Abstract
Combined arterial spin labeling (ASL) and functional magnetic resonance imaging (fMRI) can reveal more comprehensive properties of the spatiotemporal and quantitative properties of brain networks. Imaging markers of end-stage renal disease associated with mild cognitive impairment (ESRDaMCI) will be sought from these properties. The current multimodal classification methods often neglect to collect high-order relationships of brain regions and remove noise from the feature matrix. A multimodal classification framework is proposed to address this issue using hypergraph latent relation (HLR). A brain functional network with hypergraph structural information is constructed by fMRI data. The feature matrix is obtained through graph theory (GT). The cerebral blood flow (CBF) from ASL is selected as the second modal feature matrix. Then, the adaptive similarity matrix is constructed by learning the latent relation between feature matrices. Latent relation adaptive similarity learning (LRAS) is introduced to multi-task feature learning to construct a multimodal feature selection method based on latent relation (LRMFS). The experimental results show that the best classification accuracy (ACC) reaches 88.67%, at least 2.84% better than the state-of-the-art methods. The proposed framework preserves more valuable information between brain regions and reduces noise among feature matrixes. It provides an essential reference value for ESRDaMCI recognition.
1. Introduction
End-stage renal disease (ESRD) is an end-stage of chronic kidney disease, often accompanied by serious symptoms such as renal failure and multi-organ dysfunction [1]. In recent years, the global incidence of ESRD has been increasing yearly, which brings a heavy economic burden to society and families and great psychological stress to patients [2]. Studies have shown that 30% to 60% of ESRD patients, especially those receiving hemodialysis treatment, develop mild cognitive impairment (MCI) [3]. If left untreated, MCI may develop into Alzheimer’s disease (AD), affecting ESRD patients’ later treatment [4]. However, the pathophysiological mechanisms of ESRD associated with MCI (ESRDaMCI) are not fully understood, so neuroimaging studies of these patients are important for their treatment.
Currently, neuroimaging techniques have matured, allowing researchers to acquire various types of medical imaging data easily. Numerous studies have demonstrated that a more comprehensive understanding of disease mechanisms can be achieved by examining multimodal data from participants [5,6] in contrast to the information in unimodal data. For example, Jiao et al. [7] combined positron emission tomography (PET) and structural magnetic resonance imaging (sMRI) data for feature selection. Li et al. [8] integrated cerebral blood flow (CBF) from arterial spin labeling (ASL) and blood oxygen level-dependent (BOLD) of functional magnetic resonance imaging (fMRI) to replace unimodal data for the classification of mild cognitive impairment (MCI). Jann et al. [9] proposed a connectivity framework between CBF-ASL and BOLD-fMRI, which revealed more comprehensive spatiotemporal and quantitative properties of brain networks through the combination of fMRI and ASL. The better utilization of multimodal data is a hot topic in current studies.
The most crucial aspect in classifying related diseases, such as MCI or ESRDaMCI, is selecting disease-relevant features from multimodal data to improve classification performance. In machine learning, this objective can be achieved by manipulating the properties of the multimodal feature matrix, changing the feature assignment weights, and optimizing feature selection algorithms. On the one hand, Liu et al. [10] constructed the feature matrix with sparse regularization, thereby reducing the impact of redundant features. Rehman et al. [11] improved model productivity by means of feature assignment weights. On the other hand, among numerous feature selection methods, embedded methods are currently the most widely applied [12]. The multi-task learning is applied for small datasets related to medical diseases because it better reveals shared features among different tasks and facilitates data sharing between them, exhibiting good generalization capability [13]. In addition, the feature assignment right is more likely to ignore the correlation between features than multi-task feature selection, which is not suitable for the classification of multimodal data, and it does not reduce the feature dimensionality, which can easily affect the classification results. The multi-task feature selection method is often enhanced by introducing different regularization terms [14]. For instance, Jie et al. [15] proposed a learning method that combines manifold regularization and multi-task feature selection. They embedded a manifold regularization term into the feature selection process by predefined a similarity matrix to realize data sharing. Shao et al. [16] constructed hypergraph regularization terms for each modality within the feature matrix and incorporated them into multi-task learning to reflect high-order relations among subjects. In recent research, Shi et al. [17] introduced adaptive similarity learning, resulting in more accurate similarity matrices. Song et al. [18] introduced topological manifold terms to construct similarity matrices with topological relations.
Nevertheless, the aforementioned methods only construct similarity matrices based on the original feature matrix without considering the presence of noise and outliers in real-world data. They also overlook the incorporation of high-order prior information from brain regions when constructing the multimodal feature matrix. Just changing the attributes of the feature matrix, or optimizing the feature selection algorithm, does not improve the classification performance better. Improving the classification performance, and finding the discriminative brain regions of ESRDaMCI, can provide a scientific basis for medical clinical diagnosis and identification of ESRDaMCI and reduce the time and economic cost. In view of this, we propose a multimodal classification framework based on hypergraph latent relation (HLR) for classifying ESRDaMCI and normal subjects. Firstly, a brain functional network is constructed based on the method of hypergraph manifold, and the feature matrix of fMRI is extracted by graph theory (GT) [19]. Secondly, CBF from ASL is selected as the feature matrix for the second modality. Then, latent relation adaptive similarity learning (LRAS) is embedded into the multi-task feature selection, constructing a multimodal feature selection method based on latent relation (LRMFS). Finally, the selected features from the proposed framework are linearly fused into a multicore support vector machine (MKSVM) for classification. In this study, the hypergraph feature matrix retains high-order features from the brain function network with hypergraph structural information. It focuses on the relational information of multiple brain regions rather than pairwise brain region relationships. LRMFS is applied to uncover the latent relationships within the feature matrix, resulting in the construction of a robust similarity matrix and the selection of well-represented features. These two components constitute the HLR-based multimodal classification framework. Moreover, the framework can also identify discriminative brain regions affected by ESRDaMCI, providing valuable insights for identifying and diagnosing MCI-related diseases.
