







J. Imaging 2025, 11(12), 421; https://doi.org/10.3390/jimaging11120421 - 22 Nov 2025
Abstract
Multi-modal object tracking (MMOT) has received widespread attention for the ability to overcome single-sensor perception limitations. However, existing methods encounter several critical challenges. Representation learning and generalization capabilities of models are constrained by the inherent heterogeneity of cross-task multi-modal data and inter-modal synergy
[...] Read more.
Multi-modal object tracking (MMOT) has received widespread attention for the ability to overcome single-sensor perception limitations. However, existing methods encounter several critical challenges. Representation learning and generalization capabilities of models are constrained by the inherent heterogeneity of cross-task multi-modal data and inter-modal synergy imbalance. Particularly, in dynamically changing complex scenarios, the reliability and stability of data significantly degrade, further exacerbating the difficulty in multi-modal consistent perception and aggregation. To tackle the above issues, we propose SMUTrack, a unified framework with global shared parameters integrating three downstream MMOT tasks. SMUTrack implements a batch merging-and-splitting alternating strategy, coupled with multi-task joint training, to establish latent correlations across inter- and intra-task modalities, effectively avoiding over-reliance on certain modalities. Concurrently, we design a hierarchical modality synergy and reinforcement (HMSR) module, and a gated fusion and context awareness (GFCA) module to enable progressive multi-modal information exchange and integration, yielding the more discriminative and robust multi-modal representation. More importantly, we introduce a spatial–temporal information propagation (SIP) mechanism, which synchronously learns object trajectory cues and appearance variations to effectively build contextual relationships in long-term video tracking. Experimental results definitively validate the outstanding performance of SMUTrack on mainstream MMOT datasets, exhibiting its powerful adaptability to various MMOT tasks.
Full article
(This article belongs to the Section Computer Vision and Pattern Recognition)
►
Show Figures
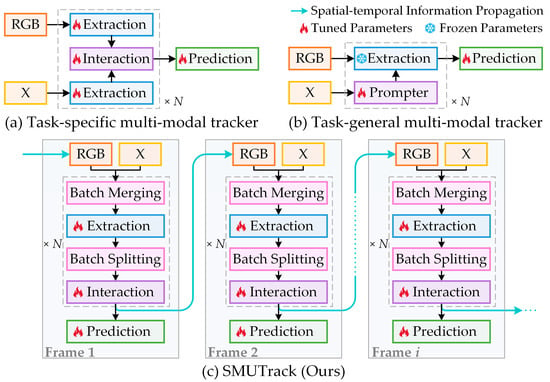
Figure 1




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}