
A Multi-Scale Target Detection Method Using an Improved Faster Region Convolutional Neural Network Based on Enhanced Backbone and Optimized Mechanisms



Abstract
1. Introduction
- (1)
- ResNet101 [19] is employed as the trunk network in the improved Faster R-CNN, which enhances the feature extraction capabilities of the model.
- (2)
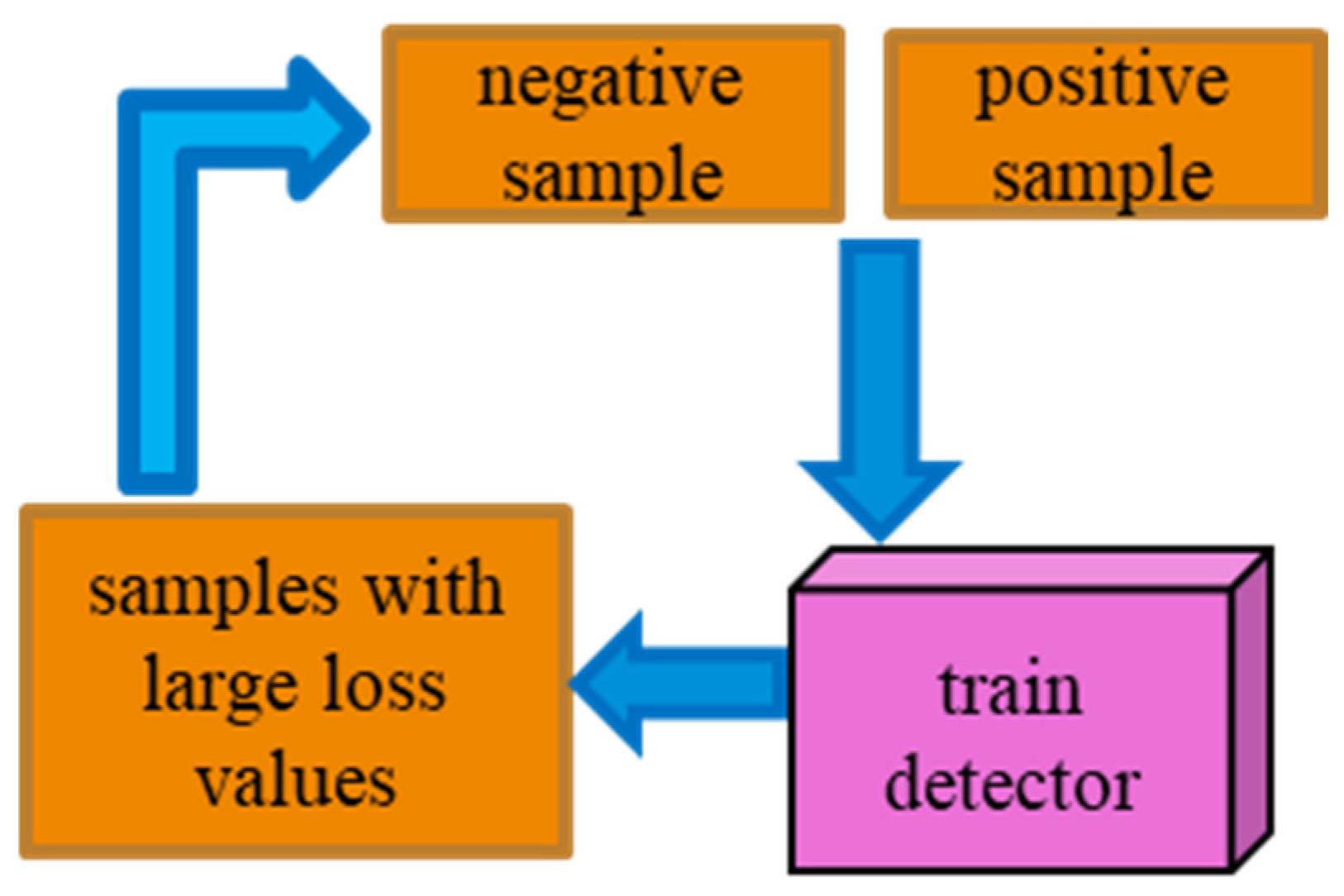
- The Online Hard Example Mining (OHEM) algorithm [20] is used to help the model learn hard-to-classify samples more efficiently, which in turn enhances the model’s capacity for generalization. The Soft non-maximum suppression (Soft-NMS) algorithm [21] and the Distance Intersection Over Union (DIOU) algorithm [22] are used to optimize the excessive bounding boxes generated by the RPN and their overlap degree, which enhances the accuracy of detecting small targets and improves the issue of missed target detection.
