
Domain Adaptation and Federated Learning for Ultrasonic Monitoring of Beer Fermentation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Ultrasonic Waveform Features
2.1.1. Energy
2.1.2. Energy Standard Deviation
2.1.3. Time of Flight
2.2. Machine Learning
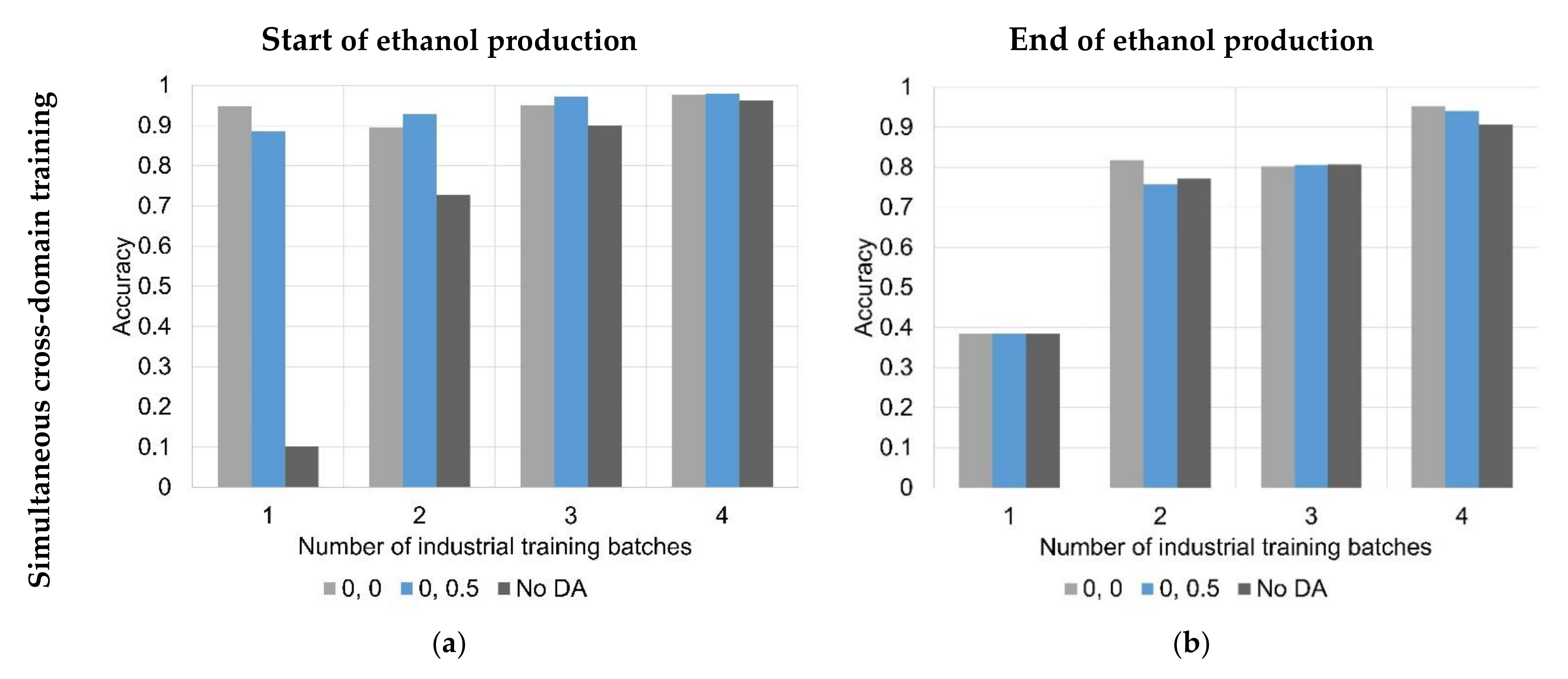
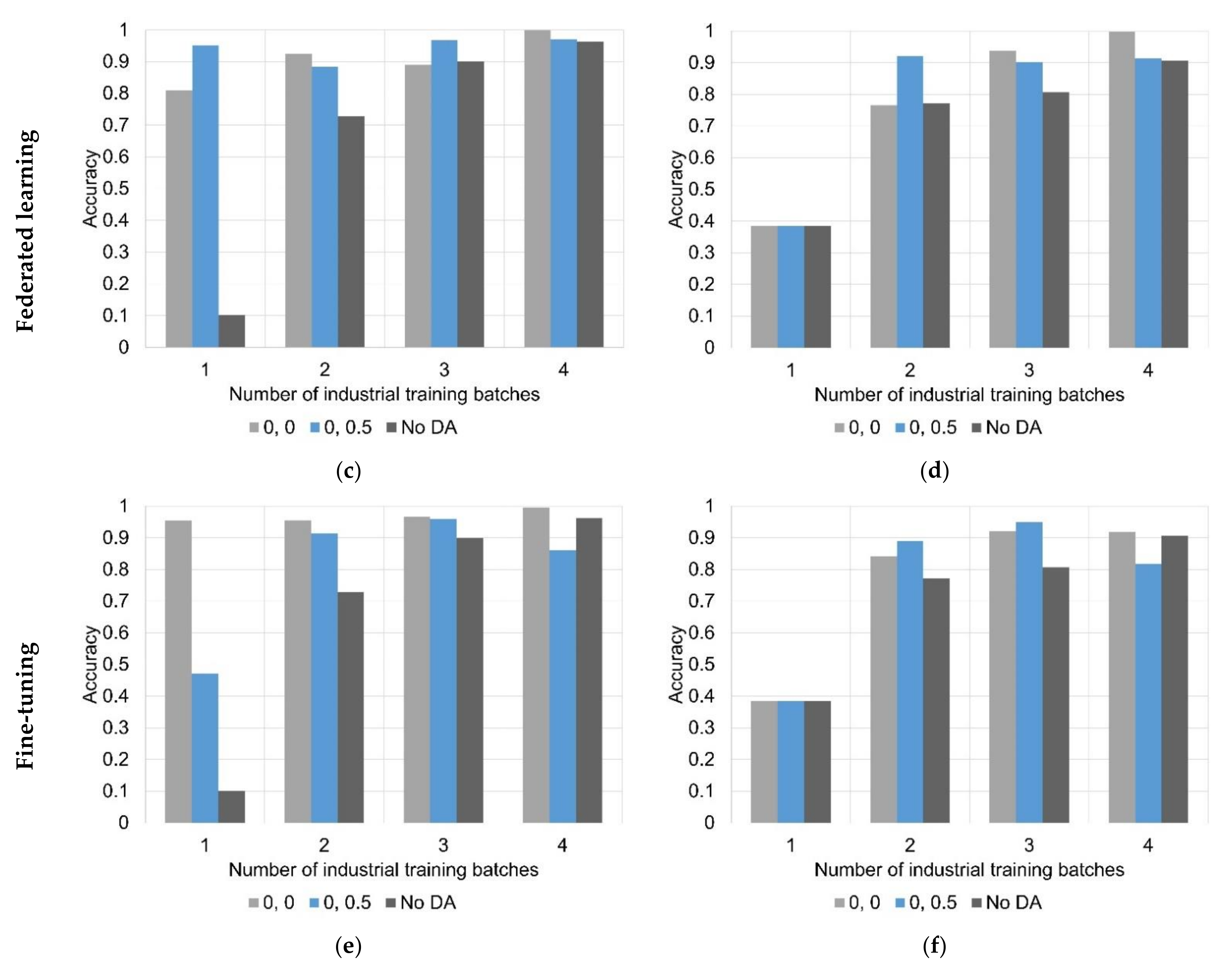
3. Results
3.1. Ultrasonic Measurements
3.2. Machine Learning
3.3. Future Research Directions
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Grassi, S.; Amigo, J.M.; Lyndgaard, C.B.; Foschino, R.; Casiraghi, E. Beer fermentation: Monitoring of process parameters by FT-NIR and multivariate data analysis. Food Chem. 2014, 155, 279–286. [Google Scholar] [CrossRef]
- Jan, M.V.S.; Guarini, M.; Guesalaga, A.; Pérez-Correa, J.R.; Vargas, Y.; Perez-Correa, J. Ultrasound based measurements of sugar and ethanol concentrations in hydroalcoholic solutions. Food Control 2008, 19, 31–35. [Google Scholar] [CrossRef]
- Vann, L.; Layfield, J.B.; Sheppard, J.D. The application of near-infrared spectroscopy in beer fermentation for online monitoring of critical process parameters and their integration into a novel feedforward control strategy. J. Inst. Brew. 2017, 123, 347–360. [Google Scholar] [CrossRef] [Green Version]
- De Beer, T.; Burggraeve, A.; Fonteyne, M.; Saerens, L.; Remon, J.; Vervaet, C. Near infrared and Raman spectroscopy for the in-process monitoring of pharmaceutical production processes. Int. J. Pharm. 2011, 417, 32–47. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, R.Y.; Xu, X.; Klotz, E.; Newman, S.T. Intelligent Manufacturing in the Context of Industry 4.0: A Review. Engineering 2017, 3, 616–630. [Google Scholar] [CrossRef]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Corro-Herrera, V.A.; Gómez-Rodríguez, J.; Hayward-Jones, P.M.; Barradas-Dermitz, D.M.; Gschaedler-Mathis, A.C.; AguilarUscanga, M.G. Real-time monitoring of ethanol production during Pichia stipitis NRRL Y-7124 alcoholic fermentation using transflection near infrared spectroscopy. Eng. Life Sci. 2018, 18, 643–653. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Li, Z.; Ma, Z.; Liang, L. Real time monitoring of multiple components in wine fermentation using an on-line auto-calibration Raman spectroscopy. Sens. Actuators B Chem. 2014, 202, 426–432. [Google Scholar] [CrossRef]
- Schalk, R.; Frank, R.; Rädle, M.; Methner, F.-J.; Beuermann, T.; Braun, F.; Gretz, N. Non-contact Raman spectroscopy for in-line monitoring of glucose and ethanol during yeast fermentations. Bioprocess Biosyst. Eng. 2017, 40, 1519–1527. [Google Scholar] [CrossRef]
- Mazarevica, G.; Diewok, J.; Baena, J.R.; Rosenberg, E.; Lendl, B. On-Line Fermentation Monitoring by Mid-Infrared Spectroscopy. Appl. Spectrosc. 2004, 58, 804–810. [Google Scholar] [CrossRef]
