
Learning Interpretable Mixture of Weibull Distributions—Exploratory Analysis of How Economic Development Influences the Incidence of COVID-19 Deaths



Abstract
:1. Introduction
2. The Proposed Fuzzy Mixture of the Weibull Distributions Model and Its Clustering-Based Identification Method
2.1. The Rule-Based Mixture of Weibull Distributions
- If is and … is , then ,
2.2. Estimation of the Model Parameters
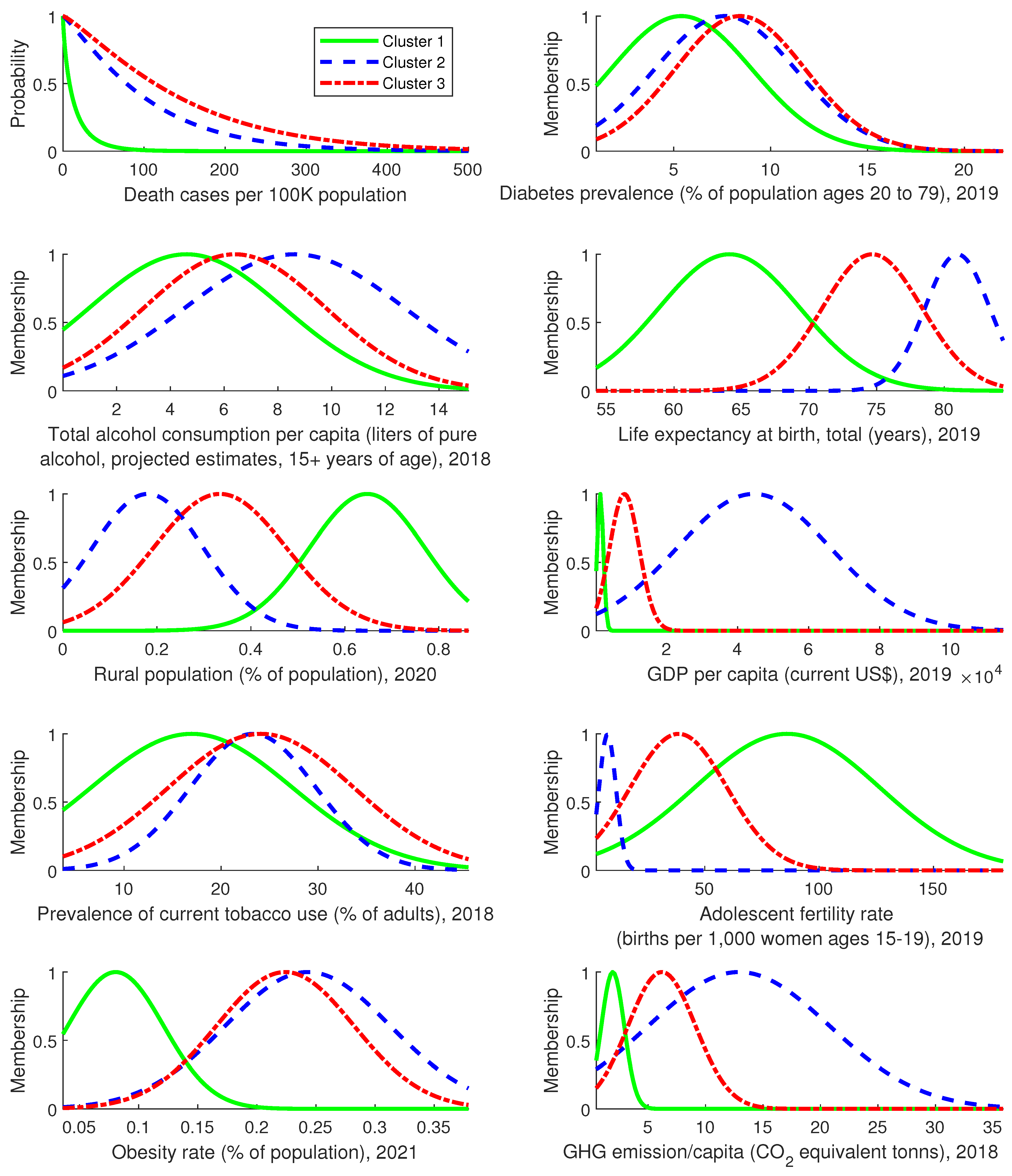
3. Analysis of the Distribution of the COVID-19 Mortality Rate
3.1. The Dataset and the Availability of the Program Code
3.2. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, K.Y.; Chang, I.H.; Pham, H. A software reliability model with a Weibull fault detection rate function subject to operating environments. Appl. Sci. 2017, 7, 983. [Google Scholar] [CrossRef] [Green Version]
- Looha, M.A.; Zarean, E.; Masaebi, F.; Pourhoseingholi, M.A.; Zali, M.R. Assessment of prognostic factors in long-term survival of male and female patients with colorectal cancer using non-mixture cure model based on the Weibull distribution. Surg. Oncol. 2021, 38, 101562. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.H.; Xiong, Q.Q.; Wu, Z.J. New method for obtaining the homogeneity index m of Weibull distribution using peak and crack damage strains. Int. J. Geomech 2018, 18, 04018034. [Google Scholar] [CrossRef]
