
The Fermentation Degree Prediction Model for Tieguanyin Oolong Tea Based on Visual and Sensing Technologies

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Design and Sample Selection
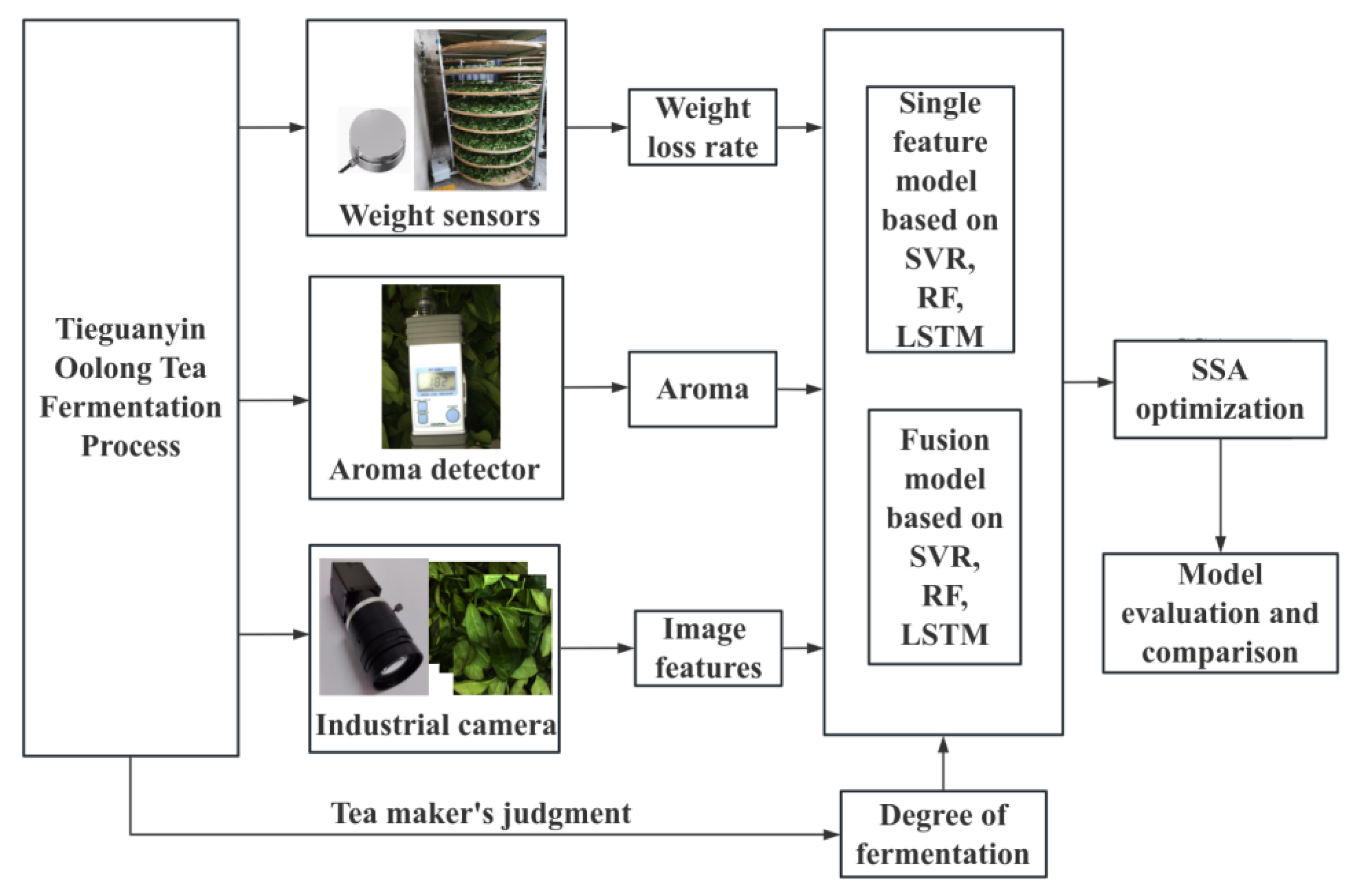
2.2. Data Collection Equipment
2.3. Image Features Extraction
2.4. Feature Selection via Tree Models
2.5. Model and Performance Evaluation
2.5.1. SVM
2.5.2. RF
2.5.3. LSTM
2.5.4. SSA
2.5.5. Model Evaluation
3. Results and Discussion
3.1. Data Acquisition
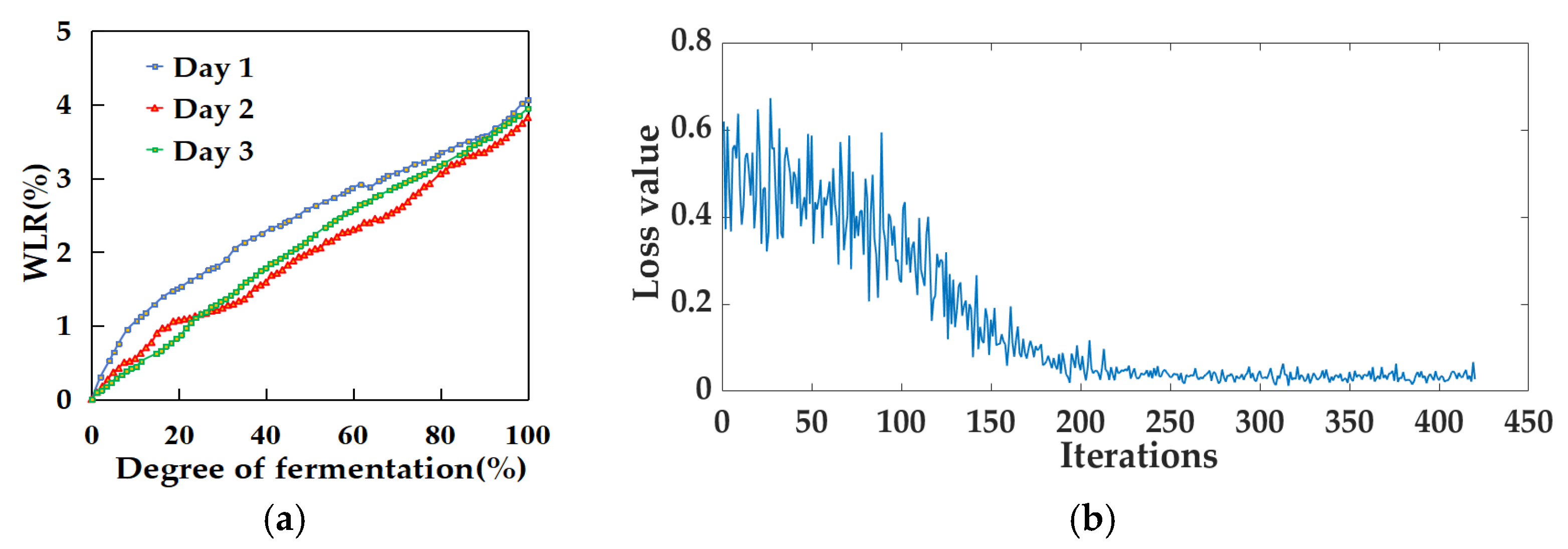
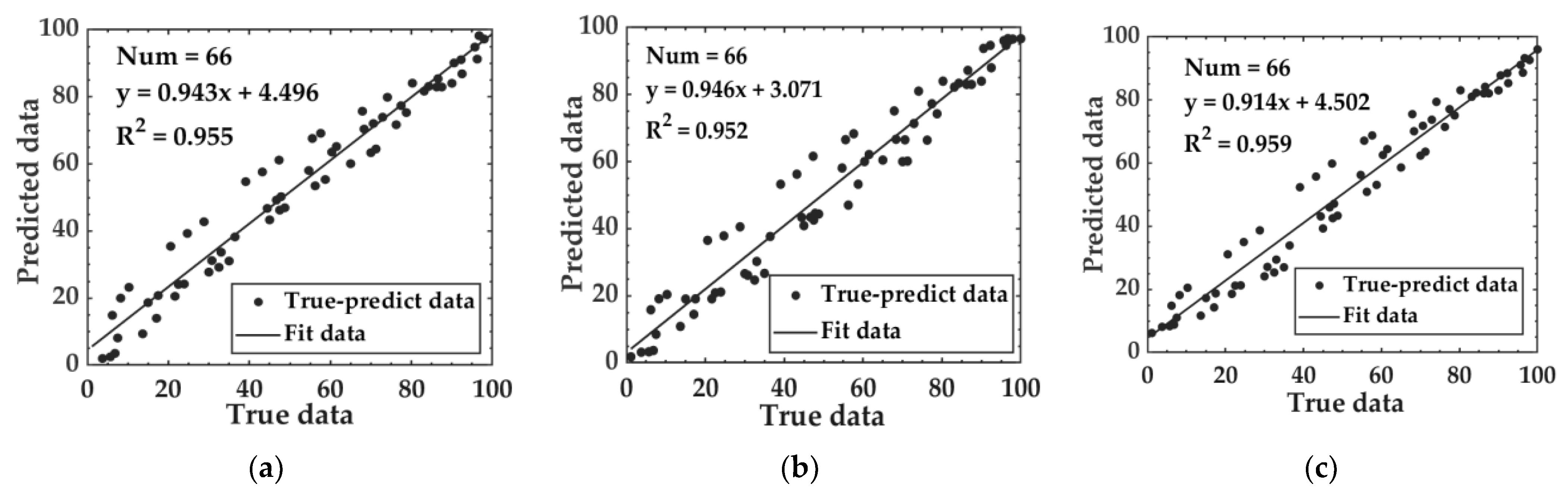
3.2. Fermentation Degree Model Based on WLR Data
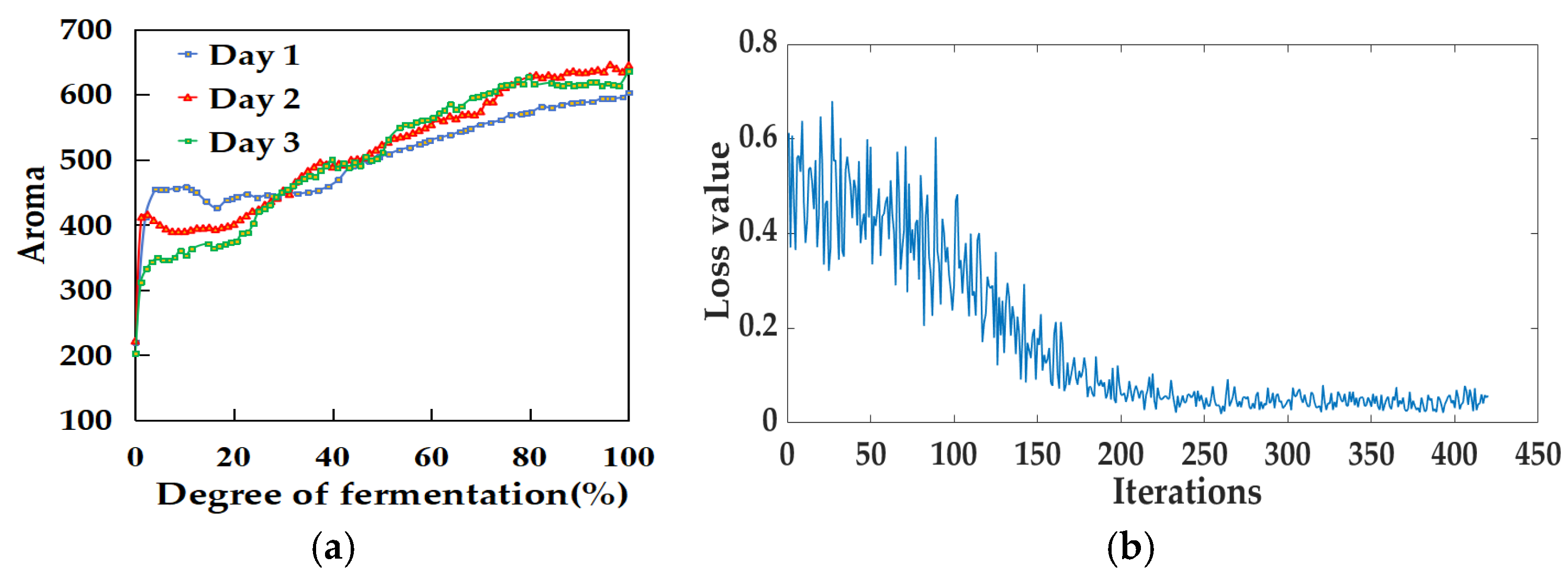
3.3. Fermentation Degree Model Based on Aroma Data
3.4. Fermentation Degree Prediction Model Based on Image Features
3.4.1. Changes in Surface Color During Fermentation
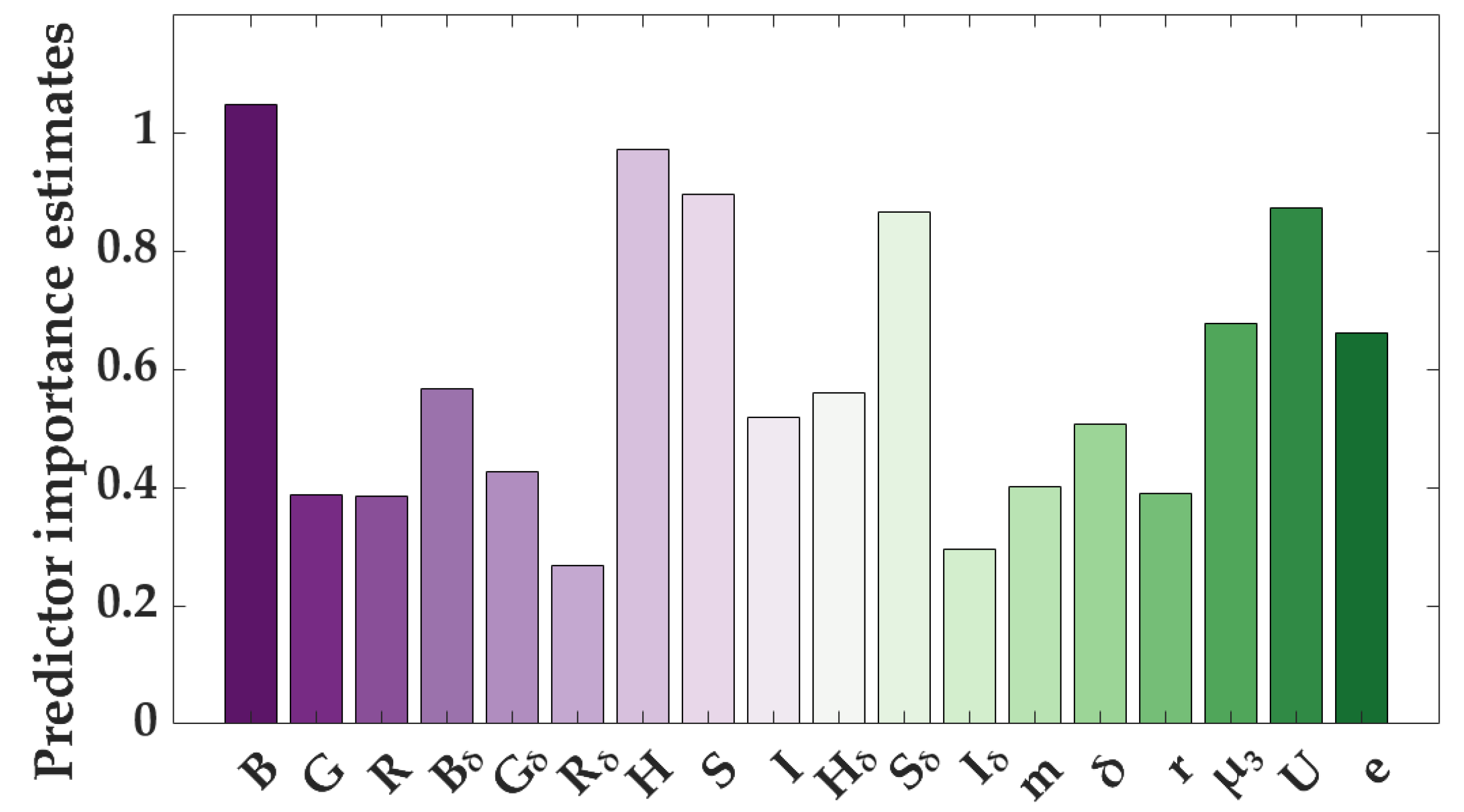
3.4.2. Feature Selection Results from Tree Models Based on Image Features
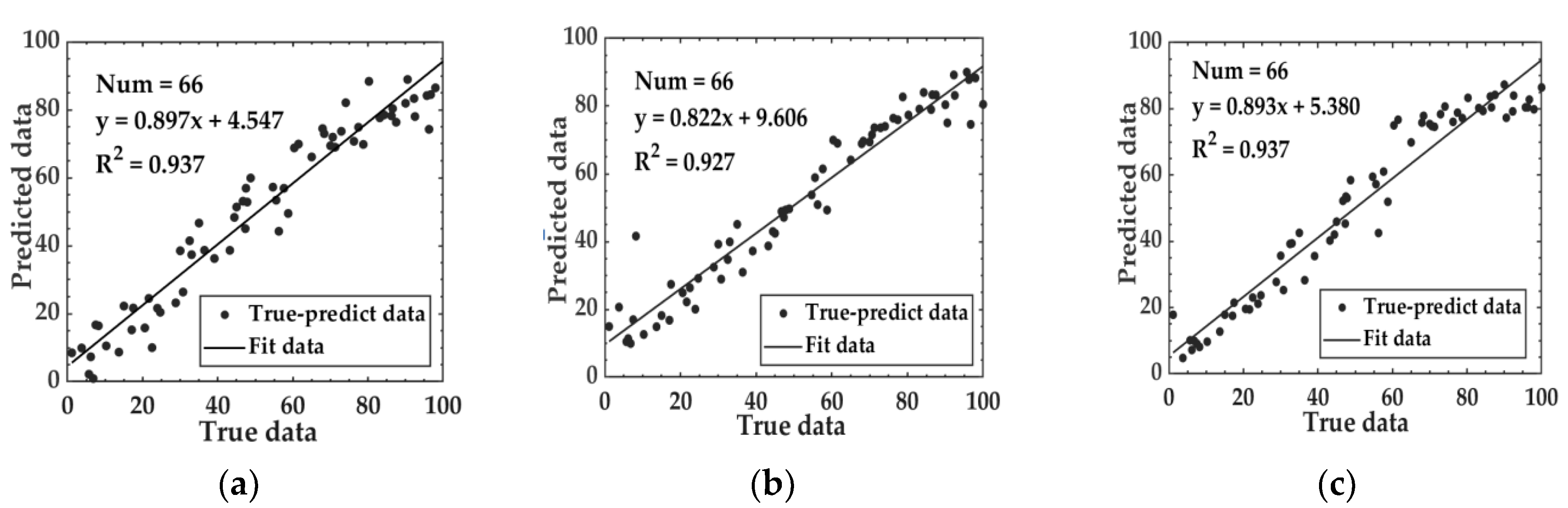
3.4.3. Model Results Based on Image Features
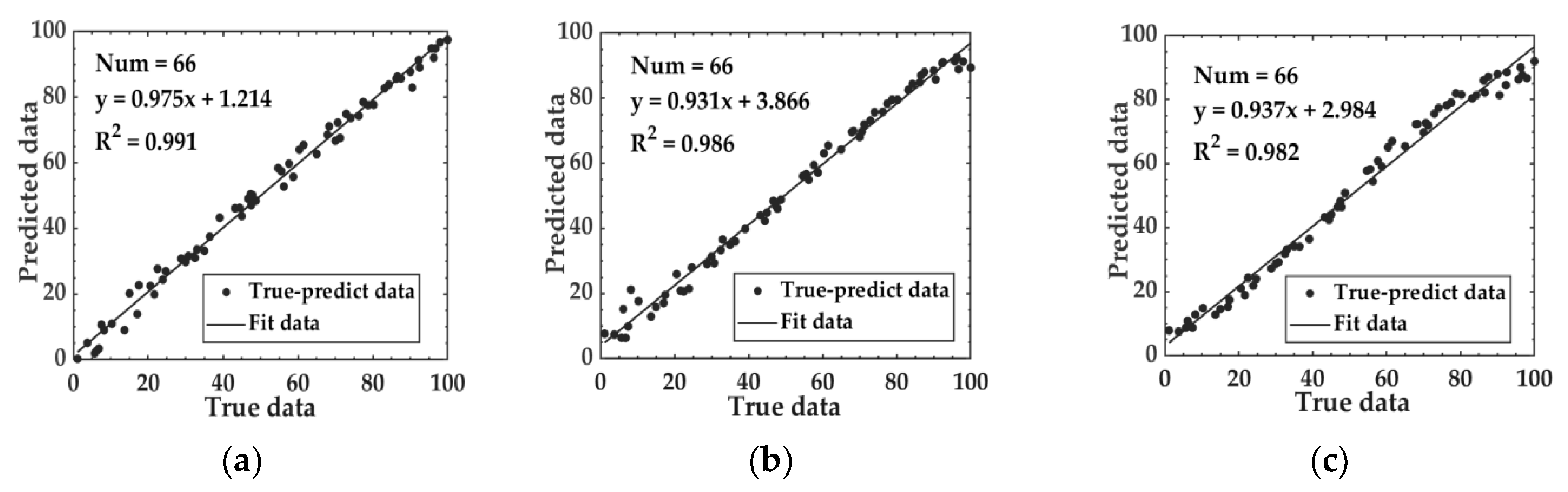
3.5. Fermentation Degree Prediction Model Based on Fusion Feature Data
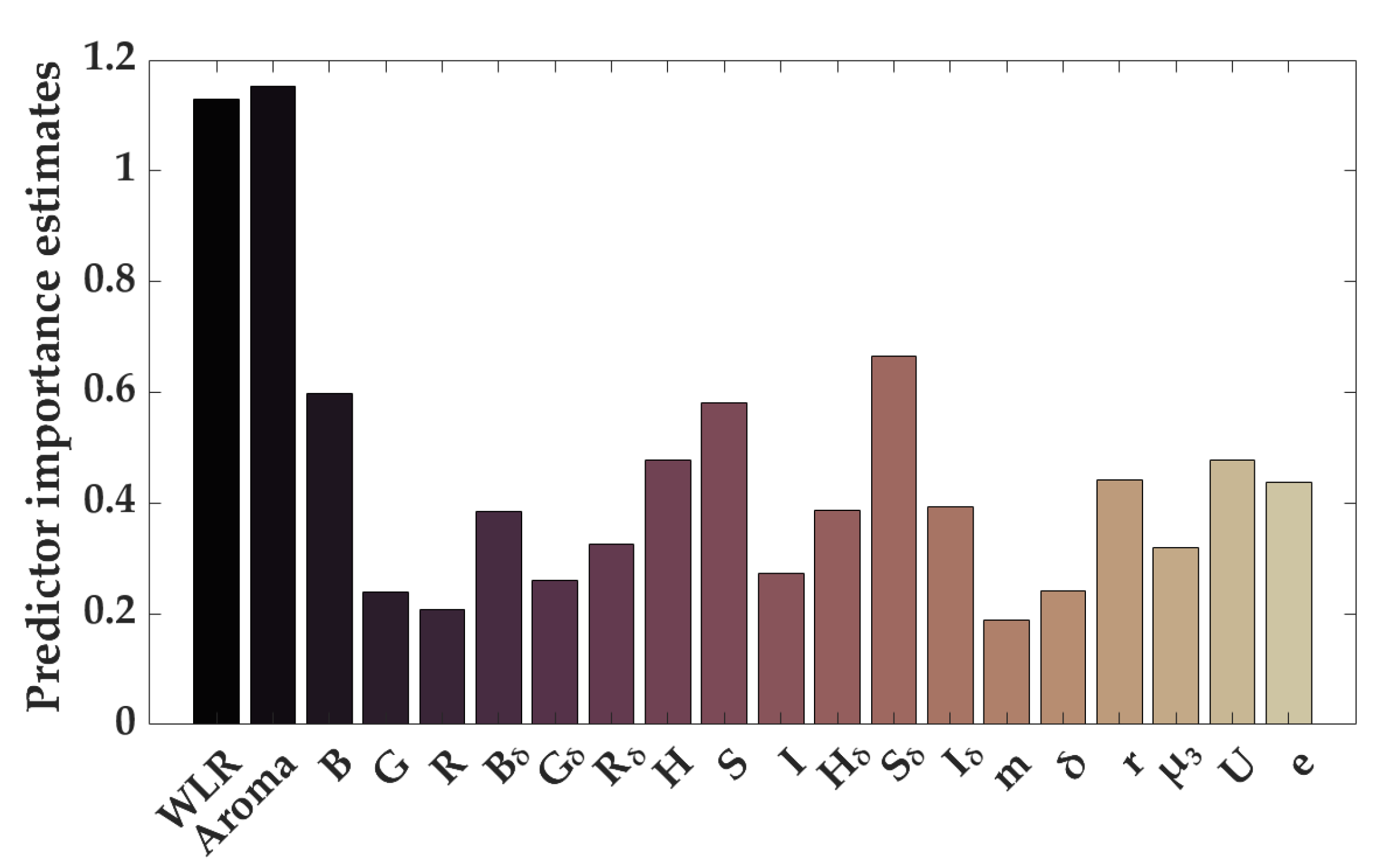
3.5.1. Feature Selection Results from Tree Models Based on Fusion Feature Data
3.5.2. Model Results Based on Fusion Feature Data
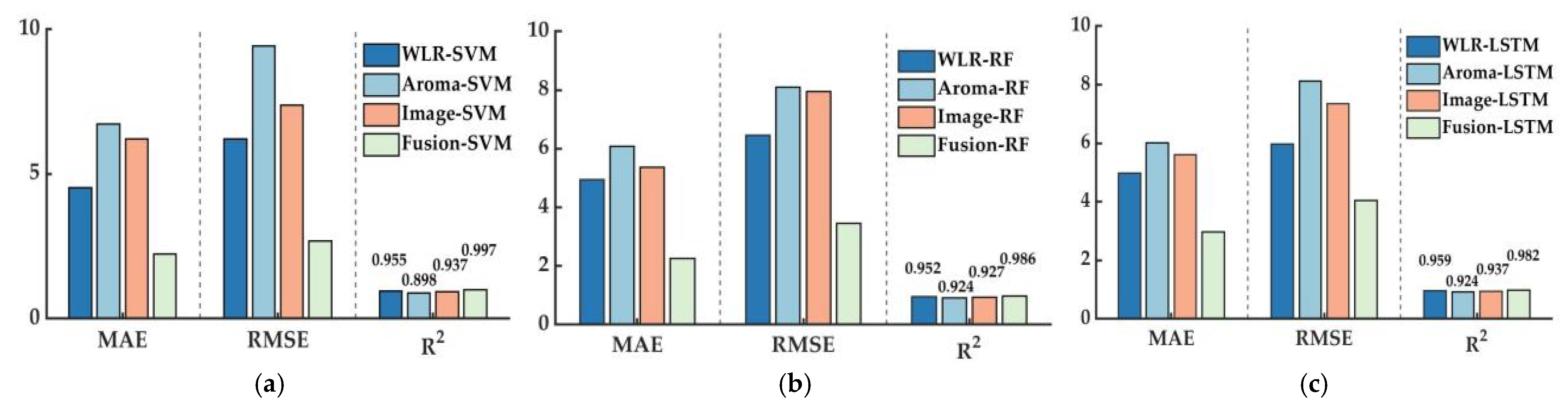
3.6. Model Comparison
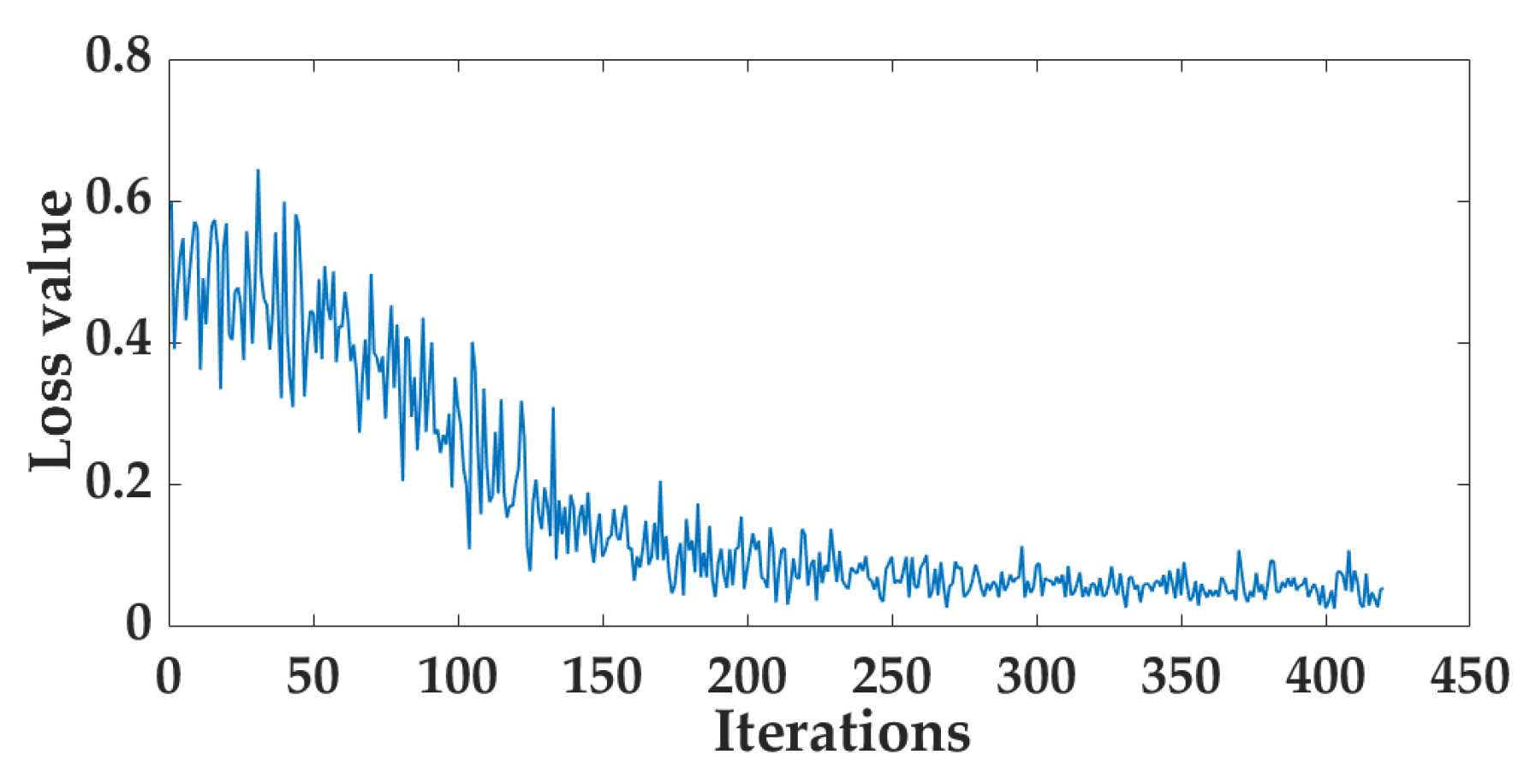
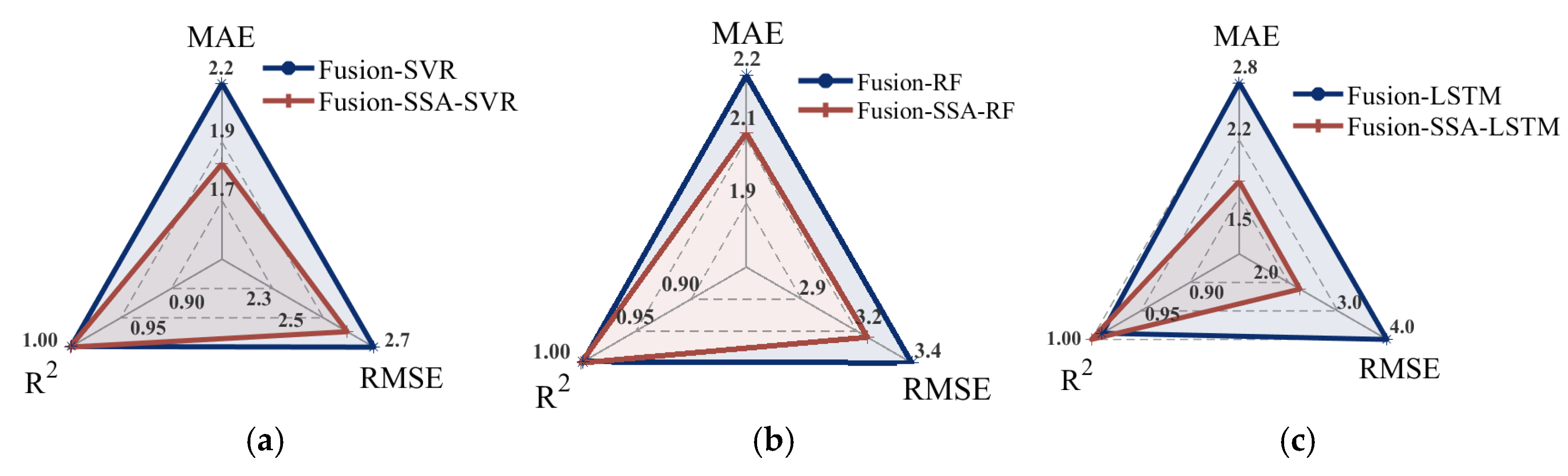
