FineTea: A Novel Fine-Grained Action Recognition Video Dataset for Tea Ceremony Actions


Abstract
1. Introduction
- FineTea is built as the benchmark dataset for the task of fine-grained action recognition and includes high-quality and fine-grained annotations. The FineTea dataset is publicly available at https://github.com/Changwei-Ouyang/FineTea (accessed on 27 August 2024).
- For fine-grained action recognition, the TSM-ConvNeXt network is designed to enhance temporal modeling capability. The proposed TSM-ConvNeXt achieves better performance than the baseline methods. Moreover, TSM-ConvNeXt obtains the best experimental results on the FineTea and Diving48 datasets.
2. Related Work
2.1. Coarse-Grained Action Recognition Datasets
2.2. Fine-Grained Action Recognition Datasets
2.3. Action Recognition Methods
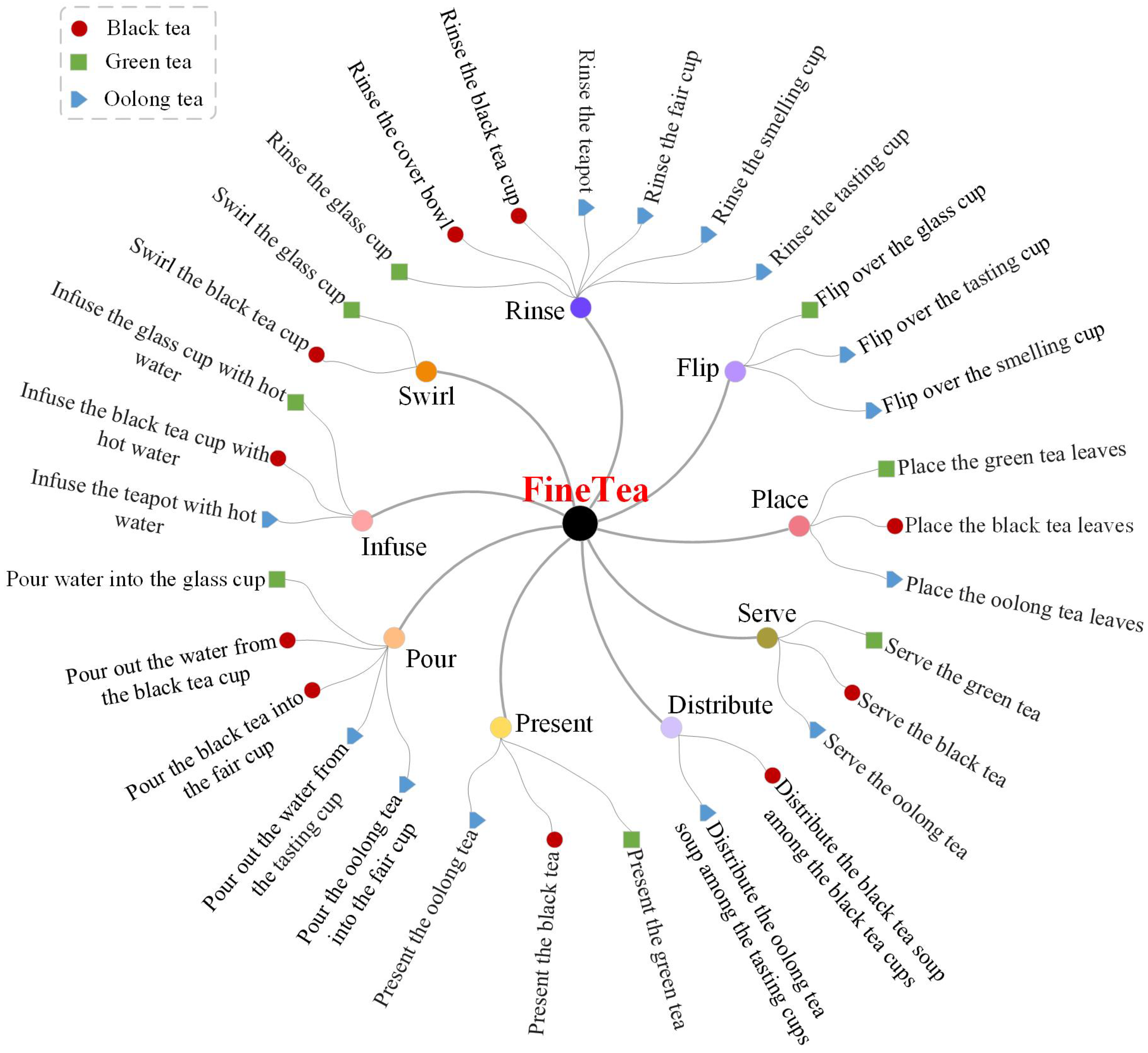
3. FineTea Dataset
3.1. Video Collection
3.2. Annotation
3.3. Dataset Split
4. Proposed Method
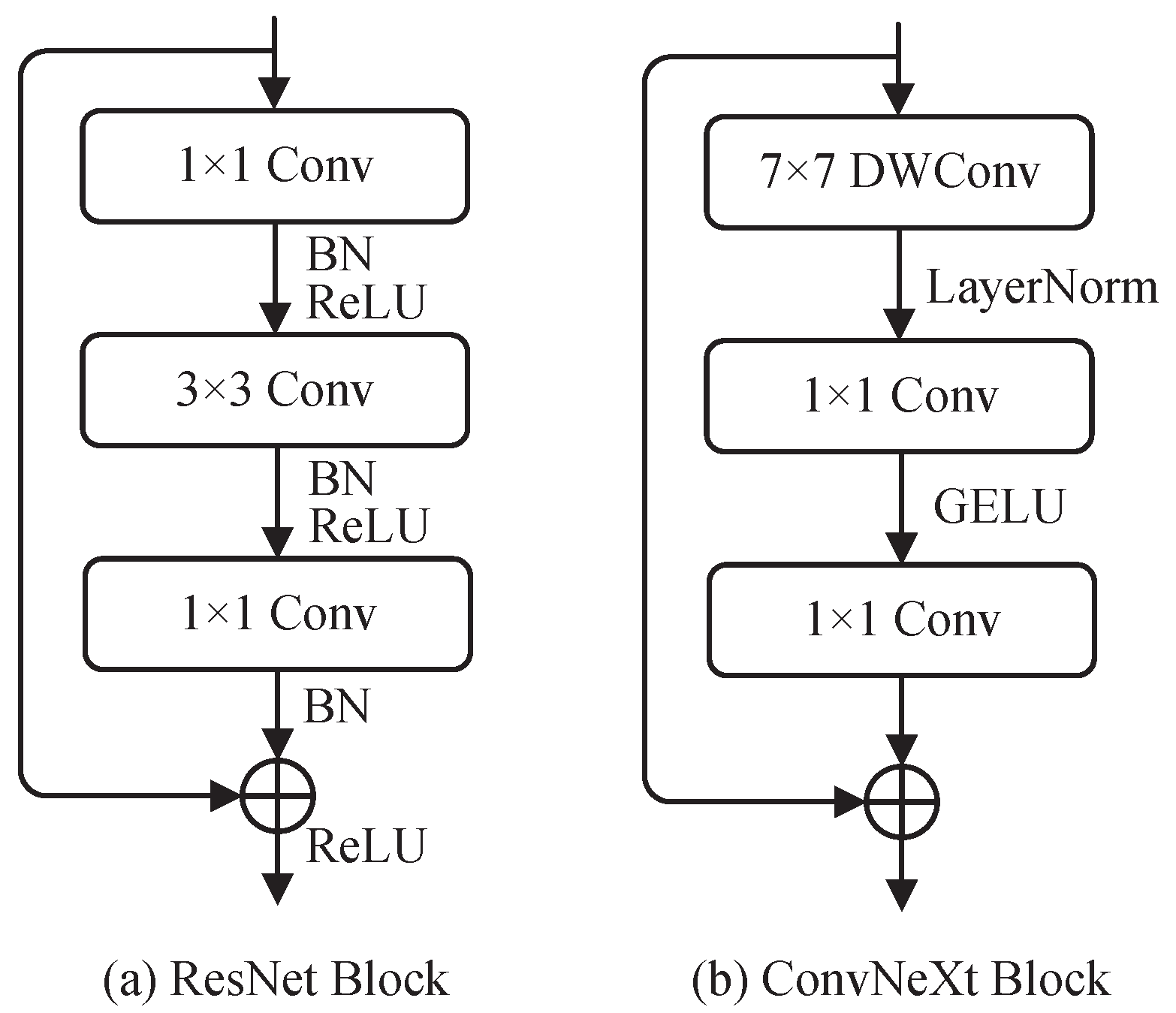
4.1. ConvNeXt Backbone
4.2. Temporal Shift Module
4.3. TSM-ConvNeXt
5. Experiment
5.1. Dataset
5.2. Experimental Setup
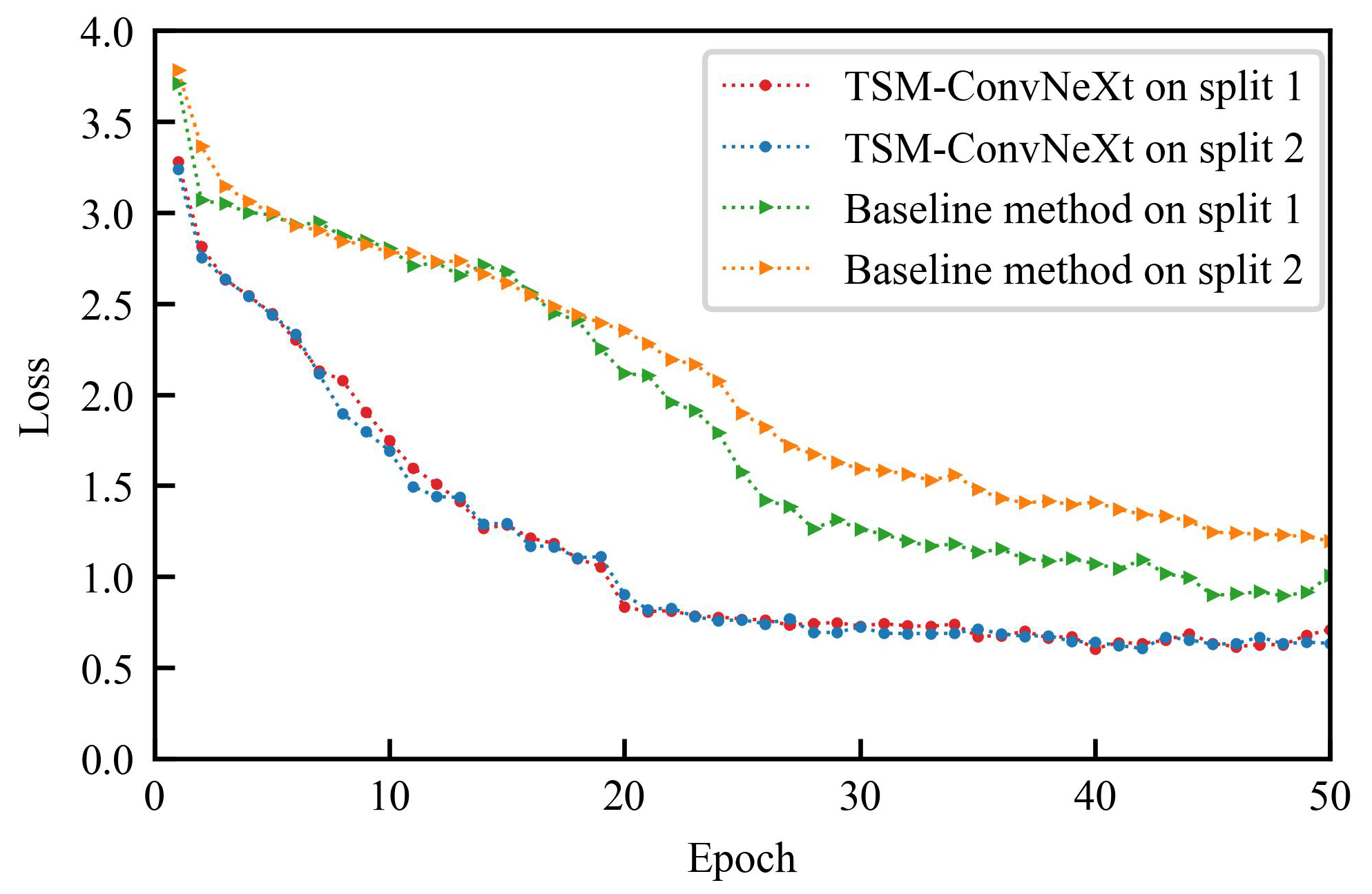
5.3. Comparison with the Baseline Method
5.4. Selection of the Hyperparameter
5.5. Ablation Experiments
5.6. Comparison with State-of-the-Art Methods
5.6.1. Comparison on the FineTea Dataset
5.6.2. Comparison on the Diving48 Dataset
5.7. Comparison of Training and Testing Times
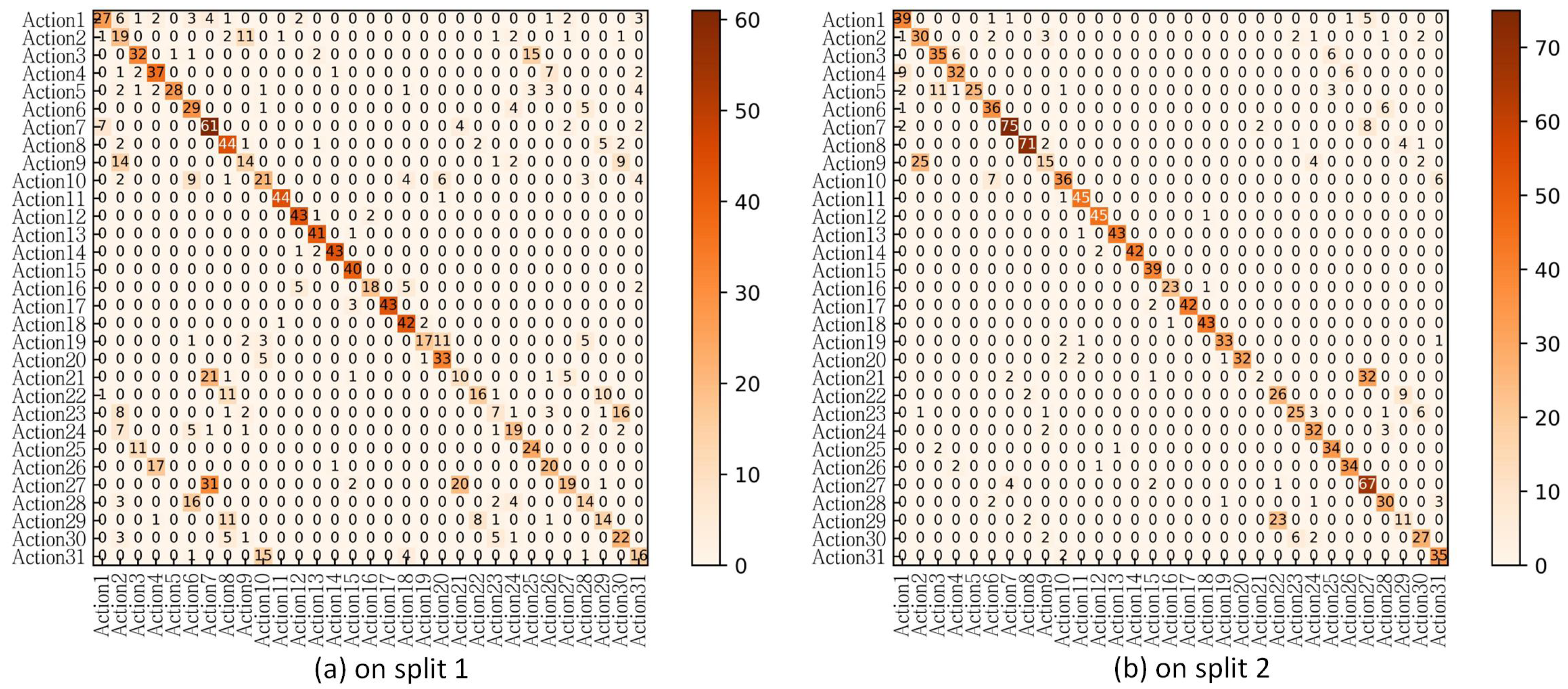
