Abstract
This publication examines the representation of information within test specifications and formulas defined in standards and directives. This information often pre-defines not only the tests and requirements to be conducted but also the information backflow within the execution. These results are crucial for the effective management of knowledge throughout the product development process as well as for the creation and maintenance of digital representations of a physical product or plant. However, the accessibility of this information is frequently hindered by its extensive and heterogenous definition across a multitude of standards, directives, and other technical regulations. Furthermore, the pre-defined information is typically documented and processed manually on a recurring basis. Given this challenge, the following article presents a holistic two-part approach for pre-defining the information backflow of subsequent physical instances. Initially, an analysis of multiple test specifications in standards and directives is conducted, resulting in the development of a generic data model to represent this Pre-defined Information Backflow (PdIB). The second step builds on the first and defines an optimized representation for machine readability and executability for the future design of standards and directives. The two parts are brought together and validated using representative examples, thereby demonstrating the practical applicability and effectiveness of the proposed approach. This enhances the accessibility and usability of information in test specifications and formulas, thereby establishing a foundation for enhancing the efficiency of knowledge work in product development and the creation of digital representations of products and plants.
1. Introduction
1.1. Motivation
The digital transformation of industry requires an increasing integration of systems across domain boundaries, hierarchical boundaries, and lifecycle phases [,] and therefore also has a profound influence on product development and quality processes and the associated standardization []. Furthermore, the digital transformation of complex processes requires careful process analysis in order to identify sub-processes and the associated data requirements []. Knowledge graphs have emerged as a suitable representation for machine-executable content and facilitate the automatic identification, extraction, and modeling of standards content, especially formulas []. Natural Language Processing techniques combined with knowledge graphs can enhance interoperability between standards and mitigate conflicts [].
In order to establish this initially, the availability and structured presentation of information, particularly in the form of formula-based test specifications, is becoming increasingly important in the context of standardization. Data-driven product creation processes and the development of digital representations require precise and easily accessible information [] as well as increased traceability and transparency.
Even if there are increasing numbers of approaches for the subsequent evaluation and analysis of text-based documents using technologies such as entity recognition [,,,], language models [,,,], and machine learning in general [], absolute accuracy in the extraction of the relevant information cannot usually be achieved here. Efforts to extract requirements from industrial standards [] and construction regulations [] have also been made using natural language processing and ontologies in the representation of semantic information from multi-modal technical documents []. However, challenges remain in bridging the semantic gap and developing appropriate evaluation methods for interpretation processes []. Moreover, the above-mentioned absolute accuracy is necessary against the background of conformity to standards and product certifications. Despite its crucial role, the machine-readable representation, executability, and interpretability of this information is a challenging task. While standards are already available today in XML format and, in particular, structuring elements such as paragraphs, tables, figures, and mathematical equations are clearly labelled, there is a lack of fine-grained semantic representation, which is regarded as the basis of machine executability and machine interpretability []. This makes a structured definition of requirements through a data model combined with the extension of today’s XML tagging indispensable. Furthermore, the information to be traced in the area of tests and inspections to be carried out is usually related to physical instances, which are linked to the respective article in the product data management (PDM) system of the respective company in a clearly identifiable, parts list-based manner [].
Against this background, this article seeks to address the existing challenges related to the availability and usability of information in the form of test specifications and formulas in the context of industrial processing. Figure 1 shows the current status in which standardization groups publish and update documents on a recurring basis, while experts in the companies evaluate them and transfer them to the respective product.
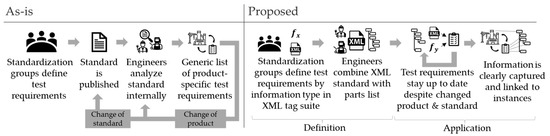
Figure 1.
Motivation.
As a proposed solution, this article therefore focuses on the development of a two-part approach for transferring information from existing standards into a generic data model and for defining the correct representation and structure of future standards. The aim is to improve the availability and usability of information in formulas and test specifications in order to support the development of digital representations through a standardized traceability process. This requires the ability to define information for machine-readable and machine-executable traceability, as shown in Figure 2.

Figure 2.
Research gap with resulting methodology.
1.2. System Boundaries and Requirements Definition
In order to narrow down the heterogeneous field of the standardization landscape, the study focuses on the structured representation of information that arises in an industrial context and is already defined in the standards and test-relevant directives of the industrial sector. These include the representation and definition of formulas, test-relevant requirements, as well as the classification and specification of necessary information that can be directly assigned to physically produced instances. A special remark is made about information where the retrieval and backflow are planned in advance for a later stage of the lifecycle. Visualized in Figure 3, the derived requirements are a classification structure of the respective information type, a usable unique XML tag suite, a standard for the Bill of Materials (BOM), and finally the possibility to realize an automated assignment.

Figure 3.
Derivation of requirements.
In a subsequent state of the art section, the structure of standards documents is first analyzed, and the specific representation of formulas is examined. This is followed by a breakdown of current approaches used to describe the information to be retrieved. Approaches based on the authors’ own prior research are also highlighted.
2. State of the Art
2.1. Standards and Standardization—Status Quo and Trends
Standards are a valuable knowledge source in product development and influence many decisions along the development process, e.g., requirements elicitation, product design, as well as verification and validation []. Despite the increasing digitization and automation of engineering activities, today’s standards are predominantly distributed in print or PDF format. Thus, standards documents are first identified and read, and information is manually extracted, analyzed, and combined to lastly be applied correctly in engineering processes [,]. This workflow not only leads to high costs but also introduces the risk of erroneous information transmission, which impacts aspects such as product safety and security, performance, and thus market acceptance []. A study of the German Federal Ministry for Economic Affairs and Climate Action (BMWK) shows that 83% of companies in Germany still rely on these formats, whereas 47% of participants would request machine-readable and machine-processable standards in the future [].
Due to increasing industry demand, standards development organizations such as ISO/IEC or DIN have intensified efforts to provide standards content outside of traditional formats, which are called digital or SMART standards [,]. This transformation builds on the ISO/IEC Utility Model and has been further refined by the Initiative Digital Standards (IDiS), which proposes a five-stage model progressing from digital documents to machine-controllable content (see Figure 4) []. While companies are still obtaining Level 0 standards, today’s standards are also distributed in XML format, fulfilling the requirements of Level 1 standards. Although the accessibility of information is enhanced due to the XML syntax, the current version of the standardized XML markup schema for standards, called NISO STS [], focuses on structural elements. Here, entire clauses are marked that contain several statements, like requirements or recommendations. This limits the capability for semantic processing []. Both—Level 0 and Level 1 standards—can be seen as document-centric formats where the content is optimized for human readability and manual processing. The goal of Level 3 standards is to change this document-centric view to a content-centric view where granular content elements are accessible by machines and enforce operations in target systems (machine executability) []. This shift from Level 2 to Level 3 standards is, today, subject to several activities in research and industry. While Level 3 standards might be achieved by fine-grained markup in XML, machine-interpretable content (Level 4 standards) requires information models that describe and explain content as well as the semantic relationships between information elements []. This enables additional standards services such as conformity checks and question answering systems. However, semantic models for knowledge representation, such as ontologies and knowledge graphs, are required []. Lastly, machine-controllable content (Level 5 standards) suggests the automatic management and adoption of standards content based on an artificial intelligence with cognitive capabilities [].
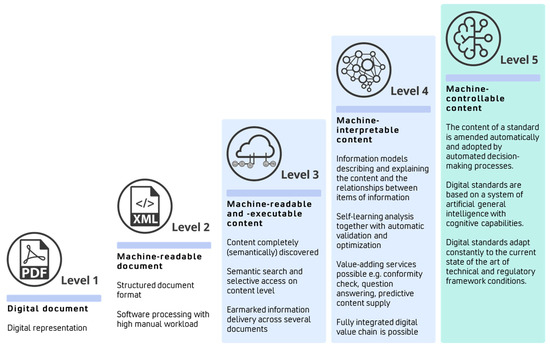
Figure 4.
Extended ISO/IEC Stage Model [].
