
Machine Learning Applications to Identify Young Offenders Using Data from Cognitive Function Tests
 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
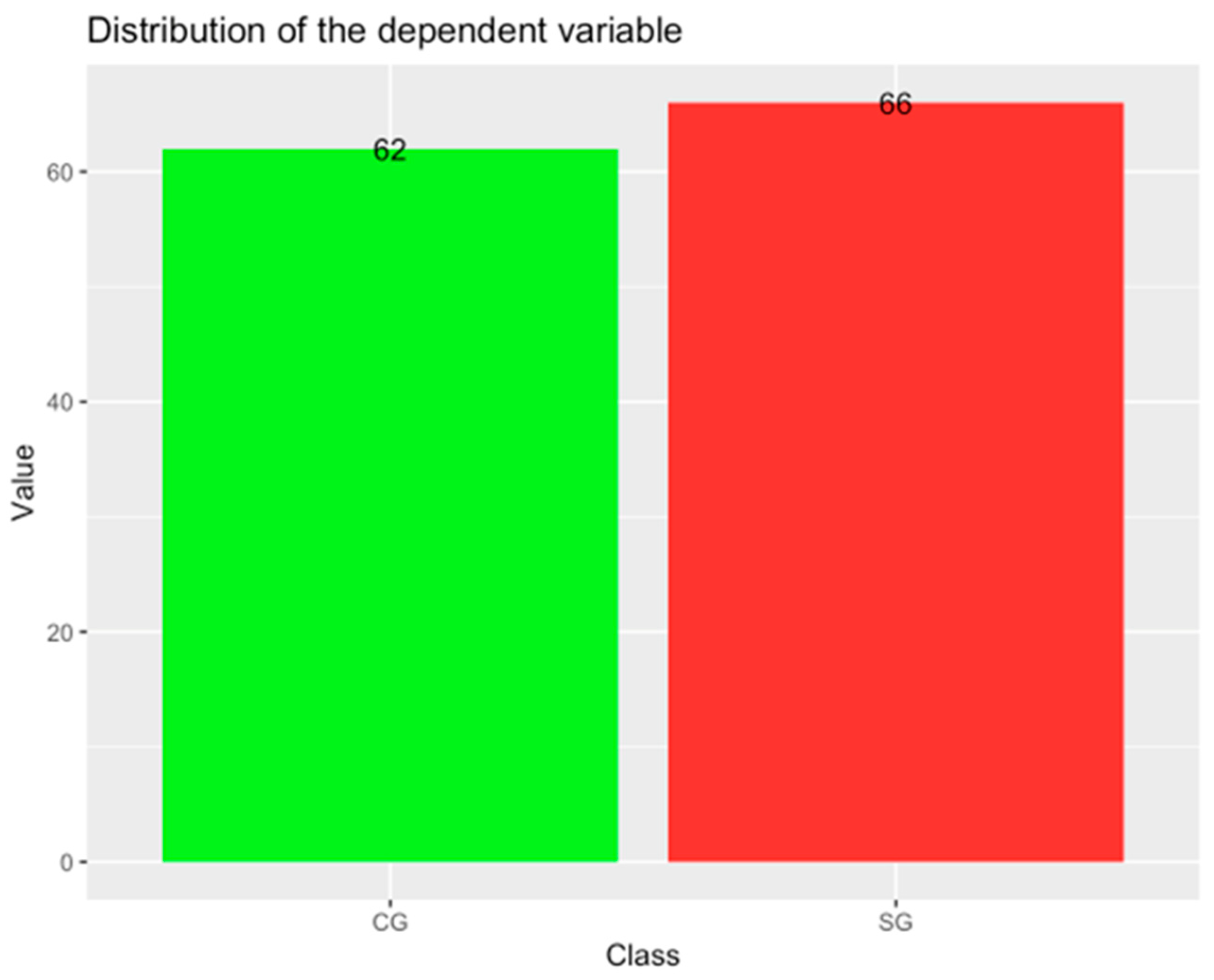
2.1. Dataset
2.2. Feature Selection
2.2.1. Features That Are Significantly Different among Groups
2.2.2. Boruta Algorithm
2.2.3. Recursive Feature Elimination (RFE) Algorithm
2.2.4. Filter Algorithm
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gil-Fenoy, M.J.; García-García, J.; Carmona-Samper, E.; Ortega-Campos, E. Antisocial Behavior and Executive Functions in Young Offenders. Rev. Psicodidact. 2018, 23, 70–76. [Google Scholar] [CrossRef]
- Pino, M.; Montaño, S.; Agudelo, K.; Idárraga, C.C.; Fernández, J.; Herrera, K. Emotion recognition in young male offenders and non-offenders. Physiol. Behav. 2019, 207, 73–75. [Google Scholar] [CrossRef]
- Santamaría-García, H.; Ibáñez, A.; Montaño, S.; García, A.M.; Patiño-Saenz, M.; Idarraga, C.; Pino, M.; Baez, S. Out of context, beyond the face: Neuroanatomical pathways of emotional face-body language integration in adolescent offenders. Front. Behav. Neurosci. 2019, 13, 34. [Google Scholar] [CrossRef] [PubMed]
- Voisin, D.R.; Sales, J.M.; Hong, J.S.; Jackson, J.M.; Rose, E.S.; DiClemente, R.J. Social Context and Problem Factors among Youth with Juvenile Justice Involvement Histories. Behav. Med. 2017, 43, 71–78. [Google Scholar] [CrossRef]
- Meijers, J.; Harte, J.M.; Meynen, G.; Cuijpers, P. Differences in executive functioning between violent and non-violent offenders. Psychol. Med. 2017, 47, 1784–1793. [Google Scholar] [CrossRef]
- Morgan, A.B.; Lilienfeld, S.O. A meta-analytic review of the relation between antisocial behavior and neuropsychological measures of executive function. Clin. Psychol. Rev. 2000, 20, 113–136. [Google Scholar] [CrossRef]
