1. Introduction
Machine Learning is mainly seen as a method of computing approximate functions that link data (input) with a label (output) to solve tasks that previously could not be solved by a human or a traditional algorithm. Deep learning has shifted the focus from approximate functions to latent spaces and how the approximate functions embed the data into these spaces through their parameters. Tuning the parameters of the approximate functions (e.g., approximating the model weights) is conducted by training the model, which is driven by the loss function of the task calculated from the labels. However, from an application perspective, the real goal is to create a latent space of data representation that provides a numerical/vectorial representation that effectively supports a particular machine learning task.
Although the meaning of latent is “existing but not yet manifest”, latent space is dependent on the context in which the term is used in different domains. Latent space generally refers to a space that is not tangible but is inferred or explored from the observed data. However, in machine learning (ML), latent space refers to a multidimensional numerical space (usually lower-dimensional than the original data space) that models the data under analysis.
More specifically, each layer within an ML model learns how to build its own latent space to represent or embed the data while retaining as much information about the data structure as possible. These spaces, once created, can later be used to explore the data properties and the underlying geometry of the manifold on which the data lives [
1]. Much of the research has focused on investigating how exactly such a geometry represents the original data space (cf. [
2,
3,
4,
5]); others directly investigate the relationship between the latent data representation (embeddings) to obtain a better model of the data distribution (cf. [
1,
6,
7]). However, both approaches have been used in various applications, e.g., anomaly detection (cf. [
8]), data augmentation (cf. [
9]) and data manipulation (cf. [
10]), explainability (cf. [
11]) as well as text and image generation (cf. [
12,
13]).
Recently, many large language models (LLMs) (e.g., generative pre-trained Transformers (GPTs) [
14]) have used a latent space in which the relationships between words (tokens) are very precisely tuned to a variety of different contexts. Previously, image-based latent representations have been extensively studied. The leading examples are generative adversarial networks (GANs) ([
15]) and variational autoencoders (VAEs) [
16], where the former have demonstrated a high capability in generating and creating non-existent but realistic data, while the latter are still superior in terms of computational and time costs. In any case, the exploration and interpretation of such latent spaces are not trivial.
Although latent spaces embed real-world data in a low-dimensional space, this space is usually not low-dimensional enough to be easily analyzed (e.g., GPT has an embedding vector with 12,288 dimensions and the latent space of StyleGAN2 consists of ); thus, dimensionality reduction techniques are required in such cases to better highlight the underlying data relationships.
In this work, we address a social-specific challenge in the
DaVinciFace application (described in
Section 3.1), namely to generate a Leonardo da Vinci-style portrait for each person. In our study, we analyze the ability of
DaVinciFace to correctly perform portrait generation in terms of gender, age, and race. To this end, we thoroughly analyze the latent image space of StyleGAN2 on a dataset of 1158 human face images by first applying a dimensionality reduction technique (namely ISOMAP [
17]) to visualize the dataset and investigate the density of latent vectors. Our study highlights the behavioral differences between sparse and dense representations of human features. We then present the detailed results of an industrial survey we sent to users of the application, which highlights potential biases related to gender and race.
The main contributions of this paper are the following:
The extension of DaVinciFace portraits to evaluate its capability to generate portraits for different social categories in the style of the Renaissance genius Leonardo da Vinci, and the demonstration of the effectiveness of latent space to support this goal.
A qualitative and quantitative analysis of a significant number of portraits to provide clear evidence of the effectiveness of our methodology in using DaVinciFace to create high-quality and realistic portraits in terms of diversity of facial features (e.g., beard, hair color, and skin tone).
Analyzing user feedback collected via a survey on the performance of DaVinciFace using a scale of identity vs style trade-off settings, including subjects with diversity regarding gender, race, and age. Where a high tolerance for the loss of identity features is observed in general to preserve more style features.
The remainder of this paper is organized as follows: The literature review is discussed in
Section 2, the presentation of our methodology is discussed in
Section 3, the obtained results are discussed in
Section 4, and the discussion and conclusion are discussed in
Section 5 and
Section 6, respectively.
2. Related Work
Here, we discuss the current state of research on the use of artificial intelligence (AI) in art and its acceptance in the community of artists and non-artists. We then explain the latent spaces and dimensionality reduction techniques and possible forms of biases in AI models.