- Veale, E.; Irudayaraj, J.; Demirci, A. An On-Line Approach to Monitor Ethanol Fermentation Using FTIR Spectroscopy. Biotechnol. Prog. 2007, 23, 494–500. [Google Scholar] [CrossRef]
- Toledo, J.; Ruiz-Díez, V.; Pfusterschmied, G.; Schmid, U.; Sánchez-Rojas, J. Flow-through sensor based on piezoelectric MEMS resonator for the in-line monitoring of wine fermentation. Sens. Actuators B Chem. 2018, 254, 291–298. [Google Scholar] [CrossRef]
- Ete-Carmona, E.C.; Gallego-Martinez, J.-J.; Martin, C.; Brox, M.; Luna-Rodriguez, J.-J.; Moreno, J. A Low-Cost IoT Device to Monitor in Real-Time Wine Alcoholic Fermentation Evolution through CO2 Emissions. IEEE Sens. J. 2020, 20, 6692–6700. [Google Scholar] [CrossRef]
- Hussein, W.B.; Hussein, M.A.; Becker, T. Robust spectral estimation for speed of sound with phase shift correction applied online in yeast fermentation processes. Eng. Life Sci. 2012, 12, 603–614. [Google Scholar] [CrossRef]
- Hoche, S.; Krause, D.; Hussein, M.A.; Becker, T. Ultrasound-based, in-line monitoring of anaerobe yeast fermentation: Model, sensor design and process application. Int. J. Food Sci. Technol. 2016, 51, 710–719. [Google Scholar] [CrossRef]
- Resa, P.; Elvira, L.; De Espinosa, F.M. Concentration control in alcoholic fermentation processes from ultrasonic velocity measurements. Food Res. Int. 2004, 37, 587–594. [Google Scholar] [CrossRef]
- Resa, P.; Elvira, L.; De Espinosa, F.M.; González, R.; Barcenilla, J. On-line ultrasonic velocity monitoring of alcoholic fermentation kinetics. Bioprocess Biosyst. Eng. 2008, 32, 321–331. [Google Scholar] [CrossRef]
- Bowler, A.; Escrig, J.; Pound, M.; Watson, N. Predicting Alcohol Concentration during Beer Fermentation Using Ultrasonic Measurements and Machine Learning. Fermentation 2021, 7, 34. [Google Scholar] [CrossRef]
- Donadini, G.; Porretta, S. Uncovering patterns of consumers’ interest for beer: A case study with craft beers. Food Res. Int. 2017, 91, 183–198. [Google Scholar] [CrossRef]
- Gatrell, J.; Reid, N.; Steiger, T.L. Branding spaces: Place, region, sustainability and the American craft beer industry. Appl. Geogr. 2018, 90, 360–370. [Google Scholar] [CrossRef]
- Bowler, A.L.; Watson, N.J. Transfer learning for process monitoring using reflection-mode ultrasonic sensing. Ultrasonics 2021, 115, 106468. [Google Scholar] [CrossRef] [PubMed]
