
LL-MAROCO: A Large Language Model-Assisted Robotic System for Oral and Craniomaxillofacial Osteotomy

 , , and
, , and
Abstract
1. Introduction
- (1)
- To the best of our knowledge, LLMs are applied for the first time to generate autonomous surgical instructions for osteotomy planning. With appropriately designed prompts, clinically relevant surgical plans can be produced by the model.
- (2)
- A control system integrating a surgical robotic platform with a navigation system is developed. Based on the generated instructions, the robotic system is able to perform task-specific actions aligned with pre-defined anatomical targets.
- (3)
- Experiments conducted on a skull model demonstrate the feasibility of the proposed system for autonomous osteotomy. In addition, a questionnaire-based evaluation indicates satisfactory performance in terms of clinical reliability and operational effectiveness.
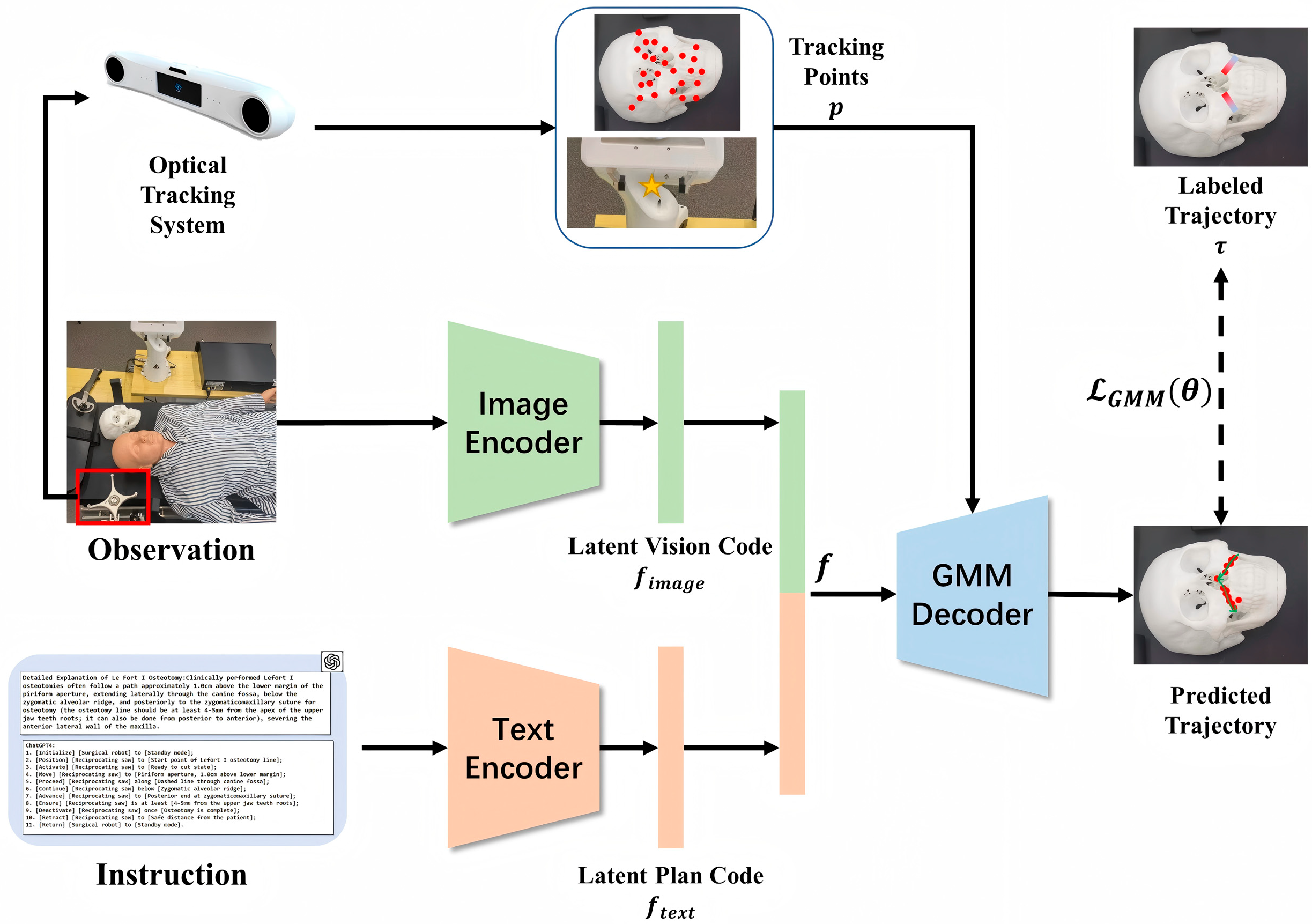
2. Materials and Methods
2.1. Instruction Generation
- Generate specific instruction texts step by step.
