
Enabling Low-Dose In Vivo Benchtop X-ray Fluorescence Computed Tomography through Deep-Learning-Based Denoising

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Setup
2.2. Deep Blind Image Denoising Model
2.2.1. Dataset
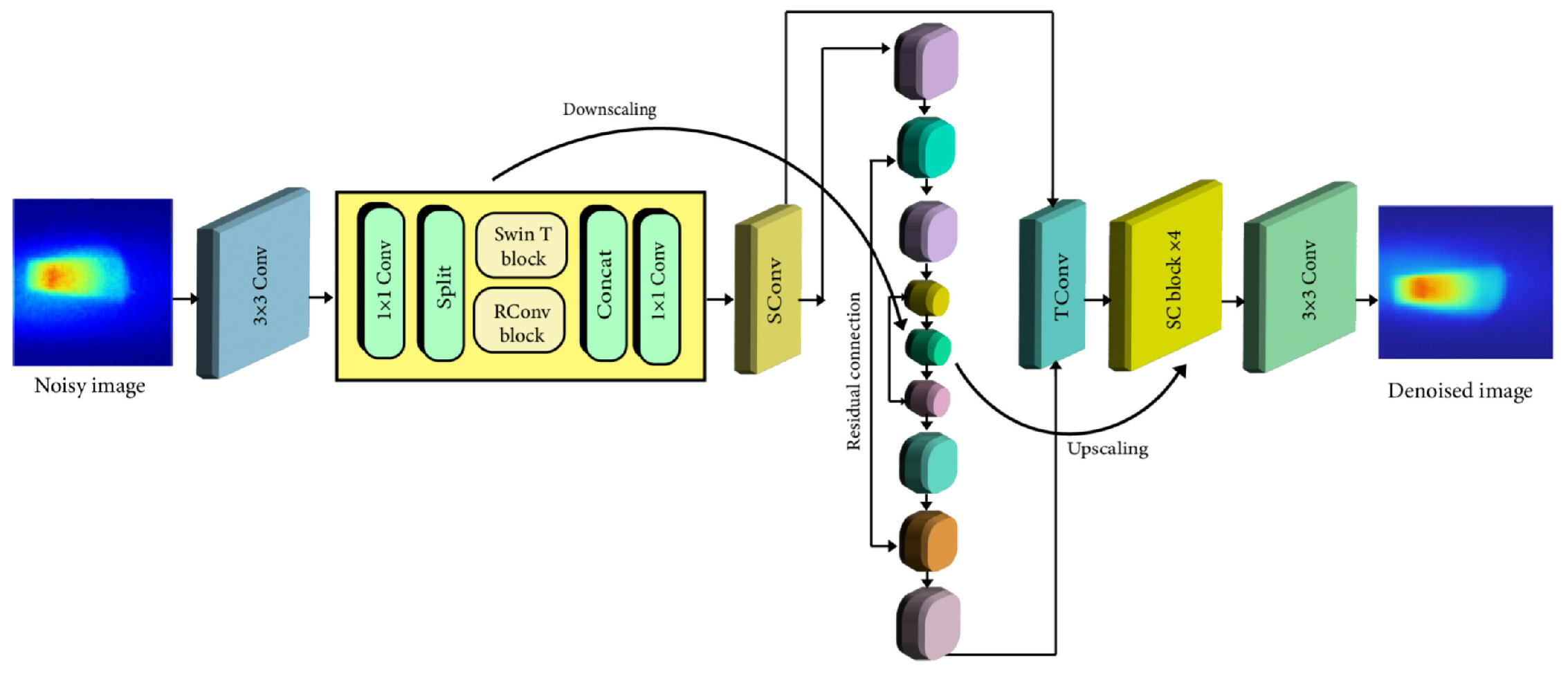
2.2.2. Proposed Model
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| XFCT | X-ray fluorescence computed tomography |
| XRF | X-ray fluorescence |
| AI | Artificial Intelligence |
| DL | Deep Learning |
| SCUNet | Swin-Conv-UNet |
| CT | Computed Tomography |
| PSNR | Peak signal-to-noise ratio |
| SSIM | Structural Similarity Index |
| BM3D | Block-Matching and 3D filtering |
| BM4D | Block-Matching and 3D filtering |
| MSE | Mean Squared Error |
| NLM | Non-local means |
| DnCNN | Denoising Convolutional Neural Network |
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Networks |
| Gd | Gadolinium |
| wt | Weight |
| Swin | Shifted window Transformer |
| keV | Kilo electron volt |
| mA | milliampere |
| CBCT | Cone-Beam Computed Tomography |
| MAP | Maximum A Posteriori |
| DRUNet | Dilated-Residual U-Net |
| SwinIR | Image Restoration Using Swin Transformer |
| SConv | Strided Convolution |
| TConv | Transposed Convolution |
| RConv | Residual Convolutional |
| SwinT | Swin Transformer |
| BW | Bin width |
| AWGN | Additive White Gaussian Noise |
References
- Staufer, T.; Grüner, F. Review of development and recent advances in biomedical X-ray fluorescence imaging. Int. J. Mol. Sci. 2023, 24, 10990. [Google Scholar] [CrossRef] [PubMed]
- Shaker, K.; Vogt, C.; Katsu-Jiménez, Y.; Kuiper, R.V.; Andersson, K.; Li, Y.; Larsson, J.C.; Rodriguez-Garcia, A.; Toprak, M.S.; Arsenian-Henriksson, M.; et al. Longitudinal in vivo X-ray fluorescence computed tomography with molybdenum nanoparticles. IEEE Trans. Med. Imaging 2020, 39, 3910–3919. [Google Scholar] [CrossRef] [PubMed]
- Manohar, N.; Reynoso, F.J.; Diagaradjane, P.; Krishnan, S.; Cho, S.H. Quantitative imaging of gold nanoparticle distribution in a tumor-bearing mouse using benchtop X-ray fluorescence computed tomography. Sci. Rep. 2016, 6, 22079. [Google Scholar] [CrossRef] [PubMed]
- Larsson, J.C.; Vogt, C.; Vågberg, W.; Toprak, M.S.; Dzieran, J.; Arsenian-Henriksson, M.; Hertz, H.M. High-spatial-resolution X-ray fluorescence tomography with spectrally matched nanoparticles. Phys. Med. Biol. 2018, 63, 164001. [Google Scholar] [CrossRef] [PubMed]
- Dao, A.T.N.; Mott, D.M.; Maenosono, S. Characterization of metallic nanoparticles based on the abundant usages of X-ray techniques. In Handbook of Nanoparticles; Springer International Publishing: Cham, Swizerland, 2015; pp. 217–244. [Google Scholar] [CrossRef]
- Takeda, T.; Yu, Q.; Yashiro, T.; Zeniya, T.; Wu, J.; Hasegawa, Y.; Hyodo, K.; Yuasa, T.; Dilmanian, F.; Akatsuka, T.; et al. Iodine imaging in thyroid by fluorescent X-ray CT with 0.05 mm spatial resolution. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2001, 467, 1318–1321. [Google Scholar] [CrossRef]