In summary, the current activities of standards development organizations, such as the program ISO SMART or IDiS, focus on identifying and defining content elements as well as developing data models to achieve machine executability and machine interpretability. For this, two strategies are applied: enrichment of XML standards and development of semantic data models. DIN and DKE propose extending the NISO STS tagging suite by introducing additional so-called semantic markup elements. This work specifically focuses on requirements and defines a tagging schema for requirements in standards []. Because of the aforementioned limitations of XML, pilot projects of ISO and IEC focus on developing a standard information model that enables cognitive search and advanced applications in third-party systems []. Additionally, Luttmer et al. developed an ontology for formulas from standards, transforming content into RDF triples and representing content in knowledge graphs for easy access and processability to achieve Level 4 standards [,].
2.2. Representation of Formulas in Standards Documents
Standards documents generally adhere to guidelines such as the ISO Directives or DIN 820, which define the document’s structure and specify types of provisions, such as requirements, recommendations, or informal content. Formulas are a core component of standards documents, alongside text, tables, and images []. Their practical significance is high, with formulas appearing in about 75% of all standards documents, particularly in technical fields such as mechanical engineering, automotive engineering, and electrical engineering. Throughout the product development process, formulas influence various activities, from design calculations to testing procedures [].
Research has shown that formulas can be used as elements for content-based standards provision to achieve machine executability. However, they consist of not only mathematical equations but also various contextual and descriptive elements. These elements are structured as a standalone, self-contained standards module, known as the formula module, which comprises five components and is shown in Figure 5. Each variable used within an equation is referenced through a variable module, also consisting of five components []. A variable module can be used across different mathematical equations and formula modules, allowing relationships to be defined between multiple formula modules. Notably, not every component in the module needs to be described for instantiation, as the module represents a maximum configuration to which other content elements can be linked, ensuring the accurate interpretation and application of formulas [,].
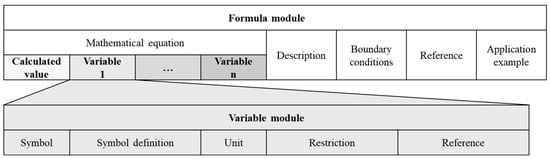
Figure 5.
Description of a formula module [].
Previous research has focused primarily on the automatic extraction and processing of formula elements from today´s XML standards. Luttmer et al. presented an approach for the automatic knowledge extraction of formula modules, which automatically aggregates the extracted information into a knowledge graph []. The focus here was on the elements “mathematical equation”, “symbol”, and “symbol explanation” as well as the relationships between these elements. Rule-based extraction approaches were explored, which have the advantage of high transparency and traceability compared to learning-based methods. However, it was shown that rule-based extraction approaches only extract between 87% and 97% of elements. This is not sufficient for industry applications as standards users demand that 100% of the relevant information is extracted and provided correctly. The authors highlighted that the main reason for this limitation is the usage of the NISO STS tagging suite as well as the representation of mathematical objects in Presentation MathML 3.0. Thus, the XML markup is optimized for rendering and readability but not for automatic processing by machines [,]. The current representation of formulas in XML standards does not enable machine execution or machine interpretation. To reach Level 3 or Level 4 standards content, other approaches of knowledge representation have to be explored.
2.3. Machine-Executable Knowledge Representation Using Knowledge Graphs
To provide semantically structured information that is interpretable by machines, knowledge graphs can be used [,]. Knowledge Graphs (KGs) represent knowledge in a graph-based data structure and aim to describe real-world entities as well as their interconnected relationships through nodes and edge. This structure forms so called triples (entity, relation, entity) [], whereas the underlying data structure is referred to as an ontology []. Introduced by Google in 2012, KGs have caused wide concern in industry and academia where the main applications are question answering, recommender systems, and information retrieval []. KGs have been utilized in different industries, such as precision dairy farming for data integration [], electronic health records for semantic interoperability [], nursing big data visualization [], and sound and music recommendation systems []. These applications demonstrate the versatility of KGs in representing domain-specific knowledge, enhancing data integration, and supporting decision-making processes across various industries.
Taheriyan et al. discussed a methodology for the automated learning of semantic models applicable to structured data sources to facilitate their integration and publication within knowledge graphs []. Within the geoscience domain, ontologies have been harnessed to surmount challenges associated with data management and exchange, as highlighted by Parekh et al. []. Brochhausen et al. demonstrated the critical role of “axiomatically-rich ontologies” in validating mappings between prevalent data models, thus facilitating the transformation of data into knowledge []. In the context of emergency management, ontologies function as a universal language, enabling the alignment of disparate standards, as noted in []. Lastly, in the field of rare disease research, Roos et al. acknowledged the pivotal role of ontologies and semantic data models in readying data for integration and securing interoperability across diverse data repositories [].
Because product development is characterized as a knowledge-intense activity [], KGs offer great advantages for efficient knowledge retrieval and management. Examples range from design knowledge acquisition from design rules for generating product concepts [] and supporting context-aware cognitive design assistants [] to the automatic construction of KGs from patents [] and standards [,]. In the domain of standards, KGs are used to structure mathematical information as well as contextual elements to achieve machine executability []. Additionally, automation approaches for constructing knowledge graphs from XML standards were investigated to reduce the manual efforts of transferring standards content to knowledge graphs []. As the authors identified the incorrect application of the XML tagging suite as well as missing semantic markup elements, this research focused on defining an appropriate markup schema to ensure correct retrieval of information for machine-execution.
2.4. Practical Application Approaches for the Definition and Exchange of Information
The definition and standardization of information are crucial components that enable seamless communication and interoperability across various systems and processes. One concept for the predefinition of information is the Quality Information Framework (QIF), which is defined by the ISO 23952 standard []. The QIF model is an architecture that defines information from the manufacturing industry in a standardized and interoperable way. The model enables the effective exchange of metrology data throughout the manufacturing quality measurement process. This includes everything from product design and inspection planning to execution, analysis, and reporting. This should enable QIF users to understand the organization of the information model without having to delve into the technical details of XML schemas.
The Requirements Interchange Format (ReqIF) is a standardized XML-based format designed to facilitate seamless exchange of requirements between different tools and stakeholders in complex systems engineering environments [,]. It supports traceability, version control, and collaboration across distributed software projects []. ReqIF allows for the encapsulation of both textual and graphical information, making it flexible enough to accommodate various requirements data []. The format is particularly useful in supplier–customer relationships, helping to mitigate risks and manage complex collaborations [].
AutomationML [] is an open, XML-based data exchange format that is standardized in IEC 62714. It comprises three formats: CAEX for the structure and relationships of production systems, COLLADA for geometry and kinematics, and PLCopen XML for logical descriptions. The syntax uses XML tags such as <InternalElement> for objects, <ExternalInterface> for interfaces, and <Attribute> for properties. The semantics are modeled using <RoleClass> for objects and <InterfaceClass> for interfaces. Objects can be assigned several <RoleClass>, while interfaces can only have one <InterfaceClass>. <RoleClass> and <InterfaceClass> are defined in a library that enables inheritance relationships. Objects can also be defined in advance as <SystemUnitClass> in a library and instantiated multiple times.
3. Analysis of Information Backflow
In order to address the issue described above, a comprehensive two-part approach is proposed. The first part entails the establishment of a standardized format for the representation of test specifications within standards and directives. For this, the existing NISO STS tagging suite will be enhanced by introducing additional so-called semantic markup elements. This serves as a foundation for machine-executable standards, whereas the second part involves the transfer of this test-relevant information into a generic data model, thereby incorporating relationships between information elements and ensuring its accurate application during the development of digital representations. To achieve this, first a detailed analysis will be conducted on the nature of test specifications, with a particular focus on the utilization of mathematical information within these specifications.
3.1. Analysis of Test Specifications in Standards
According to DIN EN 45020 “Standardization and related activities—General vocabulary”, standards can be assigned to specific classes, including product standards, process standards, and test standards []. While product standards as well as test standards are widely used in industry [], the latter are of particular importance for this research as they define standardized test specifications and ensure comparability within the industry. These test specifications are sometimes supplemented by other elements, such as sampling, test sequences, or the use of statistical methods []. For a structured representation of test specifications in standards, ISO Directives Part 2 defines elements for describing measurement and test methods. This includes information about the principle, reagents and materials, apparatus, preparation and preservation of test samples, the test procedure, expression of results, including method of calculation, as well as the test report. Moreover, test specifications refer to product requirements that may occur in separate clauses in the same or in a separate document [].