2. Data and Methods
2.1. HLR-Based Multimodal Classification Framework
Figure 1 shows the HLR-based multimodal classification framework for ESRDaMCI. The specific steps are as follows. (a) Preprocessing the fMRI data to obtain the time series of all brain regions of the Automated Anatomical Labeling (AAL) template; (b) Constructing the hypergraph feature matrix of fMRI by the hypergraph graph theory (HGT); (b-1) Transforming the Laplacian matrix obtained from hypergraph construction into a hypergraph manifold regularization term and a sparse regularization term to derive a new brain functional network; (b-2) Obtaining the feature matrix of all subjects by graph theory; (c) Extracting CBF values from various brain regions in ASL data with the AAL template to construct a feature matrix; (d) Inputting the feature matrix of two modalities into the multimodal feature selection model proposed by the framework; (e) Outputting well-selected feature vectors from both modalities; (f) Fusing the feature vectors to generate a new feature matrix; (g) Dividing the new feature matrix into training and testing sets, and performing classification on normal subjects and ESRDaMCI patients via MKSVM.
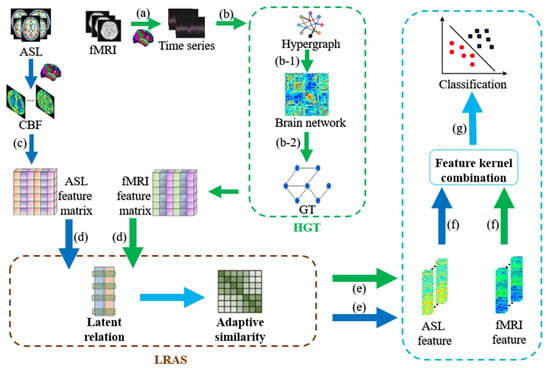
Figure 1.
Flowchart of HLR-based multimodal classification framework. Blue arrows represent ASL modality and green arrows represent fMRI modality.
2.2. Data Preprocessing
We employ the same original dataset as Song et al. [18]. Forty-four patients with ESRDaMCI from the Affiliated Changzhou No.2 People’s Hospital of Nanjing Medical University were selected as the ESRD group. They include 24 males and 20 females, aged 49.25 11.15 years. Meanwhile, 44 healthy volunteers who underwent a physical examination at the same hospital and matched the age and education level of the subjects in the ESRD group were selected as the Normal Controls (NC) group. They include 13 males and 31 females, aged 46.25 11.39 years.
This study has been approved by the Ethics Committee of this hospital and conformed to the 2013 revision of the Declaration of Helsinki (www.wma.net/en/30publications/10policies/b3/index.html), accessed on 5 May 2023. All subjects signed written informed consent and volunteered to participate in this study. The Montreal Cognitive Assessment (MoCA) assessed their cognitive functions. This assessment tool is primarily used for screening and evaluating cognitive impairments, including attention and concentration, executive functions, memory, language, visuospatial skills, abstract thinking, calculation, and orientation. It is a convenient and effective tool with a total score of 30 points. Scores with 26 or more as normal, 18–26 as mild cognitive impairment, 10–17 as moderate cognitive impairment, and less than 10 as severe cognitive impairment [20]. The ESRD group has an average score of 23.87 4.51 points. Specific participant information can be found in Table 1.

Table 1.
Demographic information of subjects.
All subjects are scanned by a GE Discovery MR 750W 3.0T scanner and are placed on the magnetic resonance imaging (MRI) equipment. Their heads are immobilized with rubber cork inside the MRI coil during the scans to avoid artifactual images caused by head movements. T1-weighted brain structure images are obtained by adopting the 3D brain volume imaging (3D-BRAVO) sequence. The specific machine parameters are repetition time (TR) = 7.5 ms, echo time (TE) = 2.5 ms, reversal time = 450 ms, flip angle (FA) = 15°, layer interval = 1 mm, the field of view (FOV) = 240 mm × 240 mm, layer thickness = 1 mm, the number of scanning layers = 154, and the scanning time = 3 min 51 s. fMRI is obtained from the gradient-echo plane echo imaging (GRE-EPI) sequence. The machine parameters are TR = 2000 ms, TE = 40 ms, layer thickness = 4 mm, FA = 90°, FOV = 240 mm × 240 mm, matrix size = 64 × 64, and the scanning time = 8 min. ASL is obtained from the 3D pseudo-continuous arterial spin labeling (3D-pcASL) sequence. The machine parameters are TR = 5335 ms, TE = 10.7 ms, layer thickness = 4 mm, post-labeling delay (PLD) = 2525 ms, FOV = 240 mm × 240 mm, layer thickness = 4 mm, the number of scanning layers = 36, and the scanning time = 3 min 44 s.
The raw fMRI data are preprocessed in the Statistical Parametric Mapping (SPM12) and the Data Processing Assistant for Resting-State fMRI (DPARSF) on the Matlab 2021a platform [21]. The preprocessing involves the following steps. (a) Data format conversion: The original sample data in DICOM format are converted to 4D NIFTI format files. (b) Slice timing correction: The first ten time points are discarded because it takes time for the examination instrument and the subject to enter a steady state. (c) Image registration: Head motion correction is performed, and the fMRI images are registered to the Montreal Neurological Institute (MNI) standard brain space by an EPI template (Bounding box: [−90, −126, −72; 90, 90, 108], Voxel Size: [3 3 3]). (d) Spatial smoothing: The normalized fMRI images are spatially smoothed with a Gaussian kernel (FWHM: [5 5 5]). (e) Bandpass filtering and linear detrending. (f) Time series extraction: It adopts the AAL template to extract the time series of 90 brain regions [22].
The raw ASL data are preprocessed in the SPM12 and the Resting-State Functional MRI Data Analysis Toolkit (REST 1.8) toolbox on the Matlab 2021a platform [23]. The preprocessing involves the following steps. (a) Data format conversion: The original sample data in DICOM format are converted to 4D NIFTI format files. (b) Image registration: It performs the registration taking the CBF image as the reference image and the T1 image as the source image. (c) Image segmentation: The registered T1 structural image is segmented. (d) Normalization: It normalizes the CBF image in the MNI standard brain space (Bounding box: [−90, −126, −72; 90, 90, 108], Voxel Size: [3 3 3]). (e) Spatial smoothing: The normalized wCBF image is spatially smoothed with a Gaussian kernel (FWHM: [5 5 5]). (f) CBF value extraction: The REST toolbox extracts feature from the smoothed CBF image. It sets the CBF of 90 brain regions as the features of ASL.
2.3. Hypergraph Feature Matrix
A basic brain functional network is constructed according to Pearson correlation coefficients. Then, the Laplacian matrix is obtained by constructing the hypergraph, which is transformed into the hypergraph manifold regularization term. It is introduced into the basic brain functional network with the sparse regularization term [24] to obtain a brain functional network with sparse and hypergraph manifold regularization (SHMR). The objective function of SHMR is:
where denotes the time series matrix and denotes the coefficient matrix of the brain function network. is the normalized Laplacian matrix of the hypergraph, and denote the hypergraph manifold regularization term parameter and sparse regularization term parameter, respectively. is set as , and is set as according to [24].
