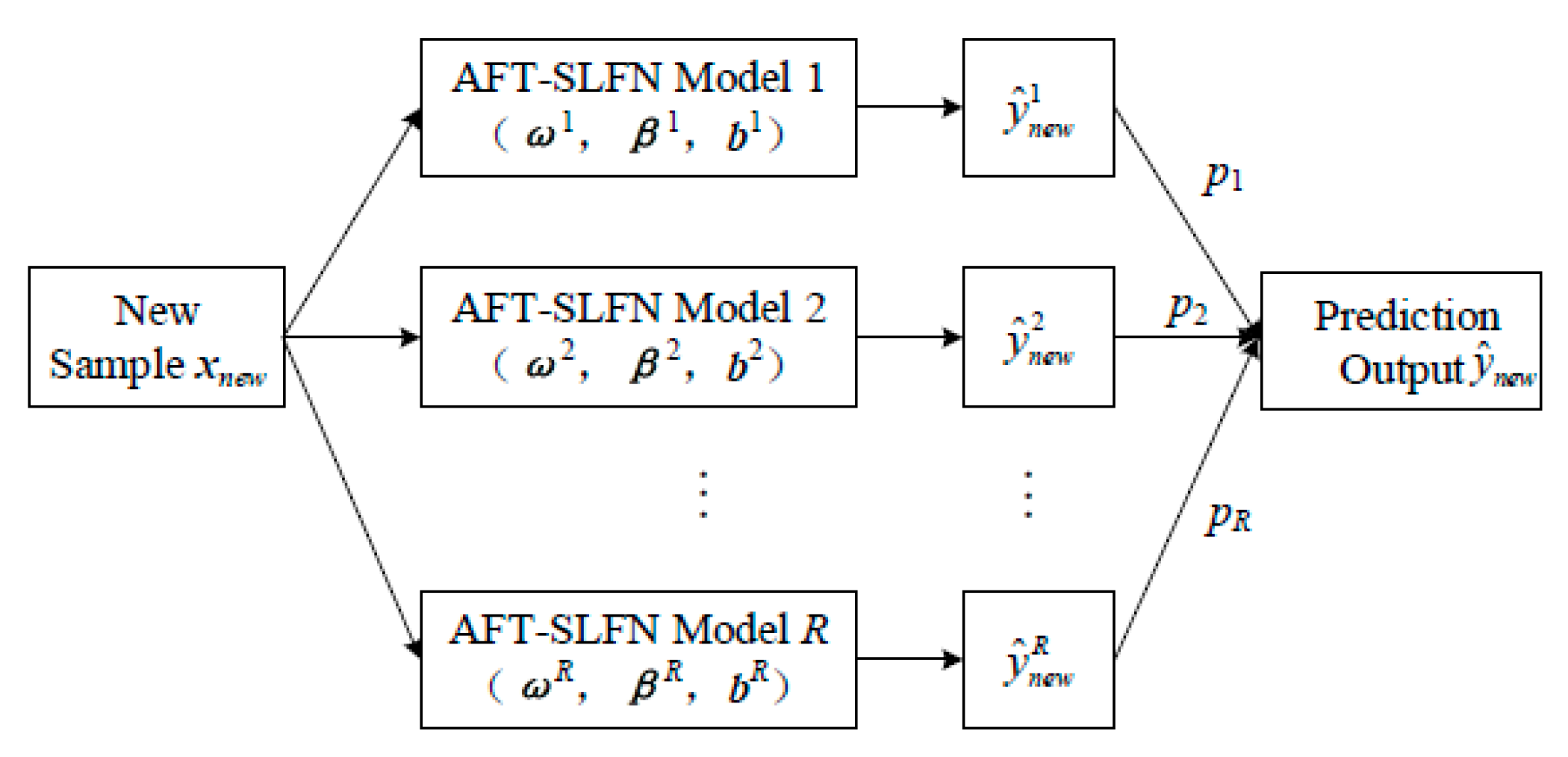
2.2. Adaptive Hybrid Model Based on Multiple AFL–SLFNs
3. Online Modification Method of Hybrid Process Model
3.1. Improved K-Neighbor Just-In-Time Learning for Small-Scale Modification
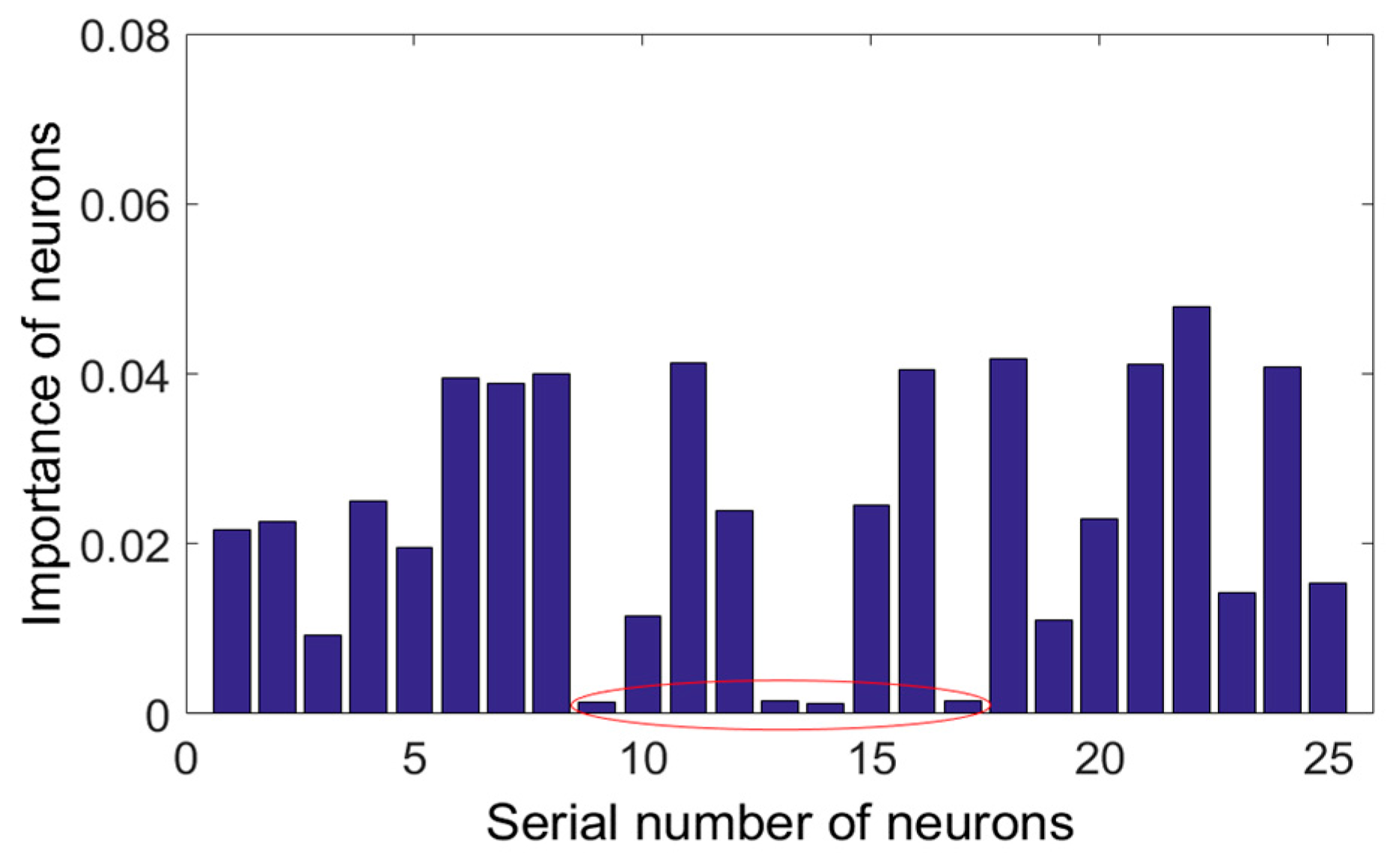
3.2. Morris-Based SLFN Structure Pruning for Medium-Scale Modification
3.3. Large-Scale Modification
4. Case Study: Online Simulation Using Industrial Data
4.1. Preprocesing of the Dataset
4.2. Small-Scale Mdoification of Prediction Model for Tailings Grade
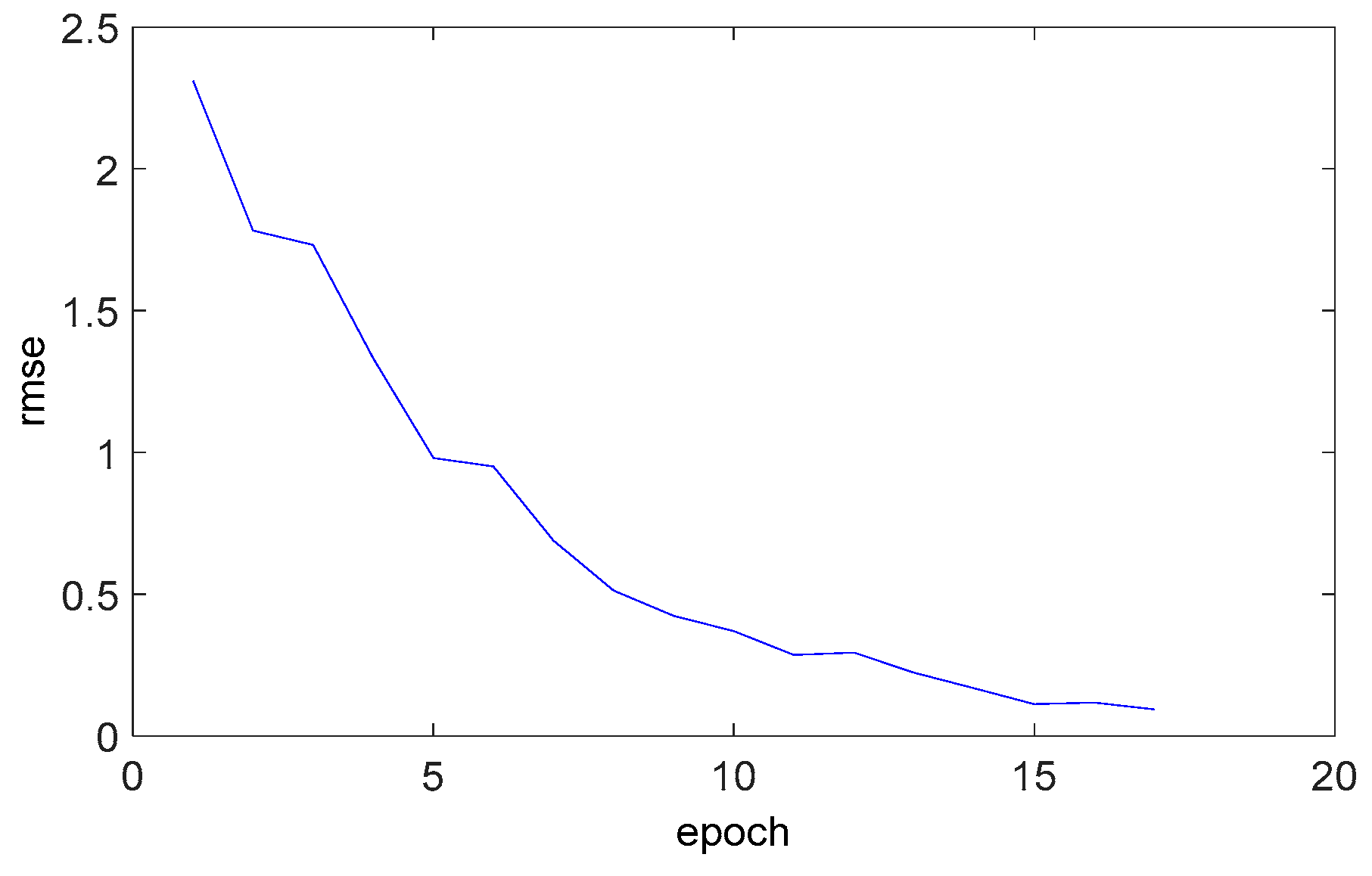
4.3. Medium-Scale Modification of Prediction Model for Tailings Grade
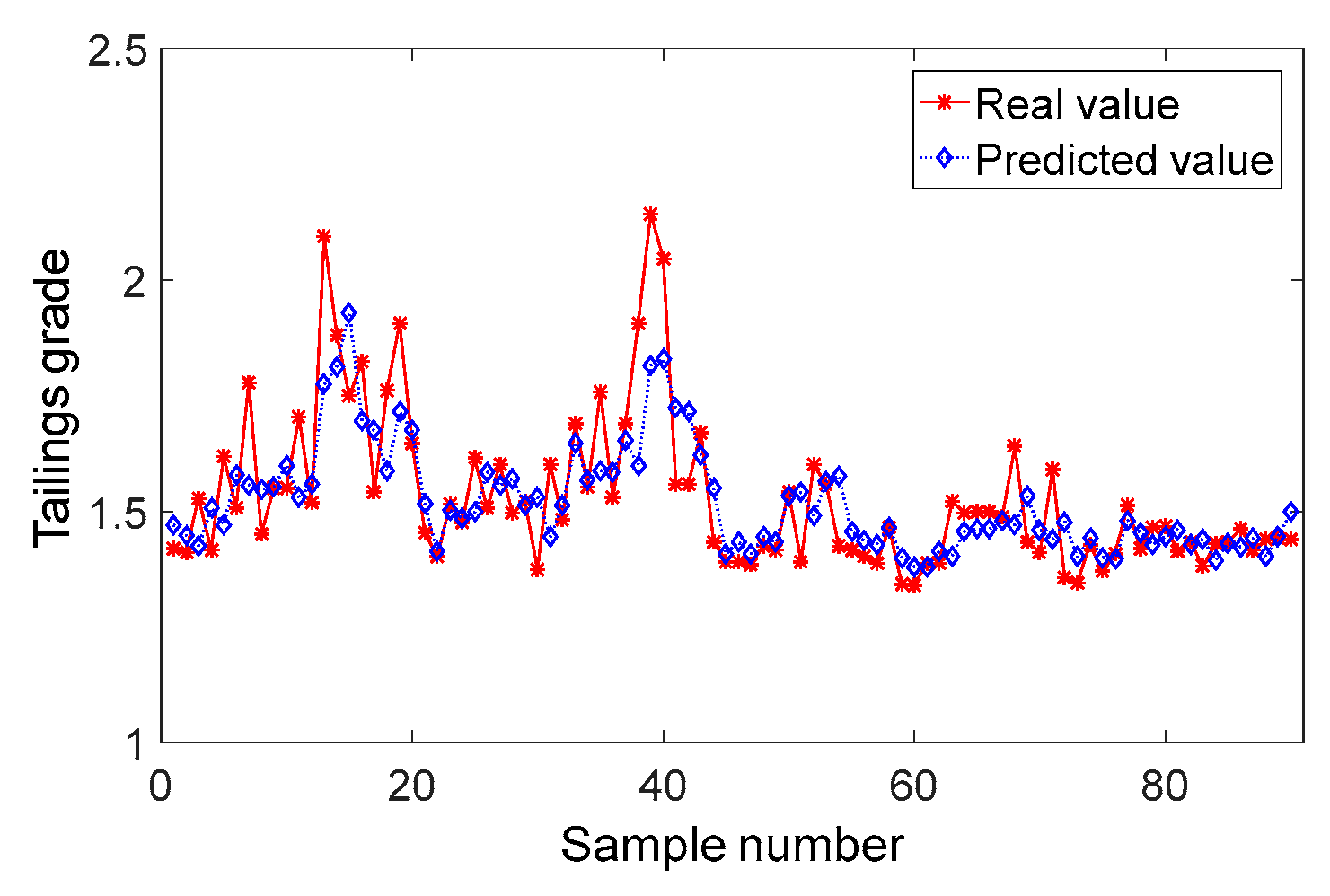
4.4. Model Comprasion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Oubelli, L.A.; Aït Ameur, Y.; Bedouet, J.; Kervarc, R.; Chausserie-Laprée, B.; Larzul, B. A scalable model based approach for data model evolution: Application to space missions data models. Comput. Lang. Syst. Struct. 2018, 54, 358–385. [Google Scholar] [CrossRef]
- Yerramilli, S.; Tangirala, A.K. Detection and diagnosis of model-plant mismatch in multivariable model-based control schemes. J. Process Control 2018, 66, 84–97. [Google Scholar] [CrossRef]
- Ge, Z.; Chen, X. Dynamic Probabilistic Latent Variable Model for Process Data Modeling and Regression Application. IEEE Trans. Control Syst. Technol. 2019, 27, 323–331. [Google Scholar] [CrossRef]
- Abdallah, A.M.; Rosenberg, D.E. A data model to manage data for water resources systems modeling. Environ. Model. Softw. 2019, 115, 113–127. [Google Scholar] [CrossRef]
