

Enhancing Apple Cultivar Classification Using Multiview Images


Abstract
1. Introduction
- evaluation of three multiview options for fruit cultivar classification to follow human expert
- presentation of a specific dataset for apple cultivar classification using multiple views per fruit
- dataset preprocessing to utilize multiview information without using a true multiview model architecture to reduce model size without applying shrinking techniques
- explore limitations of the cultivar classification approaches.
2. Related Work
3. Dataset Collection and Preparation
3.1. Image Collection
3.2. Image Preprocessing
- a dataset where the images from each view are treated as separate channels.
- a dataset where all images are stored in one folder per class. This mixes all views into one single folder.
- a dataset using specifically preprocessed images, where the corresponding images of one apple are combined into one image containing all views.
4. Classification Method
4.1. Model Selection
4.2. Model Training
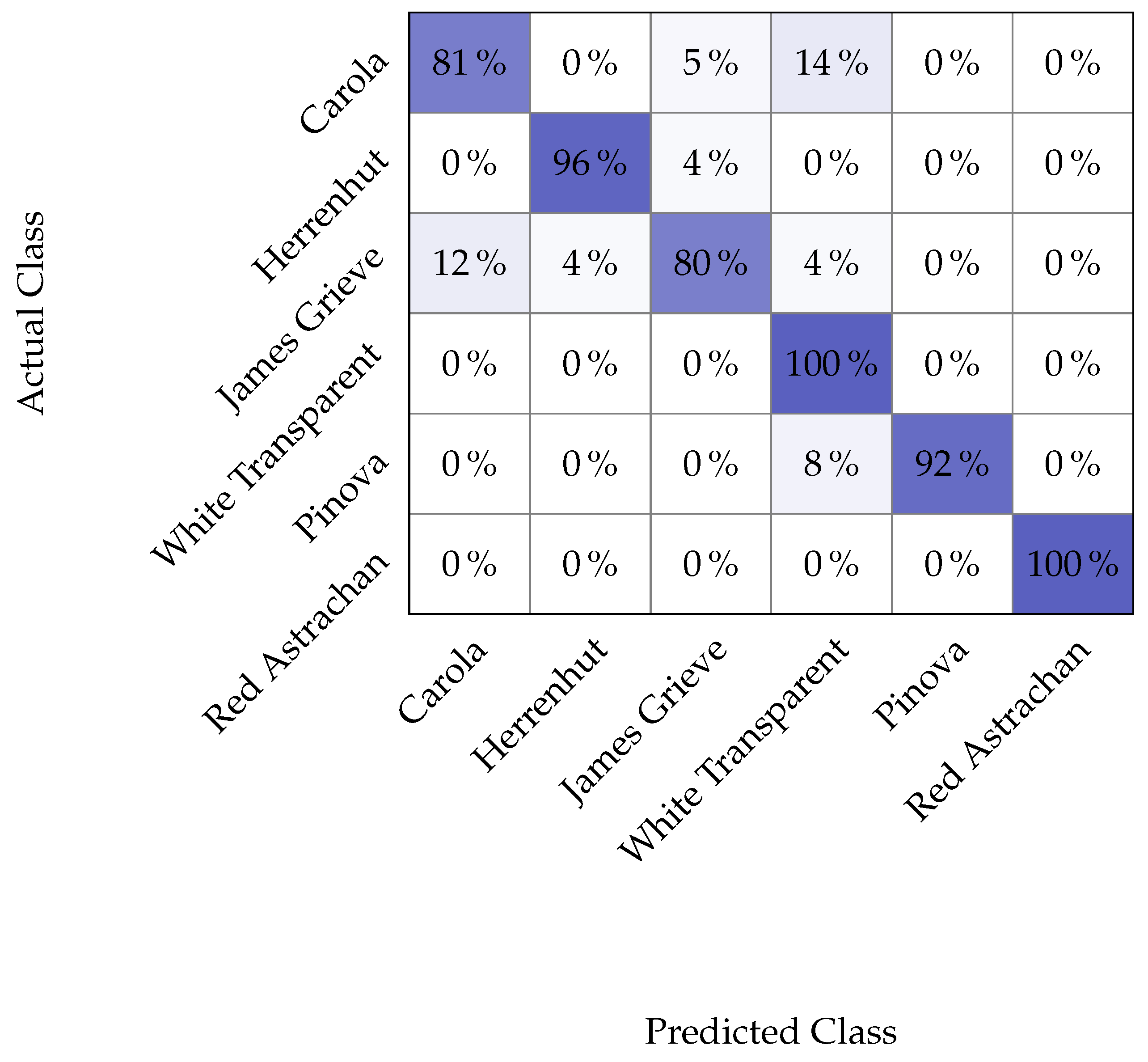
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zerbe, S. A Century of Practice and Experiences of the Restoration of Land-Use Types and Ecosystems. In Restoration of Multifunctional Cultural Landscapes: Merging Tradition and Innovation for a Sustainable Future; Springer: Berlin/Heidelberg, Germany, 2022; pp. 313–380. [Google Scholar]
- Zerbe, S. Traditional Agroforestry Systems. In Restoration of Ecosystems–Bridging Nature and Humans: A Transdisciplinary Approach; Springer: Berlin/Heidelberg, Germany, 2023; pp. 409–418. [Google Scholar]
- Kellerhals, M.; Szalatnay, D.; Hunziker, K.; Duffy, B.; Nybom, H.; Ahmadi-Afzadi, M.; Höfer, M.; Richter, K.; Lateur, M. European pome fruit genetic resources evaluated for disease resistance. Trees 2012, 26, 179–189. [Google Scholar] [CrossRef]
- Flachowsky, H.; Höfer, M. Die Deutsche Genbank Obst, ein dezentrales Netzwerk zur nachhaltigen Erhaltung genetischer Ressourcen bei Obst. J. Fur-Kult.-J. Cultiv. Plants 2010, 62, 9. [Google Scholar]
