
A Comparative Analysis of U-Net and Vision Transformer Architectures in Semi-Supervised Prostate Zonal Segmentation


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
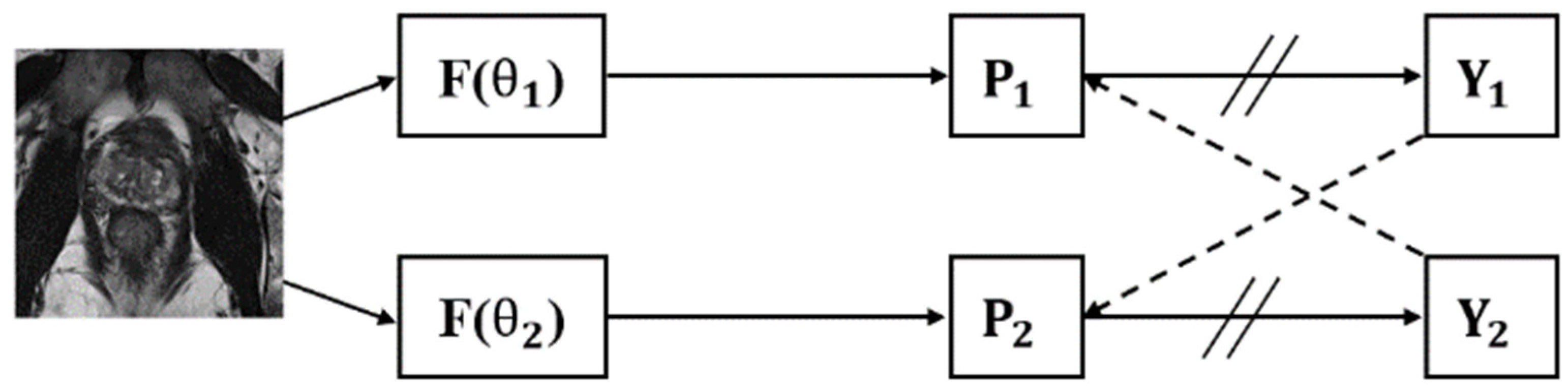
2.1. Dataset and Pre-Processing
2.2. Supervised Learning Methods
2.2.1. U-Net
2.2.2. Vision Transformer
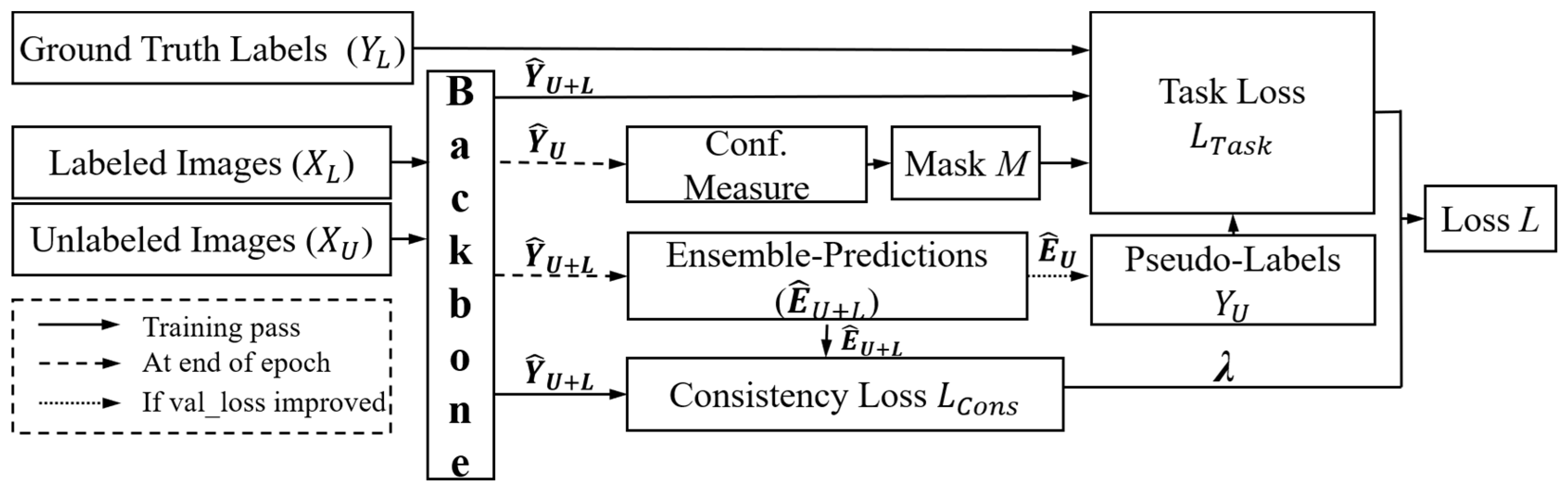
2.3. Semi-Supervised Learning Methods
2.3.1. Entropy Minimization
2.3.2. Cross Pseudo-Supervision
2.3.3. Mean Teacher
2.3.4. Uncertainty-Aware Mean Teacher
2.3.5. Interpolation Consistency Training
2.3.6. Uncertainty-Aware Temporal Self-Learning
2.4. Training Settings
3. Results
3.1. Semi-Supervised Learning Methods
3.2. Classical Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fasihi, M.S.; Mikhael, W.B. Overview of Current Biomedical Image Segmentation Methods. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 803–808. [Google Scholar]
- Scheenen, T.W.; Rosenkrantz, A.B.; Haider, M.A.; Fütterer, J.J. Multiparametric Magnetic Resonance Imaging in Prostate Cancer Management: Current Status and Future Perspectives. Investig. Radiol. 2015, 50, 594–600. [Google Scholar] [CrossRef]
- Weinreb, J.C.; Barentsz, J.O.; Choyke, P.L.; Cornud, F.; Haider, M.A.; Macura, K.J.; Margolis, D.; Schnall, M.D.; Shtern, F.; Tempany, C.M.; et al. PI-RADS Prostate Imaging-Reporting and Data System: 2015, Version 2. Eur. Urol. 2016, 69, 16–40. [Google Scholar] [CrossRef] [PubMed]
- McNeal, J.E. The zonal anatomy of the prostate. Prostate 1981, 2, 35–49. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.D.; Yan, S.S.; Liu, R.J.; Zhang, Y.S. Apparent differences in prostate zones: Susceptibility to prostate cancer, benign prostatic hyperplasia and prostatitis. Int. Urol. Nephrol. 2024, 56, 2451–2458. [Google Scholar] [CrossRef] [PubMed]
- Hoeh, B.; Wenzel, M.; Hohenhorst, L.; Köllermann, J.; Graefen, M.; Haese, A.; Tilki, D.; Walz, J.; Kosiba, M.; Becker, A.; et al. Anatomical Fundamentals and Current Surgical Knowledge of Prostate Anatomy Related to Functional and Oncological Outcomes for Robotic-Assisted Radical Prostatectomy. Front. Surg. 2022, 8, 825183. [Google Scholar] [CrossRef] [PubMed]
- Klein, S.; van der Heide, U.A.; Lips, I.M.; van Vulpen, M.; Staring, M.; Pluim, J.P. Automatic segmentation of the prostate in 3D MR images by atlas matching using localized mutual information. Med. Phys. 2008, 35, 1407–1417. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Debats, O.; van de Ven, W.; Karssemeijer, N.; Huisman, H. A pattern recognition approach to zonal segmentation of the prostate on MRI. In Medical Image Computing and Computer-Assisted Intervention: MICCAI, Proceedings of the 15th International Conference on Medical Image Computing and Computer-Assisted Intervention, Nice, France, 1–5 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7511, pp. 413–420. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Cham, Switzerland, 18 November 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Yan, C.; Liu, F.; Peng, Y.; Zhao, Y.; He, J.; Wang, R. 3D convolutional network with edge detection for prostate gland and tumor segmentation on T2WI and ADC. Biomed. Signal Process. Control 2024, 90, 105883. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, R.; Chen, H.; Zhang, L.; Zhang, Q. CCT-Unet: A U-Shaped Network Based on Convolution Coupled Transformer for Segmentation of Peripheral and Transition Zones in Prostate MRI. IEEE J. Biomed. Health Inform. 2023, 27, 4341–4351. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7242–7252. [Google Scholar]
- Hung, A.L.Y.; Zheng, H.; Miao, Q.; Raman, S.S.; Terzopoulos, D.; Sung, K. CAT-Net: A Cross-Slice Attention Transformer Model for Prostate Zonal Segmentation in MRI. IEEE Trans. Med. Imaging 2023, 42, 291–303. [Google Scholar] [CrossRef]
- Karimi, D.; Samei, G.; Kesch, C.; Nir, G.; Salcudean, S.E. Prostate segmentation in MRI using a convolutional neural network architecture and training strategy based on statistical shape models. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1211–1219. [Google Scholar] [CrossRef]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2512–2521. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.-W.; Heng, P.-A. Uncertainty-Aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI, Proceedings of the 22nd International Conference, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 605–613. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Verma, V.; Kawaguchi, K.; Lamb, A.; Kannala, J.; Solin, A.; Bengio, Y.; Lopez-Paz, D. Interpolation consistency training for semi-supervised learning. Neural Netw. 2022, 145, 90–106. [Google Scholar] [CrossRef] [PubMed]
- Zou, K.H.; Warfield, S.K.; Bharatha, A.; Tempany, C.M.; Kaus, M.R.; Haker, S.J.; Wells, W.M., 3rd; Jolesz, F.A.; Kikinis, R. Statistical validation of image segmentation quality based on a spatial overlap index. Acad. Radiol. 2004, 11, 178–189. [Google Scholar] [CrossRef]
- Parikh, R.; Mathai, A.; Parikh, S.; Chandra Sekhar, G.; Thomas, R. Understanding and using sensitivity, specificity and predictive values. Indian J. Ophthalmol. 2008, 56, 45–50. [Google Scholar] [CrossRef]
- Meyer, A.; Ghosh, S.; Schindele, D.; Schostak, M.; Stober, S.; Hansen, C.; Rak, M. Uncertainty-aware temporal self-learning (UATS): Semi-supervised learning for segmentation of prostate zones and beyond. Artif. Intell. Med. 2021, 116, 102073. [Google Scholar] [CrossRef]