Artificial intelligence for art: Visual AI applications for art generation and style transfer. With the unprecedented success of AI-based solutions in almost all areas of life, art is no exception. AI is used not only for analysis, authorship identification, or forgery detection but also for creative generation and style transfer (cf. “Creating Art with AI” [
18], “AI art in architecture” [
19], and “Can Computers Be Creative” [
20]). Recently, many AI-based art applications have emerged, but not all have been well received by critics or even non-experts; therefore, some critical studies and reviews have been developed (cf. [
21,
22,
23,
24]). The style transfer approach is an active field of research not only in art (cf. [
25,
26]), but also in text processing [
27], medical cancer classification [
28], and in videos [
29]. In this paper, we investigate the main features of an existing application that creates Da Vinci-style portraits by conducting an online survey among the users of the application, distinguishing art-related backgrounds, gender, and age.
Latent spaces and density. A latent space is mainly concerned with how the model layers represent the data in it. Therefore, studying the characteristics of this space is crucial in most real-world applications. By learning such characteristics, tasks such as classification, prediction, or even generation become clearer and easier [
1]. The most studied latent spaces are those generated by either generative adversarial networks (GANs) [
15] or variational autoencoders (VAEs) [
16]. However, GAN-based spaces are not only used intensively for the generation and manipulation in computer vision applications ([
13,
30]), but also for medical data, sensors, multi-modal data, and others (cf. medical image synthesis [
10], brain imaging [
31], collocating clothes [
32], cross-modal image generation [
33], and a built environment [
34]). For example, the latent space StyleGAN2, first proposed in [
35] and improved in [
36], is one of the most widely used pre-trained models for generating realistic faces from noise, for which its ability to learn unsupervised high-level attribute separation (e.g., pose) [
37] has been demonstrated. StyleGAN usually requires task-specific training for different tasks, but in terms of image manipulation and editing tasks, it produces high-quality and realistic generations, which has encouraged many researchers to propose tools to detect the generated fake photos to limit misuse and forgery (cf. [
38,
39]). In this work, we dive deep into the latent space of StyleGAN2 to visualize, analyze, and observe how the representations of the data in this space are either sparse or dense.
Dimensionality reduction. Although GAN-based frameworks reduce the dimensionality of high-dimensional input data to their latent spaces [
12], the dimensions of these spaces are not low enough to be analyzed by humans (e.g., the latent space of StyleGAN2 is
[
36]). Some research has proposed to apply clustering and data exploration techniques within the latent representation to better understand these spaces and disentangle the original data features (cf. embedding algorithm [
40], attribute editing and disentanglement [
41], clustering [
6], interpretability and disentanglement [
42], latent space organization [
43], and disentanglement inference [
44]); others use traditional non-linear
dimensionality reduction (cf. [
25,
45]). Non-linear dimensionality reduction techniques are used for numerous purposes, e.g., for feature extraction [
46], data visualization [
47], pattern recognition [
48] or even as a pre-processing step [
49]. Isometric mapping (ISOMAP), discussed in [
17], is one of the timeless algorithms of nonlinear projection-based algorithms that focus on global structure. More recent algorithms preserve more information in the reduced dimensions when the local geometry is close to Euclidean geometry, such as t-distributed stochastic neighbor embedding (t-SNE) [
50] and uniform manifold approximation and projection (UMAP) (cf. [
51,
52]). In this work, we use ISOMAP to visualize the latent space of StyleGAN2 as it can understand the global structure of the data.
Bias of AI models (in human images). Biases in AI [
53] can generally be due to either a bias in the data or in the model processing. The latter is not easy to detect as the decision of the model is not readable by humans, making the detection and characterization of bias challenging. The bias in the dataset can be caused by the labeling of the data, which is a subjective task [
54]. The bias of the model in photo-based systems and its mitigation are studied in depth in face recognition with an in-depth analysis of bias related to gender or race (cf. [
53,
54,
55,
56,
57,
58]). However, in style transfer applications (see [
59,
60,
61]), a different type of bias occurs. This bias may be related to the photos of the reference style, and so far the style features cannot be completely separated from the subject presented in the reference to be transferred without compromising the identity of the new subject. In this paper, we investigate bias in the application of
DaVinciFace focusing on gender and race aspects (see
Section 4.3 and
Section 4.4 for our analysis).
