1. Introduction
The human voice results from a complex configuration, arrangement, and coordination of the elements that make up the phonatory apparatus, the respiratory system, and the central nervous system. Therefore, abnormal neurological and anatomical features often related to genetic syndromes could alter voice production. Over the years, several works have investigated the detection of voice pathology due to benign formations (e.g., nodules and polyps), neuromuscular disorders (e.g., paralysis of the vocal cords) [
1,
2] and neurodegenerative diseases such as Parkinson’s disease [
3,
4] by using acoustical features extracted from a sustained vowel (/a/). Vocal-tract, larynx, and vocal-fold abnormalities can be identified by analyzing key acoustical parameters assessed perceptually by experienced clinicians and objectively by dedicated software. In the latter context, some of the most important parameters are [
5]:
The fundamental frequency (F0), which describes the vibration frequency of the vocal folds;
The first formant (F1), which is related to the constriction of the anterior half of the oral cavity; the larger the cavity, the lower the F1. F1 is also raised by the constriction of the pharyngeal tract;
The second formant (F2) (linked to tongue movements), which is lowered by posterior tongue constriction and raised by anterior tongue constriction;
The third formant (F3), which depends on the rounding of the lips; the more this configuration is accentuated, the lower the F3;
F0 and formants F1–F3, which are inversely proportional to the size and thickness of the vocal folds and the length of the vocal tract.
In the last two decades, acoustical analysis has been applied to patients affected by genetic syndromes such as Costello (OMIM #218040, CS), Down (OMIM #190685, DS), Noonan (OMIM #163950, NS), and Smith–Magenis syndromes (OMIM #182290, SMS), with interesting results highlighting highly irregular voices. The non-invasive semiotics of these diseases are generally determined by studying somatic traits. A promising approach to obtain a more detailed phenotype involves the use of objective acoustical analysis to identify parameters associated with individual pathological conditions.
Perceptually, low tonality and voice intensity, as well as hoarseness, are typical characteristics of adult CS individuals [
6]. The rarity of this syndrome has made it particularly difficult to outline a precise acoustical profile, and no objective acoustical analysis has been carried out on these patients.
In Down syndrome, Moura et al. [
7] found statistically significant differences compared to HS in the F0 for sustained vowels (/a /, /e /, /i /, and /ɔ/), as well as for formants F1–F2 and HNR measures in Portuguese-speaking children. In adults, Bunton and Leddy [
8] highlighted difficulties in phonating the three cardinal vowels (/a/, /I/, and /u/), which were associated with reduced vowel space and intelligibility.
Turkyilmaz et al. [
9] analyzed the sustained /a/ vowel of 11 children with Noonan syndrome using MVDP software (Kay Elemetrics Corporation, Lincoln Park, NJ, USA); no significant differences were found compared to a control group, except for the soft phonation index (SPI). Moreover, in a single case report, Wilson and Dyson [
10] found vowel neutralization and nasalization in a female child.
In a study by Hidalgo et al. [
11], SMS adults showed higher F0 values for the vowel /a/ than normophonic subjects, but no significant differences were found in voice disorder measures. In another paper [
12], the same authors experimented with the same vocal task with SMS children, analyzing formants F1–F2 and cepstral peak prominence (CPP) [
13], an important parameter for the assessment of dysphonia. Only CPP showed a significant difference between patients and controls.
These studies suggest that acoustical analysis can provide helpful information to doctors and speech therapists. However, the cited works focused on a single pathology and identified acoustical parameters that show statistically significant differences compared to the normophonic case. It is therefore important to extend this research by analyzing and comparing the vocal phenotypes of different syndromes to find significant changes that could support and speed up differential diagnosis and guide clinicians in the development of treatment or rehabilitation programs, especially for syndromes that are characterized by several variants that have yet to be discovered, such as Noonan’s syndrome [
14]. Artificial intelligence represents a powerful automatic system to recognize and monitor actions and movements of daily life in elder care [
15] and to analyze and distinguish images of patients diagnosed with various genetic syndromes by relying on features extracted from their facial appearance [
16]. However, such a technique has never been applied to these patients’ voice and speech characteristics, even though both anatomo-physiological and statistical studies of voice quality measures have shown significant differences compared to healthy subjects. Therefore, a methodology that allows for homogeneous collection of relevant data to perform deeper statistical analysis and novel machine learning experiments could be helpful. In this work, we propose a procedure for standardizing the recording and analysis of patients’ voices affected by different genetic syndromes. Specifically, this procedure focuses on the most appropriate devices for voice recording and vocal tasks. To ensure repeatability, we also propose signal preprocessing and feature extraction steps. Furthermore, this thesis describes statistical analysis, the development of machine learning models, and performance evaluation. The validation, feasibility, and robustness of the proposed procedure were tested by applying the proposed approach to 72 patients recruited at the Fondazione Policlinico Universitario A. Gemelli (FPUG) in Rome, Italy.