3.7. Model Optimization
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, C.; Lin, J.; Hu, Q.; Sun, Y.; Wu, L. An integrated metabolomic and transcriptomic analysis reveals the dynamic changes of key metabolites and flavor formation over Tieguanyin oolong tea production. Food Chem. X 2023, 20, 100952. [Google Scholar] [CrossRef] [PubMed]
- Cao, Q.; Wang, J.; Chen, J.; Wang, F.; Gao, Y.; Granato, D.; Zhang, X.; Yin, J.; Xu, Y.-Q. Optimization of brewing conditions for Tieguanyin oolong tea by quadratic orthogonal regression design. npj Sci. Food 2022, 6, 25. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Jing, T.; Zhao, M.; Jin, J.; Xu, M.; Chen, Y.; Zhang, S.; Wan, X.; Schwab, W.; Song, C. Untargeted metabolomics coupled with chemometrics analysis reveals potential non-volatile markers during oolong tea shaking. Food Res. Int. 2019, 123, 125–134. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Liu, H.; Zhao, X.; Li, X.; Shan, W.; Wang, X.; Wang, S.; Yu, W.; Yang, Z.; Yu, X. Non-targeted metabolomics analysis reveals dynamic changes of volatile and non-volatile metabolites during oolong tea manufacture. Food Res. Int. 2020, 128, 108778. [Google Scholar] [CrossRef]
- Yao, Q.; Huang, M.; Zheng, Y.; Chen, M.; Huang, C.; Lin, Q. Prediction and Health Risk Assessment of Copper, Lead, Cadmium, Chromium, and Nickel in Tieguanyin Tea: A Case Study from Fujian, China. Foods 2022, 11, 1593. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, P.; Shi, J.; Gao, Y.; Wang, Q.-S.; Yin, J.-F. Quality development and main chemical components of Tieguanyin oolong teas processed from different parts of fresh shoots. Food Chem. 2018, 249, 176–183. [Google Scholar] [CrossRef]
- Chen, L.; Chen, K.; Chen, Q.; Zhang, Y.; Song, Z.; Wang, L.; You, Z. Effects of Green-making Technique on Aroma Pattern of Oolong Tea. J. Tea Sci. 2014, 34, 387–395. [Google Scholar]
- Hu, C.; Li, D.; Ma, Y.; Zhang, W.; Lin, C.; Zheng, X.; Liang, Y.; Lu, J. Formation mechanism of the oolong tea characteristic aroma during bruising and withering treatment. Food Chem. 2018, 269, 202–211. [Google Scholar] [CrossRef]
- Lin, S.; Lo, L.; Chen, I.; Chen, P. Effect of shaking process on correlations between catechins and volatiles in oolong tea. J. Food Drug Anal. 2016, 24, 500–507. [Google Scholar] [CrossRef]
- Tseng, T.; Hsiao, M.; Chen, P.-A.; Lin, S.; Chiu, S.; Yao, D. Utilization of a Gas-Sensing System to Discriminate Smell and to Monitor Fermentation during the Manufacture of Oolong Tea Leaves. Micromachines 2021, 12, 93. [Google Scholar] [CrossRef]
- An, T.; Huang, W.; Tian, X.; Fan, S.; Duan, D.; Dong, C.; Zhao, C.; Li, G. Hyperspectral imaging technology coupled with human sensory information to evaluate the fermentation degree of black tea. Sens. Actuators B Chem. 2022, 366, 131994. [Google Scholar] [CrossRef]