- Han, K.; Sheng, V.S.; Song, Y.; Liu, Y.; Qiu, C.; Ma, S.; Liu, Z. Deep semi-supervised learning for medical image segmentation: A review. Expert Syst. Appl. 2024, 245, 123052. [Google Scholar] [CrossRef]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. In Proceedings of the 17th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 1 December 2004; pp. 529–536. [Google Scholar]
- Ibrahim, S.; Nguyen, T.; Fu, X. Deep learning from crowdsourced labels: Coupled cross-entropy minimization, identifiability, and regularization. arXiv 2023, arXiv:2306.03288. [Google Scholar]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the ICML 2013 Workshop: Challenges in Representation Learning (WREPL), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Xiang, C.; Gan, V.J.L.; Guo, J.; Deng, L. Semi-supervised learning framework for crack segmentation based on contrastive learning and cross pseudo supervision. Measurement 2023, 217, 113091. [Google Scholar] [CrossRef]
- Xiang, R.; Yin, S. Semi-supervised Text Classification with Temporal Ensembling. In Proceedings of the 2021 International Conference on Computer Communication and Artificial Intelligence (CCAI), Guangzhou, China, 7–9 May 2021; pp. 204–208. [Google Scholar]
- Xu, Z.; Wang, Y.; Lu, D.; Luo, X.; Yan, J.; Zheng, Y.; Tong, R.K.-Y. Ambiguity-selective consistency regularization for mean-teacher semi-supervised medical image segmentation. Med. Image Anal. 2023, 88, 102880. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.O.D.; Barentsz, J.; Karssemeijer, N.; Huisman, H. ProstateX Challenge Data; The Cancer Imaging Archive: New York, NY, USA, 2017. [Google Scholar]
- Meyer, A.; Rakr, M.; Schindele, D.; Blaschke, S.; Schostak, M.; Fedorov, A.; Hansen, C. Towards Patient-Individual PI-Rads v2 Sector Map: Cnn for Automatic Segmentation of Prostatic Zones From T2-Weighted MRI. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 696–700. [Google Scholar]
- Zoltan, K. Markov Random Fields in Image Segmentation. Found. Trends Signal Process. 2012, 5, 1–155. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Liu, D.; Yu, J. Otsu Method and K-means. In Proceedings of the 2009 Ninth International Conference on Hybrid Intelligent Systems, Shenyang, China, 12–14 August 2009; pp. 344–349. [Google Scholar]
- Hoang, N.-D.; Nguyen, L. Metaheuristic Optimized Edge Detection for Recognition of Concrete Wall Cracks: A Comparative Study on the Performances of Roberts, Prewitt, Canny, and Sobel Algorithms. Adv. Civ. Eng. 2018, 2018, 7163580. [Google Scholar] [CrossRef]