5. Discussion
This paper proposes a detailed procedure for assessing the voice characteristics of patients affected by genetic diseases. It was developed according to the general guidelines provided by otolaryngological societies and associations and by reviewing literature articles on voice analysis and automatic voice quality assessment. This is the first attempt to standardize the acquisition, analysis, and classification processes of voice samples of subjects affected by genetic syndromes. Acoustical analysis represents a promising, non-invasive approach in this clinical field, and this work aims to establish ground rules for uniform and comparable results. A Huawei Mate 10 Lite (RNE-L21) smart phone was used for the recordings. Although rigorous, the proposed procedure is easily adaptable to other pathologies. Moreover, this procedure might also be applied to languages other than Italian, considering specific vocal tasks. Being an exploratory analysis, we validated it with statistical analysis and machine learning techniques and reported the outcome. Age range and gender were taken into account, which allowed us to obtain more reliable acoustical parameters. Voice properties were compared between healthy and pathological subjects and among genetic syndromes. Specifically, we considered Costello (CS), Down (DS), Noonan (NS), and Smith-Magenis (SMS) syndromes. The results are discussed in this order.
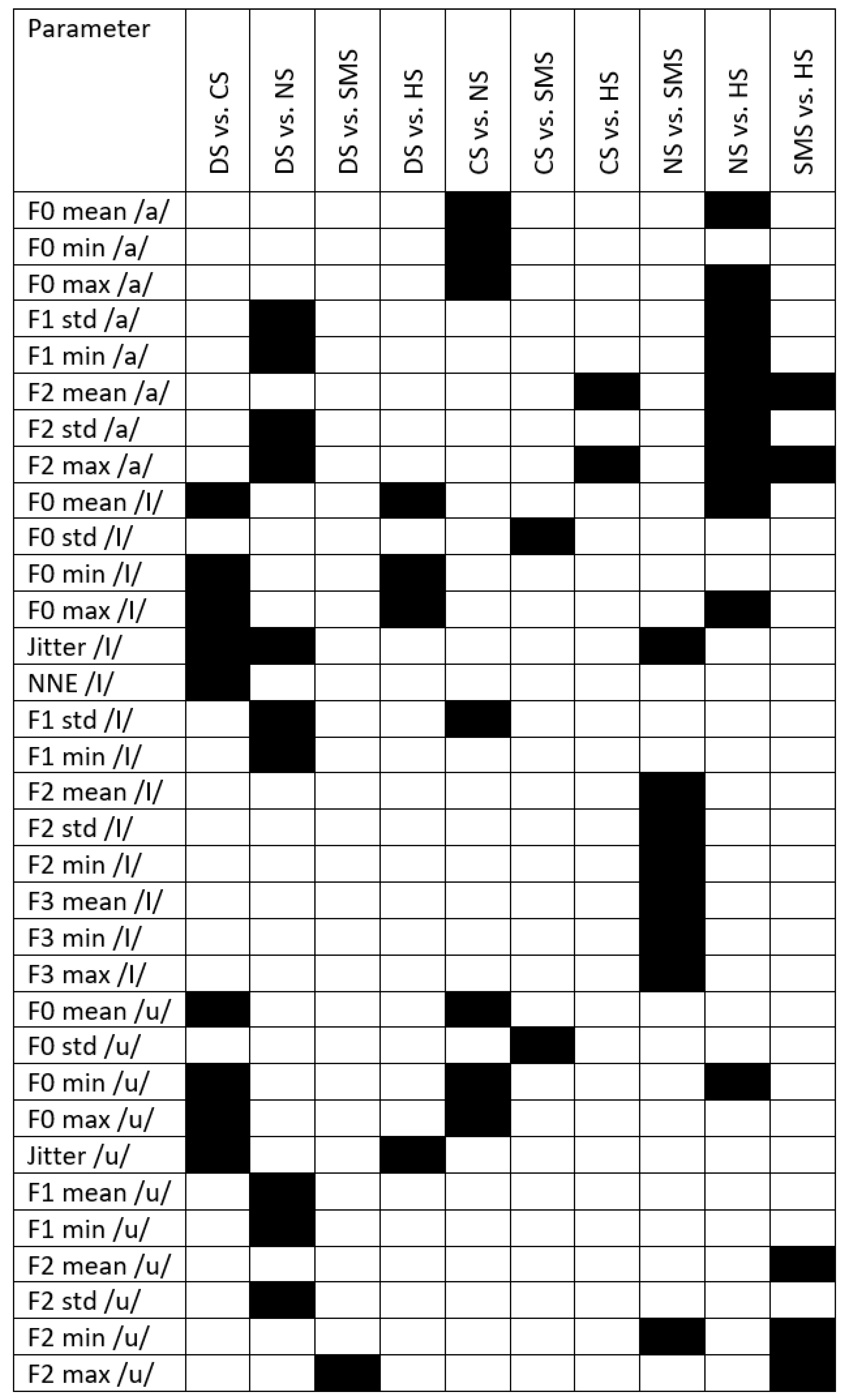
Concerning F0-related parameters, CS pediatric subjects did not show any statistically significant difference in acoustical parameters with respect to either healthy subjects or patients except, for F0 std /a/, which could reflect a lower ability to sustain vowel emission with respect to SMS patients due to generalized hypotonia or neck-muscle spasticity [
52]. Articulation deficits were highlighted by the vowel triangle (shrunk and left-shifted diagram in
Figure 3a), which may depend on detectable deformations of the vocal tract such as an ogival palate, macroglossia, hypopharyngeal velum laxity, and supraglottic stenosis [
52]. These signs, as well as pharynx structural malformations, might cause difficulties in tongue movements. Statistical analysis detected significant differences in formant ratios (related to tongue motor ranges) and articulatory measures, e.g., the F ratio