- Reim, S.; Schiffler, J.; Braun-Lüllemann, A.; Schuster, M.; Flachowsky, H.; Höfer, M. Genetic and Pomological Determination of the Trueness-to-Type of Sweet Cherry Cultivars in the German National Fruit Genebank. Plants 2023, 12, 205. [Google Scholar] [CrossRef]
- Höfer, M.; Eldin Ali, M.A.M.S.; Sellmann, J.; Peil, A. Phenotypic evaluation and characterization of a collection of Malus species. Genet. Resour. Crop. Evol. 2014, 61, 943–964. [Google Scholar] [CrossRef]
- Krug, S.; Hutschenreuther, T. A Case Study toward Apple Cultivar Classification Using Deep Learning. AgriEngineering 2023, 5, 814–828. [Google Scholar] [CrossRef]
- Silva, B.; Barbosa-Anda, F.R.; Batista, J. Exploring Multi-Loss Learning for Multi-View Fine-Grained Vehicle Classification. J. Intell. Robot. Syst. 2022, 105, 43. [Google Scholar] [CrossRef]
- Seeland, M.; Mäder, P. Multi-view classification with convolutional neural networks. PLoS ONE 2021, 16, e0245230. [Google Scholar] [CrossRef]
- Keles, O.; Taner, A. Classification of hazelnut varieties by using artificial neural network and discriminant analysis. Span. J. Agric. Res. 2021, 19, e0211. [Google Scholar] [CrossRef]
- Taner, A.; Öztekin, Y.B.; Duran, H. Performance analysis of deep learning CNN models for variety classification in hazelnut. Sustainability 2021, 13, 6527. [Google Scholar] [CrossRef]
- Ropelewska, E.; Piecko, J. Discrimination of tomato seeds belonging to different cultivars using machine learning. Eur. Food Res. Technol. 2022, 248, 685–705. [Google Scholar] [CrossRef]
- Ropelewska, E.; Sabanci, K.; Aslan, M.F. Discriminative power of geometric parameters of different cultivars of sour cherry pits determined using machine learning. Agriculture 2021, 11, 1212. [Google Scholar] [CrossRef]
- Pandey, R.; Uziel, S.; Hutschenreuther, T.; Krug, S. Towards Deploying DNN Models on Edge for Predictive Maintenance Applications. Electronics 2023, 12, 639. [Google Scholar] [CrossRef]
- Pandey, R.; Uziel, S.; Hutschenreuther, T.; Krug, S. Weighted Pruning with Filter Search to Deploy DNN Models on Microcontrollers. In Proceedings of the IEEE 12th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Dortmund, Germany, 7–9 September 2023; Volume 1, pp. 1077–1082. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Christodoulou, M.D.; Clark, J.Y.; Culham, A. The Cinderella discipline: Morphometrics and their use in botanical classification. Bot. J. Linn. Soc. 2020, 194, 385–396. [Google Scholar] [CrossRef]
