
Pedestrian-Accessible Infrastructure Inventory: Enabling and Assessing Zero-Shot Segmentation on Multi-Mode Geospatial Data for All Pedestrian Types

Abstract
:1. Introduction
- (1)
- How can mobile LiDAR technology be leveraged to produce comprehensive pedestrian-accessible infrastructure inventory?
- (2)
- How well does SAM generalize to mobile LiDAR and satellite imagery data in representative segmentation tasks for pedestrian-accessible infrastructure inventory work?
- (3)
- What data representations can effectively boost zero-shot image segmentation performance with SAM for pedestrian-accessible infrastructure inventory work?
2. Literature Review
2.1. Image-Based
2.2. Point-Cloud-Based
2.3. Data Fusion-Based
3. Methodology
3.1. Description of Data Collection Methodology and Datasets
3.2. SAM-Based Workflow
3.2.1. Data Pre-Processing
3.2.2. Data Projection and Alignment
3.2.3. Zero-Shot Segmentation with a Web-Based Image Annotation Platform
3.2.4. Mask Reprojection and Pooling
3.3. Experiment and Assessment
4. Results and Discussion
- (1)
- Occlusions. Sidewalks can be severely occluded by tree canopies in satellite imagery, leading to incomplete segmentation of sidewalks. Occlusions to sidewalks by vehicles and other street objects are much less a concern when satellite imagery is used, but they limit what can be extracted from mobile LiDAR point clouds on busy street environments. On the other hand, mobile LiDAR data can capture data about sidewalks under tree canopies well. Therefore, combining mobile LiDAR data with satellite imagery can address each method’s weakness and allow for the complete extraction of sidewalks with SAM in most cases (Figure 6). However, we have found several pitfalls in using SAM. SAM-based zero-shot learning on our images was not stable, as SAM crashed multiple times. A considerable number of prompts, specifically clicks on areas in need of segmentation, are needed to achieve good segmentation. This is likely due to the size and resolution of these images, which are as large as . In other words, SAM can work more effectively with satellite and BEV images with smaller fields of view or lower image resolutions. However, analyzing satellite imagery or BEV images at smaller patches may result in an impractical larger number of interactions and/or lower performance in segmentation.There is a need to automate the prompts by staging a proposal generation framework before SAM. This is one of our future research directions.