- Kouw, W.M.; Loog, M. A Review of Domain Adaptation without Target Labels. IEEE T Pattern Anal. 2021, 43, 766–785. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.-Q. Multi-Layer domain adaptation method for rolling bearing fault diagnosis. Signal Process. 2019, 157, 180–197. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhang, W.; Ding, Q. A robust intelligent fault diagnosis method for rolling element bearings based on deep distance metric learning. Neurocomputing 2018, 310, 77–95. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines with Unlabeled Data. IEEE T. Ind. Electron. 2019, 9, 7316–7325. [Google Scholar] [CrossRef]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE T. Ind. Electron. 2017, 3, 2296–2305. [Google Scholar] [CrossRef]
- Geng, B.; Tao, D.; Xu, C. DAML: Domain adaptation metric learning. IEEE T. Image Process. 2011, 10, 2980–2989. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. Proc. CVPR IEEE 2017, 2017, 2962–2971. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Ouyang, W.; Li, W.; Xu, D. Collaborative and Adversarial Network for Unsupervised Domain Adaptation. Proc. CVPR IEEE 2018, 2018, 3801–3809. [Google Scholar] [CrossRef]
- Zhang, Y.; Qiu, Z.; Yao, T.; Liu, D.; Mei, T. Fully Convolutional Adaptation Networks for Semantic Segmentation. Proc. CVPR IEEE 2018, 2018, 6810–6818. [Google Scholar] [CrossRef] [Green Version]
- Tsai, Y.-H.; Hung, W.-C.; Schulter, S.; Sohn, K.; Yang, M.-H.; Chandraker, M. Learning to Adapt Structured Output Space for Semantic Segmentation. Proc. CVPR IEEE. 2018, 2018, 7472–7481. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, H.; Li, Y.; Su, H.; Wang, Z.; Tu, C.; Lischinski, D.; Cohen-Or, D.; Chen, B. Synthesizing training images for boosting human 3D pose estimation. Proc. 3DV 2016, 2016, 479–488. [Google Scholar] [CrossRef] [Green Version]
- Sankaranarayanan, S.; Balaji, Y.; Castillo, C.D.; Chellappa, R. Generate to Adapt: Aligning Domains Using Generative Adversarial Networks. Proc. CVPR IEEE 2018, 2018, 8503–8512. [Google Scholar] [CrossRef] [Green Version]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation. Proc. CVPR IEEE 2018, 2018, 3752–3761. [Google Scholar] [CrossRef] [Green Version]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. Proc. CVPR IEEE 2017, 2017, 95–104. [Google Scholar] [CrossRef] [Green Version]
- Bousmalis, K.; Irpan, A.; Wohlhart, P.; Bai, Y.; Kelcey, M.; Kalakrishnan, M.; Downs, L.; Ibarz, J.; Pastor, P.; Konolige, K.; et al. Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping. IEEE Int. Conf. Robot. 2018, 2018, 4243–4250. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Geng, W. Surface EMG-based inter-session gesture recognition enhanced by deep domain adaptation. Sensors 2017, 17, 458. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.; Yoo, J.; Kim, H.H.; Sin, H.J.; Sung, K.; Ye, J.C. Deep learning with domain adaptation for accelerated projection-reconstruction MR. Magn. Reson. Med. 2018, 80, 1189–1205. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM T. Intel. Syst. Tec. 2019, 10, 12. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [Green Version]
