

Federated Learning for Data Analytics in Education
 , , , and
, , , and
Abstract
:1. Introduction
Our Proposal and Related Works
2. Methods
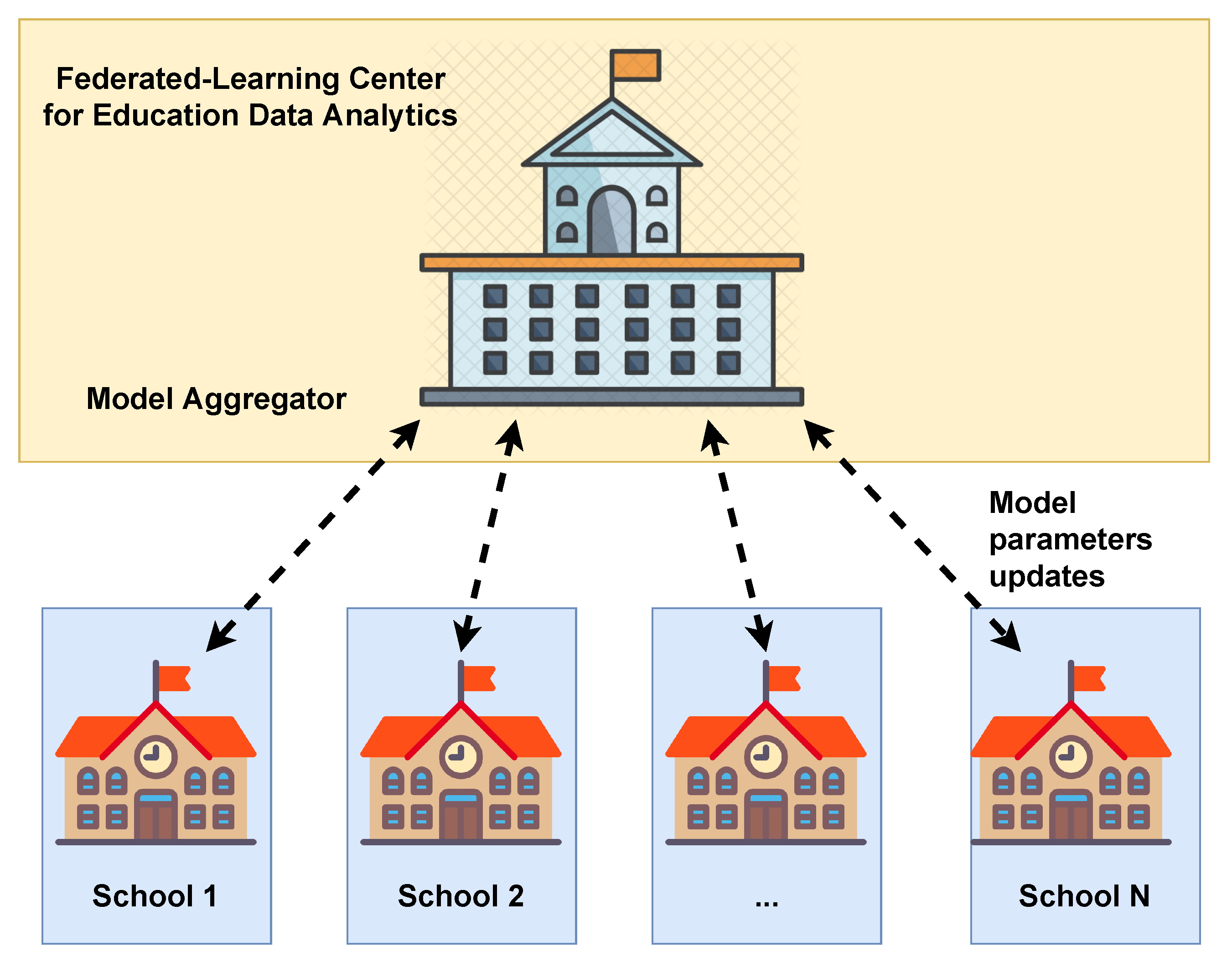
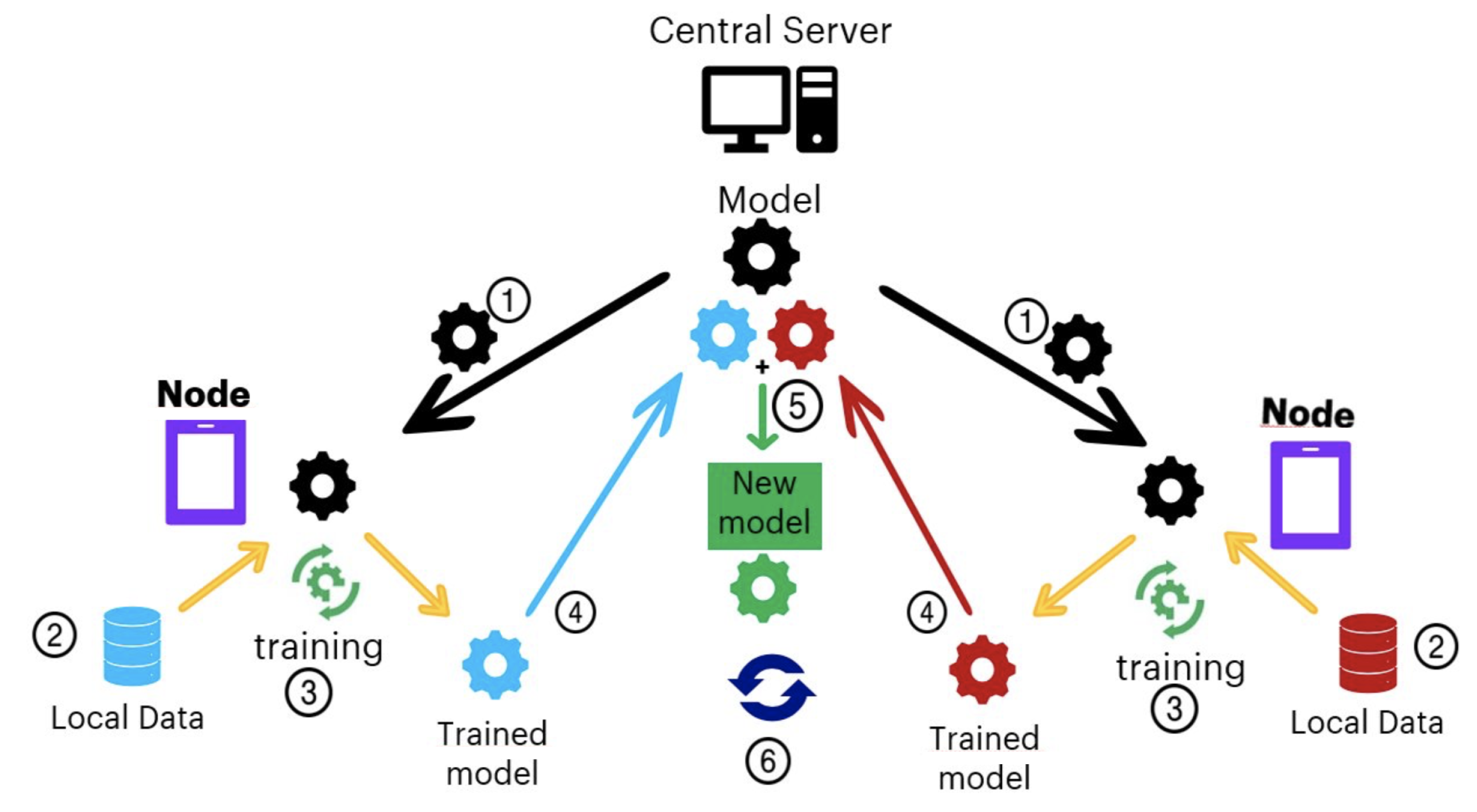