- (2)
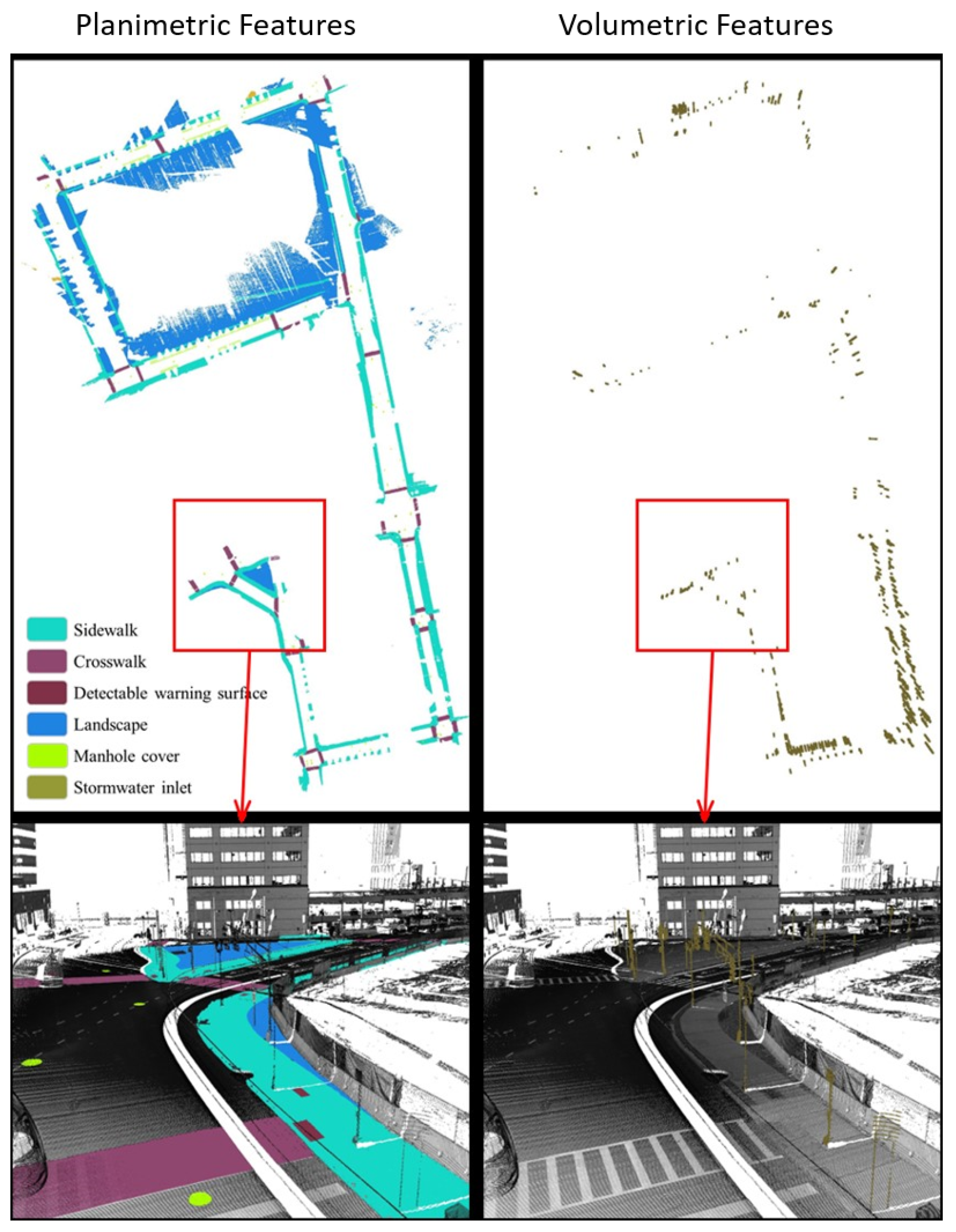
- Small volumetric features. It is generally difficult to extract small volumetric pedestrian infrastructure features, such as fire hydrants, parking meters, and posts, as well as small planimetric features, such as manhole covers, from either satellite imagery or BEV images generated from mobile LiDAR data. But they can be identified and segmented in high quality with SAM with very few prompts from street-view images that are generated from mobile LiDAR point-cloud data (Figure 7).
- (3)
- Planimetric features. The SAM models achieved remarkable performance in segmenting planimetric pedestrian infrastructure features such as sidewalks, crosswalks, detectable warning surfaces, and curb ramps under zero-shot learning scenarios on street-view images that are generated from mobile LiDAR point clouds with only ground and low vegetation classes (Figure 7). Very few prompts are needed to achieve complete segmentation of these features. The exception cases are streets with significant amounts of street-level occlusions, such as on-street parking. On the other hand, over-segmentation of planimetric pedestrian infrastructure features can happen frequently in street-view images generated from mobile LiDAR point clouds with all classes (Figure 8).
- (4)
- Color versus reflectance images. Segmenting pedestrian infrastructure objects in BEV and street-level images with color pixel values in some cases is easier than that of those intensity-based images as the color provides stronger clues about the boundary of these objects in the images. But this is only true in cases where the shadow is not of a concern. The intensity values, representing the strength of laser reflectance, are not influenced by shadows and light conditions. They are consistent for the same types of materials. In addition, the color information in Rep. 3, 4, 7, and 9 in Figure 3 are the results of data fusion, which involves aligning outputs of the laser scanners and cameras while the platform hosting them is moving at 10–40 miles per hour. The error in alignment is inevitable but will have significant impacts on the quality of data fusion.