- Each step contains at most one action, one manipulated object, and one positional information.
- Terms related to actions, objects, and target positions should be enclosed in parentheses.
2.2. Multi-Space Registration
2.3. Navigation System
2.4. Experimental Platform
2.5. Evaluation of Surgery Performance
- The content of the reply made by ChatGPT-4 is easy to understand and logical.
- The text generated by ChatGPT-4 for the decomposition of surgical robotic osteotomy tasks is safe and reasonable.
- The process of the LL-MAROCO system as shown in the video is reasonable and convenient for you.
- The actual osteotomy process of the robotic arm as shown in the video aligns with actual clinical practice.
- If this type of control strategy can be promoted, you think it can protect patients’ rights and interests.
- You are willing to use LL-MAROCO to perform robotic osteotomies yourself.
3. Results
3.1. Quality of Generated Instruction
- Instruction Accuracy (I-A): whether the generated instructions correctly matched the surgical paths and instruments.
- Anatomical Appropriateness (A-A): whether relevant anatomical landmarks and target sites were correctly identified.
- Step Coherence (S-C): whether a logical sequence was maintained between different procedural steps.
- Terminological Precision (T-P): whether domain-specific terminology was used appropriately without semantic ambiguity.
3.2. Quantitative Results: Trajectory Accuracy and Procedural Completion
3.3. Qualitative Results: Questionnaire-Based Subjective Feedback from Surgeons
4. Discussion
4.1. Research Synthesis and LL-MAROCO’s Performance
4.2. Ethical Considerations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Augmented Reality |
| CAD/CAM | Computer-Aided Design/Computer-Aided Manufacturing |
| CT | Computed Tomography |
| DICOM | Digital Imaging and Communications in Medicine |
| FDI | Fédération Dentaire Internationale (ISO Tooth Numbering System) |
| GMM | Gaussian Mixture Model |
| LLM | Large Language Model |
| MIS | Minimally Invasive Surgery |
| MLP | Multi-Layer Perceptron |
| MRI | Magnetic Resonance Imaging |
| RASS | Robotic-Assisted Surgery System |
| STL | Standard Tessellation Language (File Format) |
| SVD | Singular Value Decomposition |
| VR | Virtual Reality |
References
- Patel, P.K.; Novia, M.V. The surgical tools: The LeFort I, bilateral sagittal split osteotomy of the mandible, and the osseous genioplasty. Clin. Plast. Surg. 2007, 34, 447–475. [Google Scholar] [CrossRef] [PubMed]
