We have performed all the work on the datasets on a computer with the following configuration.
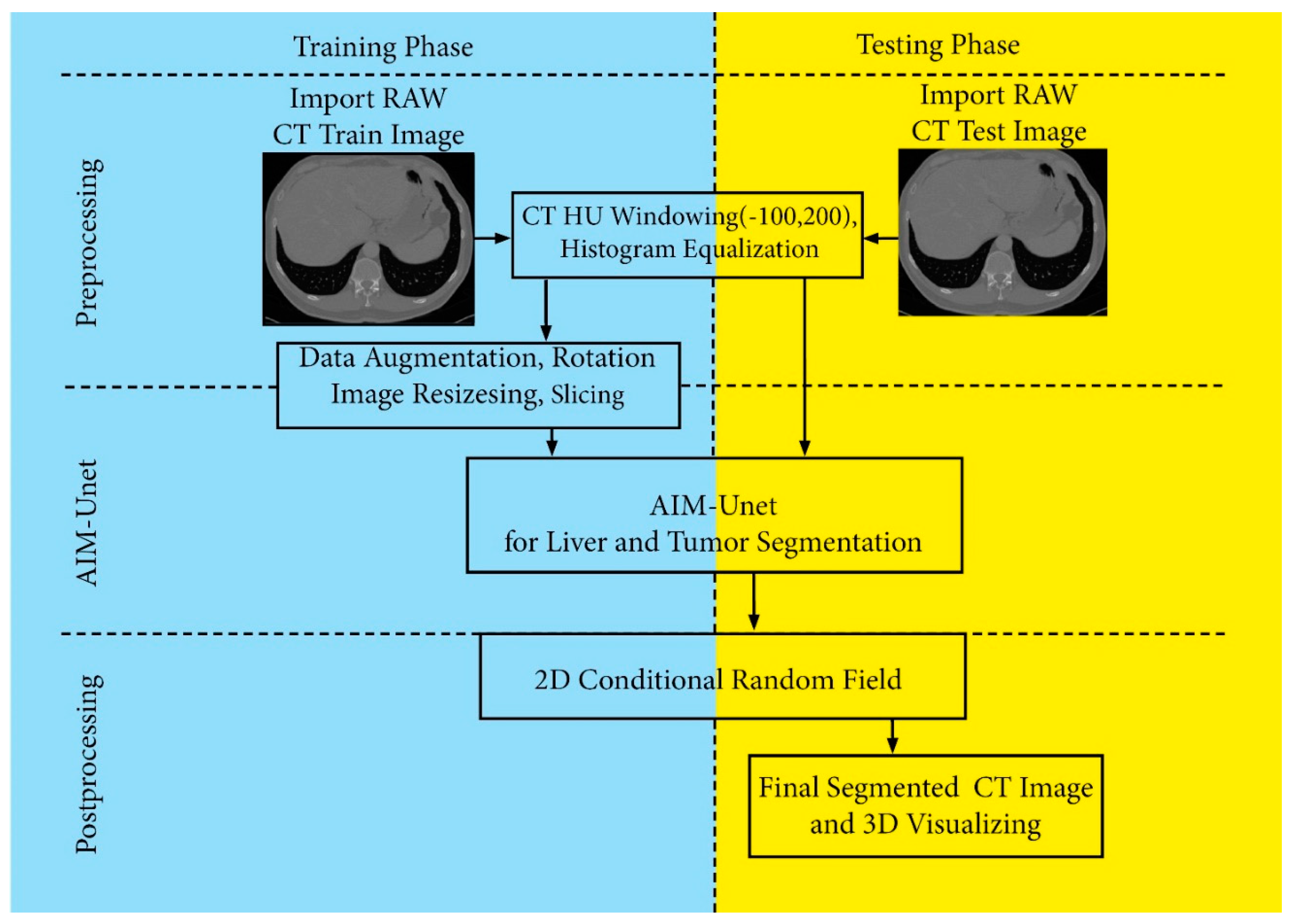
We used the Tensorflow 2.2.0 framework, which allows for dynamic stack size, to do the research. We also developed our application on the Spider 5.0 IDE, with Python 3.6 interpreter and Keras-nightly version 2.5.0. We chose the binary cross entropy function as the loss function for the measurement of accuracy and loss. We also observed IoU (Intersection Over Union), Dice loss, recall, and precision metrics during the training. The network architecture is based on the U-Net architecture and the Inception architecture. However, convolution and stack normalization layers are included in the skip connections of this study, and the number of layers has changed in the skip connections. Therefore, the network is trained from scratch each time. During the training, many experiments were carried out by adjusting the hyperparameters used in the network. The learning rate, batch size, epoch and dropout value, optimizer, loss function, and activation function were checked for different values and assignments. After much trial and error, a batch size of 3, epochs of 100, a validation division of 0.20 (after test data separation), and a learning rate of 0−3 were used. We saw that the Adaptive Moment Estimation (Adam) optimizer gave the best results. When we used early stopping for the validation loss (for patience = 5) in our trainings, we saw that the 95th epoch training was complete. Most values did not change after this epoch, and that is why we didn’t use early stops in the next training. We finished the training in the 100th epoch
4.1. Datasets
We use three liver image datasets to evaluate our model, two of which are the publicly available LiST dataset and the CHAOS dataset, and the other is the dataset we created. Most of the liver-free sections of patients in these datasets were discarded. Any patient’s data in the datasets is 512 × 512 × N in size. Here, the N number is called the number of slices and may vary according to the patient’s liver size. Each slice (abdominal) image of the patients was recorded as an image. 10% of patients were randomly assigned for testing across all datasets. Then, in the remaining patients, 30% were randomly assigned as validation data and 70% as test data. Each dataset was trained and tested separately. Details of the number of images used in datasets are given in
