
Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Fermentation Materials and Sample Collection
2.2. Device Requirement
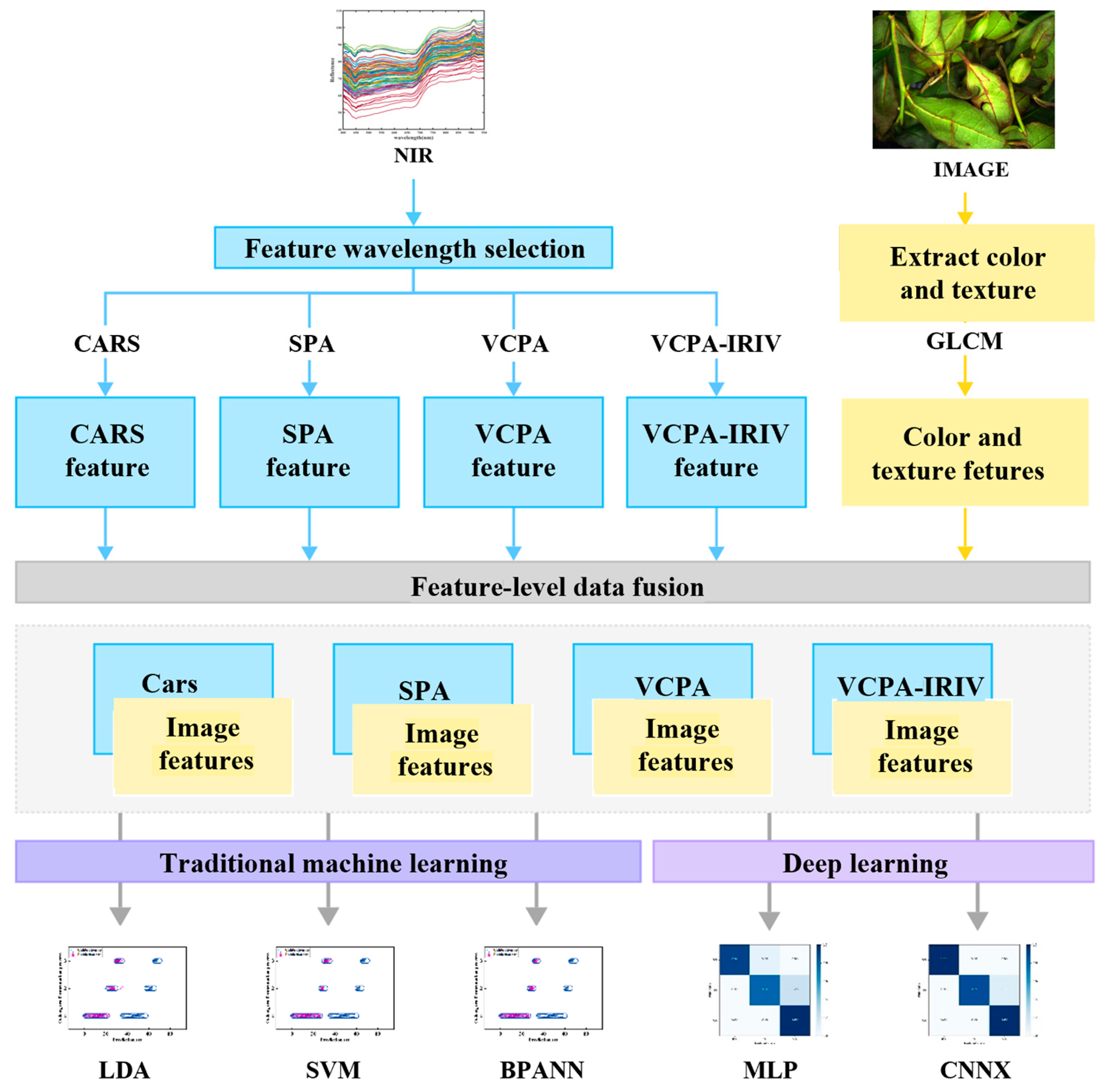
2.3. Acquisition of Spectral and Image Signals
2.4. Image Feature Extraction
2.5. Spectral Feature Extraction
2.5.1. Spectral Preprocessing
2.5.2. Spectral Feature Screening
2.6. Data Fusion
2.7. Identification Models for Determining the Fermentation Degree of Oolong Tea
2.7.1. Three Traditional Machine Learning Models
2.7.2. Two Deep Learning Models
2.7.3. Model Evaluation Index
3. Results and Discussions
3.1. Device Construction
3.2. Image Feature Extraction Results
3.3. VIS-NIR Spectral Feature Screening Results
3.3.1. VIS-NIR Analysis
3.3.2. Feature Wavelength Screening
3.4. Results of Judging the Fermentation Degree of Oolong Tea
3.4.1. Classification Models and Dataset Partitioning
3.4.2. Single-Sensor Model Analysis
3.4.3. Applying Three Traditional Machine Learning Algorithms on the Fusion Data Modeling Results
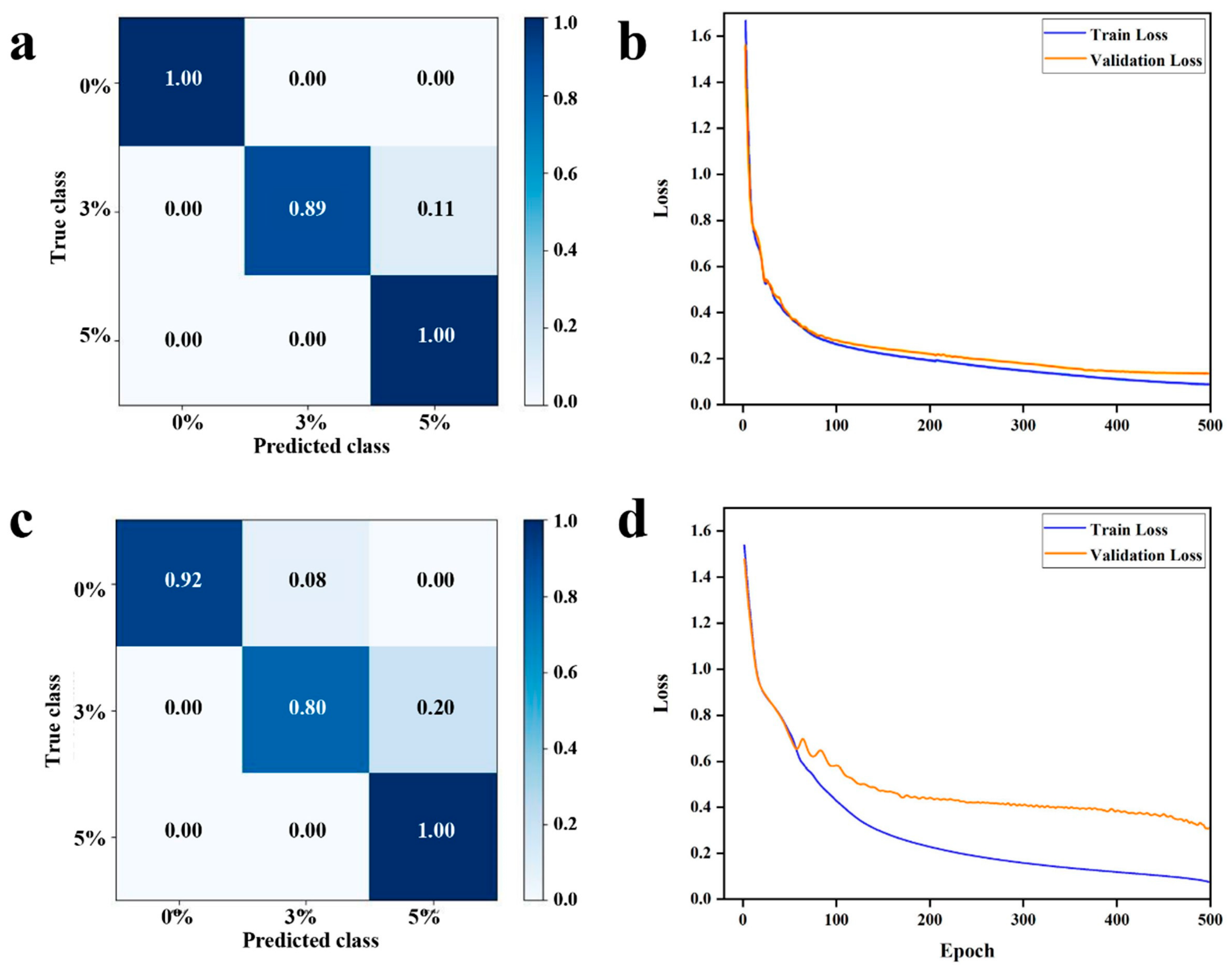
3.4.4. Results of Deep Learning Modeling
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ng, K.-W.; Cao, Z.-J.; Chen, H.-B.; Zhao, Z.-Z.; Zhu, L.; Yi, T. Oolong tea: A critical review of processing methods, chemical composition, health effects, and risk. Crit. Rev. Food Sci. Nutr. 2017, 58, 2957–2980. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Yu, W.; Zhou, L.; Fan, X.; Wang, F.; Wang, P.; Fang, W.; Cai, C.; Ye, N. Genetic diversity of oolong tea (Camellia sinensis) germplasms based on the nanofluidic array of single-nucleotide polymorphism (SNP) markers. Tree Genet. Genomes 2019, 16, 3. [Google Scholar] [CrossRef]
- Xu, Y.-Q.; Liu, P.-P.; Shi, J.; Gao, Y.; Wang, Q.-S.; Yin, J.-F. Quality development and main chemical components of Tieguanyin oolong teas processed from different parts of fresh shoots. Food Chem. 2018, 249, 176–183. [Google Scholar] [CrossRef] [PubMed]
- Theppakorn, T. Stability and chemical changes of phenolic compounds during Oolong tea processing. Int. Food Res. J. 2016, 23, 564. [Google Scholar]