- Speth, J. Guidelines in Practice: Minimally Invasive Surgery. AORN J. 2023, 118, 250–257. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, S.; Das, S.; Ganguly, K.; Mandal, D. Advancements in robotic surgery: Innovations, challenges and future prospects. J. Robot. Surg. 2024, 18, 28. [Google Scholar] [CrossRef] [PubMed]
- Yu, M.; Luo, Y.; Li, B.; Xu, L.; Yang, X.; Man, Y. A Comparative Prospective Study on the Accuracy and Efficiency of Autonomous Robotic System Versus Dynamic Navigation System in Dental Implant Placement. J. Clin. Periodontol. 2025, 52, 280–288. [Google Scholar] [CrossRef] [PubMed]
- Maurin, B.; Doignon, C.; Gangloff, J.; Bayle, B.; de Mathelin, M.; Piccin, O.; Gangi, A. CTBot: A stereotactic-guided robotic assistant for percutaneous procedures of the abdomen. In Medical Imaging 2005: Visualization, Image-Guided Procedures, and Display; SPIE: Bellingham, WA, USA, 2005; pp. 241–250. [Google Scholar]
- Eslami, S.; Shang, W.; Li, G.; Patel, N.; Fischer, G.S.; Tokuda, J.; Hata, N.; Tempany, C.M.; Iordachita, I. In-bore prostate transperineal interventions with an MRI-guided parallel manipulator: System development and preliminary evaluation. Int. J. Med. Robot. 2016, 12, 199–213. [Google Scholar] [CrossRef]
- Han, R.; Uneri, A.; De Silva, T.; Ketcha, M.; Goerres, J.; Vogt, S.; Kleinszig, G.; Osgood, G.; Siewerdsen, J.H. Atlas-based automatic planning and 3D–2D fluoroscopic guidance in pelvic trauma surgery. Phys. Med. Biol. 2019, 64, 095022. [Google Scholar] [CrossRef]
- Han, R.; Uneri, A.; Ketcha, M.; Vijayan, R.; Sheth, N.; Wu, P.; Vagdargi, P.; Vogt, S.; Kleinszig, G.; Osgood, G.M.; et al. Multi-body 3D–2D registration for image-guided reduction of pelvic dislocation in orthopaedic trauma surgery. Phys. Med. Biol. 2020, 65, 135009. [Google Scholar] [CrossRef]
- Han, R.; Uneri, A.; Vijayan, R.C.; Wu, P.; Vagdargi, P.; Sheth, N.; Vogt, S.; Kleinszig, G.; Osgood, G.M.; Siewerdsen, J.H. Fracture reduction planning and guidance in orthopaedic trauma surgery via multi-body image registration. Med. Image Anal. 2021, 68, 101917. [Google Scholar] [CrossRef]
- Fauser, J.; Stenin, I.; Bauer, M.; Hsu, W.-H.; Kristin, J.; Klenzner, T.; Schipper, J.; Mukhopadhyay, A. Toward an automatic preoperative pipeline for image-guided temporal bone surgery. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 967–976. [Google Scholar] [CrossRef]
- Fauser, J.; Bohlender, S.; Stenin, I.; Kristin, J.; Klenzner, T.; Schipper, J.; Mukhopadhyay, A. Retrospective in silico evaluation of optimized preoperative planning for temporal bone surgery. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 1825–1833. [Google Scholar] [CrossRef]