- Mcbride, J.; Sullivan, A.; Xia, H.; Petrie, A.; Zhao, X. Reconstruction of physiological signals using iterative retraining and accumulated averaging of neural network models. Physiol. Meas. 2011, 32, 661–675. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Hong, W.; Lei, X.; Ping, W.; Song, Z. Data driven model mismatch detection based on statistical band of Markov parameters. Comput. Electr. Eng. 2014, 40, 2178–2192. [Google Scholar]
- Giantomassi, A.; Ippoliti, G.; Longhi, S.; Bertini, I.; Pizzuti, S. On-line steam production prediction for a municipal solid waste incinerator by fully tuned minimal RBF neural networks. J. Process Control 2011, 21, 164–172. [Google Scholar] [CrossRef]
- Song, W.; Liang, J.Z.; He, X.L.; Chen, P. Taking advantage of improved resource allocating network and latent semantic feature selection approach for automated text categorization. Appl. Soft Comput. J. 2014, 21, 210–220. [Google Scholar] [CrossRef]
- Wallace, M.; Tsapatsoulis, N.S. Intelligent initialization of resource allocating RBF networks. Neural Netw. 2005, 18, 117–122. [Google Scholar] [CrossRef]
- Wang, M.; Qi, C.; Yan, H.; Shi, H. Hybrid neural network predictor for distributed parameter system based on nonlinear dimension reduction. Neurocomputing 2016, 171, 1591–1597. [Google Scholar] [CrossRef]
- Liu, J.; Luan, X.; Liu, F. Adaptive JIT-Lasso modeling for online application of near infrared spectroscopy. Chemom. Intell. Lab. Syst. 2018, 183, 90–95. [Google Scholar] [CrossRef]
- Cheng, C.; Chiu, M.-S. A new data-based methodology for nonlinear process modeling. Chem. Eng. Sci. 2004, 59, 2801–2810. [Google Scholar] [CrossRef]
