
Adapting the Segment Anything Model for Plant Recognition and Automated Phenotypic Parameter Measurement


 ,
, 
Abstract
1. Introduction
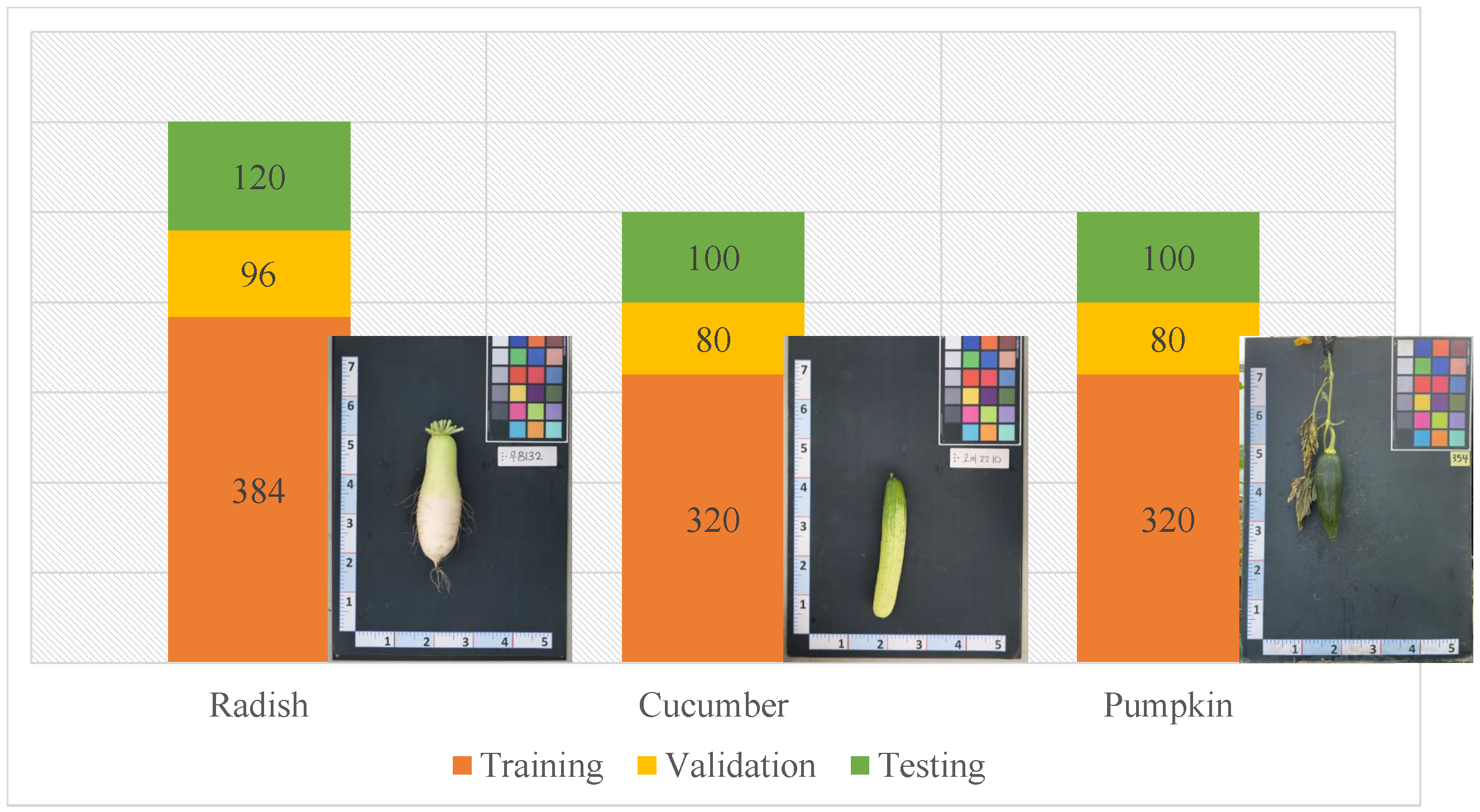
2. Plant Phenotypic Dataset
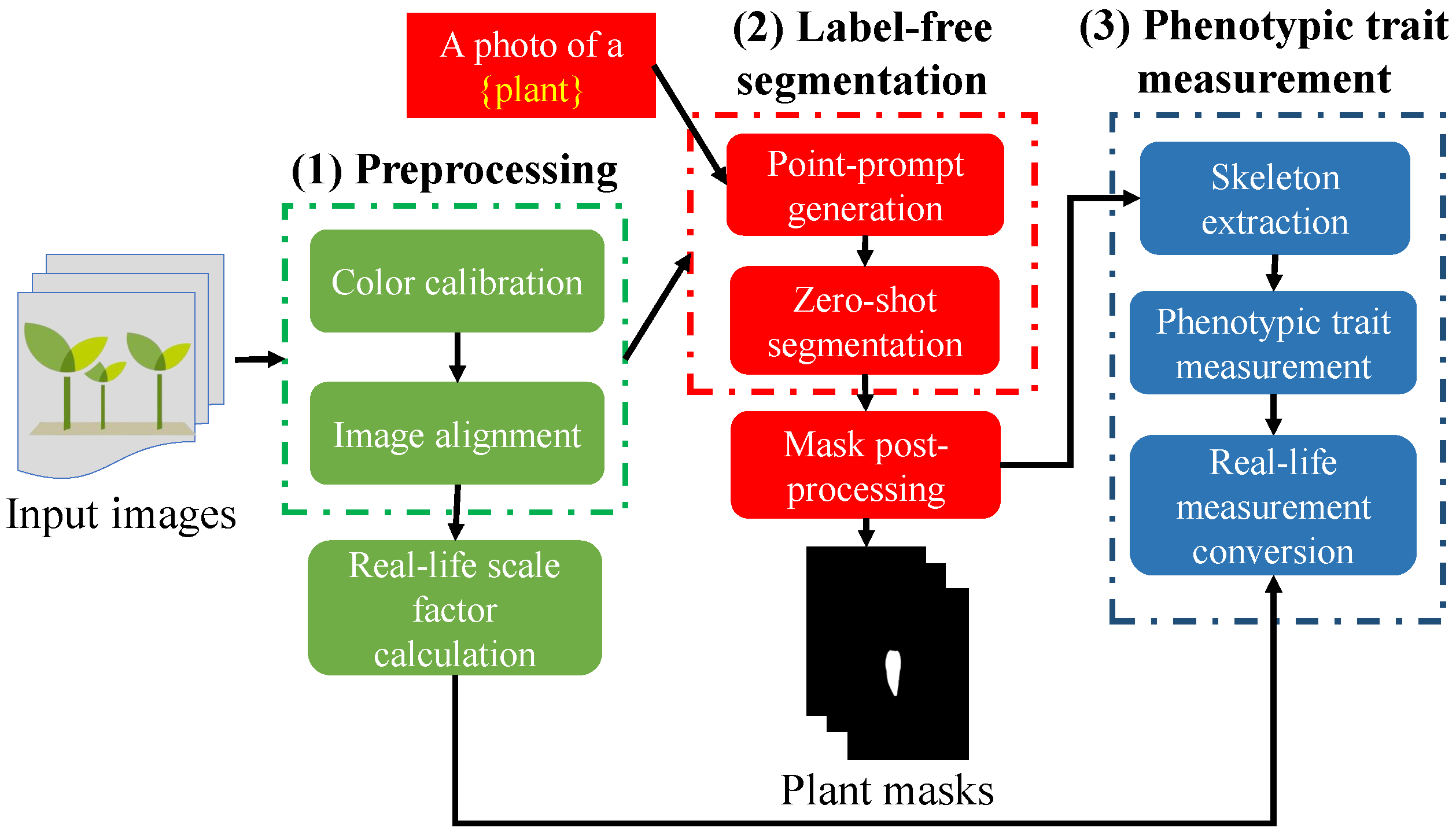
3. System Overview
- Preprocessing: Preprocessing plays a crucial role in ensuring accurate plant trait identification. In this study, two preprocessing methods, namely, color calibration and image alignment, were carried out. Color calibration corrects inconsistencies in color reproduction caused by camera settings, lighting variations, or sensor specifications. On the other hand, image alignment addresses misalignment arising from camera movement, wind-blown plants, or uneven terrain. After the preprocessing step, a scale factor is calculated to facilitate the conversion of measurements from an image space system into an object space system.