- McClements, D. Advances in the application of ultrasound in food analysis and processing. Trends Food Sci. Technol. 1995, 6, 293–299. [Google Scholar] [CrossRef]
- Zhan, X.; Jiang, S.; Yang, Y.; Liang, J.; Shi, T.; Li, X. Inline Measurement of Particle Concentrations in Multicomponent Suspensions using Ultrasonic Sensor and Least Squares Support Vector Machines. Sensors 2015, 15, 24109–24124. [Google Scholar] [CrossRef] [Green Version]
- Henning, B.; Rautenberg, J. Process monitoring using ultrasonic sensor systems. Ultrasonics 2006, 44, e1395–e1399. [Google Scholar] [CrossRef]
- Li, X.; Zhao, L.; Wei, L.; Yang, M.-H.; Wu, F.; Zhuang, Y.; Ling, H.; Wang, J. DeepSaliency: Multi-Task Deep Neural Network Model for Salient Object Detection. IEEE T. Image Process. 2016, 25, 3919–3930. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Machine Learning Mastery. Available online: https://machinelearningmastery.com/handle-long-sequences-long-short-termmemory-recurrent-neural-networks/ (accessed on 11 August 2021).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lamberti, N.; Ardia, L.; Albanese, D.; Di Matteo, M. An ultrasound technique for monitoring the alcoholic wine fermentation. Ultrasonics 2009, 49, 94–97. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Chunag, Y.-C.; Wu, A.-Y.A. Online Extreme Learning Machine Design for the Application of Federated Learning. In Proceedings of the IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; pp. 188–192. [Google Scholar] [CrossRef]
- Dib, M.A.D.S.; Ribeiro, B.; Prates, P. Federated Learning as a Privacy-Providing Machine Learning for Defect Predictions in Smart Manufacturing. Smart Sustain. Manuf. Syst. 2021, 5, 1–17. [Google Scholar] [CrossRef]
- Ge, N.; Li, G.; Zhang, L.; Liu, Y. Failure prediction in production line based on federated learning: An empirical study. J Intell Manuf. 2021. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Simultaneous Cross-Domain Training | Federated Learning | Fine-Tuning |
|---|---|---|---|
| Training datasets | Both source and target domain | Both source and target domain | Both source and target domain Followed by fine-tuning on target domain |
| Training strategy | Trained on both domains simultaneously | Trained on each domain sequentially | Either, depending on starting model used |
| Application | Transfer learning for laboratory data Transfer learning from other processes within the same company | Transfer learning between companies | Either, depending on starting model used |
| Advantages | More training options available as both datasets can be used simultaneously | Preserves privacy between domains | Either, depending on starting model used |
