Adaptive Resource Allocation for Emergency Communications with Unmanned Aerial Vehicle-Assisted Free Space Optical/Radio Frequency Relay System


Abstract
:1. Introduction
- (1)
- A mathematical model for emergency communication scenarios is formulated, where several UAVs were used as offloading nodes for MEC or as access relays, facilitating the connection between MUs and GBSs. Specifically, we described the scenario, RF model, FSO model, and delay model of emergency communication.
- (2)
- We propose a UAV-assisted resource allocation method known as K-means MADDPS (KMADDPG), which aims to maximize the number of successful tasks while prioritizing high-priority ones. The proposed algorithm builds on the MADDPG algorithm, integrating it with the K-means algorithm to handle the high data dimensionality in the above-mentioned scenarios. For different tasks with different urgency levels, we incorporate a priority mechanism for mobile users.
- (3)
- We examine the time complexity of the proposed algorithm and assess its performance in emergency communication settings through simulation studies. The results indicate that the proposed KMADDPG effectively optimizes communication resource allocation in regions affected by disasters with compromised communication infrastructures. Additionally, extensive simulations reveal that KMADDPG surpasses several baseline methods regarding convergence speed and the number of successful tasks.
2. Related Work
3. System Model
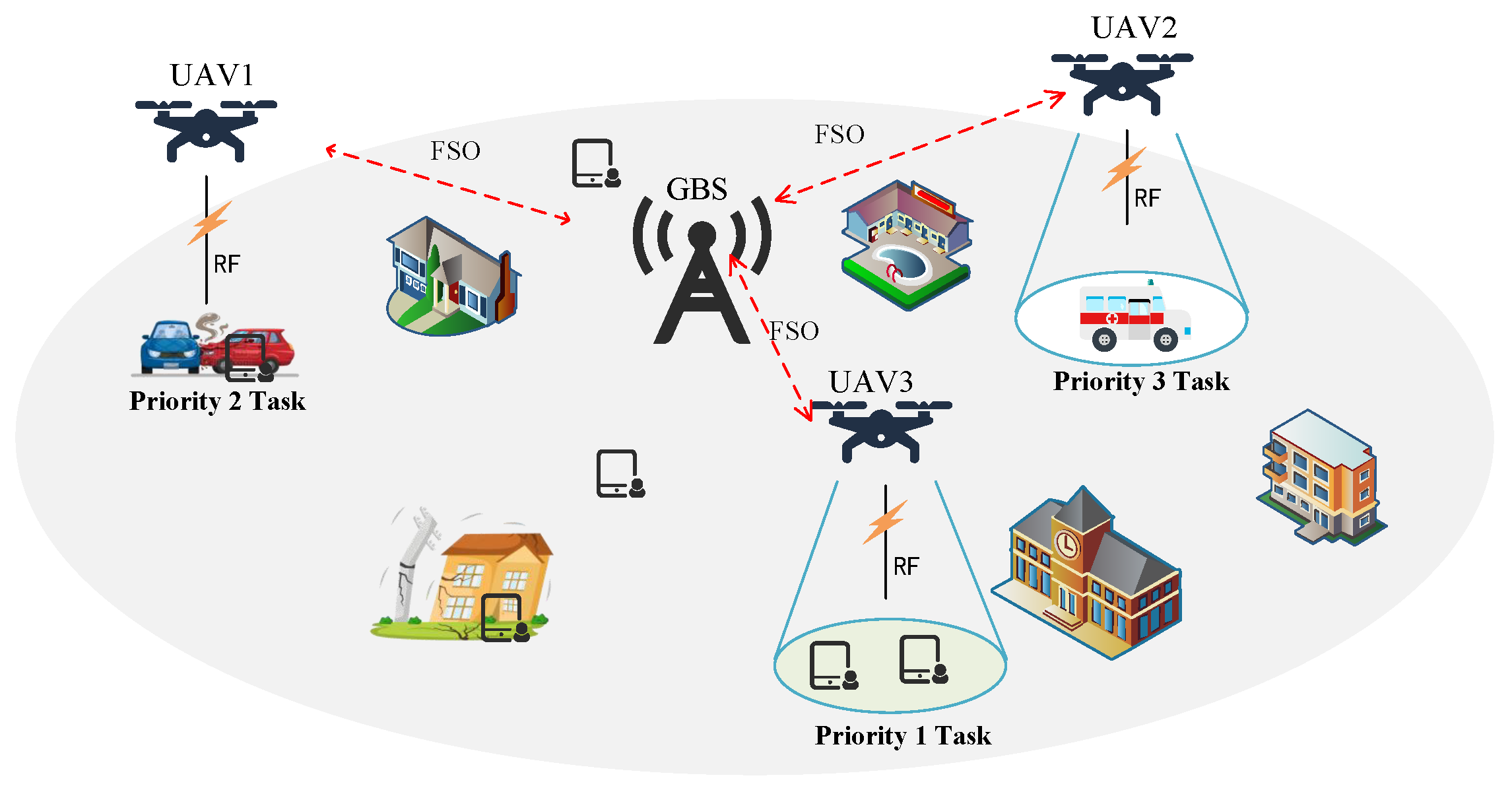
3.1. Scenario
3.2. Air-to-Ground Channel
3.3. Air-to-Air Channel
3.4. Computing Delay Model
- (1)
- Local Computing: When the computing power of the device of an MU can satisfy the task requirements, the MU can choose local processing. The processing time of a task can be expressed as , where can be expressed aswhere l indicates the time slot, represents the pre-assigned offload ratio of UAVs for the task of MU j. is the size of the task submitted by user j. is the CPU frequency of the user’s device. s represents the CPU cycles required per bit.
- (2)
- Offloading to UAVs: When the computing power of the device of an MU cannot meet the task requirements, the MU can choose to offload part of the task to the UAVs for concurrent execution. can be represented aswhere and represent the time of transmission and computing when the user transmits data to UAV i by the RF channel, respectively. and can be expressed asand