- Chitsabesan, P.; Bailey, S.; Williams, R.; Kroll, L.; Kenning, C.; Talbot, L. Learning disabilities and educational needs of juvenile offenders. J. Child. Serv. 2007, 2, 4–17. [Google Scholar] [CrossRef]
- Rodgers, D.B.; Reed, D.K.; Houchins, D.E.; Aloe, A.M. The writing abilities of juvenile justice youths: A confirmatory factor analysis. J. Educ. Res. 2020, 113, 438–451. [Google Scholar] [CrossRef]
- Borrani, J.; Frías, M.; Alemán, B.; García, A.; Ramírez, C.; Valdez, P. Neuropsychological disorders in juvenile delinquents. Rev. Mex. Neurocienc. 2019, 20, 244–252. [Google Scholar] [CrossRef]
- Muscatello, M.R.A.; Scimeca, G.; Pandolfo, G.; Micò, U.; Romeo, V.M.; Mallamace, D.; Mento, C.; Zoccali, R.; Bruno, A. Executive functions and basic symptoms in adolescent antisocial behavior: A cross-sectional study on an italian sample of late-onset offenders. Compr. Psychiatry 2014, 55, 631–638. [Google Scholar] [CrossRef] [PubMed]
- Na, C. Within-individual effects of dropping out of school on violent victimization among serious adolescent offenders. J. Interpers. Violence 2022, 37, NP20259–NP20287. [Google Scholar] [CrossRef]
- Eitle, D.; Turner, R.J. Exposure to Community Violence and Young Adult Crime: The Effects of Witnessing Violence, Traumatic Victimization, and Other Stressful Life Events. J. Res. Crime Delinq. 2002, 39, 214–237. [Google Scholar] [CrossRef]
- Masho, S.W.; Schoeny, M.E.; Webster, D.; Sigel, E. Outcomes, Data, and Indicators of Violence at the Community Level. J. Prim. Prev. 2016, 37, 121–139. [Google Scholar] [CrossRef]
- Voith, L.; Salas, M.; Sorensen, A.; Thomas, T.J.; Coulton, C.; Barksdale, E. Identifying Risk Factors and Advancing Services for Violently Injured Low-Income Black Youth. J. Racial Ethn. Health Disparities 2022, 10, 1809–1822. [Google Scholar] [CrossRef]