- Ding, Y.; Wang, Y.; Zhou, D. Mortality prediction for ICU patients combining just-in-time learning and extreme learning machine. Neurocomputing 2018, 281, 12–19. [Google Scholar] [CrossRef]
- Xiong, W.; Zhang, W.; Xu, B.; Huang, B. JITL based MWGPR soft sensor for multi-mode process with dual-updating strategy. Comput. Chem. Eng. 2016, 90, 260–267. [Google Scholar] [CrossRef]
- Fujiwara, K.; Kano, M.; Hasebe, S.; Takinami, A. Soft-sensor development using correlation-based just-in-time modeling. AIChE J. 2009, 55, 1754–1765. [Google Scholar] [CrossRef]
- Fujiwara, K.; Kano, M.; Hasebe, S. Development of correlation-based pattern recognition algorithm and adaptive soft-sensor design. Control Eng. Pract. 2012, 20, 371–378. [Google Scholar] [CrossRef]
- Yu, A.; Grauman, K. Predicting Useful Neighborhoods for Lazy Local Learning. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Uchimaru, T.; Kano, M. Sparse Sample Regression Based Just-In-Time Modeling (SSR-JIT): Beyond Locally Weighted Approach. IFAC Pap. 2016, 49, 502–507. [Google Scholar] [CrossRef]
- Niu, D.; Liu, Y. Modeling hydrometallurgical leaching process based on improved just-in-time learning algorithm. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017. [Google Scholar]
- Yuan, X.; Huang, B.; Ge, Z.; Song, Z. Double locally weighted principal component regression for soft sensor with sample selection under supervised latent structure. Chemom. Intell. Lab. Syst. 2016, 153, 116–125. [Google Scholar] [CrossRef]
- Morris, M.D. Factorial sampling plans for preliminary computational experiments. Technometrics 1991, 33, 161–174. [Google Scholar] [CrossRef]
