OpenBiodiv: A Knowledge Graph for Literature-Extracted Linked Open Data in Biodiversity Science

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Background
1.2. Working Examples of Biodiversity Data Platforms and Knowledge Management Systems
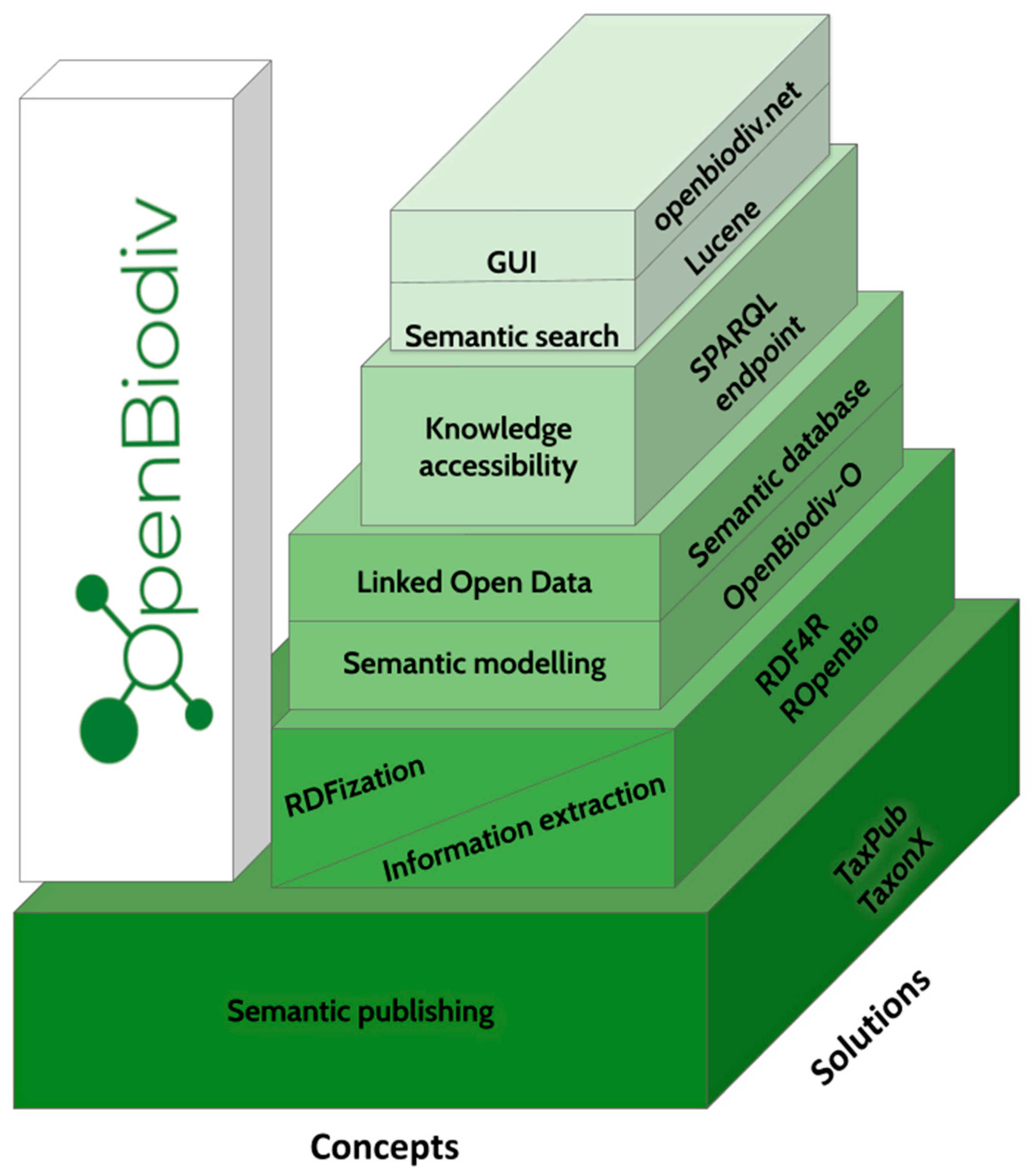
2. Materials and Methods
3. Results
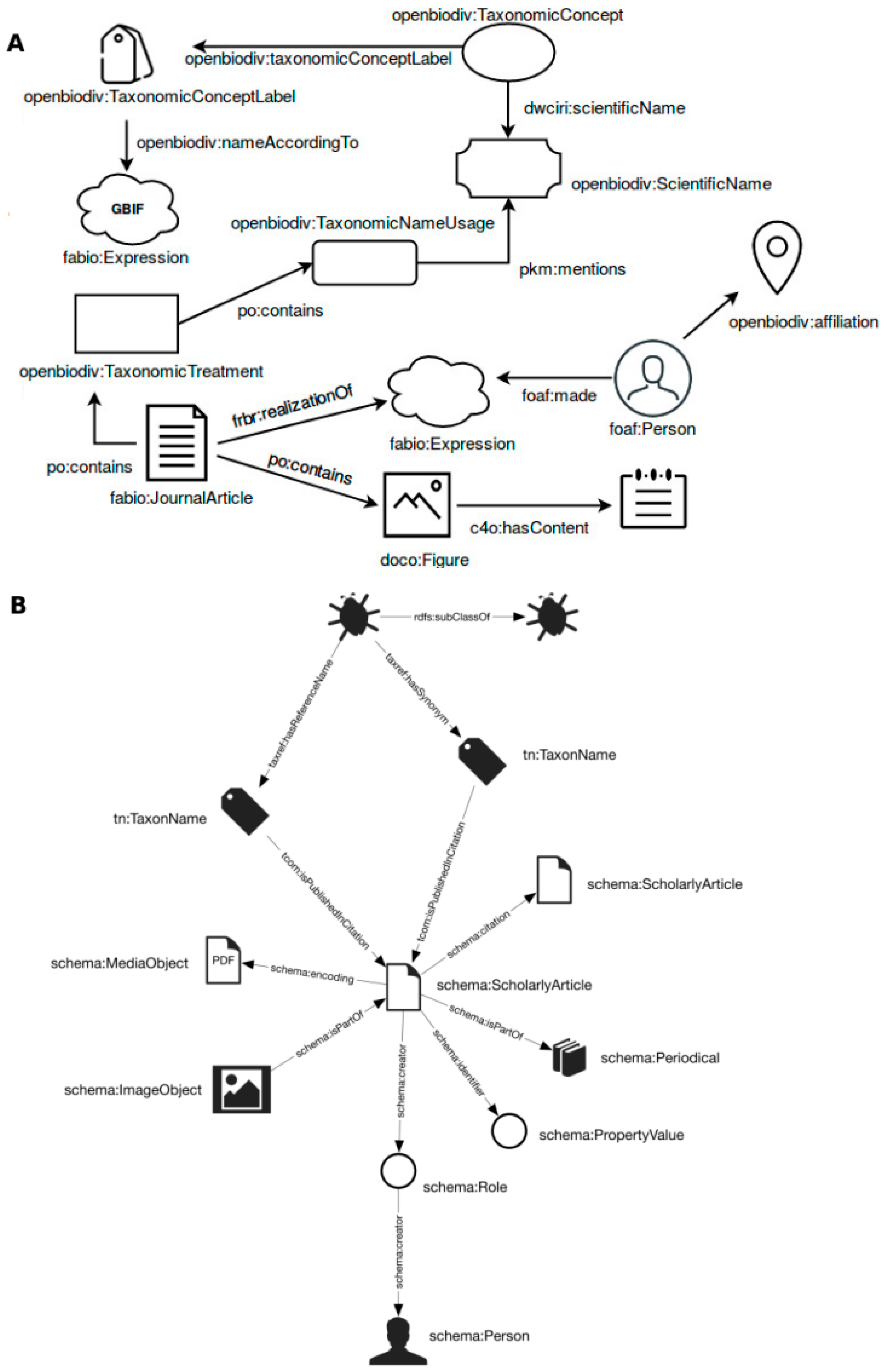
3.1. System Architecture and Data Model
3.2. The OpenBiodiv-O Ontology
3.3. The OpenBiodiv Knowledge Base
3.4. Semantic Search
4. Discussion
4.1. OpenBiodiv as a Major Step towards FAIR Data and Open Science
4.2. Comparison with Other Biodiversity Knowledge Graphs
4.3. Limitations and Future Directions
4.3.1. Reusing and Sharing Identifiers with Other Sources of Biodiversity Knowledge
4.3.2. User Interaction with The Knowledge Graph
4.3.3. Enriching the Knowledge Graph
4.3.4. Disambiguation
5. Conclusions
- OpenBiodiv is at a beta version stage but already provides a working solution to the overarching goal for creating an Open Biodiversity Knowledge Management System based on FAIR Linked Open Data.