Table 2.
4.1.1. Patients and Data Acquisition Protocol
This study was carried out in accordance with the criteria determined by the Ministry of Health by obtaining the necessary permission from the Faculty of Medicine of Trakya University, dated 12 February 2020, and numbered 600-E.411005. The study was performed in accordance with the Helsinki Declaration and approved by the local ethics committee, numbered TÜTF-BAEK 2020-7254. In addition, patient data were collected and processed in accordance with Republic of Turkey Law No. 6698 on the Protection of Personal Data. In this study, data from 50 different patients (28 males and 22 females) aged between 25 and 83, some of whom were diseased and some of whom were healthy, were used. The dataset was created with the abdominal images of each patient, consisting of an average of 73 sections.
4.1.2. Creating the Dataset (Our Dataset)
It is very difficult to obtain the amount of data that needs to be collected to solve a segmentation problem. By difficult, we mean time, hardware, and perhaps most importantly, the labeling of data. An ordinary eye will not be sufficient for tagging, localization, and positioning information of each pixel, especially in areas that require sensitive approaches such as biomedical or defense. For this, expert eyes and experience are needed in many related images.
Appropriate PET-CT images were stored from the hospital database in Digital Imaging and Processing in Medicine (DICOM) format. All stored images were resized to a resolution of 4.7 × 6.3 × 30 mm. The sections were examined one by one by the specialist medical doctor, and the anatomical liver tissue was marked. Liver areas (ROI) determined by expert radiologists were labeled 1, and non-hepatic areas were labeled 0. After the tagging process, the original images were added to the dataset as 512 × 512 × 3 pixels with a jpg extension with a 3-channel color depth, and the tagged images as a png extension with a single-color channel with 512 × 512 × 1 dimensions.