- Lacave, C.; Diez, F.J. A review of explanation methods for heuristic expert systems. Knowl. Eng. Rev. 2004, 19, 133–146. [Google Scholar] [CrossRef]
- Tagliabue, E.; Bombieri, M.; Fiorini, P.; Dall’Alba, D. Autonomous Robotic Surgical Systems: Needing Common Sense to Achieve Higher Levels of Autonomy [Opinion]. IEEE Robot. Autom. Mag. 2023, 30, 149–163. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and applications of large language models. arXiv 2023, arXiv:2307.10169. [Google Scholar]
- Huang, W.; Xia, F.; Xiao, T.; Chan, H.; Liang, J.; Florence, P.; Zeng, A.; Tompson, J.; Mordatch, I.; Chebotar, Y. Inner monologue: Embodied reasoning through planning with language models. arXiv 2022, arXiv:2207.05608. [Google Scholar]
- Vemprala, S.H.; Bonatti, R.; Bucker, A.; Kapoor, A. ChatGPT for Robotics: Design Principles and Model Abilities. IEEE Access 2024, 12, 55682–55696. [Google Scholar] [CrossRef]
- You, H.; Ye, Y.; Zhou, T.; Zhu, Q.; Du, J. Robot-Enabled Construction Assembly with Automated Sequence Planning Based on ChatGPT: RoboGPT. Buildings 2023, 13, 1772. [Google Scholar] [CrossRef]
- Li, F.; Huang, C.; Feng, X.; Wang, L.; Zhang, C.; Chen, X. Intraoperative surgical navigation based on laser scanner for image-guided oral and maxillofacial surgery. J. Mech. Med. Biol. 2024, 24, 2440028. [Google Scholar] [CrossRef]
- Mandlekar, A.; Xu, D.; Wong, J.; Nasiriany, S.; Wang, C.; Kulkarni, R.; Fei-Fei, L.; Savarese, S.; Zhu, Y.; Martín-Martín, R. What matters in learning from offline human demonstrations for robot manipulation. arXiv 2021, arXiv:2108.03298. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Nair, S.; Rajeswaran, A.; Kumar, V.; Finn, C.; Gupta, A. R3m: A universal visual representation for robot manipulation. arXiv 2022, arXiv:2203.12601. [Google Scholar]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral cloning from observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Li, B.; Zhang, L.; Sun, H.; Yuan, J.; Shen, S.G.; Wang, X. A novel method of computer aided orthognathic surgery using individual CAD/CAM templates: A combination of osteotomy and repositioning guides. Br. J. Oral Maxillofac. Surg. 2013, 51, e239–e244. [Google Scholar] [CrossRef] [PubMed]
- Van den Bempt, M.; Liebregts, J.; Maal, T.; Bergé, S.; Xi, T. Toward a higher accuracy in orthognathic surgery by using intraoperative computer navigation, 3D surgical guides, and/or customized osteosynthesis plates: A systematic review. J. Craniomaxillofac. Surg. 2018, 46, 2108–2119. [Google Scholar] [CrossRef]
- Dai, J.; Wu, J.; Wang, X.; Yang, X.; Wu, Y.; Xu, B.; Shi, J.; Yu, H.; Cai, M.; Zhang, W.; et al. An excellent navigation system and experience in craniomaxillofacial navigation surgery: A double-center study. Sci. Rep. 2016, 6, 28242. [Google Scholar] [CrossRef]