2.1. Main Concepts of Federated Learning
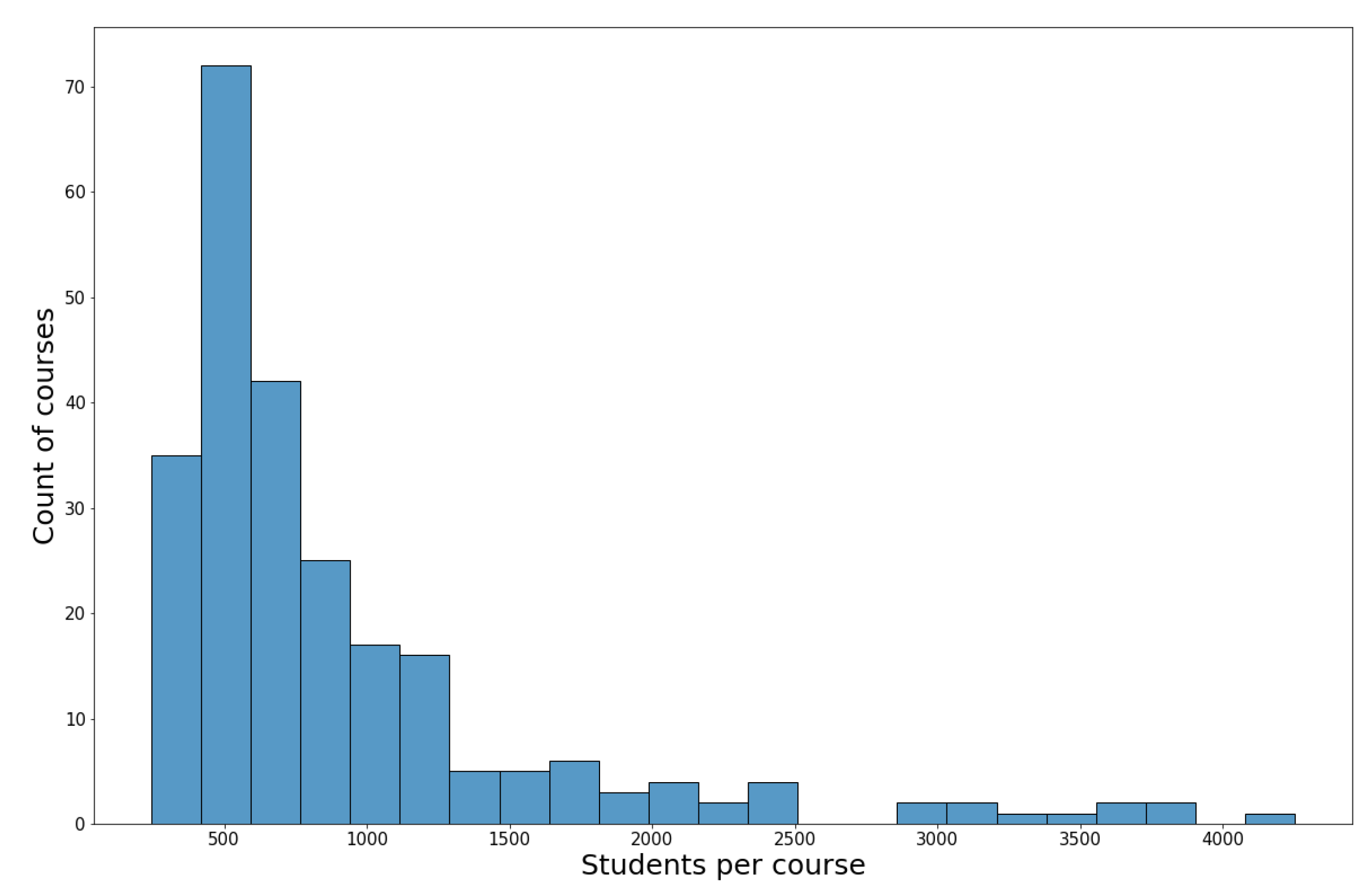
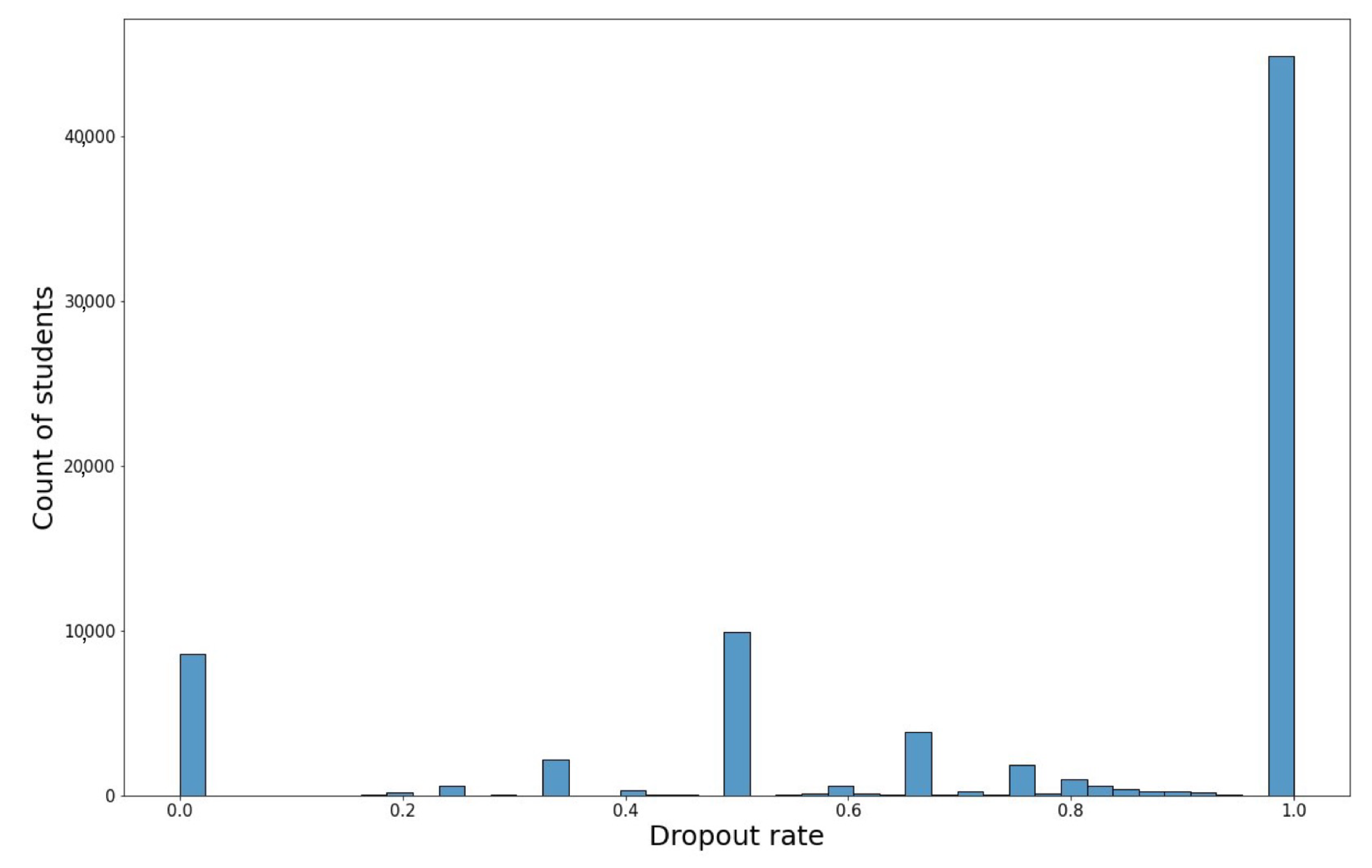
2.2. Dataset Description and Pre-Processing
2.3. Network Architecture