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical Image Segmentation Review: The success of U-Net. arXiv 2022, arXiv:2211.14830. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | PZ | TZ | DPU | AFS | Mean | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice | TPR | Dice | TPR | Dice | TPR | Dice | TPR | Dice | TPR | ||
| U-Net | Supervised | 76.59 | 73.65 | 85.99 | 85.01 | 72.22 | 70.43 | 42.61 | 49.05 | 69.35 | 69.54 |
| EM | 78.09 | 74.66 | 87.75 | 86.40 | 74.07 | 73.57 | 45.33 | 48.69 | 71.31 | 70.83 | |
| CPS | 79.68 | 81.77 | 87.74 | 86.04 | 72.64 | 70.12 | 46.42 | 52.94 | 71.62 | 72.72 | |
| MT | 77.96 | 75.39 | 86.89 | 84.92 | 74.35 | 74.71 | 43.78 | 50.73 | 70.75 | 71.44 | |
| UAMT | 77.71 | 74.84 | 86.02 | 88.40 | 73.13 | 77.33 | 44.09 | 50.40 | 70.24 | 72.74 | |
| ICT | 78.87 | 78.08 | 87.75 | 86.37 | 72.77 | 71.35 | 47.88 | 55.17 | 71.82 | 72.74 | |
| UATS | 78.90 | 76.73 | 87.56 | 89.61 | 73.09 | 73.56 | 43.60 | 51.52 | 70.79 | 72.86 | |
| ViT | Supervised | 69.49 | 70.35 | 82.68 | 80.06 | 61.86 | 56.75 | 37.79 | 38.36 | 62.96 | 61.38 |
| EM | 67.61 | 68.91 | 81.46 | 79.89 | 57.75 | 49.95 | 35.88 | 39.20 | 60.68 | 59.49 | |
| CPS | 69.34 | 72.98 | 82.31 | 79.30 | 61.99 | 60.19 | 38.30 | 41.96 | 62.99 | 63.61 | |
| MT | 69.95 | 72.91 | 83.18 | 79.65 | 61.97 | 57.42 | 33.64 | 30.99 | 62.19 | 60.24 | |
| UAMT | 70.54 | 72.25 | 82.95 | 82.16 | 61.42 | 55.93 | 38.39 | 46.30 | 63.33 | 64.16 | |
| ICT | 69.59 | 73.49 | 82.72 | 80.89 | 62.34 | 58.38 | 37.28 | 38.36 | 62.98 | 62.78 | |
| UATS | 70.43 | 70.11 | 83.92 | 83.21 | 61.33 | 58.10 | 35.88 | 33.29 | 62.89 | 61.18 | |
| Backbone | PZ | TZ | DPU | AFS | Mean | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice (%) | TPR (%) | Dice (%) | TPR (%) | Dice (%) | TPR (%) | Dice (%) | TPR (%) | Dice (%) | TPR (%) | ||
| EM | 1.96 | 1.37 | 2.05 | 1.64 | 2.56 | 4.46 | 6.38 | −0.73 | 2.82 | 1.86 | |
| CPS | 4.03 | 11.03 | 2.04 | 1.21 | 0.58 | −0.44 | 8.94 | 7.93 | 3.27 | 4.58 | |
| U-Net | MT | 1.79 | 2.36 | 1.05 | −0.11 | 2.95 | 6.08 | 2.75 | 3.43 | 2.01 | 2.74 |
| UAMT | 1.46 | 1.62 | 0.03 | 3.99 | 1.26 | 9.80 | 3.47 | 2.75 | 1.28 | 4.61 | |
| ICT | 2.98 | 6.01 | 2.05 | 1.60 | 0.76 | 1.31 | 12.37 | 12.48 | 3.55 | 4.61 | |
| UATS | 3.02 | 4.18 | 1.83 | 5.41 | 1.2 | 4.44 | 2.32 | 5.04 | 2.08 | 4.77 | |
| EM | −2.05 | −2.05 | −1.48 | −0.21 | −6.64 | −11.98 | −5.05 | 2.19 | −3.62 | −3.08 | |
| CPS | −0.22 | 3.74 | −0.45 | −0.95 | 0.21 | 6.06 | 1.35 | 9.38 | 0.05 | 3.63 | |
| ViT | MT | 0.66 | 3.64 | 0.60 | −0.51 | 0.18 | 1.18 | −10.98 | −19.21 | −1.22 | −1.85 |
| UAMT | 1.51 | 2.70 | 0.33 | 2.62 | −0.89 | −1.44 | 1.59 | 20.70 | 0.59 | 4.53 | |
| ICT | 0.14 | 4.46 | 0.05 | 1.04 | 0.78 | 2.87 | 1.35 | 0.00 | 0.04 | 2.28 | |
| UATS | 1.35 | −0.34 | 1.50 | 3.93 | −0.86 | 2.38 | −5.05 | −13.21 | −0.11 | −0.33 | |