Although the elements are defined in ISO Directives Part 2, an in-depth analysis of selected standards (see Table 1) is conducted to analyze the application of the rules and to identify key elements of test specifications as outlined in standards documents. For this, standards of different application areas—represented by the International Classification of Standards (ICS)—as well as standardization organizations are used so that the results are not biased toward specific application areas or forms of description of specific organizations. Regarding the areas of application, test standards from primarily technical, product-related ICS areas are analyzed. For example, ISO 898-1 from ICS area 21 “Mechanical systems and mechanical components” is examined. Additionally, standards from the ISO/IEC, CEN/CENELEC, and DIN organizations are employed, ensuring representation of national, European, and international levels (see Table 1). During analysis, the test methods described in each standard are identified and analyzed with respect to their structure (i.e., sections and subsections) as well as the provided information. As an example, ISO 898-1 defines 15 test methods to identify the mechanical properties of fasteners. These test methods are mostly structured according to the directive; however, additional information about the scope and boundary conditions are provided.

Table 1.
Analysis of standards.
In summary, the analysis of test specifications in selected standard documents reveals that the rules of the ISO Directives Part 2 are mostly applied correctly, and elements of a test specification are structured accordingly. The test specification begins with the name of the test method in the title of the section or chapter. Subsequently, the key elements are described in text sections, whereas the analyzed standards show that, in addition to general information, the boundary conditions and the scope are described in detail. The key elements of a test specification are summarized in Table 2. It is important to note that not every element is necessarily included in the analyzed standards. The core of the test specification comprises the test result and the requirements for the test result, which reflect information about the determination of actual values and the pass or fail status of a test. Results can be presented quantitatively (e.g., comparing a pressing force in kN with a target value) or qualitatively (e.g., the outcome of a visual inspection). For a conformity assessment, this information must be fed back and is part of the Pre-defined Information Backflow (PdIB). Additionally, the scope and the test procedure are other important elements of a test specification. Here, the process and any intermediate results are described, and requirements for the correct execution of a test are specified.
Table 2.
Key elements of a test specification.
3.2. Usage of Mathematical Elements in Test Specifications
Formulas hold significant practical relevance, especially within test procedures, due to their high interpretability compared to textual elements. The analysis of test standards indicates that test results and their corresponding requirements often encompass mathematical information. This information may be explicitly presented as mathematical equations or inequalities or implicitly embedded within the text. The analysis reveals that formula information can manifest in various forms, detailed as follows:
- Pure formula: Presented solely in mathematical notation without additional context. This format precisely defines mathematical relationships but necessitates linking variables to their respective symbols and definitions.
- Textual formula: Describes mathematical equations using prose instead of formal notation. Due to the inherent ambiguity and lack of strict rules in prose, processing such information is limited.
- Mixed formula: Combines mathematical notation with supplementary components to elucidate, contextualize, or specify the application scope of the formula. These components can be textual or mathematical, such as boundary condition descriptions, enhancing the formula’s comprehensibility and applicability.
The study indicates that a mapping between the components of the formula module and elements of test specifications is conceivable. The primary component—the mathematical equation—corresponds to the test result, representing the calculation of a test value compared against a target. Additional details about the test procedure, intermediate calculations, etc., align with the components “Description” and “Boundary Conditions” of the formula module, as they provide additional information or define the formula’s applicability and correct usage. This forms the foundation of the approach presented in Chapter 5.
While the formula components represent the semantic framework of the formula module, their utilization in XML can be further specified. Current XML standards employ markup elements defined in the NISO STS standard, primarily focusing on structural elements like paragraphs or mathematical expressions. Regarding the formula module, explicit tagging of components is absent. Only the mathematical equation is tagged with <disp-formula>, adhering to the MathML 3.0 notation. Presently, XML standards utilize Presentation MathML, emphasizing the rendering of mathematical expressions. However, this approach does not fully capture the semantics—the meaning of individual operations and their interconnections—thereby limiting machine executability. Other formula components are predominantly textual and embedded within paragraphs, represented by the <p> tag in NISO STS. A special case is the boundary condition, often containing mathematical information like value ranges, which are marked within the <p> tag using additional elements like <inline-formula>. This demonstrates that the current representation of formula components in XML standards has limited capabilities for automatic processing in machines (machine executability) and needs to be enhanced by additional semantic markup elements as well as a semantically enriched mathematical markup.
4. Development of a Data Model for the Value-Related Definition of Pre-Defined Information Backflow
Based on the findings of Chapter 3, the conclusion is drawn that a fully mathematical representation of the proposed Pre-defined Information Backflow (PdIB) in the context of its formulas and the associated components and conditions is inevitable. The approach developed for this systematic feedback of instance-related information with the so-called “Instantiation Blocks” [,] starts with the correct definition of this information. The term Instantiation in this context refers to information to be instantiated, i.e., assignable to physical instances, and was developed and introduced in previous publications by Layer et al. [,]. The concept of Instantiation Blocks serves to facilitate and enable the assignment and merging of all relevant information in connection with a physical instance and extends the data model to include the real relationship between the data and the physical components in the industrial environment.
This relevant information is often generated by manufacturing, commissioning, or testing and quality processes and is linked to physical components. The focus here is on the description and modeling of the result data as information backflow in the context of its creation processes and components. The data model developed is designed for the industrial environment and addresses requirements in both production technology and the process industry.
The central element of the supporting developed data model (see Figure 6) is therefore the “Value” entity, which is described by the “Information Format” entity through the “DescribedBy” relation. The “Value” entity is related to various “Values” via the “Result Relation” entity and enables comparisons to be made between the actual values that arise and the target values through the “ConsistsOf” relation. With the “Combination” relationship, several “Result Relation” can be represented through AND or OR links.
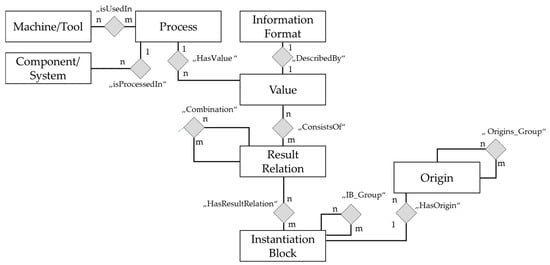
Figure 6.
Data model for pre-defining information backflow.
The “Process” entity is linked to “Value” through the “HasValue“ relation and establishes the link to the processed or treated “Component/System” and the “Machine/Tool” used.
In addition, the above-mentioned “Instantiation Block” is integrated into the data model as an entity and linked to the Result Relation entity through the “HasResultRelation” relation. The respective Instantiation Blocks can be grouped hierarchically with “IB_Grouped” and are linked to an “Origin” entity via the “hasOrigin” relation in order to link the origin of the requirement of the pre-defined information.
The proposed data model is converted into a graph in the next step, allowing the structure and relationships to be visualized and modeled. The “Value” entity and its relation to “Result”, “Combination”, and “Process” is represented in the form of nodes and edges in the graph, making dependencies and comparisons between actual and target values visible. The integration of the “Instantiation Block” entity enables the assignment and merging of all relevant information in connection with a physical instance, thus forming the link in the test definition.
The hierarchical grouping and the link to the “Origin” entity means that the origin of the requirements for the pre-defined information can not only be traced but also analyzed. This conversion makes it possible to evaluate the quality of the result data, identify dependencies and correlations, and examine the effectiveness and efficiency of the processes in an industrial environment. The graph-based representation allows the application of analysis techniques such as network analysis, pattern recognition, and visualization to gain new insights and support data-driven decisions.
Figure 7 presents a process of information analysis in the context of the developed data model. This begins with an identified piece of information, which can be assigned to a physical component.
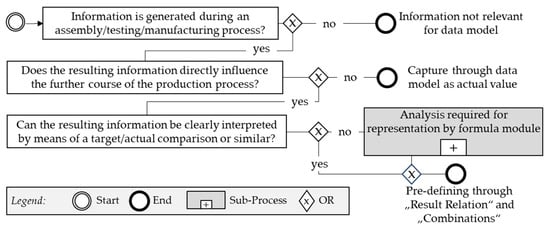
Figure 7.
Information analysis flow in BPMN notation.