3. Experimental Results
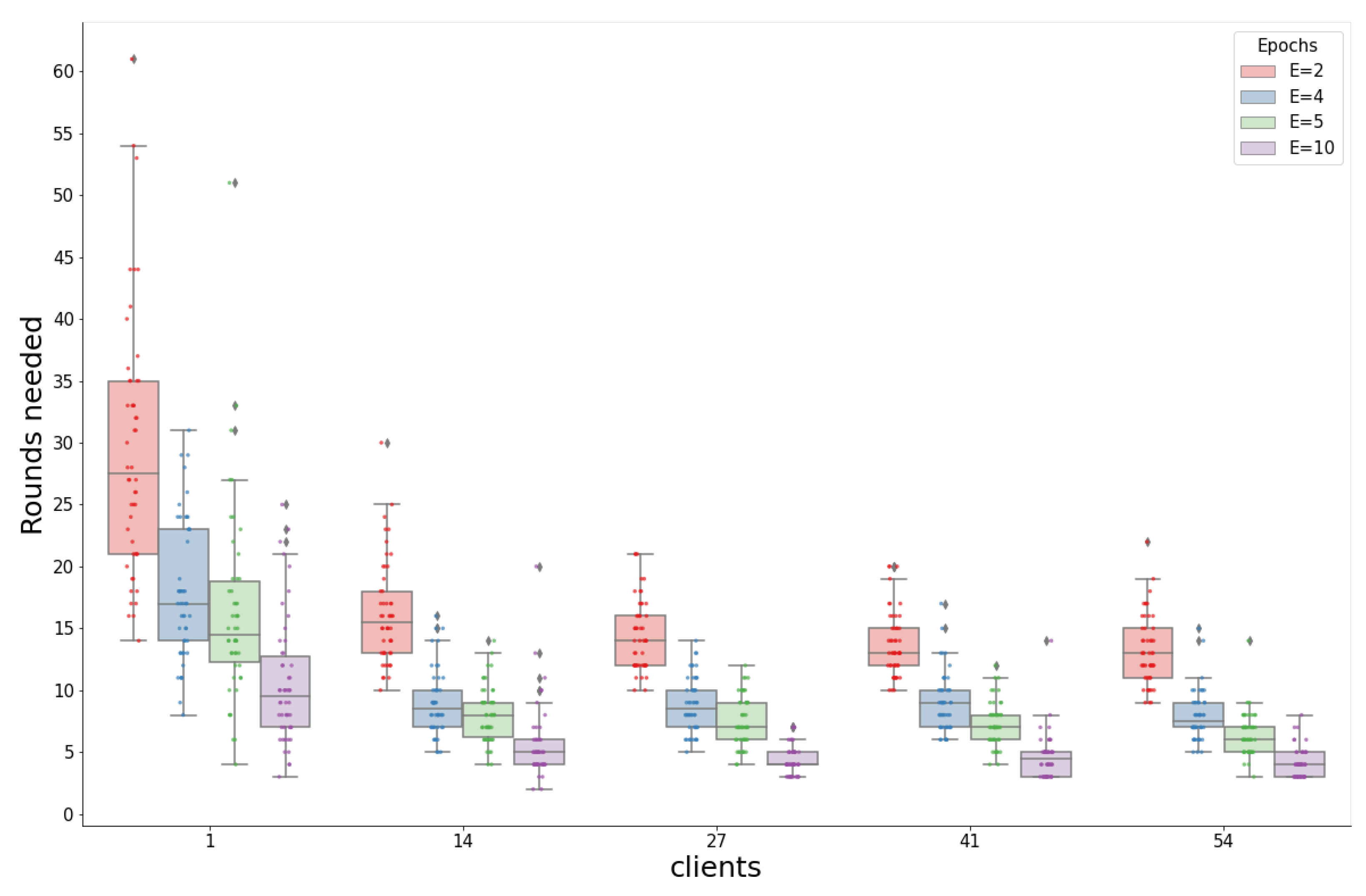
3.1. Federated Learning Parameters
3.1.1. Experiment
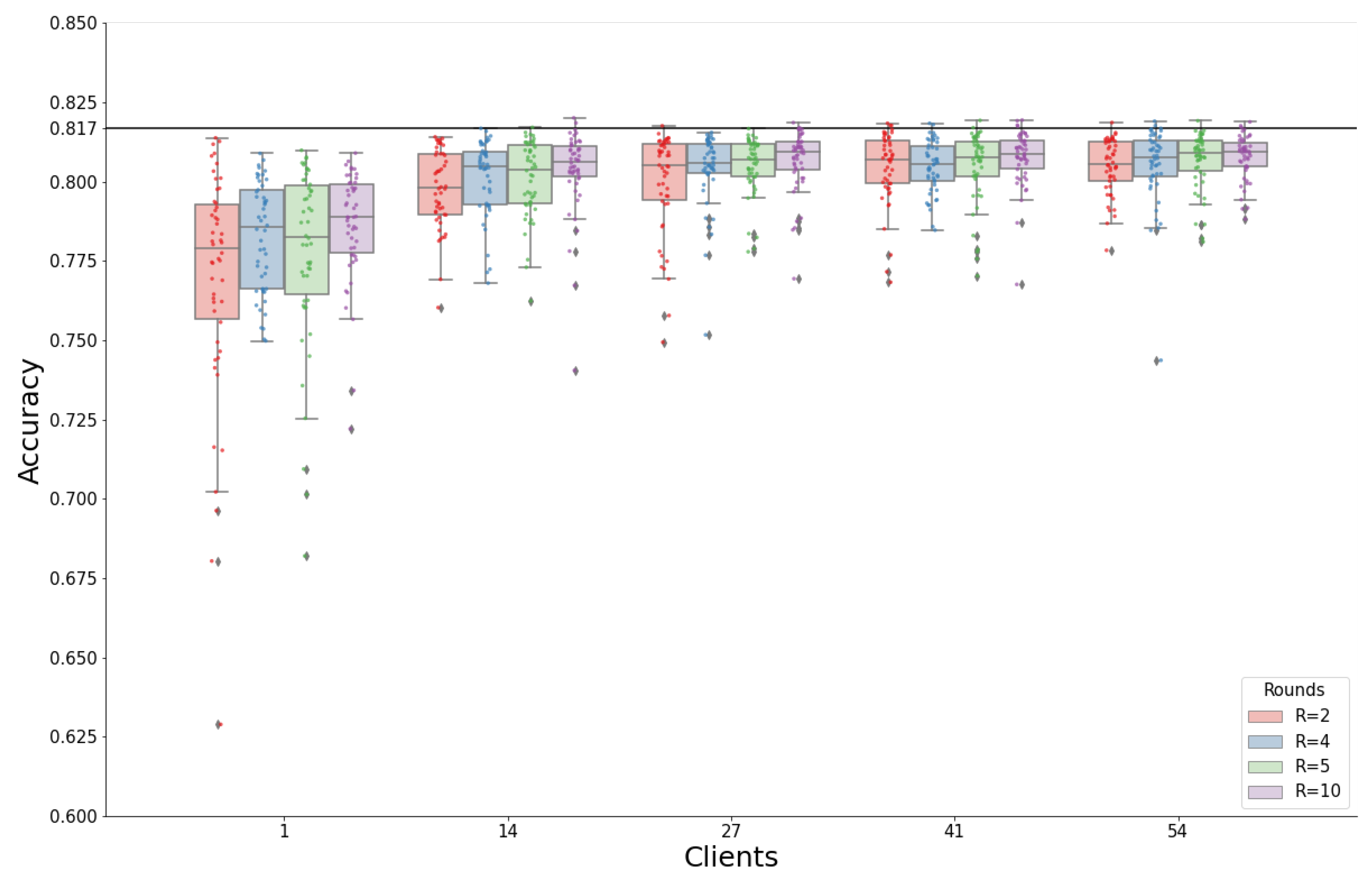
3.1.2. Results
3.2. Further Tuning of the Federation