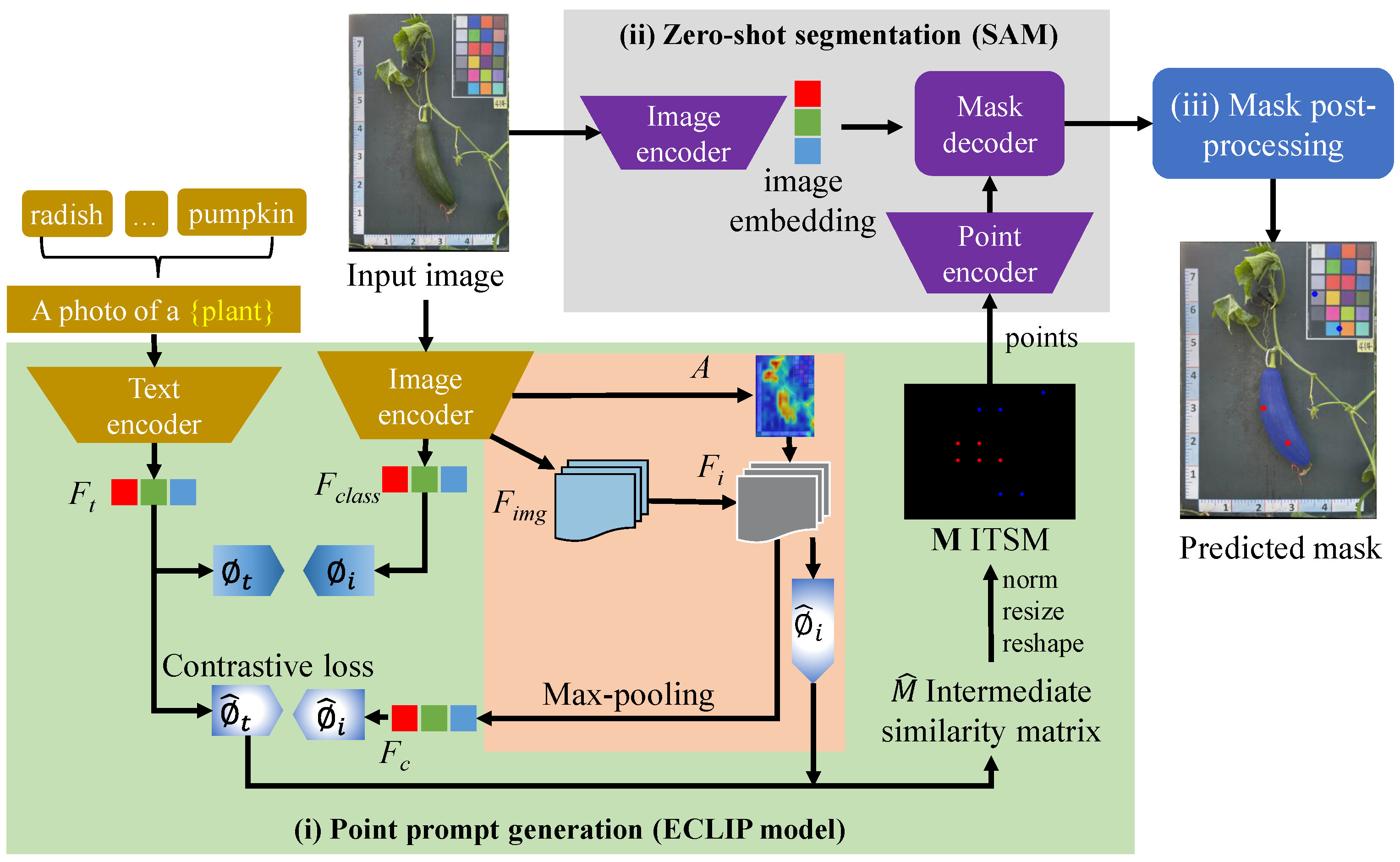
- Label-free segmentation: The zero-shot segmentation method bypasses the requirement for conventionally labeled datasets by utilizing the capabilities of pretrained large models. ECLIP, a pretrained image-text model, processes textual descriptions of plant parts and directly generates keypoint locations on the image. These points serve as guiding signals for SAM, a powerful segmentation model, allowing it to identify and segment the plant components. Finally, a postprocessing step refines the segmentation mask, eliminating wrongly segmented regions and ensuring a clean, accurate representation of the plant for further analysis.