- (5)
- Street-view images. Street-level images with intensity values generated from mobile LiDAR data have the overall best performance in working with SAM to segment both planimetric and volumetric pedestrian infrastructure features. But if street-level images, those generated from mobile LiDAR data, are used as the sole source of data for extracting pedestrian infrastructure objects, we must address the street-level occlusion problem. One way to alleviate the problem is to conduct nighttime data collection, as laser scanning alone is not impacted by daylight, and there will be far fewer occlusions due to vehicles at night. In addition, this can be done through automated recognition of the presence of street occlusion objects and automated filling of occluded areas.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lo, R.H. Walkability: What is it? J. Urban. 2009, 2, 145–166. [Google Scholar] [CrossRef]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Azmi, D.I.; Karim, H.A. Implications of walkability towards promoting sustainable urban neighbourhood. Procedia-Soc. Behav. Sci. 2012, 50, 204–213. [Google Scholar] [CrossRef]
- Gamache, S.; Routhier, F.; Morales, E.; Vandersmissen, M.H.; Boucher, N. Mapping review of accessible pedestrian infrastructures for individuals with physical disabilities. Disabil. Rehabil. Assist. Technol. 2019, 14, 410–422. [Google Scholar] [CrossRef]
- Frackelton, A.; Grossman, A.; Palinginis, E.; Castrillon, F.; Elango, V.; Guensler, R. Measuring walkability: Development of an automated sidewalk quality assessment tool. Suburb. Sustain. 2013, 1, 4. [Google Scholar] [CrossRef]
- Cahen, A.J.; Dannenberg, A.L.; Kraft, M.K. Municipal Sidewalk Inventories: A Tool for Equity and ADA Compliance. SSRN 2022, 4100935. [Google Scholar] [CrossRef]
- Kang, B.; Lee, S.; Zou, S. Developing sidewalk inventory data using street view images. Sensors 2021, 21, 3300. [Google Scholar] [CrossRef]
- Hosseini, M.; Araujo, I.B.; Yazdanpanah, H.; Tokuda, E.K.; Miranda, F.; Silva, C.T.; Cesar, R.M., Jr. Sidewalk measurements from satellite images: Preliminary findings. arXiv 2021, arXiv:2112.06120. [Google Scholar]
- Hosseini, M.; Saugstad, M.; Miranda, F.; Sevtsuk, A.; Silva, C.T.; Froehlich, J.E. Towards global-scale crowd + AI techniques to map and assess sidewalks for people with disabilities. arXiv 2022, arXiv:2206.13677. [Google Scholar]
- Hosseini, M.; Sevtsuk, A.; Miranda, F.; Cesar Jr, R.M.; Silva, C.T. Mapping the walk: A scalable computer vision approach for generating sidewalk network datasets from aerial imagery. Comput. Environ. Urban Syst. 2023, 101, 101950. [Google Scholar] [CrossRef]
- Luo, J.; Wu, G.; Wei, Z.; Boriboonsomsin, K.; Barth, M. Developing an aerial-image-based approach for creating digital sidewalk inventories. Transp. Res. Rec. 2019, 2673, 499–507. [Google Scholar] [CrossRef]
- Senlet, T.; Elgammal, A. Segmentation of occluded sidewalks in satellite images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 805–808. [Google Scholar]
- Ai, C.; Tsai, Y. Automated sidewalk assessment method for americans with disabilities act compliance using three-dimensional mobile lidar. Transp. Res. Rec. 2016, 2542, 25–32. [Google Scholar] [CrossRef]
- Hou, Q.; Ai, C. A network-level sidewalk inventory method using mobile LiDAR and deep learning. Transp. Res. Part C Emerg. Technol. 2020, 119, 102772. [Google Scholar] [CrossRef]
- Horváth, E.; Pozna, C.; Unger, M. Real-time LiDAR-based urban road and sidewalk detection for autonomous vehicles. Sensors 2021, 22, 194. [Google Scholar] [CrossRef] [PubMed]
- Omar, K.S.; Moreira, G.; Hodczak, D.; Hosseini, M.; Miranda, F. Crowdsourcing and Sidewalk Data: A Preliminary Study on the Trustworthiness of OpenStreetMap Data in the US. arXiv 2022, arXiv:2210.02350. [Google Scholar]
- Erraguntla, M.; Delen, D.; Agrawal, R.K.; Madanagopal, K.; Mayer, R. Mobile-Based Sidewalk Inventory App for Smart Communities, Health, and Safety. Suburb. Sustain. 2017, 5, 3. [Google Scholar]
- Luaces, M.R.; Fisteus, J.A.; Sánchez-Fernández, L.; Munoz-Organero, M.; Balado, J.; Díaz-Vilariño, L.; Lorenzo, H. Accessible routes integrating data from multiple sources. ISPRS Int. J. Geo-Inf. 2020, 10, 7. [Google Scholar] [CrossRef]
- Huang, K.; Shi, B.; Li, X.; Li, X.; Huang, S.; Li, Y. Multi-Modal Sensor Fusion for Auto Driving Perception: A Survey. arXiv 2022, arXiv:2202.02703. [Google Scholar]