5.8. Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Faris, M.; Chiverton, J.; Ndzi, D.; Ahmed, A.I. A review on computer vision-based methods for human action recognition. J. Imaging 2020, 6, 46. [Google Scholar] [CrossRef] [PubMed]
- Rohrbach, M.; Amin, S.; Andriluka, M.; Schiele, B. A database for fine grained activity detection of cooking activities. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1194–1201. [Google Scholar]
- Piergiovanni, A.; Ryoo, M.S. Fine-grained activity recognition in baseball videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1740–1748. [Google Scholar]
- Li, Y.; Li, Y.; Vasconcelos, N. Resound: Towards action recognition without representation bias. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 513–528. [Google Scholar]
- Martin, P.E.; Benois-Pineau, J.; Péteri, R.; Morlier, J. Fine grained sport action recognition with Twin spatio-temporal convolutional neural networks: Application to table tennis. Multimed. Tools Appl. 2020, 79, 20429–20447. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 813–824. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 10078–10093. [Google Scholar]
- Yang, T.; Zhu, Y.; Xie, Y.; Zhang, A.; Chen, C.; Li, M. AIM: Adapting image models for efficient video action recognition. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 32–36. [Google Scholar]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Idrees, H.; Zamir, A.R.; Jiang, Y.G.; Gorban, A.; Laptev, I.; Sukthankar, R.; Shah, M. The thumos challenge on action recognition for videos “in the wild”. Comput. Vis. Image Underst. 2017, 155, 1–23. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 510–526. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5842–5850. [Google Scholar]
- Shao, D.; Zhao, Y.; Dai, B.; Lin, D. Finegym: A hierarchical video dataset for fine-grained action understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2616–2625. [Google Scholar]
- Ullah, H.; Munir, A. Human activity recognition using cascaded dual attention cnn and bi-directional gru framework. J. Imaging 2023, 9, 130. [Google Scholar] [CrossRef] [PubMed]
- Host, K.; Pobar, M.; Ivasic-Kos, M. Analysis of movement and activities of handball players using deep neural networks. J. Imaging 2023, 9, 80. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- MMAction2 Contributors. OpenMMLab’s Next Generation Video Understanding Toolbox and Benchmark. Available online: https://github.com/open-mmlab/mmaction2 (accessed on 27 August 2024).