- Engelbrecht, A.P. A new pruning heuristic based on variance analysis of sensitivity information. IEEE Trans. Neural Netw. 2001, 12, 1386–1399. [Google Scholar] [CrossRef]
- Khoshroo, A.; Emrouznejad, A.; Ghaffarizadeh, A.; Kasraei, M.; Omid, M. Sensitivity analysis of energy inputs in crop production using artificial neural networks. J. Clean. Prod. 2018, 197, 992–998. [Google Scholar] [CrossRef]
- Ibrahim, S.; Choong, C.E.; El-Shafie, A. Sensitivity analysis of artificial neural networks for just-suspension speed prediction in solid-liquid mixing systems: Performance comparison of MLPNN and RBFNN. Adv. Eng. Inform. 2019, 39, 278–291. [Google Scholar] [CrossRef]
- Huang, G.B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAP-RBF) neural network for function approximation. IEEE Trans. Neural Netw. 2005, 16, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, Y.; Setiono, R.; Azcarraga, A. Neural network training and rule extraction with augmented discretized input. Neurocomputing 2016, 207, 610–622. [Google Scholar] [CrossRef]
- Yin, J. A variable-structure online sequential extreme learning machine for time-varying system prediction. Neurocomputing 2017, 261, 115–125. [Google Scholar] [CrossRef]
- Henríquez, P.A.; Ruz, G.A. A non-iterative method for pruning hidden neurons in neural networks with random weights. Appl. Soft Comput. 2018, 70, 1109–1121. [Google Scholar] [CrossRef]
- Mohammed, M.F.; Lim, C.P. A new hyperbox selection rule and a pruning strategy for the enhanced fuzzy min–max neural network. Neural Netw. 2017, 86, 69–79. [Google Scholar] [CrossRef]