The brain topological structure is disrupted after the onset of cognitive impairment, leading to decreased transmission efficiency of individual nodes [25]. Thus, we select nodal efficiency as the first modal feature. For each participant’s SHMR-based brain functional network, binary processing is performed by the matrix sparsity as the threshold. The sparsity is set from 0.01 to 0.35 with a step size of 0.01 [26]. The area under the curve (AUC) of nodal efficiency is computed for all participants within the range of sparsity thresholds, resulting in the hypergraph feature matrix. Additionally, we adopt the Z-score normalization method to standardize and normalize the hypergraph feature matrix. The Z-score normalization method can eliminate differences between the CBF features and hypergraph features, facilitating feature weight learning.
2.4. Adaptive Similarity Learning
In the case of single-modal data, we assume a feature matrix and a label matrix corresponding to the data, where d represents the feature dimension and n represents the number of features. The similarity vector s is constructed by calculating the Euclidean distance between different pairs of feature dimensions. Additionally, it is assumed that the smaller the distance between feature vectors and , the larger the similarity . If feature vectors and belong to different classes, then . The objective function is defined as follows:
where represents the similarity vector between and others and represents the j-th element of . The objective function of adaptive similarity learning can calculate the similarity matrix for each subject, taking into account both cases: when a feature vector has one or more nearest neighbors with the same similarity and when it does not. Generally, we treat the latter case as a regularization term to avoid trivial solutions from the former case.
Once the objective function for the unimodal similarity vector is determined, it can extend the adaptive similarity learning to multimodal learning. We define the number of modalities as m, and represents the feature matrix of the m-th modality. For the multimodal data, we solve the following problem to obtain the similarity matrix S:
2.5. Multimodal Feature Selection Based on Adaptive Similarity Learning
Multi-task learning involves simultaneously learning multiple related tasks and improving learning efficiency by leveraging the shared data among the tasks [12]. The adaptive similarity-based multimodal feature selection (ASMFS) method is proposed by combining adaptive learning and multi-task feature learning, with the objective function defined as follows:
where is the feature weight matrix, and represents the weight vector of the m-th modality. represents the norm of the matrix W, denoted as , which allows joint feature selection by combining the weights of the same features across different modalities. are regularization parameters that balance the relative weights of the terms in the equation.
2.6. Multimodal Feature Selection Based on Latent Relation
During adaptive similarity learning, real data often contain noise and outliers, which can affect the accuracy of the similarity matrix. Therefore, it is necessary to learn the latent relation within the original data, allowing the adaptive similarity learning process to resist noise and filter out anomalies. Currently, semi-negative matrix factorization (SNMF) can extract the latent relation in the original data due to its intuitive interpretation based on parts [27].
We define as the base matrix for modality, which represents the base matrix for the m-th modality. V is the complementary coefficient matrix for all modalities. is the coefficient matrix of latent feature vectors for different modalities, which is calculated adopting the inverse distance weighted strategy. The objective function for learning the latent relation is expressed as follows:
The coefficient matrix V in Equation (5) can effectively capture the intrinsic features of the original data. Its orthogonality constraint helps reduce the influence of outliers and noise [28]. V can be considered a robust representation of the original data X, and it can substitute for X in the adaptive similarity learning process. The objective function of the LRMFS is:
where c is the number of categories and is the Laplace rank constraint.
This objective function involves constraints such as orthogonality, non-negativity, and norm. The iterative update algorithm efficiently addresses the objective function [29]. Its constraints are separated by introducing auxiliary variables and , and the equivalence is maintained during the update process. Moreover, balancing parameters and are introduced, with serving as the Lagrange multiplier matrix for the difference between the target variable and auxiliary variable. Each variable is optimized through iterative updates.
- (a)
- Update :
Update under the constraint of , the optimization equation is shown below:
- (b)
- Update :
With the other variables kept fixed, V is updated, and the optimization equation is changed to:
where Q is obtained by Equation (9):
The solution of V is given by
where O and H are the left and right singular values of SVD [30] of Q
- (c)
- Update :
Ensuring that the other variables are fixed, the optimization formula for is
where .
- (d)
- Update W:
Inspired by [31], the elements of Equation (6) related to W are weighted and iterated. When the element in row W is not zero, define , and obtain the derivative with respect to :
Defining D as the diagonal matrix of the diagonal elements after obtaining Equation (12), we get the indefinite integral of Equation (12). Finally, the derivative formula for the part of Equation (6) containing W is obtained as follows
- (e)
- Update S:
In the same way as updating W, Equation (6) containing S is extracted and then is defined. The new objective function is finally obtained as follows:
Since the above objective function is a convex function, it can be solved by the Karush-Kuhn-Tucker (KKT) conditions with the Lagrange multiplier method [32]. The final optimal solution obtained as follows:
where is the Lagrange multiplier. The iterative update process of LRMFS is shown in Algorithm 1.
| Algorithm 1 Objective function optimization algorithm |
| Input: //The feature matrix of the m-th modality; |
| //The label corresponding to the m-th modality subjects; |
| K//The adaptive similarity neighbors; |
| //The group sparsity regularization parameter; |
| β//The regularization parameter for adaptive similarity learning. |
| Output: //The weight matrix of features. |
| Initialize S//Constructed by Equation (4); |
| While not converges Fix other variables Update U by Equation (7) with the constraint Then Fix other variables Compute SVD of Q Update V by Equation (10) Then Fix other variables Compute P Update E by Equation (11) Then Fix other variables Define D Calculated derivative Update W by Equation (13) Then Fix other variables KKT conditions Update S by Equation (15) End while |
3. Experiment and Analysis
We select MKSVM as the classifier for data classification [33]. MKSVM performs a linear fusion of kernel functions based on a support vector machine (SVM). It has excellent generalization ability and is particularly suitable for small-sample situations like medical data classification.
The ten-fold cross-validation [34], which allows us to fully use the experimental data, is adopted to evaluate the classification performance of each method. Accuracy (ACC), AUC, specificity (SPE), and sensitivity (SEN) are selected as evaluation metrics for classification performance [8]. ACC represents the proportion of correctly classified samples, AUC describes the size of the area under the curve, and SPE and SEN represent the accuracy of classifying negative and positive samples, respectively. It conducted experiments to investigate the impact of different parameters on its classification performance and identified the optimal parameters after determining the evaluation metrics.