In the final step, the developed data model is combined with the basic elements of test specifications as well as the formula module introduced in Chapter 3. This combination enables a structured and machine-readable representation of the mathematical information contained in standards and test specifications. The basic elements of test specifications and the formula module are combined into three overarching markup elements that can be defined in XML tags, as follows:
- General information: This information includes general notes and contextual information that are necessary for understanding and correctly applying the test specification. They are displayed in the formula module as descriptive information and embedded in XML tags.Example: <general-information>General information on the test specification</general-information>
- Fulfillment criterion: These are the mathematical equations or inequalities that define the criteria for passing or failing a test. These formulas are displayed in the formula module as the element “mathematical equation”.Example: <disp-formula>ΔP_gauge < 0.025 * P_gauge_initial</disp-formula>
- Boundary conditions: These conditions define the specific circumstances or parameters under which the test specification is applied. They are displayed in the formula module as boundary conditions and are also embedded in XML tags.Example: <boundary-condition>System pressure must be between 100% and 110% of the maximum operating overpressure</boundary-condition>
A particular focus is on the isolated representation of the values used in the test specifications. These values must be clearly represented in XML tags to ensure precise and machine-readable processing. This makes it possible to extract and analyze the values independently of their context. By embedding the mathematical representation in the formula module and using specific XML tags, the applicability of the test specifications is significantly improved. This creates a basis for machine executability and interpretation of standards content and contributes to increased efficiency in product development and quality assurance.
5. Approaches for Integrating the Data Model into Existing Standards
The previously introduced data model for the value-related definition of Pre-defined Information Backflow (PdIB) serves as a basis for developing the approach presented in this chapter. First, an XML schema for test specifications in standards is described that allows for the automatic processing of standards content (machine executability) as well as the conversion of test relevant information into the data model and its combination with product structures for practical application. Moreover, the update methodology will be described.
5.1. Application-Oriented Definition in XML Format
In order to integrate the developed data model into existing standards, the extension of the current NISO STS standard is proposed. Hereby, the XML data format is retained and standards documents are enriched by semantic markup elements. Based on the problems identified above, it is necessary to differentiate between two areas: Firstly, the semantically unambiguous labeling of mathematical equations or expressions to make mathematical information executable and interpretable; and secondly, the conversion of previously identified information elements of the data model (see Chapter 4) into XML tags and their assignment to the formula module.
With regard to the labeling of mathematical equations, MathML markup in the form of Presentation MathML is used today. Presentation MathML is used for the pure graphical representation of the components of a mathematical expression, which are represented using around 30 different elements. These are listed in reading order, i.e., from left to right, which keeps the structure of the formula simple. As today’s XML standards are designed with high readability in mind and aspects of machine executability are neglected, Presentation MathML fulfills previous purposes. However, the automatic evaluation of mathematical expressions in Presentation MathML is limited and not sufficient for the purpose of this research, which requires semantically rich mathematical modeling languages. Solutions for this are OpenMath and Content MathML, which break down mathematical expressions into individual arithmetic operations and execute them according to the top–down principle from higher-level to lower-level calculations. Due to the current use of Presentation MathML, the use of Content MathML is proposed, as the current presentation layer only needs to be supplemented by the content layer.
Content MathML is centered around the <apply> element, which announces a calculation operation and is followed by a tag that determines the type of calculation (e.g., <plus/>) as well as the respective elements that are used within this calculation. In this way, misinterpretations or inconsistent calculation sequences can be prevented by a user or other software, as the step-by-step application of the formula is clearly specified. The individual elements can also be assigned properties that are stored in so-called content libraries. When reading these properties, the formula components are given semantics.
In order to process the test specifications automatically and transfer them from a standards document to the data model, it is necessary to process contextual information in addition to the unambiguous description of mathematical expressions. For this, the elements of the formula module are used. This requires a clear definition of XML tags and thus extension of the NISO STS standard. This extension can be realized by either revising the underlying XML schema or by using the specific NISO STS element <named-content> within the existing tag suite. The latter offers the advantage that the data schema of the XML does not have to be adapted, thus reducing the change effort. The element name is defined via the content type attribute, e.g., <named-content content-type=“general information”> General information on the test specification </named-content>
With the help of the elements described above, the semantic markup of the formula components can be carried out, which is then used for transferring standards content to the data model. The proposal also integrates the elements of the test specification so that simple identification and processing of test specifications with mathematical information can be realized. This results in the following XML structure:
- Enclosing tag: <named-content content-type=“test case” name=”example”>This tag encloses the entire test specification and provides the context for the information it contains.
- General information: <named-content content-type=“general information”>This tag contains general notes and contextual information on the test specification.
- Fulfillment criterion: <named-content content-type=“fulfillment criterion”>
This tag contains the result of the test and the corresponding mathematical equation or inequality.
- Boundary condition: <named-content content-type=“boundary condition”>
This tag contains the specific conditions under which the test specification is applied.
By presenting test specifications in this structure, test-relevant information can be automatically identified via tags and processed automatically. Thus, the correct formulation and tagging should already be taken into account by the standardization groups during the creation of the standards. This would make the machine executability and interpretability of standards considerably easier and increase efficiency in product development and quality assurance. The standardized classification and provision of information in XML tags enables companies to extract and apply the relevant data more quickly and precisely.
5.2. Combination with Product Structure and Integration in Data Model
The combination of the developed XML standard with the product structure is a crucial step to ensure the machine executability and integration of the standard content into industrial processes. In order to combine the developed XML standard with the components of a Bill of Materials (BOM), a parser transfers the XML markup to the data model and establishes a mapping between standards contents and physical instances. This mapping can also be realized via a classification approach.
Steps for the combination:
- Identification of the relevant elements: First, the relevant elements of the BOM and the XML standard are identified. This includes the product components, their classifications and test specifications, as well as the test requirements.
- Creation of the mapping: A mapping is created between the tags of the XML standard and the elements of the BOM. This includes the assignment of the test requirements to the corresponding product components and their classifications.
- Integration of elements: The elements of the XML standard are integrated into the data model and linked to the BOM.
- Validation: The combined structure is validated to ensure that the test information is correctly integrated into the product structure and can be processed automatically.
5.3. Update Methodology in the Event of Changes to the Standard or Product Structure
The update methodology in the event of changes to the standard or product structure is of central importance in order to ensure that information is consistent and up-to-date in a dynamic industrial environment. A systematic approach to standardizing mapping, performing delta analysis, and integrating change notifications is essential.
To ensure that changes in standards or product structures are processed efficiently and consistently, standardization of the mapping between the standard content and the data model is required. This includes the definition of rules and procedures for assigning standard elements to the corresponding entities in the data model. Past mappings must be taken into account so that existing assignments are not lost and the consistency of the data is maintained. This includes the implementation of a versioning system for the mapping, the development of tools for automatic differentiation and comparison of mapping versions, and ensuring the backwards compatibility of new mapping versions.
Delta analysis plays a decisive role in the identification of changes in standards or product structures. Change notifications are created in a standardized format such as XML. This includes the development of algorithms for the automatic identification of changes, the generation of change notifications, and the automatic integration of changes into the data model based on these notifications.
For common changes to the product, standardized change processes are used to ensure a structured and traceable implementation of the changes. The process begins with the submission of a change request by the person or department responsible. The change request is then evaluated by a committee or a responsible body. After the evaluation, the change is approved by the responsible decision makers. Once the change has been approved, it is implemented in the affected documents and systems and finally documented to ensure the traceability and consistency of the information.
6. Representative Validation
To illustrate the validation, examples from two standards will be used. The first standard describes the test procedures for pressurized parts, whereas the second standard defines tests for identifying the mechanical properties of fasteners. The following sections will provide insight into the preparatory steps of transferring standard content into the previously defined XML markup, which is used to automatically create the data model for PdIB.
6.1. Leak Testing
The first validation standard describes the test procedures for pressurized parts, where the example used focuses on leak testing (see Figure 8).

Figure 8.
Leakage test according to exemplary standard.
To prepare standards content for its usage in the previously introduced data model for Pre-defined Information Backflow, the textual description of mathematical elements is first converted to a mathematical representation. These elements are identified manually (see Table 3), whereas the automatic conversion of textual elements into mathematical representation will be part of future work. Moreover, the allocation to markup elements shows that, although each category contains mathematical elements, especially the fulfillment criteria need to be modeled as mathematical elements in order to ensure machine executability.