- Han, H.-G.; Zhang, S.; Qiao, J.-F. An adaptive growing and pruning algorithm for designing recurrent neural network. Neurocomputing 2017, 242, 51–62. [Google Scholar] [CrossRef]
- Mei, W.; Liu, Z.; Cheng, Y.; Zhang, Y. A MDPSO-Based Constructive ELM Approach With Adjustable Influence Value. IEEE Access 2018, 6, 60757–60768. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Z.; Huang, X.; Xiao, W. A Modified Residual Extreme Learning Machine Algorithm and Its Application. IEEE Access 2018, 6, 62215–62223. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Y.; Sun, B.; Peng, K.; Zhang, X. ELM weighted hybrid modeling and its online modification. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 3443–3448. [Google Scholar]
- Yang, S.; Wang, Y.; Wang, M.; He, H.; Li, Y. Active Functions Learning Neural Network. J. Jiangnan Univ. 2015, 6. [Google Scholar]
- Huang, G.B. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Yao, L.; Ge, Z. Distributed parallel deep learning of Hierarchical Extreme Learning Machine for multimode quality prediction with big process data. Eng. Appl. Artif. Intell. 2019, 81, 450–465. [Google Scholar] [CrossRef]
- Adhikari, N.C.D.; Alka, A.; George, R.K. TFFN: Two hidden layer feed forward network using the randomness of extreme learning machine. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 852–857. [Google Scholar]
- Golestaneh, P.; Zekri, M.; Sheikholeslam, F. Fuzzy wavelet extreme learning machine. Fuzzy Sets Syst. 2018, 342, 90–108. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S.; Yin, Y. Online sequential ELM algorithm with forgetting factor for real applications. Neurocomputing 2017, 261, 144–152. [Google Scholar] [CrossRef]
