
Optimisation of Convolution-Based Image Lightness Processing


Abstract
1. Introduction
- We introduce a linear optimisation approach to convolutional retinex that mitigates shading (illumination gradients) from images. As described below, the theory is an analytic reformulation and extension of an earlier 1988 paper by Hurlbert and Poggio [30].
- The optimal linear filter adapts to known or estimated autocorrelation statistics of the albedo and illumination components of a given image training dataset. Consequently, the filter can be optimised for particular image datasets or scene categories. As discussed later in the paper, more accurate estimates of the autocorrelation matrices, for example situations where the illumination gradients have a known functional form, will lead to a better optimal filter.
- Since the filter can be obtained in closed form, the method is computationally very simple.
- Our method could be incorporated into more sophisticated (and computationally expensive) methods that utilise a linear step as part of their image enhancement processing or could be used as a preprocessing stage for training CNNs [34].
2. Hurlbert and Poggio’s Method
3. Derivation of an Optimal Lightness Convolution Filter in Closed Form
- Given a training set of albedo vectors and shading vectors, an expression for a colour signal matrix that contains all possible combinations of these vectors is derived.
- Significantly, an analytic decomposition of the least squares solution is performed, which shows that the optimisation depends primarily upon and , which are the autocorrelation matrices for the albedos and shadings, respectively.
- By introducing models for the albedo and shading training vectors, closed-form expressions for and are obtained by integrating over all possible training vectors.
- The algorithm and implementation details are discussed.
3.1. The Set of All Colour Signals
3.2. Least Squares Solution
3.3. Analytic Decomposition
- is the colour signal autocorrelation matrix for the set of all colour signals,
- is the shading autocorrelation matrix for the starting set of m vectors defined by Equation (11),
- is the albedo autocorrelation matrix for the starting set of n vectors defined by Equation (11),
- is a row vector defined by the mean of the set ,
- is a row vector defined by the mean of the set .
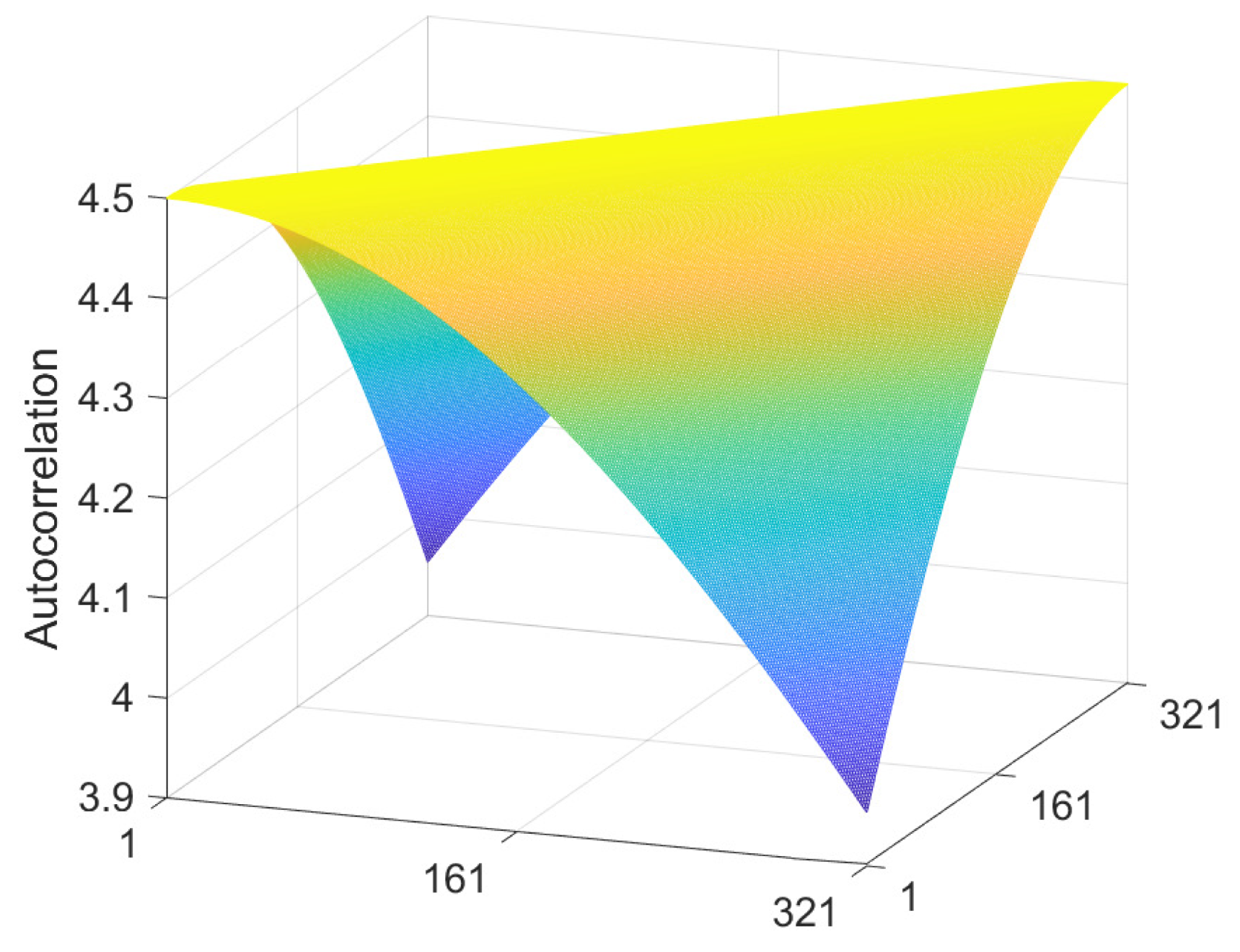
3.4. Shading Autocorrelation Matrix
3.5. Albedo Autocorrelation Matrix
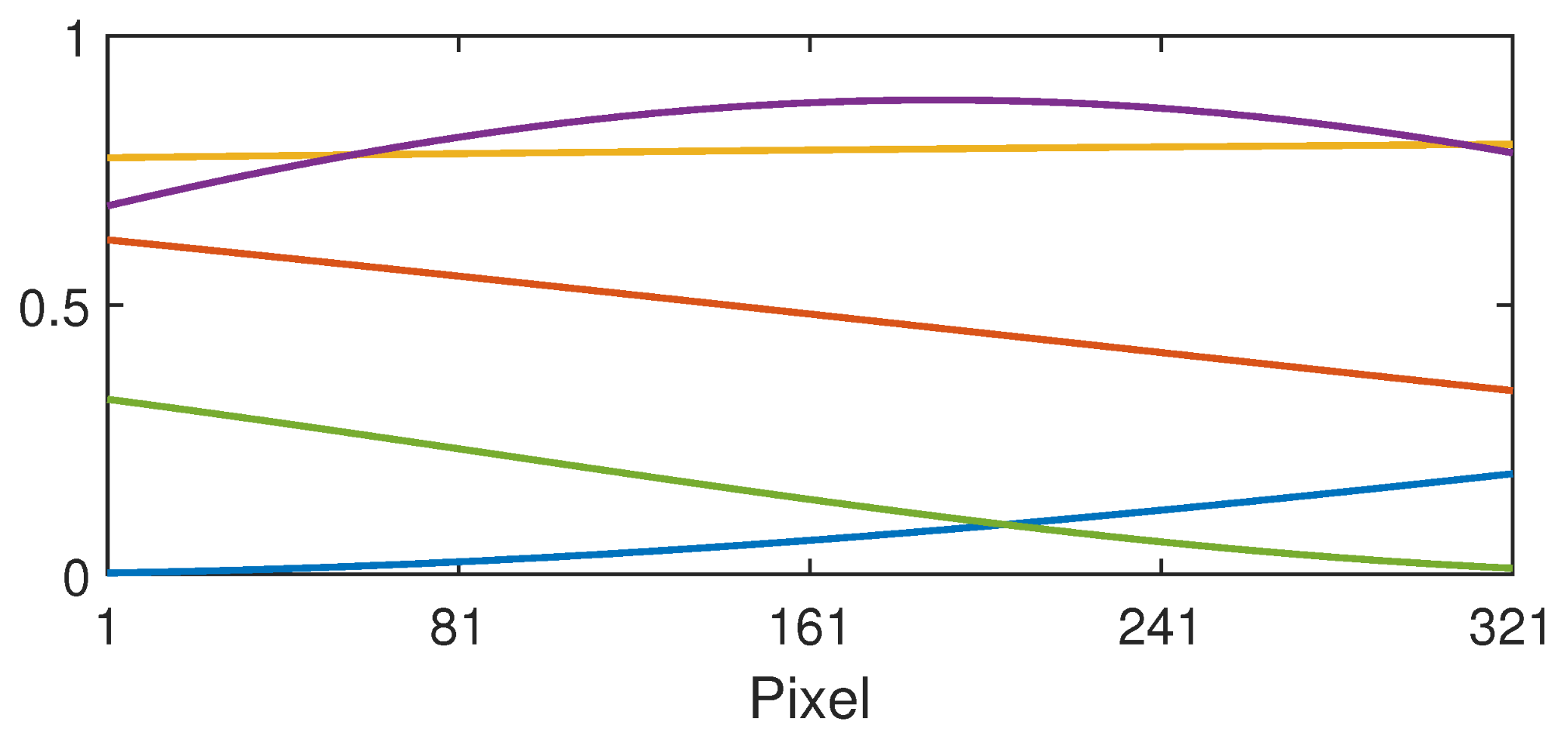
3.6. Implementation
3.6.1. Designing a Filter
- Linearise the input images by inverting the gamma encoding curve and calculate the luminance channel as the appropriate weighted sum of the RGB channels.