- Körnig, C.; Staufer, T.; Schmutzler, O.; Bedke, T.; Machicote, A.; Liu, B.; Liu, Y.; Gargioni, E.; Feliu, N.; Parak, W.J.; et al. In-situ X-ray fluorescence imaging of the endogenous iodine distribution in murine thyroids. Sci. Rep. 2022, 12, 2903. [Google Scholar] [CrossRef] [PubMed]
- Staufer, T.; Körnig, C.; Liu, B.; Liu, Y.; Lanzloth, C.; Schmutzler, O.; Bedke, T.; Machicote, A.; Parak, W.J.; Feliu, N.; et al. Enabling X-ray fluorescence imaging for in vivo immune cell tracking. Sci. Rep. 2023, 13, 11505. [Google Scholar] [CrossRef] [PubMed]
- Grüner, F.; Blumendorf, F.; Schmutzler, O.; Staufer, T.; Bradbury, M.; Wiesner, U.; Rosentreter, T.; Loers, G.; Lutz, D.; Richter, B.; et al. Localising functionalised gold-nanoparticles in murine spinal cords by X-ray fluorescence imaging and background-reduction through spatial filtering for human-sized objects. Sci. Rep. 2018, 8, 16561. [Google Scholar] [CrossRef]
- Kumar, K.; Fachet, M.; Al-Maatoq, M.; Chakraborty, A.; Khismatrao, R.S.; Oka, S.V.; Staufer, T.; Grüner, F.; Michel, T.; Walles, H.; et al. Characterization of a polychromatic microfocus X-ray fluorescence imaging setup with metallic contrast agents in a microphysiological tumor model. Front. Phys. 2023, 11, 1125143. [Google Scholar] [CrossRef]
- Zhang, S.; Li, L.; Chen, J.; Chen, Z.; Zhang, W.; Lu, H. Quantitative imaging of Gd nanoparticles in mice using benchtop cone-beam X-ray fluorescence computed tomography system. Int. J. Mol. Sci. 2019, 20, 2315. [Google Scholar] [CrossRef]
- Deng, L.; Ahmed, M.F.; Jayarathna, S.; Feng, P.; Wei, B.; Cho, S.H. A detector’s eye view (DEV)-based OSEM algorithm for benchtop X-ray fluorescence computed tomography (XFCT) image reconstruction. Phys. Med. Biol. 2019, 64, 08NT02. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.; Kim, T.; Lee, W.; Kim, H.; Kim, H.S.; Im, H.J.; Ye, S.J. Dynamic in vivo X-ray fluorescence imaging of gold in living mice exposed to gold nanoparticles. IEEE Trans. Med. Imaging 2019, 39, 526–533. [Google Scholar] [CrossRef]
- Jung, S.; Sung, W.; Ye, S.J. Pinhole X-ray fluorescence imaging of gadolinium and gold nanoparticles using polychromatic X-rays: A Monte Carlo study. Int. J. Nanomed. 2017, 12, 5805–5817. [Google Scholar] [CrossRef]
- Ahmad, M.; Bazalova-Carter, M.; Fahrig, R.; Xing, L. Optimized detector angular configuration increases the sensitivity of X-ray fluorescence computed tomography (XFCT). IEEE Trans. Med. Imaging 2014, 34, 1140–1147. [Google Scholar] [CrossRef] [PubMed]
- Cong, W.; Shen, H.; Cao, G.; Liu, H.; Wang, G. X-ray fluorescence tomographic system design and image reconstruction. J. X-ray Sci. Technol. 2013, 21, 1–8. [Google Scholar] [CrossRef]
- Jones, B.L.; Manohar, N.; Reynoso, F.; Karellas, A.; Cho, S.H. Experimental demonstration of benchtop X-ray fluorescence computed tomography (XFCT) of gold nanoparticle-loaded objects using lead-and tin-filtered polychromatic cone-beams. Phys. Med. Biol. 2012, 57, N457. [Google Scholar] [CrossRef] [PubMed]