- Wu, W.; Wang, Y.; Cheng, X.; Zheng, M. Study on the color degree recognition of Wuyi Rock Tea with machinery vision. J. Shanxi Agric. Univ. (Nat. Sci. Ed.) 2019, 39, 86–92. [Google Scholar]
- Jin, G.; Wang, Y.; Li, L.; Shen, S.; Deng, W.-W.; Zhang, Z.; Ning, J. Intelligent evaluation of black tea fermentation degree by FT-NIR and computer vision based on data fusion strategy. LWT 2020, 125, 109216. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, R.; Yang, C.; Hu, B.; Luo, X.; Li, Y.; Dong, C. Research on moisture content detection method during green tea processing based on machine vision and near-infrared spectroscopy technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 271, 120921. [Google Scholar] [CrossRef]
- Wei, Y.; Wu, F.; Xu, J.; Sha, J.; Zhao, Z.; He, Y.; Li, X. Visual detection of the moisture content of tea leaves with hyperspectral imaging technology. J. Food Eng. 2019, 248, 89–96. [Google Scholar] [CrossRef]
- Liu, Y. Moisture effects and mathematical modeling of oolong tea greening process. Tea Sci. Bull. 1990, 1, 25–28. [Google Scholar]
- Kang, S.; Zhang, Q.; Li, Z.; Yin, C.; Feng, N.; Shi, Y. Determination of the quality of tea from different picking periods: An adaptive pooling attention mechanism coupled with an electronic nose. Postharvest Biol. Technol. 2023, 197, 112214. [Google Scholar] [CrossRef]
- Zhang, C. Research progress on the changes of aroma composition and formation mechanism of oolong tea during processing. Fujian Tea 2006, 1, 7–8. [Google Scholar]