- (3)
- Offloading to BS via UAV: When the computing power of both the user’s device and the UAV cannot meet the task requirements, the UAV will forward the received task data to the GBS via the FSO channel. can be represented aswhere is the transmission time from UAV i to the GBS g via the FSO channel, can be expressed as
3.5. Problem Formulation
4. KMADDPG-Based UAV Resource Allocation
4.1. Overview
4.2. Markov Decision Analysis
- (1)
- State : In the proposed system model, the information obtained by agents through observations at time slot t is defined as . Due to each agent having its local observation and local decision space, is typically incomplete. It can be composed of , where represents the state information of the GBS. denotes the state information of UAV i at time slot t, which can be expressed aswhere and represent the bandwidth and CPU computing power held by the UAV, respectively. represents the state information of user equipment, and its components are aswhere represents the delay requirement for the task delivered by user j; indicates the priority weight of the current task.
- (2)
- Observation : At time slot t, all agents’ local observation information can be combined to form a global observation . It can be expressed as
- (3)
- Action Space : The action space of KMADDPG mainly consists of three parts: decisions of task matching, edge offloading, and resource allocation. The components of are aswhere denotes the decision of UAV matching with users, and . denotes the decision of task offloading rate, and indicates the actions of resource allocation.
- (4)
- Reward Function : is the sum of rewards completed by all UAVs. In the proposed scenario, the priority weights of user requests differ; it should focus on handling high-priority urgent requests. Therefore, the reward function is related to priority weights and completion status, which can be expressed aswhere is a binary coefficient indicating the completion status of the task. If the UAV can satisfy the user’s delay requirement, then = 1 and the task is considered completed. The task reward can be expressed as . Otherwise, = 0 and the task reward can be expressed as , where is the reward coefficient for task completion, and is the penalty coefficient for task failure.