- Li, L.; Wang, Y.; Cui, Q.; Liu, Y.; Ning, J.; Zhang, Z. Qualitative and quantitative quality evaluation of black tea fermentation through noncontact chemical imaging. J. Food Compos. Anal. 2022, 106, 104300. [Google Scholar] [CrossRef]
- Fraser, K.; Lane, G.A.; Otter, D.E.; Harrison, S.J.; Quek, S.-Y.; Hemar, Y.; Rasmussen, S. Monitoring tea fermentation/manufacturing by direct analysis in real time (DART) mass spectrometry. Food Chem. 2013, 141, 2060–2065. [Google Scholar] [CrossRef] [PubMed]
- Tseng, T.S.; Hsiao, M.H.; Chen, P.A.; Lin, S.Y.; Chiu, S.W.; Yao, D.J. Utilization of a Gas-Sensing System to Discriminate Smell and to Monitor Fermentation during the Manufacture of Oolong Tea Leaves. Micromachines 2021, 12, 93. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Xu, L.; Huang, P.; Luo, X.; Wang, P.; Kang, Z. Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning. Agriculture 2021, 11, 1106. [Google Scholar] [CrossRef]
- Shi, D.; Hang, J.; Neufeld, J.; Zhao, S.; House, J.D. Estimation of crude protein and amino acid contents in whole, ground and defatted ground soybeans by different types of near-infrared (NIR) reflectance spectroscopy. J. Food Compos. Anal. 2022, 111, 104601. [Google Scholar] [CrossRef]
- Chakravartula, S.S.N.; Bandiera, A.; Nardella, M.; Bedini, G.; Ibba, P.; Massantini, R.; Moscetti, R. Computer vision-based smart monitoring and control system for food drying: A study on carrot slices. Comput. Electron. Agric. 2023, 206, 107654. [Google Scholar] [CrossRef]
- Salman, S.; Öz, G.; Felek, R.; Haznedar, A.; Turna, T.; Özdemir, F. Effects of fermentation time on phenolic composition, antioxidant and antimicrobial activities of green, oolong, and black teas. Food Biosci. 2022, 49, 101884. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, J.; Sun, R. A multi-source heterogeneous spatial big data fusion method based on multiple similarity and voting decision. Soft Comput. 2022, 27, 2479–2492. [Google Scholar] [CrossRef]