- Katal, N.; Rzanny, M.; Mäder, P.; Wäldchen, J. Deep learning in plant phenological research: A systematic literature review. Front. Plant Sci. 2022, 13, 805738. [Google Scholar] [CrossRef]
- Wäldchen, J.; Rzanny, M.; Seeland, M.; Mäder, P. Automated plant species identification—Trends and future directions. PLoS Comput. Biol. 2018, 14, e1005993. [Google Scholar] [CrossRef]
- Wäldchen, J.; Mäder, P. Machine learning for image based species identification. Methods Ecol. Evol. 2018, 9, 2216–2225. [Google Scholar] [CrossRef]
- Mäder, P.; Boho, D.; Rzanny, M.; Seeland, M.; Wittich, H.C.; Deggelmann, A.; Wäldchen, J. The Flora Incognita app–interactive plant species identification. Methods Ecol. Evol. 2021, 12, 1335–1342. [Google Scholar] [CrossRef]
- Kahl, S.; Wilhelm-Stein, T.; Klinck, H.; Kowerko, D.; Eibl, M. Recognizing birds from sound-the 2018 BirdCLEF baseline system. arXiv 2018, arXiv:1804.07177. [Google Scholar]
- Kahl, S.; Wood, C.M.; Eibl, M.; Klinck, H. BirdNET: A deep learning solution for avian diversity monitoring. Ecol. Inform. 2021, 61, 101236. [Google Scholar] [CrossRef]
- Mena, F.; Arenas, D.; Nuske, M.; Dengel, A. Common practices and taxonomy in deep multi-view fusion for remote sensing applications. arXiv 2024, arXiv:2301.01200. [Google Scholar]
- Yan, X.; Hu, S.; Mao, Y.; Ye, Y.; Yu, H. Deep multi-view learning methods: A review. Neurocomputing 2021, 448, 106–129. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Gerdan, D.; Beyaz, A.; Vatandaş, M. Classification of apple varieties: Comparison of ensemble learning and naive bayes algorithms in H2O framework. J. Agric. Fac. Gaziosmanpa 2020, 37, 9–16. [Google Scholar]
- Gururaj, N.; Vinod, V.; Vijayakumar, K. Deep grading of mangoes using Convolutional Neural Network and Computer Vision. Multimed. Tools Appl. 2023, 82, 39525–39550. [Google Scholar] [CrossRef]