- Douglas, T.; Pugh, J.; Singh, I.; Savulescu, J.; Fazel, S. Risk assessment tools in criminal justice and forensic psychiatry: The need for better data. Eur. Psychiatry 2017, 42, 134–137. [Google Scholar] [CrossRef]
- Rolin, S.A.; Bareis, N.; Bradford, J.M.; Rotter, M.; Rosenfeld, B.; Pauselli, L.; Compton, M.T.; Stroup, T.S.; Appelbaum, P.S.; Dixon, L.B. Violence Risk Assessment for Young Adults Receiving Treatment for Early Psychosis. Int. J. Law Psychiatry 2021, 76, 101701. [Google Scholar] [CrossRef]
- De Vogel, V.; De Beuf, T.; Shepherd, S.; Schneider, R.D. Violence Risk Assessment with the HCR-20V3 in Legal Contexts: A Critical Reflection. J. Personal. Assess. 2022, 104, 252–264. [Google Scholar] [CrossRef]
- Barzman, D.; Ni, Y.; Griffey, M.; Bachtel, A.; Lin, K.; Jackson, H.; Sorter, M.; DelBello, M. Automated Risk Assessment for School Violence: A Pilot Study. Psychiatr. Q. 2018, 89, 817–828. [Google Scholar] [CrossRef] [PubMed]
- Singh, J.P.; Desmarais, S.L.; Hurducas, C.; Arbach-lucioni, K.; Condemarin, C.; Dean, K.; Doyle, M.; Folino, J.O.; Godoy-cervera, V.; Grann, M.; et al. International Perspectives on the Practical Application of Violence Risk Assessment: A Global Survey of 44 Countries. Int. J. Forensic Ment. Health 2014, 13, 193–206. [Google Scholar] [CrossRef]
- Tortora, L.; Meynen, G.; Bijlsma, J.; Tronci, E.; Ferracuti, S. Neuroprediction and A.I. in Forensic Psychiatry and Criminal Justice: A Neurolaw Perspective. Front. Psychol. 2020, 11, 220. [Google Scholar] [CrossRef] [PubMed]
- Coid, J.; Mickey, N.; Kahtan, N.; Zhang, T.; Yang, M. Patients discharged from medium secure forensic psychiatry services: Reconvictions and risk factors. Br. J. Psychiatry 2007, 190, 223–229. [Google Scholar] [CrossRef]