- (3)
- The RPN structure is optimized by adding an anchor box with a scale of 64 and using a smaller convolutional kernel to achieve bounding box regression. Employing the multi-scale training (MST) method to train the improved Faster R-CNN [23] achieves a balance between detection accuracy and speed.
2. Methodology and Modeling
2.1. The Adjusted Faster R-CNN Network
2.1.1. Improved Backbone Network
2.1.2. Modifying the Region Proposal Network
2.1.3. Optimization of Detection Boxes and Sample Imbalance
2.1.4. Multi-Scale Training
2.2. Evaluation Metrics
3. Experiments and Results
3.1. Data and Preprocessing
3.1.1. Data Collection
3.1.2. Data Augmentation
3.2. Results
4. Discussion
4.1. Comparison of Trunk Networks
4.2. Comparison of Different Object Detectors
4.3. The Ablation Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A Small-Sized Object Detection Oriented Multi-Scale Feature Fusion Approach with Application to Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Deng, Y.; Hu, X.L.; Li, B.; Zhang, C.X.; Hu, W.M. Multi-scale self-attention-based feature enhancement for detection of targets with small image sizes. Pattern Recogn. Lett. 2023, 166, 46–52. [Google Scholar] [CrossRef]
- Ma, Y.L.; Wang, Q.Q.; Cao, L.; Li, L.; Zhang, C.J.; Qiao, L.S.; Liu, M.X. Multi-Scale Dynamic Graph Learning for Brain Disorder Detection with Functional MRI. IEEE Trans. Neur. Syst. Rehabil. 2023, 31, 3501–3512. [Google Scholar] [CrossRef] [PubMed]
- Menezes, A.G.; de Moura, G.; Alves, C.; de Carvalho, A. Continual Object Detection: A review of definitions, strategies, and challenges. Neural Netw. 2023, 161, 476–493. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.B.; Zhang, M.H.; Song, W.; Mei, H.B.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Goswami, P.K.; Goswami, G. A Comprehensive Review on Real Time Object Detection using Deep Learing Model. In Proceedings of the 2022 11th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 16–17 December 2022; pp. 1499–1502. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Coiumbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. 2017, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6154–6162. [Google Scholar]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 2016 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Liang, Q.; Zhu, W.; Long, J.; Wang, Y.; Sun, W.; Wu, W. A real-time detection framework for on-tree mango based on SSD network. In Proceedings of the 2018 11th International Conference on Intelligent Robotics and Applications (ICIRA), Newcastle, NSW, Australia, 9–11 August 2018; pp. 423–436. [Google Scholar]
- Anagnostis, A.; Tagarakis, A.C.; Asiminari, G.; Papageorgiou, E.; Kateris, D.; Moshou, D.; Bochtis, D. A deep learning approach for anthracnose infected trees classification in walnut orchards. Comput. Electron. Agric. 2021, 182, 105998. [Google Scholar] [CrossRef]
- Tian, X.X.; Bi, C.K.; Han, J.; Yu, C. EasyRP-R-CNN: A fast cyclone detection model. Vis. Comput. 2024, 40, 4829–4841. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.C.; Wu, C.H.; Cui, Z.X.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Tech. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y. Rethinking PASCAL-VOC and MS-COCO dataset for small object detection. J. Vis. Commun. Image R. 2023, 93, 103830. [Google Scholar] [CrossRef]