- Tapia-Mendez, E.; Cruz-Albarran, I.A.; Tovar-Arriaga, S.; Morales-Hernandez, L.A. Deep Learning-Based Method for Classification and Ripeness Assessment of Fruits and Vegetables. Appl. Sci. 2023, 13, 12504. [Google Scholar] [CrossRef]
- Zhang, L.; Hao, Q.; Cao, J. Attention-Based Fine-Grained Lightweight Architecture for Fuji Apple Maturity Classification in an Open-World Orchard Environment. Agriculture 2023, 13, 228. [Google Scholar] [CrossRef]
- Rzanny, M.; Wittich, H.C.; Mäder, P.; Deggelmann, A.; Boho, D.; Wäldchen, J. Image-based automated recognition of 31 poaceae species: The most relevant perspectives. Front. Plant Sci. 2022, 12, 804140. [Google Scholar] [CrossRef]
- Peng, Y.; Zhao, S.; Liu, J. Fused deep features-based grape varieties identification using support vector machine. Agriculture 2021, 11, 869. [Google Scholar] [CrossRef]
- Machado, G.; Pereira, M.B.; Nogueira, K.; Dos Santos, J.A. Facing the void: Overcoming missing data in multi-view imagery. IEEE Access 2022, 11, 12547–12554. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Fei, L.; Zhang, B.; Xu, Y.; Zhang, Z.; Li, J. A survey on incomplete multiview clustering. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 1136–1149. [Google Scholar] [CrossRef]
- Tang, J.; Hou, Z.; Yu, X.; Fu, S.; Tian, Y. Multi-view cost-sensitive kernel learning for imbalanced classification problem. Neurocomputing 2023, 552, 126562. [Google Scholar] [CrossRef]
- Franczyk, B.; Hernes, M.; Kozierkiewicz, A.; Kozina, A.; Pietranik, M.; Roemer, I.; Schieck, M. Deep learning for grape variety recognition. Procedia Comput. Sci. 2020, 176, 1211–1220. [Google Scholar] [CrossRef]
- Schieck, M.; Krajsic, P.; Loos, F.; Hussein, A.; Franczyk, B.; Kozierkiewicz, A.; Pietranik, M. Comparison of deep learning methods for grapevine growth stage recognition. Comput. Electron. Agric. 2023, 211, 107944. [Google Scholar] [CrossRef]
- Suresha, M.; Shilpa, N.; Soumya, B. Apples grading based on SVM classifier. Int. J. Comput. Appl. 2012, 975, 8878. [Google Scholar]
- Miriti, E. Classification of Selected Apple Fruit Varieties Using Naive Bayes. Ph.D. Thesis, University of Nairobi, Nairobi, Kenya, 2016. [Google Scholar]