- Based upon an estimate for the nature of the shadings present in the dataset, calculate the shading autocorrelation matrix and mean vector , for example by using Equations (29) and (31). Considerations include the following:
- The type of shadings present such as sinusoids, linear ramps, or a weighted combination. For sinusoids, the minimum wavelength can be changed.
- The spatial extent of the shadings (in pixels). This corresponds to the length of the scan lines and hence the diameter of the output filter.
- The shading value limits . If the image pixel values have been normalised to the range in the primal domain, then v can be taken to be 1 and an estimate can be made for u before converting to logarithmic units.
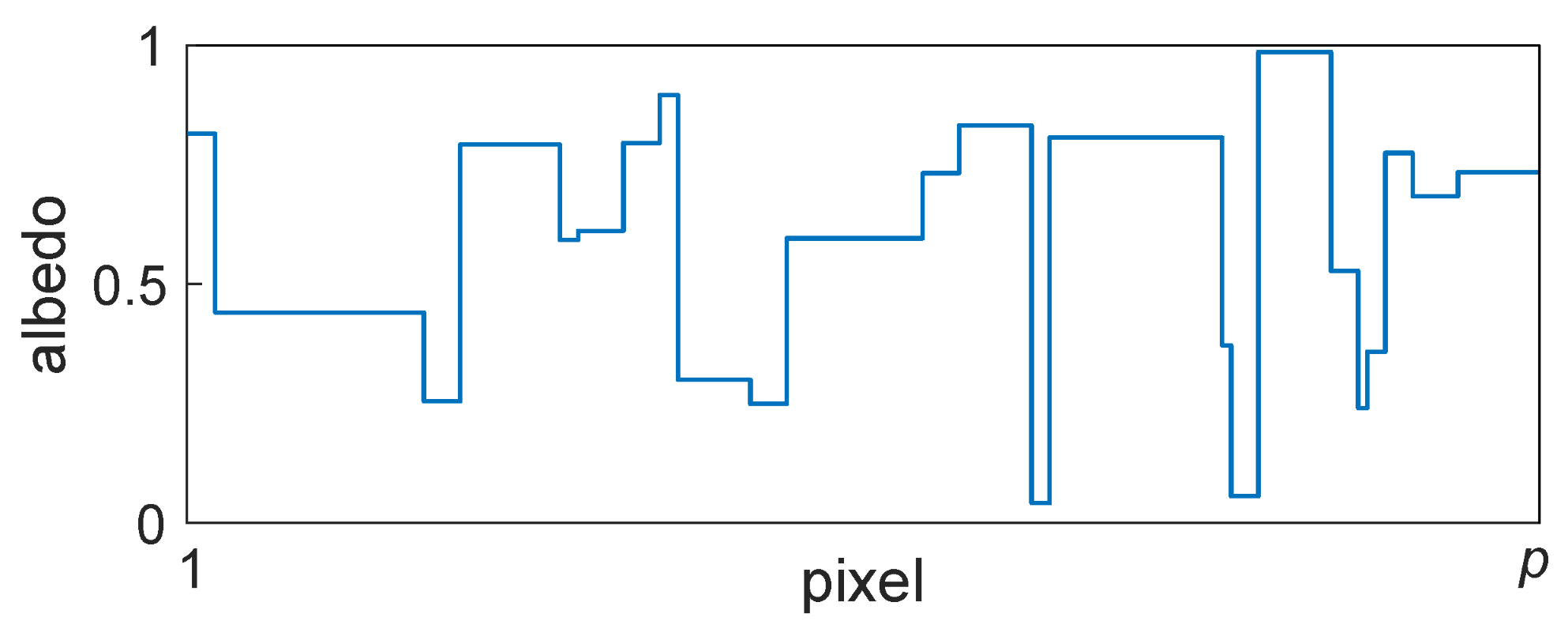
- Calculate the albedo autocorrelation matrix and mean vector . To do this,
- (a)
- First, calculate and the mean vector for the dataset (logarithm of the luminance channel) numerically using Equation (32). For every image in the dataset, the scan lines (training vectors) of length p can be extracted by rotating the images through all 360 single degree increments and taking a scan line from a fixed position each time, for example by choosing the horizontal line that passes through the centre of the images.