3.1. Parameters Selection
There are a total of one parameter K for the number of neighbors, and two regularization parameters and β. Experimentally, the nearest neighbor number K is set to take the values of 1, 3, 5, 7, and 9. The two regularization parameters and β take the values of {0,5,10,15,20} and {0.1,5,20,60,100}, respectively [17]. We selected an appropriate value for K and obtained the results shown in Figure 2 by fixing the values of and β. Different colors are chosen for the bar chart to make the results more intuitive and beautiful. In further, all experiments are performed by a ten-fold cross-validation method.
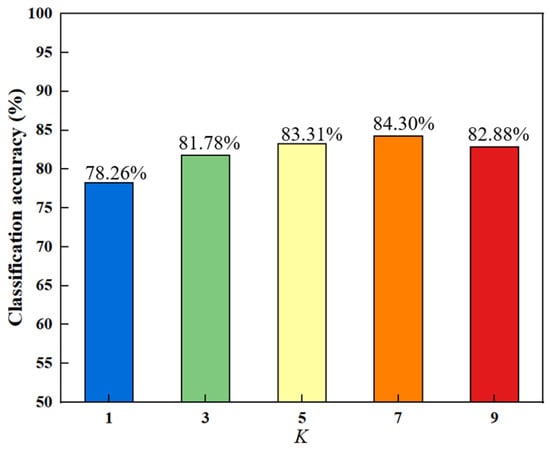
Figure 2.
Classification accuracy of different nearest neighbors.
In Figure 2, the trend of the bar chart indicates that the overall classification accuracy increases initially and then decreases with the increase of K. The best accuracy is obtained when K equals 7. The reason for this increasing and then decreasing trend may be that as the number of nearest neighbors increases, the local manifold structure of the data becomes clearer, which helps in selecting discriminative features and improving the accuracy. The manifold structure starts to become unstable after reaching the peak, leading to a decline in accuracy.
The value of K is fixed after determining the optimal number of nearest neighbors as 7. The optimal values of these regularization parameters can be searched by varying the values of the group sparsity regularization parameter and the adaptive similarity learning regularization parameter β. Finally, this regularization parameter combination can help the method get the best classification performance. Figure 3 shows the classification accuracy results for different regularization parameters. As well, we chose different colors in the figure to make the results more intuitive and beautiful.
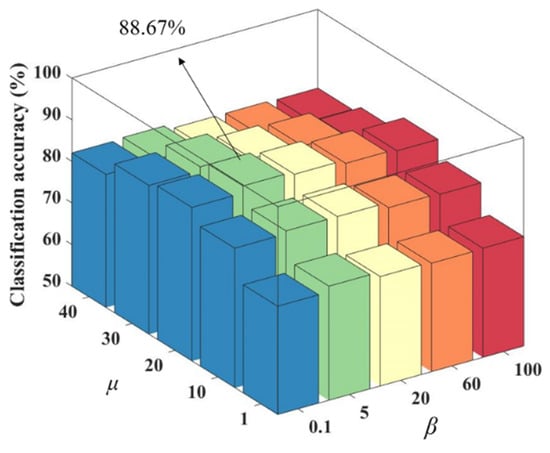
Figure 3.
Classification accuracy of different regularization parameter combinations.
As seen in Figure 3, among different regularization parameter combinations, has a greater impact on the classification accuracy compared to β. When is held constant, remains relatively stable. When β is held constant, shows a trend of increasing and then decreasing classification accuracy as its value increases. The reason for this trend may be that affects the sparsity of the matrix W, which determines the number of features. If is too small, some features may be ignored, while if it is too large, redundant features may be present, both of which can reduce the classification accuracy. The number of nearest neighbors K is set to 7, is set to 20 and β is set to 5.
3.2. Contrast Experiment
In the experiment, nine methods are selected for comparison to validate the effectiveness of the proposed framework. The baseline methods include MKSVM [33], MKSVM with Lasso feature selection performed independently on single modality (Lasso-MKSVM) [35], manifold regularized-based multimodal feature selection (M2TFS) [15], hypergraph-based multimodal feature selection (HMTFS) [16], ASMFS [17], self-expression topological manifolds-based multimodal feature selection (SETMFS) [18], multimodal classification framework based on ordinary features’ latent relation (OLR), unimodal fMRI and unimodal ASL. The first six methods and unimodal fMRI, along with the proposed framework, depend on SHMR-based brain functional networks to obtain hypergraph feature matrices. In contrast, OLR depends on a lower-order brain functional network constructed solely based on the Pearson correlation to obtain ordinary feature matrices. All the above-mentioned, including the proposed framework, are evaluated via ten-fold cross-validation. Furthermore, all methods exploit grid search to obtain the optimal classification performance results. Table 2 shows the specific classification performance, where the best classification results are highlighted in bold.
Table 2.
Classification performance of different methods.
The ACC, AUC, SPE, and SEN obtained by the proposed method are 88.67 ± 0.08%, 86.20 ± 0.16%, 93.50 ± 0.10%, and 86.00 ± 0.17%, respectively. It can be observed in Table 2 that HLR outperforms the other nine methods in all metrics except for SEN in the ESRDaMCI classification. The classification performance of unimodal fMRI and ASL is completely lower than that of multimodal classification methods when also using MKSVM. It proves that multimodal classification methods combined with different brain imaging modalities can reveal the functions and features of brain networks from different perspectives, and it also proves that joint fMRI and ASL can better improve classification performance. HMTFS demonstrates better classification performance compared to the first five methods, indicating that the hypergraph regularization term can discover high-order relations between features. ASMFS performs better than HMTFS, suggesting that dynamically capturing the intrinsic similarity shared by different modalities can select more informative features for classification. The classification accuracy of SETMFS reached 85.83 ± 0.10%, indicating that adopting a topology manifold to compute the similarity between data points within the feature matrix outperforms the traditional use of Euclidean distance as a similarity measure. This approach fully considers the topological relationships among data points from different modalities, which is conducive to improving classification performance.
Nonetheless, HLR outperformed SETMFS in terms of classification performance, suggesting that solely considering the topological relationships between different modalities is not as effective as mining the latent relation among feature matrices to select more useful feature information. The latent relation matrix, which replaces the original features, is not affected by outliers and noise, providing strong robustness. The constructed similarity matrix contains more manifold information compared to ASMFS and SETMFS. Moreover, HLR performs better classification than OLR. It indicates that the hypergraph features extracted on SHMR-based brain functional networks can enhance classification accuracy compared to ordinary features. The reason for the higher SEN values for OLR than HLR may be that OLR has a higher recognition rate for positive samples. In contrast, HLR has high-order information and is more sensitive to disease information, resulting in a slight decrease in the recognition rate of positive samples.