| Backbone | PZ | TZ | DPU | AFS | Mean | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice | TPR | Dice | TPR | Dice | TPR | Dice | TPR | Dice | TPR | ||
| U-Net | Supervised | 78.94 | 80.23 | 88.75 | 87.36 | 72.49 | 74.78 | 39.14 | 40.58 | 69.83 | 70.74 |
| EM | 79.31 | 81.82 | 89.66 | 89.13 | 70.07 | 70.93 | 41.75 | 49.88 | 70.20 | 72.94 | |
| CPS | 80.43 | 81.12 | 89.63 | 88.85 | 71.64 | 71.27 | 39.49 | 47.47 | 70.30 | 72.18 | |
| MT | 80.47 | 82.35 | 88.58 | 85.95 | 71.07 | 71.56 | 40.18 | 47.16 | 70.07 | 71.76 | |
| UAMT | 81.12 | 82.38 | 89.36 | 87.13 | 71.79 | 75.09 | 40.29 | 47.71 | 70.64 | 73.08 | |
| ICT | 80.72 | 83.19 | 88.99 | 89.05 | 72.42 | 74.06 | 40.87 | 46.64 | 70.75 | 73.23 | |
| UATS | 80.39 | 83.26 | 88.66 | 88.57 | 68.53 | 67.89 | 43.15 | 51.20 | 70.18 | 72.73 | |
| ViT | Supervised | 69.04 | 74.95 | 84.25 | 82.20 | 58.66 | 54.73 | 36.63 | 38.52 | 62.15 | 62.60 |
| EM | 69.26 | 77.68 | 85.19 | 82.40 | 60.19 | 54.06 | 36.7 | 34.94 | 62.84 | 62.27 | |
| CPS | 69.14 | 74.66 | 84.58 | 82.50 | 57.91 | 53.14 | 37.79 | 44.85 | 62.35 | 63.79 | |
| MT | 69.23 | 72.21 | 85.06 | 82.69 | 58.95 | 51.62 | 36.52 | 37.08 | 62.44 | 60.90 | |
| UAMT | 69.02 | 77.34 | 84.73 | 82.20 | 59.16 | 56.82 | 35.42 | 38.18 | 62.08 | 63.63 | |
| ICT | 69.11 | 73.51 | 84.53 | 83.30 | 59.61 | 55.56 | 37.88 | 42.39 | 62.78 | 63.70 | |
| UATS | 68.70 | 74.34 | 85.14 | 81.82 | 60.75 | 56.36 | 37.92 | 43.11 | 63.13 | 63.91 | |
| PZ | TZ | DPU | AFS | |||||
|---|---|---|---|---|---|---|---|---|
| Dice | TPR | Dice | TPR | Dice | TPR | Dice | TPR | |
| MRF | 13.77 | 25.78 | 18.92 | 46.86 | 0.04 | 2.23 | 8.56 | 34.37 |
| Mean Shift | 9.06 | 19.21 | 14.15 | 30.21 | 0.07 | 3.31 | 6.36 | 22.51 |
| Ostu | 9.44 | 20.15 | 13.52 | 45.04 | 0 | 0 | 8.43 | 22.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, G.; Xia, B.; Zhuang, H.; Yan, B.; Wei, C.; Qi, S.; Qian, W.; He, D. A Comparative Analysis of U-Net and Vision Transformer Architectures in Semi-Supervised Prostate Zonal Segmentation. Bioengineering 2024, 11, 865. https://doi.org/10.3390/bioengineering11090865
Huang G, Xia B, Zhuang H, Yan B, Wei C, Qi S, Qian W, He D. A Comparative Analysis of U-Net and Vision Transformer Architectures in Semi-Supervised Prostate Zonal Segmentation. Bioengineering. 2024; 11(9):865. https://doi.org/10.3390/bioengineering11090865
Chicago/Turabian StyleHuang, Guantian, Bixuan Xia, Haoming Zhuang, Bohan Yan, Cheng Wei, Shouliang Qi, Wei Qian, and Dianning He. 2024. "A Comparative Analysis of U-Net and Vision Transformer Architectures in Semi-Supervised Prostate Zonal Segmentation" Bioengineering 11, no. 9: 865. https://doi.org/10.3390/bioengineering11090865