




Utilizing Hybrid Machine Learning Techniques and Gridded Precipitation Data for Advanced Discharge Simulation in Under-Monitored River Basins



Abstract
1. Introduction
2. Materials and Methods
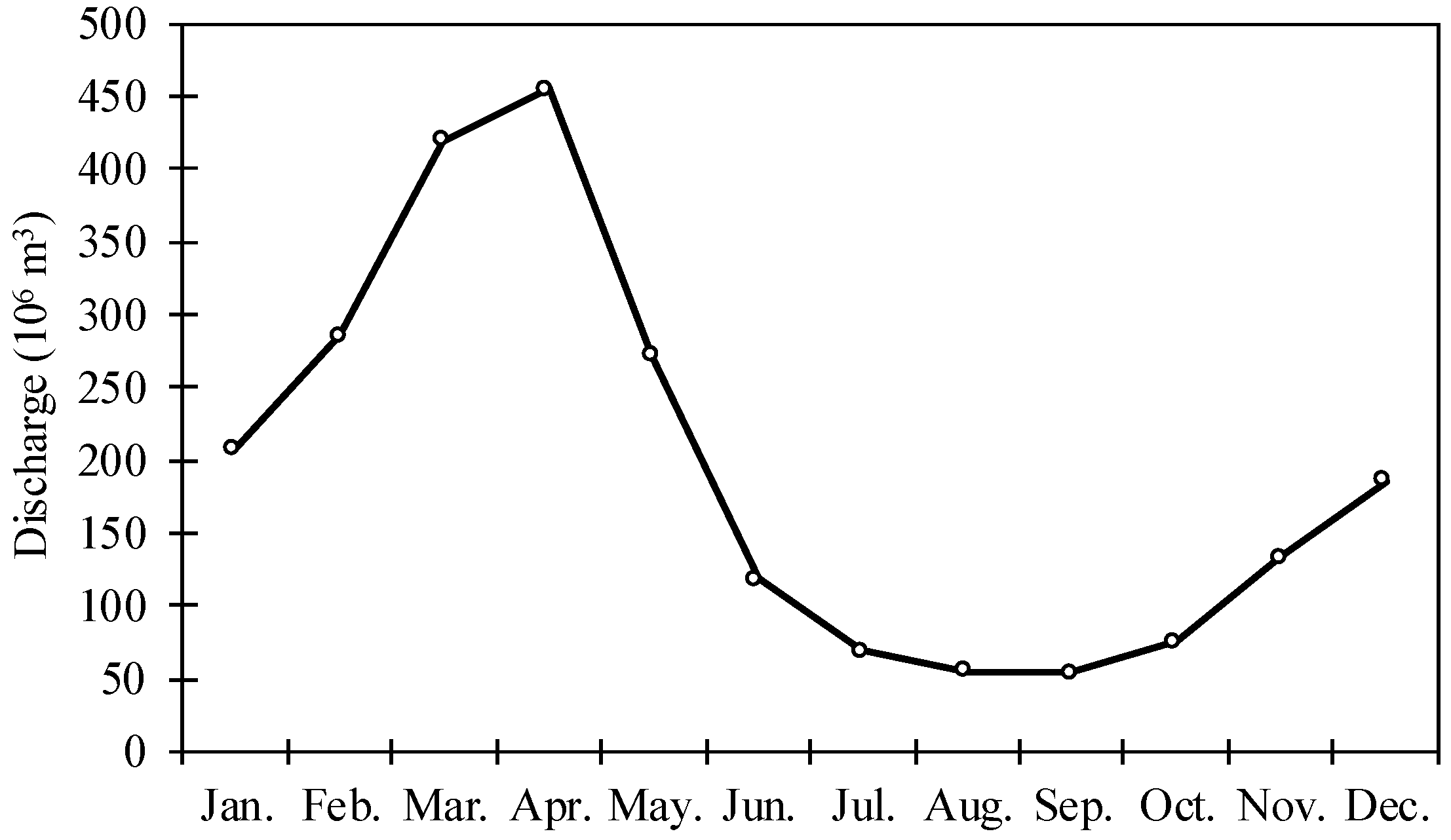
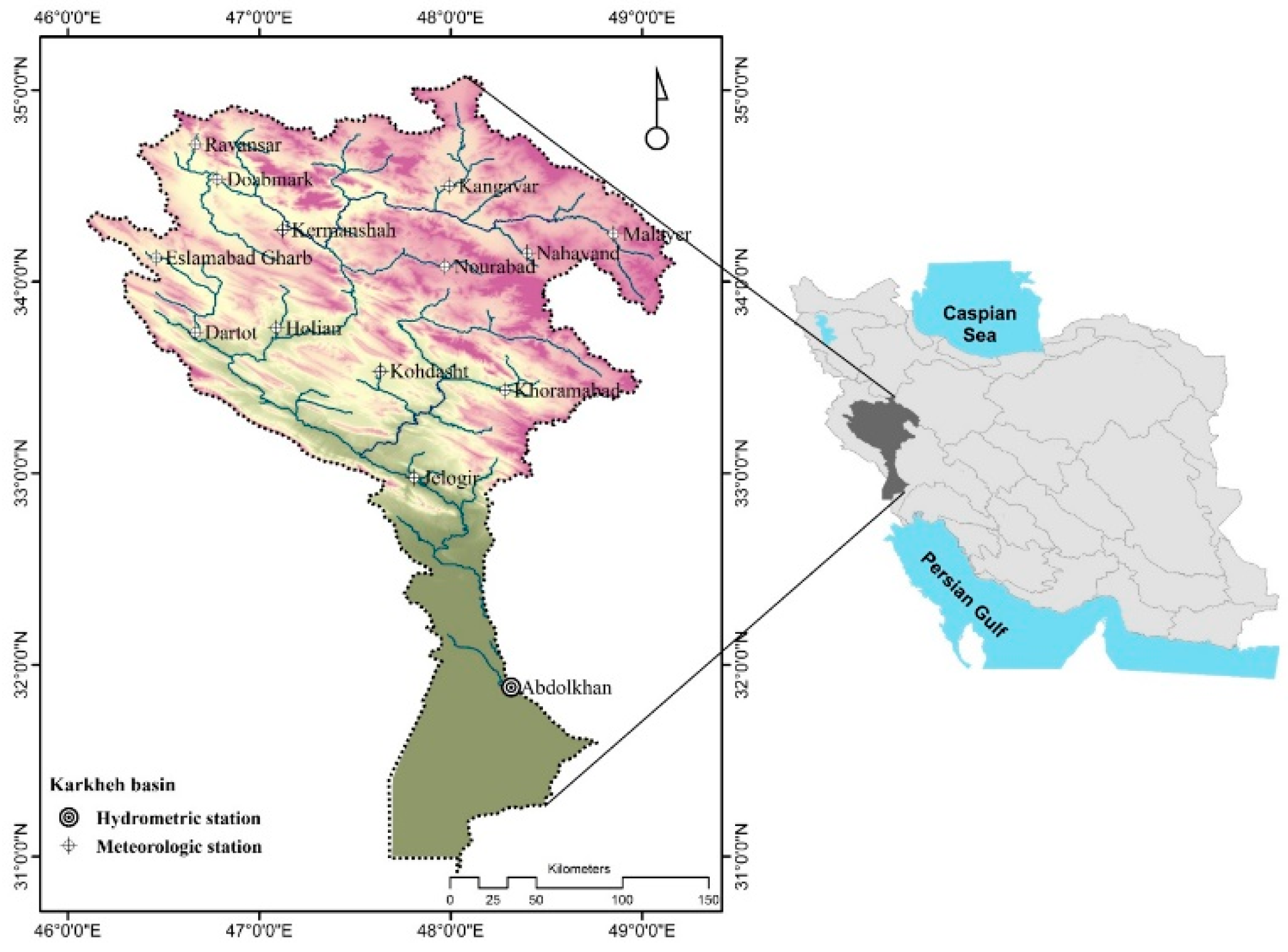
2.1. Case Study
2.2. Databases
2.2.1. APHRODITE
2.2.2. GPCC
2.2.3. CRU TS
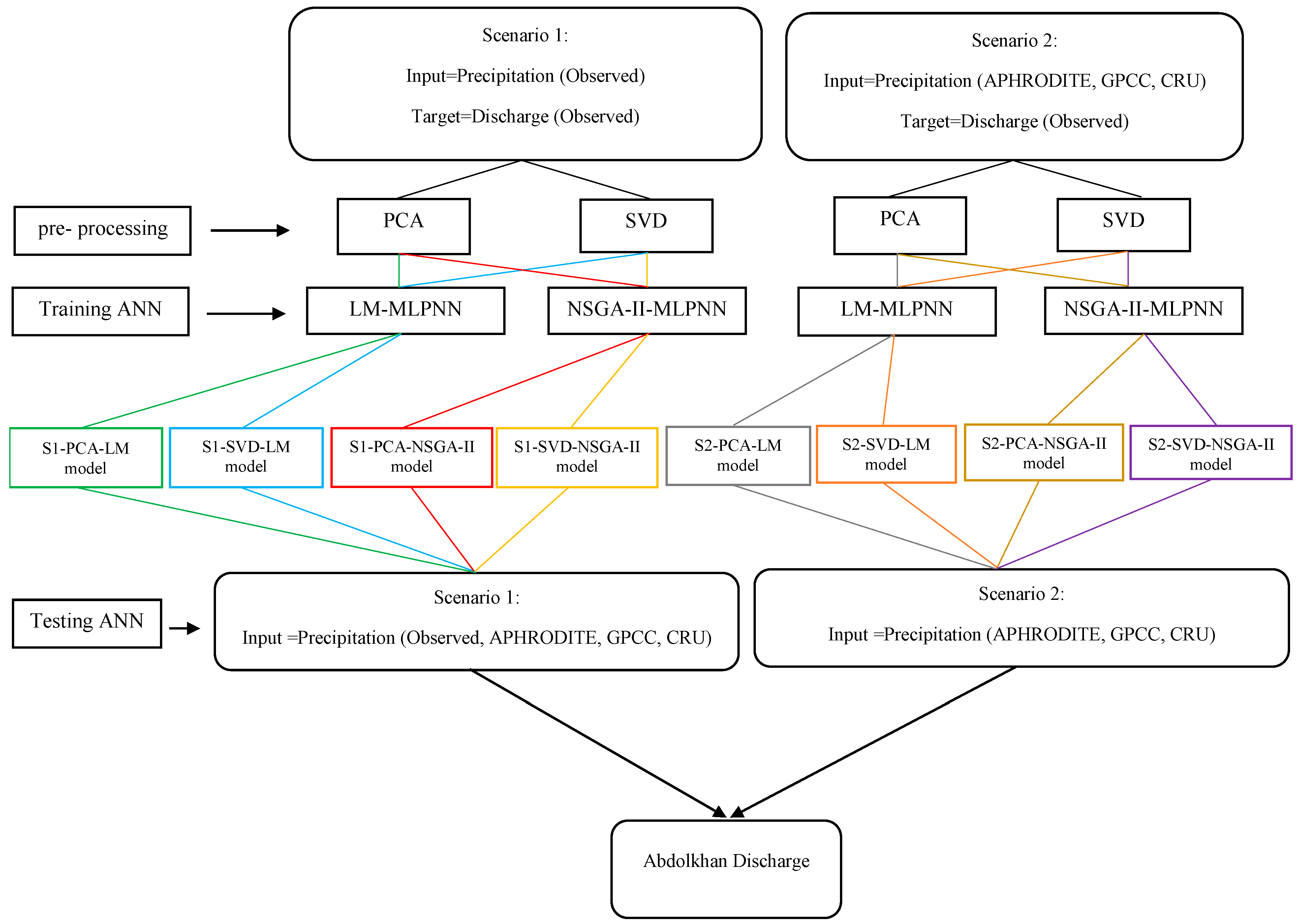
2.3. Rainfall-Runoff Modeling
2.4. Non-Dominated Sorting Genetic Algorithm II (NSGA-II)
2.5. Data Pre-Processing
2.5.1. Principal Component Analysis
2.5.2. Singular Value Decomposition
2.6. Evaluation Criteria
3. Results and Discussion
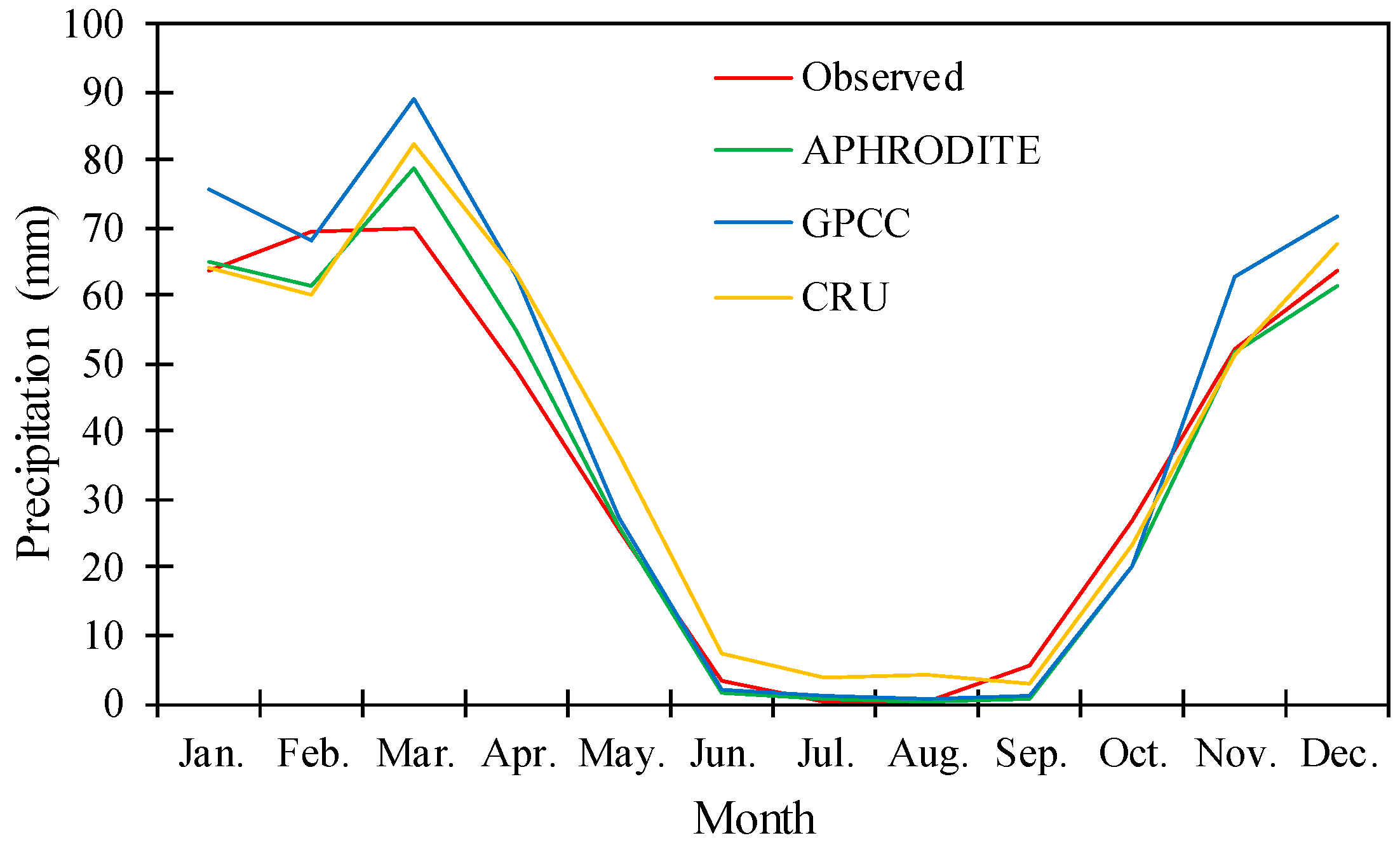
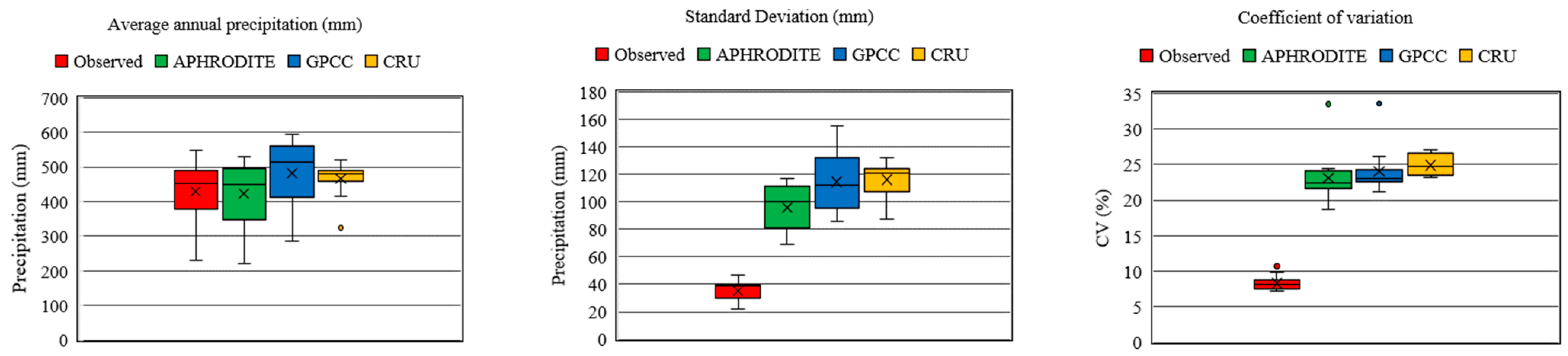
3.1. Evaluation of Precipitation Data
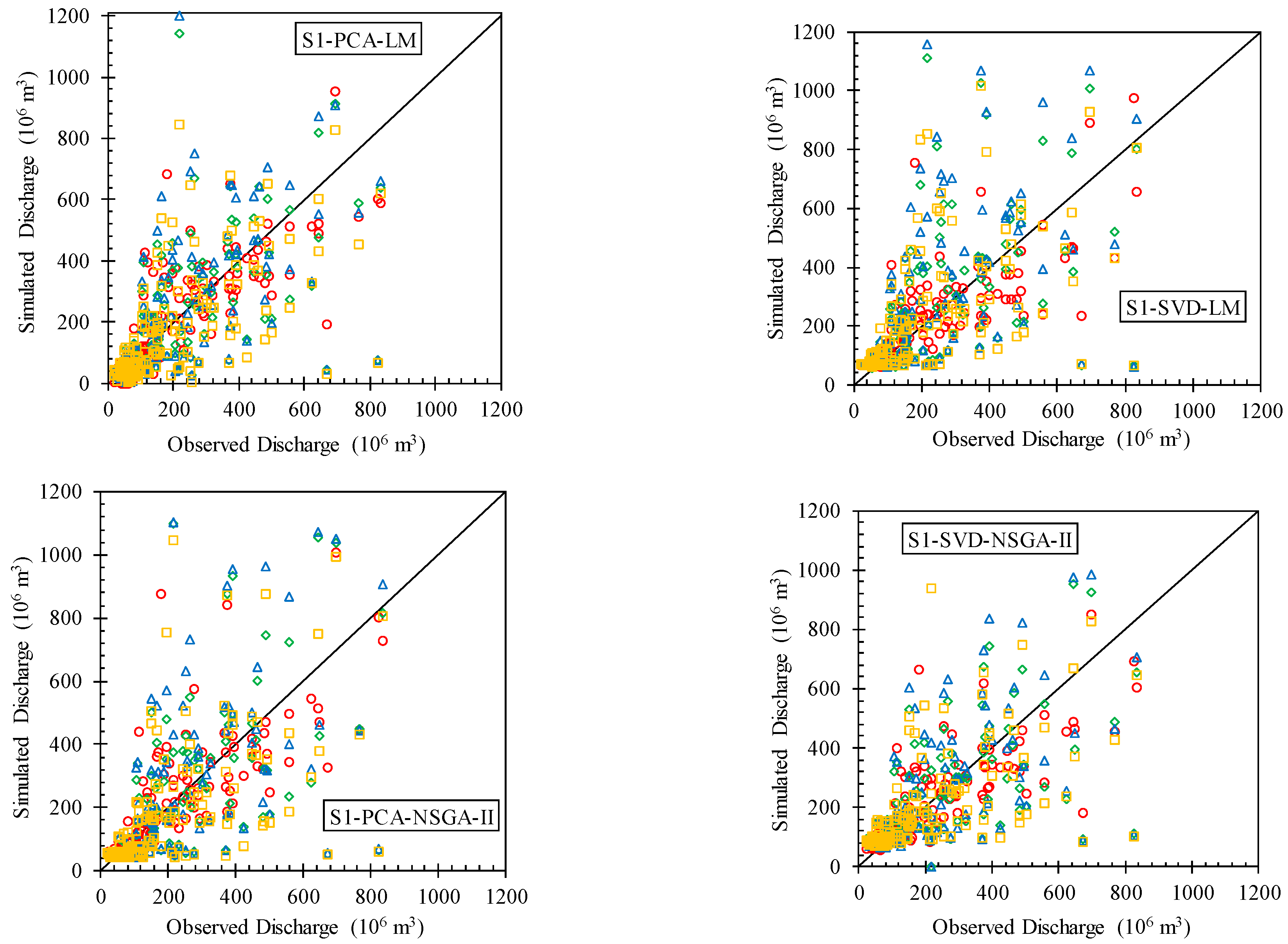
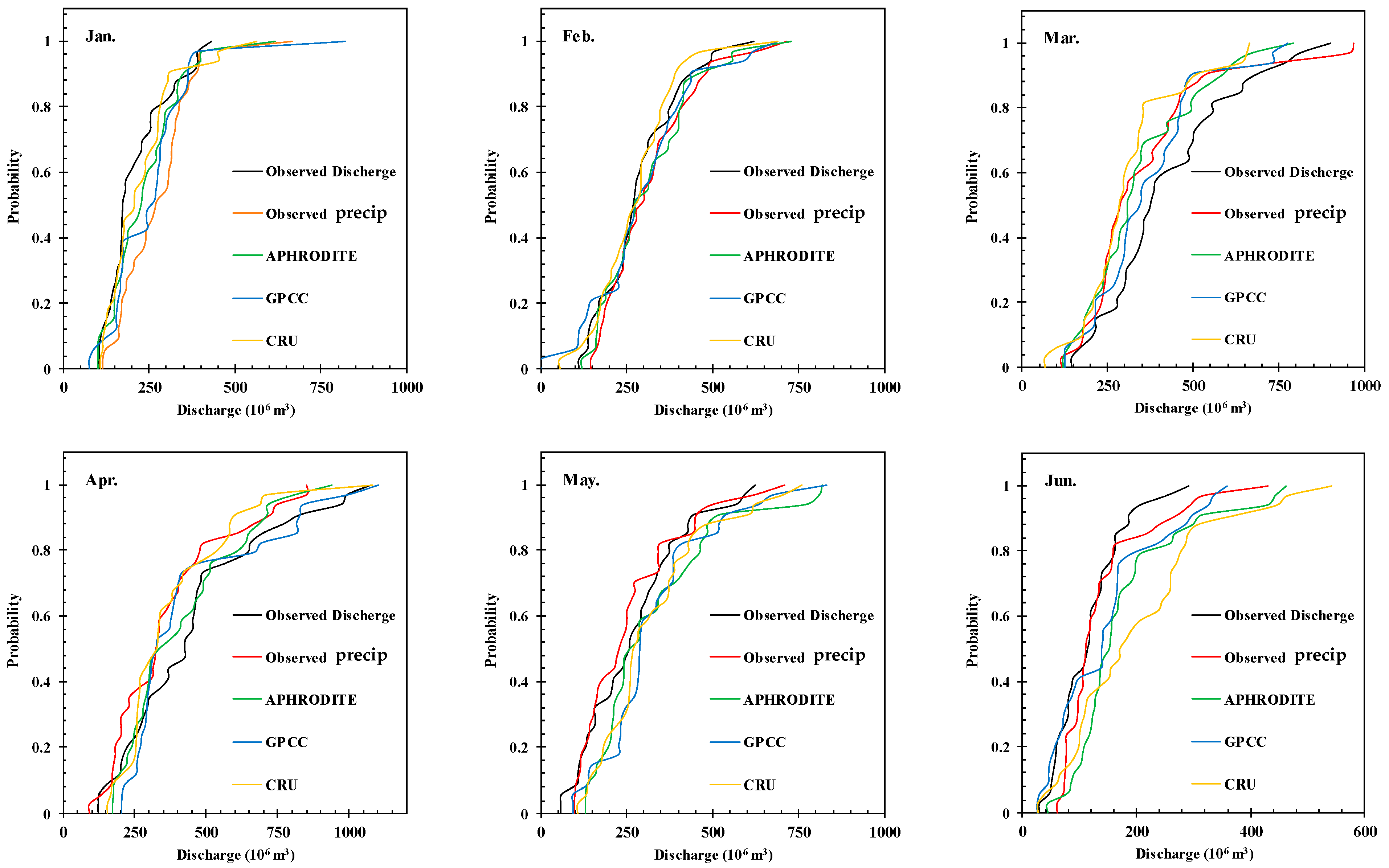
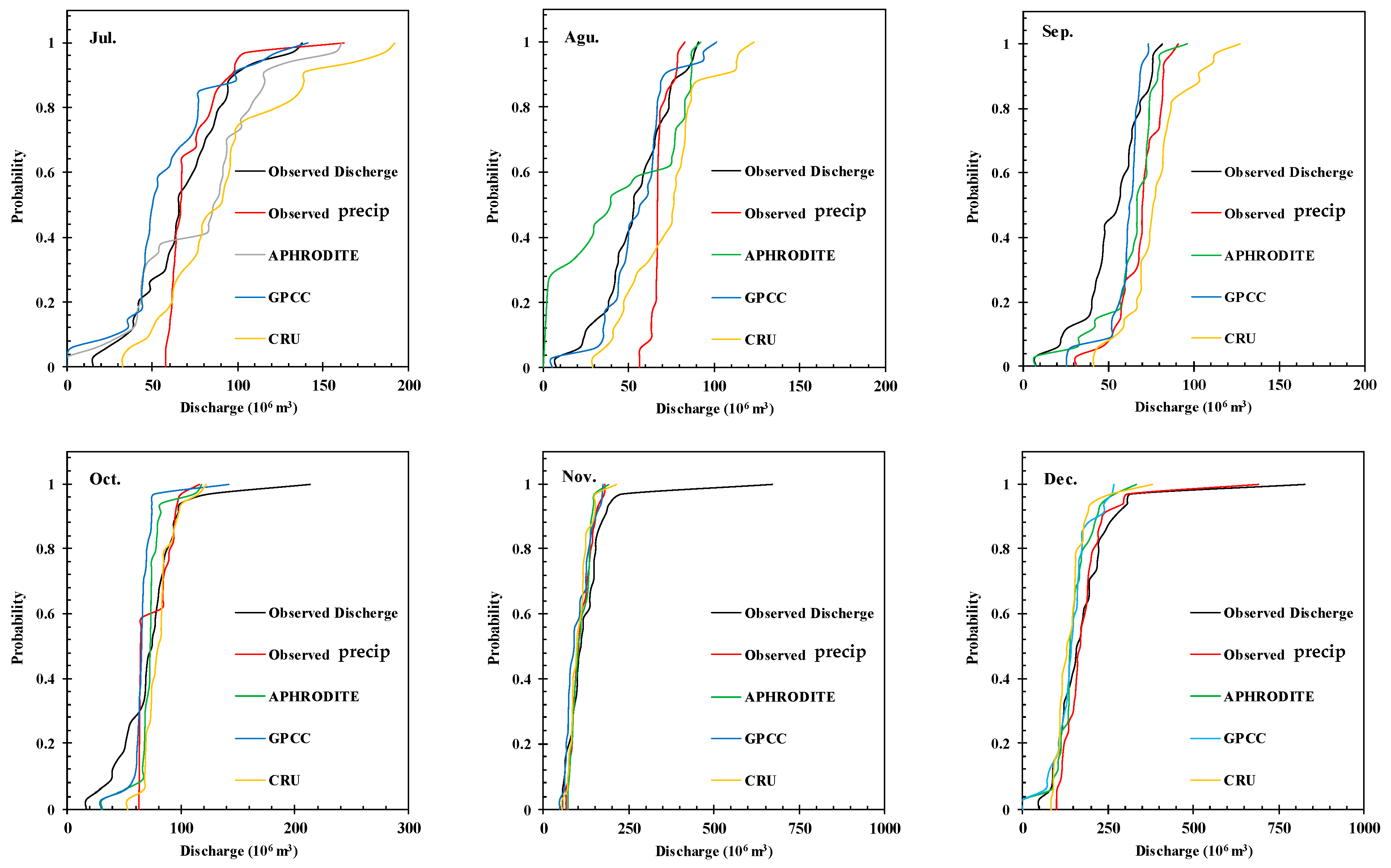
3.2. Rainfall-Runoff Modeling
4. Conclusions
- (1)
