
PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision


Abstract
:1. Introduction
2. Pesticide Methods
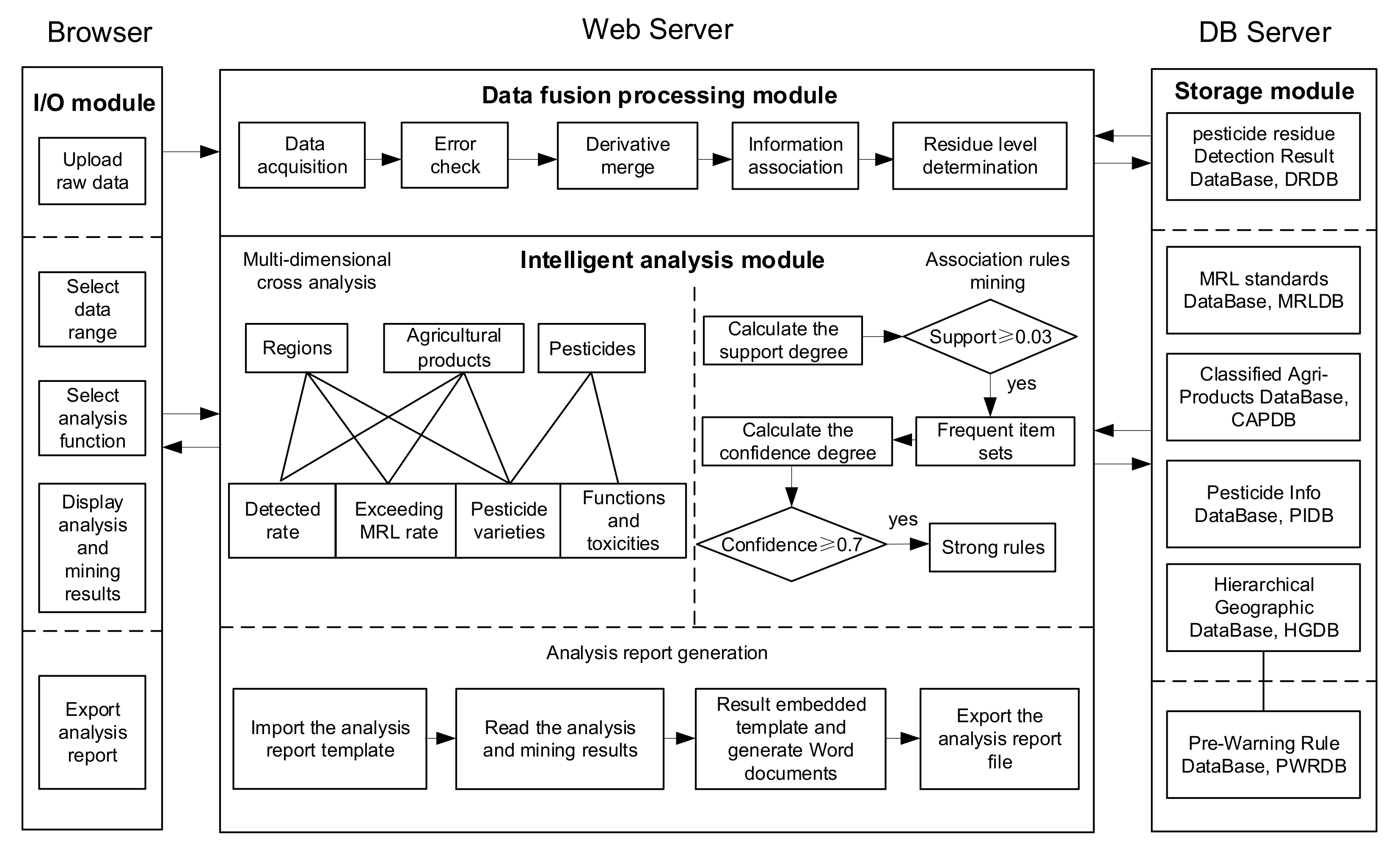
2.1. PRIAS Framework
2.2. Database Design
- (1)
- The detection results mainly include sampling time, sampling point, sample name, and the name and content of the pesticide detected.
- (2)
- Pesticide information includes pesticide name, chemical composition, function, toxicity, and derivative. Among them, the chemical composition includes organochlorine, organophosphorus, carbamate, pyrethroid, organic nitrogen, or organic sulfur pesticide. The function includes insecticides, fungicides, herbicides, and plant growth regulators. Toxicity can be low, medium, high, or severe.