- Sabancı, K. Different apple varieties classification using kNN and MLP algorithms. Int. J. Intell. Syst. Appl. Eng. 2016, 4, 166–169. [Google Scholar] [CrossRef]
- Sau, S.; Ucchesu, M.; D’hallewin, G.; Bacchetta, G. Potential use of seed morpho-colourimetric analysis for Sardinian apple cultivar characterisation. Comput. Electron. Agric. 2019, 162, 373–379. [Google Scholar] [CrossRef]
- Liu, C.; Han, J.; Chen, B.; Mao, J.; Xue, Z.; Li, S. A novel identification method for apple (Malus domestica Borkh.) cultivars based on a deep convolutional neural network with leaf image input. Symmetry 2020, 12, 217. [Google Scholar] [CrossRef]
- Ropelewska, E. The application of image processing for cultivar discrimination of apples based on texture features of the skin, longitudinal section and cross-section. Eur. Food Res. Technol. 2021, 247, 1319–1331. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Classification and grading of multiple varieties of apple fruit. Food Anal. Methods 2021, 14, 1359–1368. [Google Scholar] [CrossRef]
- Shruthi, U.; Narmadha, K.S.; Meghana, E.; Meghana, D.; Lakana, K.; Bhuvan, M. Apple Varieties Classification using Light Weight CNN Model. In Proceedings of the 4th International Conference on Circuits, Control, Communication and Computing, Bangalore, India, 21–23 December 2022; pp. 68–72. [Google Scholar]
- Chen, J.; Han, J.; Liu, C.; Wang, Y.; Shen, H.; Li, L. A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment. Symmetry 2022, 14, 1671. [Google Scholar] [CrossRef]
- García Cortés, S.; Menéndez Díaz, A.; Oliveira Prendes, J.A.; Bello García, A. Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification. Agronomy 2022, 12, 2856. [Google Scholar] [CrossRef]
- Hasan, M.A. Classification of apple types using principal component analysis and K-nearest neighbor. Int. J. Inf. Syst. Technol. Data Sci. 2023, 1, 15–22. [Google Scholar] [CrossRef]
- Taner, A.; Mengstu, M.T.; Selvi, K.Ç.; Duran, H.; Kabaş, Ö.; Gür, İ.; Karaköse, T.; Gheorghiță, N.E. Multiclass apple varieties classification using machine learning with histogram of oriented gradient and color moments. Appl. Sci. 2023, 13, 7682. [Google Scholar] [CrossRef]