4.3. MADDPG-Based Resource Allocation and Task Offloading
- (1)
- Joint K-Means Algorithm: We propose a joint K-means algorithm for initializing the positions of UAVs. According to the path loss formula, path loss is positively correlated with the distance between UAVs and MUs. During centralized training, the system obtains the positions of all agents. We define sets and to represent the positions of UAVs and users, respectively. Here, is different from the Q mentioned earlier; it only represents the 2D coordinates of UAVs and users. The purpose of the K-means algorithm is to set I cluster centers , assign J user devices to the nearest cluster centers , and finally, the positions of the cluster centers will be the target positions for the UAVs. The optimization objective function of the K-means algorithm can be expressed asThe updating process of K-means can be expressed as
- (2)
- Deep Reinforcement Learning Algorithm: To avoid the additional load and delay caused by information exchange between the central controller and UAVs, this paper proposes a distributed joint resource management algorithm based on MADDPG. We consider a centralized training decentralized execution DRL mechanism. In the CTDE strategy, the collaborative operation of agents can be viewed as an optimization problem that maximizes expected rewards. This optimization problem can be expressed aswhere represents the policy network of the agent. denotes the discounted return at time slot t. We set the parameters of the policy network as , then the expected return gradient of the UAV can be written aswhere D is the experience replay buffer that stores experience tuples . is the value function. The loss function of the Critic network for UAV i can be expressed aswhere is the TD error, which can be expressed aswhere and are the target Critic network and target Actor network, respectively. The specific neural network update process is shown in Algorithm 1.
- (3)