- This study attempted to find an operational approach to simulate discharge or fill in the gaps that existed in discharge data over a poorly gauged basin. To this end, three gridded precipitation datasets (APHRODITE, GPCC, and CRU) were evaluated = on their accuracy in depicting hydrological behavior in the Karkheh basin in Iran during 1967–2000. The results can be presented in two parts.
- (2)
- The first one is the comparison between in situ precipitation and girded datasets, and the second part is the assessment of R-R modeling results. The comparison of the precipitation datasets showed that APHRODITE outperformed the other datasets. For instance, on an annual scale, the average difference between APHRODITE precipitation and in situ data is 6.5 mm, while the values of this difference for the GPCC and CRU data are approximately equal to 53 and 44 mm, respectively. The findings align closely with those reported in references [56] and [45]. The analysis reveals that although the datasets accurately identify different patterns in precipitation, they exhibit biases in most months, and they possess bias in the majority of months.
- (3)
- After comparing the precipitation data, the development of an R-R model was investigated to simulate the outflow of the Karkheh basin. The MLPNN was used in the R-R modeling. Due to the fact that the number of inputs of the R-R model was equal to 42, PCA and SVD were employed to reduce the dimensions of the datasets. In the next step, to train the model, with regard to being stuck in the local optimum of the LM algorithm, the NSGA-II was employed to determine network weights and biases, and its results were compared with LM. Two scenarios were chosen for model calibration: in the first scenario, the MLPNN was calibrated based on the observed precipitation, and it was examined based on observed and gridded precipitation; in the second scenario, the calibrating and testing of the model were performed separately for each dataset.
- (4)
- The R-R modeling results showed that the models were more efficient, and all three databases demonstrated appropriate performances in the second scenario. Because the main error in the gridded precipitation dataset is the bias error, it will disappear automatically when the model is calibrated using gridded precipitation datasets. The results were better for wet months than for dry months. Overall, the comparison between pre-processing methods indicated that SVD gave superior results to PCA. These results match well with the findings of [2]. Again, the NSGA-II operated better than LM in model training. To sum up, APHRODITE, based on the S2-PCA-NSGA-II model, and GPCC and CRU, based on the S2-SVD-NSGA-II model, had the best performances, and can be considered as alternatives for hydrological studies.