- Di Rosa, A.R.; Leone, F.; Cheli, F.; Chiofalo, V. Fusion of electronic nose, electronic tongue and computer vision for animal source food authentication and quality assessment – A review. J. Food Eng. 2017, 210, 62–75. [Google Scholar] [CrossRef]
- Du, Q.; Zhu, M.; Shi, T.; Luo, X.; Gan, B.; Tang, L.; Chen, Y. Adulteration detection of corn oil, rapeseed oil and sunflower oil in camellia oil by in situ diffuse reflectance near-infrared spectroscopy and chemometrics. Food Control 2021, 121, 107577. [Google Scholar] [CrossRef]
- Saha, D.; Manickavasagan, A. Machine learning techniques for analysis of hyperspectral images to determine quality of food products: A review. Curr. Res. Food Sci. 2021, 4, 28–44. [Google Scholar] [CrossRef] [PubMed]
- Kamruzzaman, M.; Kalita, D.; Ahmed, M.T.; ElMasry, G.; Makino, Y. Effect of variable selection algorithms on model performance for predicting moisture content in biological materials using spectral data. Anal. Chim. Acta 2022, 1202, 339390. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Zhu, J.; Jiao, T.; Wang, B.; Wei, W.; Ali, S.; Ouyang, Q.; Zuo, M.; Chen, Q. Development of a novel wavelength selection method VCPA-PLS for robust quantification of soluble solids in tomato by on-line diffuse reflectance NIR. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 243, 118765. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.; Chen, M.; Zhang, S.; Pan, H.; Chen, Y.; Wu, Y. Rapid Determination of Geniposide and Baicalin in Lanqin Oral Solution by Near-Infrared Spectroscopy with Chemometric Algorithms during Alcohol Precipitation. Molecules 2022, 28, 4. [Google Scholar] [CrossRef]
- Liu, D.; Sun, D.-W.; Zeng, X.-A. Recent Advances in Wavelength Selection Techniques for Hyperspectral Image Processing in the Food Industry. Food Bioprocess Technol. 2013, 7, 307–323. [Google Scholar] [CrossRef]
- Song, X.; Du, G.; Li, Q.; Tang, G.; Huang, Y. Rapid spectral analysis of agro-products using an optimal strategy: Dynamic backward interval PLS-competitive adaptive reweighted sampling. Anal. Bioanal. Chem. 2020, 412, 2795–2804. [Google Scholar] [CrossRef]
