1. Introduction
The hidden potential for research and innovation held by data is nowadays widely acknowledged [
1,
2]. However, collaborative use of data based on data exchange between the parties involved is still far from becoming a standard practice and still faces various challenges [
3,
4,
5,
6,
7]. In our study, focused on the Austrian Federal State of Styria, we survey regional stakeholders from private and public institutions to identify the factors that facilitate collaborative data use, and investigate the need for data infrastructures, expertise, and training, as well as attitudes toward sharing, which could enable the widespread cooperative use of data in the future.
The project “IDE@S: Innovative Data Environment @ Styria”, funded by the government of the Federal State of Styria, is fostering cooperation between Styrian stakeholders (companies, academia, and public institutions) in data science and collaborative data tools with the goal of creating a distributed data platform that ensures data sovereignty irrespective of how data is exchanged. This is achieved by exploring the current state, existing gaps, and desired development of technical infrastructures, services, human resources (including education and training), as well as governance structure and potential business models. As one of the most innovative regions in the EU, Styria presents a rich mix of higher education and research institutions and industrial clusters (in sectors like e.g., automotive, green tech, health, or semiconductor technologies), eager to adopt new technologies and innovation strategies, and constitutes the ideal breeding ground for the creation of innovative data ecosystems.
The present study, part of the IDE@S project, provides insight into day-to-day work with data from Styrian stakeholders, investigates their attitude toward data-driven collaboration, and sets the basis to evaluate the need for regional data infrastructures. It also provides an overview of data-related tasks, best practices, and competences among staff. We use the responses to interviews held with Styrian stakeholders in the course of the project to analyze what further developments are required to extend collaboration through data exchange. The paper is organized as follows: After giving background information in
Section 2, we introduce the interview framework in
Section 3, then show the results of closed and open questions in
Section 4, and discuss the main findings in
Section 5.
2. Literature Survey
Many actors in the academic world and in a large number of industrial sectors are aware of the importance of the exchange of open and well-documented high-quality data supported by reliable and effective data services [
8] to transfer knowledge, boost innovation, and introduce new business models [
9,
10]. A number of cultural, ethical, financial, legal, and technical factors [
4,
5,
6] hinder the exploitation of its full advantages. Conversely, some of these challenges can also enable public-private collaborations if enough suitable technical and organizational resources are allocated [
11]. To ensure scientific progress and sustainable development, collaborative initiatives that involve both private (including academia and others as “not-for-profit organizations”, or NFPO) and private (for-profit organizations, or FPO) institutions are required [
12,
13,
14]. This connection between private and public sectors forms the foundation of knowledge-based innovation systems [
15], since it allows universities to know and eventually follow market needs, and support companies by providing them with additional research and development opportunities. Governmental institutions play the important role of facilitating the coordination of policies and investments. Every organization, to a greater or lesser extent, does rely on data assets and data management resources which can be used to create knowledge and evolve business processes [
16]. Thus far, the public administration has lagged behind the private and research sector in terms of big data use based on the main components of business strategy, organizational capabilities, big data application strategy, and IT infrastructure, while data collaborations could further benefit from them being up to date on big-data readiness and the digital transformation [
17,
18]. Such cross-sector and public-private partnerships that add value to a social good or innovation appear in various forms, which have been described taxonomically by their dimensions and characteristics [
19], dynamics and governance [
20], and in terms of sustainability [
21].
The monetary value of data is often perceived differently among stakeholders due to its complex nature, together with quality information asymmetry and lack of pricing standards [
22]. The current evolution of data generation by dispersed and linked sources makes data not reliably attributable to one identifiable person. This demands collaborative strategies for data networks [
23]. Generally speaking, collaborative data networks contribute to the successful generation of quality information by considering data value, management, and technology [
24]. Moreover, extended data networks can increase the amount of data collected as well as interrelated models [
25].
The interaction and collaboration between data producers and consumers usually occurs in so-called “data ecosystems”, i.e., environments that contain the necessary infrastructures and services for the exchange, processing, or reuse of available data [
26]. Such data ecosystems can only work if the right tools for federated data management, and the access to and between data collections, are in place [
27,
28,
29,
30,
31]. Federated data environments, a particular case of data ecosystems characterized by the control over data retained by data producers at all times (as opposed to centralizing data in a single repository from which it is retrieved for analysis), are best placed to take advantage of the benefits of data sharing data ecosystems [
32], especially if they incorporate basic linked data principles, such as interlinking between data and the accompanying services, that allow the integration of data silos [
33], or establish data spaces through the use of linked data frameworks [
34,
35]. Several examples of joint data platforms demonstrate the benefits of sharing data collections, and support the transition from private to shared domains [
36,
37,
38,
39,
40]. A closer look at any of these platforms shows that in order to fulfill their mission they must deal with the technical management of distributed data infrastructures together with the accompanying organizational and legal issues. Lynn et al. [
41] and Grunzke et al. [
42] have shown that this can be achieved by focusing on the optimization of organizational and technical requirements, management of the existing infrastructure, training, and sustainability. Other matters that require consideration are the additional information required when organizations of different types exchange data, and lastly, the human factor [
43,
44,
45]. This latter aspect of data network systems is related to the development of competences and training, but is especially relevant since awareness creation, formation of a community, and the design and implementation of best practices, are of crucial importance for the success of current and future data exchange infrastructures [
45,
46].
The establishment of a fully functional data ecosystem across all Europe is being pursued by large initiatives like the European Open Science Cloud (EOSC), lead by the European Commission, and GAIA-X, lead by the industry. GAIA-X focuses more on the needs of companies, aiming to enable data sharing while allowing participants to retain data sovereignty [
47]; EOSC is conceived mainly for research institutions. In some specific sectors, for example, health and life sciences, domain-specific data ecosystems are under development [
38,
48]. However, top-down initiatives should go together with complementary bottom-up approaches to overcome the numerous challenges they face. National or regional infrastructures are necessary to develop use cases that then feed into the larger initiatives, following results that show that they significantly increase innovation output [
49].