- Liao, Y.H.; Chou, J.C. Weighted Data Fusion Use for Ruthenium Dioxide Thin Film pH Array Electrodes. IEEE Sens. J. 2009, 9, 842–848. [Google Scholar] [CrossRef]
- Lewis, A.; Smith, R.; Williams, B. Gradient free active subspace construction using Morris screening elementary effects. Comput. Math. Appl. 2016, 72, 1603–1615. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Chen, X. Controlled Morris method: A new distribution-free sequential testing procedure for factor screening. In Proceedings of the 2017 Winter Simulation Conference (WSC), Las Vegas, NV, USA, 3–6 December 2017; pp. 1820–1831. [Google Scholar]
- Liang, N.; Huang, G.; Saratchandran, P.; Sundararajan, N. A Fast and Accurate Online Sequential Learning Algorithm for Feedforward Networks. IEEE Trans. Neural Netw. 2006, 17, 1411–1423. [Google Scholar] [CrossRef]
- Zong, W.; Huang, G.-B.; Chen, Y. Weighted extreme learning machine for imbalance learning. Neurocomputing 2013, 101, 229–242. [Google Scholar] [CrossRef]
- Park, J.M.; Kim, J.H. Online recurrent extreme learning machine and its application to time-series prediction. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Al-Musaylh, M.S.; Deo, R.C.; Adamowski, J.F.; Li, Y. Short-term electricity demand forecasting with MARS, SVR and ARIMA models using aggregated demand data in Queensland, Australia. Adv. Eng. Inform. 2018, 35, 1–16. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature | Pearson Coefficient | Significance Test (Ps) |
|---|---|---|---|
| 1 | Feeding rate | −0.403262 | 2.234 × 10−19 |
| 2 | Na2CO3 addition | 0.337195 | 1.145 × 10−13 |