Table 3.
Conversion of textual description to mathematical representation.
Afterward, the prepared standards content is converted to the extended NISO STS XML format, which was introduced in Section 5.1. Therefore, textual and mathematical elements are allocated to markup elements and modeled accordingly, e.g., by considering the rule of the markup language Content MathML. The complete XML script can be found in Appendix A, while the excerpt in Figure 9 contains the overarching markup elements without a detailed description.

Figure 9.
Excerpt of XML markup for exemplary test specifications.
The resulting XML script, including the overarching XML markup elements “General information”, “Fulfillment criterion”, and “Boundary conditions” as well as the detailed, content-oriented mathematical modeling in Content MathML fulfill the requirements of machine-executable standards content and ensure that the test procedure can be automatically transferred to the data model (see Figure 10), which was introduced in Chapter 4. For this, a parser identifies the XML markup elements, separates mathematical information elements, and transfers this to the data model. Additionally, the test system is linked to the actual BOM element. Hereby, the actual and target values are being defined within the “Value” table. The “Result Relation” table holds both the fulfillment criterion and boundary condition, with links to the value IDs.
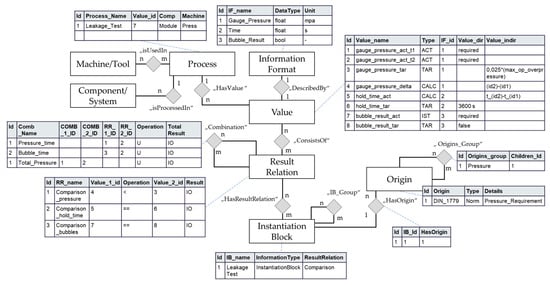
Figure 10.
Resulting data model with selected visualized tables.
6.2. Test Specifications for Mechanical Properties of Fasteners
The second validation standard, which defines tests for identifying the mechanical properties of fasteners, contains 15 test specifications for bolts, screws, and studs. These range from tensile tests to torsional tests as well as retempering tests. All test specifications were used for validation of the proposed approach. In comparison to the example described in Section 6.1, several tables are referenced in the test specifications that are used to retrieve threshold values for passing or failing tests. Moreover, the standard contains mathematical equations for calculating values that are used for comparison and serve as the starting point for transferring the standard content into machine-executable format.
As an example, the following paragraphs describe the tensile test under wedge loading of finished bolts. It is structured into six overall sections: “General”, “Applicability”, “Apparatus”, “Testing device”, “Test procedure”, and “Test results”. The information for PdIB can be found in the sections “Test procedure” and “Test results”, however, boundary conditions are referenced and combined in tables and need to be created for all different variants. For validation, the properties of an M8 bolt with property class 6.8 were chosen. As displayed in Figure 11, the value to be measured is (the ultimate tensile load), while the fulfillment criterion is that the resulting calculated (tensile strength) needs to be higher than the fulfillment criterion of 600 MPa, as described in the table attached. can be calculated based on the displayed formulas.
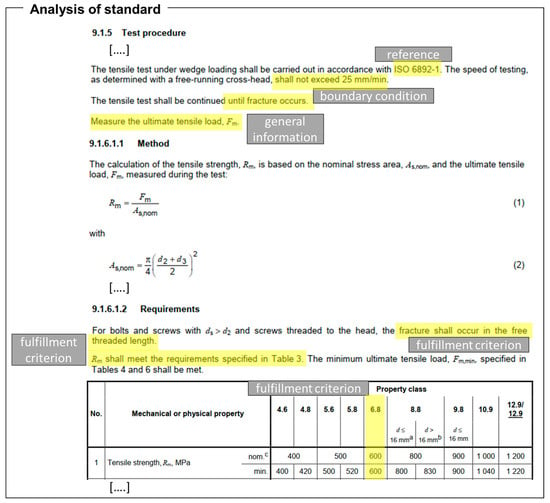
Figure 11.
Bolt tensile test according to ISO 898-1.
In the case of bolt tensile testing, the primary value of interest is , the ultimate tensile load, analogous to the pressure delta (∆gauge_pressure) in the leak testing example. The design values and correspond to the maximum operating pressure in the previous use case, serving as a reference for the acceptable range of mechanical properties.
The requirement that “fracture shall occur at the free threaded length” is conceptually similar to the absence of bubble formation in leak testing, as both criteria are qualitative indicators of a successful test outcome. Furthermore, the comparison of the resulting ultimate tensile strength to the predefined standard of 600 MPa mirrors the quantitative assessment in leak testing, where the measured pressure drop is evaluated against a percentage of the initial gauge pressure.
The conversion of textual descriptions to mathematical representations is a critical step for enabling machine executability. In this context, the values of , , and are again defined within the “Value” table of the data model, while the “Result Relation” table captures the fulfillment criteria and boundary conditions, establishing the necessary links to the corresponding value IDs. In the extended NISO STS XML format, each test specification element is semantically marked up to facilitate automatic identification and processing. This includes general information about the test, the mathematical formulation of the fulfillment criteria, and the explicit boundary conditions under which the test is valid. The application of Content MathML ensures content-oriented mathematical modeling that machines can interpret and execute, thereby aligning with the methodology outlined in Section 5.1.
7. Discussion
The validation examples prove the overall applicability of the proposed approach. The structure of the formula module (described in Section 2.2) serves as basis for defining a machine-executable XML markup that can be automatically transferred to the data model, as defined in Chapter 4. The combination of both elements leads to the approach for pre-defining the information backflow of physical instances (see Figure 12). While the semantically enhanced XML markup formally satisfies the requirements of Level 3 standards, combination with the data model ensures that the relationships between test values, calculations, and boundary conditions are considered. Thus, information backflow can be carried out automatically without transmission errors. This serves as a step toward Level 4 machine-interpretable standards.
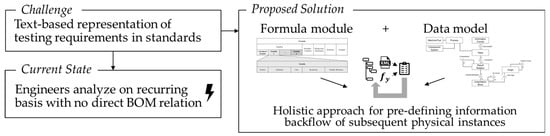
Figure 12.
Two-part approach in the context of standards-based test specifications.
7.1. Benefits of the Proposed Approach
Implementation of the approach described offers numerous potentials and solutions that can significantly improve the efficiency and accuracy of information processing from standards and directives:
- Structured data: The use of XML tags and standardized data models significantly improves the machine executability of the information. This enables efficient and error-free processing of the data by automated systems. The definition of semantic XML markup elements (see Section 5.1) is necessary for reaching Level 3 standards according to [] and is the foundation for realizing automated approaches based on standards content. In contrast to existing solutions for automated standards processing (for example, [,,,]), the enhanced XML markup simplifies post-processing activities as the content is identified based on its tags. This ensures that information is extracted and processed with 100% accuracy. In addition, the application of the data model, which can be characterized as ontology, structures not only entities but also their interrelations and dependencies. This serves as a foundation for automating the processing of test-relevant information and correct information backflow overall.
- Precise allocation: The clear and structured presentation of the information enables precise allocation of the data to the corresponding processes and components. This improves the traceability and consistency of the data and supports quality assurance.
- Automated updating: The system, which is developed for displaying, automatically recognizing, and updating changes in standards and test specifications, ensures that the data are always up-to-date and consistent. Because of the semantically enhanced XML markup, changes can be analyzed more efficiently. In the case of updates, the data model is adapted automatically and recurring efforts of engineers are reduced.
7.2. Integration Challenges
The integration of the data model into existing standards poses various challenges. One major challenge is the adaptation of the existing NISO STS XML schema in order to integrate the newly introduced semantic tags. While the schema already allows for the definition of additional markup elements through the element “named-content”, the naming and application of the proposed elements need to be standardized as well to ensure consistency and compatibility. This must be managed by international standardization organizations, such as ISO, to not limit the approach to specific countries, similar to the proposed markup elements for requirements, as described in []. Here, the main challenge is updating the standards corpus and enhancing XML documents by adding markup elements. Two distinct ways are conceivable: manual and semi-automatic extension. While the manual extension of standard documents leads to high efforts in terms of time and costs, the semi-automatic approach can leverage research results for the automatic extraction of formulas and their components (see [,]) in order to automatically add semantic tags to existing XML standards. As these solutions are limited in terms of accuracy, manual checks have to be integrated to ensure correctness of content.