Exploring latent space for artistic or human face applications. In [
62], the researchers implemented DeepIE (deep interactive evolutionary) with the style-based generator of a StyleGAN model to generate visual art from the fusion of two original works, and they collected subjective ratings through a questionnaire. However, they were concerned with visual art in general and did not focus on human portraits or the model’s bias toward social categories. On the other hand, the work of [
63] develops a tunable algorithm to mitigate the hidden biases in the training data of human faces in a variational autoencoder-based model, while our analysis deals with GAN-based models for artistic applications. Ref. [
64] investigates the entanglement problem using the InterFaceGAN framework on StyleGAN2 to improve the quality of the synthesized images, while our work focuses on the artistic application
DaVinciFaceand the specific features concerning social categories. The idea of analyzing the effect of latent spatial representations in preserving specific features of human faces, especially the beard, for use in artistic portraits has been preliminary introduced before in [
25]. The methodology outlined in this paper constitutes a substantial advancement from [
25], introducing: (1) the setup process for configuring the application to create Da Vinci-style portraits, (2) the establishment of a pipeline for gathering human feedback alongside its corresponding subjective evaluation, (3) an extensive experimental assessment aimed at comprehending how latent representations encapsulate portrait features, with a nuanced focus on examining socially specific challenges concerning race, age, and gender, and (4) the execution of a crowd-sourcing survey to collect feedback regarding DaVinciFace’s capacity to generate high-quality portraits within an artistic framework.
4. Results
In this section, we discuss our experimental results to better understand how the latent representations embed the characteristics of the analyzed data, to address social-specific challenges related to racial, age, and gender diversity. To this end, we first describe the dataset and the corresponding latent representations in the
Section 4.1 and
Section 4.2. The discussion of the effects of some representations on the projected portraits (generated with the application
DaVinciFace) in terms of gender and other characteristics is presented in
Section 4.3, while the analysis of the crowd-sourcing survey to collect feedback in an artistic context is answered in
Section 4.4.
4.1. Dataset and Latent Representations
We used a dataset of 1158 input images from the test environment of the application DaVinciFace with the corresponding latent vectors ( each). The dataset is protected by copyright and, therefore, cannot be published. However, it consists of images of faces used in the first steps of creating and testing the application. The image is pre-processed with the two most important steps before projection:
The projection into the latent space of the pre-trained model StyleGAN2 is performed in reverse order, starting with a random latent vector, generating the image, calculating the pixel-wise loss between this image and the original, and optimizing the latent vector, which is repeated for 1000 iterations. The output for each image consists of 18 vectors, each with a length of 512. For all results reported in this paper, we normalized the mixed vector in the latent space before creating the image, and we used a variance proportion of 0.4%.
4.2. Dimensionality Reduction and Density Calculation
We used ISOMAP to visualize each vector distribution in two-dimensional space to examine the effects of each vector—in terms of its density—on the output to detect any disentanglement between the images under study and their representation in latent space.
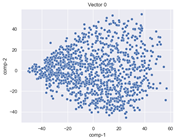
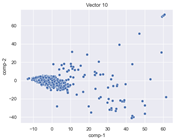
Table 3 and
Table 4 show the ISOMAP representations of the 18 vectors of the latent vectors of the points in the dataset using the scatter plot and the kernel density estimation plot, respectively (count starts at zero). The differences in the distributions can be clearly seen in
Table 3. Some vectors are sparser than others (e.g., vectors 2 and 15), others are very dense around zero (e.g., vectors 5 and 6).
Furthermore,
Table 4 shows that the density within the sparse vectors is not uniform. While vector 2 has approximately one central dense region, vector 15 has 3 regions. Within these vectors, we found that the coarse features (the first 5 vectors) and the fine features (the last six vectors) are sparser, while the middle vectors are relatively dense (except for vector 8), suggesting that sparse vectors may entangle more distinguishable features, while dense vectors embed the general human features. This motivates us to further investigate the effects of sparse and dense vectors on the creation of the resulting image. Since ISOMAP tends to learn the manifold of the original data and preserve the geometry [
49], this gives us evidence that the features in the StyleGAN2 space not only have a local geometry but also a global geometry.
To obtain a quantitative measure of the density of the vectors, we calculate the average distance between the data points, as shown in
Table 5. First, we reduce the dimensions of the individual vectors from 512 to two each using ISOMAP and then calculate the average Euclidean distance between the resulting two-dimensional representations.
Table 5 underpins the previous discussion, so we can see the large difference in the average distance between the sparse and dense vectors (the minimum is vector 6 at 5.42 and the maximum is vector 3 at 49.73).