3. Materials and Methods
We conducted an interview study including survey questions with regional stakeholders from various sectors and scientific domains about the current status and expected evolution of their ideal technical infrastructure.
3.1. Procedure & Analysis
The interviews were conducted online between February and July 2021 with a duration time between 30 and 70 min, using the Cisco Webex Meetings videoconferencing tool, and the resulting documents were saved on the Nextcloud server of TU Graz Data collection followed TU Graz’ data protection policies, and included informed consent information to document the interviews. The data extracted from the documents was anonymized, aggregated, and transformed into spreadsheets for further analysis. The interview template in German, a translated version of the questionnaire in English, as well as anonymized aggregated data can be found as
Supplementary Material. Interview documentation related to unfeasible anonymization cannot be made public. All data is stored under restricted access, available only to IDE@S project members, and will be deleted when the project ends in 2022.
The template for interviews was created by a project core team of three researchers and was validated by several steps: First, the survey was reviewed by three project-related researchers different from the core-team, to gain a user perspective and ensure that essential topical questions have been captured. Using this feedback, the questions were refined to ensure intelligibility and avoid redundancy. Two participants, from a NFPO and FPO respectively, were chosen for a test run and feedback session in order to enhance the comprehensibility and overall evaluation possibilities of the questionnaire, by introducing additional predefined answers and scoring options for further insights. All interviews were carried out by the same researcher from the project core team to ensure the same systematic entry and documentation of answers, and a second core team member attended three sessions chosen randomly to enable further control over the process. The open questions were recorded with permission from interviewees to allow for repeated listening to answers, so that their full content could be grasped and individual viewpoints well understood.