If machine-executable standards containing test-relevant information are provided by standardization organizations, standards users will not interact with documents and manually retrieve information. The information will be automatically assigned to the data model and standards users will interact with the content via the data model. This significantly simplifies the workflow of processing standards.
In addition to XML standards, compatibility with other common classification structures, such as eCl@ss [] or roleClasses of AutomationML, have to be considered. This is currently not considered in the proposed approach and will be part of future work.
7.3. Limitations
While the proposed approach has demonstrated significant advantages in the structured representation and machine readability of pre-defined information backflow, there are inherent limitations that must be acknowledged, particularly regarding the handling of complex graphical elements. The focus on mathematical content has enabled precise definition and automated processing of formulas and calculations, which are central to testing and compliance in the industrial sector. However, the validation examples have shown that elements like graphs, curves, and tabular content are often referenced to the test relevant procedures.
These tables and graphs combine several conditions in a compact format, which is optimized for human readability but not for machine execution. This is illustrated by the fulfillment criterions depending on property classes and the nominal thread diameter d of the example shown in Section 6.2, illustrated in Figure 11.
The approach of this paper has examined information in such a form through a look-up table. Future research needs to look into extracting information from this visual form and, more importantly, defining an optimized format for the XML-based representation of tables and graphical elements.
8. Conclusions and Outlook
This article addresses the structured presentation of information that is embedded in standards and directives as part of formulas and test specifications. This information is essential for data-driven product development processes and the creation of digital representations. Despite this crucial role, the machine-readable representation and tangibility of this information is a recurring challenge. The model developed focuses on the result data generated by testing within manufacturing or commissioning and quality processes that are linked to physical components in the industrial environment. The structure of the data model was enriched using XML tags to enable integration into existing standards. The concept was developed, tested, and discussed within the plant engineering domain, as this is characterized by a gap between information definition and information backflow due to on-site commissioning requirements. However, the overall principles developed can be applied in other domains where test specifications from standards and directives are defined and used for information tracking. The definition of a data model and the XML-based description can serve as a basis for further automation of test sequences and their execution.
For future research, it is envisaged to represent the test sequence as a flowchart in order to realize complete machine executability. This allows the test sequences to be represented clearly and in a machine-executable manner, which in turn enables automated processing of the information and facilitates transfer to the data model. Furthermore, the authors propose the development of a reference architecture, particularly in the areas of application-related special tests. Ultimately, the authors suggest that certifying bodies and institutions (TÜV, etc.) should be more closely involved in the process and data exchange in order to reduce redundancies and inefficiencies in testing.
Author Contributions
Conceptualization, M.L. and J.L.; Methodology “Data model for PDiB”, M.L.; Methodology “Standards content processing”, J.L.; Validation, M.L. and J.L.; Writing—original draft preparation, M.L. and J.L.; Writing—review and editing, R.S. and A.N.; Visualization, M.L.; Supervision, R.S. and A.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are derived from standards that are available in repositories such as Nautos (for DIN standards) at https://nautos.de/ (accessed on 11 December 2024).
Conflicts of Interest
Author Max Layer was employed by the company Siemens Energy Global GmbH & Co. KG. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A
The following XML script contains the complete representation of the exemplary test specification (see Chapter 6) in a machine-readable and machine-executable format:
- <named-content content-type=“test case” name=”Leak testing”>
- <named-content content-type=“ general information”>
- <p>Recorded values: gauge pressure at t<sub>1</sub> and t<sub>2</sub></p>
- <p>Reference: DIN EN 1779</p>
- <p>Test system: Pressurized part</p>
- <disp-formula name=”gauge_pressure_delta”>
- <math xmlns=“http://www.w3.org/1998/Math/MathML”>
- <apply>
- <eq/>
- <ci>gauge_pressure_delta</ci>
- <apply> <minus/>
- <ci>gauge_pressure_act_t2</ci>
- <ci>gauge_pressure_act_t1</ci>
- </apply>
- </apply>
- </math>
- </disp-formula>
- </named-content>
- <named-content content-type=“fulfillment criterion”>
- <disp-formula name=”comparison_pressure”>
- <math xmlns=“http://www.w3.org/1998/Math/MathML”>
- <apply>
- <lt/>
- <ci>gauge_pressure_delta</ci>
- <apply>
- <times/>
- <cn>0.025</cn>
- <ci>gauge_pressure_act_t1</ci>
- </apply>
- </apply>
- </math>
- </disp-formula>
- <disp-formula name=”comparison_hold_time”>
- <math xmlns=“http://www.w3.org/1998/Math/MathML”>
- <apply>
- <eq/>
- <apply>
- <minus/>
- <ci>t_2</ci>
- <ci>t_1</ci>
- </apply>
- <apply>
- <times/>
- <cn>30</cn>
- <ci>minutes</ci>
- </apply>
- </apply>
- </math>
- </disp-formula>
- <disp-formula name=”comparison_bubbles>
- <math xmlns=“http://www.w3.org/1998/Math/MathML”>
- <apply>
- <eq/>
- <ci>bubble_formation</ci>
- <false/>
- </apply>
- </math>
- </disp-formula>
- </named-content>
- <named-content content-type=“boundary condition”>
- <disp-formula name=”gauge_pressure_act”>
- <math xmlns=“http://www.w3.org/1998/Math/MathML”>
- <apply>
- <and/>
- <apply>
- <geq/>
- <ci>gauge_pressure_max</ci>
- <ci>gauge_pressure_ist</ci>
- </apply>
- <apply>
- <geq/>
- <ci>gauge_pressure_ist</ci>
- <ci>gauge_pressure_min</ci>
- </apply>
- </apply>
- </math></disp-formula></named-content>
References
- Deutsches Institut für Normung. Deutsche Normungs-Roadmap: Industrie 4.0; Deutsches Institut für Normung: Berlin, German, 2023. [Google Scholar]
- Bader, S.R.; Grangel-Gonzalez, I.; Nanjappa, P.; Vidal, M.-E.; Maleshkova, M. A Knowledge Graph for Industry 4.0. In The Semantic Web; Harth, A., Kirrane, S., Ngonga Ngomo, A.-C., Paulheim, H., Rula, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 465–480. [Google Scholar] [CrossRef]