4.1.3. The LiTS Image Dataset
The images in this dataset were collected from clinics and university hospitals in various countries around the world. IRCAD Institute Strasbourg, Hebrew University of Jerusalem, Tel Aviv University, Sheba Medical Center, Ludwig Maximilian University of Munich, Polytechnique and CHUM Research Center Montreal, and Radboud University Medical Center of Nijmegen are some of them. Most of the patients in this dataset suffer from liver diseases. The images of the patients include primary (i.e., originating in the liver-like hepatocellular carcinoma, HCC) and secondary (i.e., spreading to the liver-like colorectal cancer) tumor diseases, as well as metastases originating from breast and lung cancers. Images were acquired from different devices under different acquisition protocols. Therefore, the data has different resolutions, image quality, and contrast densities. The LiTS dataset contains 131 and 70 contrast-enhanced 3D abdominal CT scans for training and testing, respectively [
46]. The number of sections in the images of these patients ranged from 42 to 1026, and the number of sections containing the liver ranged from 30 to 253. Each patient has an average of 150 images. The sections have different thicknesses between 0.45 mm and 6.0 mm. Data were downloaded in nfii file format, and images without liver were extracted for a faster conclusion of the model. In the training and test sets of the liver, volumes show a normal distribution and are similar to known distributions. There are 19,433 images in total in the dataset, and the usage distribution of these images is shown in detail in
Table 2.
4.1.4. CHAOS Dataset
The images in this dataset were collected by the Department of Radiology at Dokuz Eylül University. The dataset includes original CT images of 40 patients and images marked by expert radiologists. Of these patients, 22 were men and 18 were women [
47]. In addition, the age range of the patients ranged from 18 to 63 years. Patient images do not contain any pathological abnormalities (tumors, metastases). So the images contain only healthy abdominal organs. There are 2975 images in total in the dataset, and the distribution of use of these images is shown in detail in
Table 2. The number of slices for each patient varies between 77 and 105, and an average patient has 90 images. Images are in a DICOM format with 512 × 512 resolution. The slice thickness of each image ranges from 3.0 to 3.2 mm. As in the LiST dataset, the liver sizes in this dataset show differences. The reason for this is that the anatomical structure of each patient is different.
4.1.5. 3DIRCADb Dataset
This dataset is a subset of patients 28-47 from the LiST dataset, which consists of 131 patient records. A total of 20 patients are included in the 3DIRCADb dataset. 16 of these patients have tumor images. The total number of slices with tumors is 588.
4.4. Metrics
Various measurement performances are taken into account to analyze the experimental results [
49,
50]. Accuracy (AC), recall (sensitivity) (RE), prevalence (PV), specificity (SP), precision (PR), Dice similarity coefficient (DSC), and Jaccard similarity coefficient (JSC) measurement performances are some of them. To calculate these performance measures, a confusion matrix is used, which includes the variables True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN) in
Figure 5.
The overall accuracy value was calculated using Equation (1), and recall is calculated using Equation (2).
Furthermore, the precision [
51] value is calculated using the following Equation (3).
Cross-entropy loss is the loss function that is widely employed in semantic segmentation tasks. The cross-entropy loss examines each pixel one by one and compares the predicted results (probability distribution vector) for each pixel category with the heat-coded label vector. When there are only two categories, a binary cross entropy loss, called BCE loss, is used and represented as Equation (4). We chose the binary croossentropy function as the loss function when training the datasets. Cross-entropy [
4] can be defined as a measure of the difference between two probability distributions for a given random variable or set of events. It is commonly used to classify the objects and the segmentation levels, if pixel works properly.
Binary cross-entropy is defined as:
Here, P is the predicted image by the prediction, and G is the ground truth image.
We can consider Dice score as the matching level between predicted and ground truth image. The range of a Dice score is a value between 0 and 1. The higher the score, the better the performance. If this value is zero, it indicates that there is no relationship between the predicted image and the ground truth image. It is clear that the maximum of Dice score is one, if the predicted image and the ground truth image are completely overlapping. In addition to the calculation of binary precision, the threshold parameter, which we set to 0.5, is calculated. Each predicted pixel is compared with the threshold. If the pixel value is less than or equal to the threshold value, 0 is assigned to the value of that pixel, if the pixel value is greater than the threshold value, that pixel value is assigned 1.
The Dice coefficient is calculated using Equation (5), and Dice loss is calculated using Equation (6).
where P is the image predicted by our proposed model, and G is the ground truth image.
Jaccard index is very popular and used as a similarity index for binary data, as shown in the following form.
We also calculated the mean IoU, recall, and precision metrics as well as the Dice score metric. These metric values are given in
Table 3 and
Table 4 for 3 datasets.