The full disentanglement of these vectors is still ongoing and the analysis is mainly based on the results discussed in [
35], where the initial vectors are for pose and coarse features, gradually moving to fine features and style. However, gender, race, and age are distributed throughout the vectors as they are based on different facial and style features.
4.3. The Effect of Sparse Vectors
To better understand the effect of vectors on human facial features, we show the images resulting from blending the subject image with the style image using different settings and analyze the difference. As mentioned in
Section 3.1, we focus on the middle vectors from vector 8 to vector 11 to investigate the social-specific feature entanglement.
Compared to the default settings of
DaVinciFace which can be seen in
Table 1, bearded or mustachioed males obtain less or almost no bearded/mustachioed portraits, and in general all examples lose important identity features such as eyebrow shape, cheekbones, and chin structure as well as lip and nose type. In particular, the square face shape, the very light eyebrows, the double lower eyelid, the Greek nose, and the corners of the mouth are strongly influenced by the reference photo of Da Vinci’s masterpiece, the famous Mona Lisa. This has also been commented on, in rare cases, by users of the application who noted the lack of self-representation in the resulting portraits, which can be self-referential and subjective. However, we reduce self-involvement by using the subjects (celebrities or not) to provide subjective feedback, but with some self-detachment in the judgment.
Table 6 compares six examples, starting with the subject image on the left, then the portrait with the default settings (vectors 0 to 7 from the subject image and the rest from the style image), and then continuing to the right, with each time adding another vector from the subject image instead of the style image (using the same subjects from
Table 1). The effect of vector 8 is immediately apparent in the identity and gender features such as the beard and mustache in the male portraits and hair color and makeup in the female portraits.
However, adding more vectors (to the right) has a slight effect on increasing the identity features, and the style is gradually lost as the colors are lightened and changed. In addition, not only are the identity features clearer in the male portraits, but the individuals also tend to become younger toward the right. In the female examples, on the other hand, the light eye and hair color in the second example are more clearly visible, as is the light skin color in the sixth example and the dark skin of the fourth example. Our original aim is to enhance the identity while retaining the Da Vinci style as much as possible.
If we focus more on the effect of vector 8, it is expected to embed more distinctive features due to its low density compared to the other vectors (as explained in
Section 4.2).
Table 7 shows the two test cases (cases 1 and 2) and another five examples of bearded and blond subjects. In the first row, the first 12 vectors of the subject, including vector 8, are compared (with the same settings as in the last column
Table 6), and in the second row, the same settings are kept, but vector 8 from the style image is used instead. The absence of this vector has a significant effect on the hair color and beard, but also on the chin, face shape, and eye type. However, other features such as eyebrow shape, nose type, and lips are not as strongly affected. We conclude that this sparse vector has a greater influence on identity and gender features than the other dense vectors. However, it is not the only one.
4.4. Survey Results
We evaluate our results using a crowd-sourcing survey. The survey was advertised for one month, conducted online, and sent to all users of the application. Out of 525 total views, 370 completed the survey and 9 started it without completing it. This results in a participation rate of 72.2% and a completion rate of 97.6%, with an average completion time of 3:44 min. We used SurveyHero (
www.surveyhero.com (accessed on 27 June 2024) is a software for designing, collecting, and analyzing survey responses) to design the survey and collect the responses.