3.3. Discriminative Brain Regions
We conduct experiments to seek the most discriminative brain regions in ESRDaMCI classification after determining the optimal parameter combination through ten-fold cross-validation. The weight matrix W is analyzed and sorted, and the top fifteen brain regions with the highest weights are selected as the discriminative brain regions. The BrainNet Viewer toolbox is utilized to visually showcase these regions, and the results are shown in Figure 4. This visualization allows for a more straightforward presentation of the spatial locations and relations among the selected discriminative brain regions.
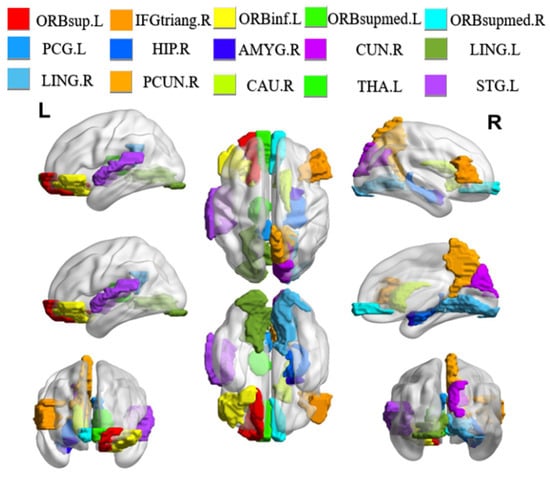
Figure 4.
Visualization of discriminative brain regions. L and R represent the left and right directions, respectively.
It is found that the selected discriminative brain regions are predominantly located in the frontal lobe through the analysis of the results. These regions include the left orbital part of the superior frontal gyrus (ORBsup.L), the right triangular part of the inferior frontal gyrus (IFGtriang.R), and the left orbital part of the inferior frontal gyrus (ORBinf.L), among others. The frontal lobe plays a significant role in brain memory, judgment, and abstract thinking [36]. As a result, these selected brain regions indicate that individuals with ESRDaMCI have experienced changes in functions such as memory and judgment compared to healthy individuals. In addition, the chosen discriminative brain regions include the right hippocampus (HIP.R), right caudate nucleus (CAU.R), left lingual gyrus (LING.L), and right lingual gyrus (LING.R), which play essential roles in human memory and spatial localization abilities [37]. The left thalamus (THA.L) plays a crucial role in sensory reception functions [38], while the right precuneus (PCUN.R) and right cuneus (CUN.R) are associated with various high-order cognitive functions [39]. These findings are consistent with previous pathological studies and reports on neuroimaging biomarkers of ESRDaMCI [40,41]. They validate our results from the perspective of overall brain function, revealing the discriminative brain regions underlying ESRDaMCI and providing clinical significance for diagnostic purposes.
3.4. Data Visualization and Analysis
This section visualizes the ASL and fMRI data images, as shown in Figure 5.
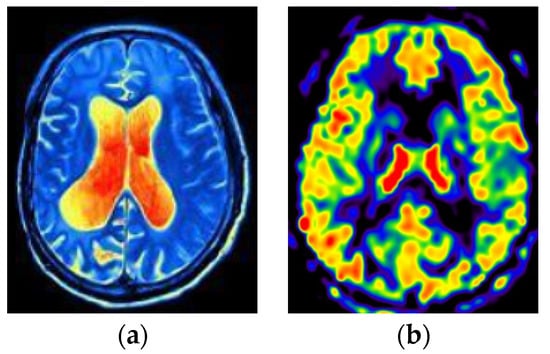
Figure 5.
Visualization of fMRI and ASL data. (a) fMRI (b) ASL.
In this study, fMRI is processed as the first modal data and ASL as the second modal data. The combination of these two modal data can better collect feature information inspired by [8,9]. First, different modes provide different types of information. fMRI shows the temporal and spatial distribution of brain activity, ASL provides information on blood flow in brain regions, and both modes provide more comprehensive information. Next, fMRI can be affected by noise, while ASL provides blood flow information that reduces potential errors. Finally, the combination of fMRI and ASL can better observe the changes in brain regions, which is convenient for finding the discernible brain regions of ESRDaMCI.
4. Discussion
In recent years, there has been increasing attention from researchers on MCI-related diseases [42,43,44,45], including ESRDaMCI, which has gained significant importance. However, the underlying pathological mechanisms of the disease remain unclear, making the classification and identification of related diseases a challenge. Multimodal learning has been introduced in the field of medical imaging, allowing researchers to gain a more comprehensive understanding of complementary information from different modalities, thereby aiding in the diagnosis and identification of ESRDaMCI. High-dimensional features have a significant impact on the final performance of the models in multimodal classification. Existing multimodal disease classification methods mostly focus on improving feature selection algorithms, but these methods have varying degrees of limitations and issues. HMTFS proposed by Shao et al. [16] considers the high-order relations between different modalities and gets good classification performance. It neglects whether the feature matrix accurately reflects the high-order relations between brain regions, thereby limiting its ability to discover discriminative brain regions for imaging diseases. M2TFS, proposed by Jie et al. [15], constructs a fixed similarity matrix, failing to reveal the underlying data structure. ASMFS, proposed by Shi et al. [17], updates the similarity matrix in real-time, but it does not consider outliers and noise in the features. SETMFS proposed by Song et al. [18] only focuses on the topological relationships between different modalities without considering the latent relation among features within each modality and the handling of noise. They also neglect the quantity and quality of useful information contained in the original feature matrix.
These methods fail to gather more high-order prior information on brain regions and exploit the latent relation between feature matrices. To address these issues, HLR constructs SHMR-based brain functional networks with hypergraph structure information and obtains the hypergraph feature matrix with GT when constructing the modality feature matrix. This ensures that the high-order information between brain regions is not overlooked and allows for better capturing of important features in the data [46]. Furthermore, the LRMFS is obtained using LRAS on the basis of multi-task feature selection. This method generates more accurate similarity matrices, ensuring clear features while removing noise from the feature matrix. In particular, previous similarity matrices are constructed from the original feature matrix, ignoring the latent feature relation and noise. Whereas in the real world, the noise, outliers, and special values contained in the data affect the quality of the similarity matrix. If the original feature matrix is robustly decomposed, it constructs a similarity matrix unaffected by noise and has high information content. The feature matrix in the HLR is robustly structured to mine the feature information between the features, control the noise effects and improve the classification performance.