- (5)
- It should be indicated that the spatial resolution of APHRODITE is half that of the other two datasets, which can improve the accuracy of the modelling. Nevertheless, temporal resolutions of the datasets in this study are not important because all of the modeling process was performed at monthly scale. It is worth mentioning that GPCC and CRU have a reasonable lag time to updating their data while APHRODITE data are updated with a significant delay. This deficiency can be considered a weakness for APHRODITE data. So, before practical application, it is suggested that spatial–temporal resolution and the lag time of updating data should be considered in addition to the accuracy of the given datasets. Also, a combination of different datasets may improve R-R modeling performance. Hence, hybrid dataset development is suggested for future studies. Based on the results in poorly gauged basins, it is recommended that the same dataset be used to calibrate and test the model in order to perform R-R modeling. Thus, applying an existing model for discharge reconstruction or to fill the gap based on gridded precipitation may not achieve good accuracy. According to the results of this study, a well-trained ANN is very practical in hydrological applications and, therefore, the model’s calibration should be completed attentively. Future research should aim to overcome the limitations noted, particularly the variable performance of models in periods of low discharge rates. Recognizing these difficulties will steer further studies to enhance simulation precision in comparable hydrological scenarios, fostering a deeper insight into and utilization of discharge modeling methodologies. In conclusion, this study’s findings illuminate the path forward for hydrological modeling in data-scarce regions, advocating for a nuanced approach to dataset selection, model calibration, and optimization. By leveraging advanced computational techniques and a thorough understanding of dataset characteristics and limitations, researchers and practitioners can enhance the precision and reliability of hydrological models, thereby improving water resource management and planning outcomes in similar contexts worldwide.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial Neural Networks in Hydrology. I: Preliminary Concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- Chitsaz, N.; Azarnivand, A.; Araghinejad, S. Pre-processing of data-driven river flow forecasting models by singular value decomposition (SVD) technique. Hydrol. Sci. J. 2016, 61, 2164–2178. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Fu, M.; Wang, C.; Mohtar, W.H.M.W.; Deo, R.C.; El-shafie, A. Application of the Hybrid Artificial Neural Network Coupled with Rolling Mechanism and Grey Model Algorithms for Streamflow Forecasting Over Multiple Time Horizons. Water Resour. Manag. 2018, 32, 1883–1899. [Google Scholar] [CrossRef]
- Araghinejad, S.; Fayaz, N.; Hosseini-Moghari, S.-M. Development of a Hybrid Data Driven Model for Hydrological Estimation. Water Resour. Manag. 2018, 32, 3737–3750. [Google Scholar] [CrossRef]
- Thakur, B.; Kalra, A.; Ahmad, S.; Lamb, K.W.; Lakshmi, V. Bringing statistical learning machines together for hydro-climatological predictions—Case study for Sacramento San joaquin River Basin, California. J. Hydrol. Reg. Stud. 2020, 27, 100651. [Google Scholar] [CrossRef]
- Ghobadi, F.; Kang, D. Multi-Step Ahead Probabilistic Forecasting of Daily Streamflow Using Bayesian Deep Learning: A Multiple Case Study. Water 2022, 14, 3672. [Google Scholar] [CrossRef]
- Tyson, C.; Longyang, Q.; Neilson, B.T.; Zeng, R.; Xu, T. Effects of meteorological forcing uncertainty on high-resolution snow modeling and streamflow prediction in a mountainous karst watershed. J. Hydrol. 2023, 619, 129304. [Google Scholar] [CrossRef]
- Ebrahimi, E.; Shourian, M. A feature-based adaptive combiner for coupling meta-modelling techniques to increase accuracy of river flow prediction. Hydrol. Sci. J. 2022, 67, 2065–2081. [Google Scholar] [CrossRef]
- Khalil, B.; Broda, S.; Adamowski, J.; Ozga-Zielinski, B.; Donohoe, A. Short-term forecasting of groundwater levels under conditions of mine-tailings recharge using wavelet ensemble neural network models. Hydrogeol. J. 2015, 23, 121–141. [Google Scholar] [CrossRef]
- Naderianfar, M.; Piri, J.; Kisi, O. Pre-processing data to predict groundwater levels using the fuzzy standardized evapotranspiration and precipitation index (SEPI). Water Resour. Manag. 2017, 31, 4433–4448. [Google Scholar] [CrossRef]
- Sahoo, S.; Russo, T.A.; Elliott, J.; Foster, I. Machine learning algorithms for modeling groundwater level changes in agricultural regions of the U.S. Water Resour. Res. 2017, 53, 3878–3895. [Google Scholar] [CrossRef]
- Sattari, M.T.; Mirabbasi, R.; Sushab, R.S.; Abraham, J. Prediction of Groundwater Level in Ardebil Plain Using Support Vector Regression and M5 Tree Model. Groundwater 2018, 56, 636–646. [Google Scholar] [CrossRef] [PubMed]
- Dadhich, A.P.; Goyal, R.; Dadhich, P.N. Assessment and Prediction of Groundwater using Geospatial and ANN Modeling. Water Resour. Manag. 2021, 35, 2879–2893. [Google Scholar] [CrossRef]
- Navale, V.; Mhaske, S. Artificial Neural Network (ANN) and Adaptive Neuro-Fuzzy Inference System (ANFIS) model for Forecasting Groundwater Level in the Pravara River Basin, India. Model. Earth Syst. Environ. 2023, 9, 2663–2676. [Google Scholar] [CrossRef]
- Mokhtarzad, M.; Eskandari, F.; Jamshidi Vanjani, N.; Arabasadi, A. Drought forecasting by ANN, ANFIS, and SVM and comparison of the models. Environ. Earth Sci. 2017, 76, 729. [Google Scholar] [CrossRef]
- Khan, M.M.H.; Muhammad, N.S.; El-Shafie, A. Wavelet based hybrid ANN-ARIMA models for meteorological drought forecasting. J. Hydrol. 2020, 590, 125380. [Google Scholar] [CrossRef]
- Alawsi, M.A.; Zubaidi, S.L.; Al-Bdairi, N.S.S.; Al-Ansari, N.; Hashim, K. Drought Forecasting: A Review and Assessment of the Hybrid Techniques and Data Pre-Processing. Hydrology 2022, 9, 115. [Google Scholar] [CrossRef]
- Latt, Z.Z.; Wittenberg, H. Improving Flood Forecasting in a Developing Country: A Comparative Study of Stepwise Multiple Linear Regression and Artificial Neural Network. Water Resour. Manag. 2014, 28, 2109–2128. [Google Scholar] [CrossRef]
- Alexander, A.A.; Thampi, S.G.; Chithra, N.R. Development of hybrid wavelet-ANN model for hourly flood stage forecasting. ISH J. Hydraul. Eng. 2018, 24, 266–274. [Google Scholar] [CrossRef]
- Dtissibe, F.Y.; Ari, A.A.A.; Titouna, C.; Thiare, O.; Gueroui, A.M. Flood forecasting based on an artificial neural network scheme. Nat. Hazards 2020, 104, 1211–1237. [Google Scholar] [CrossRef]