- Azagury, D.E.; Dua, M.M.; Barrese, J.C.; Henderson, J.M.; Buchs, N.C.; Ris, F.; Cloyd, J.M.; Martinie, J.B.; Razzaque, S.; Nicolau, S.; et al. Image-guided surgery. Curr. Probl. Surg. 2015, 52, 476–520. [Google Scholar] [CrossRef]
- Kaplan, N.; Marques, M.; Scharf, I.; Yang, K.; Alkureishi, L.; Purnell, C.; Patel, P.; Zhao, L. Virtual Reality and Augmented Reality in Plastic and Craniomaxillofacial Surgery: A Scoping Review. Bioengineering 2023, 10, 480. [Google Scholar] [CrossRef]
- Qian, L.; Wu, J.Y.; DiMaio, S.P.; Navab, N.; Kazanzides, P. A Review of Augmented Reality in Robotic-Assisted Surgery. IEEE Trans. Med. Robot. Bionics 2020, 2, 1–16. [Google Scholar] [CrossRef]
- Cepolina, F.; Razzoli, R.P. An introductory review of robotically assisted surgical systems. Int. J. Med. Robot. 2022, 18, e2409. [Google Scholar] [CrossRef]
- Mozer, P.S. Accuracy and Deviation Analysis of Static and Robotic Guided Implant Surgery: A Case Study. Int. J. Oral Maxillofac. Implant. 2020, 35, e86–e90. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Qin, C.; Fan, S.; Yu, D.; Wu, Y.; Qin, J.; Chen, X. Pilot study of a surgical robot system for zygomatic implant placement. Med. Eng. Phys. 2020, 75, 72–78. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.Y.; Lee, S.J.; Yoo, J.Y.; Han, J.J.; Hwang, S.J.; Huh, K.H.; Lee, S.S.; Heo, M.S.; Choi, S.C.; Yi, W.J. Autonomous bone reposition around anatomical landmark for robot-assisted orthognathic surgery. J. Craniomaxillofac. Surg. 2017, 45, 1980–1988. [Google Scholar] [CrossRef]
- Han, J.J.; Woo, S.Y.; Yi, W.J.; Hwang, S.J. Robot-Assisted Maxillary Positioning in Orthognathic Surgery: A Feasibility and Accuracy Evaluation. J. Clin. Med. 2021, 10, 2596. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Hui, W.; Huang, J.; Luan, N.; Lin, Y.; Zhang, Y.; Zhang, S. The Feasibility of Robot-Assisted Chin Osteotomy on Skull Models: Comparison with Surgical Guides Technique. J. Clin. Med. 2022, 11, 6807. [Google Scholar] [CrossRef]
- Wu, J.; Hui, W.; Niu, J.; Chen, S.; Lin, Y.; Luan, N.; Shen, S.G.; Zhang, S. Collaborative Control Method and Experimental Research on Robot-Assisted Craniomaxillofacial Osteotomy Based on the Force Feedback and Optical Navigation. J. Craniofac. Surg. 2022, 33, 2011–2018. [Google Scholar] [CrossRef]
- Wake, N.; Kanehira, A.; Sasabuchi, K.; Takamatsu, J.; Ikeuchi, K. ChatGPT Empowered Long-Step Robot Control in Various Environments: A Case Application. IEEE Access 2023, 11, 95060–95078. [Google Scholar] [CrossRef]