It is worth noting that this study involves the same original dataset as Song et al., yet the classification performance of HLR surpasses that of SETMFS. It indicates that merely changing the method of computing similarity to capture the topological relationship between feature matrices does not suffice for better extracting latent relation between them. HLR uses latent relation matrices instead of feature matrices to construct the similarity matrix, thereby reducing the impact of noise and outliers on classification performance. Then the feature matrix of SETMFS focuses only on the relational information of pairs of brain regions, and HLR retains the high-order relational information of multiple brain regions, identifying more accurate discriminative brain regions. Overall, HLR changes the feature matrix attributes so that the feature matrix has high-order information. It also proposes a new LRMFS method that changes the construction of the similarity matrix to mine the potential relationships between the data and improve the robustness of the model.
In addition, HLR is a multimodal classification framework based on the combination of ASL and fMRI. Studies have shown that these two modalities provide a more comprehensive understanding of brain information [8,9]. On the one hand, ASL measures CBF to reflect brain metabolism, while fMRI detects changes in blood oxygen levels to reflect functional brain activity. Combining them allows for a more comprehensive representation of neural activity. Additionally, ASL provides temporal data of neural activity through CBF values, while fMRI provides high spatial resolution brain activity images, enabling the correspondence between time and space. On the other hand, the blood flow data in ASL are closely related to brain metabolism and neural activity, while the blood oxygen level changes in fMRI reflect the demand for neural activity. Therefore, combining these two modalities can provide more accurate and comprehensive physiological interpretability.
The experimental results demonstrate that HLR outperforms the comparison methods regarding classification performance and obtains significant results in identifying subtle changes in ESRDaMCI brain regions. It has some significance for the clinical diagnosis of ESRDaMCI. Nevertheless, HLR still has certain limitations and requires further improvement. Traditional Euclidean distance calculation in constructing the similarity matrix may not be suitable for capturing complex network topology structures [47]. In the upcoming work, we will integrate topological manifold terms [18] to compute the topological relationship matrix between features, thereby obtaining a more accurate similarity matrix. HLR involves many parameters and requires multiple parameters tuning to get the optimal model, and the process is complex, requiring further model refinement. Moreover, deep learning is also developing rapidly in the medical field [48,49,50,51], and HLR can adopt graph convolutional networks to construct more appropriate dynamic hypergraphs that retain more a priori information about the brain. Finally, HLR shows good performance on the binary classification problem of ESRDaMCI, but it can be further extended to the multiclassification problem, which is able to recognize and classify ESRDaMCI with different degrees of refinement.
In summary, the HLR-based multimodal classification framework has the following advantages and contributions. (a) The feature matric retains the priori information between multiple brain regions rather than between pairs of brain regions. It better reflects the changes in ESRDaMCI brain regions and contributes to obtaining more accurate discriminative brain regions. (b) A new feature selection method of LRMFS is proposed, which utilizes the original features to construct coefficient matrices with good noise immunity. It adapts adaptive learning and latent relation learning to combine in a multi-task feature selection model to explore the latent relation between features and improve the robustness of the model. (c) The current status of the development of two types of medical images, ASL and fMRI, is examined, and the advantages of combining the two modalities, ASL and fMRI, are explored. (d) The discriminative brain regions of ESRDaMCI are identified by the selected features. It can provide a research basis for the prevention and treatment of ESRDaMCI by determining the subtle changes in these brain regions in medical clinical diagnosis.
5. Conclusions
We propose a HLR-based multimodal classification framework and apply it to the identification of ESRDaMCI disease. The HLR, unlike previous studies, achieves joint learning of high-order information in hypergraphs and latent relation feature selection. This framework constructs a hypergraph feature matrix by the SHMR-based brain functional network, providing more high-order prior information about brain regions and identifying discriminative brain regions for ESRDaMCI. It better reflects the pathogenesis of ESRDaMCI through these discriminative brain regions. Moreover, HLR adopts the latent relation in the feature matrix to construct a new feature coefficient matrix, which reduces the impact of noise and enhances robustness. Subsequently, it constructs a similarity matrix that yields greater information and more discriminative features through adaptive learning, thereby improving the classification performance for ESRDaMCI. In clinical diagnosis, it can assist patients in receiving timely treatment, reduce the likelihood of MCI converting to AD, and provide important imaging markers for ESRDaMCI. Nevertheless, our study has many limitations. For example, we construct the similarity matrix according to traditional Euclidean. It tends to neglect the topological relationship between the feature matrices of different modalities. In fact, the framework involves many parameters, and the model optimization process is complicated. Deep learning, especially deep neural networks, will also be applied in recognizing ESRDaMCI to further improve classification performance.
Author Contributions
Conceptualization, H.S.; methodology, X.F., H.S. and Z.J.; software, C.S.; validation, H.S., Z.J. and X.F.; formal analysis, R.Z.; investigation, X.F. and C.S.; data curation, H.S.; writing—original draft preparation, X.F.; writing—review and editing, Z.J.; visualization, X.F.; project administration, Z.J.; funding acquisition, Z.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (grant No. 51877013) and the Jiangsu Provincial Key Research and Development Program (grant No. BE2021636). This work was also sponsored by the Qing Lan Project of Jiangsu Province.
Institutional Review Board Statement
Informed consent was obtained from all subjects involved in the study.
Informed Consent Statement
All participants had given written informed consent prior to being included in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy and ethical.
Acknowledgments
Data used in preparation of this article were obtained from the Affiliated Changzhou No. 2 People’s Hospital of Nanjing Medical University. This work was conducted with the approval and supervision of the Ethics Committee of the Affiliated Changzhou No. 2 People’s Hospital of Nanjing Medical University (approval number KY039-01).
Conflicts of Interest
The authors declare there is no conflict of interest.