- Complexity Analysis: The complexity analysis of the KMADDPG algorithm can be divided into two main components: the K-means algorithm and the neural network. For the K-means algorithm, each iteration requires the position coordinates of each UAV and MU, resulting in a time complexity of . The number of iteration is denoted as . After iterating, the total time complexity for the K-means algorithm is given bySince the dimensionality of the 2D coordinates and the number of iterations are generally constants, this complexity simplifies to . For the neural network part, the efficiency of the proposed algorithm is further evaluated through its time complexity. Both offline training and online execution involve mapping states to actions using deep neural networks. The computational complexity of the deep neural network, denoted as , is expressed as follows [39]:where is the number of layers, and represents the number of neurons in the n-th layer. The dimensions of input and output layers of the deep neural network depends on the size of state space and action space. For episodes, S steps, and experiences, the algorithm’s time complexity is
| Algorithm 1 KMADDPG Algorithm | |
| Initialize: Max_episode, Max_ep_len; | |
| 1: | for episode from 1 to Max_episode do |
| 2: | |
| 3: | |
| 4: | for each MU do |
| 5: | Calculate the distance between UAV and MU; |
| 6: | Find the closest centroids ; |
| 7: | Assign to closet centroids ; |
| 8: | endfor |
| 9: | Update centroids position: |
| 10: | ; |
| 11: | for t = 1 to Max_ep_len do |
| 12: | |
| 13: | |
| 14: | |
| 15: | |
| 16: | |
| 17: | for agent i = 1 to I do |
| 18: | N |
| 19: | |
| 20: | |
| 20: | |
| 22: | |
| 23: | endfor |
| 24: | |
| 25: | |
| 26: | |
| 27: | endfor |
| 28: | endfor |
5. Experimental Design and Analysis
5.1. Simulation Parameters
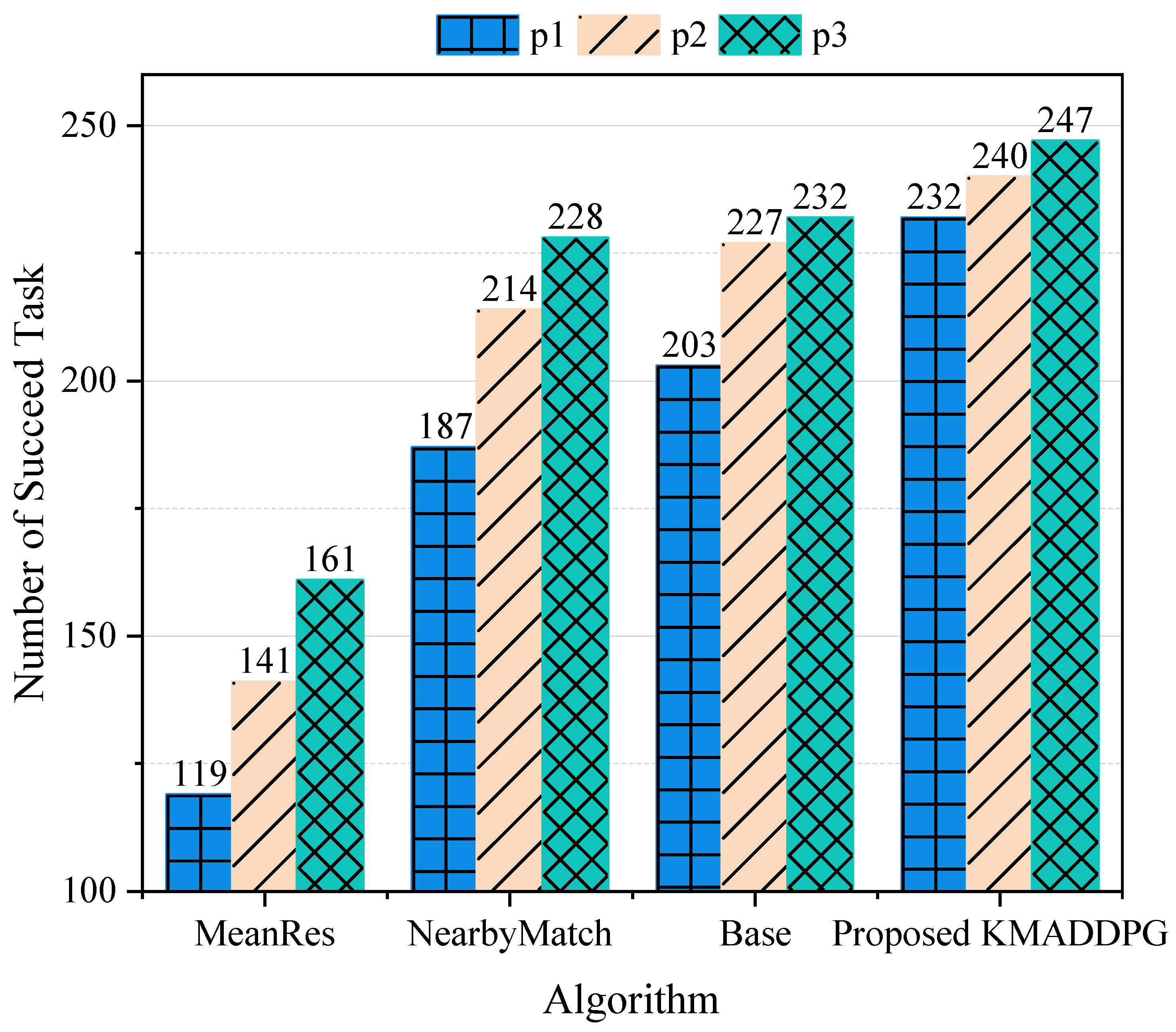
- •
- MeanResource MADDPG (MeanRes): An algorithm where the neural network selects the matching objects, but the offloading ratio and resource allocation ratio are evenly distributed.
- •
- NearbyMatch MADDPG (NearbyMatch): An algorithm where the neural network selects the offloading and resource ratios, and the service objects are the nearest users.
- •
- Base MADDPG (Base): An algorithm where the neural network selects the matching objects, offloading, and resource ratios.
- •
- Proposed KMADDPG (Proposed): An algorithm that integrates K-means into the Base MADDPG algorithm.