- Wang, G.; Yang, J.; Hu, Y.; Li, J.; Yin, Z. Application of a novel artificial neural network model in flood forecasting. Environ. Monit. Assess. 2022, 194, 125. [Google Scholar] [CrossRef] [PubMed]
- Banihabib, M.E.; Emami, E. Geo-hydroclimatological-based estimation of sediment yield by the artificial neural network. Int. J. Water 2017, 11, 159–177. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Mahdavi Meymand, A.; Ahmadipour, M. Estimating incipient motion velocity of bed sediments using different data-driven methods. Appl. Soft Comput. 2018, 69, 165–176. [Google Scholar] [CrossRef]
- Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; Teo, F.Y.; Ebrahimi, M.; Fai, C.M.; Huang, Y.F.; El-Shafie, A. Suspended sediment load prediction using artificial neural network and ant lion optimization algorithm. Environ. Sci. Pollut. Res. 2020, 27, 38094–38116. [Google Scholar] [CrossRef] [PubMed]
- Yadav, A.; Hasan, M.K.; Joshi, D.; Kumar, V.; Aman, A.H.M.; Alhumyani, H.; Alzaidi, M.S.; Mishra, H. Optimized Scenario for Estimating Suspended Sediment Yield Using an Artificial Neural Network Coupled with a Genetic Algorithm. Water 2022, 14, 2815. [Google Scholar] [CrossRef]
- Haghnazar, H.; Abbasi, Y.; Morovati, R.; Johannesson, K.H.; Somma, R.; Pourakbar, M.; Aghayani, E. Polycyclic aromatic hydrocarbons (PAHs) in the surficial sediments of the Abadan freshwater resources − Northwest of the Persian Gulf. J. Geochem. Explor. 2024, 258, 107390. [Google Scholar] [CrossRef]
- Antonopoulos, V.Z.; Gianniou, S.K.; Antonopoulos, A.V. Artificial neural networks and empirical equations to estimate daily evaporation: Application to Lake Vegoritis, Greece. Hydrol. Sci. J. 2016, 61, 2590–2599. [Google Scholar] [CrossRef]
- Nourani, V.; Sayyah-Fard, M.; Alami, M.T.; Sharghi, E. Data pre-processing effect on ANN-based prediction intervals construction of the evaporation process at different climate regions in Iran. J. Hydrol. 2020, 588, 125078. [Google Scholar] [CrossRef]
- Arya Azar, N.; Kardan, N.; Ghordoyee Milan, S. Developing the artificial neural network–evolutionary algorithms hybrid models (ANN–EA) to predict the daily evaporation from dam reservoirs. Eng. Comput. 2023, 39, 1375–1393. [Google Scholar] [CrossRef]
- Kasiviswanathan, K.S.; Cibin, R.; Sudheer, K.P.; Chaubey, I. Constructing prediction interval for artificial neural network rainfall runoff models based on ensemble simulations. J. Hydrol. 2013, 499, 275–288. [Google Scholar] [CrossRef]
- Nayak, P.C.; Venkatesh, B.; Krishna, B.; Jain, S.K. Rainfall-runoff modeling using conceptual, data driven, and wavelet based computing approach. J. Hydrol. 2013, 493, 57–67. [Google Scholar] [CrossRef]
- Shoaib, M.; Shamseldin, A.Y.; Melville, B.W. Comparative study of different wavelet based neural network models for rainfall–runoff modeling. J. Hydrol. 2014, 515, 47–58. [Google Scholar] [CrossRef]
- Mao, G.; Wang, M.; Liu, J.; Wang, Z.; Wang, K.; Meng, Y.; Zhong, R.; Wang, H.; Li, Y. Comprehensive comparison of artificial neural networks and long short-term memory networks for rainfall-runoff simulation. Phys. Chem. Earth Parts ABC 2021, 123, 103026. [Google Scholar] [CrossRef]
- Condon, L.E.; Kollet, S.; Bierkens, M.F.P.; Fogg, G.E.; Maxwell, R.M.; Hill, M.C.; Fransen, H.H.; Verhoef, A.; Van Loon, A.F.; Sulis, M.; et al. Global Groundwater Modeling and Monitoring: Opportunities and Challenges. Water Resour. Res. 2021, 57, e2020WR029500. [Google Scholar] [CrossRef]
- Getirana, A.C.V.; Espinoza, J.C.V.; Ronchail, J.; Rotunno Filho, O.C. Assessment of different precipitation datasets and their impacts on the water balance of the Negro River basin. J. Hydrol. 2011, 404, 304–322. [Google Scholar] [CrossRef]
- Shokoohi, A.; Morovati, R. Basinwide Comparison of RDI and SPI Within an IWRM Framework. Water Resour. Manag. 2015, 29, 2011–2026. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Temporal Hydrological Drought Index Forecasting for New South Wales, Australia Using Machine Learning Approaches. Atmosphere 2020, 11, 585. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, J.; Cheng, F.; Deng, H.; Chen, S. Drought monitoring in Yunnan Province based on a TRMM precipitation product. Nat. Hazards 2020, 104, 2369–2387. [Google Scholar] [CrossRef]
- Hosseini, A.; Ghavidel, Y.; Mohammad Khorshiddoust, A.; Farajzadeh, M. Spatio-temporal analysis of dry and wet periods in Iran by using Global Precipitation Climatology Center-Drought Index (GPCC-DI). Theor. Appl. Climatol. 2021, 143, 1035–1045. [Google Scholar] [CrossRef]
- Morsy, M.; Moursy, F.I.; Sayad, T.; Shaban, S. Climatological Study of SPEI Drought Index Using Observed and CRU Gridded Dataset over Ethiopia. Pure Appl. Geophys. 2022, 179, 3055–3073. [Google Scholar] [CrossRef]
- Pan, T.-Y.; Yang, Y.-T.; Kuo, H.-C.; Tan, Y.-C.; Lai, J.-S.; Chang, T.-J.; Lee, C.-S.; Hsu, K.H. Improvement of watershed flood forecasting by typhoon rainfall climate model with an ANN-based southwest monsoon rainfall enhancement. J. Hydrol. 2013, 506, 90–100. [Google Scholar] [CrossRef]
- Hounguè, N.R.; Ogbu, K.N.; Almoradie, A.D.S.; Evers, M. Evaluation of the performance of remotely sensed rainfall datasets for flood simulation in the transboundary Mono River catchment, Togo and Benin. J. Hydrol. Reg. Stud. 2021, 36, 100875. [Google Scholar] [CrossRef]
- Try, S.; Tanaka, S.; Tanaka, K.; Sayama, T.; Khujanazarov, T.; Oeurng, C. Comparison of CMIP5 and CMIP6 GCM performance for flood projections in the Mekong River Basin. J. Hydrol. Reg. Stud. 2022, 40, 101035. [Google Scholar] [CrossRef]
- Tahir, A.A.; Chevallier, P.; Arnaud, Y.; Neppel, L.; Ahmad, B. Modeling snowmelt-runoff under climate scenarios in the Hunza River basin, Karakoram Range, Northern Pakistan. J. Hydrol. 2011, 409, 104–117. [Google Scholar] [CrossRef]
- Vu, M.T.; Raghavan, S.V.; Liong, S.Y. SWAT use of gridded observations for simulating runoff—A Vietnam river basin study. Hydrol. Earth Syst. Sci. 2012, 16, 2801–2811. [Google Scholar] [CrossRef]
- Zhang, G.; Xie, H.; Yao, T.; Li, H.; Duan, S. Quantitative water resources assessment of Qinghai Lake basin using Snowmelt Runoff Model (SRM). J. Hydrol. 2014, 519, 976–987. [Google Scholar] [CrossRef]
- Zubieta, R.; Getirana, A.; Espinoza, J.C.; Lavado, W. Impacts of satellite-based precipitation datasets on rainfall–runoff modeling of the Western Amazon basin of Peru and Ecuador. J. Hydrol. 2015, 528, 599–612. [Google Scholar] [CrossRef]
- Xiong, J.; Yin, J.; Guo, S.; He, S.; Chen, J.; Abhishek. Annual runoff coefficient variation in a changing environment: A global perspective. Environ. Res. Lett. 2022, 17, 064006. [Google Scholar] [CrossRef]