- (3)
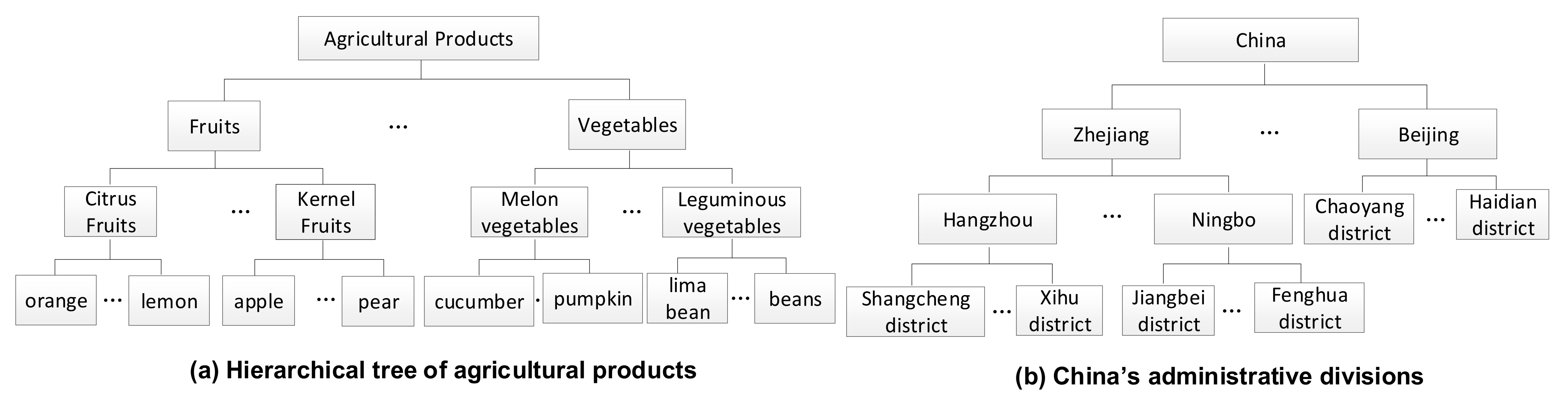
- The classification of agricultural products is organized in a hierarchical structure, as shown in Figure 2a, and includes primary, secondary, and tertiary categories. The primary classification can take the values of fruits, vegetables, and so on. The secondary classification can be citrus fruits, melon vegetables, and so on. The tertiary classification can take the values of orange, cucumber, and so on.
- (4)
- Sampling points are usually supermarkets or farmers’ markets. The geographical areas (China) to which they belong are also organized in a hierarchy, including geographic regions (e.g., East China and North China), provinces level (e.g., Zhejiang and Beijing), cities (e.g., Hangzhou and Zhangjiakou), and counties (e.g., Shangcheng and Xihu), as shown in Figure 2b.
- (5)
- The MRL standard specifies the maximum limit of each pesticide in specific agricultural products, which is the basis for determining the residue level. It mainly involves the names of pesticides, agricultural products, and limit values.
- (6)
- The pre-warning rules are the results obtained after mining pesticide residue data through association rules, including rule’s antecedent items, rule’s subsequent items, support, and confidence. The item set includes information on agricultural products, sampling area, detected pesticides, the chemical composition of detected pesticides, the toxicity of detected pesticides, and function of detected pesticides.