- (b)
- (c)
- In order to obtain a perfectly smooth closed-form solution, find the closest Mondrian autocorrelation matrix. This can be achieved by applying scale and offset parameters to Equation (34) and then performing a least squares fit to Equation (38). The mean vector , which will be approximately constant, can be smoothed by averaging its elements if necessary.
- Calculate the matrix operator using Equation (22). Use the central column as the 1d albedo filter and convert this to 2d.
3.6.2. Filtering an Image
- Linearise by inverting the encoding gamma curve and calculate the luminance channel Y as the appropriate weighting of the RGB channels. Take the logarithm of the luminance channel.
- Transform the log luminance image to the Fourier domain and multiply by the Fourier transform of the 2d filter (zero padded if necessary) before converting back to the primal domain. Since artefacts can arise from discontinuities at the image boundaries due to the non-periodic nature of a typical real-world image, a computational trick to remove these is to first convert the image into a continuous image that is four times as large by mirroring in the horizontal and vertical directions [33].
- Subtract the 99.7th quantile in order that the maximum value of the log luminance image be zero. (Any values larger than zero should be clipped to zero). This generally produces a lighter image, which is useful from an image preference point of view.
- Exponentiate the filtered log luminance image from the previous step. Use the original RGB channels (colour signals) together with the filtered luminance channel to calculate a filtered colour image, appropriately scaling for the new luminance. Mathematically,where with i = R, G, or B are the output colour signals, with i = R, G, or B are the corresponding input colour signals, Y is the input luminance channel, and is the filtered output luminance channel. This colour mapping preserves chromaticity [11]. Finally, reapply the gamma encoding curve and renormalise the image to the desired range as required.
3.7. Filter Shape
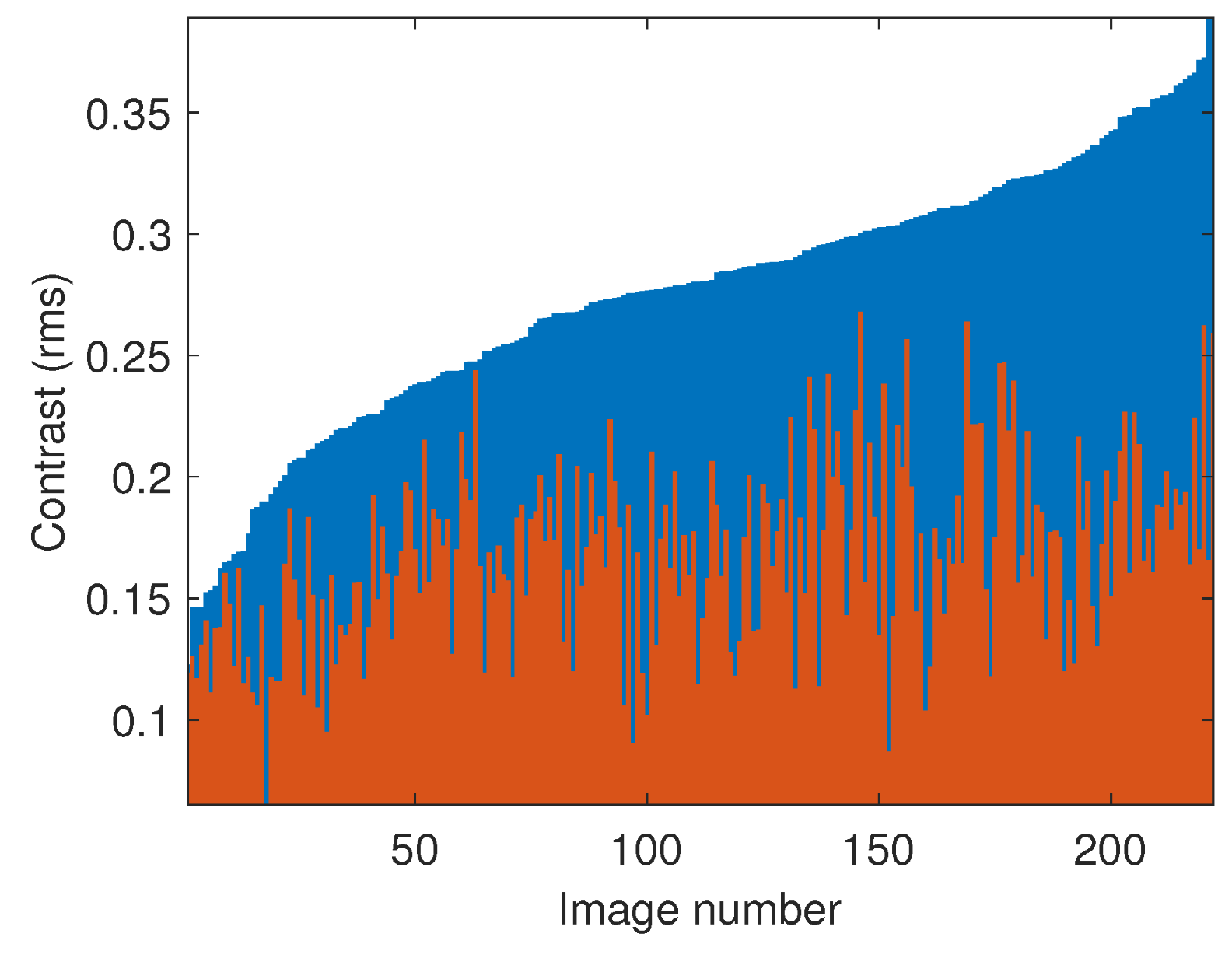
4. Results and Discussion
4.1. Text Image Processing
4.2. Lightness Processing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Analytic Decomposition
Appendix B. Linear Ramps
References
- Land, E.H.; McCann, J.J. Lightness and retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Land, E.H. The Retinex Theory of Color Vision. Sci. Am. 1977, 237, 108–128. [Google Scholar] [CrossRef] [PubMed]
- Hurlbert, A.C. Formal connections between lightness algorithms. J. Opt. Soc. Am. A 1986, 3, 1684–1693. [Google Scholar] [CrossRef]
- Funt, B.; Ciurea, F.; McCann, J. Retinex in MatlabTM. J. Electron. Imag. 2004, 13, 48–57. [Google Scholar] [CrossRef]