with respect to DS (
p-value = 0.006) and HS (
p-value = 0.014) and FCR with respect to NS (
p-value = 0.021), DS (
p-value = 0.015), and HS (
p-value < 0.001).
Vocal instability and noise metrics computed for /I/ showed significant differences in the FA CS group: jitter with respect to DS (
p-value = 0.018) and NNE with respect to NS (
p-value = 0.026). The latter finding agrees with the perceptual evaluation of the CS voice, which is defined as hoarse [
6]. Hypotonia constraints of lips and tongue movements, especially in reaching their limit positions, and pharyngeal space reduction due to macroglossia could be the reason for significant differences in F2 mean /a/ and F2 max /a/ with respect to the control group (
p value = 0.031 and
p value = 0.005, respectively).
In adult CS males, statistical analysis showed differences concerning articulation, specifically with respect to NS (
p-value = 0.044) for F2 min /a/ and with respect to HS (
p-value = 0.024) for F2 mean /u/, which is also supported by the vowel triangle shown in
Figure 3c. This could be related to structural alterations of the posterior fossa, which can cause dysarthria [
53], macroglossia, or generalized hypotonia. This medical evidence also relates to a significant difference in F3 min /u/ with respect to HS (
p-value = 0.023).
In the DS PS group, unlike the results reported by Moura et al. [
7], the F0 of vowels and jitter did not significantly differ from the HS group. Such a discrepancy could be related to different spoken languages (Brazilian Portuguese in [
7]), the size of the sample (The authors of [
7] applied acoustical analysis to a group of patients ten times larger than the one of this study), and the software used for acoustical analysis (PRAAT [
42]). In a review by Kent [
36], it was also stated that voice impairments with neurologic origin cause large variability in results, especially when evaluating F0 and its perturbations. As far as formant analysis is concerned, multiple comparisons showed statistical differences with respect to CS in F1 mean /a/ (
p = 0.002) and VSA (
p = 0.015) and with respect to NS in F2 max /I/ (
p = 0.021). These could be related to larger tongue dimensions, which affect tongue movements and modify vocal tract resonances.