3.2. Questionnaire
The interviews were conducted according to a questionnaire, presented to the participants while notes were taken by the interviewer. The questionnaire was structured in the following sections: Information about the interviewee’s organization, introductory questions, and main questions (31 in total). The questionnaire covers different topics in data management and data science. First, aspects of technical resources and challenges are covered, followed by a survey of changes in technical infrastructure over the recent years. This leads to questions on changes in technical infrastructures planned for the next years, continued by questions on the topic of human resources for data management and data science. Some open questions are intended to get insights to the general data operation methods. Finally, there are questions on collaborative working schemes, as well as network integration.
3.3. Participants
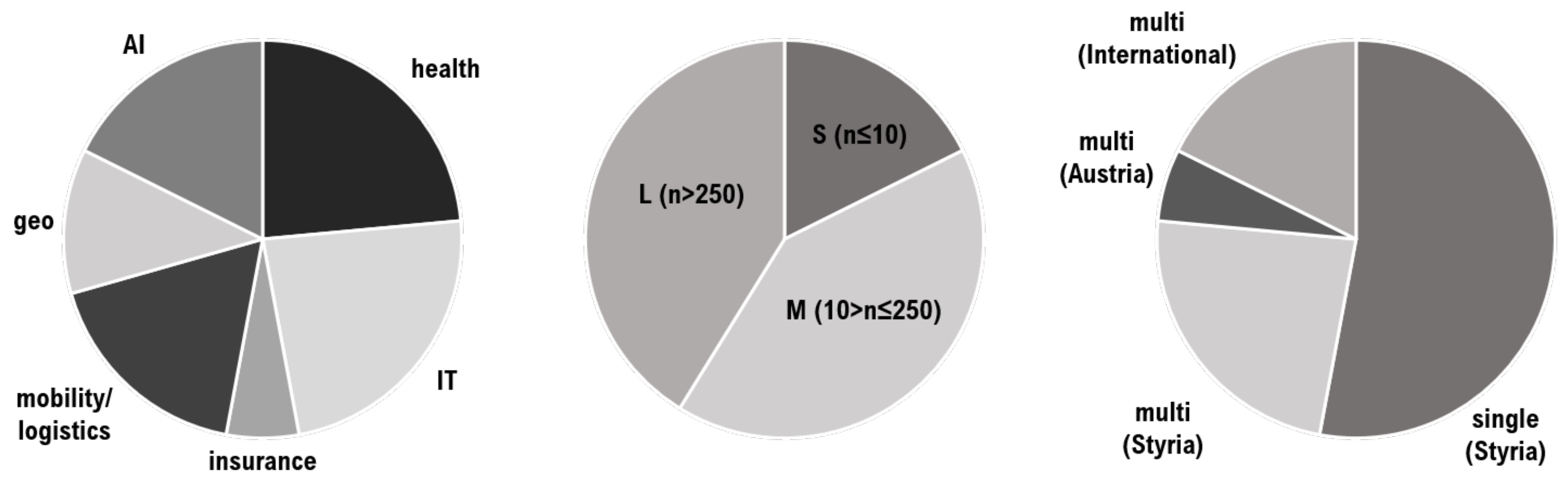
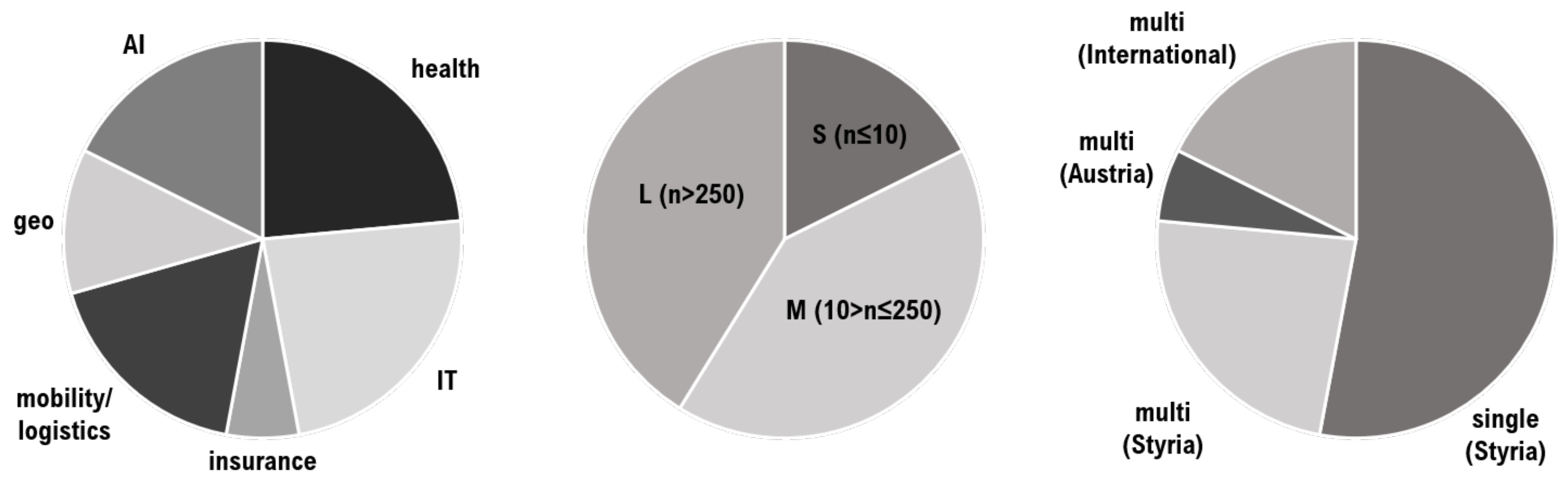
Interviews were carried out with respondents from
institutions, corresponding to 9 FPOs and 8 NFPOs. Several more potential Styrian stakeholders have been asked via mail or phone to be involved in the interview study; these 17 are the number of all respondents who positively answered the request to participate in the interview study. FPOs comprise private companies from several industrial sectors, while NFPOs include institutions from the public sector, with the exception of a third-party construct of private NFPO that was formerly a public institution. NFPOs can be further classified into academia (
out of 8), government, or department in public administration (
out of 8). Stakeholder characteristics from respondents are presented in