References
- De Deyn, P.P.; Saxena, V.K.; Abts, H.; Borggreve, F.; D’Hooge, R.; Marescau, B.; Crols, R. Clinical and pathophysiological aspects of neurological complications in renal failure. Acta Neurol. Belg. 1992, 92, 191–206. [Google Scholar]
- Saji, N.; Sato, T.; Sakuta, K.; Aoki, J.; Kobayashi, K.; Matsumoto, N.; Uemura, J.; Shibazaki, K.; Kimura, K. Chronic Kidney Disease Is an Independent Predictor of Adverse Clinical Outcomes in Patients with Recent Small Subcortical Infarcts. Cerebrovasc. Dis. Extra 2014, 4, 174–181. [Google Scholar] [CrossRef]
- Karunaratne, K.; Taube, D.; Khalil, N.; Perry, R.; A Malhotra, P. Neurological complications of renal dialysis and transplantation. Pract. Neurol. 2018, 18, 115–125. [Google Scholar] [CrossRef]
- Raphael, K.L.; Wei, G.; Greene, T.; Baird, B.C.; Beddhu, S. Cognitive Function and the Risk of Death in Chronic Kidney Disease. Am. J. Nephrol. 2012, 35, 49–57. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, L.; Huang, J.; Han, L.; Zhang, D. Dual Attention Multi-Instance Deep Learning for Alzheimer’s Disease Diagnosis with Structural MRI. IEEE Trans. Med. Imaging 2021, 40, 2354–2366. [Google Scholar] [CrossRef]
- Xi, Z.; Liu, T.; Shi, H.; Jiao, Z. Hypergraph representation of multimodal brain networks for patients with end-stage renal disease associated with mild cognitive impairment. Math. Biosci. Eng. 2023, 20, 1882–1902. [Google Scholar] [CrossRef]
- Jiao, Z.; Chen, S.; Shi, H.; Xu, J. Multi-Modal Feature Selection with Feature Correlation and Feature Structure Fusion for MCI and AD Classification. Brain Sci. 2022, 12, 80. [Google Scholar] [CrossRef]
- Li, Y.; Liu, J.; Gao, X.; Jie, B.; Kim, M.; Yap, P.-T.; Wee, C.-Y.; Shen, D. Multimodal hyper-connectivity of functional networks using functionally-weighted LASSO for MCI classification. Med. Image Anal. 2019, 52, 80–96. [Google Scholar] [CrossRef]
- Jann, K.; Gee, D.G.; Kilroy, E.; Schwab, S.; Smith, R.X.; Cannon, T.D.; Wang, D.J. Functional connectivity in BOLD and CBF data: Similarity and reliability of resting brain networks. Neuroimage 2015, 106, 111–122. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef]
- Rehman, M.U.; Akhtar, S.; Zakwan, M.; Mahmood, M.H. Novel architecture with selected feature vector for effective classification of mitotic and non-mitotic cells in breast cancer histology images. Biomed. Signal Process. Control 2022, 71, 103212. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Lei, B.Y.; Cheng, N.N.; Alejandro, F.F.; Tan, E.L.; Cao, J.W.; Yang, P.; Ahmed, E.; Du, J.; Xu, Y.W.; Wang, T.F. Self-calibrated brain network estimation and joint non-convex multi-task learning for identification of early Alzheimer’s disease. Med. Image Anal. 2020, 61, 101652. [Google Scholar] [CrossRef]
- Hao, X.; Bao, Y.; Guo, Y.; Yu, M.; Zhang, D.; Risacher, S.L.; Saykin, A.J.; Yao, X.; Shen, L. Multimodal neuroimaging feature selection with consistent metric constraint for diagnosis of Alzheimer’s disease. Med. Image Anal. 2020, 60, 101625. [Google Scholar] [CrossRef]
- Jie, B.; Zhang, D.Q.; Cheng, B.; Shen, D.G. Manifold regularized multi-task feature selection for multimodal classification in Alzheimer’s disease. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Nagoya, Japan, 22–26 September 2013; pp. 275–283. [Google Scholar]
- Shao, W.; Peng, Y.; Zu, C.; Wang, M.; Zhang, D. Hypergraph based multi-task feature selection for multimodal classification of Alzheimer’s disease. Comput. Med. Imaging Graph. 2020, 80, 101663. [Google Scholar] [CrossRef]
- Shi, Y.; Zu, C.; Hong, M.; Zhou, L.; Wang, L.; Wu, X.; Wang, Y. ASMFS: Adaptive-similarity-based multimodal feature selection for classification of Alzheimer’s disease. Pattern Recognit. 2022, 126, 108566. [Google Scholar] [CrossRef]
- Song, C.; Liu, T.; Wang, H.; Shi, H.; Jiao, Z. Multi-modal feature selection with self-expression topological manifold for end-stage renal disease associated with mild cognitive impairment. Math. Biosci. Eng. 2023, 20, 14827–14845. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, Q.; Fu, X.; Shi, H.; Jiao, Z. Integrated Prediction Framework for Clinical Scores of Cognitive Functions in ESRD Patients. Comput. Intell. Neurosci. 2022, 2022, 8124053. [Google Scholar] [CrossRef]
- Xu, C.Y.; Chen, C.C.; Guo, Q.W.; Lin, Y.W.; Meng, X.Y. Comparison of moCA-B and MES scales for the recognition of amnestic mild cognitive impairment. J. Alzheimer’s Dis. Relat. Disord. 2021, 4, 33–36. [Google Scholar] [CrossRef]
- Rubinov, M.; Sporns, O. Complex network measures of brain connectivity: Uses and interpretations. Neuroimage 2010, 52, 1059–1069. [Google Scholar] [CrossRef]
- Nathalie, T.M.; Brigitte, L.; Dimitri, P.; Fabrice, C.; Olivier, E.; Nicolas, D.; Bernard, M.; Marc, J. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 2002, 15, 273–289. [Google Scholar] [CrossRef]
- Wang, Z.; Aguirre, G.K.; Rao, H.; Wang, J.; Fernández-Seara, M.A.; Childress, A.R.; Detre, J.A. Empirical optimization of ASL data analysis using an ASL data processing toolbox: ASLtbx. Magn. Reson. Imaging 2008, 26, 261–269. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, Y.; Shi, H.; Jiao, Z.; Wang, S.-H.; Wang, C. Constructing Dynamic Brain Functional Networks via Hyper-Graph Manifold Regularization for Mild Cognitive Impairment Classification. Front. Neurosci. 2021, 15, 669345. [Google Scholar] [CrossRef]