- OpenBiodiv serves to liberate and re-use data closed in isolated silos of biodiversity literature, including such available only in PDF.
- OpenBiodiv allows integration of interoperable data from various sources in the biodiversity domain and federation with Linked Open Data from other domains.
- By using open ontology and open source code, the OpenBiodiv-O is expected to catalyze Open Science principles and practices proclaimed in the Bouchout Declaration for biodiversity data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Example SPARQL Query

{kind=link}
{kind=link}
{kind=link}
| PREFIX fabio: <http://purl.org/spar/fabio/> PREFIX prism: <http://prismstandard.org/namespaces/basic/2.0/> PREFIX po: <http://www.essepuntato.it/2008/12/pattern#> PREFIX openbiodiv: <http://openbiodiv.net/> PREFIX pkm: <http://proton.semanticweb.org/protonkm#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> SELECT (COUNT (DISTINCT ?article) AS ?article_number) ?years (GROUP_CONCAT(DISTINCT ?title;SEPARATOR="; ") AS ?titles) WHERE { ?article a fabio:JournalArticle. ?article prism:publicationDate ?date. BIND(REPLACE(STR($date),"(\\d+)-\\d*-\\d*", "$1") AS ?year) FILTER (?year > "2000" && ?year < "2019") ?article po:contains ?tnu. ?article dc:title ?title. ?tnu a openbiodiv:TaxonomicNameUsage. ?tnu pkm:mentions ?scName. ?scName rdfs:label "Eupolybothrus"^^xsd:string. } GROUP BY (xsd:integer(?year) AS ?years) ORDER BY ?years |
References
- Agosti, D.; Egloff, W. Taxonomic information exchange and copyright: The Plazi approach. BMC Res. Notes 2009, 2, 53. [Google Scholar] [CrossRef]
- Sarkar, I.N. Biodiversity informatics: Organizing and linking information across the spectrum of life. Brief. Bioinform. 2007, 8, 347–357. [Google Scholar] [CrossRef]
- Hobern, D.; Baptiste, B.; Copas, K.; Guralnick, R.; Hahn, A.; van Huis, E.; Kim, E.-S.; McGeoch, M.; Naicker, I.; Navarro, L.; et al. Connecting data and expertise: A new alliance for biodiversity knowledge. Biodivers. Data J. 2019, 7, e33679. [Google Scholar] [CrossRef]
- TDWG: History. Available online: http://old.tdwg.org/about-tdwg/history/ (accessed on 19 February 2019).
- What Is GBIF. Available online: https://www.gbif.org/what-is-gbif (accessed on 9 May 2019).
- pro-iBiosphere Consortium. pro-iBiosphere—Project Final Report; Naturalis: Leiden, The Netherlands, 2014; Available online: http://wiki.pro-ibiosphere.eu/w/media/4/46/Pro_iBiosphere_final_report_VFF_05_11_2014.pdf (accessed on 9 May 2019).
- Senderov, V.; Penev, L. The Open Biodiversity Knowledge Management System in Scholarly Publishing. Res. Ideas Outcomes 2016, 2, e7757. [Google Scholar] [CrossRef]
- Bouchout Declaration. Available online: http://www.bouchoutdeclaration.org/declaration/ (accessed on 9 May 2019).