5.2. Convergence Analysis
5.3. Priority Analysis
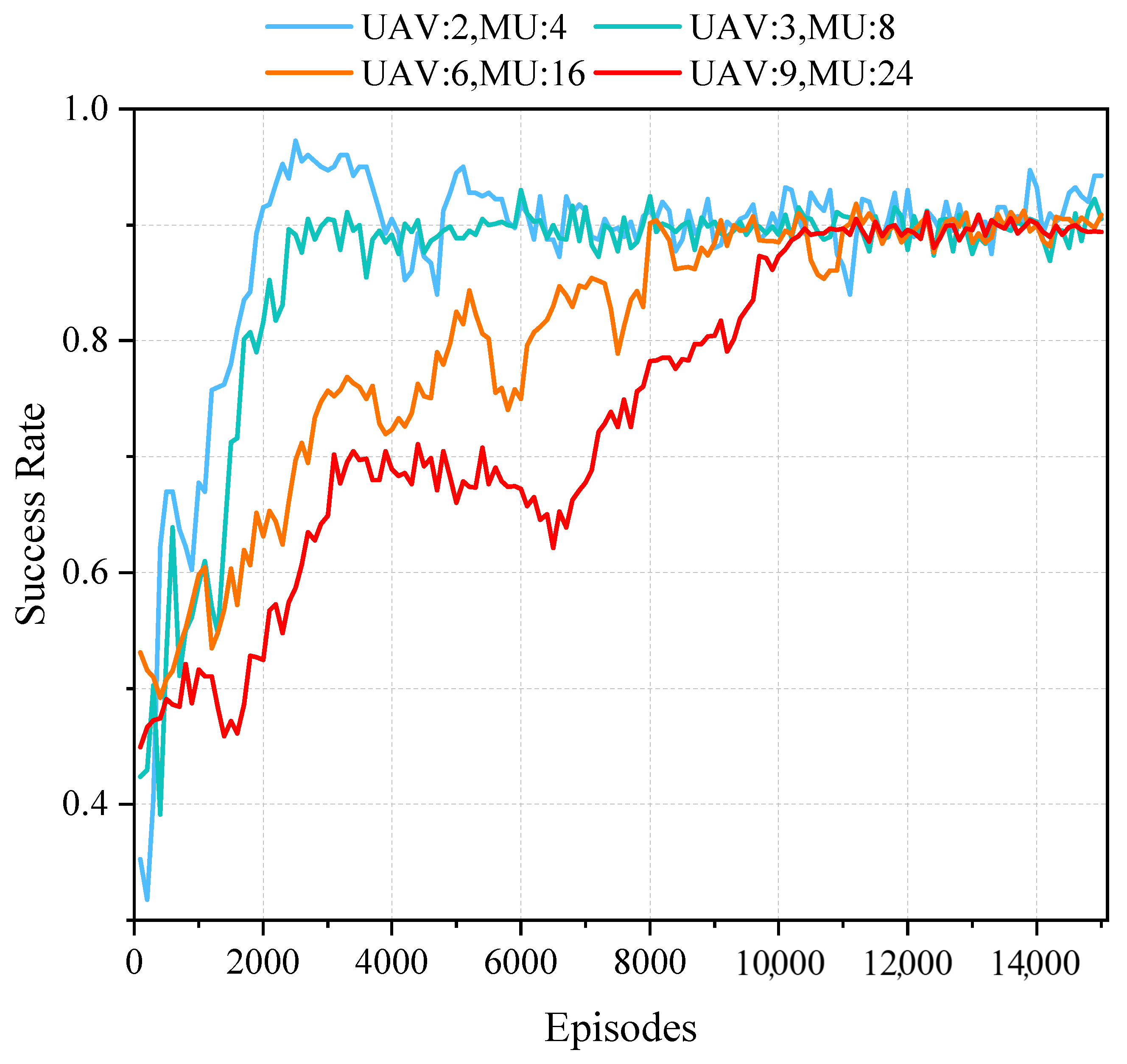
5.4. Convergence under Different Proportions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Cao, Y.; Lam, K.Y.; Hu, Y.; Kaiwartya, O. Authentication and Key Agreement Based On Three Factors and PUF for UAVs-Assisted Post-Disaster Emergency Communication. IEEE Internet Things J. 2024, 11, 20457–20472. [Google Scholar] [CrossRef]
- Yao, Z.; Cheng, W.; Zhang, W.; Zhang, H. Resource allocation for 5G-UAV-based emergency wireless communications. IEEE J. Sel. Areas Commun. 2021, 39, 3395–3410. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Q.; Jiang, H.; Wang, H.; Xie, Y.; Xu, W.; Zhou, P.; Xu, Z.; Chen, L.; Li, B.; et al. Joint Power and Coverage Control of Massive UAVs in Post-Disaster Emergency Networks: An Aggregative Game-Theoretic Learning Approach. IEEE Trans. Netw. Sci. Eng. 2024, 11, 3782–3799. [Google Scholar] [CrossRef]
- Tang, X.; Chen, F.; Wang, F.; Jia, Z. Disaster Resilient Emergency Communication With Intelligent Air-Ground Cooperation. IEEE Internet Things J. 2023, 11, 5331–5346. [Google Scholar] [CrossRef]
- Gao, J.; Wang, Q.; Li, Z.; Zhang, X.; Hu, Y.; Han, Q.; Pan, Y. Towards Efficient Urban Emergency Response Using UAVs Riding Crowdsourced Buses. IEEE Internet Things J. 2024, 11, 22439–22455. [Google Scholar] [CrossRef]
- Zhou, M.; Chen, H.; Shu, L.; Liu, Y. UAV-assisted sleep scheduling algorithm for energy-efficient data collection in agricultural Internet of Things. IEEE Internet Things J. 2021, 9, 11043–11056. [Google Scholar] [CrossRef]
- Bekkali, A.; Fujita, H.; Hattori, M. New generation free-space optical communication systems with advanced optical beam stabilizer. J. Light. Technol. 2022, 40, 1509–1518. [Google Scholar] [CrossRef]
- Bekkali, A.; Hattori, M.; Hara, Y.; Suga, Y. Free Space Optical Communication Systems FOR 6G: A Modular Transceiver Design. IEEE Wirel. Commun. 2023, 30, 50–57. [Google Scholar] [CrossRef]
- Guo, Z.; Gao, W.; Ye, H.; Wang, G. A location-aware resource optimization for maximizing throughput of emergency outdoor–indoor UAV communication with FSO/RF. Sensors 2023, 23, 2541. [Google Scholar] [CrossRef] [PubMed]
- Yahia, O.B.; Erdogan, E.; Kurt, G.K.; Altunbas, I.; Yanikomeroglu, H. A weather-dependent hybrid RF/FSO satellite communication for improved power efficiency. IEEE Wirel. Commun. Lett. 2021, 11, 573–577. [Google Scholar] [CrossRef]
- Aboelala, O.; Lee, I.E.; Chung, G.C. A survey of hybrid free space optics (FSO) communication networks to achieve 5G connectivity for backhauling. Entropy 2022, 24, 1573. [Google Scholar] [CrossRef] [PubMed]
