- Article

Automated Radiological Report Generation from Breast Ultrasound Images Using Vision and Language Transformers
- Shaheen Khatoon and
- Azhar Mahmood
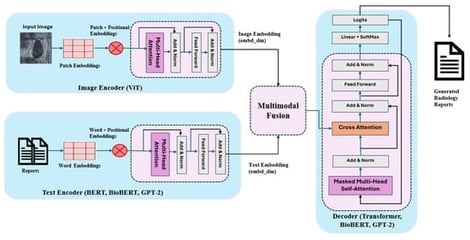
Breast ultrasound imaging is widely used for the detection and characterization of breast abnormalities; however, generating detailed and consistent radiological reports remains a labor-intensive and subjective process. Recent advances in deep learning have demonstrated the potential of automated report generation systems to support clinical workflows, yet most existing approaches focus on chest X-ray imaging and rely on convolutional–recurrent architectures with limited capacity to model long-range dependencies and complex clinical semantics. In this work, we propose a multimodal Transformer-based framework for automatic breast ultrasound report generation that integrates visual and textual information through cross-attention mechanisms. The proposed architecture employs a Vision Transformer (ViT) to extract rich spatial and morphological features from ultrasound images. For textual embedding, pretrained language models (BERT, BioBERT, and GPT-2) are implemented in various encoder–decoder configurations to leverage both general linguistic knowledge and domain-specific biomedical semantics. A multimodal Transformer decoder is implemented to autoregressively generate diagnostic reports by jointly attending to visual features and contextualized textual embeddings. We conducted an extensive quantitative evaluation using standard report generation metrics, including BLEU, ROUGE-L, METEOR, and CIDEr, to assess lexical accuracy, semantic alignment, and clinical relevance. Experimental results demonstrate that BioBERT-based models consistently outperform general domain counterparts in clinical specificity, while GPT-2-based decoders improve linguistic fluency.
6 February 2026