- Castet, J.F.; Saleh, J.H. Single versus mixture Weibull distributions for nonparametric satellite reliability. Reliab. Eng. Syst. Saf. 2010, 95, 295–300. [Google Scholar] [CrossRef]
- Elmahdy, E.E. Modelling reliability data with finite Weibull or lognormal mixture distributions. Appl Math Inf. Sci 2017, 11, 1081–1089. [Google Scholar] [CrossRef]
- Bennis, A.; Mouysset, S.; Serrurier, M. Estimation of Conditional Mixture Weibull Distribution with Right Censored Data Using Neural Network for Time-to-Event Analysis. In Advances in Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2020; Volume 12084, pp. 687–698. [Google Scholar]
- Abonyi, J.; Babuska, R.; Szeifert, F. Modified Gath-Geva fuzzy clustering for identification of Takagi-Sugeno fuzzy models. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2002, 32, 612–621. [Google Scholar] [CrossRef] [PubMed]
- Abonyi, J.; Szeifert, F. Supervised fuzzy clustering for the identification of fuzzy classifiers. Pattern Recognit. Lett. 2003, 24, 2195–2207. [Google Scholar] [CrossRef] [Green Version]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- John Hopkins University, Coronavirus Resource Center: Cases and Mortality by Country. Available online: https://coronavirus.jhu.edu/data/mortality (accessed on 27 September 2021).
- World Data Bank. Available online: https://data.worldbank.org/ (accessed on 27 September 2021).
- Most Obese Countries. 2021. Available online: https://worldpopulationreview.com/country-rankings/most-obese-countries (accessed on 11 October 2021).