- Nafees, M.; Huang, S.; Thompson, J.; Safari, M. Backhaul-aware user association and throughput maximization in UAV-aided hybrid FSO/RF network. Drones 2023, 7, 74. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Wang, C.X.; Sun, J.; Liu, Y. Deep reinforcement learning for dynamic spectrum sensing and aggregation in multi-channel wireless networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 464–475. [Google Scholar] [CrossRef]
- Zhu, G.; Lyu, Z.; Jiao, X.; Liu, P.; Chen, M.; Xu, J.; Cui, S.; Zhang, P. Pushing AI to wireless network edge: An overview on integrated sensing, communication, and computation towards 6G. Sci. China Inf. Sci. 2023, 66, 130301. [Google Scholar] [CrossRef]
- Song, F.; Xing, H.; Wang, X.; Luo, S.; Dai, P.; Xiao, Z.; Zhao, B. Evolutionary multi-objective reinforcement learning based trajectory control and task offloading in UAV-assisted mobile edge computing. IEEE Trans. Mob. Comput. 2022, 22, 7387–7405. [Google Scholar] [CrossRef]
- Yang, Y.; Song, T.; Yang, J.; Xu, H.; Xing, S. Joint Energy and AoI Optimization in UAV-Assisted MEC-WET Systems. IEEE Sensors J. 2024, 24, 15110–15124. [Google Scholar] [CrossRef]
- Guo, S.; Zhao, X. Multi-Agent Deep Reinforcement Learning Based Transmission Latency Minimization for Delay-Sensitive Cognitive Satellite-UAV Networks. IEEE Trans. Commun. 2023, 71, 131–144. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhang, Y.; Lim, W.Y.B.; Kang, J.; Niyato, D.; Leung, C.; Miao, C. UAV-assisted wireless energy and data transfer with deep reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 85–99. [Google Scholar] [CrossRef]
- Qin, Z.; Liu, Z.; Han, G.; Lin, C.; Guo, L.; Xie, L. Distributed UAV-BSs Trajectory Optimization for User-Level Fair Communication Service With Multi-Agent Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 12290–12301. [Google Scholar] [CrossRef]
- Westheider, J.; Rückin, J.; Popović, M. Multi-uav adaptive path planning using deep reinforcement learning. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 649–656. [Google Scholar]
- Orr, J.; Dutta, A. Multi-agent deep reinforcement learning for multi-robot applications: A survey. Sensors 2023, 23, 3625. [Google Scholar] [CrossRef] [PubMed]
- Pang, W.; Wang, P.; Han, M.; Li, S.; Yang, P.; Li, G.; Guo, L. Optical intelligent reflecting surface for mixed dual-hop FSO and beamforming-based RF system in C-RAN. IEEE Trans. Wirel. Commun. 2022, 21, 8489–8506. [Google Scholar] [CrossRef]
- Wang, D.; Wu, M.; Wei, Z.; Yu, K.; Min, L.; Mumtaz, S. Uplink secrecy performance of RIS-based RF/FSO three-dimension heterogeneous networks. IEEE Trans. Wirel. Commun. 2023, 23, 1798–1809. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, K.H.; Ko, Y.C.; Alouini, M.S. Spectral-efficient network design for high-altitude platform station networks with mixed RF/FSO system. IEEE Trans. Wirel. Commun. 2022, 21, 7072–7087. [Google Scholar] [CrossRef]