Figure 1. Participants come from several disciplines, grouped into Artificial Intelligence (AI), IT services and telecommunication, health, geosciences and geostatistics, mobility and logistics, and finance and insurance. All respondents hold leading positions or management responsibilities related to IT departments. The size of the organizations includes everything from start-ups and small working groups with up to 10 employees, small-to-medium enterprises (SMEs) between 11 and 250 employees, and large institutions with over 250 employees and up to the five-digit range.
4. Results
We investigated the toward data sharing, technical infrastructure requirements, practices, and expert knowledge (skills) on collaborative data use. Results on each of these aspects are presented as quantifiable results from survey responses and summarized answers from open questions thereafter. We processed the survey responses to extract information about (i) attitudes of stakeholders towards data sharing in general, (ii) understanding data-related tasks, (iii) requirements for technical infrastructure, (iv) standard practices, (v) necessary expert knowledge on collaborative data use, and (vi) the habits of stakeholders in Styria toward data reuse and exchange in NFPOs and FPOs.
First, the different positions on data sharing of stakeholders from the three classes considered (FPOs, PA, and academia) are presented in
Section 4.1.
Section 4.2 shows then that the different data handling practices cannot be mainly attributed to class- or domain-specific rules, but reflect decisions made by within each organization. Data infrastructure requirements and outsourcing practices are presented in
Section 4.3.
Additionally, for classification according to their public or private character, we found it useful to separate stakeholders by their domain or discipline of activity: The interviewees belonged to organizations working in AI and machine learning (ML), environmental and geosciences, health and life sciences, ICT production and IT services, finances and insurance, mobility and logistics, and smart factory. The results on domain-specific differences, shown in
Section 4.4, can be found foremost in best practices and standard protocols and tools. This section also contains best practices and general standards common to all disciplines.