- Ye, Y.; You, H.; Du, J. Improved Trust in Human-Robot Collaboration With ChatGPT. IEEE Access 2023, 11, 55748–55754. [Google Scholar] [CrossRef]
- Gao, Y.; Tong, W.; Wu, E.Q.; Chen, W.; Zhu, G.; Wang, F.Y. Chat With ChatGPT on Interactive Engines for Intelligent Driving. IEEE Trans. Intell. Veh. 2023, 8, 2034–2036. [Google Scholar] [CrossRef]
- Bell, S.W.; Anthony, I.; Jones, B.; MacLean, A.; Rowe, P.; Blyth, M. Improved Accuracy of Component Positioning with Robotic-Assisted Unicompartmental Knee Arthroplasty: Data from a Prospective, Randomized Controlled Study. J. Bone Jt. Surg. Am. 2016, 98, 627–635. [Google Scholar] [CrossRef]
- Lin, L.; Shi, Y.; Tan, A.; Bogari, M.; Zhu, M.; Xin, Y.; Xu, H.; Zhang, Y.; Xie, L.; Chai, G. Mandibular angle split osteotomy based on a novel augmented reality navigation using specialized robot-assisted arms—A feasibility study. J. Craniomaxillofac. Surg. 2016, 44, 215–223. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Zhu, M.; Shi, Y.; Lin, L.; Chai, G.; Zhang, Y.; Xie, L. Robot-Assisted Surgery for Mandibular Angle Split Osteotomy Using Augmented Reality: Preliminary Results on Clinical Animal Experiment. Aesthetic Plast. Surg. 2017, 41, 1228–1236. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Chai, Y.; Chai, G.; Zheng, X. Fully Automatic Robot-Assisted Surgery for Mandibular Angle Split Osteotomy. J. Craniofac. Surg. 2020, 31, 336–339. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
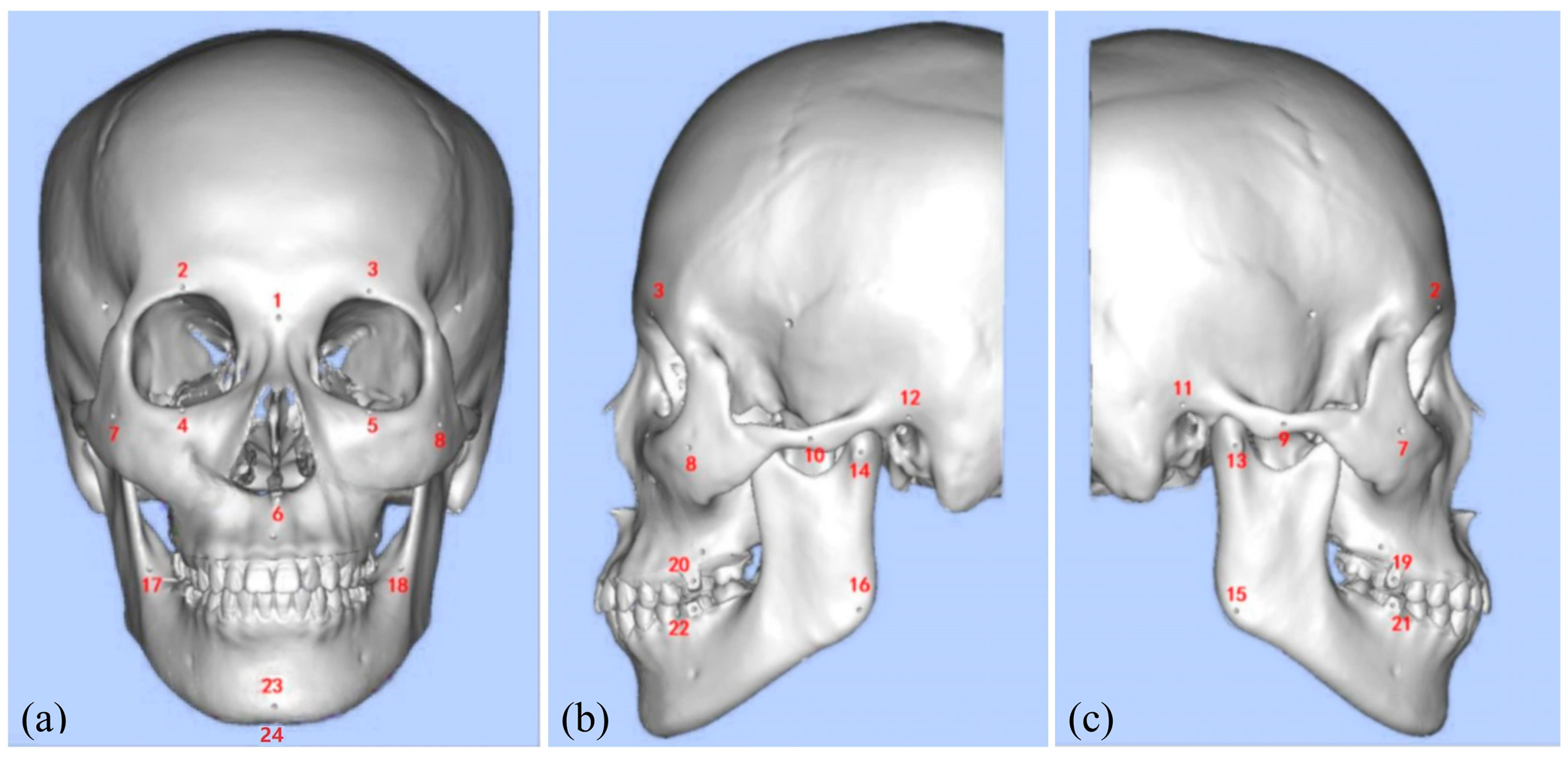
| Number | The Anatomical Landmark | Number | The Anatomical Landmark |
|---|---|---|---|
| 1 | Nasion | 13 | Right Lateral Condyle Point |
| 2 | Right Supraorbital Foramen | 14 | Left Lateral Condyle Point |
| 3 | Left Supraorbital Foramen | 15 | Right Gonion |
| 4 | Right Infraorbital Margin | 16 | Left Gonion |
| 5 | Left Infraorbital Margin | 17 | Right Mandibular Ramus Bend |
| 6 | Anterior Nasal Spine | 18 | Left Mandibular Ramus Bend |
| 7 | Right Zygion | 19 | Maxillary right first molar buccal point (FDI 16) |
| 8 | Left Zygion | 20 | Maxillary left first molar buccal point (FDI 26) |
| 9 | Right Zygomatic Arch Prominence | 21 | Mandibular right first molar buccal point (FDI 46) |
| 10 | Left Zygomatic Arch Prominence | 22 | Mandibular left first molar buccal point (FDI 36) |
| 11 | Right Auricular Point | 23 | Pogonion |
| 12 | Left Auricular Point | 24 | Menton |
| Type A | Type B | Type C | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I-A | 5/5 | 4/5 | 5/5 | 4/5 | 4/4 | 3/4 | 4/5 | 5/5 | 4/5 | 5/5 | 4/5 | 5/5 | 5/5 | 5/5 | 5/5 | 4/5 | 5/5 | 4/5 | 4/4 | 5/5 | 4/4 | 4/5 | 5/4 | 5/4 | 5/4 | 5/5 | 5/4 | 5/4 | 4/4 | 5/5 |
