A Dataset for Comparing Mirrored and Non-Mirrored Male Bust Images for Facial Recognition



Abstract
:1. Summary
- Facilitates the testing of the impact of the use of mirrored imagery for testing facial recognition algorithms and for comparing this impact between algorithms.
- Includes mirrored and non-mirrored data for different subject positions, lighting angles, lighting brightness, and lighting temperature conditions.
- Includes mirrored and non-mirrored non-occluded data and data with hat and glasses occlusions.
- The data was collected in a controlled environment with a consistent background.
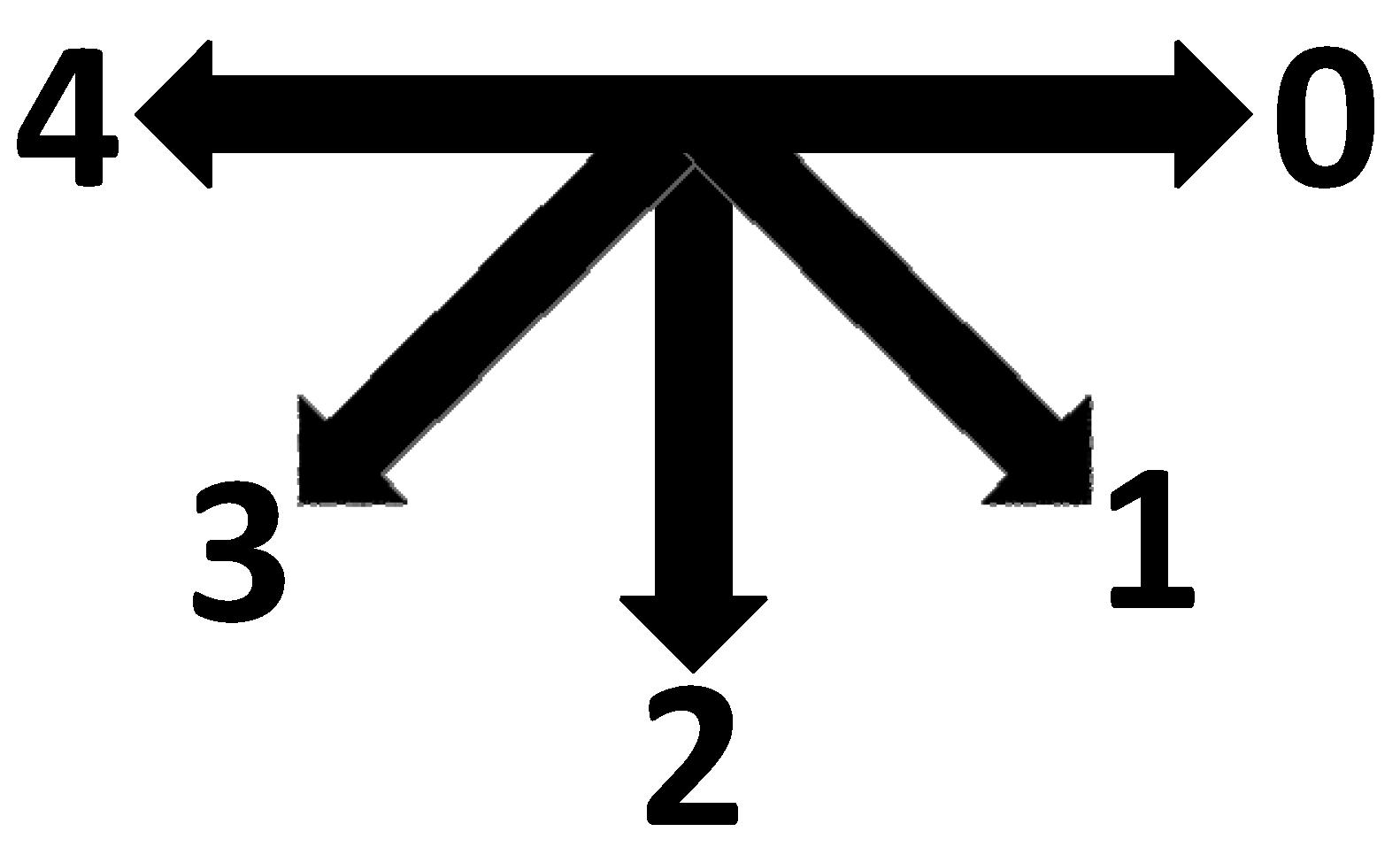
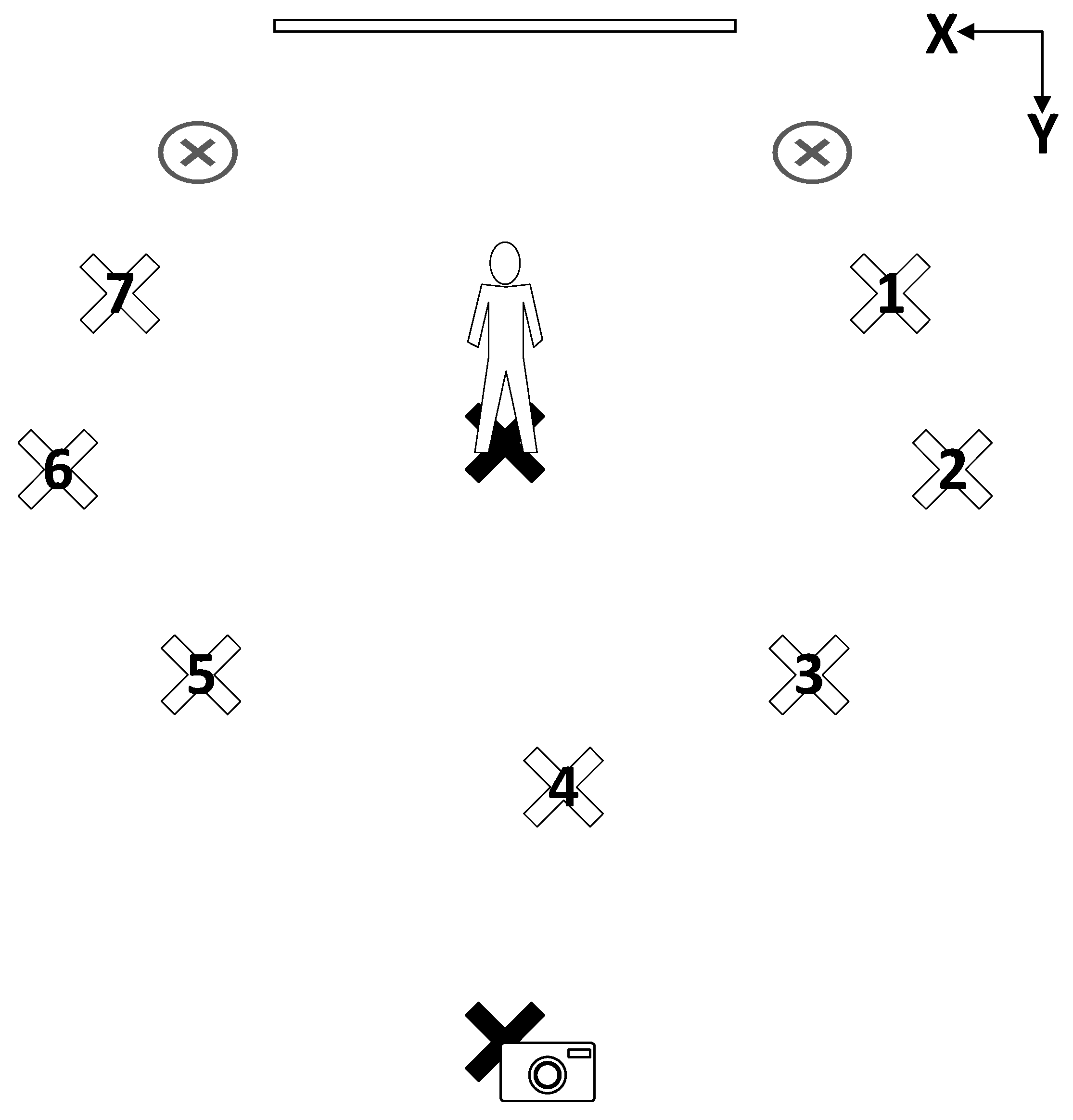
2. Data Description