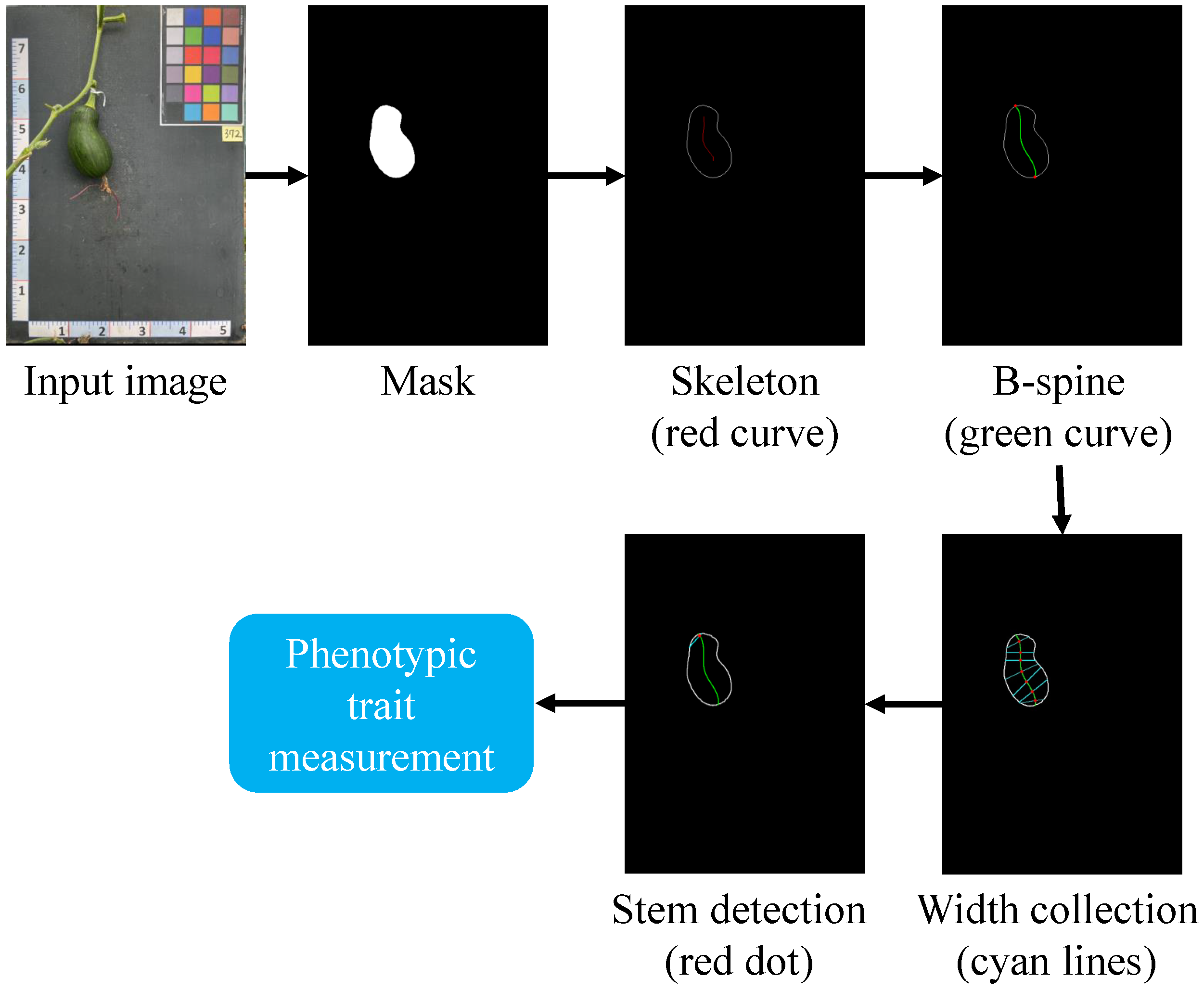
- Phenotypic trait measurement: By utilizing the segmented masks created by the label-free segmentation module and the calculated scale factor (converting the image space system into the object space system), we can accurately measure various plant phenotypic traits, such as width and length, in real-world units.