- Sheng, Q.; Zhang, Y.; Shi, H.; Jiao, Z. Global iterative optimization framework for predicting cognitive function statuses of patients with end-stage renal disease. Int. J. Imaging Syst. Technol. 2023, 33, 837–852. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J.; Wu, Q.; Kuang, W.; Huang, X.; He, Y.; Gong, Q. Disrupted Brain Connectivity Networks in Drug-Naive, First-Episode Major Depressive Disorder. Biol. Psychiatry 2011, 70, 334–342. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Tsang, I.W.; Xu, Z.; Lv, J. Latent Representation Guided Multi-view Clustering. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Ding, C.; Li, T.; Peng, W.; Park, H. Orthogonal nonnegative matrix t-factorizations for clustering. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 126–135. [Google Scholar] [CrossRef]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming: Theory and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Wall, M.E.; Rechtsteiner, A.; Rocha, L.M. Singular Value Decomposition and Principal Component Analysis. In A Practical Approach to Microarray Data Analysis; Springer: Boston, MA, USA, 2003; pp. 91–109. [Google Scholar] [CrossRef]
- Nie, F.; Huang, H.; Cai, X.; Ding, C. Efficient and robust feature selection via joint -norms minimization. Adv. Neural Inf. Process. Syst. 2021, 2, 1813–1821. [Google Scholar]
- Kabgani, A.; Soleimani-Damaneh, M.; Zamani, M. Optimality conditions in optimization problems with convex feasible set using convexificators. Math. Methods Oper. Res. 2017, 86, 103–121. [Google Scholar] [CrossRef]
- Bach, F.R.; Lanckriet, G.R.; Jordan, M.I. Multiple kernel learning, conic duality, and the SMO algorithm. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Mei, J.; Tao, M.; Wang, X.; Zhao, Q.; Liang, X.; Wu, W.; Ding, D.; Wang, P. Feature Selection and Combination of Information in the Functional Brain Connectome for Discrimination of Mild Cognitive Impairment and Analyses of Altered Brain Patterns. Front. Aging Neurosci. 2020, 12, 28. [Google Scholar] [CrossRef]
- Huang, S.; Li, J.; Ye, J.; Wu, T.; Chen, K. Fleisher and E. Reiman. Identifying Alzheimer’s disease-related brain regions from multimodal neuroimaging data using sparse composite linear discrimination analysis. Adv. Neural Inf. Process. Syst. 2011, 24, 1431–1439. [Google Scholar]
- Zhang, Y.; Wang, S.; Sui, Y.; Yang, M.; Liu, B.; Cheng, H.; Sun, J.; Jia, W.; Phillips, P.; Gorriz, J.M. Multivariate Approach for Alzheimer’s Disease Detection Using Stationary Wavelet Entropy and Predator-Prey Particle Swarm Optimization. J. Alzheimer’s Dis. 2018, 65, 855–869. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Dong, Z. Classification of alzheimer disease based on structural magnetic resonance imaging by kernel support vector machine decision tree. Prog. Electromagn. Res. 2014, 144, 171–184. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S. Detection of Alzheimer’s disease by displacement field and machine learning. PeerJ 2015, 3, e1251. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Liu, G.; Phillips, P.; Yuan, T.-F. Detection of Alzheimer’s Disease by Three-Dimensional Displacement Field Estimation in Structural Magnetic Resonance Imaging. J. Alzheimer’s Dis. 2016, 50, 233–248. [Google Scholar] [CrossRef]
- Wu, B.L.; Yue, Z.; Li, X.K.; Li, L.; Zhang, M.; Ren, J.P.; Liu, W.L.; Han, D.M. Brain functional network changes in patients with end-stage renal disease and its correlation with cognitive function. Chin. J. Neuromedicine 2020, 19, 181–187. [Google Scholar] [CrossRef]
- McKhann, G.M.; Knopman, D.S.; Chertkow, H.; Hyman, B.T.; Jack, C.R., Jr.; Kawas, C.H.; Klunk, W.E.; Koroshetz, W.J.; Manly, J.J.; Mayeux, R.; et al. The diagnosis of dementia due to Alzheimer’s disease: Recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimer’s Dement. 2011, 7, 263–269. [Google Scholar] [CrossRef]
- Wang, S.-H.; Zhang, Y.; Li, Y.-J.; Jia, W.-J.; Liu, F.-Y.; Yang, M.-M.; Zhang, Y.-D. Single slice based detection for Alzheimer’s disease via wavelet entropy and multilayer perceptron trained by biogeography-based optimization. Multimedia Tools Appl. 2018, 77, 10393–10417. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Phillips, P.; Dong, Z.; Ji, G.; Yang, J. Detection of Alzheimer’s disease and mild cognitive impairment based on structural volumetric MR images using 3D-DWT and WTA-KSVM trained by PSOTVAC. Biomed. Signal Process. Control 2015, 21, 58–73. [Google Scholar] [CrossRef]
- Jiao, Z.; Ji, Y.; Gao, P.; Wang, S.-H. Extraction and analysis of brain functional statuses for early mild cognitive impairment using variational auto-encoder. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 5439–5450. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, L.; Wang, L.; Zhang, D. Attention-Diffusion-Bilinear Neural Network for Brain Network Analysis. IEEE Trans. Med. Imaging 2020, 39, 2541–2552. [Google Scholar] [CrossRef]
- Xi, Z.; Song, C.; Zheng, J.; Shi, H.; Jiao, Z. Brain Functional Networks with Dynamic Hypergraph Manifold Regularization for Classification of End-Stage Renal Disease Associated with Mild Cognitive Impairment. Comput. Model. Eng. Sci. 2023, 135, 2243–2266. [Google Scholar] [CrossRef]
- Zhao, P.; Wu, H.; Huang, S. Multi-View Graph Clustering by Adaptive Manifold Learning. Mathematics 2022, 10, 1821. [Google Scholar] [CrossRef]
- Ryu, J.; Rehman, M.U.; Nizami, I.F.; Chong, K.T. SegR-Net: A deep learning framework with multi-scale feature fusion for robust retinal vessel segmentation. Comput. Biol. Med. 2023, 163, 107132. [Google Scholar] [CrossRef]
- Mangj, S.M.; Hussan, P.H.; Shakir, W.M.R. Efficient Deep Learning Approach for Detection of Brain Tumor Disease. Int. J. Online Biomed. Eng. 2023, 19, 66–80. [Google Scholar] [CrossRef]
- Rehman, M.U.; Ryu, J.; Nizami, I.F.; Chong, K.T. RAAGR2-Net: A brain tumor segmentation network using parallel processing of multiple spatial frames. Comput. Biol. Med. 2023, 152, 106426. [Google Scholar] [CrossRef]
- Attallah, O.; Zaghlool, S. AI-Based Pipeline for Classifying Pediatric Medulloblastoma Using Histopathological and Textural Images. Life 2022, 12, 232. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).