- Meng, J.; Li, L.; Hao, Z.; Wang, J.; Shao, Q. Suitability of TRMM satellite rainfall in driving a distributed hydrological model in the source region of Yellow River. J. Hydrol. 2014, 509, 320–332. [Google Scholar] [CrossRef]
- Pombo, S.; De Oliveira, R.P. Evaluation of extreme precipitation estimates from TRMM in Angola. J. Hydrol. 2015, 523, 663–679. [Google Scholar] [CrossRef]
- Schneider, U.; Finger, P.; Meyer-Christoffer, A.; Rustemeier, E.; Ziese, M.; Becker, A. Evaluating the Hydrological Cycle over Land Using the Newly-Corrected Precipitation Climatology from the Global Precipitation Climatology Centre (GPCC). Atmosphere 2017, 8, 52. [Google Scholar] [CrossRef]
- Dos Santos, D.C.; Santos, C.A.G.; Brasil Neto, R.M.; Da Silva, R.M.; Dos Santos, C.A.C. Precipitation variability using GPCC data and its relationship with atmospheric teleconnections in Northeast Brazil. Clim. Dyn. 2023, 61, 5035–5048. [Google Scholar] [CrossRef]
- Minaei, A.; Todeschini, S.; Sitzenfrei, R.; Creaco, E. Ensemble Evaluation and Member Selection of Regional Climate Models for Impact Models Assessment. Water 2022, 14, 3967. [Google Scholar] [CrossRef]
- Bayazidy, M.; Maleki, M.; Khosravi, A.; Shadjou, A.M.; Wang, J.; Rustum, R.; Morovati, R. Assessing Riverbank Change Caused by Sand Mining and Waste Disposal Using Web-Based Volunteered Geographic Information. Water 2024, 16, 734. [Google Scholar] [CrossRef]
- Hosseini-Moghari, S.-M.; Morovati, R.; Moghadas, M.; Araghinejad, S. Optimum Operation of Reservoir Using Two Evolutionary Algorithms: Imperialist Competitive Algorithm (ICA) and Cuckoo Optimization Algorithm (COA). Water Resour. Manag. 2015, 29, 3749–3769. [Google Scholar] [CrossRef]
- Onishi, T.; Yoh, M.; Nagao, S.; Shibata, H. Improvement of Runoff Simulation of the Amur River. Glob. Environ. Res. 2011, 15, 173–182. [Google Scholar]
- Katiraie-Boroujerdy, P.-S.; Nasrollahi, N.; Hsu, K.; Sorooshian, S. Quantifying the reliability of four global datasets for drought monitoring over a semiarid region. Theor. Appl. Climatol. 2016, 123, 387–398. [Google Scholar] [CrossRef]
- Try, S.; Tanaka, S.; Tanaka, K.; Sayama, T.; Oeurng, C.; Uk, S.; Takara, K.; Hu, M.; Han, D. Comparison of gridded precipitation datasets for rainfall-runoff and inundation modeling in the Mekong River Basin. PLoS ONE 2020, 15, e0226814. [Google Scholar] [CrossRef] [PubMed]
- Yatagai, A.; Kamiguchi, K.; Arakawa, O.; Hamada, A.; Yasutomi, N.; Kitoh, A. APHRODITE: Constructing a Long-Term Daily Gridded Precipitation Dataset for Asia Based on a Dense Network of Rain Gauges. Bull. Am. Meteorol. Soc. 2012, 93, 1401–1415. [Google Scholar] [CrossRef]
- Schneider, U.; Becker, A.; Finger, P.; Meyer-Christoffer, A.; Ziese, M.; Rudolf, B. GPCC’s new land surface precipitation climatology based on quality-controlled in situ data and its role in quantifying the global water cycle. Theor. Appl. Climatol. 2014, 115, 15–40. [Google Scholar] [CrossRef]
- Harris, I.; Jones, P.D.; Osborn, T.J.; Lister, D.H. Updated high-resolution grids of monthly climatic observations—The CRU TS3.10 Dataset: Updated high-resolution grids of monthly climatic observations. Int. J. Climatol. 2014, 34, 623–642. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J. River suspended sediment estimation by climatic variables implication: Comparative study among soft computing techniques. Comput. Geosci. 2012, 43, 73–82. [Google Scholar] [CrossRef]
- Shiri, J.; Kisi, O.; Yoon, H.; Lee, K.-K.; Hossein Nazemi, A. Predicting groundwater level fluctuations with meteorological effect implications—A comparative study among soft computing techniques. Comput. Geosci. 2013, 56, 32–44. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Araghinejad, S. Data-Driven Modeling: Using MATLAB® in Water Resources and Environmental Engineering; Springer: Dordrecht, The Netherlands, 2014; Volume 67, ISBN 978-94-007-7505-3. [Google Scholar]
- Kumar, M.; Raghuwanshi, N.S.; Singh, R.; Wallender, W.W.; Pruitt, W.O. Estimating Evapotranspiration using Artificial Neural Network. J. Irrig. Drain. Eng. 2002, 128, 224–233. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Gosain, A.K.; Ramasastri, K.S. Estimating Actual Evapotranspiration from Limited Climatic Data Using Neural Computing Technique. J. Irrig. Drain. Eng. 2003, 129, 214–218. [Google Scholar] [CrossRef]
- Kişi, Ö.; Tombul, M. Modeling monthly pan evaporations using fuzzy genetic approach. J. Hydrol. 2013, 477, 203–212. [Google Scholar] [CrossRef]
- Bahrami, S.; Doulati Ardejani, F.; Baafi, E. Application of artificial neural network coupled with genetic algorithm and simulated annealing to solve groundwater inflow problem to an advancing open pit mine. J. Hydrol. 2016, 536, 471–484. [Google Scholar] [CrossRef]
- Pham, A.-D.; Hoang, N.-D.; Nguyen, Q.-T. Predicting Compressive Strength of High-Performance Concrete Using Metaheuristic-Optimized Least Squares Support Vector Regression. J. Comput. Civ. Eng. 2016, 30, 06015002. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Ottaviani, G.; Paoletti, R. A Geometric Perspective on the Singular Value Decomposition. arXiv 2015, arXiv:1503.07054. [Google Scholar] [CrossRef]
- Meidani, E.; Araghinejad, S. Long-Lead Streamflow Forecasting in the Southwest of Iran by Sea Surface Temperature of the Mediterranean Sea. J. Hydrol. Eng. 2014, 19, 05014005. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the use of “goodness-of-fit” Measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Krause, P.; Boyle, D.P.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Name | Latitude | Longitude | Average (mm) | Max. (mm) | Min. (mm) | SD † (mm) |
|---|---|---|---|---|---|---|
| Doabmark | 46°47′ | 34°34′ | 488 | 777 | 210 | 133 |
| Dartot | 46°39′ | 33°33′ | 443 | 623 | 232 | 103 |
| Holian | 47°46′ | 33°46′ | 336 | 613 | 100 | 118 |
| Jelogir | 46°47′ | 32°58′ | 470 | 793 | 259 | 151 |
| Nourabad | 47°48′ | 34°05′ | 461 | 833 | 152 | 133 |
| Ravansar | 46°40′ | 34°43′ | 548 | 773 | 334 | 96 |
| Kangavar | 48°00′ | 34°30′ | 395 | 620 | 222 | 84 |
| Kermanshah | 47°07′ | 34°16′ | 475 | 859 | 259 | 124 |
| Malayer | 48°18′ | 34°15′ | 305 | 413 | 132 | 55 |
| Nahavand | 48°24′ | 34°09′ | 396 | 593 | 226 | 87 |
| Eslamabad Gharb | 46°48′ | 34°07′ | 500 | 699 | 258 | 88 |
| Kohdasht | 47°38′ | 33°32′ | 444 | 631 | 246 | 87 |
| Khoramabad | 48°17′ | 48°26′ | 520 | 806 | 275 | 134 |
| Abdolkhan | 48°22′ | 31°49′ | 229 | 434 | 92 | 78 |
| Dataset | Annual Time Series | Monthly Time Series † | ||||
|---|---|---|---|---|---|---|
| Mean (mm) | SD (mm) | CV (%) | CC | RMSE (mm) | Bias (%) | |