| Problem definition | Define N datasets {D1, … DN} used to train a ML model MDA. | Define N data owners wishing to train a ML model MFED using all their data {D1, … DN} without sharing the datasets and thus maintaining privacy. | Define N datasets {D1, … DN} used to train a ML model MS. Define DT as the target domain dataset (DT included in {D1, … DN}. |
| Algorithm | θ = model weights E = number of epochs Initialise θ0 For i = 1 to E Iterate θ for 1 epoch using a combined dataset consisting of D1, … DN. End | θ = model weights C = number of communication rounds w = weighting factor Initialise θ0 For i = 1 to C Global model: θG = Σ wjθj Local models: For j = 1 to N Initialise θj = θG Iterate θj for 1 epoch using Dj Return θj End End | θ = model weights E = number of epochs Initialise θ = θS For i = 1 to E Iterate θ for 1 epoch using DT End |
| Parameter | Size of Training Set | |||
|---|---|---|---|---|
| Number of industrial scale fermentation batches in training set | 1 | 2 | 3 | 4 |
| Number of industrial scale fermentation batches in test set | 4 | 3 | 2 | 1 |
| Number of validation folds | 0 | 2 | 3 | 4 |
| Number of industrial fermentation batch occurrences per epoch when training on both domains simultaneously | 13 | 6 | 4 | 3 |
| Industrial dataset weighting factor for federated learning | 0.9 | 0.85 | 0.8 | 0.75 |
| Method | Model | Start of Ethanol Production Accuracy (MAE) | End of Ethanol Production Accuracy (MAE) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | ||
| Base-line model | No DA | 2.769 | 1.099 | 0.646 | 0.710 | 2.035 | 1.278 | 1.047 | 0.534 |
| Conventional domain adaptation | 0, 0 | 1.942 | 0.93 | 0.423 | 0.541 | 1.767 | 0.980 | 0.950 | 0.681 |
| 0, 0.5 | 3.326 | 1.528 | 0.836 | 0.171 | 7.29 | 2.027 | 1.528 | 0.920 | |
| Federated Learning | 0, 0 | 2.496 | 0.540 | 0.431 | 0.726 | 3.884 | 1.133 | 0.599 | 0.351 |
| 0, 0.5 | 2.482 | 0.423 | 0.520 | 0.296 | 3.073 | 1.089 | 0.937 | 0.663 | |
| Fine-tuning | 0, 0 | 2.536 | 0.485 | 0.334 | 0.402 | 4.998 | 0.833 | 0.517 | 1.061 |
| 0, 0.5 | 3.376 | 0.514 | 0.338 | 0.416 | 5.110 | 0.837 | 0.64 | 1.451 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bowler, A.L.; Pound, M.P.; Watson, N.J. Domain Adaptation and Federated Learning for Ultrasonic Monitoring of Beer Fermentation. Fermentation 2021, 7, 253. https://doi.org/10.3390/fermentation7040253
Bowler AL, Pound MP, Watson NJ. Domain Adaptation and Federated Learning for Ultrasonic Monitoring of Beer Fermentation. Fermentation. 2021; 7(4):253. https://doi.org/10.3390/fermentation7040253
Chicago/Turabian StyleBowler, Alexander L., Michael P. Pound, and Nicholas J. Watson. 2021. "Domain Adaptation and Federated Learning for Ultrasonic Monitoring of Beer Fermentation" Fermentation 7, no. 4: 253. https://doi.org/10.3390/fermentation7040253