2.1. Data Organization
2.2. Comparison to Other Data Sets
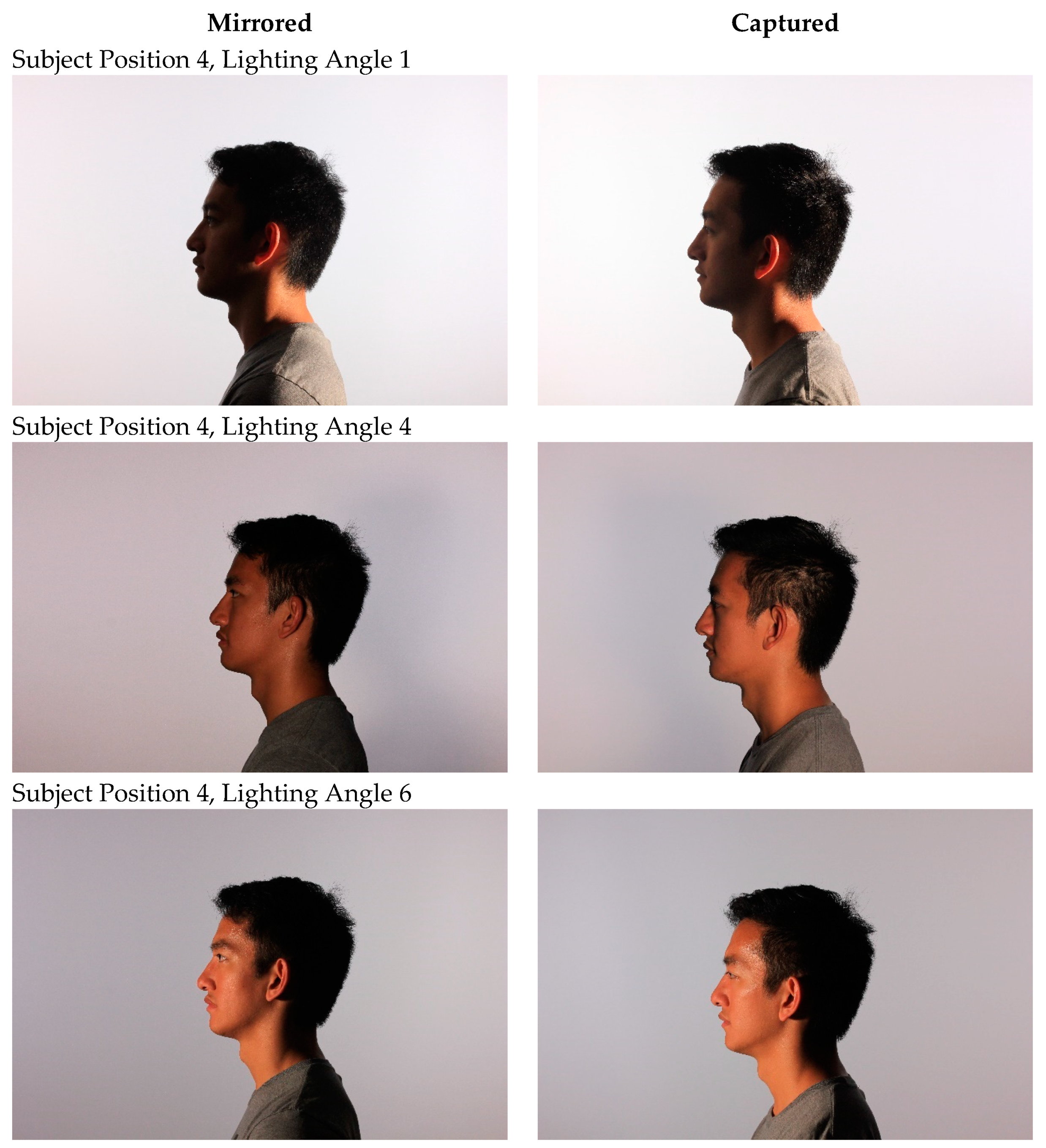
3. Methods
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Denimarck, P.; Bellis, D.; McAllister, C. Biometric System and Method for Identifying a Customer upon Entering a Retail Establishment. U.S. Patent 09/909,576, 23 January 2003. [Google Scholar]
- Lu, D.; Kiewit, D.A.; Zhang, J. Market research method and system for collecting retail store and shopper market research data. U.S. Patent 5,331,544, 19 July 1994. [Google Scholar]
- Payne, J.H. Biometric face recognition for applicant screening. U.S. Patent No. 6,072,894, 6 June 2000. [Google Scholar]
- Kail, K.; Williams, C.; Kail, R. Access control system with RFID and biometric facial recognition. U.S. Patent Application 11/790,385, 1 November 2007. [Google Scholar]
- Introna, L.; Wood, D. Picturing algorithmic surveillance: the politics of facial recognition systems. Surveill. Soc. 2004, 2, 177–198. [Google Scholar] [CrossRef]
- Ramesha, K.B.R.K.; Raja, K.B.; Venugopal, K.R.; Patnaik, L.M. Feature Extraction based Face Recognition, Gender and Age Classification. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.163.4518 (accessed on 5 February 2019).
- Wiskott, L.; Fellous, J.-M.; Krüger, N.; von der Malsburg, C. Face Recognition and Gender Determination. 1995, pp. 92–97. Available online: http://cogprints.org/1485/2/95_WisFelKrue+.pdf (accessed on 5 February 2019).