| Observed | 429.17 | 76.63 | 17.86 | |||
| APHRODITE | 422.66 | 84.42 | 19.97 | 0.81 | 22.13 | −1.52 |
| GPCC | 482.64 | 97.08 | 20.12 | 0.80 | 26.23 | 11.08 |
| CRU | 466.80 | 107.58 | 23.05 | 0.78 | 24.23 | 8.77 |
| Dataset | Mean (mm) | SD (mm) | CV (%) | CC | RMSE (mm) | Bias (%) | Mean (mm) | SD (mm) | CV (%) | CC | RMSE (mm) | Bias (%) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Observed | Jan. | 63.83 | 15.62 | 24.47 | Jul. | 0.16 | 0.44 | 273.98 | ||||||
| APHRODITE | 65.06 | 26.51 | 40.75 | 0.79 | 16.87 | 1.92 | 0.82 | 1.55 | 187.96 | 0.79 | 1.38 | 416.15 | ||
| GPCC | 75.68 | 31.59 | 41.75 | 0.79 | 24.24 | 18.56 | 1.14 | 1.51 | 131.63 | 0.74 | 1.55 | 617.51 | ||
| CRU | 64.10 | 28.72 | 44.81 | 0.83 | 17.85 | 0.43 | 3.82 | 7.62 | 199.14 | 0.32 | 8.24 | 2299.73 | ||
| Observed | Feb. | 69.35 | 17.31 | 24.95 | Aug. | 0.06 | 0.11 | 189.66 | ||||||
| APHRODITE | 61.67 | 22.65 | 36.72 | 0.67 | 18.36 | −11.07 | 0.36 | 0.68 | 190.58 | 0.26 | 0.72 | 493.77 | ||
| GPCC | 68.35 | 25.52 | 37.34 | 0.67 | 18.71 | −1.44 | 0.52 | 1.00 | 191.43 | 0.33 | 1.06 | 764.65 | ||
| CRU | 59.99 | 26.42 | 44.05 | 0.74 | 19.94 | −13.50 | 4.32 | 8.87 | 205.46 | 0.24 | 9.69 | 7064.96 | ||
| Observed | Mar. | 69.83 | 20.93 | 29.97 | Sep. | 5.50 | 4.33 | 78.76 | ||||||
| APHRODITE | 78.76 | 35.44 | 45.00 | 0.76 | 25.06 | 12.80 | 0.73 | 1.14 | 155.50 | 0.24 | 6.31 | −86.64 | ||
| GPCC | 89.10 | 39.38 | 44.20 | 0.75 | 33.19 | 27.59 | 1.25 | 2.87 | 228.76 | 0.04 | 6.58 | −77.19 | ||
| CRU | 82.51 | 37.08 | 44.94 | 0.78 | 27.18 | 18.16 | 2.74 | 5.54 | 202.20 | 0.30 | 6.44 | −50.16 | ||
| Observed | Apr. | 49.23 | 19.45 | 39.50 | Oct. | 26.75 | 17.14 | 64.09 | ||||||
| APHRODITE | 54.75 | 29.11 | 53.17 | 0.88 | 15.86 | 11.23 | 20.04 | 22.99 | 114.70 | −0.01 | 29.17 | −25.06 | ||
| GPCC | 62.77 | 32.80 | 52.25 | 0.89 | 22.21 | 27.50 | 20.16 | 25.09 | 124.46 | −0.01 | 30.78 | −24.62 | ||
| CRU | 63.43 | 36.63 | 57.75 | 0.88 | 25.54 | 28.85 | 23.24 | 27.67 | 119.06 | −0.01 | 32.44 | −13.11 | ||
| Observed | May. | 25.40 | 17.31 | 68.12 | Nov. | 52.20 | 22.12 | 42.38 | ||||||
| APHRODITE | 25.90 | 19.79 | 76.40 | 0.80 | 11.77 | 1.95 | 51.49 | 44.71 | 86.83 | 0.06 | 47.89 | −1.36 | ||
| GPCC | 27.24 | 22.73 | 83.46 | 0.75 | 14.82 | 7.21 | 62.64 | 51.32 | 81.92 | 0.05 | 55.05 | 20.00 | ||
| CRU | 36.52 | 28.98 | 79.35 | 0.80 | 21.33 | 43.76 | 51.06 | 40.13 | 78.60 | −0.02 | 45.59 | −2.19 | ||
| Observed | Jun. | 3.12 | 2.78 | 89.03 | Dec. | 63.74 | 15.31 | 24.02 | ||||||
| APHRODITE | 1.46 | 2.12 | 145.34 | 0.49 | 3.00 | −53.21 | 61.61 | 29.85 | 48.45 | 0.06 | 32.28 | −3.35 | ||
| GPCC | 2.13 | 3.03 | 142.65 | 0.52 | 2.98 | −31.88 | 71.68 | 36.12 | 50.39 | 0.08 | 38.36 | 12.45 | ||
| CRU | 7.41 | 10.58 | 142.77 | 0.42 | 10.52 | 137.45 | 67.66 | 29.69 | 43.87 | 0.07 | 32.20 | 6.15 |
| Dataset | Pre-Processing | Training Algorithm | Train | Validation | Test | PCA | SVD | LM | NSGA-II | PCA | SVD | PCA | SVD | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CC | RMSE | Bias | CC | RMSE | Bias | CC | RMSE | Bias | LM | LM | NSGA-II | NSGA-II | ||||||||
| Scenario 1 | Observed | PCA | LM | 0.90 | 90.73 | 2.73 | 0.86 | 65.21 | −5.03 | 0.82 | 104.03 | −3.44 | 6 | 4 | 2 | 4 | 2 | |||
| PCA | NSGA-II | 0.90 | 88.02 | −1.68 | 0.83 | 72.38 | −7.25 | 0.80 | 110.27 | −1.40 | ||||||||||
| SVD | LM | 0.90 | 89.77 | 5.20 | 0.84 | 70.47 | −4.96 | 0.81 | 104.10 | −5.44 | 7 | 2 | 5 | 2 | 5 | |||||
| SVD | NSGA-II | 0.90 | 89.52 | 1.24 | 0.82 | 71.02 | −10.09 | 0.82 | 100.07 | 0.29 | ||||||||||
| APHRODITE | PCA | LM | 0.67 | 153.54 | −4.93 | 0 | 0 | 0 | 0 | 0 | ||||||||||
| PCA | NSGA-II | 0.65 | 166.40 | −2.87 | ||||||||||||||||
| SVD | LM | 0.64 | 173.57 | 12.15 | 3 | 0 | 3 | 0 | 3 | |||||||||||
| SVD | NSGA-II | 0.68 | 137.33 | 2.38 | ||||||||||||||||
| GPCC | PCA | LM | 0.66 | 166.60 | −0.58 | 1 | 1 | 0 | 1 | 0 | ||||||||||
| PCA | NSGA-II | 0.65 | 179.90 | 5.16 | ||||||||||||||||
| SVD | LM | 0.64 | 193.70 | 22.16 | 2 | 0 | 2 | 0 | 2 | |||||||||||
| SVD | NSGA-II | 0.67 | 148.82 | 7.19 | ||||||||||||||||
| CRU | PCA | LM | 0.63 | 152.64 | −13.60 | 1 | 1 | 0 | 1 | 0 | ||||||||||
| PCA | NSGA-II | 0.61 | 165.95 | −9.71 | ||||||||||||||||
| SVD | LM | 0.60 | 167.72 | 5.38 | 2 | 0 | 2 | 0 | 2 | |||||||||||
| SVD | NSGA-II | 0.61 | 149.20 | −1.32 | ||||||||||||||||
| Scenario 2 | APHRODITE | PCA | LM | 0.89 | 90.84 | −4.49 | 0.78 | 85.45 | −6.95 | 0.71 | 136.66 | −0.15 | 7 | 3 | 4 | 3 | 4 | |||
| PCA | NSGA-II | 0.90 | 89.59 | −0.03 | 0.77 | 92.50 | 0.76 | 0.72 | 124.59 | 1.29 | ||||||||||
| SVD | LM | 0.88 | 95.16 | −2.17 | 0.77 | 83.57 | −0.90 | 0.73 | 126.82 | 1.20 | 3 | 1 | 2 | 1 | 2 | |||||
| SVD | NSGA-II | 0.89 | 92.07 | 1.00 | 0.72 | 92.00 | 1.45 | 0.74 | 124.53 | 7.03 | ||||||||||
| GPCC | PCA | LM | 0.90 | 86.83 | 2.13 | 0.76 | 87.84 | −5.09 | 0.71 | 139.34 | 2.54 | 3 | 1 | 2 | 1 | 2 | ||||
| PCA | NSGA-II | 0.92 | 81.51 | 2.25 | 0.75 | 94.08 | −1.69 | 0.72 | 125.74 | −2.41 | ||||||||||
| SVD | LM | 0.90 | 88.96 | 0.14 | 0.76 | 83.32 | 3.09 | 0.71 | 124.63 | 1.77 | 8 | 3 | 5 | 3 | 5 | |||||
| SVD | NSGA-II | 0.92 | 80.18 | 1.43 | 0.77 | 84.71 | −2.31 | 0.72 | 129.44 | −1.36 | ||||||||||
| CRU | PCA | LM | 0.84 | 108.59 | 1.04 | 0.71 | 92.95 | 1.48 | 0.69 | 128.30 | −6.30 | 2 | 1 | 1 | 1 | 1 | ||||
| PCA | NSGA-II | 0.85 | 107.43 | −2.74 | 0.72 | 93.98 | −4.00 | 0.71 | 125.88 | −8.52 | ||||||||||
| SVD | LM | 0.86 | 104.71 | −1.28 | 0.72 | 92.10 | −2.01 | 0.72 | 124.60 | −7.49 | 8 | 3 | 5 | 3 | 5 | |||||
| SVD | NSGA-II | 0.87 | 99.97 | −2.73 | 0.70 | 93.91 | −0.41 | 0.71 | 124.56 | −0.73 | ||||||||||
| SUM | 20 | 33 | 20 | 33 | 11 | 9 | 9 | 24 | ||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morovati, R.; Kisi, O. Utilizing Hybrid Machine Learning Techniques and Gridded Precipitation Data for Advanced Discharge Simulation in Under-Monitored River Basins. Hydrology 2024, 11, 48. https://doi.org/10.3390/hydrology11040048
Morovati R, Kisi O. Utilizing Hybrid Machine Learning Techniques and Gridded Precipitation Data for Advanced Discharge Simulation in Under-Monitored River Basins. Hydrology. 2024; 11(4):48. https://doi.org/10.3390/hydrology11040048
Chicago/Turabian StyleMorovati, Reza, and Ozgur Kisi. 2024. "Utilizing Hybrid Machine Learning Techniques and Gridded Precipitation Data for Advanced Discharge Simulation in Under-Monitored River Basins" Hydrology 11, no. 4: 48. https://doi.org/10.3390/hydrology11040048
APA StyleMorovati, R., & Kisi, O. (2024). Utilizing Hybrid Machine Learning Techniques and Gridded Precipitation Data for Advanced Discharge Simulation in Under-Monitored River Basins. Hydrology, 11(4), 48. https://doi.org/10.3390/hydrology11040048