- Patanavanich, R.; Glantz, S.A. Smoking is associated with COVID-19 progression: A meta-analysis. Nicotine Tob. Res. 2020, 22, 1653–1656. [Google Scholar] [CrossRef] [PubMed]
- Peric, S.; Stulnig, T.M. Diabetes and COVID-19. Wien. Klin. Wochenschr. 2020, 132, 356–361. [Google Scholar] [CrossRef] [PubMed]
- Bulled, N.L.; Sosis, R. Examining the relationship between life expectancy, reproduction, and educational attainment. Hum. Nat. 2010, 21, 269–289. [Google Scholar] [CrossRef]
- Makaroun, L.K.; Bachrach, R.L.; Rosland, A.M. Elder abuse in the time of COVID-19—Increased risks for older adults and their caregivers. Am. J. Geriatr. Psychiatry 2020, 28, 876. [Google Scholar] [CrossRef] [PubMed]
- Katsoulakos, N.; Misthos, L.M.; Doulos, I.G.; Kotsios, V. Environment and Development. In Environment and Development; Elsevier: Amsterdam, The Netherlands, 2016; pp. 499–569. [Google Scholar]
- Konstantinoudis, G.; Padellini, T.; Bennett, J.; Davies, B.; Ezzati, M.; Blangiardo, M. Long-term exposure to air-pollution and COVID-19 mortality in England: A hierarchical spatial analysis. Environ. Int. 2021, 146, 106316. [Google Scholar] [CrossRef] [PubMed]
- Bhadra, A.; Mukherjee, A.; Sarkar, K. Impact of population density on Covid-19 infected and mortality rate in India. Model. Earth Syst. Environ. 2021, 7, 623–629. [Google Scholar] [CrossRef] [PubMed]
- Malik, P.; Patel, U.; Patel, K.; Martin, M.; Shah, C.; Mehta, D.; Malik, F.A.; Sharma, A. Obesity a predictor of outcomes of COVID-19 hospitalized patients—a systematic review and meta-analysis. J. Med. Virol. 2021, 93, 1188–1193. [Google Scholar] [CrossRef] [PubMed]
- Calina, D.; Hartung, T.; Mardare, I.; Mitroi, M.; Poulas, K.; Tsatsakis, A.; Rogoveanu, I.; Docea, A.O. COVID-19 pandemic and alcohol consumption: Impacts and interconnections. In Toxicology Reports; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sector | Variable Name | Time Interval | Downloaded | Source |
|---|---|---|---|---|
| Economic | GDP per capita | 01.01.2019 | 27.09.2021 | [11] |
| (current US$) | 31.12.2019 | |||
| Health | Adolescent fertility rate | 01.01.2019 | 27.09.2021 | [11] |
| (births per 1000 women ages 15–19) | 31.12.2019 | |||
| Economic | GHG emission/capita | 01.01.2018 | 27.09.2021 | [11] |
| (CO2 equivalent) | 31.12.2018 | |||
| Urban | Rural Population | 01.01.2020 | 27.09.2021 | [11] |
| (% of population) | 31.12.2020 | |||
| Health | Diabetes prevalence | 01.01.2019 | 27.09.2021 | [11] |
| (% of population ages 20–79) | 31.12.2019 | 27.09.2021 | ||
| Health | Total alcohol consumption per capita | 01.01.2018 | 27.09.2021 | [11] |
| (liters of pure alcohol, | 31.12.2018 | |||
| projected estimates, 15+ years of age) | ||||
| Health | Life expectancy at birth | 01.01.2019 | 27.09.2021 | [11] |
| (years) | 31.12.2019 | |||
| Health | Prevalence of current tobacco use | 01.01.2018 | 27.09.2021 | [11] |
| (% of adults) | 31.12.2018 | |||
| Health | Obesity Rate | 01.01.2021 | 11.10.2021 | [12] |
| (% of population) | 31.12.2021 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Csalódi, R.; Birkner, Z.; Abonyi, J. Learning Interpretable Mixture of Weibull Distributions—Exploratory Analysis of How Economic Development Influences the Incidence of COVID-19 Deaths. Data 2021, 6, 125. https://doi.org/10.3390/data6120125
Csalódi R, Birkner Z, Abonyi J. Learning Interpretable Mixture of Weibull Distributions—Exploratory Analysis of How Economic Development Influences the Incidence of COVID-19 Deaths. Data. 2021; 6(12):125. https://doi.org/10.3390/data6120125
Chicago/Turabian StyleCsalódi, Róbert, Zoltán Birkner, and János Abonyi. 2021. "Learning Interpretable Mixture of Weibull Distributions—Exploratory Analysis of How Economic Development Influences the Incidence of COVID-19 Deaths" Data 6, no. 12: 125. https://doi.org/10.3390/data6120125
APA StyleCsalódi, R., Birkner, Z., & Abonyi, J. (2021). Learning Interpretable Mixture of Weibull Distributions—Exploratory Analysis of How Economic Development Influences the Incidence of COVID-19 Deaths. Data, 6(12), 125. https://doi.org/10.3390/data6120125