- Kılıçarslan, S.; Dönmez, E.; Kılıçarslan, S. Identification of apple varieties using hybrid transfer learning and multi-level feature extraction. Eur. Food Res. Technol. 2023, 250, 895–909. [Google Scholar] [CrossRef]
- Yu, F.; Lu, T.; Xue, C. Deep Learning-Based Intelligent Apple Variety Classification System and Model Interpretability Analysis. Foods 2023, 12, 885. [Google Scholar] [CrossRef]
- Taner, A.; Mengstu, M.T.; Selvi, K.Ç.; Duran, H.; Gür, İ.; Ungureanu, N. Apple Varieties Classification Using Deep Features and Machine Learning. Agriculture 2024, 14, 252. [Google Scholar] [CrossRef]
- Minakova, S.; Stefanov, T. Memory-Throughput Trade-off for CNN-based Applications at the Edge. ACM Trans. Des. Autom. Electron. Syst. 2022, 28, 1–26. [Google Scholar] [CrossRef]
- Garip, Z.; Ekinci, E.; Çimen, M.E. A comparative study of optimization algorithms for feature selection on ML-based classification of agricultural data. Clust. Comput. 2023, 1, 1–22. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 26 February 2024).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 26 February 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | ML Tool | Capture | Images | Cultivars | Plant Organ | Fruit Views | Expert Appr. | Multiview |
|---|---|---|---|---|---|---|---|---|---|
| [38] | 2012 | SVM | Web | 90 | 2 | Fruit | Outside | no | no |
| [39] | 2016 | Naive Bayes | Phone | 150 | 3 | Fruit | Outside | no | no |
| [40] | 2016 | MLP/kNN | 90 | 3 | Fruit | Outside | no | no | |
| [41] | 2019 | LDA | Scanner | 25 | Seeds | no | no | ||
| [27] | 2020 | Naive Bayes | Spectral | 180 | 3 | Fruit | Outside | no | no |
| [42] | 2020 | CNN | Camera | 12,400 | 14 | Leaf | no | no | |
| [43] | 2021 | CNN | Scanner | 3 | Fruit | Outside, Cut | no | no | |
| [44] | 2021 | SVM | Public data | 13,000 | 6 | Fruit | Outside | no | no |
| [45] | 2022 | CCN | Public data | 7159 | 14 | Fruit | Outside | no | no |
| [46] | 2022 | Custom DL | Camera | 14,400 | 30 | Leaf | no | no | |
| [47] | 2022 | CNN | Camera | 9 | Fruit | Outside | no | no | |
| [48] | 2023 | kNN, SVM | 60 | 2 | Fruit | Outside | no | no | |