- Han, Z.; Ahmad, W.; Rong, Y.; Chen, X.; Zhao, S.; Yu, J.; Zheng, P.; Huang, C.; Li, H. A Gas Sensors Detection System for Real-Time Monitoring of Changes in Volatile Organic Compounds during Oolong Tea Processing. Foods 2024, 13, 1721. [Google Scholar] [CrossRef]
- Zheng, P.; Solomon Adade, S.Y.-S.; Rong, Y.; Zhao, S.; Han, Z.; Gong, Y.; Chen, X.; Yu, J.; Huang, C.; Lin, H. Online System for Monitoring the Degree of Fermentation of Oolong Tea Using Integrated Visible–Near-Infrared Spectroscopy and Image-Processing Technologies. Foods 2024, 13, 1708. [Google Scholar] [CrossRef]
- Dong, C.; Liang, G.; Hu, B.; Yuan, H.; Jiang, Y.; Zhu, H.; Qi, J. Prediction of Congou Black Tea Fermentation Quality Indices from Color Features Using Non-Linear Regression Methods. Sci. Rep. 2018, 8, 10535. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Bhargava, A.; Agarwal, D. Deep Learning-Based Tea Fermentation Grading. In Proceedings of the Innovative Computing and Communications, New Delhi, India, 16–17 February 2024; Springer: Singapore, 2024; pp. 171–186. [Google Scholar]
- Salman, S.; Öz, G.; Felek, R.; Haznedar, A.; Turna, T.; Özdemir, F. Effects of fermentation time on phenolic composition, antioxidant and antimicrobial activities of green, oolong, and black teas. Food Biosci. 2022, 49, 101884. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Gu, S. Rapid identification of tea quality by E-nose and computer vision combining with a synergetic data fusion strategy. J. Food Eng. 2019, 241, 10–17. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Jia, P.; Dai, Y. Identification of Longjing Teas with Different Geographic Origins Based on E-Nose and Computer Vision System Combined with Data Fusion Strategies. Trans. ASABE 2021, 64, 327–340. [Google Scholar] [CrossRef]
- Zhou, Q.; Dai, Z.; Song, F.; Li, Z.; Song, C.; Ling, C. Monitoring black tea fermentation quality by intelligent sensors: Comparison of image, e-nose and data fusion. Food Biosci. 2023, 52, 102454. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Tsai, J.; Saritporn, V. Inspection of tea quality by using multi-sensor information fusion based on NIR spectroscopy and machine vision. Trans. CSAE 2008, 24, 5–10. [Google Scholar]
- Paja, W. Feature Selection Methods Based on Decision Rule and Tree Models. In Proceedings of the Intelligent Decision Technologies 2016, Tenerife, Spain, 15–17 June 2016; Springer: Cham, Switzerland, 2016; pp. 63–70. [Google Scholar]
- Sánchez, A.S.; Nieto, P.G.; Fernández, P.R.; del Coz Díaz, J.J.; Iglesias-Rodríguez, F.J. Application of an SVM-based regression model to the air quality study at local scale in the Avilés urban area (Spain). Math. Comput. Model. 2011, 54, 1453–1466. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Xie, X.; Wu, T.; Zhu, M.; Jiang, G.; Xu, Y.; Wang, X.; Pu, L. Comparison of random forest and multiple linear regression models for estimation of soil extracellular enzyme activities in agricultural reclaimed coastal saline land. Ecol. Indic. 