- Land, E.H. An alternative technique for the computation of the designator in the retinex theory of color vision. Proc. Natl. Acad. Sci. USA 1986, 83, 3078–3080. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. Properties and Performance of a Center/Surround Retinex. IEEE Trans. Imag. Proc. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A Multiscale Retinex for Bridging the Gap between Color Images and the Human Observation of Scenes. IEEE Trans. Imag. Proc. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Rahman, Z.u.; Jobson, D.; Woodell, G. Retinex processing for automatic image enhancement. J. Electron. Imaging 2004, 13, 100–110. [Google Scholar]
- Lisani, J.L.; Morel, J.M.; Petro, A.B.; Sbert, C. Analyzing center/surround retinex. Inf. Sci. 2020, 512, 741–759. [Google Scholar] [CrossRef]
- Poynton, C. The rehabilitation of gamma. In SPIE/IS&T Conference, Proceedings of the Human Vision and Electronic Imaging III, San Jose, CA, USA, 24 January 1998; Rogowitz, B.E., Pappas, T.N., Eds.; SPIE: Bellingham, WA, USA, 1998; Volume 3299, pp. 232–249. [Google Scholar] [CrossRef]
- Barnard, K.; Funt, B. Investigations into multi-scale retinex. In Proceedings of the Colour Imaging in Multimedia’98, Derby, UK, March 1998; pp. 9–17. [Google Scholar]
- Kotera, H.; Fujita, M. Appearance improvement of color image by adaptive scale-gain retinex model. In Proceedings of the IS&T/SID Tenth Color Imaging Conference, Scottsdale, AZ, USA, 12 November 2002; pp. 166–171. [Google Scholar] [CrossRef]
- Yoda, M.; Kotera, H. Appearance Improvement of Color Image by Adaptive Linear Retinex Model. In Proceedings of the IS&T International Conference on Digital Printing Technologies (NIP20), Salt Lake City, UT, USA, 31 October 2004; pp. 660–663. [Google Scholar] [CrossRef]
- McCann, J.; Rizzi, A. The Art and Science of HDR Imaging; John Wiley & Sons: Chichester, UK, 2012. [Google Scholar]
- McCann, J. Retinex Algorithms: Many spatial processes used to solve many different problems. Electron. Imaging 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Morel, J.M.; Petro, A.B.; Sbert, C. What is the right center/surround for Retinex? In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4552–4556. [Google Scholar] [CrossRef]
- Lisani, J.L.; Petro, A.B.; Sbert, C. Center/Surround Retinex: Analysis and Implementation. Image Process. Line 2021, 11, 434–450. [Google Scholar] [CrossRef]
- Rahman, Z.U.; Jobson, D.; Woodell, G.; Hines, G. Multi-sensor fusion and enhancement using the Retinex image enhancement algorithm. Proc. SPIE Int. Soc. Opt. 2002, 4736, 36–44. [Google Scholar] [CrossRef]