| 3 | Roughing dispersant | −0.254534 | 1.123 × 10−7 |
| 4 | Cleaner_1 dispersant | −0.298500 | 6.705 × 10−11 |
| 5 | Fan frequency for air sparge | −0.319802 | 2.251 × 10−12 |
| 6 | Roughing_1 collector | −0.339910 | 7.071 × 10−14 |
| 7 | Rough scavenging collector | 0.388968 | 4.982 × 10−18 |
| 8 | Cleaner scavenging collector | 0.372919 | 1.363 × 10−16 |
| 9 | Roughing_1 froth depth | −0.329549 | 4.342 × 10−13 |
| 10 | Roughing_2 froth depth | −0.289702 | 2.517 × 10−10 |
| 11 | Cleaner_1 froth depth | −0.258562 | 1.906 × 10−8 |
| 12 | Cleaner_2 froth depth | −0.255940 | 2.678 × 10−8 |
| R | H | MRE | RMSE | R2 | Time (s) |
|---|---|---|---|---|---|
| 3 | 10 | 0.0653 | 0.1463 | 0.4795 | 1.2163 |
| 25 | 0.0582 | 0.1248 | 0.6622 | 1.2424 | |
| 40 | 0.0600 | 0.1244 | 0.6666 | 1.2815 | |
| 6 | 10 | 0.0608 | 0.1376 | 0.5906 | 1.2525 |
| 25 | 0.0583 | 0.1211 | 0.6870 | 1.2883 | |
| 40 | 0.0577 | 0.1223 | 0.6792 | 1.3946 | |
| 10 | 10 | 0.0617 | 0.1392 | 0.5898 | 1.3412 |
| 25 | 0.0589 | 0.1214 | 0.6839 | 1.3204 | |
| 40 | 0.0591 | 0.1230 | 0.6703 | 1.5452 |
| No. | Sliding Window | [0, 0.08) | [0.08, 0.15) | [0.15, 0.25) | [0.25, ∞] | Query Sample | Modification Strategy |
|---|---|---|---|---|---|---|---|
| 1 | Samples 1–9 | 4 | 4 | 1 | 0 | 10 | Small |
| 2 | Samples 2–10 | 4 | 4 | 1 | 0 | 11 | Small |
| 3 | Samples 3–11 | 3 | 4 | 2 | 0 | 12 | Small |
| 4 | Samples 4–12 | 4 | 3 | 2 | 0 | 13 | Small |
| 5 | Samples 5–13 | 4 | 2 | 2 | 1 | 14 | None |
| 6 | Samples 6–14 | 5 | 1 | 2 | 1 | 15 | None |
| 7 | Samples 7–15 | 4 | 1 | 3 | 1 | 16 | Medium |
| 8 | Samples 8–16 | 4 | 2 | 2 | 1 | 17 | None |
| 81 | Samples 81–89 | 9 | 0 | 0 | 0 | 90 | None |