4. Methodology
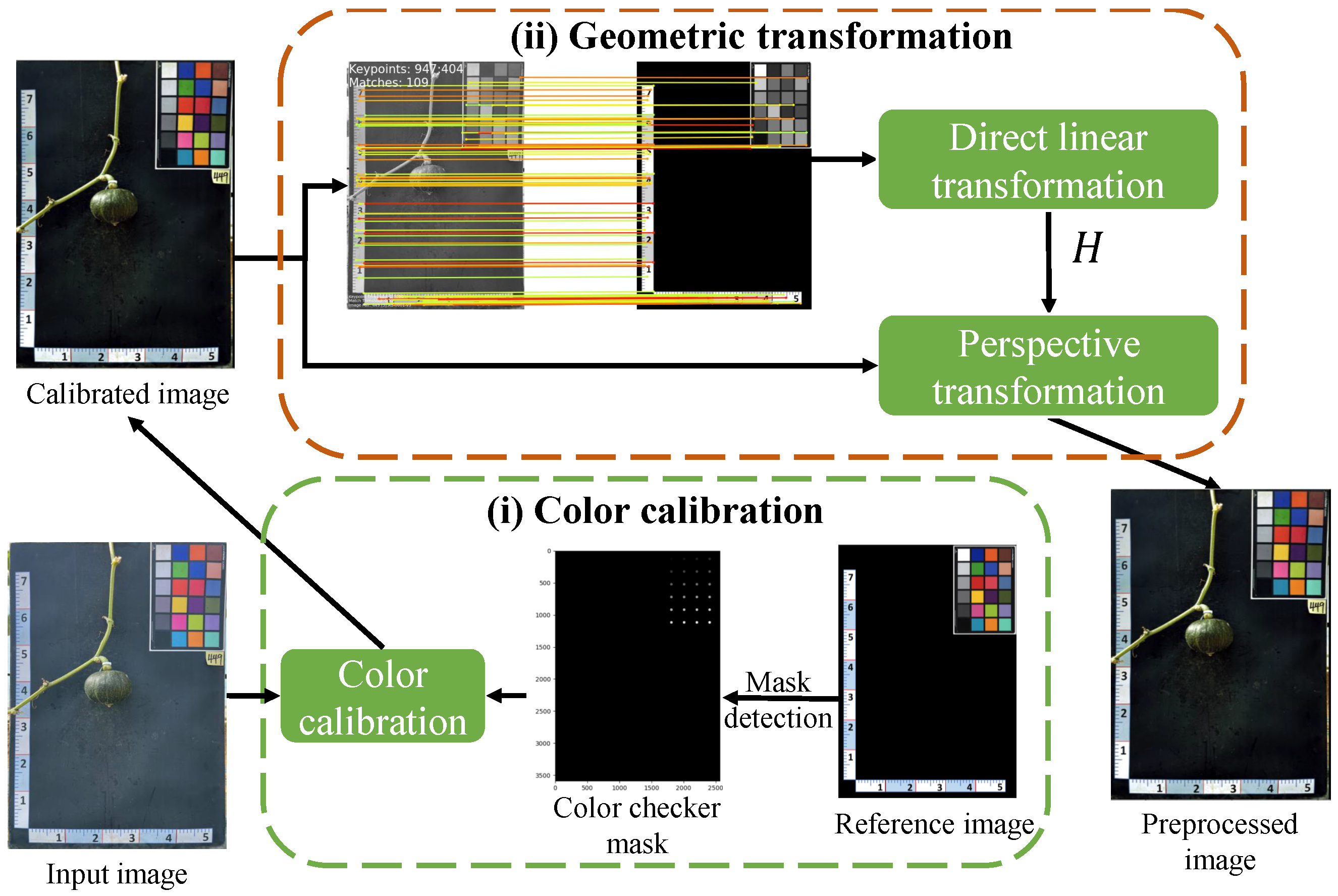
4.1. Preprocessing
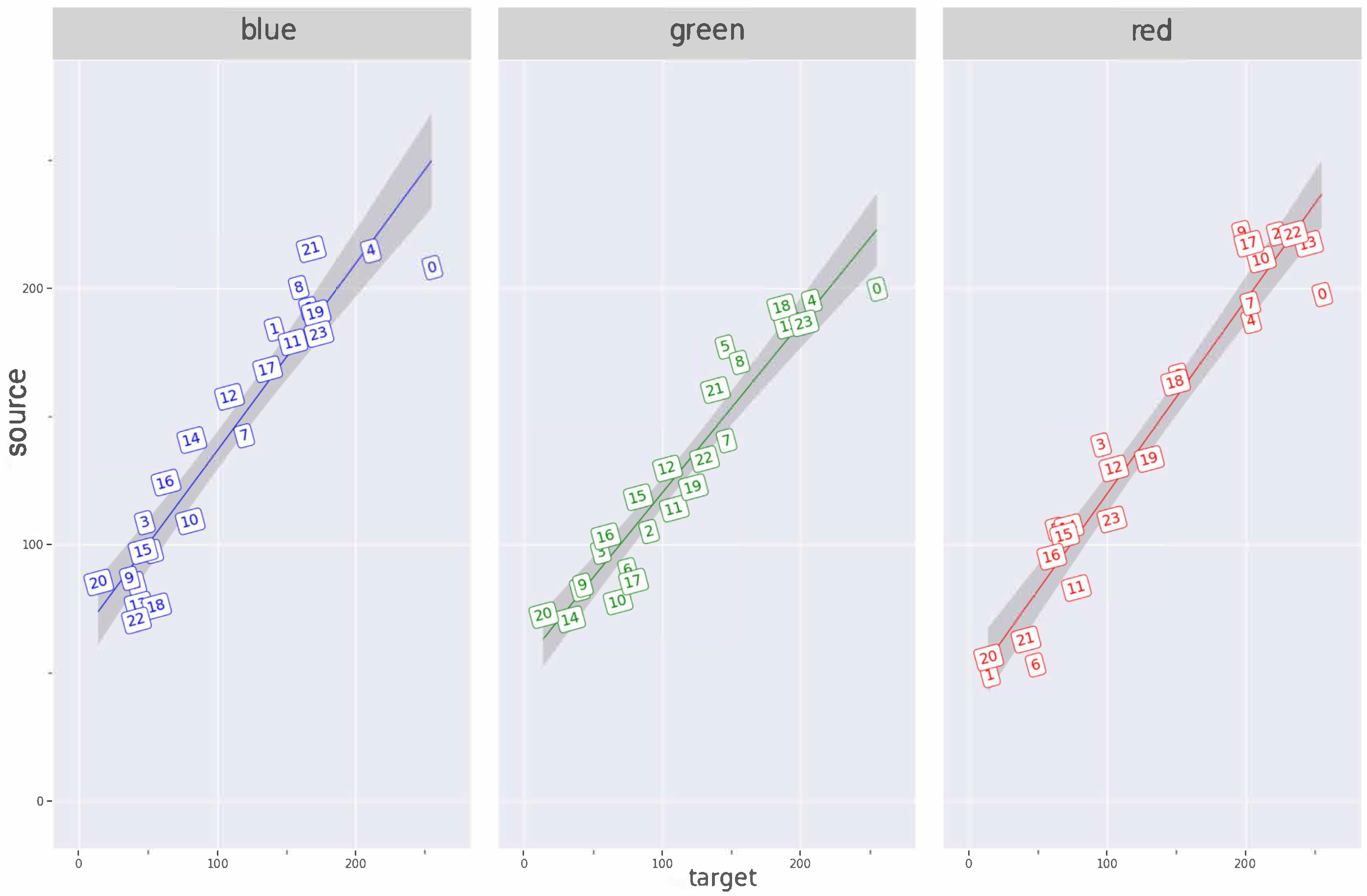
4.1.1. Color Calibration
4.1.2. Image Alignment
4.2. Label-Free Segmentation