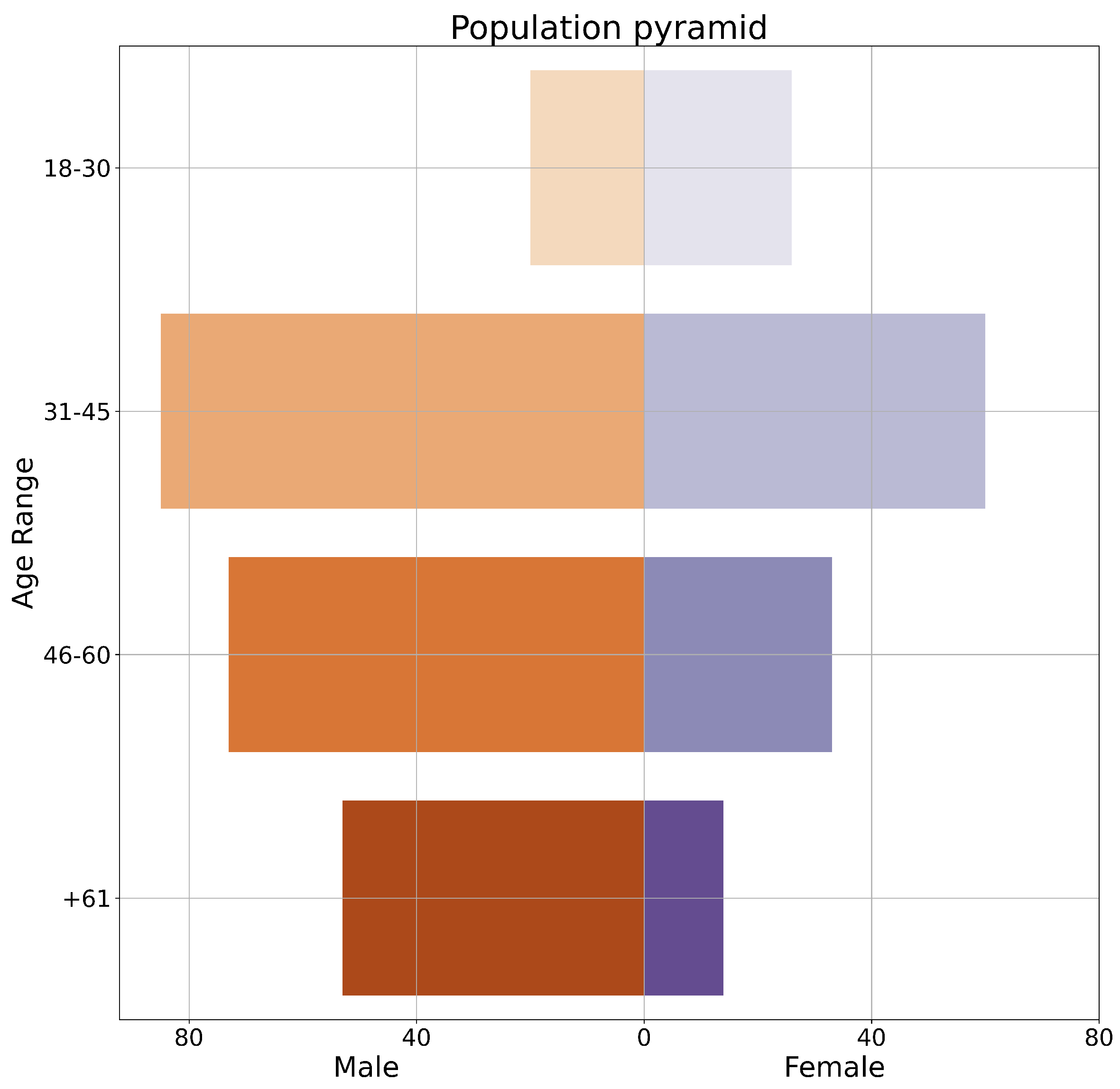
Figure 7 shows the population pyramid of participants in terms of age range and gender, male in orange and female in purple.
The demographic and background information on the participants is as follows:
Gender perspective, out of 360 responses: 224 (62.22%) are men, 129 (35.83%) are women and 7 (1.94%) preferred not to answer.
Age perspective: Out of 360 responses, 39.44% of participants belong to the age group (31–45), followed by 28.89% in the age group (46–60), 18.33% are older than 61 and 13.33% are younger than 30.
Art-related background: Most users are interested in art (56.82%), followed by people not related or are not interested in art (21.17%), while professional artists and art students represent 16.71% and 5.29% respectively.
The results of the survey on research question 1 (RQ1) (whether the default setting sufficiently preserves the subject’s identity) are shown in
Figure 8, which shows that the highest recognition was given to Lucy Liu, followed by Freddie Mercury and then Roberto Benigni.