- Demir, A.; Yilmaz, F.; Kose, O. Early detection of skin cancer using deep learning architectures: Resnet-101 and inception-v3. In Proceedings of the 2019 Medical Technologies Congress (TIPTEKNO 2019), Izmir, Turkey, 3–5 October 2019; pp. 1–4. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 761–769. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5561–5569. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the 2020 20th AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Tian, R.; Shi, H.; Guo, B.; Zhu, L. Multi-scale object detection for high-speed railway clearance intrusion. Appl. Intell. 2022, 52, 3511–3526. [Google Scholar] [CrossRef]
- Wang, H.; Xiao, N. Underwater object detection method based on improved Faster RCNN. Appl. Sci. 2023, 13, 2746. [Google Scholar] [CrossRef]
- Lu, X.; Wang, H.; Zhang, J.J.; Zhang, Y.T.; Zhong, J.; Zhuang, G.H. Research on J wave detection based on transfer learning and VGG16. Biomed. Signal. Process. 2024, 95, 106420. [Google Scholar] [CrossRef]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Corso, M.P.; Stefenon, S.F.; Singh, G.; Matsuo, M.V.; Perez, F.L.; Leithardt, V.R.Q. Evaluation of visible contamination on power grid insulators using convolutional neural networks. Electr. Eng. 2023, 105, 3881–3894. [Google Scholar] [CrossRef]
- Chan, S.X.; Tao, J.; Zhou, X.L.; Bai, C.; Zhang, X.Q. Siamese Implicit Region Proposal Network with Compound Attention for Visual Tracking. IEEE Trans. Image Process. 2022, 31, 1882–1894. [Google Scholar] [CrossRef] [PubMed]
- Sha, G.; Wu, J.; Yu, B. The improved faster-RCNN for spinal fracture lesions detection. J. Intell. Fuzzy Syst. 2022, 42, 5823–5837. [Google Scholar] [CrossRef]
- Zhou, D.; Fang, J.; Song, X.; Guan, C.; Yin, J.; Dai, Y.; Yang, R. Iou loss for 2d/3d object detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 85–94. [Google Scholar]
- Shen, Y.Y.; Zhang, F.Z.; Liu, D.; Pu, W.H.; Zhang, Q.L. Manhattan-distance IOU loss for fast and accurate bounding box regression and object detection. Neurocomputing 2022, 500, 99–114. [Google Scholar] [CrossRef]
- Wang, Z.H.; Jiang, Q.P.; Zhao, S.S.; Feng, W.S.; Lin, W.S. Deep Blind Image Quality Assessment Powered by Online Hard Example Mining. IEEE Trans. Multimed. 2023, 25, 4774–4784. [Google Scholar] [CrossRef]
- Li, W.B.; Wang, Q.; Gao, S. PF-YOLOv4-Tiny: Towards Infrared Target Detection on Embedded Platform. Intell. Autom. Soft Comput. 2023, 37, 921–938. [Google Scholar] [CrossRef]
- Xiao, L.; Wu, B.; Hu, Y. Surface defect detection using image pyramid. IEEE Sens. J. 2020, 20, 7181–7188. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14449–14458. [Google Scholar]
- Fang, H.; Ding, L.; Wang, L.; Chang, Y.; Yan, L.; Han, J. Infrared Small UAV Target Detection Based on Depthwise Separable Residual Dense Network and Multiscale Feature Fusion. IEEE Trans. Instrum. Meas. 2022, 71, 1–20. [Google Scholar] [CrossRef]
- Smart, P.D.S.; Thanammal, K.K.; Sujatha, S.S. An Ontology Based Multilayer Perceptron for Object Detection. Comput. Syst. Sci. Eng. 2023, 44, 2065–2080. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, C.; Luo, H.Z.; Zhao, W.Q.; Zhong, S.; Tang, L.; Peng, J.Y.; Fan, J.P. Automatic learning for object detection. Neurocomputing 2022, 484, 260–272. [Google Scholar] [CrossRef]
- Chen, J.A.; Tam, D.; Raffel, C.; Bansal, M.; Yang, D.Y. An Empirical Survey of Data Augmentation for Limited Data Learning in NLP. Trans. Assoc. Comput. Linguist 2023, 11, 191–211. [Google Scholar] [CrossRef]
- Shi, J.; Ghazzai, H.; Massoud, Y. Differentiable Image Data Augmentation and Its Applications: A Survey. IEEE Trans. Pattern Anal. 2024, 46, 1148–1164. [Google Scholar] [CrossRef]