- Jiang, H.; He, Y.; Xu, W.; Chen, Q. Quantitative Detection of Acid Value During Edible Oil Storage by Raman Spectroscopy: Comparison of the Optimization Effects of BOSS and VCPA Algorithms on the Characteristic Raman Spectra of Edible Oils. Food Anal. Methods 2021, 14, 1826–1835. [Google Scholar] [CrossRef]
- Chen, G.; Liu, Z.; Yu, G.; Liang, J.; Hemanth, J. A New View of Multisensor Data Fusion: Research on Generalized Fusion. Math. Probl. Eng. 2021, 2021, 1–21. [Google Scholar] [CrossRef]
- Ran, R.; Wang, T.; Li, Z.; Fang, B. Polynomial linear discriminant analysis. J. Supercomput. 2024, 80, 413–434. [Google Scholar] [CrossRef]
- Yang, J.; Gao, H. Cultural emperor penguin optimizer and its application for face recognition. Math. Probl. Eng. 2020, 2020, 9579538. [Google Scholar] [CrossRef]
- Zhao, S.; Adade, S.Y.-S.S.; Wang, Z.; Wu, J.; Jiao, T.; Li, H.; Chen, Q. On-line monitoring of total sugar during kombucha fermentation process by near-infrared spectroscopy: Comparison of linear and non-linear multiple calibration methods. Food Chem. 2023, 423, 136208. [Google Scholar] [CrossRef]
- Bonifazi, G.; Capobianco, G.; Gasbarrone, R.; Serranti, S. Contaminant detection in pistachio nuts by different classification methods applied to short-wave infrared hyperspectral images. Food Control 2021, 130, 108202. [Google Scholar] [CrossRef]
- Cai, H.; Chen, T. Multi-dimension CNN for hyperspectral image classificaton. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1275–1278. [Google Scholar]
- Zhang, H.; Dong, Z.; Li, B.; He, S. Multi-Scale MLP-Mixer for image classification. Knowl.-Based Syst. 2022, 258, 109792. [Google Scholar] [CrossRef]
- Engelhardt, U.H. Tea chemistry—What do and what don’t we know?—A micro review. Food Res. Int. 2020, 132, 109120. [Google Scholar] [CrossRef]
- Porep, J.U.; Kammerer, D.R.; Carle, R. On-line application of near infrared (NIR) spectroscopy in food production. Trends Food Sci. Technol. 2015, 46, 211–230. [Google Scholar] [CrossRef]
- Cozzolino, D.; Murray, I. Identification of animal meat muscles by visible and near infrared reflectance spectroscopy. LWT-Food Sci. Technol. 2004, 37, 447–452. [Google Scholar] [CrossRef]