- Yeasin, M.; Sharma, R.; Yeasin, M.; Member, S.; Bullot, B. Recognition of facial expressions and measurement of levels of interest from video. IEEE Trans. Multimed. 2006, 8, 500–508. [Google Scholar] [CrossRef]
- Lin, S.-H.; Kung, S.-Y.; Lin, L.-J. Face Recognition/Detection by Probabilistic Decision-Based Neural Network. IEEE Trans. Neural Netw. 1997, 8, 114–132. [Google Scholar] [PubMed]
- Martinez, A.M. Recognizing imprecisely localized, partially occluded, and expression variant faces from a single sample per class. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 748–763. [Google Scholar] [CrossRef]
- Kim, J.; Choi, J.; Yi, J.; Turk, M. Effective representation using ICA for face recognition robust to local distortion and partial occlusion. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1977–1981. [Google Scholar] [CrossRef] [PubMed]
- Venkat, I.; Khader, A.T.; Subramanian, K.G.; De Wilde, P. Psychophysically Inspired Bayesian Occlusion Model to Recognize Occluded Faces. In Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 420–426. [Google Scholar]
- Norouzi, E.; Ahmadabadi, M.N.; Araabi, B.N. Attention control with reinforcement learning for face recognition under partial occlusion. Mach. Vis. Appl. 2011, 22, 337–348. [Google Scholar] [CrossRef]
- Tan, X.; Chen, S.; Zhou, Z.-H.; Zhang, F. Face recognition from a single image per person: A survey. Pattern Recognit. 2006, 39, 1725–1745. [Google Scholar] [CrossRef]
- Drira, H.; Ben Amor, B.; Srivastava, A.; Daoudi, M.; Slama, R. 3D Face Recognition under Expressions, Occlusions, and Pose Variations. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2270–2283. [Google Scholar] [CrossRef] [PubMed]
- Coffin, J.S.; Ingram, D. Facial recognition system for security access and identification. U.S. Patent 5,991,429, 23 November 1999. [Google Scholar]
- Schroeder, C.C. Biometric security process for authenticating identity and credit cards, visas, passports and facial recognition. U.S. Patent 5,787,186, 28 July 1998. [Google Scholar]
- Bowyer, K.W. Face recognition technology: Security versus privacy. IEEE Technol. Soc. Mag. 2004, 23, 9–19. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.; Pankanti, S. Biometrics: A Tool for Information Security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–143. [Google Scholar] [CrossRef]
- Ijiri, Y.; Sakuragi, M.; Lao, S. Security Management for Mobile Devices by Face Recognition. In Proceedings of the 7th International Conference on Mobile Data Management (MDM’06), Nara, Japan, 10–12 May 2006; p. 49. [Google Scholar]
- Lemelson, J.H.; Hoffman, L.J. Facial-recognition vehicle security system and automatically starting vehicle. U.S. Patent 7,116,803, 3 October 2006. [Google Scholar]
- Karovaliya, M.; Karedia, S.; Oza, S.; Kalbande, D.R. Enhanced Security for ATM Machine with OTP and Facial Recognition Features. Procedia Comput. Sci. 2015, 45, 390–396. [Google Scholar] [CrossRef]
- Milborrow, S.; Nicolls, F. Locating Facial Features with an Extended Active Shape Model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 504–513. [Google Scholar]
- Tarrés, F.; Rama, A. A Novel Method for Face Recognition under partial occlusion or facial expression Variations 1. In Proceedings of the 47th International Symposium ELMAR, Zadar, Croatia, 8–10 June 2005; pp. 163–166. [Google Scholar]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Milborrow, S.; Morkel, J.; Nicolls, F. The MUCT Landmarked Face Database. Pattern Recogni. Assoc. South Afr. 2010. Available online: http://www.dip.ee.uct.ac.za/~nicolls/publish/sm10-prasa.pdf (accessed on 5 February 2019).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Martin, C.; Werner, U.; Gross, H.-M. A Real-time Facial Expression Recognition System based on Active Appearance Models using Gray Images and Edge Images. In Proceedings of the 8th IEEE International Conference on Face and Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 Computer Vision and Pattern Recognition Conference, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xiao, R.; Li, M.-J.; Zhang, H.-J. Robust Multipose Face Detection in Images. IEEE Trans. CIRCUITS Syst. VIDEO Technol. 2004, 14. [Google Scholar] [CrossRef]
- Lienhart, R.; Liang, L.; Kuranov, A. A detector tree of boosted classifiers for real-time object detection and tracking. In In Proceedings of the 2003 International Conference on Multimedia and Expo. ICME ’03. Proceedings (Cat. No.03TH8698), Baltimore, MD, USA, 6–9 July 2003. [Google Scholar]
- Rowley, H.A.; Baluja, S.; Kanade, T. Neural network-based face detection. In Proceedings of the CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 203–208. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. On Rendering Synthetic Images for Training an Object Detector. Comput. Vision Image Underst. 2014, 137, 24–37. [Google Scholar] [CrossRef]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When Face Recognition Meets with Deep Learning: an Evaluation of Convolutional Neural Networks for Face Recognition. In Proceedings of the 2015 International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Miclut, B.; Käster, T.; Martinetz, T.; Barth, E. Committees of deep feedforward networks trained with few data; In Proceedings of the German Conference on Pattern Recognition (GCPR 2014), Münster, Germany, 2–5 September 2014.