4.1. Different Positions on the Value of Data and Data Sharing
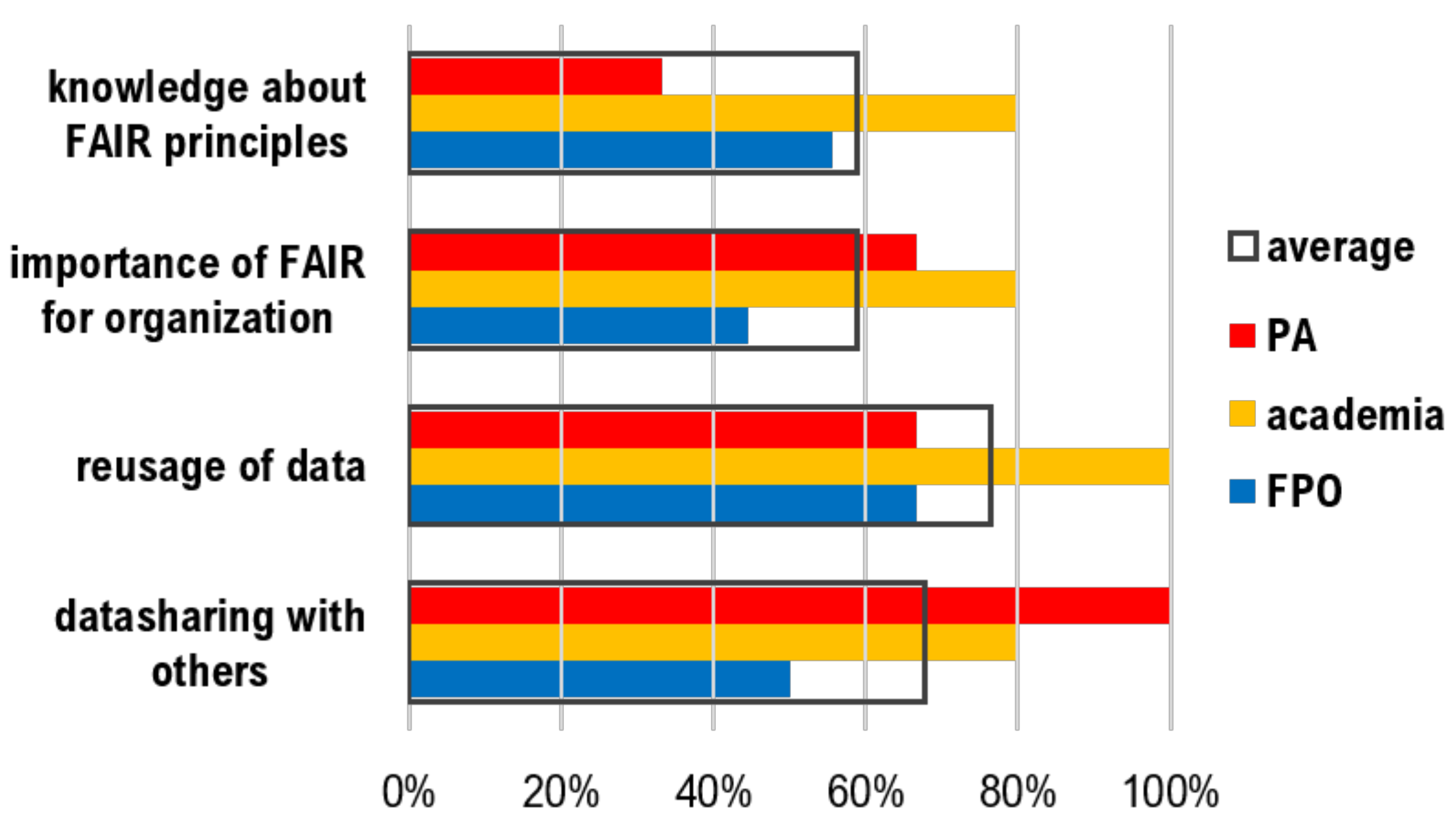
Figure 2 summarizes the knowledge about and attitude towards the guidelines to improve the Findability, Accessibility, Interoperability, and Reuse of digital assets (FAIR) among interviewees. Our first finding is that, according to the responses, FAIR principles are much more familiar among public organizations (including research and administration institutions) than private companies. Even after the FAIR principles were described to respondents from private business with low familiarity with them, most of them considered that they were not relevant to their organization. This might go back to the fact that in the public sector, data sharing is a common practice, while in the private sector, data predominantly uses data internally (i.e., only within each organization). While all sectors reuse data to a certain degree, the repeated exploitation of available resources happens much more frequently in public research organizations.
4.2. Data-Related Tasks Differing between Institutions Are Not Class- or Domain-Specific
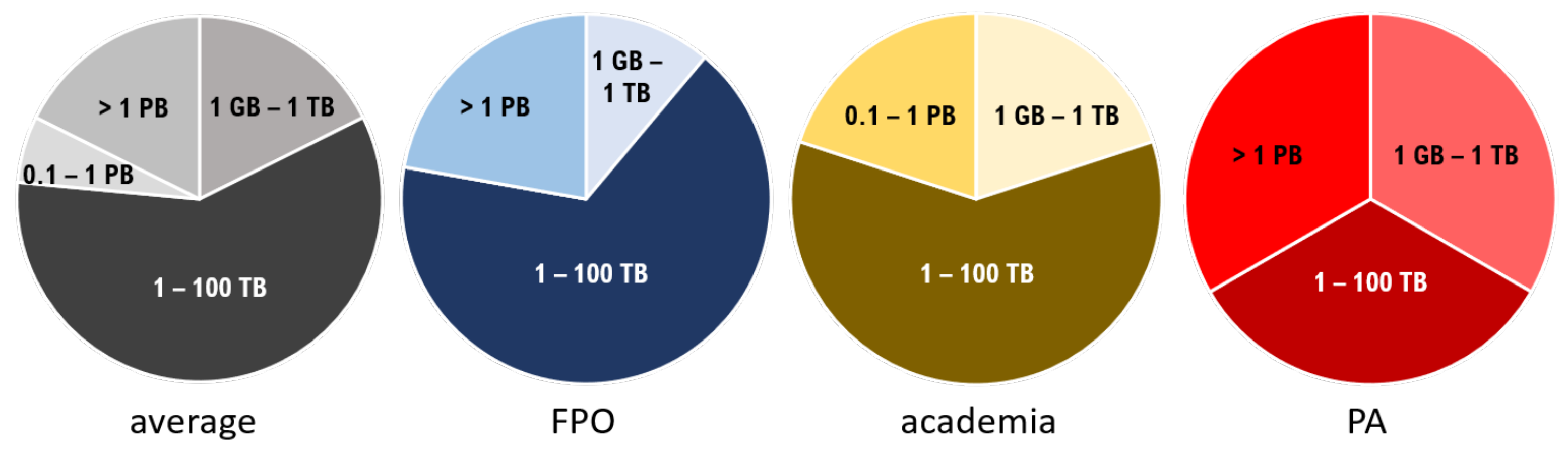
Participants were asked about their regular work routine related to data handling. Most institutions handle an average amount of data of between 1 to 100 terabytes (TB) per month, as shown in
Figure 3. Data handling includes time-consuming tasks of data management, generation, retrieval, storage, analysis, and other data manipulations. The different data-related tasks in the daily-work routine are presented in
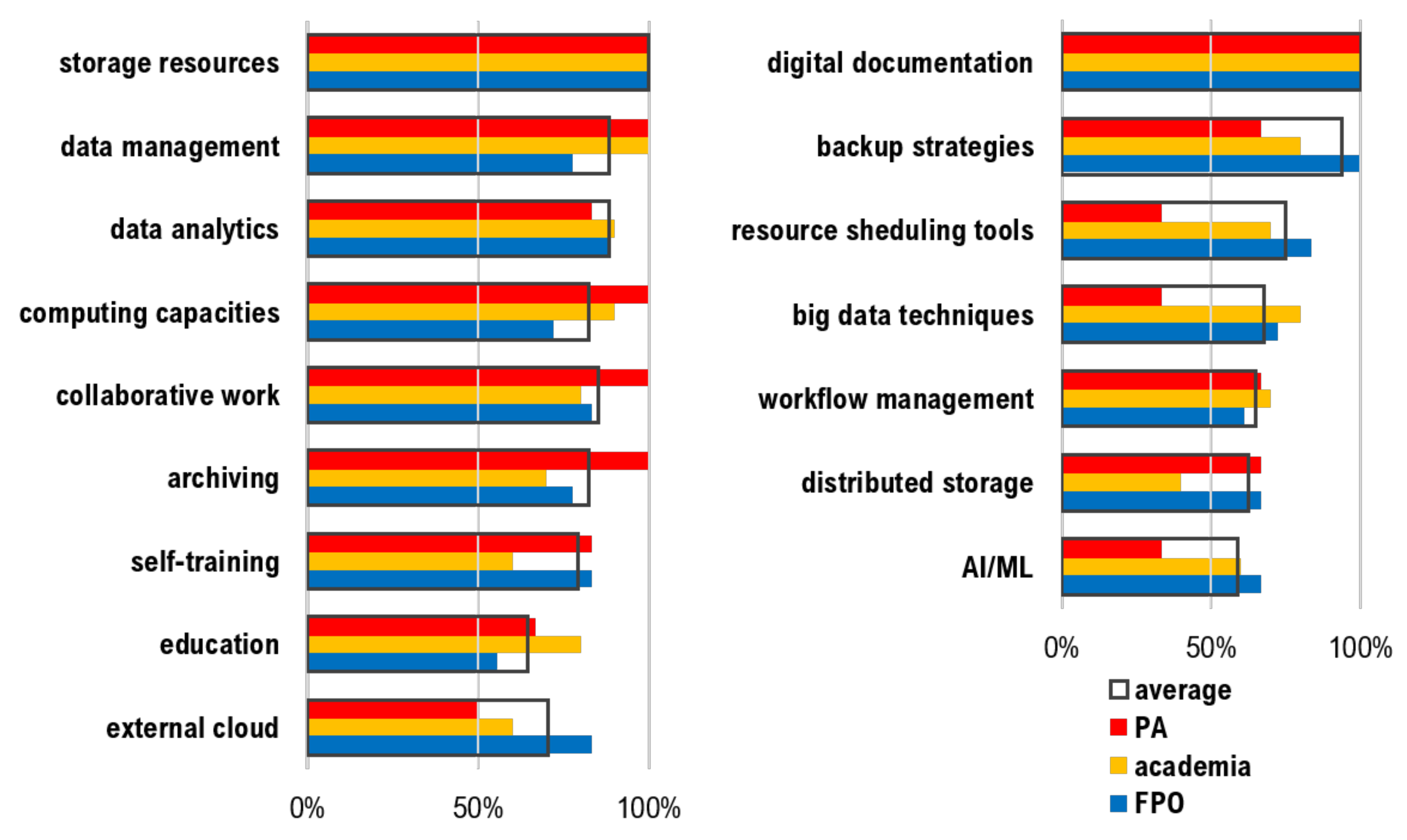
Figure 4 left and show that storage is common to all sectors, whereas the usage of external cloud resources is less widespread. Next to the daily work-routine, we asked for the general utilization of common data applications. In