- Watts, D.; Cardoso, T.D.A.; Librenza-garcia, D.; Ballester, P.; Passos, I.C. Predicting criminal and violent outcomes in psychiatry: A meta-analysis of diagnostic accuracy. Transl. Psychiatry 2022, 12, 470. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, L.A.; Lau, S.; Kirchebner, J. Advantages of Machine Learning in Forensic Psychiatric Research—Uncovering the Complexities of Aggressive Behavior in Schizophrenia. Appl. Sci. 2022, 12, 819. [Google Scholar] [CrossRef]
- Cockerill, R.G. Ethics implications of the use of artificial intelligence in violence risk assessment. J. Am. Acad. Psychiatry Law 2020, 48, 345–349. [Google Scholar] [CrossRef] [PubMed]
- Trinhammer, M.L.; Merrild, A.C.H.; Lotz, J.F.; Makransky, G. Predicting crime during or after psychiatric care: Evaluating machine learning for risk assessment using the Danish patient registries. J. Psychiatr. Res. 2022, 152, 194–200. [Google Scholar] [CrossRef]
- Watts, D.; Mamak, M.; Moulden, H.; Upfold, C.; De Azevedo Cardoso, T.; Kapczinski, F.; Chaimowitz, G. The HARM models: Predicting longitudinal physical aggression in patients with schizophrenia at an individual level. J. Psychiatr. Res. 2023, 161, 91–98. [Google Scholar] [CrossRef] [PubMed]
- Watts, D.; Moulden, H.; Mamak, M.; Upfold, C.; Chaimowitz, G. Predicting offenses among individuals with psychiatric disorders—A machine learning approach. J. Psychiatr. Res. 2021, 138, 146–154. [Google Scholar] [CrossRef]
- Günther, M.P.; Kirchebner, J.; Lau, S. Identifying Direct Coercion in a High Risk Subgroup of Offender Patients with Schizophrenia via Machine Learning Algorithms. Front. Psychiatry 2020, 11, 415. [Google Scholar] [CrossRef]
- Kirchebner, J.; Lau, S.; Machetanz, L. Offenders and non-offenders with schizophrenia spectrum disorders: Do they really differ in known risk factors for aggression? Front. Psychiatry 2023, 14, 1145644. [Google Scholar] [CrossRef]
- Koppe, G.; Meyer-Lindenberg, A.; Durstewitz, D. Deep learning for small and big data in psychiatry. Neuropsychopharmacology 2021, 46, 176–190. [Google Scholar] [CrossRef]