- Gros, C.; Straub, J. Human face images from multiple perspectives with lighting from multiple directions with no occlusion, glasses and hat. Data Br. 2019, 22, 522–529. [Google Scholar] [CrossRef] [PubMed]
- Learned-Miller, E.; Huang, G.B.; RoyChowdhury, A.; Li, H.; Hua, G. Labeled Faces in the Wild: A Survey. In Advances in Face Detection and Facial Image Analysis; Springer International Publishing: Cham, Switzerland, 2016; pp. 189–248. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 87–102. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K.; Klare, B.; et al. Pushing the Frontiers of Unconstrained Face Detection and Recognition: IARPA Janus Benchmark A. In Proceedings of the Computer Vision and Pattern Recognition 2015 Conference, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]
- Salari, S.R.; Rostami, H. Pgu-Face: A dataset of partially covered facial images. Data Br. 2016, 9, 288–291. [Google Scholar] [CrossRef] [PubMed]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Ahonen, T.; Rahtu, E.; Ojansivu, V.; Heikkila, J. Recognition of blurred faces using Local Phase Quantization. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- NIST Face Recognition Technology (FERET). Available online: https://www.nist.gov/programs-projects/face-recognition-technology-feret (accessed on 29 January 2019).
- AT&T The Database of Faces. Available online: https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html (accessed on 29 January 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | X Coordinate | Y Coordinate |
|---|---|---|
| Light 1 | 47.5 | 65 |
| Light 2 | 44 | 87.5 |
| Light 3 | 61 | 115 |
| Light 4 | 84.5 | 127.5 |
| Light 5 | 124 | 116.5 |
| Light 6 | 198 | 91 |
| Light 7 | 149 | 66 |
| Background 1 | 43.5 | 50.5 |
| Background 2 | 129 | 47 |
| Camera | 97 | 150 |
| Subject | 96.5 | 63.5 |
| Configuration Title | Settings |
|---|---|
| Warm | 60% brightness on warm (3200 k) |
| Cold | 60% brightness on cold (5500 k) |
| Low | 10% brightness on warm (3200 k) and 10% brightness on cold (5500 k) |
| Medium | 40% brightness on warm (3200 k) and 40% on brightness on cold (5500 k) |
| High | 70% brightness on warm (3200 k) and 70% brightness on cold (5500 k) |
| Subject Position | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 3′ | 4 | 4′ | ||
| Light Angle | 1 | 2 | 17 | 92 | 137 | 138 | 182 | 183 |
| 2 | 25 | 20 | 65 | 110 | 120 | 155 | 165 | |
| 3 | 55 | 10 | 35 | 80 | 72 | 125 | 117 | |
| 4 | 79 | 34 | 11 | 56 | 56 | 101 | 101 | |
| 5 | 117 | 72 | 27 | 18 | 10 | 63 | 55 | |
| 6 | 165 | 120 | 75 | 30 | 20 | 15 | 25 | |
| 7 | 183 | 138 | 93 | 48 | 17 | 3 | 2 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gros, C.; Straub, J. A Dataset for Comparing Mirrored and Non-Mirrored Male Bust Images for Facial Recognition. Data 2019, 4, 26. https://doi.org/10.3390/data4010026
Gros C, Straub J. A Dataset for Comparing Mirrored and Non-Mirrored Male Bust Images for Facial Recognition. Data. 2019; 4(1):26. https://doi.org/10.3390/data4010026
Chicago/Turabian StyleGros, Collin, and Jeremy Straub. 2019. "A Dataset for Comparing Mirrored and Non-Mirrored Male Bust Images for Facial Recognition" Data 4, no. 1: 26. https://doi.org/10.3390/data4010026
APA StyleGros, C., & Straub, J. (2019). A Dataset for Comparing Mirrored and Non-Mirrored Male Bust Images for Facial Recognition. Data, 4(1), 26. https://doi.org/10.3390/data4010026