Figure 4 right, we present the most common tools used for data management, using the options of the questionnaire. Digital documentation is a standard procedure in all organizations, while other tools such as resource scheduling, big data techniques, and AI and ML methods, which are frequently used in academia and FPOs, are less common in the public administration sector and are employed by slightly over half of all participants.
4.3. Need for Changes in Technical Infrastructure
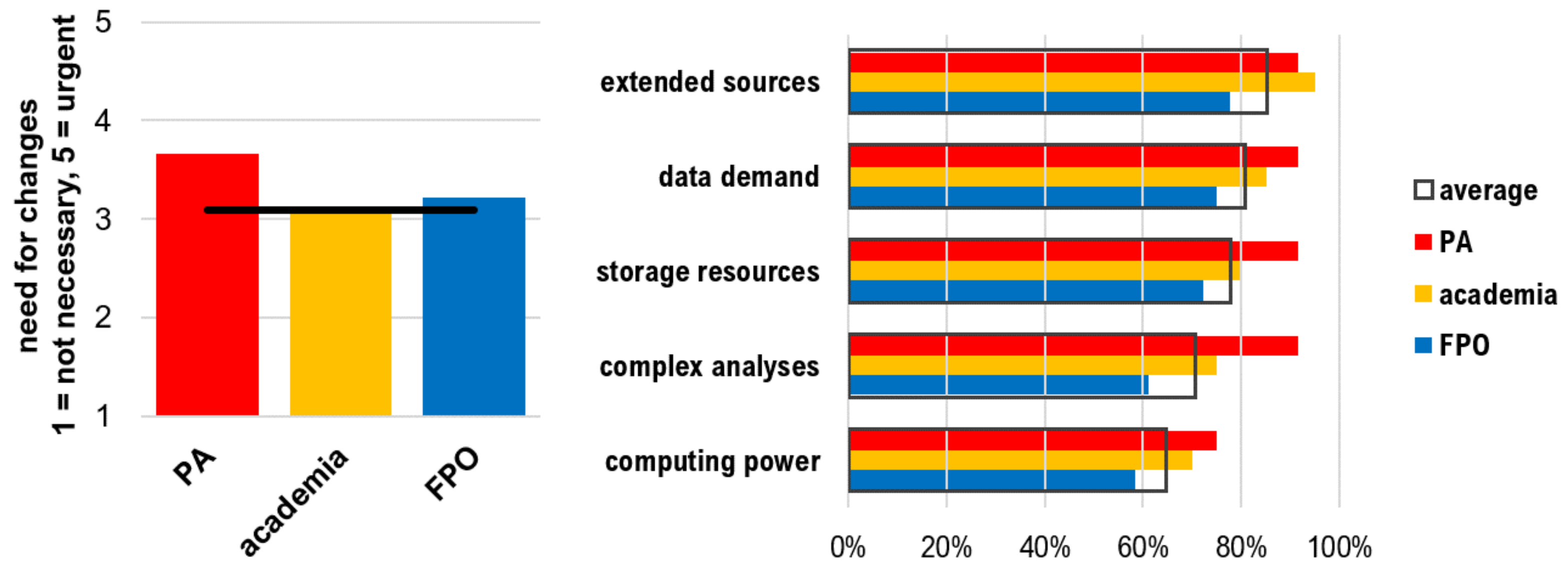
The time evolution of data infrastructure requirements follows similar trends across all organization types, with most respondents wishing to expand and update their technical infrastructure, though the urgency of such changes is different between private and public organizations, as can be seen in
Figure 5 left. Academic institutions seem to be the best equipped, and therefore express a lower pressure to upgrade their technical infrastructure, while government-related organizations in the public administration show a clear need of additional equipment and tools. The feedback on changes in data-related tasks presented in
Figure 5 right shows that the need to expand data sources is present in almost 90% of organizations, and the demand for data, which has an immediate effect on the need for additional storage, appears in over 85% of them. The increasing complexity of data analysis identified by around 80% of the interviewees is a clear indicator of the need for additional computing power (70%).
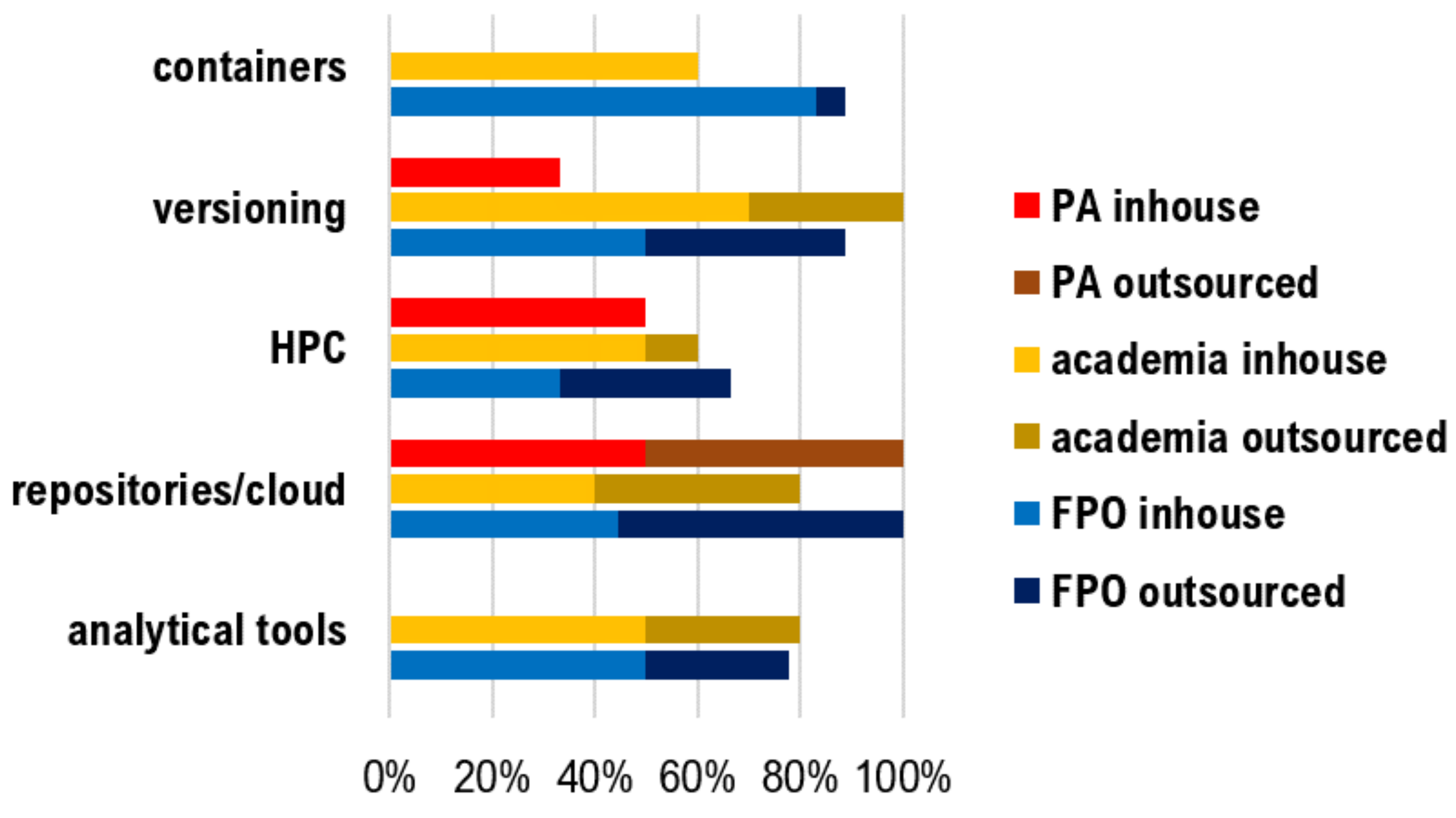
The acquisition of technical solutions over the last five years is summarized in
Figure 6. While most of the new equipment, tools and container solutions have been built or designed in-house, repositories and cloud services tend to be outsourced. Versioning systems, repositories and analytical tools, of primary interest to businesses and research organizations, are usually built in-house, but a considerable part of them are also outsourced. According to the responses from public administration, such types of organizations do not acquire any analytical tools or containers, but instead have designed versioning systems in-house. Only a small portion of high-performance computing (HPC) and repositories were outsourced.