- Wei, W.; Li, H.; Haruna, S.A.; Wu, J.; Chen, Q. Monitoring the freshness of pork during storage via near-infrared spectroscopy based on colorimetric sensor array coupled with efficient multivariable calibration. J. Food Compos. Anal. 2022, 113, 104726. [Google Scholar] [CrossRef]
- Jang, H.-D.; Park, J.-H.; Nam, H.; Chang, D.E. Deep neural networks for gas concentration estimation and the effect of hyperparameter optimization on the estimation performance. In Proceedings of the 2022 22nd International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 27 November–1 December 2022; pp. 15–19. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | VIS-NIR RAW | VIS-NIR CARS | VIS-NIR VCPA | VIS-NIR VCPA-IRIV | VIS-NIR SPA | IMAGE |
|---|---|---|---|---|---|---|
| Calibration set | 0.6356 | 0.6850 | 0.7378 | 0.7465 | 0.6457 | 0.7034 |
| Prediction set | 0.6198 | 0.6442 | 0.7130 | 0.7006 | 0.6286 | 0.6625 |
| Method | LDA | SVM | BPANN | |||
|---|---|---|---|---|---|---|
| Calibration Set | Prediction Set | Calibration Set | Prediction Set | Calibration Set | Prediction Set | |
| CARS | 0.857 | 0.800 | 1.000 | 0.924 | 0.971 | 0.857 |
| SPA | 0.857 | 0.800 | 0.990 | 0.971 | 1.000 | 0.943 |
| VCPA | 0.857 | 0.800 | 1.000 | 0.943 | 1.000 | 0.971 |
| VCPA-IRIV | 0.857 | 0.800 | 1.000 | 0.971 | 0.967 | 0.930 |
| Grade | Index | LDA | SVM | BPANN | |||
|---|---|---|---|---|---|---|---|
| Calibration Set | Prediction Set | Calibration Set | Prediction Set | Calibration Set | Prediction Set | ||
| 1 | Sensitivity | 0.8431 | 0.8462 | 1.0000 | 1.0000 | 1.0000 | 0.9615 |
| Specificity | 0.8947 | 0.6667 | 0.9474 | 0.8889 | 1.0000 | 0.8889 | |
| Accuracy | 0.8571 | 0.8000 | 0.9857 | 0.9714 | 1.0000 | 0.9429 | |
| Error | 0.1143 | 0.1714 | 0.0000 | 0.0000 | 0.0000 | 0.0571 | |
| 2 | Sensitivity | 0.8000 | 0.5000 | 0.9000 | 0.7500 | 1.0000 | 0.7500 |
| Specificity | 0.8667 | 0.8387 | 1.0000 | 1.0000 | 1.0000 | 0.9677 | |
| Accuracy | 0.8571 | 0.8000 | 0.9857 | 0.9714 | 1.0000 | 0.9429 | |