- Menger, V.; Spruit, M.; Van Est, R.; Nap, E.; Scheepers, F. Machine Learning Approach to Inpatient Violence Risk Assessment Using Routinely Collected Clinical Notes in Electronic Health Records. JAMA Netw. Open. Open 2019, 2, e196709. [Google Scholar] [CrossRef] [PubMed]
- Parmigiani, G.; Barchielli, B.; Casale, S.; Mancini, T.; Ferracuti, S. The impact of machine learning in predicting risk of violence: A systematic review. Front. Psychiatry 2022, 13, 1015914. [Google Scholar] [CrossRef]
- Sonnweber, M.; Kirchebner, J.; Philipp, M.; Kappes, J.R.; Lau, S. Exploring substance use as rule-violating behaviour during inpatient treatment of offender patientes with schizophrenia. Crim. Behav. Ment. Health 2022, 32, 255–266. [Google Scholar] [CrossRef] [PubMed]
- Salman, S.A.; Dheyab, S.A.; Salih, Q.M.; Hammood, W.A. Parallel Machine Learning Algorithms. Mesopotamian J. BigData 2023, 2023, 12–15. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cognitive Tests | Features |
|---|---|
| Osterrieth Complex Figure | Copying |
| Short-term memory | |
| Long-term memory | |
| INECO Frontal Screening (IFS) | Motor programming |
| Interference resistance | |
| Motor inhibitory control | |
| Verbal inhibitory control | |
| Verbal working memory | |
| Numerical working memory | |
| Visual working memory | |
| Abstraction capacity | |
| IFS total | |
| Montreal Cognitive Assessment (MOCA) | Executive visuospatial |
| Identification | |
| Memory | |
| Attention | |
| Language | |
| Abstraction | |
| Orientation | |
| MOCA Total | |
| STROOP | Word |
| Color | |
| Word-color | |
| VFT (Verbal Fluency Test) | Phonological fluency success |
| Phonological fluency repetitions | |
| Phonological fluency distortions | |
| Semantic fluency success | |
| Semantic fluency repetitions | |
| Semantic fluency distortions | |
| Exclusive fluency success | |
| Exclusive fluency repetitions | |