4.2.1. Point Prompt Generation
4.2.2. Zero-Shot Segmentation
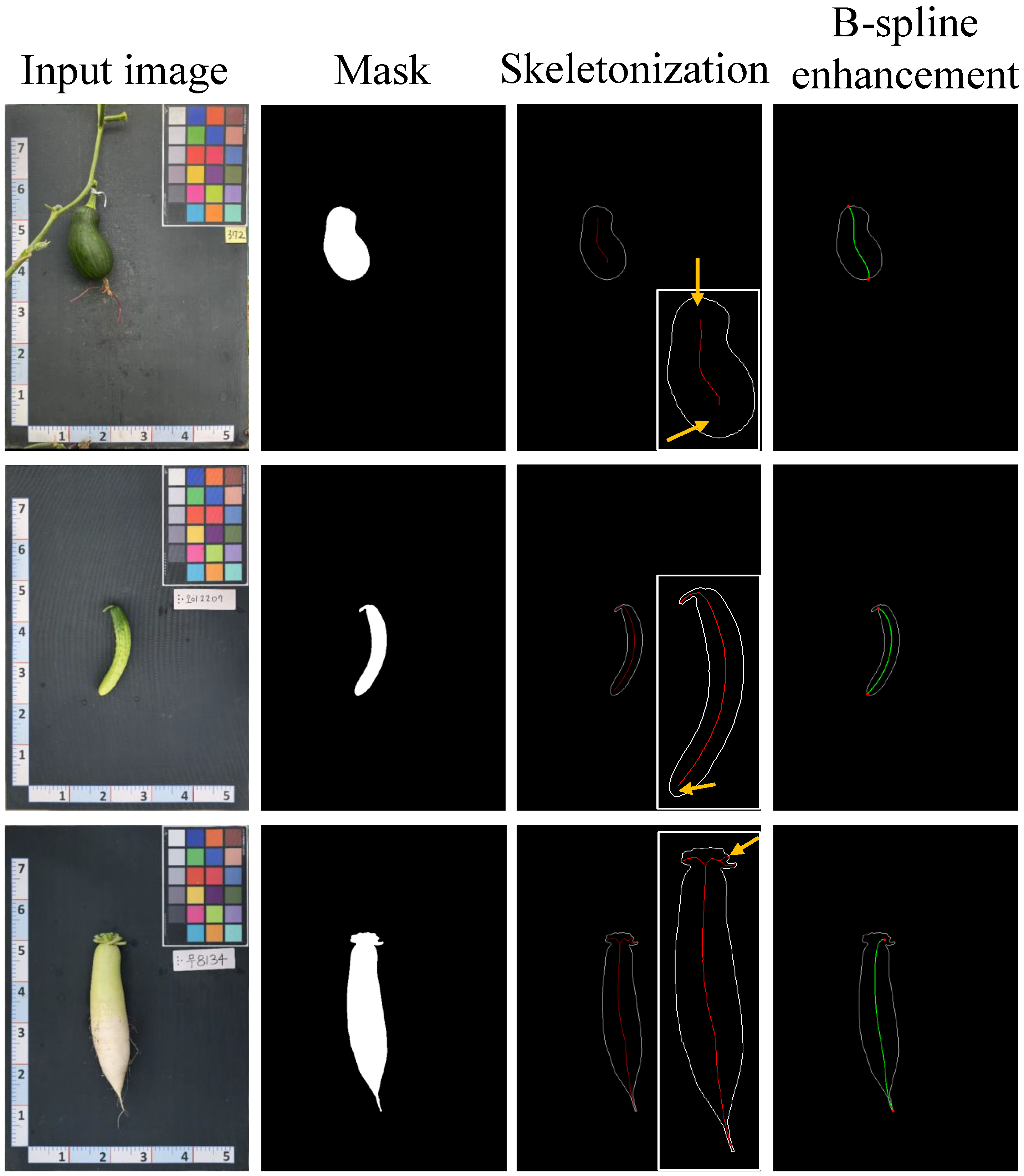
4.2.3. Mask Postprocessing
- Initialize an empty list to store the masks that meet the area criteria.