- Gower, R.M.; Loizou, N.; Qian, X.; Sailanbayev, A.; Shulgin, E.; Richtárik, P. SGD: General analysis and improved rates. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 5200–5209. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Classes | Train | Validation | Test | Total |
|---|---|---|---|---|
| Pottedplant | 133 | 112 | 224 | 469 |
| Chair | 224 | 221 | 417 | 862 |
| Sofa | 111 | 118 | 223 | 452 |
| sheep | 48 | 48 | 97 | 193 |
| bottle | 139 | 105 | 212 | 456 |
| diningtable | 97 | 103 | 190 | 390 |
| Bird | 180 | 150 | 282 | 612 |
| boat | 81 | 100 | 172 | 353 |
| aeroplane | 112 | 126 | 204 | 442 |
| motorbike | 120 | 125 | 222 | 467 |
| tvmonitor | 128 | 128 | 229 | 485 |
| person | 1025 | 983 | 2007 | 4015 |
| train | 127 | 134 | 259 | 520 |
| bicycle | 116 | 127 | 239 | 482 |
| Cow | 69 | 72 | 127 | 268 |
| Dog | 203 | 218 | 418 | 839 |
| Cat | 163 | 174 | 322 | 659 |
| Bus | 97 | 89 | 174 | 360 |
| Car | 376 | 337 | 721 | 1434 |
| horse | 139 | 148 | 274 | 561 |
| total | 2501 | 2510 | 4952 | 9963 |
| Data Set | Train | Validation | Test |
|---|---|---|---|
| A (8:1:1) | 12,000 | 1500 | 1500 |
| B (7:1.5:1.5) | 10,500 | 2250 | 2250 |
| C (6:2:2) | 9000 | 3000 | 3000 |
| Methods | mAP@0.5 (%) | F1 (%) | LAMR (%) |
|---|---|---|---|
| VGG16 | 72.7 | 55.3 | 31.4 |
| ResNet34 | 73.3 | 56.4 | 30.8 |
| ResNet50 | 73.8 | 56.2 | 30.2 |
| ResNet101 | 74.9 | 57.2 | 29.5 |
| Methods | mAP@0.5 (%) | F1 (%) | LAMR (%) | T (s) |
|---|---|---|---|---|
| RetinaNet | 75.6 | 58.5 | 29.2 | 0.155 |
| Faster R-CNN | 72.7 | 55.3 | 31.4 | 0.147 |
| Mask R-CNN | 75.8 | 58.2 | 28.5 | 0.153 |
| YOLOv4 | 76.5 | 59.2 | 27.2 | 0.132 |
| Cascade R-CNN | 76.2 | 59.7 | 28.1 | 0.139 |
| This Paper | 77.8 | 60.6 | 26.5 | 0.163 |
| Method | ResNet101 | RPN | DIOU | OHEM | Soft-NMS | MST | mAP@0.5 (%) | F1 (%) | LAMR (%) |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN(VGG16) | 72.7 | 55.3 | 31.4 | ||||||
| Faster R-CNN(ResNet101) | ✓ | 74.9 | 57.2 | 29.5 | |||||
| Improve1 | ✓ | ✓ | 75.2 | 57.4 | 29.2 | ||||
| Improve2 | ✓ | ✓ | 75.1 | 57.3 | 29.3 | ||||
| Improve3 | ✓ | ✓ | 75.4 | 57.6 | 28.9 | ||||
| Improve4 | ✓ | ✓ | 75.0 | 57.4 | 29.3 | ||||
| Improve5 | ✓ | ✓ | ✓ | ✓ | ✓ | 75.5 | 58.1 | 28.7 | |
| This paper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 77.8 | 60.6 | 26.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Li, M.; Lai, Z.; Zhu, J.; Guan, L. A Multi-Scale Target Detection Method Using an Improved Faster Region Convolutional Neural Network Based on Enhanced Backbone and Optimized Mechanisms. J. Imaging 2024, 10, 197. https://doi.org/10.3390/jimaging10080197
Chen Q, Li M, Lai Z, Zhu J, Guan L. A Multi-Scale Target Detection Method Using an Improved Faster Region Convolutional Neural Network Based on Enhanced Backbone and Optimized Mechanisms. Journal of Imaging. 2024; 10(8):197. https://doi.org/10.3390/jimaging10080197
Chicago/Turabian StyleChen, Qianyong, Mengshan Li, Zhenghui Lai, Jihong Zhu, and Lixin Guan. 2024. "A Multi-Scale Target Detection Method Using an Improved Faster Region Convolutional Neural Network Based on Enhanced Backbone and Optimized Mechanisms" Journal of Imaging 10, no. 8: 197. https://doi.org/10.3390/jimaging10080197
APA StyleChen, Q., Li, M., Lai, Z., Zhu, J., & Guan, L. (2024). A Multi-Scale Target Detection Method Using an Improved Faster Region Convolutional Neural Network Based on Enhanced Backbone and Optimized Mechanisms. Journal of Imaging, 10(8), 197. https://doi.org/10.3390/jimaging10080197