2.3. Data Fusion Processing
2.4. Statistical Analysis and Association Rule Mining
2.4.1. Statistics and Comparative Analysis
2.4.2. Association Rule Mining
2.5. Automatic Report Generation
3. Application Case
- (1)
- Data fusion and preprocess
- (2)
- Statistical analysis
- (3)
- Association rule mining
- (4)
- Automatic generation of result analysis report
4. Result and Discussion
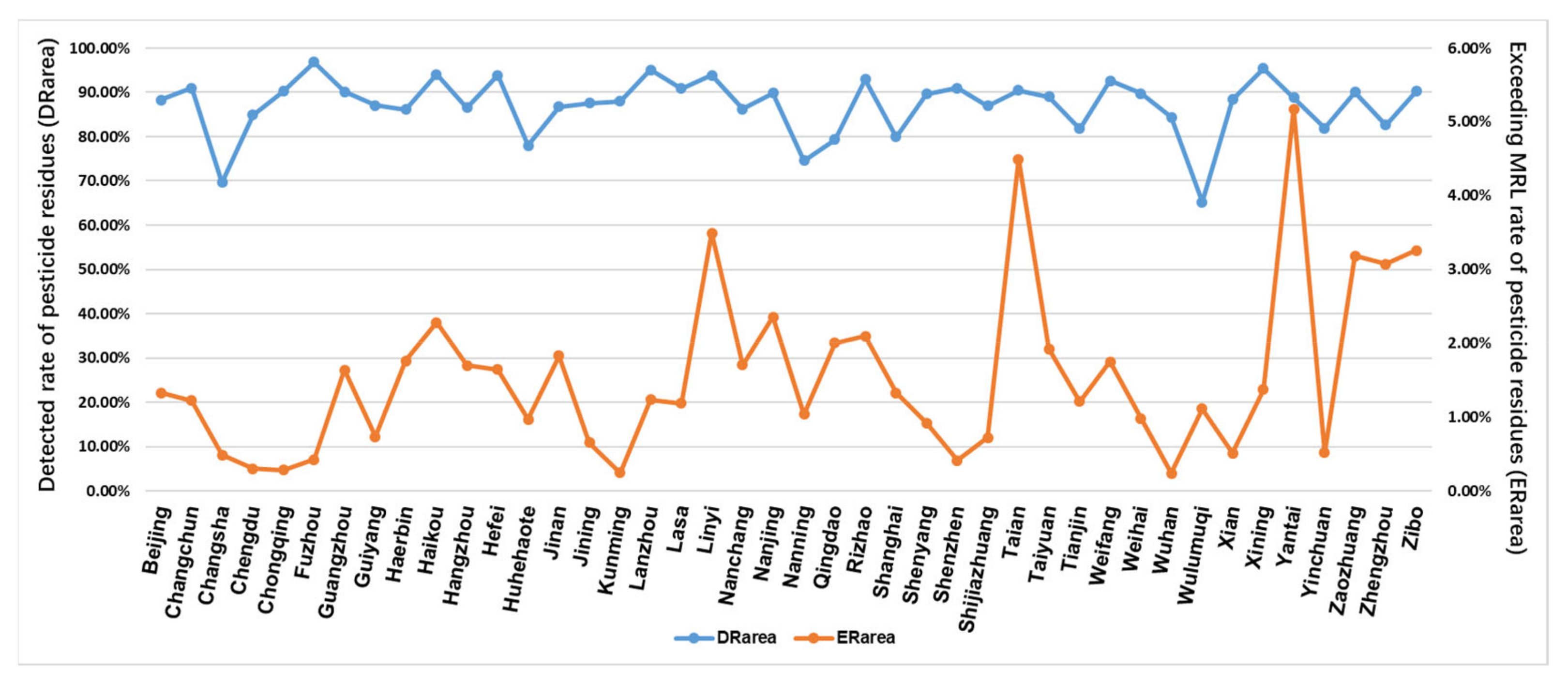
4.1. Statistics from the Perspective of Sampling Area
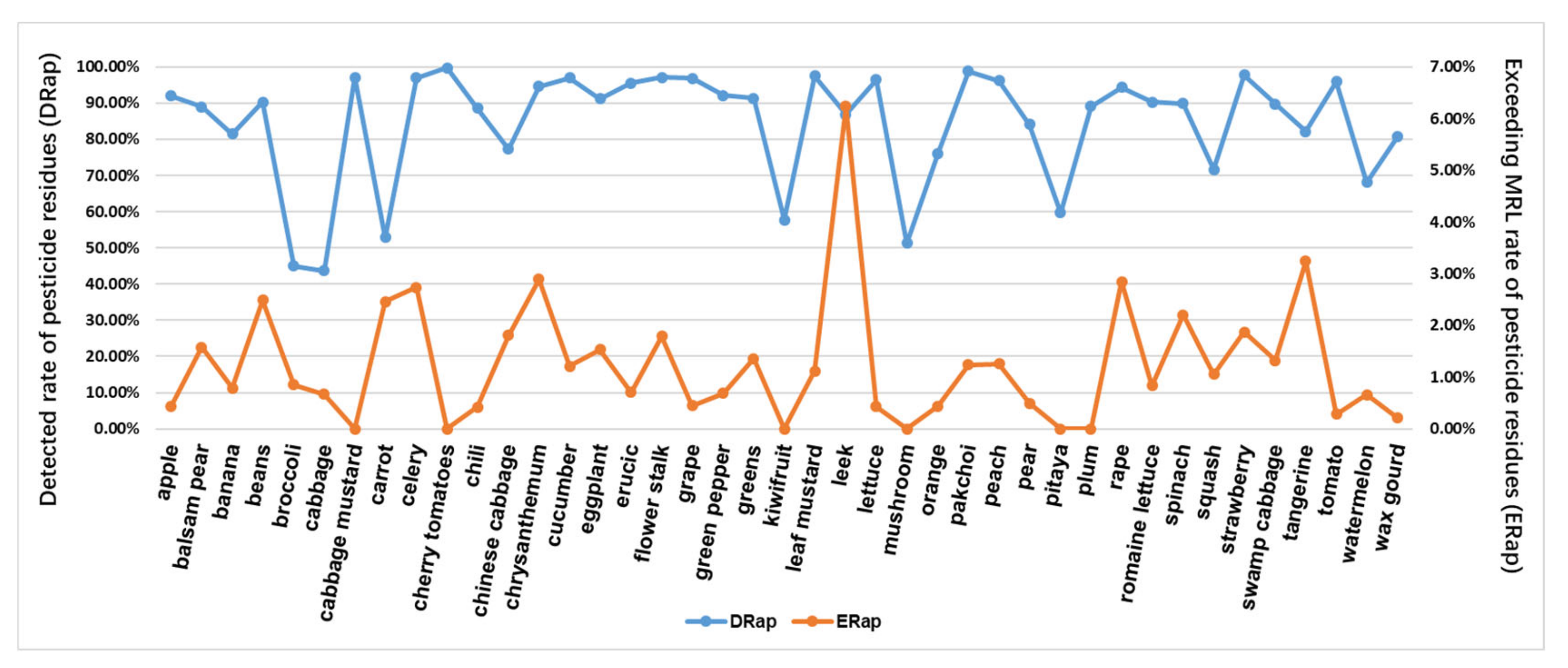
4.2. Statistics from the Perspective of Agricultural Products
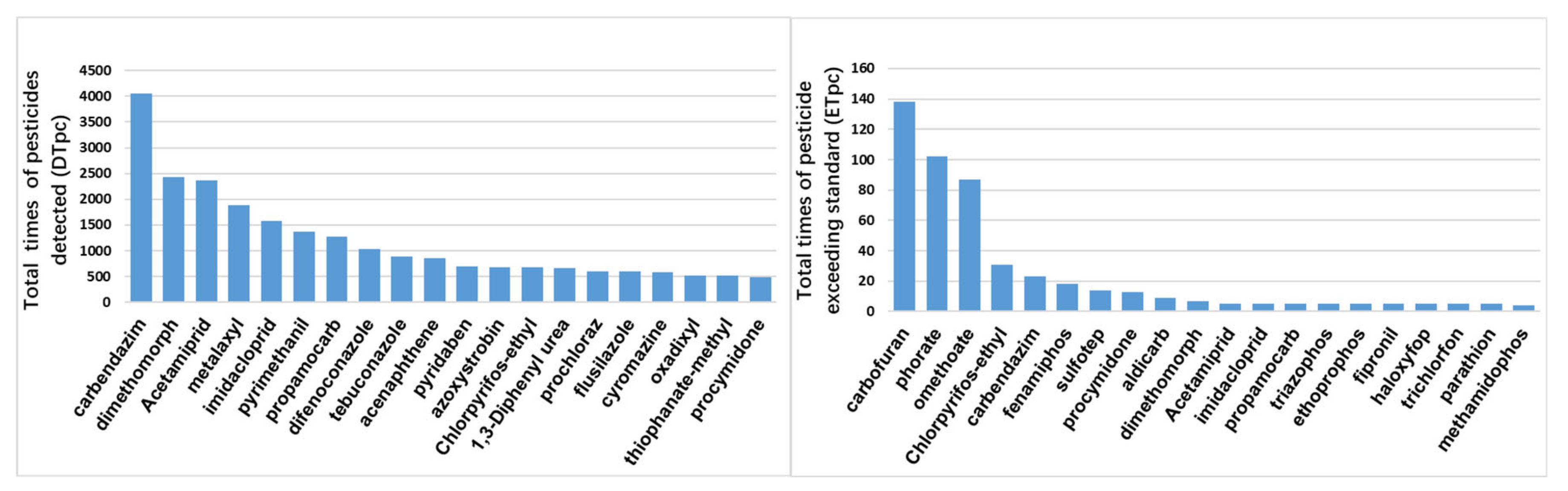
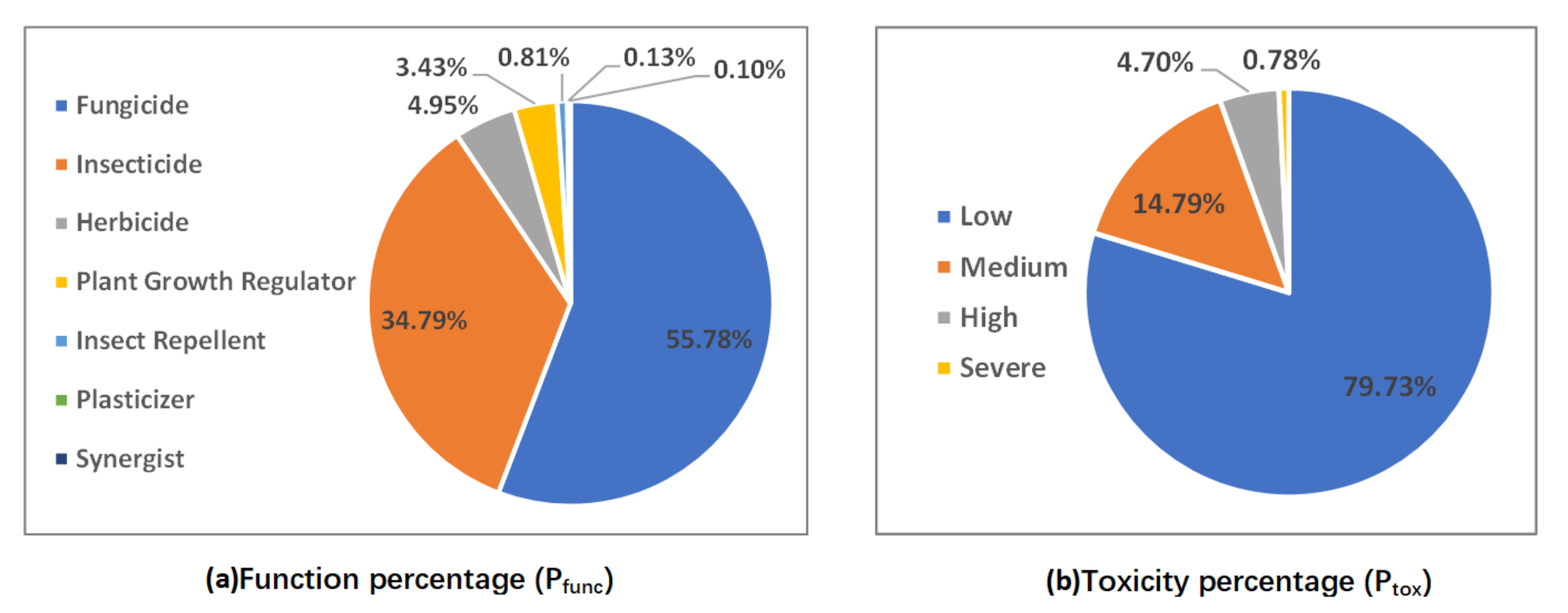
4.3. Statistics from the Perspective of Pesticides
4.4. Association Rule Mining
4.5. Discussion
- (1)
- Aggregation and accumulation of pesticide residue detection data