- Che, Y.L.; Long, W.; Luo, S.; Wu, K.; Zhang, R. Energy-efficient UAV multicasting with simultaneous FSO backhaul and power transfer. IEEE Wirel. Commun. Lett. 2021, 10, 1537–1541. [Google Scholar] [CrossRef]
- Qi, W.; Song, Q.; Guo, L.; Jamalipour, A. Energy-efficient resource allocation for UAV-assisted vehicular networks with spectrum sharing. IEEE Trans. Veh. Technol. 2022, 71, 7691–7702. [Google Scholar] [CrossRef]
- Jiang, F.; Dong, L.; Wang, K.; Yang, K.; Pan, C. Distributed resource scheduling for large-scale MEC systems: A multiagent ensemble deep reinforcement learning with imitation acceleration. IEEE Internet Things J. 2021, 9, 6597–6610. [Google Scholar] [CrossRef]
- Qin, Z.; Wang, H.; Wei, Z.; Qu, Y.; Xiong, F.; Dai, H.; Wu, T. Task selection and scheduling in UAV-enabled MEC for reconnaissance with time-varying priorities. IEEE Internet Things J. 2021, 8, 17290–17307. [Google Scholar] [CrossRef]
- Liu, X.; Xu, C.; Yu, H.; Zeng, P. Deep reinforcement learning-based multichannel access for industrial wireless networks with dynamic multiuser priority. IEEE Trans. Ind. Inform. 2021, 18, 7048–7058. [Google Scholar] [CrossRef]
- Seid, A.M.; Boateng, G.O.; Anokye, S.; Kwantwi, T.; Sun, G.; Liu, G. Collaborative computation offloading and resource allocation in multi-UAV-assisted IoT networks: A deep reinforcement learning approach. IEEE Internet Things J. 2021, 8, 12203–12218. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, P.; Zhang, M.; Zhang, Z.; Yu, F.R. Mobile-Aware Service Offloading for UAV-Assisted IoVs: A Multi-Agent Tiny Distributed Learning Approach. IEEE Internet Things J. 2024, 11, 21191–21201. [Google Scholar] [CrossRef]
- He, Y.; Gan, Y.; Cui, H.; Guizani, M. Fairness-based 3D multi-UAV trajectory optimization in multi-UAV-assisted MEC system. IEEE Internet Things J. 2023, 10, 11383–11395. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, J.; Bennis, M.; Ko, Y.C. Integrating LEO satellites and multi-UAV reinforcement learning for hybrid FSO/RF non-terrestrial networks. IEEE Trans. Veh. Technol. 2022, 72, 3647–3662. [Google Scholar] [CrossRef]
- Guan, Y.; Zou, S.; Peng, H.; Ni, W.; Sun, Y.; Gao, H. Cooperative UAV trajectory design for disaster area emergency communications: A multi-agent PPO method. IEEE Internet Things J. 2023, 11, 8848–8859. [Google Scholar] [CrossRef]
- Ali, M.A.; Jamalipour, A. UAV-aided cellular operation by user offloading. IEEE Internet Things J. 2020, 8, 9855–9864. [Google Scholar] [CrossRef]
- Liu, C.; Ding, M.; Ma, C.; Li, Q.; Lin, Z.; Liang, Y.C. Performance analysis for practical unmanned aerial vehicle networks with LoS/NLoS transmissions. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Nistazakis, H.E.; Tsiftsis, T.A.; Tombras, G.S. Performance analysis of free-space optical communication systems over atmospheric turbulence channels. IET Commun. 2009, 3, 1402–1409. [Google Scholar] [CrossRef]