2021, 120, 106925. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, D.; Zhang, L.; Zhu, J. Dynamic Gust Detection and Conditional Sequence Modeling for Ultra-Short-Term Wind Speed Prediction. Electronics 2024, 13, 4513. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Zhan, C.; Mao, H.; Fan, R.; He, T.; Qing, R.; Zhang, W.; Lin, Y.; Li, K.; Wang, L.; Xia, T.E.; et al. Detection of Apple Sucrose Concentration Based on Fluorescence Hyperspectral Image System and Machine Learning. Foods 2024, 13, 3547. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| WLR-SVM | 4.056 | 5.691 | 0.961 | 4.537 | 6.214 | 0.955 |
| WLR-RF | 3.430 | 4.595 | 0.975 | 4.956 | 6.463 | 0.952 |
| WLR-LSTM | 4.552 | 5.624 | 0.962 | 4.986 | 5.980 | 0.959 |
| Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| Aroma-SVM | 6.643 | 9.485 | 0.892 | 6.732 | 9.416 | 0.898 |
| Aroma-RF | 4.368 | 5.688 | 0.961 | 6.082 | 8.109 | 0.924 |
| Aroma-LSTM | 5.662 | 7.097 | 0.940 | 6.015 | 8.123 | 0.924 |
| Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| Image-SVM | 5.815 | 7.621 | 0.930 | 6.211 | 7.392 | 0.937 |
| Image-RF | 3.829 | 5.55 | 0.963 | 5.378 | 7.953 | 0.927 |
| Image-LSTM | 5.621 | 7.441 | 0.934 | 5.675 | 7.408 | 0.937 |
| Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| Fusion-SVM | 2.835 | 3.635 | 0.984 | 2.232 | 2.693 | 0.991 |