- (2)
- Pesticide residue distribution characteristics and potential risk discovery
- (3)
- Automatic generation of sampling analysis reports
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carvalho, F.P. Pesticides, environment, and food safety. Food Energy Secur. 2017, 6, 48–60. [Google Scholar] [CrossRef]
- Settimi, L.; Orford, R.; Davanzo, F.; Hague, C.; Desel, H.; Pelclova, D.; Dragelyte, G.; Mathieu-Nolf, M.; Adams, R.; Duarte-Davidson, R. Development of a new categorization system for pesticides exposure to support harmonized reporting between EU Member States. Environ. Int. 2016, 91, 332–340. [Google Scholar] [CrossRef] [PubMed]
- Winter, C.K. Chronic dietary exposure to pesticide residues in the United States. Food Contam. 2015, 2, 11–12. [Google Scholar] [CrossRef] [Green Version]
- Poulsen, M.E.; Andersen, J.H.; Petersen, A.; Jensen, B.H. Results from the Danish monitoring programme for pesticide residues from the period 2004–2011. Food Control 2016, 74, 25–33. [Google Scholar] [CrossRef] [Green Version]
- U.S. Food & Drug Administration. Pesticide Residue Monitoring Program Reports and Data. 2020. Available online: https://www.fda.gov/food/pesticides/pesticide-residue-monitoring-program-reports-and-data (accessed on 20 December 2021).
- European Food Safety Authority. The 2016 European Union report on pesticide residues in food. EFSA J. 2018, 16, 5348. [Google Scholar] [CrossRef] [Green Version]
- State Administration for Market Regulation. Food Safety Spot Check Announcement Result Inquiry System 2020. Available online: https://spcjsac.gsxt.gov.cn/ (accessed on 25 December 2021).