4.4. Open Questions
Together with the closed questions already described, the questionnaire also contained open questions (i.e., allowing free text answers) about other changes needed in the data infrastructures related to their organization, like standards and interoperability, human resources, automation, storage, and computing power. This time the different fields of expertise of the interviewees were taken into account in the answers.
The questionnaire was designed to identify the daily work-routines and standard practices typical of the different domains (see
Figure 4 and
Section 4.2 above for domain-independent tasks). The important domain-independent (de facto) standards that came up during the conversations are listed in
Table 1, which also shows best practices and common procedures. The activities indicated include organizational matters related to information technology and management systems, security techniques, and recommended tools. Standards provide a defined instruction to practices. In some of the conversations on this topic, one standard noted by many participants was the list of requirements for information security management systems provided by the International Standards Organization (ISO). The Structured Query Language (SQL) standard introduced by the American National Standards Institute (ANSI) and its variations provided by Oracle [
50] and other database management systems were also mentioned. Other important standards noted frequently were the open source distributed version control system Git and SAP for electronic resource planing (ERP). Among the de facto standards, the proprietary Matlab and Simulink for model simulations in the industrial and academic engineering sector, and the well-known word and slide processing tools of the Microsoft suite were often mentioned. Next to extensible markup language (XML) as the standard for generalized markup language, Digital Imaging and Communications in Medicine (DICOM) has been indicated as the standard for information imaging.
Best practices refer to common procedures and processes established at institutions, particularly where there are not uniform domain community standards available. They include organizational practices as e.g., internal rules for documentation and life-cycle management or the introduction of a chief data officer (CDO) to units. Technical approaches comprise open source frameworks, interoperability development testing, the general application of virtual servers and firewalls, and specific applications, such as agile ML.
Regarding human resources in data science, one in every four of all interviewees (28 %) showed a level of satisfaction with the current situation, while nearly half of them (44%) expressed a need for additional resources, while others refused to comment on this issue. Currently, as presented in
Table 2, the training of employees in data science and data management, including related procedures and other administrative tasks, happens in most occasions through self-learning, complemented by introductory sessions from experienced staff. Another aspect that comes out in the responses is that people with a technical university degree are more likely to be employed to perform data-related tasks; however, the broad scope of areas touched by data science requires one to grasp concepts and know-how from several disciplines, including non-technical ones, and requires continuous training of staff.
Regarding previous and ongoing cooperative projects, respondents included partners from various fields of public administrative bureaus, consulting services, contract research, university or business partners, and industry-coupled research projects.
Among the most relevant qualitative factors that enable cooperation in data science mentioned in the responses, as shown in
Table 3, we can mention the existence of open data policies and common standards, the organization of a sufficient number of workshops where the benefits and structure of the exchange networks can be discussed, the integration with international channels and initiatives, and the creation of enough grants for the general public. Respondents also described the ideal circumstances that would ensure future collaboration, indicated in the table as “Requirements” and “Additional factors”. Automation was mentioned with regard to infrastructures for data exchange, management, and steps of analysis, as well as routine processes. Process automation can be achieved through technologies such as the Integrated Rule-Oriented Data System (iRODS), in which rules to automate data management tasks can be implemented by so-called “rule engines” [
51]. Cooperation is critical to the exchange of know-how and requires a certain degree of openness and ongoing data exchanges. Data sharing thereby comprises one-time exchange of data, and the need to reward data sharing by, for example, providing some service in return. Cooperation helps to create visibility of available data and possible project partners, but it also presupposes it.
5. Discussion
The goal of this study is to highlight the factors that facilitate the cooperative use of data and help understand the attitudes of Styrian stakeholders towards data exchange and cooperation. The main elements investigated include the technical requirements as well as specialized human resources and IT practices that are necessary for given data-related tasks. The wide variability observed in the responses from public institutions to questions on the use of data, sharing practices, and technical requirements, not seen in the private sector, suggested to subdivide the public group further into academia and PA. Three main messages can be extracted from the responses: Firstly, it strikes as evident that private and public institutions alike require the development of e-infrastructures for data capturing, processing, analysis, and storage to enable that enough data is shared; secondly, data management represents an essential task of the daily work-routine in all domains, but this does not necessarily imply the employment of big data and ML methods; and thirdly, the storage capacity needs frequent updating due to the fast growth of data volumes, and this requires well-thought data structuring and alternative approaches to develop cooperative thinking on data solutions. So far, the need for extended data infrastructures is managed differently among the various stakeholders, especially regarding service sourcing. Competitiveness notably present in private organizations makes this sector tend to a regular market analysis for strategic outsourcing [
52]. This can be observed e.g., in the use of container-based technology, which has recently become popular for flexible application management and deployment [
53]. Containers were mentioned particularly by respondents from private organizations and, in the public sector, by academia, but not by administration.
The readiness to reuse data implies that some sort of data exchange with another stakeholder is likely to take place. Our survey shows that the disposition to share data is very different across the range of disciplines and organizations to whom the interviewees belong, as well as between the private and public sector. Private companies point to two hindering factors to data exchange: First, companies harvest data for their exclusive use and thus keep a competitive advantage over current or potential business rivals, according to their ultimate goal of profit maximization. Second, the willingness to share data is lower when the benefits it can bring to the general public (i.e., the society) are not clear, or if they clash with the interests of a company. In the public sector, open data policies have already been applied, but they still need both top-down and bottom-up actions to be successfully implemented on a large scale. Such changes can take place in the private sector as well, especially if introduced first in small- and medium-sized enterprises, where they should be easier to implement than in large businesses. The big difference in the degree of and the attitude to data sharing in several disciplines has been shown before, and an enforced surveillance of data sharing has been suggested as counteraction [
54]. Data exchange can lower the barriers towards data sharing still placed by private and public organizations. It is one of the pillars on which the ongoing digital transformation relies, leading in many cases to new revenue sources and growth in an increasingly digital world. Digitization, especially when accompanied by (re)use of data, enables to automate calculations and analysis for planning and discovery, suggests future directions for research, and ultimately leads to an increase in the efficiency and quality of development.