The aim of this study is to reveal the ability of different sized filters in the Inception module added to the U-Net model to automatically extract the liver region. The evaluation of the method was measured by comparing the area estimated by a radiologist with the actual area. The most commonly used measurement values are Dice score and Jaccard index (IOU). The changes to these values in our model are as shown in
Figure 6.
Figure 6 shows the decimation of the validation errors after the Adam optimizer, as we used the cause of the ted concussions and the refresh of the learning rate. Some masks that we obtained as a result of training the model are shown in
Figure 7. To measure the success of our proposed model, we trained the network only with our dataset and then tested it separately on the LiST and CHAOS datasets. Next, we repeat this procedure for the other dataset as well, and we report the results on
Table 3. The values in
Table 3 show the test results of the proposed model after training on each dataset separately. The numbers of images used in the training and test data sets are given in
Table 2. If we pay attention to
Table 4, the results trained on the LiST dataset and tested on our dataset have the largest standard deviations. The reason for this is that the image in our data set differs as a result of morphological operations. As seen from
Table 4, the most successful test results are from the model trained on the CHAOS dataset. However, the test results of the proposed model trained on our dataset and tested on the Chaos dataset are very close to the highest values. Also, looking at the data in the table, it is seen that the AIM-Unet model has achieved successful results in all datasets.
As can be seen from the test set results in
Table 4, the model we propose has very good results on three datasets. The test results in
Table 4 obtained from the three data sets show that the model can be easily used in daily routine clinical applications.
In this part of the study, we discuss and analyze the computed tomography results in the datasets to evaluate the performance of the proposed model. The results estimated by AIM-Unet from images on different datasets are shown in
Figure 8. The red areas in the comparison image show the regions that our model missed, the green areas are the areas that the model predicted incorrectly, and the yellow areas are the regions that the model predicted correctly. The estimation results of liver and tumor regions in the LiST and 3DIRCADb datasets by AIM-Unet are shown in
Figure 9.
The average Dice score and Jaccard index values of the proposed model for liver segmentation are given in
Table 5, and those for tumor segmentation in
Table 6. As can be seen from
Table 5, the model we propose has higher values than other models in terms of Dice score and Jaccard index. This shows that the use of different filters in the model produces more successful features and makes the model more successful. However, the model we proposed on the CHAOS dataset and the dataset we created, has been the most successful model. In addition, when we look at the Jaccard indexes, it was the model we recommended that showed the most successful performance on 3 datasets. While the model proposed for tumor segmentation in
Table 6 achieved very successful results on the LiST dataset, its success remained low in the 3DIRCADb dataset. The reason for this is that there are more tumor images in the LIST dataset, and the model learns better from this extra image.
The number of patients required to train a segmentation model depends on the variability in the data, the completeness of the data with respect to missing labels, and the AI model used. A model for tumor segmentation usually requires more patient data than OARs because tumor shape and location are more variable than in normal anatomy. Currently, state-of-the-art CNN-based shaping models typically consist of more than 100 patients. However, models of 50–100 patients have also been shown to segment OARs with reasonable accuracy. Information on the patient data sets used in our study is given in
Table 2. The variability in the training data should reflect the variability of the clinical data for which the model will be used. For example, if the model will be used for different imaging acquisition protocols or devices, the training set should contain all of these types of data [
62]. Finishing operations such as bonded component selection, hole filling, or smoothing can be performed to obtain more clinically relevant contours. Validation and test sets typically contain about 20 patients. A minimum of 10 patients is recommended but should be increased if there are large differences in outcomes. The test sets used in our study are given in
Table 2.
Both IoU and DSC are used to calculate the overlap of baseline truth masks and U-Net generated images, indicating the degree of similarity. High DSC and IoU values correspond to correct segmentation (
Table 5).
Contour definition accuracy in radiotherapy is also evaluated using DSC. Among CNN architectures adapted for medical imaging, U-Net and its variations are the most popular among researchers, and techniques have been devised to deal with smaller datasets, a practical limitation in many medical imaging applications [
63].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}