- Wu, Y.N.; Chen, J.S. Food safety monitoring and surveillance in China: Past, present and future. Food Control 2018, 90, 429–439. [Google Scholar] [CrossRef]
- Liu, S.Z.; Liao, Y.D.; Zhong, X.J.; Lu, J.H.; Lin, S.D.; Guo, S.Z.; Lai, X.T.; Yu, Q.F. Analysis and application of field detection technology of pesticide residues. J. Food Saf. Qual. 2019, 10, 5378–5392. [Google Scholar] [CrossRef]
- Li, Q.; Li, J.H. Rapid detection methods for pesticide residues in agricultural products. Agric. Dev. Equip. 2018, 02, 84. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Yan, K.T.; Wang, L.L.; Chen, P.C.; Han, Y.F.; Lan, Y.B. Research progress of pesticide residue detection based on fluorescence spectrum analysis. Spectrosc. Spectr. Anal. 2021, 41, 2364–2371. [Google Scholar] [CrossRef]
- Xu, M.L.; Gao, Y.; Han, X.X.; Zhao, B. Detection of pesticide residues in food using surface-enhanced raman spectroscopy: A review. J. Agric. Food Chem. 2017, 65, 6719–6762. [Google Scholar] [CrossRef]
- Jiang, Y.; Sun, D.W.; Pu, H.; Wei, Q.Y. Surface enhanced Raman spectroscopy (SERS): A novel reliable technique for rapid detection of common harmful chemical residues. Trends Food Sci. Technol. 2018, 75, 10–22. [Google Scholar] [CrossRef]
- Almeida, M.O.; Oloris, S.C.S.; Faria, V.H.F.; Ribeiro, M.C.M.; Cantini, D.M.; Soto-Blanco, B. Optimization of method for pesticide detection in honey by using liquid and gas chromatography coupled with mass spectrometric detection. Foods 2020, 9, 1368. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Dong, Y.; Sun, Y.H.; Liang, J. A multi-comparable visual analytic approach for complex hierarchical data. J. Vis. Lang. Comput. 2018, 47, 19–30. [Google Scholar] [CrossRef]
- Marvin, H.J.; Janssen, E.M.; Bouzembrak, Y.; Hendriksen, P.J.; Staats, M. Big data in food safety: An overview. Crit. Rev. Food Sci. Nutr. 2018, 57, 2286–2295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Lv, C.; Li, Y.; Chen, W.; Ma, K.L. Ordered matrix representation supporting the visual analysis of associated data. Sci. China Inf. Sci. 2020, 63, 184101. [Google Scholar] [CrossRef]
- Jin, C.; Bouzembrak, Y.; Zhou, J.; Liang, Q.; van den Bulk, L.M.; Gavai, A.; Liu, N.; van den Heuvel, L.J.; Hoenderdaal, W.; Marvin, H.J. Big Data in food safety—A review. Curr. Opin. Food Sci. 2020, 36, 24–32. [Google Scholar] [CrossRef]
- Jin, C.Y.; Bouzembrak, Y.; Zhou, J.; Liang, Q.; van den Bulk, L.M.; Gavai, A.; Liu, N.J.; van den Heuvel, L.J.; Hoenderdaal, W.; Marvin, H.J.P. Global research trends in food safety in agriculture and industry from 1991 to 2018: A data-driven analysis. Trends Food Sci. Technol. 2019, 85, 262–276. [Google Scholar] [CrossRef]
- Garre, A.; Boue, G.; Fernandez, P.S.; Membre, J.M.; Egea, J.A. Evaluation of multicriteria decision analysis algorithms in food safety: A case study on emerging zoonoses prioritization. Risk Anal. 2020, 40, 336–351. [Google Scholar] [CrossRef]
- Panghal, A.; Chhikara, N.; Sindhu, N.; Jaglan, S. Role of food safety management systems in safe food production: A review. J. Food Saf. 2018, 38, e12464. [Google Scholar] [CrossRef]
- Kuuliala, L.; Abatih, E.; Ioannidis, A.; Vanderroost, M.; De Meulenaer, B.; Ragaert, P.; Devlieghere, F. Multivariate statistical analysis for the identification of potential seafood spoilage indicators. Food Control 2018, 84, 49–60. [Google Scholar] [CrossRef] [Green Version]
- Al-Shamary, N.M.; Al-Ghouti, M.A.; Al-Shaikh, I.; Al-Meer, S.H.; Ahmad, T.A. Evaluation of pesticide residues of organochlorine in vegetables and fruits in Qatar: Statistical analysis. Environ. Monit. Assess. 2016, 188, 14. [Google Scholar] [CrossRef] [PubMed]
- Szarka, A.Z.; Hayworth, C.G.; Ramanarayanan, T.S.; Joseph, R.S. Statistical techniques to analyze pesticide data program food residue observations. J. Agric. Food Chem. 2018, 66, 7165–7171. [Google Scholar] [CrossRef] [PubMed]