- Luttmer, J.; Ehring, D.; Pluhnau, R.; Kocks, C.; Nagarajah, A. SMART standards: Modularization approach for engineering standards. In Proceedings of the ASME 2022 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, St. Louis, MI, USA, 14–17 August 2022; American Society of Mechanical Engineers: New York, NY, USA. [Google Scholar] [CrossRef]
- Keidel, A.; Eichstadt, S. Interoperable processes and infrastructure for the digital transformation of the quality infrastructure. In Proceedings of the 2021 IEEE International Workshop on Metrology for Industry 4.0 & IoT (MetroInd4.0&IoT), Rome, Italy, 7–9 June 2021; pp. 347–351. [Google Scholar] [CrossRef]
- Luttmer, J.; Ehring, D.; Pluhnau, R.; Nagarajah, A. Representation and Application of Digital Standards using Knowledge Graphs. Proc. Des. Soc. 2021, 1, 2551–2560. [Google Scholar] [CrossRef]
- Melluso, N.; Grangel-González, I.; Fantoni, G. Enhancing Industry 4.0 standards interoperability via knowledge graphs with natural language processing. Comput. Ind. 2022, 140, 103676. [Google Scholar] [CrossRef]
- Saske, B.; Schwoch, S.; Paetzold, K.; Layer, M.; Neubert, S.; Leidich, J.; Robl, P. Digitale Abbilder als Basis Digitaler Zwillinge im Anlagenbau: Besonderheiten, Herausforderungen und Lösungsansätze. Ind. 4.0 Manag. 2022, 2022, 21–24. [Google Scholar] [CrossRef]
- Layer, M.; Neubert, S.; Boda, B.; Stelzer, R. Towards a Framework for Identifying Relevant Information in regard to Specific Context on the Use Case of Standards and Directives. In Proceedings of the 34th Symposium Design for X (DFX2023), Dresden, Germany, 14–15 September 2023; pp. 235–244. [Google Scholar]
- Hakala, K.; Pyysalo, S. Biomedical Named Entity Recognition with Multilingual BERT. In Proceedings of the 5th Workshop on BioNLP Open Shared Tasks, Hong Kong, China, 4 November 2019; Jin-Dong, K., Claire, N., Robert, B., Louise, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 56–61. [Google Scholar] [CrossRef]
- Puccetti, G.; Giordano, V.; Spada, I.; Chiarello, F.; Fantoni, G. Technology identification from patent texts: A novel named entity recognition method. Technological Forecasting and Social Change. Technol. Forecast. Soc. Chang. 2023, 186, 122160. [Google Scholar] [CrossRef]
- Weston, L.; Tshitoyan, V.; Dagdelen, J.; Kononova, O.; Trewartha, A.; Persson, K.A.; Ceder, G.; Jain, A. Named Entity Recognition and Normalization Applied to Large-Scale Information Extraction from the Materials Science Literature. J. Chem. Inf. Model. 2019, 59, 3692–3702. [Google Scholar] [CrossRef] [PubMed]
- Hey, T.; Keim, J.; Koziolek, A.; Tichy, W.F. NoRBERT: Transfer learning for requirements classification. In Proceedings of the 2020 IEEE 28th International Requirements Engineering Conference (RE), Zurich, Switzerland, 31 August–4 September 2020; pp. 169–179. [Google Scholar] [CrossRef]
- Binkhonain, M.; Zhao, L. A review of machine learning algorithms for identification and classification of non-functional requirements. Expert Syst. Appl. X 2019, 1, 100001. [Google Scholar] [CrossRef]
- Winkler, J.; Vogelsang, A. Automatic classification of requirements based on convolutional neural networks. In Proceedings of the 2016 IEEE 24th International Requirements Engineering Conference Workshops (REW), Beijing, China, 12–16 September 2016; pp. 39–45. [Google Scholar]
- Fritz, S.; Srikanthan, V.; Arbai, R.; Sun, C.; Ovtcharova, J.; Wicaksono, H. Automatic Information Extraction from Text-Based Requirements. Int. J. Knowl. Eng. 2021, 7, 8–13. [Google Scholar] [CrossRef]
- Bareedu, Y.S.; Frühwirth, T.; Niedermeier, C.; Sabou, M.; Steindl, G.; Thuluva, A.S.; Tsaneva, S.; Ozkaya, N.T. Deriving semantic validation rules from industrial standards: An OPC UA study. Semant. Web 2024, 15, 517–554. [Google Scholar] [CrossRef]
- de Ribaupierre, H.; Cutting-Decelle, A.-F.; Baumier, N.; Blumental, S. Automatic extraction of requirements expressed in industrial standards: A way towards machine readable standards? arXiv 2021, arXiv:2112.13091. [Google Scholar]
- Zhang, J.; El-Gohary, N.M. Semantic NLP-Based Information Extraction from Construction Regulatory Documents for Automated Compliance Checking. J. Comput. Civ. Eng. 2016, 30, 04015014. [Google Scholar] [CrossRef]
- Tufek, N. Semantic information extraction from multi-modal technical document. In Proceedings of the 18th Iberian Conference on Information Systems and Technologies (CISTI), Aveiro, Portugal, 20–23 June 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Lamiroy, B. Interpretation, evaluation and the semantic gap…What if we were on a side-track? In Graphics Recognition. Current Trends and Challenges; Lamiroy, B., Ogier, J.-M., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 221–233. [Google Scholar] [CrossRef]
- Czarny, D.A.; Diemer, J.; Schacht, M.; Bulow, G. Scenarios for Digitizing Standardization and Standards; Management und Qualität: Berlin/Frankfurt, Germany, 2021. [Google Scholar]
- Eigner, M.; Stelzer, R. Product Lifecycle Management: Ein Leitfaden für Product Development und Life Cycle Management; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Bender, B.; Gericke, K. (Eds.) Pahl/Beitz Konstruktionslehre: Methoden und Anwendung Erfolgreicher Produktentwicklung, 9th ed.; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Loibl, A.; Manoharan, T.; Nagarajah, A. Procedure for the transfer of standards into machine-actionability. J. Adv. Mech. Des. Syst. Manuf. 2020, 14, JAMDSM0022. [Google Scholar] [CrossRef]
- Ehring, D.; Ferraz-Doughty, P.; Luttmer, J.; Nagarajah, A. A first step towards automatic identification and provision of user-specific knowledge: A verification of the feasibility of automatic text classification using the example of standards. Procedia CIRP 2023, 119, 1103–1108. [Google Scholar] [CrossRef]
- Deutsche Kommission Elektrotechnik (DKE). The Business Oriented Benefit of Smart Standards in Standard Application Process; Deutsche Kommission Elektrotechnik (DKE): Offenbach, Germany, 2024. [Google Scholar]
- Birner, N.; Gieschen, J.H.; Kudernatsch, W.; Moorfeld, R.; Weiler, P.; Schotten, H. Die Rolle der Normung 2030 und Gestaltungsoptionen unter Berücksichtigung der Technologiespezifischen Besonderheiten der IKT in der Normung und Standardisierung (Abschlussbericht). Studie im Auftrag des Bundesministeriums für Wirtschaft und Energie. 2017. Available online: https://www.bmwi.de/Redaktion/DE/Publikationen/Studien/rolle-der-normung-2030.pdf (accessed on 4 November 2024).
- Ziegenfuss, A. Digital Standards Systems—An Integrated Approach to Engineering Standards Usage; Society of Automotive Engineers: Warrendale, PA, USA, 2020. [Google Scholar]
- National Information Standards Organization. STS: Standards Tag Suite. 2017. Available online: https://groups.niso.org/higherlogic/ws/public/download/18492/Z39.102-2017.pdf (accessed on 4 November 2024).
- Both, M.; Franke, M.; Mummel, J.; Redeker, M.; Bergander, S.; Bülow, G.; Lindenstruth, T. Pilots of the Initiative Digital Standards (IDIS): Practival Usage of Smartö Standards. 2022. Available online: https://www.din.de/resource/blob/954746/47218fdee5bffc21e5a96f83e7f55a8e/din-dke-a4-idis-piloten-englisch--data.pdf (accessed on 2 November 2024).