- Egloff, W.; Agosti, D.; Kishor, P.; Patterson, D.; Miller, J.A. Copyright and the Use of Images as Biodiversity Data. Res. Ideas Outcomes 2017, 3, e12502. [Google Scholar] [CrossRef] [Green Version]
- Egloff, W.; Patterson, D.; Agosti, D.; Hagedorn, G. Open exchange of scientific knowledge and European copyright: The case of biodiversity information. ZooKeys 2014, 414, 109–135. [Google Scholar] [CrossRef] [Green Version]
- Guralnick, R.P.; Cellinese, N.; Deck, J.; Pyle, R.L.; Kunze, J.; Penev, L.; Walls, R.; Hagedorn, G.; Agosti, D.; Wieczorek, J.; et al. Community Next Steps for Making Globally Unique Identifiers Work for Biocollections Data. ZooKeys 2015, 494, 133–154. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Miller, J.; Dikow, T.; Agosti, D.; Sautter, G.; Catapano, T.; Penev, L.; Zhang, Z.-Q.; Pentcheff, D.; Pyle, R.; Blum, S.; et al. From taxonomic literature to cybertaxonomic content. BMC Biol. 2012, 10, 87. [Google Scholar] [CrossRef]
- Page, R.D.M. Biodiversity informatics: The challenge of linking data and the role of shared identifiers. Brief. Bioinform. 2008, 9, 345–354. [Google Scholar] [CrossRef]
- Peterson, A.T.; Knapp, S.; Guralnick, R.; Soberón, J.; Holder, M.T. The big questions for biodiversity informatics. Syst. Biodivers. 2010, 8, 159–168. [Google Scholar] [CrossRef] [Green Version]
- Remsen, D. The use and limits of scientific names in biological informatics. ZooKeys 2016, 550, 207–223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patterson, D.J.; Cooper, J.; Kirk, P.M.; Pyle, R.L.; Remsen, D.P. Names are key to the big new biology. Trends Ecol. Evol. 2010, 25, 686–691. [Google Scholar] [CrossRef] [Green Version]
- Lassila, O.; Swick, R.R. Resource Description Framework (RDF) Model and Syntax Specification—W3C Recommendation 22 February 1999. W3C. 1999. Available online: https://www.w3.org/TR/1999/REC-rdf-syntax-19990222/ (accessed on 9 May 2019).
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4825, pp. 722–735. ISBN 978-3-540-76297-3. [Google Scholar]
- Bingham, H.; Weatherdon, L.; Despot-Belmonte, K.; Wetzel, F.; Martin, C. The Biodiversity Informatics Landscape: Elements, Connections and Opportunities. Res. Ideas Outcomes 2017, 3, e14059. [Google Scholar] [CrossRef]
- International Nucleotide Sequence Database Collaboration | INSDC. Available online: http://www.insdc.org/ (accessed on 11 March 2019).
- Ratnasingham, S.; Hebert, P.D.N. Bold: The Barcode of Life Data System (http://www.barcodinglife.org). Mol. Ecol. Notes 2007, 7, 355–364. [Google Scholar] [CrossRef]
- Lepage, D.; Vaidya, G.; Guralnick, R. Avibase—A database system for managing and organizing taxonomic concepts. ZooKeys 2014, 420, 117–135. [Google Scholar] [CrossRef] [PubMed]
- The Diptera Site. Available online: http://diptera.myspecies.info/ (accessed on 19 February 2019).
- Hobern, D.; Apostolico, A.; Arnaud, E.; Bello, J.C.; Canhos, D.; Dubois, G.; Field, D.; Alonso García, E.; Hardisty, A.; Harrison, J.; et al. Global Biodiversity Informatics Outlook: Delivering Biodiversity Knowledge in the Information Age; Global Biodiversity Information Facility: Copenhagen, Denmark, 2012. [Google Scholar] [CrossRef]
- Page, R.D.M. Ozymandias: A biodiversity knowledge graph. PeerJ 2019, 7, e6739. [Google Scholar] [CrossRef]
- Senderov, V.; Georgiev, T.; Agosti, D.; Catapano, T.; Sautter, G.; Tuama, É.Ó.; Franz, N.; Simov, K.; Stoev, P.; Penev, L. OpenBiodiv: An Implementation of a Semantic System Running on top of the Biodiversity Knowledge Graph. Biodivers. Inf. Sci. Stand. 2017, 1, e20084. [Google Scholar] [CrossRef]
- Senderov, V.; Simov, K.; Franz, N.; Stoev, P.; Catapano, T.; Agosti, D.; Sautter, G.; Morris, R.A.; Penev, L. OpenBiodiv-O: Ontology of the OpenBiodiv knowledge management system. J. Biomed. Semant. 2018, 9, 5. [Google Scholar] [CrossRef]
- Wieczorek, J.; Bloom, D.; Guralnick, R.; Blum, S.; Döring, M.; Giovanni, R.; Robertson, T.; Vieglais, D. Darwin Core: An Evolving Community-Developed Biodiversity Data Standard. PLoS ONE 2012, 7, e29715. [Google Scholar] [CrossRef]
- Peroni, S. The semantic publishing and referencing ontologies. In Semantic Web Technologies and Legal Scholarly Publishing; Springer: New York, NY, USA, 2014; Volume 15, pp. 121–193. [Google Scholar]
- Catapano, T. TaxPub: An Extension of the NLM/NCBI Journal Publishing DTD for Taxonomic Descriptions. In Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010; National Center for Biotechnology Information (US): Bethesda, MD, USA, 2010. Available online: https://www.ncbi.nlm.nih.gov/books/NBK47081/ (accessed on 19 February 2019).