- Ning, H.; Ye, X.; Chen, Z.; Liu, T.; Cao, T. Sidewalk extraction using aerial and street view images. Environ. Plan. Urban Anal. City Sci. 2022, 49, 7–22. [Google Scholar] [CrossRef]
- Hara, K.; Sun, J.; Moore, R.; Jacobs, D.; Froehlich, J. Tohme: Detecting curb ramps in google street view using crowdsourcing, computer vision, and machine learning. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 189–204. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Rao, A.S.; Gubbi, J.; Palaniswami, M.; Wong, E. A vision-based system to detect potholes and uneven surfaces for assisting blind people. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Li, Z.; Rahman, M.; Robucci, R.; Banerjee, N. Presight: Enabling real-time detection of accessibility problems on sidewalks. In Proceedings of the 2017 14th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), San Diego, CA, USA, 12–14 June 2017; pp. 1–9. [Google Scholar]
- Schwartz, M. Human centric accessibility graph for environment analysis. Autom. Constr. 2021, 127, 103557. [Google Scholar] [CrossRef]
- Esmorís, A.M.; Vilariño, D.L.; Arango, D.F.; Varela-García, F.A.; Cabaleiro, J.C.; Rivera, F.F. Characterizing zebra crossing zones using LiDAR data. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 1767–1788. [Google Scholar] [CrossRef]
- Xia, J.; Gong, J. Computer vision based first floor elevation estimation from mobile LiDAR data. Autom. Constr. 2024, 159, 105258. [Google Scholar] [CrossRef]
- Xia, J.; Gong, J. Precise indoor localization with 3D facility scan data. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1243–1259. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]
- Microsoft COCO: Common Objects in Context. Available online: https://cocodataset.org/ (accessed on 7 November 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pedestrian Infrastructure Features | Rep. 1 | Rep. 2 | Rep. 3 | Rep. 4 | Rep. 5 | Rep. 6 | Rep. 7 | Rep. 8 | Rep. 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Planimetric features | Sidewalk | P | P | P | P | P | C | C | C | C |
| Crosswalk | C | C | C | C | C | C | C | C | C | |
| Curb ramp | P | P | P | P | N | C | C | C | C | |
| Landscape | P | P | P | P | P | C | C | P | P | |
| Stair | N | N | P | P | N | N | N | C | C | |
| Detectable warning surface | N | C | N | C | N | C | C | C | C | |
| Storm water inlet | N | N | N | N | N | C | C | C | C | |
| Manhole cover | N | N | N | N | N | C | C | C | C | |
| Traffic barrier | N | N | N | N | N | N | N | C | C | |
| Retaining wall | N | N | N | N | N | C | C | C | C | |
| Volumetric features | Bench | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| Bollard | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Fire hydrant | N | N | N | N | N | N | N | C | C | |
| Mailbox | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Memorial | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Phone booth | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Parking meter | N | N | N | N | N | C | C | C | C | |
| Post | N | N | N | N | N | N | N | C | C | |
| Public Sculpture | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Public vending machine | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Tree trunk | N | N | N | N | N | N | N | C | C | |
| Tree Canopy | N | N | P | P | P | N | N | P | P | |
| Waste container | N | N | N | N | N | N | N | C | C |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, J.; Gong, G.; Liu, J.; Zhu, Z.; Tang, H. Pedestrian-Accessible Infrastructure Inventory: Enabling and Assessing Zero-Shot Segmentation on Multi-Mode Geospatial Data for All Pedestrian Types. J. Imaging 2024, 10, 52. https://doi.org/10.3390/jimaging10030052
Xia J, Gong G, Liu J, Zhu Z, Tang H. Pedestrian-Accessible Infrastructure Inventory: Enabling and Assessing Zero-Shot Segmentation on Multi-Mode Geospatial Data for All Pedestrian Types. Journal of Imaging. 2024; 10(3):52. https://doi.org/10.3390/jimaging10030052
Chicago/Turabian StyleXia, Jiahao, Gavin Gong, Jiawei Liu, Zhigang Zhu, and Hao Tang. 2024. "Pedestrian-Accessible Infrastructure Inventory: Enabling and Assessing Zero-Shot Segmentation on Multi-Mode Geospatial Data for All Pedestrian Types" Journal of Imaging 10, no. 3: 52. https://doi.org/10.3390/jimaging10030052