- Muangprathub, J.; Boonnam, N.; Kajornkasirat, S.; Lekbangpong, N.; Wanichsombat, A.; Nillaor, P. IoT and agriculture data analysis for smart farm. Comput. Electron. Agric. 2019, 156, 467–474. [Google Scholar] [CrossRef]
- Wang, J.; Yue, H. Food safety pre-warning system based on data mining for a sustainable food supply chain. Food Control 2017, 73, 223–229. [Google Scholar] [CrossRef]
- Rong, C.; Liu, Z.; Huo, N.; Sun, H. Exploring Chinese dietary habits using recipes extracted from websites. IEEE Access 2019, 7, 24354–24361. [Google Scholar] [CrossRef]
- Mcmeekin, T.A.; Baranyi, J.; Bowman, J.; Dalgaard, P.; Kirk, M.; Ross, T.; Schmid, S.; Zwietering, M.H. Information systems in food safety management. Int. J. Food Microbiol. 2006, 112, 181–194. [Google Scholar] [CrossRef]
- Kote, D. Increasing food safety through the use of information technology. Eur. J. Eng. Res. Sci. 2018, 3, 35. [Google Scholar] [CrossRef]
- Yoo, C.W.; Parameswaran, S.; Kishore, R. Knowing about your food from the farm to the table: Using information systems that reduce information asymmetry and health risks in retail contexts. Inf. Manag. 2015, 52, 692–709. [Google Scholar] [CrossRef]
- National Health and Family Planning Commission of PRC & The Ministry of Agriculture of the People’s Republic of China. National Food Safety Standard-Maximum Residue Limits for Pesticides in Food; Standards Press: Beijing, China, 2014. [Google Scholar]
- Li, Y.; Zhang, J.; Li, T.; Liu, H.G.; Li, J.Q.; Wang, Y.Z. Geographical traceability of wild boletus edulis based on data fusion of FT-MIR and ICP-AES coupled with data mining methods (SVM). Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2017, 177, 20–27. [Google Scholar] [CrossRef]
- Cheng, Y.; Ying, X. Research and improvement of apriori algorithm for association rules. In Proceedings of the 2010 2nd International Workshop on Intelligent Systems and Applications, Wuhan, China, 22–23 May 2010. [Google Scholar] [CrossRef]
- Benatia, M.A.; Baudry, D.; Louis, A. Detecting counterfeit products by means of frequent pattern mining. J. Ambient Intell. Humaniz. Comput. 2020; in press. [Google Scholar] [CrossRef]
- Pang, G.F.; Shen, S.G.; Chang, Q.Y.; Liang, S.X.; Xu, J.Z.; Fan, C.L.; Bai, R.B.; Cao, Y.Z.; Chen, H.; Chen, Y.; et al. Research on Monitoring, Risk Assessment and Traceability Technology of Pesticide Residues in Edible Agricultural Products; Science Press: Beijing, China, 2018; pp. 1–73. [Google Scholar]
- Al-Marshadi, A.H.; Aslam, M. Statistical analysis for food quality in the presence of vague information. J. Food Qual. 2021, 2021, 5. [Google Scholar] [CrossRef]
- Aslam, M.; Albassam, M. Application of neutrosophic logic to evaluate correlation between prostate cancer mortality and dietary fat assumption. Symmetry 2019, 11, 330. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Result Database | MRL Standard Database | Pesticide Info Database | Classified Agri-Product Database | Hierarchical Geographic Database | Pre-Warning Rule Database |
|---|---|---|---|---|---|
| Sampling time | Pesticide name | Pesticide name | Sample name | Sampling point | Antecedent of the rule |
| Sampling point | Agri-product or category | CAS ID | Primary level category | Geographical region | Subsequent of the rule |
| Sample name | MRL value | Composition | Secondary level category | Provincial level | Support |
| Pesticide name | Effective time | Function | Tertiary level category | Prefecture level | Confidence |
| Content of residue | Expiration time | level | Create time |
| Residue Level | Condition | |
|---|---|---|
| Qualified | Not detected | c 1 = 0 |
| Level 1 | 0 ≤ c ≤ 0.1 × MRL | |
| Level 2 | 0.1 × MRL ≤ c ≤ 1 × MRL | |
| Unqualified | Level 3 | c ≥ 1 × MRL |
| Aspect | Statistical Indicators | Calculation Methods | Variable Description |
|---|---|---|---|
| Sampling area | (I) , the pesticide residue detection rate in each sampling area; (II) , the pesticide residue exceeding the MRL rate in each sampling area. | (1) (2) (3) (4) | is the in the th sampling area; is the in the th sampling area; is the th pesticide content detection value in the th sampling area; is the total detection frequency of the th sampling area; = 1,2,3, …, (Total of areas were sampled). |