The high frequency in which data-related tasks appear in survey responses shows that collaborative work is very important for private and public organizations, but especially for public administration, while big data techniques are predominantly used by academia and FPOs. The various applications and benefits of big data, including current open research directions based on management and manipulation of large data sets, draw the attention of organizations and researchers because of the potential delivery of insights that may be turned into added value. The possible uses of data do not end with data sharing, of course. For example, there have been increased efforts to share ML models in federated learning (FL) settings, consistent with the interest in use (and reuse) of data not only to extract knowledge, but also to be able to learn (i.e., make predictions) from them. In FL, ML algorithms are trained collaboratively across many clients (e.g., mobile phones), while the data remain decentralized, which is essential to preserve privacy in applications of ML technology [
55]. With the introduction of ML, data exchange moves to a more abstract level, since data here is not explicitly exchanged, but rather only used to enable collective learning. This satisfies the ultimate aim of working with data: To obtain added value from data from multiple owners. With data sets spread over several owners and locations, one can also profit from “transfer learning”, where a model is trained on one data set (i.e., from a specific data owner), to be then applied to data owned by others. The technique can be used in both supervised and unsupervised scenarios [
56]. This idea has been addressed by the European Commission in several funding calls and research initiatives, including studies to learn from multiple sets of proprietary data across numerous European stakeholders [
57].
In line with findings by the European Commission, who has identified interoperability frameworks as critical components for joint undertakings [
58], several responses from interviewees have highlighted interoperability as a requirement to foster data exchange and cooperation. In practice, this involves the introduction of standards and interoperability for both technical and data standards. Data standards that follow domain-specific formats and practices must be developed in collaboration with experts of the respective domains, whereas technical standards, which are related to the underlying technical requirements, need to be domain-agnostic. There have been recent approaches to develop metadata standards for multi-disciplinary data [
59], which would undoubtedly enhance data interoperability, but this remains a difficult task in most domains. A possible approach to the standardization of data exchange is shown by recent advances in medical informatics, where it has been possible to develop a standard that enables interoperability between healthcare systems [
60]. The format (named “Health Level 7 standard Fast Healthcare Interoperability Resources”, or “HL7 FHIR”) is modular and contains information on identity, metadata, human readable summaries, and standard data. In a European context, where very different languages are used simultaneously, such standards can provide both language-independent as well as language-specific layers to support data exchange.
Another essential factor that can determine whether collaborative data infrastructures are successful is the transfer of know-how among staff. As noted by respondents from all sectors, training in data science and for related tasks happens currently via self-learning in most cases. Due to the fast evolution in data science and e-infrastructures, continuous training and education will be necessary to create and keep the competences of staff at all types of institutions in this era. Here it is worth mentioning the digitization support to companies provided by the Digital Innovations Hubs (DIH) programme of the European Commission. There are currently around 400 fully operational DIHs in computing, digital twins, AI, and big data in the EU, as listed in the Joint Research Centre platform, with more expected to come in the second quarter of 2022 [
61,
62]. The role of DIHs is to organize networking events and workshops, and provide technological support for the exchange of know-how. They have become fundamental in connecting stakeholders with each other, and increasing the information flow on regional infrastructures. This is consistent with the idea that fostering collaboration depends on forging links, creating new contacts, and facilitating frequent information exchange.
In the long run, it is clear that one initiative alone will not be able to help overcome all challenges faced by research institutions and businesses in the digital age, and synergies between projects, platforms, and technological as well as organizational solutions are needed. Collaboration between individual projects will broaden and strengthen participation in large-scale initiatives.
6. Conclusions
Collaborative efforts that involve public and private entities facilitate innovation and are crucial to scientific progress and technological development. Data have emerged as the most important assets to realize collaborations. We therefore investigated factors influencing the collaborative use of data among various stakeholders from private, as for-profit organizations, and public institutions, that we further divided into academia and public administration. Results indicate that while there is a will from all stakeholders to engage in collaborative data spaces, the organizational changes and improvements required to reach the necessary standards that would make this possible still lie in the future. We have found that while both public and private entities could benefit from, and are interested in accessing data sources other than their own, existing and undiscovered synergies between isolated or fragmented systems still have to be exploited in order to achieve data interoperability and enable cooperation among institutions. The isolated factors influencing data collaborations have to be addressed individually and help to understand data-driven value creation. If the demands from different stakeholders can be properly addressed, it is possible to envision a future where data exchange across disciplines becomes a reality, with the potential of leading to true knowledge discovery. Our survey, performed within the project IDE@S in the Austrian federal state of Styria, presents a regional perspective that could be further translated to a wider context as applicable to other places. The regional aspect of this work represents a strength but also one limitation in regard to translating noted key points to a European level. Additionally, in order to highlight domain-specific issues, such as the different types of data used, future research is necessary on select individual use cases, or involving a much higher number of participants in similar studies. A large-scale survey could also give an overview of regional or national digitization progress, and furthermore, would allow for a statistical analysis of elementary factors influencing data collaboratives. Furthermore, future studies in the course of the IDE@S project will identify training gaps and highlight additional or supplementary courses and curricula that may need to be introduced for prospective joint data infrastructures. Additionally, investigating use cases will also allow one to understand the peculiarities of domain-specific data collaboratives.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}