- Meylan, L.; Süsstrunk, S. High dynamic range image rendering with a Retinex-based adaptive filter. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2006, 15, 2820–2830. [Google Scholar] [CrossRef] [PubMed]
- Setty, S.; Nk, S.; Hanumantharaju, D.M. Development of multiscale Retinex algorithm for medical image enhancement based on multi-rate sampling. In Proceedings of the Signal Process Image Process Pattern Recognit (ICSIPR), Bangalore, India, 7–8 February 2013; Volume 1, pp. 145–150. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z. Multi-scale retinex improvement for nighttime image enhancement. Optik 2014, 125, 7143–7148. [Google Scholar] [CrossRef]
- Yin, J.; Li, H.; Du, J.; He, P. Low illumination image Retinex enhancement algorithm based on guided filtering. In Proceedings of the 2014 IEEE 3rd International Conference on Cloud Computing and Intelligence Systems, Shenzhen & Hong Kong, China, 27–29 November 2014; pp. 639–644. [Google Scholar] [CrossRef]
- Shu, Z.; Wang, T.; Dong, J.; Yu, H. Underwater Image Enhancement via Extended Multi-Scale Retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar] [CrossRef]
- Galdran, A.; Bria, A.; Alvarez-Gila, A.; Vazquez-Corral, J.; Bertalmío, M. On the Duality Between Retinex and Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8212–8221. [Google Scholar] [CrossRef]
- Huang, F. Parallelization implementation of the multi-scale retinex image-enhancement algorithm based on a many integrated core platform. Concurr. Comput. Pract. Exp. 2020, 32, e5832. [Google Scholar] [CrossRef]
- Simone, G.; Lecca, M.; Gianini, G.; Rizzi, A. Survey of methods and evaluation of Retinex-inspired image enhancers. J. Electron. Imaging 2022, 31, 063055. [Google Scholar] [CrossRef]
- Wang, W.; Wu, X.; Yuan, X.; Gao, Z. An Experiment-Based Review of Low-Light Image Enhancement Methods. IEEE Access 2020, 8, 87884–87917. [Google Scholar] [CrossRef]
- Rasheed, M.T.; Guo, G.; Shi, D.; Khan, H.; Cheng, X. An Empirical Study on Retinex Methods for Low-Light Image Enhancement. Remote Sens. 2022, 14, 4608. [Google Scholar] [CrossRef]
- Rowlands, D.A.; Finlayson, G.D. First-principles approach to image lightness processing. In Proceedings of the 31st Color Imaging Conference, Paris, France, 13–17 November 2023; pp. 115–121. [Google Scholar] [CrossRef]
- Hurlbert, A.C.; Poggio, T.A. Synthesizing a Color Algorithm from Examples. Sci. New Ser. 1988, 239, 482–485. [Google Scholar] [CrossRef]
- Hurlbert, A.C. The Computation of Color. Ph.D. Thesis, MIT Artificial Intelligence Laboratory, Cambridge, MA, USA, 1989. [Google Scholar]
- Vonikakis, V. TM-DIED: The Most Difficult Image Enhancement Dataset. 2021. Available online: https://sites.google.com/site/vonikakis/datasets/tm-died (accessed on 15 July 2024).