| Exclusive fluency distortions | |
| WAIS (Wechsler Adult Intelligence Scale) | Matrices |
| Similarities | |
| Vocabulary | |
| SDMT (Symbol Digit Modalities Test) | Total correct answers |
| Total answers |
| Cognitive Tests | Features | Ranking |
|---|---|---|
| Osterrieth Complex Figure | Copying | 4 |
| Short-term memory | 7 | |
| Long-term memory | 9 | |
| INECO Frontal Screening (IFS) | Verbal inhibitory control | 3 |
| Visual working memory | 13 | |
| IFS total | 1 | |
| Montreal Cognitive Assessment (MOCA) | Abstraction | 5 |
| MOCA total | 12 | |
| VFT (Verbal Fluency Test) | Semantic fluency repetitions | 11 |
| Exclusive fluency success | 14 | |
| WAIS (Wechsler Adult Intelligence Scale) | Matrices_Total | 2 |
| Similarities_Total | 10 | |
| SDMT (Symbol Digit Modalities Test) | Total correct answers | 8 |
| Total answers | 6 |
| Features Selected by | ||||||
|---|---|---|---|---|---|---|
| Model | Metric | All Features | Levene Test | Boruta | RFE | Filter |
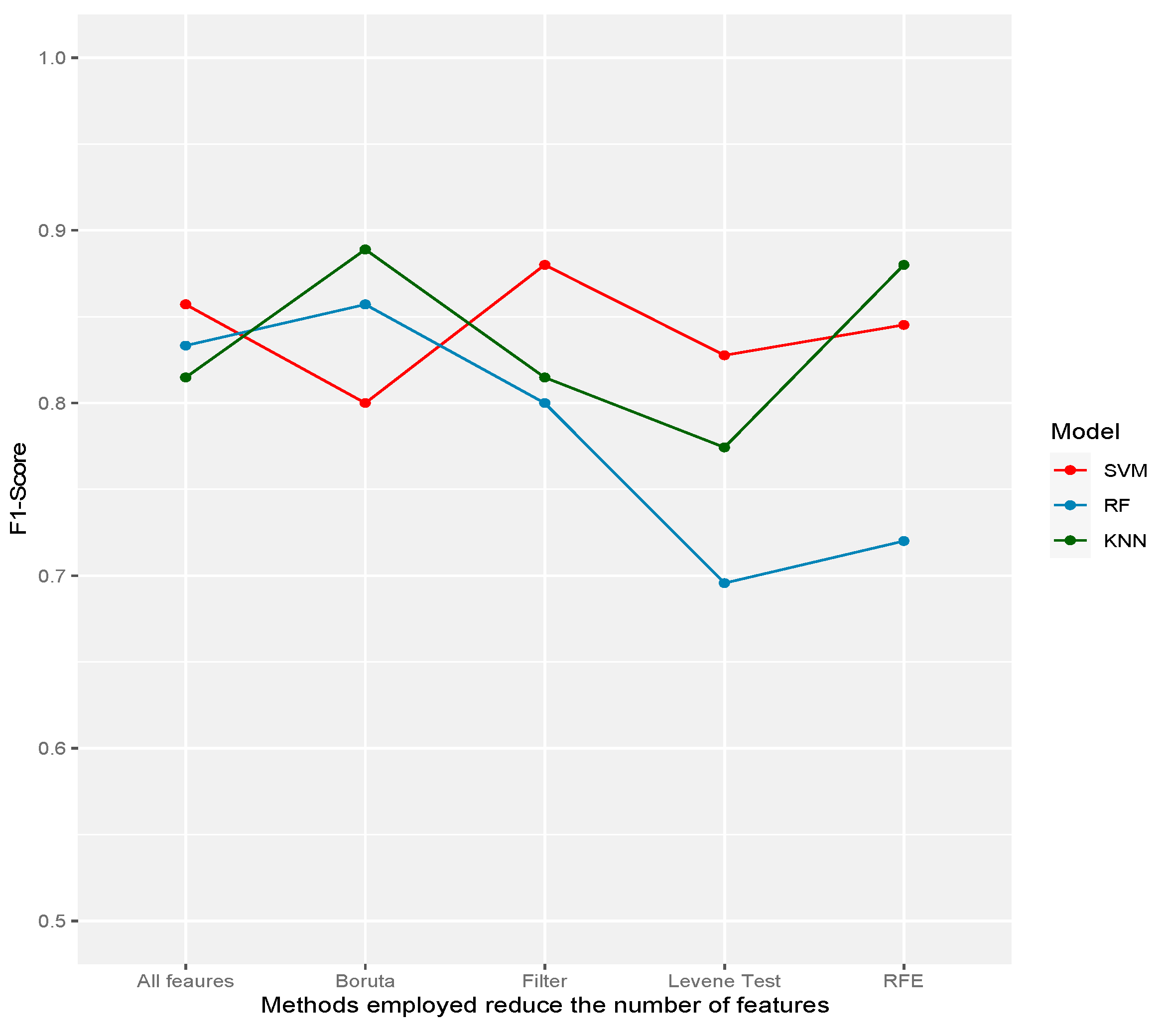
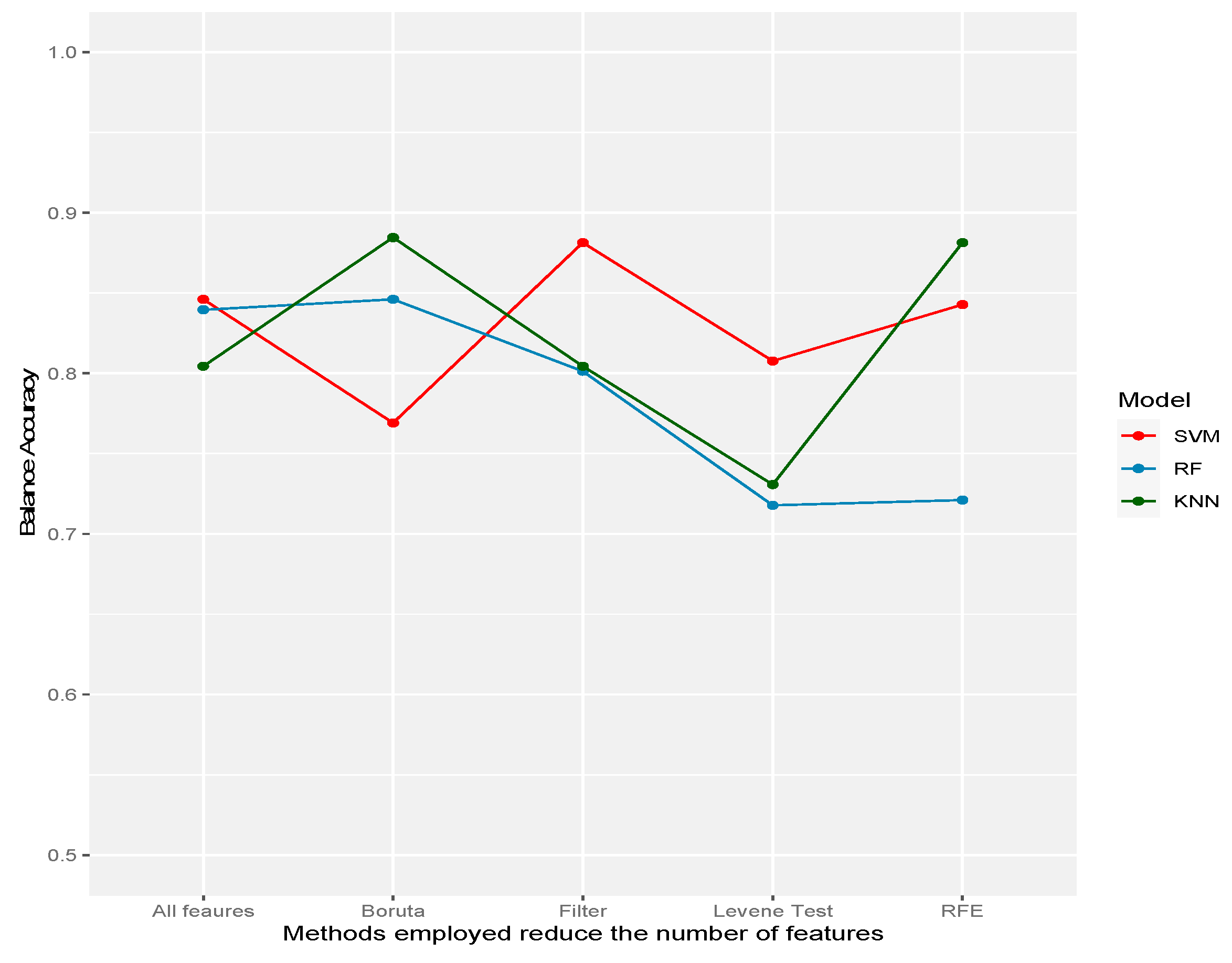
| Sensitivity/recall | 1.0000 | 1.0000 | 1.0000 | 0.9167 | 0.9167 | |
| SVM | Specificity | 0.6923 | 0.6154 | 0.5385 | 0.7692 | 0.8462 |
| F1 | 0.8571 | 0.8276 | 0.8000 | 0.8452 | 0.8800 | |
| Balance accuracy | 0.8462 | 0.8077 | 0.7692 | 0.8429 | 0.8814 | |
| Sensitivity/recall | 0.8333 | 0.6667 | 1.0000 | 0.7500 | 0.8333 | |
| RF | Specificity | 0.8462 | 0.7692 | 0.6923 | 0.6923 | 0.7692 |
| F1 | 0.8333 | 0.6957 | 0.8571 | 0.7200 | 0.8000 | |
| Balance accuracy | 0.8397 | 0.7179 | 0.8462 | 0.7212 | 0.8013 | |
| Sensitivity/recall | 0.9167 | 1.0000 | 1.0000 | 0.9167 | 0.9167 | |
| KNN | Specificity | 0.6923 | 0.4615 | 0.7692 | 0.8462 | 0.6923 |
| F1 | 0.8148 | 0.7742 | 0.8889 | 0.8800 | 0.8148 | |
| Balance accuracy | 0.8045 | 0.7308 | 0.8846 | 0.8814 | 0.8045 | |
| Cognitive Tests | Features |