- For each mask in the output masks from SAM:
- −
- Find the largest contour in the mask and calculate its area.
- −
- If the area of the largest contour is within the range of and , add the mask to .
- Initialize an empty list to store the final selected masks.
- While is not empty:
- −
- Remove one mask from and assign it to .
- −
- For each remaining mask in :
- ∗
- Calculate the IoU and the overlap ratio between the and the current mask.
- ∗
- If the IoU is greater than a threshold or the overlap ratio is greater than a threshold , merge the current mask with the .
- −
- Add the to .
4.3. Phenotypic Trait Measurement
4.3.1. Implementation Descriptions
4.3.2. Evaluation Metrics
5. Experimental Results
5.1. Preprocessing
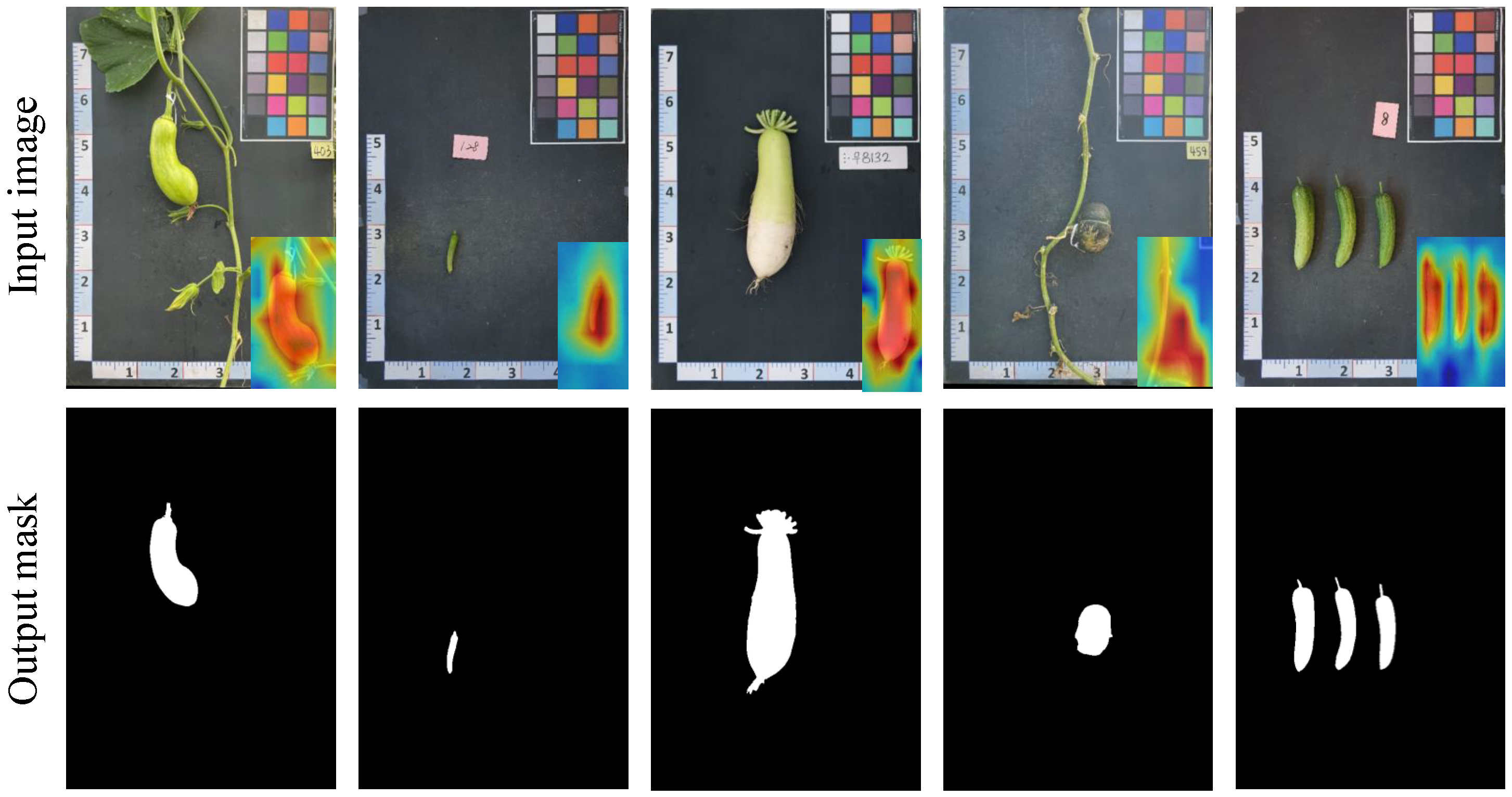
5.2. Zero-Shot Plant Component Segmentation Performance Analysis
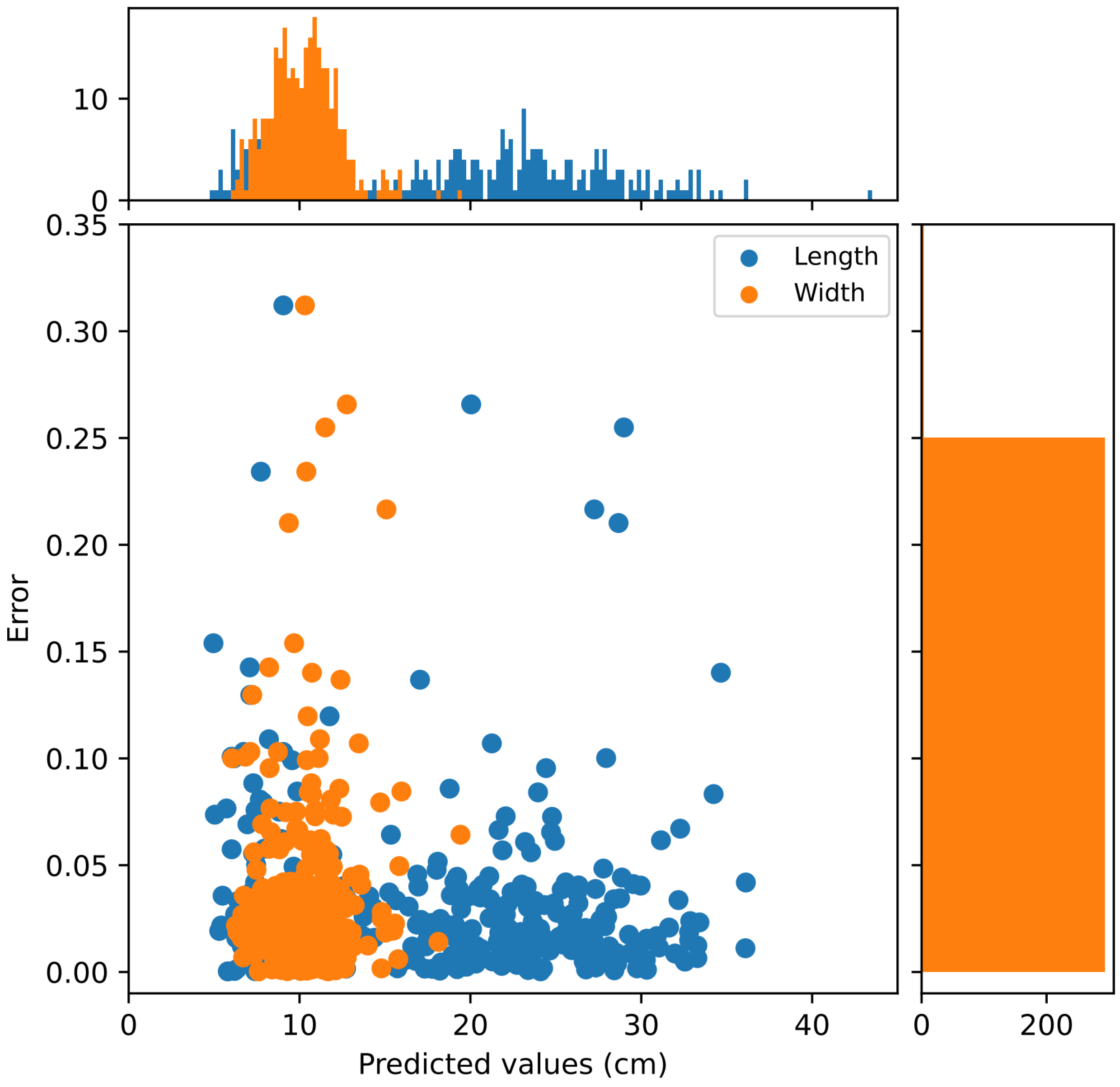
5.3. Phenotypic Trait Measurement
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pieruschka, R.; Schurr, U. Plant phenotyping: Past, present, and future. Plant Phenomics 2019, 2019, 7507131. [Google Scholar] [CrossRef]
- Sade, N.; Peleg, Z. Future challenges for global food security under climate change. Plant Sci. 2020, 295, 110467. [Google Scholar] [CrossRef]
- Reynolds, M.; Chapman, S.; Crespo-Herrera, L.; Molero, G.; Mondal, S.; Pequeno, D.N.; Pinto, F.; Pinera-Chavez, F.J.; Poland, J.; Rivera-Amado, C.; et al. Breeder friendly phenotyping. Plant Sci. 2020, 295, 110396. [Google Scholar] [CrossRef]
- Li, Z.; Guo, R.; Li, M.; Chen, Y.; Li, G. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 105672. [Google Scholar] [CrossRef]
- Falster, D.; Gallagher, R.; Wenk, E.H.; Wright, I.J.; Indiarto, D.; Andrew, S.C.; Baxter, C.; Lawson, J.; Allen, S.; Fuchs, A.; et al. AusTraits, a curated plant trait database for the Australian flora. Sci. Data 2021, 8, 254. [Google Scholar] [CrossRef]
- Dang, M.; Wang, H.; Li, Y.; Nguyen, T.H.; Tightiz, L.; Xuan-Mung, N.; Nguyen, T.N. Computer Vision for Plant Disease Recognition: A Comprehensive Review. Bot. Rev. 2024, 1–61. [Google Scholar] [CrossRef]
- Yang, W.; Feng, H.; Zhang, X.; Zhang, J.; Doonan, J.H.; Batchelor, W.D.; Xiong, L.; Yan, J. Crop phenomics and high-throughput phenotyping: Past decades, current challenges, and future perspectives. Mol. Plant 2020, 13, 187–214. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Dang, L.M.; Sadeghi-Niaraki, A.; Moon, H. Crop pest recognition in natural scenes using convolutional neural networks. Comput. Electron. Agric. 2020, 169, 105174. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Dang, L.M.; Moon, H. An efficient attention module for instance segmentation network in pest monitoring. Comput. Electron. Agric. 2022, 195, 106853. [Google Scholar] [CrossRef]