- Kim, I.I.; Koontz, J.; Hakakha, H.; Adhikari, P.; Stieger, R.; Moursund, C.; Barclay, M.; Stanford, A.; Ruigrok, R.; Schuster, J.J.; et al. Measurement of scintillation and link margin for the TerraLink laser communication system. In Wireless Technologies and Systems: Millimeter-Wave and Optical; SPIE: Bellingham, WA, USA, 1998; Volume 3232, pp. 100–118. [Google Scholar]
- Wang, S.; Lv, T. Deep reinforcement learning based dynamic multichannel access in HetNets. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| The index/set of UAVs | |
| The index/set of MUs | |
| The index/set of GBSs | |
| Distance between UAV i and MU j | |
| The position of UAV i/MU j | |
| Average path loss between UAV i and MU j | |
| Transmission rate between UAV i and MU j | |
| Backhaul rate between UAV i and its GBS | |
| Distance between UAV i and GBS g | |
| Load rate between UAV i and MU j | |
| Bandwidth allocated to MU j by UAV i | |
| CPU frequency allocated to MU j by UAV i | |
| The RF/FSO transmit time between UAV i and GBS g | |
| Additive white Gaussian noise | |
| The weight of priority | |
| S | State space |
| A | Action space |
| Reward | |
| Obeject function | |
| Value function |
| Parameters | Value |
|---|---|
| Learning rate of actor | 2 |
| Learning rate of Critic | 5 |
| The number of Episode | 15,000 |
| Episode length | 10 |
| Channel bandwidth | 50 |
| Cpu frequency of UAV () | |
| Cpu frequency of MU () | |
| Size of task () | 0.1 M–1.5 M |
| Requested delay of task () | 12 ms–15 ms |
| LoS additional path loss | |
| NLoS additional path loss for | |
| LoS path loss exponent | 2.09 |
| NLoS path loss exponent | 3.75 |
| Noise power | −95 |
| Operating altitude of UAV | |
| Transmit power of UAV i | 30 |
| Transmission power of FSO | 200 |
| Efficiencies of optic | 0.8 |
| Receiver diameter of FSO channel | |
| Transmitter divergence of FSO channel () | rad |
| Wavelength of FSO channel | |
| Sensitivity of receiver | 100 photons/bit |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Ai, Y.; Xu, Z.; Wang, J.; Li, J. Adaptive Resource Allocation for Emergency Communications with Unmanned Aerial Vehicle-Assisted Free Space Optical/Radio Frequency Relay System. Photonics 2024, 11, 754. https://doi.org/10.3390/photonics11080754
Lin Y, Ai Y, Xu Z, Wang J, Li J. Adaptive Resource Allocation for Emergency Communications with Unmanned Aerial Vehicle-Assisted Free Space Optical/Radio Frequency Relay System. Photonics. 2024; 11(8):754. https://doi.org/10.3390/photonics11080754
Chicago/Turabian StyleLin, Yuanmo, Yuxun Ai, Zhiyong Xu, Jingyuan Wang, and Jianhua Li. 2024. "Adaptive Resource Allocation for Emergency Communications with Unmanned Aerial Vehicle-Assisted Free Space Optical/Radio Frequency Relay System" Photonics 11, no. 8: 754. https://doi.org/10.3390/photonics11080754