3.2.1. Experiment
3.2.2. Results
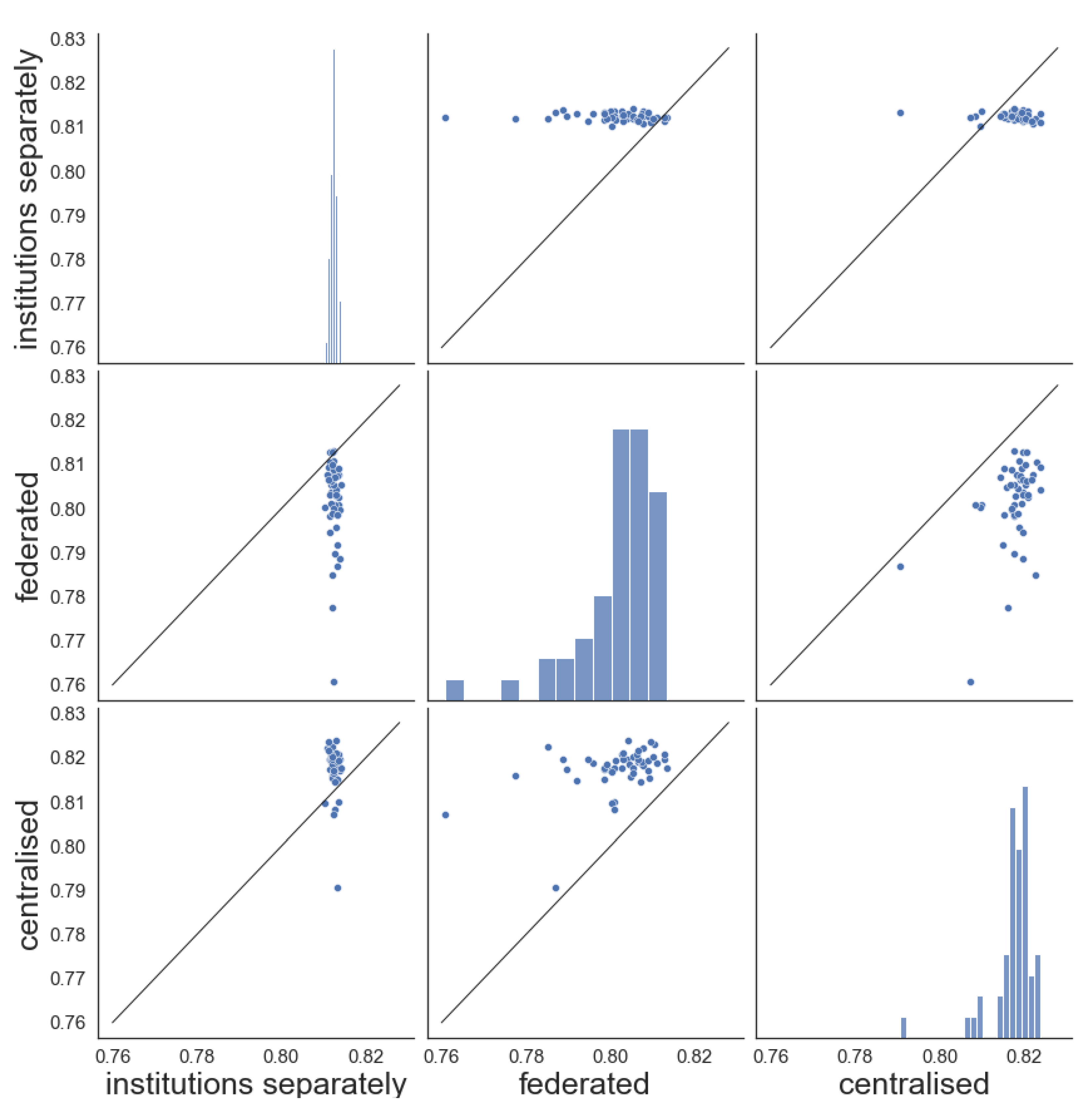
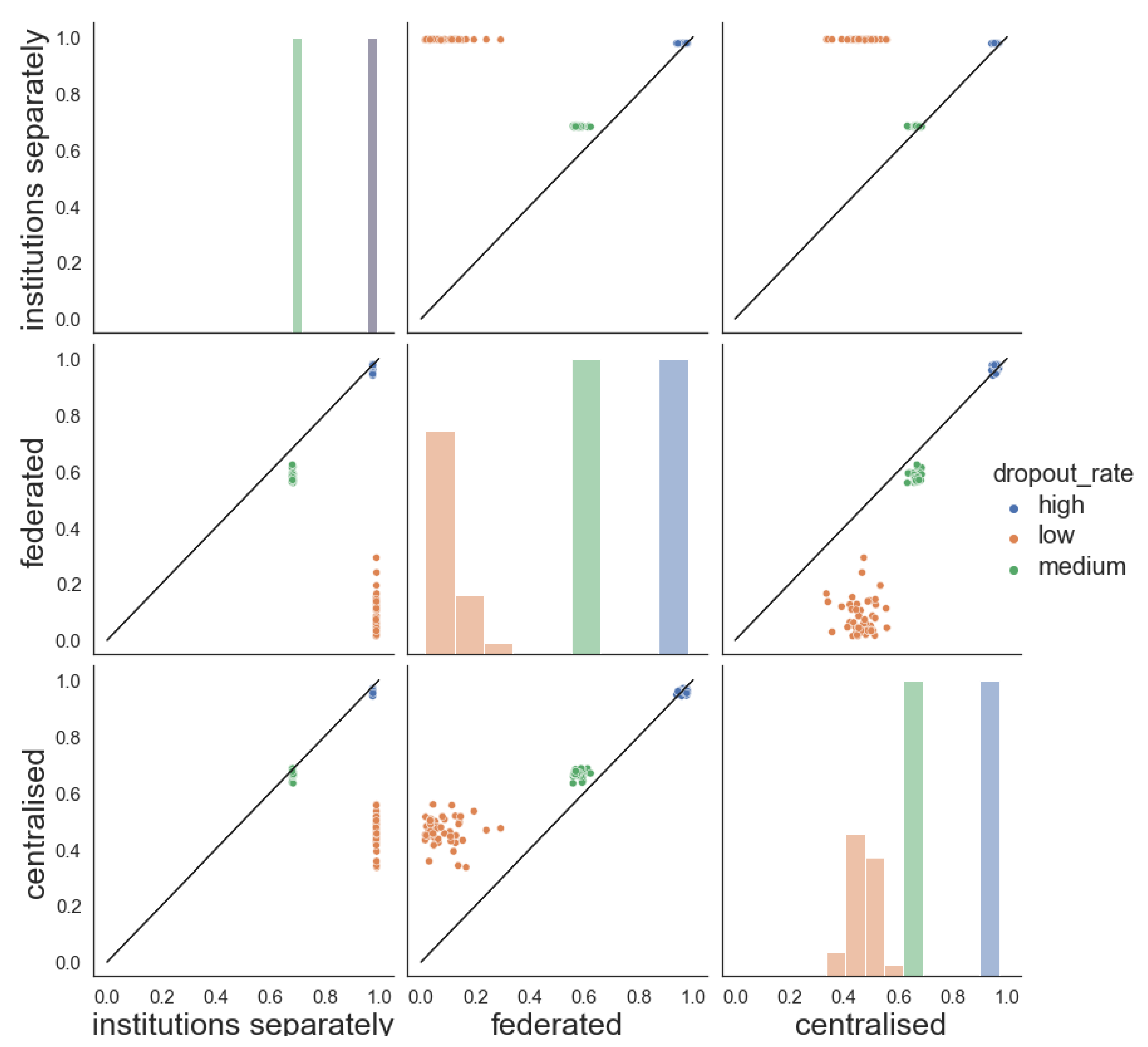
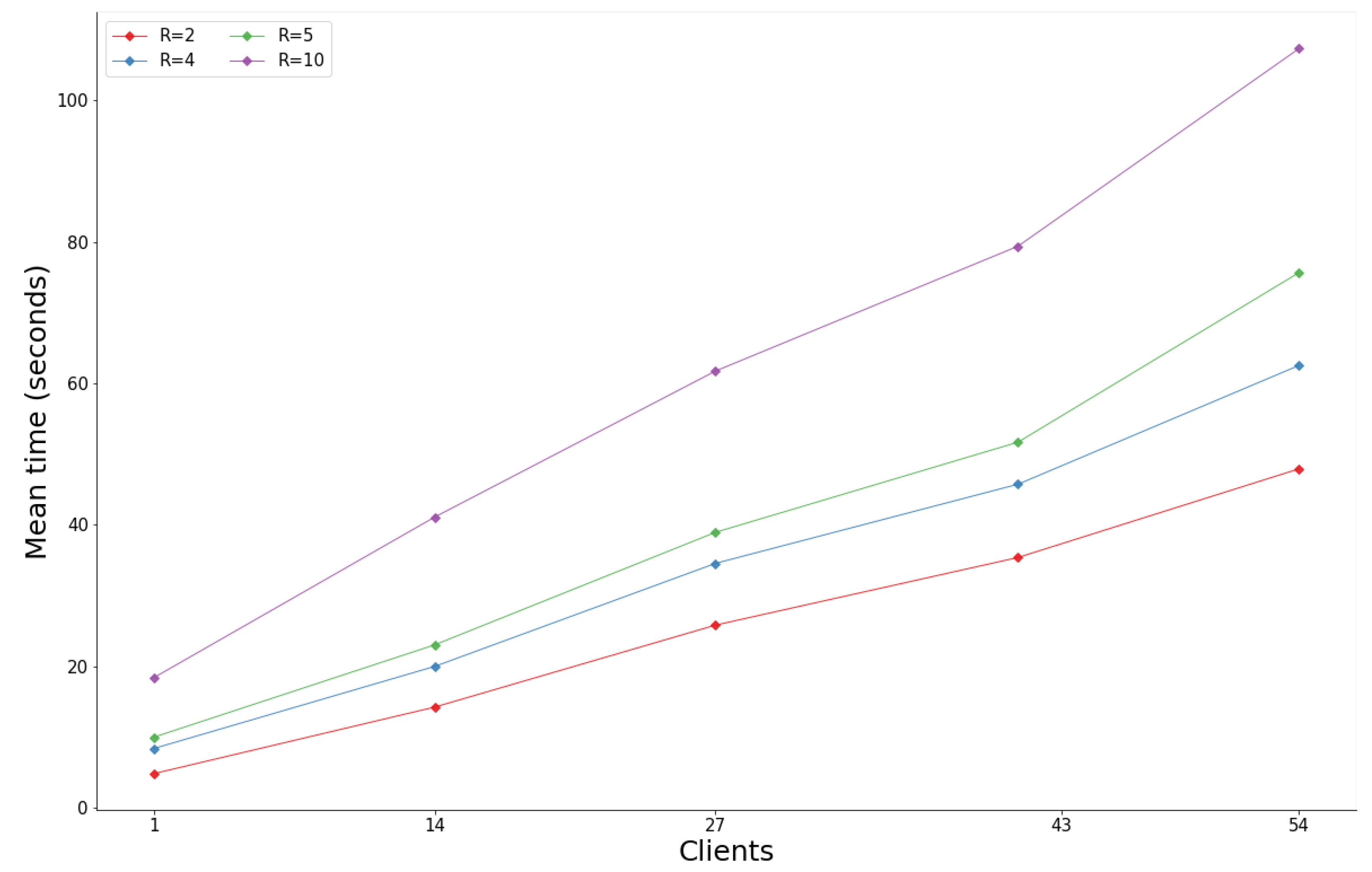
3.3. Federated Learning Performance
3.3.1. Homogeneous Data Distribution
3.3.2. Heterogeneous Data Distribution
3.3.3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
[‘seek_video#num’, ‘play_video#num’, ‘pause_video#num’, ‘stop_video#num’,
‘load_video#num’, ‘problem_get#num’, ‘problem_check#num’,
‘problem_save#num’, ‘reset_problem#num’, ‘problem_check_correct#num’,
‘problem_check_incorrect#num’, ‘create_thread#num’,
‘create_comment#num’, ‘delete_thread#num’, ‘delete_comment#num’,
‘click_info#num’, ‘click_courseware#num’, ‘click_about#num’,
‘click_forum#num’, ‘click_progress#num’, ‘close_courseware#num’]

-
CPU 2.3 GHz Quad-Core Intel Core i7.