- Penev, L.; Georgiev, T.; Geshev, P.; Demirov, S.; Senderov, V.; Kuzmova, I.; Kostadinova, I.; Peneva, S.; Stoev, P. ARPHA-BioDiv: A toolbox for scholarly publication and dissemination of biodiversity data based on the ARPHA Publishing Platform. Res. Ideas Outcomes 2017, 3, e13088. [Google Scholar] [CrossRef]
- Penev, L.; Agosti, D.; Georgiev, T.; Catapano, T.; Miller, J.; Blagoderov, V.; Roberts, D.; Smith, V.; Brake, I.; Ryrcroft, S.; et al. Semantic tagging of and semantic enhancements to systematics papers: ZooKeys working examples. ZooKeys 2010, 50, 1–16. [Google Scholar] [CrossRef]
- Penev, L.; Catapano, T.; Agosti, D.; Georgiev, T.; Sautter, G.; Stoev, P. Implementation of TaxPub, an NLM DTD extension for domain-specific markup in taxonomy, from the experience of a biodiversity publisher. In Journal Article Tag Suite Conference (JATS-Con) Proceedings 2012; National Center for Biotechnology Information (US): Bethesda, MD, USA, 2012. Available online: https://www.ncbi.nlm.nih.gov/books/NBK100351/ (accessed on 20 February 2019).
- Penev, L.; Lyal, C.H.C.; Weitzman, A.; Morse, D.; King, D.; Sautter, G.; Georgiev, T.A.; Morris, R.A.; Catapano, T.; Agosti, D. XML schemas and mark-up practices of taxonomic literature. ZooKeys 2011, 150, 89–116. [Google Scholar] [CrossRef] [Green Version]
- RDF4R: R Library for Working with RDF. Available online: https://github.com/pensoft/rdf4r (accessed on 9 May 2019).
- ropenbio. Available online: https://github.com/pensoft/ropenbio (accessed on 9 May 2019).
- GBIF Secretariat. GBIF Backbone Taxonomy. Checklist Dataset. 2017. Available online: https://doi.org/10.15468/39omei (accessed on 9 May 2019).
- OpenBiodiv. Available online: https://github.com/pensoft/OpenBiodiv (accessed on 9 May 2019).
- Ontotext GraphDB 8.8. Available online: http://graphdb.ontotext.com/ (accessed on 15 February 2019).
- GraphDB Workbench. Available online: http://graph.openbiodiv.net/ (accessed on 19 February 2019).
- OpenBiodiv—The Open Biodiversity Knowledge Management System. Available online: http://openbiodiv.net/ (accessed on 19 February 2019).
- TaxonX. Available online: https://sourceforge.net/projects/taxonx/ (accessed on 15 February 2019).
- Pensoft Publishers. Plazi Automated Biodiversity Data Mining Workflow (Image). Available online: https://media.eurekalert.org/multimedia_prod/pub/web/164542_web.jpg (accessed on 19 February 2019).
- Janowicz, K.; Hitzler, P.; Adams, B.; Kolas, D.; Vardeman, C. Five stars of Linked Data vocabulary use. Semant. Web 2014, 5, 173–176. [Google Scholar] [Green Version]
- Bénichou, L.; Gérard, I.; Laureys, É.; Price, M. Consortium of European Taxonomic Facilities (CETAF) best practices in electronic publishing in taxonomy. Eur. J. Taxon. 2018, 475, 1–37. [Google Scholar] [CrossRef]
- Authors Guidelines. Available online: https://zookeys.pensoft.net/about#AuthorsGuidelines (accessed on 9 May 2019).