Multiple comparisons in for DS adult females showed significant differences for jitter /I/ with respect to CS (p value = 0.018) and NS (p value < 0.001) and for jitter /u/ with respect to CS (p value = 0.037) and HS (p value = 0.038). Articulation problems, which are still present in adults, determine significant differences in F1 mean /u/ and F1 min /a/ with respect to NS (p value = 0.001 and p value = 0.028) and F2 max /u/ with respect to SMS (p value = 0.003).
In the MA DS group, post hoc analysis detected significant statistical differences for FCR with respect to HS (p-value = 0.007), for F2 mean /a/ with respect to NS (p value < 0.001) and HS (p-value = 0.015), for F2 mean /I/ with respect to HS (p-value = 0.004), and for F3 mean /a/ with respect to NS (p-value = 0.008) and HS (p-value = 0.004). Neurologic abnormalities located in the low temporal regions of the motor cortex could be the reason for these results.
For NS pediatric subjects, generalized low muscular tone, which tends to make lateralization and protrusion of the lips and tongue difficult and limits jaw opening, might explain statistical differences in F1 min /a/ with respect to HS (
p = 0.024), in F2 mean /a/ with respect to HS (
p = 0.001), in F2 mean /I/ with respect to SMS (
p = 0.001), and F ratio
with respect to CS (
p = 0.049). Indeed, with ultrasonographic measures, Lee et al. [
54] demonstrated that F1 and F2 are strongly correlated to the oral cavity anterior length and the tongue posterior superficial length. Moreover, T0(F0 min) /a/ and T0(F0 max) /a/ show significant statistical differences with respect to HS (
p ≤ 0.001 and
p = 0.002, respectively), which could be related to patients’ difficulty in maintaining stable and regular vocal-fold vibration during phonation.
Statistical analysis of FA diagnosed with NS has highlighted differences in F0 mean /a/ and F0 mean /I/ with respect to HS (
p value = 0.005 and
p value = 0.028, respectively) and in F0 mean /u/ with respect to CS (
p-value = 0.006). These alterations might depend on the shorter height and neck with respect to control subjects, a common phenotypical feature for this syndrome. Moreover, jitter /I/ showed a significant difference with respect to CS (
p-value = 0.018) and SMS (
p-value = 0.025). However, this consideration must be taken with caution due to the limited size of our database. As shown in
Figure 3b, the NS FA vowel triangle is characterized by a small area, but VSA did not show any statistical significance. Nevertheless, formant coordinates have shown significant differences in F2 mean /a/ with respect to HS (
p-value = 0.001), in F1 mean /u/ with respect to DS (
p-value = 0.001), and in F2 mean /I/ with respect to SMS (
p-value = 0.024). Such alterations can be associated with difficulties in lips protrusion and lateralization [
37].
Regarding the NS MA group, NNE values were closer to 0, especially for /I/ and /u/ with respect to HS (
p value < 0.001 and
p value = 0.001, respectively), which might be associated with the presence of an anterior glottis web [
55] or a tendency to incur vocal fold paralysis. However, since this work is mainly focused on acoustical analysis, it was not possible to verify this statement through laryngostroboscopy for these patients.
Figure 3c shows vowel-area reduction and centralization. Significant differences in both VSA and FCR were detected with respect to HS (
p value < 0.001 and
p value = 0.001, respectively). F2 also showed significant differences: F2 mean /a/ with respect to DS (
p value < 0.001), F2 mean /I/ with respect to HS (
p-value = 0.004), and F2 mean /u/ with respect to HS (
p-value = 0.028). Such alterations might depend on structural properties, such as choanal atresia, supraglottic stenosis, soft palate laxity, and neurologic problems.