In order to address research question 2 (RQ2) mentioned in
Section 3.3 (i.e., finding a better trade-off between style and identity preservation than the default settings), the survey contained 8 questions presenting four different celebrities (i.e., Monica Bellucci, Luciano Pavarotti, G-Dragon, and Barack Obama) and four additional test cases (see
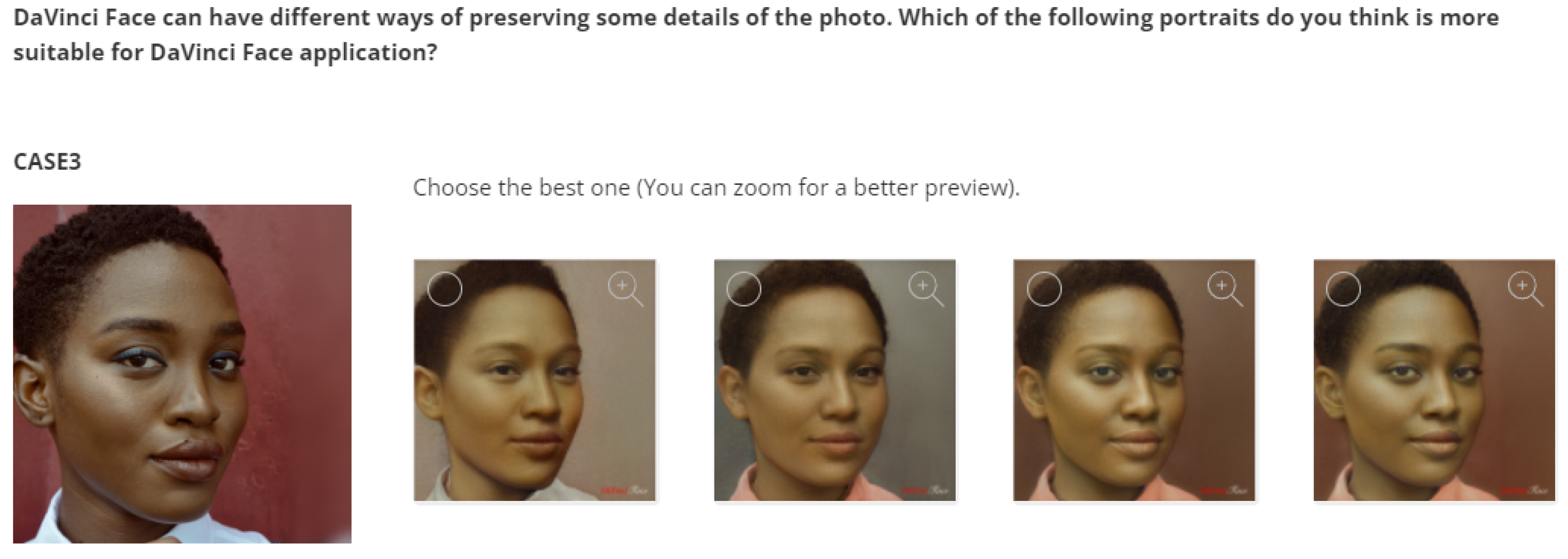
Table 2). Each question contains the photo of the corresponding subject with the following four settings: (a) default settings; (b) add vector 8 from the original image; (c) add up to vector 10 from the original image; (d) add up to vector 11 from the original image; (see
Figure 6 as an example). The user can select the most favorable alternative from the various alternatives.
Table 8 shows the statistics of the selected options for the 8 subjects. According to the responses, the default version (which has the most style) is chosen most often, although identity preservation is the least favorable. More specifically, the percentage of default settings increases when the subject is a brunette female (Monica Bellucci with 67.93% and test case 4 with 57.49%), while it decreases for bearded males (test case 1 with 31.21% and Luciano Pavarotti with 43.84%). However, the default settings are no longer the preferred option if the test subject is not Caucasian (G-Dragon with a majority of 38.15% for option (b), Barack Obama with a majority of 28.86% for option (d), and test case 3 with a majority of 31.14% for option (b)).
Table 9 and
Table 10 show the most selected option for the same subjects, but grouped by art-related background and the stated gender identity of the participants respectively. Grouping by participant information shows more detail about each group’s responses and eliminates the effect of the majority group’s dominance on the overall result.
In
Table 9, the majority group is interested in art (56.82%), and the dominance of this group clearly affects the final results in the cases:
For G-Dragon, two other groups chose option (a), and the majority chose option (b);
For Barack Obama, all other groups chose option (c), and the majority chose option (d);
For test case 1, two other groups chose option (b), and the majority chose option (a).
On the other hand, the majority group could not dominate in test case 3, although their choice was option (a).
In
Table 10, the majority of the group is male (62.22%). We can see the dominance of this group in all cases, as the female group chose option (a) for all subjects. The reason why the female group chose more styles for all subjects is not clear. However, we can assume that females prefer artistic output or that the participants are mainly concerned with art.