- Tausen, M.; Clausen, M.; Moeskjær, S.; Shihavuddin, A.; Dahl, A.B.; Janss, L.; Andersen, S.U. Greenotyper: Image-based plant phenotyping using distributed computing and deep learning. Front. Plant Sci. 2020, 11, 1181. [Google Scholar] [CrossRef]
- Arya, S.; Sandhu, K.S.; Singh, J.; Kumar, S. Deep learning: As the new frontier in high-throughput plant phenotyping. Euphytica 2022, 218, 47. [Google Scholar] [CrossRef]
- Busemeyer, L.; Mentrup, D.; Möller, K.; Wunder, E.; Alheit, K.; Hahn, V.; Maurer, H.P.; Reif, J.C.; Würschum, T.; Müller, J.; et al. BreedVision—A multi-sensor platform for non-destructive field-based phenotyping in plant breeding. Sensors 2013, 13, 2830–2847. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Nguyen, T.N.; Park, H.Y.; Lee, O.N.; Song, H.K.; Moon, H. Vision-Based White Radish Phenotypic Trait Measurement with Smartphone Imagery. Agronomy 2023, 13, 1630. [Google Scholar] [CrossRef]
- Zhou, S.; Chai, X.; Yang, Z.; Wang, H.; Yang, C.; Sun, T. Maize-IAS: A maize image analysis software using deep learning for high-throughput plant phenotyping. Plant Methods 2021, 17, 48. [Google Scholar] [CrossRef]
- Qiao, F.; Peng, X. Uncertainty-guided model generalization to unseen domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6790–6800. [Google Scholar]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-shot learning-the good, the bad and the ugly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4582–4591. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Li, Y.; Wang, H.; Duan, Y.; Xu, H.; Li, X. Exploring visual interpretability for contrastive language-image pre-training. arXiv 2022, arXiv:2209.07046. [Google Scholar]
- Sunoj, S.; Igathinathane, C.; Saliendra, N.; Hendrickson, J.; Archer, D. Color calibration of digital images for agriculture and other applications. ISPRS J. Photogramm. Remote. Sens. 2018, 146, 221–234. [Google Scholar] [CrossRef]
- Brunet, J.; Flick, A.J.; Bauer, A.A. Phenotypic selection on flower color and floral display size by three bee species. Front. Plant Sci. 2021, 11, 587528. [Google Scholar] [CrossRef]
- Juarez-Salazar, R.; Zheng, J.; Diaz-Ramirez, V.H. Distorted pinhole camera modeling and calibration. Appl. Opt. 2020, 59, 11310–11318. [Google Scholar] [CrossRef]