In PS SMS subjects, articulation measures and formants showed significant statistical differences for F1 mean /u/ with respect to CS (
p = 0.034), F2 mean /a/ with respect to HS (
p = 0.037), F2 mean /I/ with respect to HS (
p = 0.015) and CS (
p = 0.001), F ratio
with respect to HS (
p = 0.004), and FCR with respect to HS (
p = 0.001). According to Hidalgo et al. [
12], neither F1 nor F2 could discriminate SMS individuals from the control group. This difference could have resulted from the use of different acoustical analysis software tools. First-formant alterations may be linked to velopharyngeal insufficiency, which is an incomplete closure typical of SMS patients that causes a constant airflow leak through nasal cavities, consequently altering resonant frequency along the vocal tract [
38].
For the FA group diagnosed with SMS, significant differences were found for F2 mean /a/ with respect to HS (
p-value = 0.026), F2 mean /I/ with respect to NS (
p-value = 0.024), and F3 median /I/ with respect to NS (
p-value = 0.001) and CS (
p-value = 0.039). Hypotonia and structural lip malformations [
11], in addition to frontal lobe calcification and cortical atrophy, could be the reasons for these anomalies.
For the MA SMS group, orofacial dysfunctions worsened by hypotonia, soft-palate clefts, and posterior fossa anomalies might be responsible for articulation disabilities and related to significant differences that were identified for F1 min /a/ and F2 max /u/ with respect to HS (p value = 0.050 and p value = 0.009, respectively).
The shape and position of the vocalic triangles shown in
Figure 3 show that age and gender strongly influence F1 and F2 compared to the reference adult males (solid line with diamond markers); the PS group; and, to a lesser extent, the FA group. Higher formant values are associated with shorter and smaller sizes of the vocal folds and vocal tract. These results underline the importance of conducting acoustical analysis considering age and gender. Moreover, as shown in
Figure 3c, a difference also exists between the healthy adult male subjects considered in this study (simple solid line) and the reference adult males (solid line with diamonds), possibly because of our limited sample size.
Table 6 shows an interesting result: HS is always correctly identified in the PS and FA groups. As supported by statistical analysis, the voice quality of normophonic and pathological subjects differs, for allowing an almost complete separation between these two macroclasses.
In particular, the KNN classifier of the PS group achieved the highest mean accuracy of 87%. Such a result was expected due to the larger size of the pediatric subject dataset. The CS class showed a high precision (100%). However, the low recall value (50%), along with its std, suggests that vocal properties might not be specific solely to this syndrome. SMS and NS present a more stable outcome, with especially high specificity scores. However, NS is characterized by a variable recall value (80 ± 42%), which may mean that the NS vocal phenotype is not easy to define.
The SVM model of the FA group performed well on the CS and DS classes. Therefore, these two syndromes seem to present specific voice characteristics, avoiding the other pathologies being classified as NS and CS due to their 100% specificity values. The SMS class showed poor performance, as some NS, CS, and DS observations were classified as SMS, possibly because it was the most numerous class.
Considerations similar to those of the FA group can be applied to the male cohort. High performance characterized CS and DS class recognition as well. It is important to note that the HS were not all correctly identified in the MA group, and some observations were misclassified as DS. The overall accuracy is similar to that of the PS group (84%), but this result must be taken cautiously, as the MA cohort was the smallest in our study. Therefore, in the future, it will be important to understand whether the same performance can be achieved by increasing the sample size and reducing the number of parameters.
These preliminary results are promising in terms of defining a phonatory profile for genetic diseases. However, we remark that this outcome was obtained with a limited dataset, so more voice samples must be collected. Another limitation is the choice to use all available recordings for some of the patients in the case of extremely rare diseases; although precautions were taken, the results might be biased due to the lack of totally independent data. By applying the proposed procedure to a larger dataset, it will be possible to carry out reliable comparisons to validate and possibly find new acoustical features that could reliably describe genetic syndromes. Indeed, with a large amount of data, new models could be developed to determine whether the same differences in the acoustical parameters between syndromes found in this work can be confirmed and whether any improvements in classification results are feasible. For this exploratory analysis, we used acoustical features of the sustained /a/, /I/, and /u/ vowels to obtain results comparable with those reported in previous works. Moreover, these vowels were the most numerous vocal tasks in our small dataset. The small number of subjects analyzed in this first study did not allow for investigation of feature selection or feature engineering techniques to obtain better classifiers. Such methods will be implemented once a more extensive database is available.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}