| A-A | 3/3 | 3/4 | 4/3 | 3/3 | 3/4 | 4/5 | 4/4 | 3/4 | 3/4 | 3/3 | 5/5 | 4/5 | 5/5 | 5/4 | 5/4 | 5/5 | 5/5 | 5/5 | 5/5 | 5/5 | 3/3 | 3/3 | 3/3 | 3/2 | 3/3 | 2/3 | 4/3 | 4/4 | 2/2 | 2/3 |
| S-C | 3/4 | 4/5 | 3/5 | 5/5 | 5/5 | 5/5 | 5/5 | 4/5 | 5/5 | 4/5 | 5/5 | 5/5 | 4/5 | 5/5 | 5/5 | 5/5 | 5/5 | 5/5 | 4/5 | 4/5 | 4/3 | 4/4 | 4/4 | 4/3 | 5/4 | 3/3 | 2/3 | 2/2 | 3/2 | 3/3 |
| T-P | 3/3 | 2/3 | 3/3 | 4/4 | 3/3 | 3/4 | 4/4 | 3/3 | 3/4 | 3/3 | 4/5 | 4/4 | 5/5 | 4/5 | 4/4 | 5/5 | 5/4 | 5/4 | 5/5 | 4/4 | 4/5 | 4/4 | 5/4 | 5/5 | 4/4 | 4/5 | 4/5 | 5/5 | 5/4 | 5/4 |
| Metrics | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| /mm | 0.23 | 0.34 | 0.18 | 0.25 | 0.21 | 0.23 | 0.22 | 0.31 | 0.19 | 0.23 | 0.24 |
| /mm | 1.45 | 1.98 | 1.23 | 1.32 | 1.38 | 1.41 | 1.43 | 1.67 | 1.32 | 1.38 | 1.46 |
| Target | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Le Fort I | 85% | 90% | 80% | 95% | 85% | 85% | 90% | 85% | 95% | 80% | 87% |
| Genioplasty | 90% | 95% | 90% | 90% | 95% | 95% | 90% | 90% | 90% | 95% | 92% |
| Methods | Success Rate | /mm | |
|---|---|---|---|
| Le Fort I | Genioplasty | ||
| BC-RNN [21] | 71% | 76% | 1.68 |
| BC-GPT [22] | 82% | 85% | 1.52 |
| BC-R3M [23] | 80% | 83% | 1.61 |
| Ours | 87% | 92% | 1.46 |
| Options | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 |
|---|---|---|---|---|---|---|
| Strongly agree | 45 | 18 | 19 | 43 | 9 | 47 |
| Agree | 5 | 22 | 27 | 7 | 28 | 3 |
| Neutral | 0 | 8 | 4 | 0 | 11 | 0 |
| Disagree | 0 | 2 | 0 | 0 | 2 | 0 |
| Strongly disagree | 0 | 0 | 0 | 0 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Shao, L.; Wu, J.; Xu, X.; Chen, X.; Zhang, S. LL-MAROCO: A Large Language Model-Assisted Robotic System for Oral and Craniomaxillofacial Osteotomy. Bioengineering 2025, 12, 629. https://doi.org/10.3390/bioengineering12060629
Jiang L, Shao L, Wu J, Xu X, Chen X, Zhang S. LL-MAROCO: A Large Language Model-Assisted Robotic System for Oral and Craniomaxillofacial Osteotomy. Bioengineering. 2025; 12(6):629. https://doi.org/10.3390/bioengineering12060629
Chicago/Turabian StyleJiang, Lai, Liangjing Shao, Jinyang Wu, Xiaofeng Xu, Xinrong Chen, and Shilei Zhang. 2025. "LL-MAROCO: A Large Language Model-Assisted Robotic System for Oral and Craniomaxillofacial Osteotomy" Bioengineering 12, no. 6: 629. https://doi.org/10.3390/bioengineering12060629
APA StyleJiang, L., Shao, L., Wu, J., Xu, X., Chen, X., & Zhang, S. (2025). LL-MAROCO: A Large Language Model-Assisted Robotic System for Oral and Craniomaxillofacial Osteotomy. Bioengineering, 12(6), 629. https://doi.org/10.3390/bioengineering12060629