- International Electrotechnical Commission (IEC). Unlocking the Potential of Smart Standards: A Deeper Dive into the Pilot Programme; International Electrotechnical Commission (IEC): London, UK, 2024. [Google Scholar]
- Günzroth, N.; Steinborn, A.; Luttmer, J.; Ehring, D. Neue Marktpotenziale durch die Anwendung von fragmentierten Normenbestandteilen am Beispiel von Formeln; DIN-Mitteilungen: Berlin, Germany, 2022. [Google Scholar]
- Luttmer, J.; Kandel, M.; Ehring, D.; Nagarajah, A. Automatic knowledge graph creation from engineering standards using the example of formulas. Proc. Des. Soc. 2024, 4, 423–432. [Google Scholar] [CrossRef]
- Zou, X. A Survey on Application of Knowledge Graph. J. Phys. Conf. Ser. 2020, 1487, 12016. [Google Scholar] [CrossRef]
- Song, A.; Yin, H.; Zhong, S.; Xu, M. Efficient semantic relationship and representation reconstruction based on knowledge graph. In Proceedings of the 2024 International Conference on Electrical, Computer and Energy Technologies (ICECET), Sydney, Australia, 25–27 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, Y.; Yu, S.; Chu, J.; Su, Z.; Cong, Y.; Wang, H.; Fan, H. Combining Deep Learning with Knowledge Graph for Design Knowledge Acquisition in Conceptual Product Design. Comput. Model. Eng. Sci. 2024, 138, 167–200. [Google Scholar] [CrossRef]
- Tomic, D.; Drenjanac, D.; Hoermann, S.; Auer, W. Experiences with creating a Precision Dairy Farming Ontology (DFO) and a Knowledge Graph for the Data Integration Platform in agriOpenLink. J. Agric. Inform. 2015, 6, 115–126. [Google Scholar] [CrossRef][Green Version]
- Sachdeva, S.; Bhalla, S. Using Knowledge Graph Structures for Semantic Interoperability in Electronic Health Records Data Exchanges. Information 2022, 13, 52. [Google Scholar] [CrossRef]
- Hussey, P.; Das, S.; Farrell, S.; Ledger, L.; Spencer, A. A Knowledge Graph to Understand Nursing Big Data: Case Example for Guidance. J. Nurs. Scholarsh. 2021, 53, 323–332. [Google Scholar] [CrossRef] [PubMed]
- Oramas, S.; Ostuni, V.C.; Di Noia, T.; Serra, X.; Di Sciascio, E. Sound and Music Recommendation with Knowledge Graphs. ACM Trans. Intell. Syst. Technol. 2017, 8, 1–21. [Google Scholar] [CrossRef]
- Taheriyan, M.; Knoblock, C.A.; Szekely, P.; Ambite, J.L. Learning the semantics of structured data sources. J. Web Semant. 2016, 37, 152–169. [Google Scholar] [CrossRef]
- Parekh, V.; Gwo, J.-P.J.; Finin, T. Ontology based semantic metadata for geoscience data. In Proceedings of the International Conference on Information and Knowledge Engineering, Las Vegas, NV, USA, 21–24 June 2004; pp. 485–490. [Google Scholar]
- Brochhausen, M.; Bona, J.; Blobel, B. The role of axiomatically-rich ontologies in transforming medical data to knowledge. In pHealth 2018; IOS Press: Amsterdam, The Netherlands, 2018; pp. 38–49. [Google Scholar]
- Gençtürk, M.; Evci, E.; Guney, A.; Kabak, Y.; Erturkmen, G.B.L. Achieving Semantic Interoperability in Emergency Management Domain; Springer: Berlin/Heidelberg, Germany, 2017; pp. 279–289. [Google Scholar]
- Roos, M.; López Martin, E.; Wilkinson, M.D. Preparing Data at the Source to Foster Interoperability across Rare Disease Resources. Adv. Exp. Med. Biol. 2017, 1031, 165–179. [Google Scholar] [CrossRef] [PubMed]
- Frishammar, J.; Lichtenthaler, U.; Rundquist, J. Identifying Technology Commercialization Opportunities: The Importance of Integrating Product Development Knowledge. J. Prod. Innov. Manag. 2012, 29, 573–589. [Google Scholar] [CrossRef]
- Huet, A.; Pinquié, R.; Segonds, F.; Véron, P. A cognitive design assistant for context-aware computer-aided design. Procedia CIRP 2023, 119, 1029–1034. [Google Scholar] [CrossRef]
- Siddharth, L.; Blessing, L.T.M.; Wood, K.L.; Luo, J. Engineering Knowledge Graph From Patent Database. J. Comput. Inf. Sci. Eng. 2022, 22, 021008. [Google Scholar] [CrossRef]
- Jiang, Y.; Gao, X.; Su, W.; Li, J. Systematic Knowledge Management of Construction Safety Standards Based on Knowledge Graphs: A Case Study in China. Int. J. Environ. Res. Public Health 2021, 18, 10692. [Google Scholar] [CrossRef] [PubMed]
- ISO 23952:2020; Automation Systems and Integration—Quality Information Framework (QIF): An Integrated Model for MANUFACTURING Quality Information 2020;25.040.40. ISO Copyright Office: Geneva, Switzerland, 2020.
- Monteiro, M.R.; Ebert, C.; Recknagel, M. Improving the exchange of requirements and specifications between business partners. In Proceedings of the 2009 17th IEEE International Requirements Engineering Conference (RE), Atlanta, GA, USA, 31 August–4 September 2009; pp. 253–260. [Google Scholar] [CrossRef]
- Ebert, C.; Jastram, M. ReqIF: Seamless Requirements Interchange Format between Business Partners. IEEE Softw. 2012, 29, 82–87. [Google Scholar] [CrossRef]
- Noyer, A.; Iyenghar, P.; Pulvermueller, E.; Pramme, F.; Bikker, G. Traceability and interfacing between requirements engineering and UML domains using the standardized ReqIF format. In Proceedings of the 2015 3rd International Conference on Model-Driven Engineering and Software Development (MODELSWARD), Angers, France, 9–11 February 2015. [Google Scholar]
- Adedjouma, M.; Dubois, H.; Terrier, F. Requirements exchange: From specification documents to models. In Proceedings of the 2011 16th IEEE International Conference on Engineering of Complex Computer Systems (ICECCS), Las Vegas, NV, USA, 27–29 April 2011; pp. 350–354. [Google Scholar] [CrossRef]
- IEC 62714; Datenaustauschformat für Planungsdaten industrieller Automatisierungssysteme: Automation Markup Language 2018;35.060. IEC Central Office: Geneva, Switzerland, 2018.
- DIN EN 45020; Normung und Damit Zusammenhängende Tätigkeiten: Allgemeine Begriffe 2007;01.040.01; 01.120. Beuth: Berlin, Germany, 2007.
- International Organization for Standardization (ISO); International Electrotechnical Commission (IEC). ISO/IEC Directives Part 2: Principles and Rules for the Structure and Drafting of ISO and IEC Documents 2021; ISO: Geneva, Switzerland; IEC: London, UK, 2021. [Google Scholar]
- ISO 898-1; Mechanical Properties of Fasteners Made of Carbon Steel and Alloy Steel—Part 1: Bolts, Screws and Studs with Specified Property Classes—Coarse Thread and Fine Pitch Thread 2013;21.060.10. ISO Central Office: Geneva, Switzerland. Available online: https://www.iso.org/standard/60610.html (accessed on 4 November 2024).
- ISO 18164; Passenger Car, Truck, Bus and Motorcycle Tyres—Methods of Measuring Rolling Resistance 2005;83.160.10. ISO Central Office: Geneva, Switzerland. Available online: https://www.iso.org/standard/33328.html (accessed on 4 November 2024).
- DIN EN 15091; Sanitary Tapware—Electronic Opening and Closing Sanitary Tapware 2013;91.140.70. Beuth Verlag GmbH: Berlin, Geramny. Available online: https://www.dinmedia.de/en/standard/din-en-15091/188814064 (accessed on 4 November 2024).
- DIN EN 1628; Pedestrian Doorsets, Windows, Curtain Walling, Grilles and Shutters—Burglar Resistance—Test Method for the Determination of Resistance Under Static Loading 2021;13.310; 91.060.50. Beuth Verlag GmbH: Berlin, Germany. Available online: https://www.dinmedia.de/en/standard/din-en-1628/332348098 (accessed on 4 November 2024).
- DIN EN 16051-2; Inflation Devices and Accessories for Inflatable Consumer Products—Part 2: Safety Requirements, Durability, Performance, Compatibility and Test Methods of Inflators 2013;23.080; 97.220.40. Beuth Verlag GmbH: Berlin, Germany. Available online: https://www.dinmedia.de/en/standard/din-en-16051-2/143104891 (accessed on 4 November 2024).
- ISO 29461-1; Air Intake Filter Systems for Rotary Machinery—Test Methods 2021;29.160.99. ISO Central Office: Geneva, Switzerland. Available online: https://www.iso.org/standard/76920.html (accessed on 4 November 2024).
- DIN EN 60312; Vacuum Cleaners for Household Use—Part 1: Dry Vacuum Cleaners—Methods for Measuring the Performance 2017;97.080. Beuth Verlag GmbH: Berlin, Germany. Available online: https://www.vde-verlag.de/standards/0701102/din-en-60312-1-vde-0705-312-1-2017-11.html (accessed on 4 November 2024).
- DIN EN 1191; Windows and Doors—Resistance to Repeated Opening and Closing—Test Method 2013;91.060.50. Beuth Verlag GmbH: Berlin, Germany. Available online: https://www.dinmedia.de/en/standard/din-en-1191/154133685 (accessed on 4 November 2024).
- Layer, M.; Neubert, S.; Tiemann, L.; Stelzer, R. Identification and Retrieval of Relevant Information for Instantiating Digital Twins during the Construction of Process Plants. Proc. Des. Soc. 2023, 3, 2175–2184. [Google Scholar] [CrossRef]
- Layer, M.; Neubert, S.; Stelzer, R. Introducing a multipliable BOM-based automatic definition of information retrieval in plant engineering. Proc. Des. Soc. 2024, 4, 413–422. [Google Scholar] [CrossRef]
- Block, C. The eCl@ss Standard as Semantic Basis for CAE Product Data Exchange; NAFEMS Deutschland, Österreich, Schweiz: Ebersberg, Germany, 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).