- Cheong, S.K.; Jones, B.L.; Siddiqi, A.K.; Liu, F.; Manohar, N.; Cho, S.H. X-ray fluorescence computed tomography (XFCT) imaging of gold nanoparticle-loaded objects using 110 kVp X-rays. Phys. Med. Biol. 2010, 55, 647. [Google Scholar] [CrossRef] [PubMed]
- Feng, P.; Luo, Y.; Zhao, R.; Huang, P.; Li, Y.; He, P.; Tang, B.; Zhao, X. Reduction of Compton background noise for X-ray fluorescence computed tomography with deep learning. Photonics 2022, 9, 108. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Wang, J. A deep learning method for denoising based on a fast and flexible convolutional neural network. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Rahim, T.; Usman, M.A.; Shin, S.Y. A survey on contemporary computer-aided tumor, polyp, and ulcer detection methods in wireless capsule endoscopy imaging. Comput. Med. Imaging Graph. 2020, 85, 101767. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-dose CT with a residual encoder-decoder convolutional neural network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar] [CrossRef]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Krull, A.; Buchholz, T.O.; Jug, F. Noise2void-learning denoising from single noisy images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2129–2137. [Google Scholar]
- Sun, J.; Tappen, M.F. Learning non-local range Markov random field for image restoration. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2745–2752. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, L.; Chang, C.; Liu, C.; Zhang, L.; Cui, H. An image denoising method based on BM4D and GAN in 3D shearlet domain. Math. Probl. Eng. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Xu, P.; Chen, B.; Xue, L.; Zhang, J.; Zhu, L.; Duan, H. A new MNF–BM4D denoising algorithm based on guided filtering for hyperspectral images. ISA Trans. 2019, 92, 315–324. [Google Scholar] [CrossRef] [PubMed]
- Lefkimmiatis, S. Non-local color image denoising with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3587–3596. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Schmidt, U.; Roth, S. Shrinkage fields for effective image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2774–2781. [Google Scholar]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H.U. A General U-Shaped Transformer for Image Restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Li, Y.; Zhang, K.; Cao, J.; Timofte, R.; Van Gool, L.L. Bringing locality to vision transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Rehman, A.; Wang, Z. SSIM-based non-local means image denoising. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 217–220. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Heo, Y.C.; Kim, K.; Lee, Y. Image denoising using non-local means (NLM) approach in magnetic resonance (MR) imaging: A systematic review. Appl. Sci. 2020, 10, 7028. [Google Scholar] [CrossRef]
- Babu, D.; K Jose, S. Review on CNN based image denoising. In Proceedings of the International Conference on Systems, Energy & Environment (ICSEE), Singapore, 3–5 February 2021. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Y.; Liang, J.; Cao, J.; Zhang, Y.; Tang, H.; Fan, D.P.; Timofte, R.; Gool, L.V. Practical blind image denoising via Swin-Conv-UNet and data synthesis. Mach. Intell. Res. 2023, 20, 822–836. [Google Scholar] [CrossRef]