| Agricultural Products | (III), the pesticide residues detection rate in various agricultural products; (IV), the pesticide residue exceeding the MRL rate in various agricultural products. | (5) (6) | is the of the th agricultural product. is the of the th agricultural product. and are obtained from Equations (3) and (4), respectively, where is the th pesticide content detection value of the th agricultural product. is the total detection frequency of the th agricultural product. = 1,2,3, …, (the total of agricultural products detected). |
| Pesticides | (V) , the total frequency of various pesticides detected; (VI) , the total frequency of exceeding MRL. | (7) (8) | is the of the th pesticide. is the of the th pesticide. and are obtained from Equations (3) and (4), respectively, where is the pesticide content detection value of the th pesticide at the th time. = 1,2,3, …, (Total of times were detected). |
| (VII) , percentage of pesticides detected belonging to each function; (VIII) , percentage of pesticides detected belonging to each toxicity level. | (9) (10) | is the of the th function. is the of the th toxicity level. is the number of pesticide species belonging to the th function, = 1,2,3, ..., ( functions of the detected pesticides are considered). is the number of pesticide species belonging to the th toxicity level, = 1,2,3, ..., ( toxicity levels of the pesticides detected are considered). is the number of pesticide species. |
| Sampling Time | Agricultural Product Name | Sampling Area | Pesticide Name | … | Content of Residue (µg/kg) | MRL (µg/kg) |
|---|---|---|---|---|---|---|
| 2015-03-08 | apple | Tianjin | etofenprox | … | 0.0052 | 0.6 |
| 2014-03-11 | leek | Xining | terbufos | … | 0.0023 | 0.01 |
| 2013-08-06 | potato | Shenyang | pharate | … | 0.0013 | 0.01 |
| 2012-07-30 | cucumber | Beijing | metalaxyl | … | 0.001 | 0.5 |
| 2012-07-30 | apple | Beijing | pyrimethanil | … | 0.001 | 7 |
| No. | Sampling Area | Agricultural Product | Pesticide | Chemical Composition | Toxicity Level | Function |
|---|---|---|---|---|---|---|
| 1 | Haerbing | celery | nitrofen | organochlorine | low | Herbicide |
| 2 | Changsha | carrot | phorate | organophosphorus | severe | Insecticide |
| 3 | Changsha | celery | carbofuran | carbamates | high | Insecticide |
| 4 | Beijing | strawberry | dimethomorph | organic nitrogen | low | Fungicide |
| 5 | Beijing | leek | carbendazim | organic nitrogen | low | Fungicide |
| 6 | Hefei | romaine lettuce | daminozide | other | low | Plant growth regulator |
| No. | Rule | Support | Confidence |
|---|---|---|---|
| 1 | Sampling area = Zhengzhou + toxicity = high function = insecticide | 0.06 | 1.0 |
| 2 | Chemical component = Carbamates + agricultural product = beens function = insecticide + toxicity = high | 0.06 | 1.0 |
| 3 | Toxicity = severe + agricultural product = celery function = insecticide | 0.049 | 1.0 |
| 4 | Toxicity = severe + agricultural product = leek function = insecticide | 0.042 | 1.0 |
| 5 | Agricultural product = carrot pestcide = phorate + sampling area = Guangzhou | 0.035 | 0.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Dou, H.; Chang, Q.; Fan, C. PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision. Foods 2022, 11, 780. https://doi.org/10.3390/foods11060780
Chen Y, Dou H, Chang Q, Fan C. PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision. Foods. 2022; 11(6):780. https://doi.org/10.3390/foods11060780
Chicago/Turabian StyleChen, Yi, Haifeng Dou, Qiaoying Chang, and Chunlin Fan. 2022. "PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision" Foods 11, no. 6: 780. https://doi.org/10.3390/foods11060780
APA StyleChen, Y., Dou, H., Chang, Q., & Fan, C. (2022). PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision. Foods, 11(6), 780. https://doi.org/10.3390/foods11060780