-
16 GB of RAM.
References
- Drachsler, H.; Kismihók, G.; Chen, W.; Hoel, T.; Berg, A.; Cooper, A.; Scheffel, M.; Ferguson, R. Ethical and privacy issues in the design of learning analytics applications. In ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2016; Volume 25–29, pp. 492–493. [Google Scholar] [CrossRef] [Green Version]
- Banihashem, S.K.; Aliabadi, K.; Pourroostaei Ardakani, S.; Delaver, A.; Nili Ahmadabadi, M. Learning Analytics: A Systematic Literature Review. Interdiscip. J. Virtual Learn. Med. Sci. 2018, 9, 63024. [Google Scholar] [CrossRef] [Green Version]
- Mangaroska, K.; Giannakos, M. Learning Analytics for Learning Design: A Systematic Literature Review of Analytics-Driven Design to Enhance Learning. IEEE Trans. Learn. Technol. 2019, 12, 516–534. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Khalil, M.; Ebner, M. De-Identification in Learning Analytics. J. Learn. Anal. 2016, 3, 129–138. [Google Scholar] [CrossRef]
- Kyritsi, K.H.; Zorkadis, V.; Stavropoulos, E.C.; Verykios, V.S. The pursuit of patterns in educational data mining as a threat to student privacy. J. Interact. Media Educ. 2019, 2019, 2. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Gursoy, M.E.; Inan, A.; Nergiz, M.E.; Saygin, Y. Privacy-Preserving Learning Analytics: Challenges and Techniques. IEEE Trans. Learn. Technol. 2017, 10, 68–81. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtarik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Hakak, S.; Ray, S.; Khan, W.Z.; Scheme, E. A framework for edge-assisted healthcare data analytics using federated learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 3423–3427. [Google Scholar]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 1–7. [Google Scholar] [CrossRef]
- Divi, S.; Lin, Y.S.; Farrukh, H.; Celik, Z.B. New Metrics to Evaluate the Performance and Fairness of Personalized Federated Learning. arXiv 2021, arXiv:2107.13173. [Google Scholar] [CrossRef]
- Shi, Y.; Yu, H.; Leung, C. A Survey of Fairness-Aware Federated Learning. arXiv 2021, arXiv:2111.01872. [Google Scholar]
- Feng, W.; Tang, J.; Liu, T.X. Understanding dropouts in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI: Palo Alto, CA, USA, 2019; Volume 33, pp. 517–524. [Google Scholar]
- Guo, S.; Zeng, D. Pedagogical Data Federation toward Education 4.0. In Proceedings of the 6th International Conference on Frontiers of Educational Technologies; Association for Computing Machinery: New York, NY, USA, 2020; pp. 51–55. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, B.; Song, S.; Thakkar, O.; Thakurta, A.; Xu, Z. Practical and Private (Deep) Learning without Sampling or Shuffling. arXiv 2021, arXiv:2103.00039. [Google Scholar] [CrossRef]
- Zaman, F. Instilling Responsible and Reliable AI Development with Federated Learning. 2020. Available online: https://medium.com/accenture-the-dock/instilling-responsible-and-reliable-ai-development-with-federated-learning-d23c366c5efd (accessed on 3 January 2023).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- KDD. KDDCup. 2015. Available online: http://moocdata.cn/challenges/kdd-cup-2015 (accessed on 3 January 2023).
- FLEA. FLEA Project Public Repository. 2022. Available online: https://gitlab.fing.edu.uy/lorenae/flea (accessed on 3 January 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, B.; Ding, M.; Shaham, S.; Rahayu, W.; Farokhi, F.; Lin, Z. When Machine Learning Meets Privacy: A Survey and Outlook. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| % of All Students | # Courses | Students Taking # Courses |
|---|---|---|
| 46% | 2 | 35,683 |
| 17% | 3 | 13,271 |
| 16% | 1 | 12,411 |
| 8% | 4 | 6277 |
| 4% | 5 | 3212 |
| 9% | >5 | 6229 |
| Students with a low dropout rate (lower than 0.2): | 8895 | 11.54% |
| Students with a medium dropout rate (between 0.2 and 0.8): | 20,567 | 26.68% |
| Students with a high dropout rate (higher than 0.8): | 47,621 | 61.78% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fachola, C.; Tornaría, A.; Bermolen, P.; Capdehourat, G.; Etcheverry, L.; Fariello, M.I. Federated Learning for Data Analytics in Education. Data 2023, 8, 43. https://doi.org/10.3390/data8020043
Fachola C, Tornaría A, Bermolen P, Capdehourat G, Etcheverry L, Fariello MI. Federated Learning for Data Analytics in Education. Data. 2023; 8(2):43. https://doi.org/10.3390/data8020043
Chicago/Turabian StyleFachola, Christian, Agustín Tornaría, Paola Bermolen, Germán Capdehourat, Lorena Etcheverry, and María Inés Fariello. 2023. "Federated Learning for Data Analytics in Education" Data 8, no. 2: 43. https://doi.org/10.3390/data8020043
APA StyleFachola, C., Tornaría, A., Bermolen, P., Capdehourat, G., Etcheverry, L., & Fariello, M. I. (2023). Federated Learning for Data Analytics in Education. Data, 8(2), 43. https://doi.org/10.3390/data8020043