
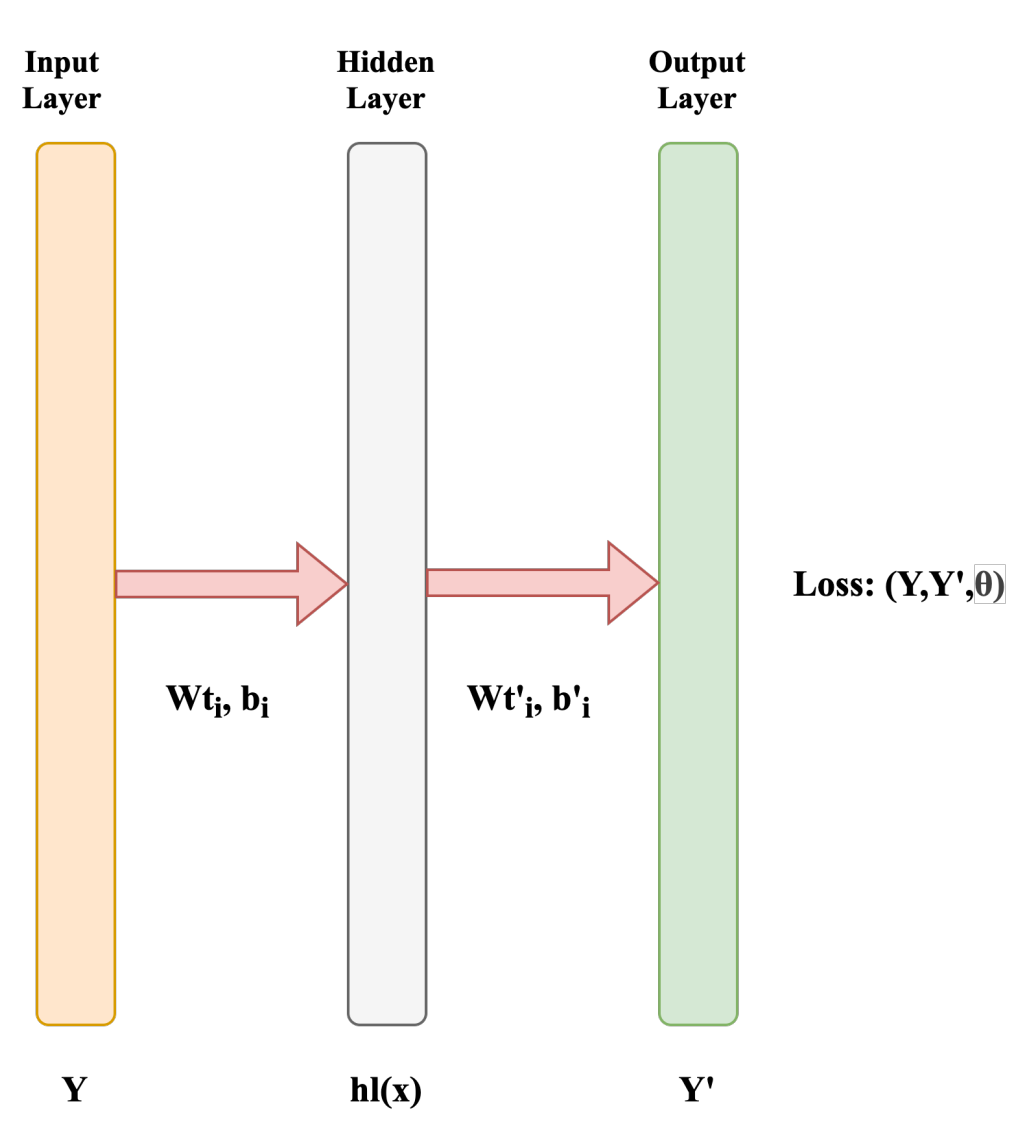
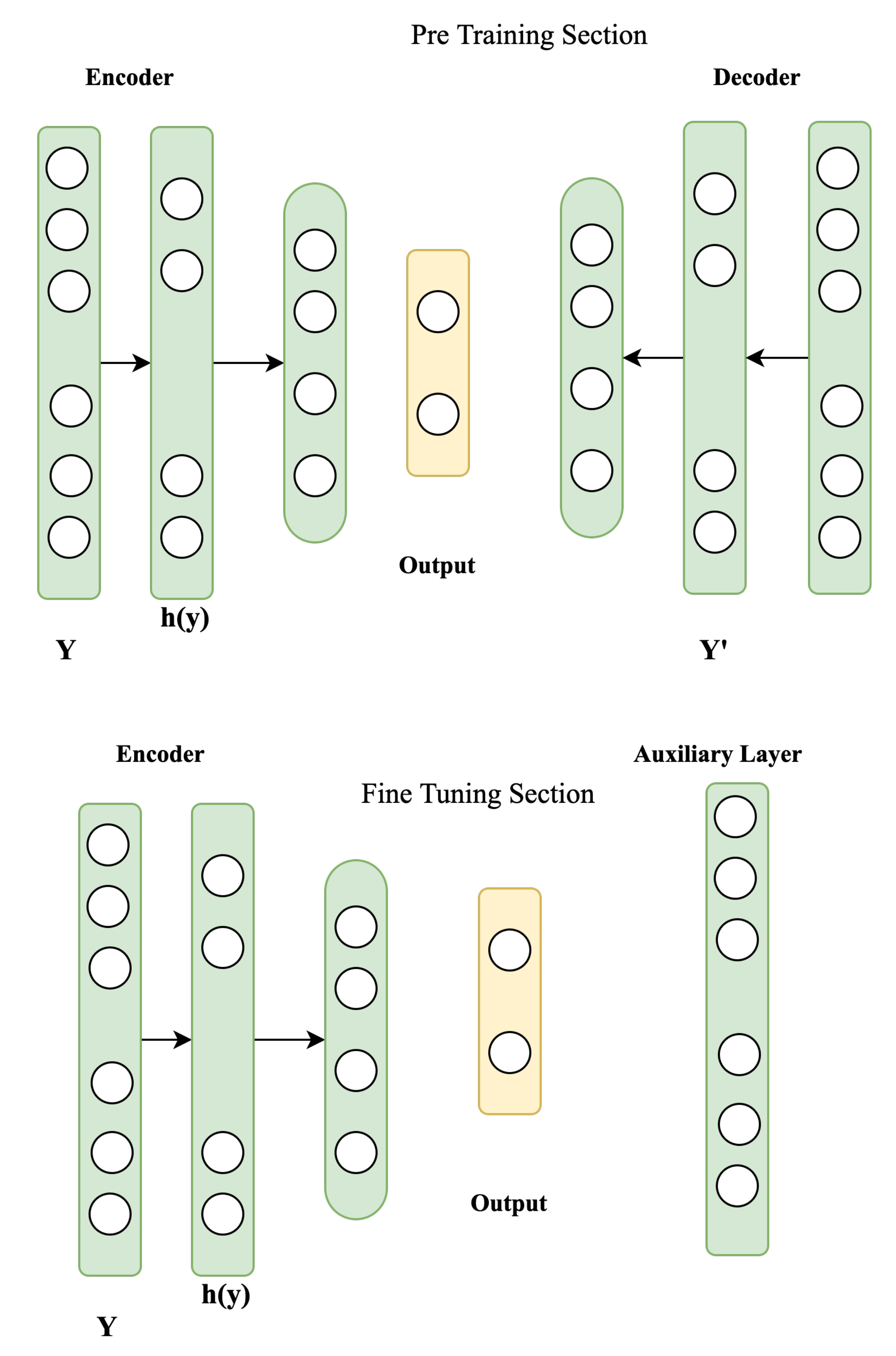
Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Amjad, A.; Khan, L.; Chang, H.-T. Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification. Processes 2021, 9, 2286. https://doi.org/10.3390/pr9122286
Amjad A, Khan L, Chang H-T. Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification. Processes. 2021; 9(12):2286. https://doi.org/10.3390/pr9122286
Chicago/Turabian StyleAmjad, Ammar, Lal Khan, and Hsien-Tsung Chang. 2021. "Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification" Processes 9, no. 12: 2286. https://doi.org/10.3390/pr9122286
APA StyleAmjad, A., Khan, L., & Chang, H.-T. (2021). Semi-Natural and Spontaneous Speech Recognition Using Deep Neural Networks with Hybrid Features Unification. Processes, 9(12), 2286. https://doi.org/10.3390/pr9122286