- Liang, T.; Jin, Y.; Li, Y.; Wang, T. Edcnn: Edge enhancement-based densely connected network with compound loss for low-dose ct denoising. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 193–198. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bin Widths | Noise Level | BM3D | BM4D | NLM | DnCNN | SCUNet | Proposed Model |
|---|---|---|---|---|---|---|---|
| BW-0.05 | 25% | 13.93 | 31.44 | 27.92 | 36.82 | 22.77 | 29.68 |
| 50% | 13.91 | 28.61 | 25.16 | 31.07 | 24.51 | 26.97 | |
| 75% | 13.89 | 29.18 | 24.58 | 24.75 | 25.29 | 31.44 | |
| BW-0.1 | 25% | 13.70 | 29.78 | 32.42 | 38.88 | 22.87 | 35.48 |
| 50% | 13.70 | 31.20 | 28.19 | 34.50 | 27.82 | 29.06 | |
| 75% | 13.67 | 27.02 | 27.71 | 27.75 | 26.77 | 29.33 | |
| BW-0.5 | 25% | 11.76 | 28.18 | 39.94 | 49.35 | 22.54 | 31.81 |
| 50% | 11.75 | 33.27 | 38.77 | 43.66 | 22.74 | 32.67 | |
| 75% | 11.75 | 31.22 | 36.75 | 38.40 | 25.58 | 39.05 |
| Bin Widths | Noise Level | BM3D | BM4D | NLM | DnCNN | SCUNet | Proposed Model |
|---|---|---|---|---|---|---|---|
| BW-0.05 | 25% | 0.073 | 0.7902 | 0.7435 | 0.9430 | 0.4661 | 0.7868 |
| 50% | 0.0720 | 0.7710 | 0.739 | 0.872 | 0.5177 | 0.8369 | |
| 75% | 0.071 | 0.7917 | 0.7156 | 0.7431 | 0.6472 | 0.8654 | |
| BW-0.1 | 25% | 0.0716 | 0.7425 | 0.7985 | 0.8594 | 0.6153 | 0.8284 |
| 50% | 0.0715 | 0.7154 | 0.7984 | 0.8023 | 0.6206 | 0.8658 | |
| 75% | 0.0712 | 0.7556 | 0.7801 | 0.7867 | 0.6453 | 0.8218 | |
| BW-0.5 | 25% | 0.0617 | 0.8349 | 0.8029 | 0.9139 | 0.5773 | 0.8786 |
| 50% | 0.0616 | 0.8314 | 0.7626 | 0.9014 | 0.4972 | 0.8466 | |
| 75% | 0.0615 | 0.8424 | 0.7611 | 0.7582 | 0.5290 | 0.8638 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoodian, N.; Rezapourian, M.; Inamdar, A.A.; Kumar, K.; Fachet, M.; Hoeschen, C. Enabling Low-Dose In Vivo Benchtop X-ray Fluorescence Computed Tomography through Deep-Learning-Based Denoising. J. Imaging 2024, 10, 127. https://doi.org/10.3390/jimaging10060127
Mahmoodian N, Rezapourian M, Inamdar AA, Kumar K, Fachet M, Hoeschen C. Enabling Low-Dose In Vivo Benchtop X-ray Fluorescence Computed Tomography through Deep-Learning-Based Denoising. Journal of Imaging. 2024; 10(6):127. https://doi.org/10.3390/jimaging10060127
Chicago/Turabian StyleMahmoodian, Naghmeh, Mohammad Rezapourian, Asim Abdulsamad Inamdar, Kunal Kumar, Melanie Fachet, and Christoph Hoeschen. 2024. "Enabling Low-Dose In Vivo Benchtop X-ray Fluorescence Computed Tomography through Deep-Learning-Based Denoising" Journal of Imaging 10, no. 6: 127. https://doi.org/10.3390/jimaging10060127
APA StyleMahmoodian, N., Rezapourian, M., Inamdar, A. A., Kumar, K., Fachet, M., & Hoeschen, C. (2024). Enabling Low-Dose In Vivo Benchtop X-ray Fluorescence Computed Tomography through Deep-Learning-Based Denoising. Journal of Imaging, 10(6), 127. https://doi.org/10.3390/jimaging10060127