- Rios-Orellana, O.I.; Juarez-Salazar, R.; Diaz-Ramirez Sr, V.H. Analysis of algebraic and geometric distances for projective transformation estimation. In Optics and Photonics for Information Processing XIV; SPIE: Cergy-Pontoise, France, 2020; Volume 11509, pp. 67–81. [Google Scholar]
- Song, L.; Wu, J.; Yang, M.; Zhang, Q.; Li, Y.; Yuan, J. Stacked homography transformations for multi-view pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6049–6057. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4938–4947. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhang, C.; Puspitasari, F.D.; Zheng, S.; Li, C.; Qiao, Y.; Kang, T.; Shan, X.; Zhang, C.; Qin, C.; Rameau, F.; et al. A survey on segment anything model (sam): Vision foundation model meets prompt engineering. arXiv 2023, arXiv:2306.06211. [Google Scholar]
- Bo, P.; Luo, G.; Wang, K. A graph-based method for fitting planar B-spline curves with intersections. J. Comput. Des. Eng. 2016, 3, 14–23. [Google Scholar] [CrossRef][Green Version]
- Dang, L.M.; Nadeem, M.; Nguyen, T.N.; Park, H.Y.; Lee, O.N.; Song, H.K.; Moon, H. VPBR: An Automatic and Low-Cost Vision-Based Biophysical Properties Recognition Pipeline for Pumpkin. Plants 2023, 12, 2647. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Pumpkin | Radish | Cucumber |
|---|---|---|---|
| mIoU | 70.2 | 73.7 | 68.4 |
| Precision | 69.1 | 72.1 | 70.2 |
| Recall | 71.5 | 70.8 | 70.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Dang, L.M.; Nguyen, L.Q.; Alam, N.; Bui, N.D.; Park, H.Y.; Moon, H. Adapting the Segment Anything Model for Plant Recognition and Automated Phenotypic Parameter Measurement. Horticulturae 2024, 10, 398. https://doi.org/10.3390/horticulturae10040398
Zhang W, Dang LM, Nguyen LQ, Alam N, Bui ND, Park HY, Moon H. Adapting the Segment Anything Model for Plant Recognition and Automated Phenotypic Parameter Measurement. Horticulturae. 2024; 10(4):398. https://doi.org/10.3390/horticulturae10040398
Chicago/Turabian StyleZhang, Wenqi, L. Minh Dang, Le Quan Nguyen, Nur Alam, Ngoc Dung Bui, Han Yong Park, and Hyeonjoon Moon. 2024. "Adapting the Segment Anything Model for Plant Recognition and Automated Phenotypic Parameter Measurement" Horticulturae 10, no. 4: 398. https://doi.org/10.3390/horticulturae10040398
APA StyleZhang, W., Dang, L. M., Nguyen, L. Q., Alam, N., Bui, N. D., Park, H. Y., & Moon, H. (2024). Adapting the Segment Anything Model for Plant Recognition and Automated Phenotypic Parameter Measurement. Horticulturae, 10(4), 398. https://doi.org/10.3390/horticulturae10040398