| 82 | Samples 82–90 | 9 | 0 | 0 | 0 | None | None |
| Modification Strategy | RMSE | MRE | R2 | Time (s) |
|---|---|---|---|---|
| No modification | 0.1211 | 0.0583 | 0.6870 | 1.2883 |
| Small-scale modification | 0.1057 | 0.0474 | 0.7818 | 4.6665 |
| Multiscale modification | 0.0845 | 0.0316 | 0.8748 | 9.1429 |
| Model | RMSE | MRE | R2 | Time (s) |
|---|---|---|---|---|
| SVR | 0.1472 | 0.0697 | 0.4755 | 2.7811 |
| ELM | 0.1421 | 0.0651 | 0.5405 | 1.0093 |
| OS-ELM | 0.1405 | 0.0634 | 0.5473 | 1.8993 |
| Weighted ELM | 0.1380 | 0.0612 | 0.5644 | 1.6771 |
| OR-ELM | 0.1326 | 0.0629 | 0.6202 | 1.8219 |
| AFL–SLFN hybrid | 0.1211 | 0.0583 | 0.6870 | 1.2883 |
| AFL–SLFN hybrid with modification | 0.0845 | 0.0361 | 0.8748 | 9.1429 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhang, H.; Wang, Y.; Yang, S. ELM-Based AFL–SLFN Modeling and Multiscale Model-Modification Strategy for Online Prediction. Processes 2019, 7, 893. https://doi.org/10.3390/pr7120893
Wang X, Zhang H, Wang Y, Yang S. ELM-Based AFL–SLFN Modeling and Multiscale Model-Modification Strategy for Online Prediction. Processes. 2019; 7(12):893. https://doi.org/10.3390/pr7120893
Chicago/Turabian StyleWang, Xiaoli, He Zhang, Yalin Wang, and Shaoming Yang. 2019. "ELM-Based AFL–SLFN Modeling and Multiscale Model-Modification Strategy for Online Prediction" Processes 7, no. 12: 893. https://doi.org/10.3390/pr7120893
APA StyleWang, X., Zhang, H., Wang, Y., & Yang, S. (2019). ELM-Based AFL–SLFN Modeling and Multiscale Model-Modification Strategy for Online Prediction. Processes, 7(12), 893. https://doi.org/10.3390/pr7120893