| Error | 0.1429 | 0.8857 | 0.0143 | 0.0286 | 0.0000 | 0.0571 | |
| 3 | Sensitivity | 1.0000 | 0.8000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Specificity | 0.8361 | 0.8000 | 0.9836 | 0.9667 | 1.0000 | 0.9333 | |
| Accuracy | 0.8571 | 0.8000 | 0.9857 | 0.9714 | 1.0000 | 0.9429 | |
| Error | 0.0286 | 0.8286 | 0.0143 | 0.0286 | 0.0000 | 0.0000 | |
| Models | Grade | NC a | Results in the Calibration Set | NP b | Results in the Prediction Set | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | CR c | 1 | 2 | 3 | CR c | ||||
| LDA | 1 | 153 | 129 | 24 | 0 | 85.71% | 78 | 66 | 12 | 0 | 80.00% |
| 2 | 30 | 0 | 24 | 6 | 12 | 0 | 6 | 6 | |||
| 3 | 27 | 0 | 0 | 27 | 15 | 0 | 3 | 12 | |||
| SVM | 1 | 153 | 153 | 0 | 0 | 98.57% | 78 | 78 | 0 | 0 | 97.14% |
| 2 | 30 | 0 | 27 | 3 | 12 | 0 | 9 | 3 | |||
| 3 | 27 | 0 | 0 | 27 | 15 | 0 | 0 | 15 | |||
| BPANN | 1 | 51 | 51 | 0 | 0 | 100.00% | 78 | 75 | 3 | 0 | 94.29% |
| 2 | 10 | 0 | 10 | 0 | 12 | 3 | 9 | 0 | |||
| 3 | 9 | 0 | 0 | 9 | 15 | 0 | 0 | 15 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, P.; Solomon Adade, S.Y.-S.; Rong, Y.; Zhao, S.; Han, Z.; Gong, Y.; Chen, X.; Yu, J.; Huang, C.; Lin, H. Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies. Foods 2024, 13, 1708. https://doi.org/10.3390/foods13111708
Zheng P, Solomon Adade SY-S, Rong Y, Zhao S, Han Z, Gong Y, Chen X, Yu J, Huang C, Lin H. Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies. Foods. 2024; 13(11):1708. https://doi.org/10.3390/foods13111708
Chicago/Turabian StyleZheng, Pengfei, Selorm Yao-Say Solomon Adade, Yanna Rong, Songguang Zhao, Zhang Han, Yuting Gong, Xuanyu Chen, Jinghao Yu, Chunchi Huang, and Hao Lin. 2024. "Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies" Foods 13, no. 11: 1708. https://doi.org/10.3390/foods13111708
APA StyleZheng, P., Solomon Adade, S. Y.-S., Rong, Y., Zhao, S., Han, Z., Gong, Y., Chen, X., Yu, J., Huang, C., & Lin, H. (2024). Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies. Foods, 13(11), 1708. https://doi.org/10.3390/foods13111708