| Entity Type | Comment | Ontology Source |
|---|---|---|
| Journal Article | A scientific article | http://purl.org/spar/fabio |
| Article Title | The title of an article | http://purl.org/dc/elements/1.1/ |
| Digital Object Identifier (DOI) | The DOI of an article | http://prismstandard.org/namespaces/basic/2.0/ |
| Introduction | The Introduction section of an article | http://www.sparontologies.net/ontologies/deo |
| Author Name | The name of an article author | http://xmlns.com/foaf/0.1/ |
| Treatment | Section of a taxonomic article | http://openbiodiv.net/ontology |
| Nomenclature Section | Subsection of Treatment | http://openbiodiv.net/ontology |
| Nomenclature Citation List | List of citations of related concepts | http://openbiodiv.net/ontology |
| Materials Examined | List of examined specimens | http://openbiodiv.net/ontology |
| Biology Section | Subsection of Treatment | http://openbiodiv.net/ontology |
| Description Section | Subsection of Treatment | http://openbiodiv.net/ontology |
| Taxonomic Key | Section with an identification key | http://openbiodiv.net/ontology |
| Taxonomic Checklist | Section with a list of taxa for a region | http://openbiodiv.net/ontology |
| Taxonomic Name Usage | Mention of a taxonomic name | http://openbiodiv.net/ontology |
| Taxonomic Concept | Contextualized use of a taxonomic name, including a literature source | http://openbiodiv.net/ontology |
| OpenBiodiv | Ozymandias | |
|---|---|---|
| Year of launch of a prototype | 2016 (TDWG 2016) [27] | 2018 (Ebbe Nielsen Challenge 2018) [26] |
| Ontology used | OpenBiodiv-O | schema.org, TAXREF, TDWG LSID |
| Main resource types | Journal, Article, Article metadata, Article sections, Figure legend, Taxonomic treatment, Taxonomic treatment subsections, Taxonomic concept, Taxonomic name usage | Journal, Article, Article metadata, Figure, Taxonomic name, Taxonomic concept |
| Taxonomic classification | GBIF | Atlas of Living Australia (ALA) |
| Reconciliation of authors and publications | In progress | CrossRef, ORCID, Wikispecies, Biostor |
| Additional identifier cross-linking | - | Wikidata, GBIF |
| Figures | Figure legends from taxonomic publications and treatments | Biodiversity Literature Repository |
| Number of entity instances | ||
| Journals | 35 | 6210 |
| Journal articles | 24,212 | 68,217 |
| Authors | 38,800 | 32,548 |
| Scientific names | 6,704,000 (extracted from literature) 5,798,686 (imported from GBIF) | 444,222 |
| Question | Target User Groups | Value |
|---|---|---|
| Are there any articles mentioning the scientific name X and how many are there? | Taxonomists, ecologists and practitioners | Evaluation of the current state of research of taxon name X |
| Which specimens from a certain collection have been used/cited in publications and which are these publications? | Natural history collection managers and administrators; taxonomists | Tracking usage of collection material of particular value (holotypes, type series, extinct taxa, other material) |
| Which taxon treatments (or other general article sections) mention both scientific name X and Y? | Taxonomists, ecologists | Identification of taxa that are potentially related |
| How many articles about taxon X has a given researcher written in the past 10 years? | Research institutions, funding bodies, biodiversity researchers | Evaluation of a scientist’s research impact and expertise (e.g., during the grant proposal writing process) |
| How many articles about a taxon X are published over a certain period of time? | Research institutions, funding bodies, ecological organizations, biodiversity researchers | Identification of poorly known species to evaluate the need for funding and conducting research; facilitation of literature discovery and research |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Penev, L.; Dimitrova, M.; Senderov, V.; Zhelezov, G.; Georgiev, T.; Stoev, P.; Simov, K. OpenBiodiv: A Knowledge Graph for Literature-Extracted Linked Open Data in Biodiversity Science. Publications 2019, 7, 38. https://doi.org/10.3390/publications7020038
Penev L, Dimitrova M, Senderov V, Zhelezov G, Georgiev T, Stoev P, Simov K. OpenBiodiv: A Knowledge Graph for Literature-Extracted Linked Open Data in Biodiversity Science. Publications. 2019; 7(2):38. https://doi.org/10.3390/publications7020038
Chicago/Turabian StylePenev, Lyubomir, Mariya Dimitrova, Viktor Senderov, Georgi Zhelezov, Teodor Georgiev, Pavel Stoev, and Kiril Simov. 2019. "OpenBiodiv: A Knowledge Graph for Literature-Extracted Linked Open Data in Biodiversity Science" Publications 7, no. 2: 38. https://doi.org/10.3390/publications7020038
APA StylePenev, L., Dimitrova, M., Senderov, V., Zhelezov, G., Georgiev, T., Stoev, P., & Simov, K. (2019). OpenBiodiv: A Knowledge Graph for Literature-Extracted Linked Open Data in Biodiversity Science. Publications, 7(2), 38. https://doi.org/10.3390/publications7020038