| Fusion-RF | 1.582 | 2.335 | 0.993 | 2.249 | 3.447 | 0.986 |
| Fusion-LSTM | 2.517 | 3.668 | 0.984 | 2.783 | 3.969 | 0.982 |
| Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | |
| Fusion-SSA-SVM | 2.335 | 3.775 | 0.985 | 1.834 | 2.600 | 0.992 |
| Fusion-SSA-RF | 0.958 | 1.386 | 0.998 | 2.078 | 3.230 | 0.988 |
| Fusion-SSA-LSTM | 1.689 | 2.257 | 0.994 | 1.703 | 2.258 | 0.994 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Zhao, J.; Zheng, C.; Li, C.; Wang, T.; Xiao, L.; Chen, Y. The Fermentation Degree Prediction Model for Tieguanyin Oolong Tea Based on Visual and Sensing Technologies. Foods 2025, 14, 983. https://doi.org/10.3390/foods14060983
Huang Y, Zhao J, Zheng C, Li C, Wang T, Xiao L, Chen Y. The Fermentation Degree Prediction Model for Tieguanyin Oolong Tea Based on Visual and Sensing Technologies. Foods. 2025; 14(6):983. https://doi.org/10.3390/foods14060983
Chicago/Turabian StyleHuang, Yuyan, Jian Zhao, Chengxu Zheng, Chuanhui Li, Tao Wang, Liangde Xiao, and Yongkuai Chen. 2025. "The Fermentation Degree Prediction Model for Tieguanyin Oolong Tea Based on Visual and Sensing Technologies" Foods 14, no. 6: 983. https://doi.org/10.3390/foods14060983
APA StyleHuang, Y., Zhao, J., Zheng, C., Li, C., Wang, T., Xiao, L., & Chen, Y. (2025). The Fermentation Degree Prediction Model for Tieguanyin Oolong Tea Based on Visual and Sensing Technologies. Foods, 14(6), 983. https://doi.org/10.3390/foods14060983