5. Discussion
A crowd-sourcing survey was advertised for one month, conducted online, and sent to all users of the application. Of the total of 525 total views, 370 users completed the survey. We were able to analyze the performance of DaVinciFace using a scale of attitudes toward identity and style compromise that included subjects of different genders, races, and ages. The results of the survey are not to be expected. It turned out that the use of DaVinciFace with celebrities or even with non-celebrities where the user is not personally involved in the portraits allows more tolerance for the loss of important identity features while retaining more style. In addition, the audience of DaVinciFace is mainly interested in art, artists, or art students, which might justify the skew of results toward more style in general.
Identity preservation: When users were asked to recognize celebrities portrayed with
DaVinciFace,
Figure 8 shows that the most frequently recognized celebrity is Lucy Liu, followed by Freddie Mercury and then Roberto Benigni, although we can attribute these celebrities to the age majority of participants. The low percentage of recognition for young celebrities such as Billie Eilish is as expected, but we can say that
DaVinciFace might have more recognition if it is a celebrity in general. The low recognition of Maria Sharapova as a celebrity in sports can also be explained by the fact that the audience is more interested in art. However, the case of Morgan Freeman is the most interesting, as he is internationally known and has a longer career. The reason for the low percentage of recognition could point to the bias of the
DaVinciFace toward subjects of African descent.
Identity/style trade-off: The results of the other eight questions (
Table 8,
Table 9 and
Table 10) show that participants generally chose to maintain the Da Vinci style even if it meant losing identity features. This is particularly evident when the subject is a Caucasian Female (Monica Bellucci, test cases 2 and 4) (see
Table 8 and
Table 9). However, further analysis based on the participant’s stated gender identity (
Table 10) shows that the first option for Females retains most of the style, regardless of the subject’s characteristics. The reason for this bias toward option (a) (more style) cannot be determined, whether due to a bias of the model toward female subjects, due to the fact that Da Vinci’s works contained mostly female subjects, or due to the fact that the identity is somehow preserved in this particular case.
Social perspective: For individuals with darker skin tones (e.g., Barack Obama and test case 3), option (a) is not consistently preferred across all groups, as mentioned above. It is still crucial to maintain distinctive identity characteristics, even if stylistic nuances are gradually softened. This also applies to personalities such as Morgan Freeman. The reason for this—whether it is the loss of identity features (such as the lower eyelid, nose, and lip shape) or the fact that participants are unfamiliar with Da Vinci’s style, which is synonymous with such distinct features—is not yet clear. Furthermore, since the changes in skin color affect all subjects influenced by the style’s color palette, the effect could be more pronounced in those with darker skin tones. Further analysis is required to determine whether this bias stems from the training data used in StyleGAN2 or from the DaVinciFace application. In contrast, for the bearded man (e.g., Luciano Pavarotti and test case 1), option (a) is typically—but not always—preferred. Although Da Vinci’s style did not traditionally include a beard, participants often favored this style over more masculine features, especially the beard.
However, we can conclude that the highest bias of the model toward the reference photo is observed in people of African race according to our participants. A lower bias is observed for bearded males, while Caucasians and Asians, especially females, were also accepted by the participants with a less identity-preserving but more style-preserving option.
6. Conclusions
In this paper, we presented the exploration of the latent space of StyleGAN2 by analyzing it from the perspective of social features. We concluded that sparse vectors have a greater effect on these features. To evaluate our results, we conducted a survey that we sent to the users of DaVinciFace to collect their feedback, and we collected 360 responses. We demonstrate the analysis of these responses and find that the crowd-sourcing application maintains style even when identity or gender-specific features are lost, with the exception of African individuals.
The main limitation in generalizing these results is the subjective opinion of participants, especially if they are not related to or interested in art. Another known limitation is that surveys are best suited to show trends. In addition, the survey was only sent to users who have already tried DaVinciFace before, which can lead to a personal bias based on previous experiences. These results will be taken into account when designing the next version of the survey with new industry and research questions to appeal to a wider audience. Another approach to exploring the latent space is to use a reinforcement agent that aligns with the survey results to create the “perfect” portrait.
As a next step, we plan to develop strategies to improve the DaVinciFace features and mitigate biases in both the dataset and the corresponding AI application, especially biases affecting individuals with darker skin tones. We also want to compare different artistic styles to evaluate their impact on the accuracy of face recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}