- Petro, A.B.; Sbert, C.; Morel, J.M. Multiscale Retinex. Image Process. Line 2014, 4, 71–88. [Google Scholar] [CrossRef]
- Tian, Z.; Qu, P.; Li, J.; Sun, Y.; Li, G.; Liang, Z.; Zhang, W. A Survey of Deep Learning-Based Low-Light Image Enhancement. Sensors 2023, 23, 7763. [Google Scholar] [CrossRef]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C.S. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Paul, J. Digital Image Colour Correction. Ph.D. Thesis, University of East Anglia, Norwich, UK, 2006. [Google Scholar]
- Gubner, J.A. Probability and Random Processes for Electrical and Computer Engineers; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Rowlands, D.A.; Finlayson, G.D. Mondrian representation of real world image statistics. In Proceedings of the London Imaging Meeting, London, UK, 28–30 June 2023; pp. 45–49. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- McCann, J.J.; McKee, S.; Taylor, T. Quantitative Studies in Retinex theory, a comparison between theoretical predictions and observer responses to Color Mondrian experiments. Vis. Res. 1976, 16, 445–458. [Google Scholar] [CrossRef] [PubMed]
- Valberg, A.; Lange-Malecki, B. “Colour constancy” in Mondrian patterns: A partial cancellation of physical chromaticity shifts by simultaneous contrast. Vis. Res. 1990, 30, 371–380. [Google Scholar] [CrossRef] [PubMed]
- McCann, J.J. Lessons Learned from Mondrians Applied to Real Images and Color Gamuts. In Proceedings of the IS&T/SID Seventh Color Imaging Conference, Scottsdale, AZ, USA, 16–19 November 1999; pp. 1–8. [Google Scholar] [CrossRef]
- Hurlbert, A. Colour vision: Is colour constancy real? Curr. Biol. 1999, 9, R558–R561. [Google Scholar] [CrossRef] [PubMed]
- Dow, M. Explicit inverses of Toeplitz and associated matrices. ANZIAM J. 2003, 44, E185–E215. [Google Scholar] [CrossRef]
- Li, X.; Zhang, B.; Liao, J.; Sander, P.V. Document rectification and illumination correction using a patch-based CNN. ACM Trans. Graph. 2019, 38, 168. [Google Scholar] [CrossRef]
- Peli, E. Contrast in complex images. J. Opt. Soc. Am. A 1990, 7, 2032–2040. [Google Scholar] [CrossRef] [PubMed]
- Durand, F.; Dorsey, J. Fast bilateral filtering for the display of high-dynamic-range images. ACM Trans. Graph. 2002, 21, 257–266. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rowlands, D.A.; Finlayson, G.D. Optimisation of Convolution-Based Image Lightness Processing. J. Imaging 2024, 10, 204. https://doi.org/10.3390/jimaging10080204
Rowlands DA, Finlayson GD. Optimisation of Convolution-Based Image Lightness Processing. Journal of Imaging. 2024; 10(8):204. https://doi.org/10.3390/jimaging10080204
Chicago/Turabian StyleRowlands, D. Andrew, and Graham D. Finlayson. 2024. "Optimisation of Convolution-Based Image Lightness Processing" Journal of Imaging 10, no. 8: 204. https://doi.org/10.3390/jimaging10080204
APA StyleRowlands, D. A., & Finlayson, G. D. (2024). Optimisation of Convolution-Based Image Lightness Processing. Journal of Imaging, 10(8), 204. https://doi.org/10.3390/jimaging10080204