| [49] | 2023 | kNN, SVM, MLP | Camera | 5830 | 10 | Fruit | no | no | |
| [50] | 2023 | CNN | 120 | 6 | Fruit | no | no | ||
| [51] | 2023 | CNN | 8538 | 13 | Fruit | Outside | no | no | |
| [52] | 2024 | CNN | Camera | 5808 | 10 | Fruit | Outside | no | no |
| [7] | 2023 | CNN | Phone | 600 | 5 | Fruit | Cut | yes | no |
| ours | 2024 | CNN | Phone | 2030 | 6 | Fruit | Outside and Cut | yes | yes |
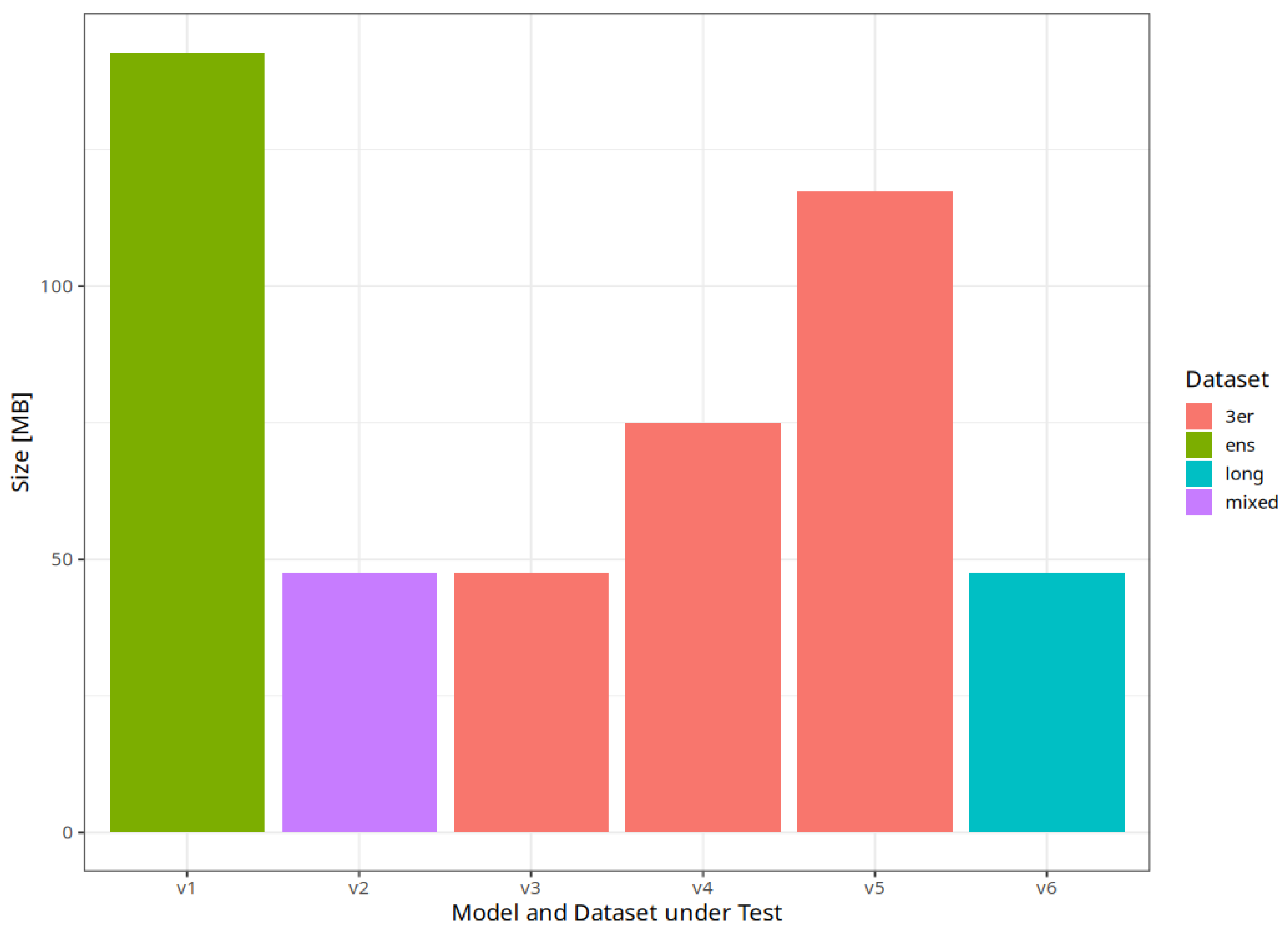
| Model | Image Size | Weights Memory | Parameters | Depth | Datasets |
|---|---|---|---|---|---|
| [px, px] | [MByte] | ||||
| EfficientNetB3 | 300, 300 | 47.6 | 12.3 M | 210 | 2, 3 |
| EfficientNetB4 | 380, 380 | 75 | 19.5 M | 258 | 3 |
| EfficientNetB5 | 456, 456 | 118 | 30.6 M | 312 | 3 |
| EfficientNetB3 Ensemble | 300, 300 | 144 | 37.5 M | 210 | 1 |
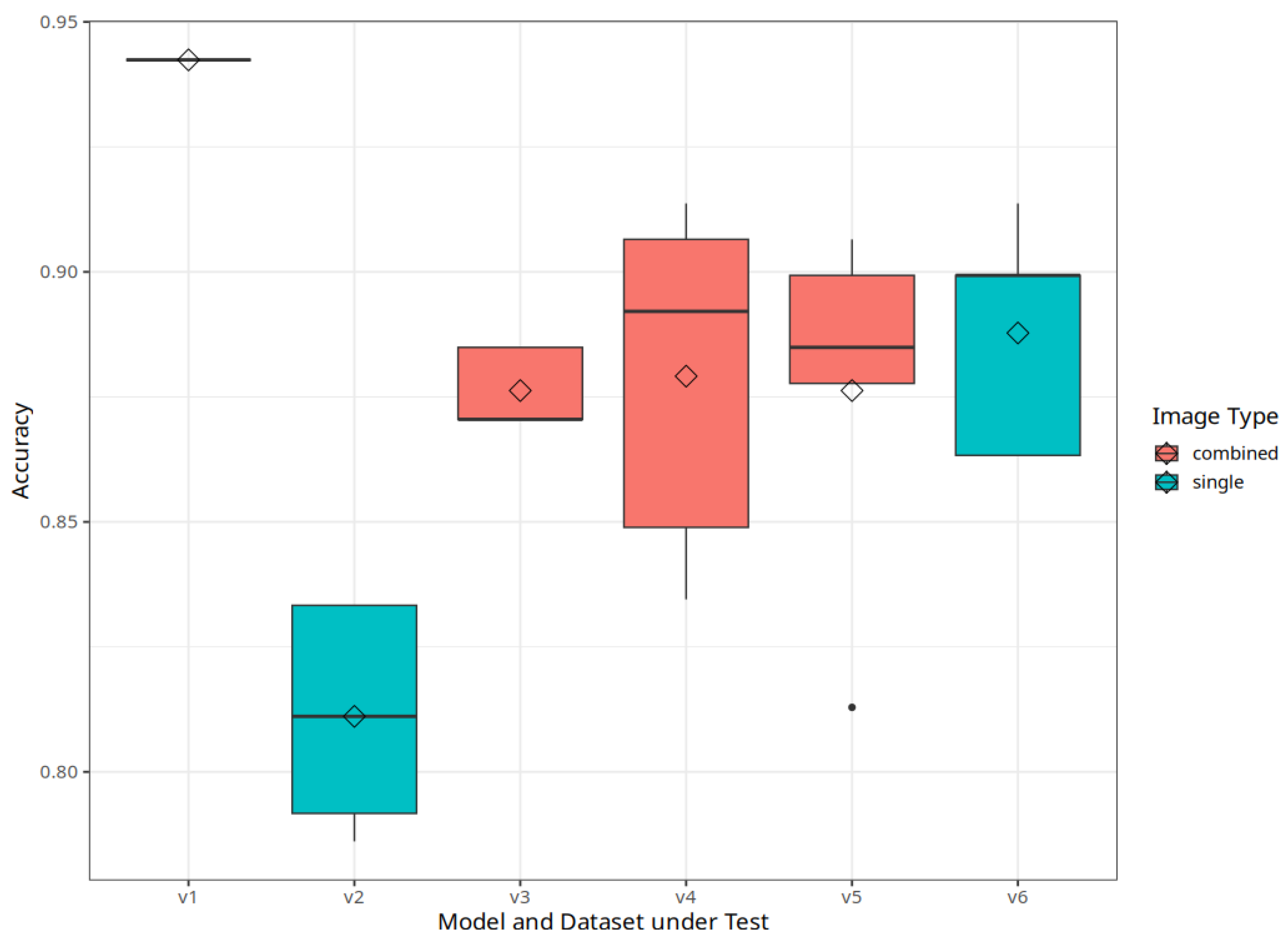
| Variant | Model | Dataset | Accuracy | Image Type | ||
|---|---|---|---|---|---|---|
| Max | Average | Deviation | ||||
| v1 | EfficientNetB3-Ensemble | ens | 0.9424 | 0.9424 | single | |
| v2 | EfficientNetB3 | mixed | 0.8333 | 0.8111 | 0.0223 | single |
| v3 | EfficientNetB3 | 3er | 0.8849 | 0.8763 | 0.0079 | combined |
| v4 | EfficientNetB4 | 3er | 0.9137 | 0.8791 | 0.0354 | combined |
| v5 | EfficientNetB5 | 3er | 0.9065 | 0.8763 | 0.0372 | combined |
| v6 | EfficientNetB3 | long | 0.9137 | 0.8878 | 0.0231 | single |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krug, S.; Hutschenreuther, T. Enhancing Apple Cultivar Classification Using Multiview Images. J. Imaging 2024, 10, 94. https://doi.org/10.3390/jimaging10040094
Krug S, Hutschenreuther T. Enhancing Apple Cultivar Classification Using Multiview Images. Journal of Imaging. 2024; 10(4):94. https://doi.org/10.3390/jimaging10040094
Chicago/Turabian StyleKrug, Silvia, and Tino Hutschenreuther. 2024. "Enhancing Apple Cultivar Classification Using Multiview Images" Journal of Imaging 10, no. 4: 94. https://doi.org/10.3390/jimaging10040094
APA StyleKrug, S., & Hutschenreuther, T. (2024). Enhancing Apple Cultivar Classification Using Multiview Images. Journal of Imaging, 10(4), 94. https://doi.org/10.3390/jimaging10040094