|---|---|
| Osterrieth Complex Figure | Copying |
| Short-term memory | |
| Long-term memory | |
| INECO Frontal Screening (IFS) | Verbal inhibitory control |
| IFS total | |
| Montreal Cognitive Assessment (MOCA) | Abstraction |
| MOCA total | |
| VFT (Verbal Fluency Test) | Semantic fluency repetitions |
| Cognitive Tests | Features |
|---|---|
| Osterrieth Complex Figure | Copying |
| Short-term memory | |
| Long-term memory | |
| INECO Frontal Screening (IFS) | Verbal inhibitory control |
| Visual working memory | |
| IFS total | |
| Montreal Cognitive Assessment (MOCA) | Abstraction |
| MOCA total | |
| VFT (Verbal Fluency Test) | Semantic fluency repetitions |
| Exclusive fluency success | |
| WAIS (Wechsler Adult Intelligence Scale) | Matrices |
| Similarities | |
| SDMT (Symbol Digit Modalities Test) | Total correct answers |
| Total answers |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonfante, M.C.; Montes, J.C.; Pino, M.; Ruiz, R.; González, G. Machine Learning Applications to Identify Young Offenders Using Data from Cognitive Function Tests. Data 2023, 8, 174. https://doi.org/10.3390/data8120174
Bonfante MC, Montes JC, Pino M, Ruiz R, González G. Machine Learning Applications to Identify Young Offenders Using Data from Cognitive Function Tests. Data. 2023; 8(12):174. https://doi.org/10.3390/data8120174
Chicago/Turabian StyleBonfante, María Claudia, Juan Contreras Montes, Mariana Pino, Ronald Ruiz, and Gabriel González. 2023. "Machine Learning Applications to Identify Young Offenders Using Data from Cognitive Function Tests" Data 8, no. 12: 174. https://doi.org/10.3390/data8120174
APA StyleBonfante, M. C., Montes, J. C., Pino, M., Ruiz, R., & González, G. (2023). Machine Learning Applications to Identify Young Offenders Using Data from Cognitive Function Tests. Data, 8(12), 174. https://doi.org/10.3390/data8120174