- Koh, T.C.; Yeo, C.K.; Jing, X.; Sivadas, S. Towards efficient video-based action recognition: Context-aware memory attention network. SN Appl. Sci. 2023, 5, 330. [Google Scholar] [CrossRef]
- Hao, Y.; Wang, S.; Tan, Y.; He, X.; Liu, Z.; Wang, M. Spatio-temporal collaborative module for efficient action recognition. IEEE Trans. Image Process. 2022, 31, 7279–7291. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Wang, S.; Cao, P.; Gao, X.; Xu, T.; Wu, J.; He, X. Attention in attention: Modeling context correlation for efficient video classification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7120–7132. [Google Scholar] [CrossRef]
- Zhang, C.; Gupta, A.; Zisserman, A. Temporal query networks for fine-grained video understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4486–4496. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Ma, Y.; Wang, R. Relative-position embedding based spatially and temporally decoupled Transformer for action recognition. Pattern Recognit. 2024, 145, 109905. [Google Scholar] [CrossRef]
- Kim, M.; Kwon, H.; Wang, C.; Kwak, S.; Cho, M. Relational self-attention: What’s missing in attention for video understanding. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–16 December 2021; pp. 8046–8059. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Field | Number of Classes | Number of Clips | Video Source |
|---|---|---|---|---|
| MPII Cooking [2] | Cooking | 67 | 5609 | Self-collected |
| MLB-YouTube [3] | Baseball | 9 | 4290 | Major League Baseball |
| Diving48 [4] | Diving | 48 | 18,404 | Diving competition |
| TTStroke-21 [5] | Table tennis | 21 | 1154 | Self-collected |
| FineTea | Tea ceremony | 31 | 2745 | Self-collected |
| ID | Action | Number of Clips | Tea Ceremony Activity |
|---|---|---|---|
| 1 | Rinse the cover bowl | 99 | Black tea |
| 2 | Rinse the black teacup | 81 | Black tea |
| 3 | Present the black tea | 98 | Black tea |
| 4 | Place the black tea leaves | 97 | Black tea |
| 5 | Swirl the black teacup | 88 | Black tea |
| 6 | Pour out the water from the black teacup | 82 | Black tea |
| 7 | Infuse the black teacup with hot water | 163 | Black tea |
| 8 | Pour the black tea into the fair cup | 136 | Black tea |
| 9 | Distribute the black tea soup among the black teacups | 86 | Black tea |
| 10 | Serve the black tea | 99 | Black tea |
| 11 | Flip over the glass cup | 91 | Green tea |
| 12 | Rinse the glass cup | 92 | Green tea |
| 13 | Present the green tea | 86 | Green tea |
| 14 | Place the green tea leaves | 90 | Green tea |
| 15 | Pour water into the glass cup | 79 | Green tea |
| 16 | Swirl the glass cup | 54 | Green tea |
| 17 | Infuse the glass cup with hot water | 90 | Green tea |
| 18 | Serve the green tea | 89 | Green tea |
| 19 | Flip over the smelling cup | 76 | Oolong tea |
| 20 | Flip over the tasting cup | 76 | Oolong tea |
| 21 | Rinse the teapot | 76 | Oolong tea |
| 22 | Rinse the fair cup | 76 | Oolong tea |
| 23 | Rinse the smelling cup | 76 | Oolong tea |
| 24 | Rinse the tasting cup | 75 | Oolong tea |
| 25 | Present the oolong tea | 72 | Oolong tea |
| 26 | Place the oolong tea leaves | 72 | Oolong tea |
| 27 | Infuse the teapot with hot water | 147 | Oolong tea |
| 28 | Pour out the water from the tasting cup | 76 | Oolong tea |
| 29 | Pour the oolong tea into the fair cup | 72 | Oolong tea |
| 30 | Distribute the oolong tea soup among the tasting cups | 74 | Oolong tea |
| 31 | Serve the oolong tea | 74 | Oolong tea |
| Set | Tea Ceremony Activity | Number of Clips | Total |
|---|---|---|---|
| Set 1 | Green Tea | 331 | 1378 |
| Black Tea | 530 | ||
| Oolong Tea | 517 | ||
| Set 2 | Green Tea | 340 | 1367 |
| Black Tea | 499 | ||
| Oolong Tea | 528 |
| Method | Backbone | Pre-Train | Accuracy/% | ||
|---|---|---|---|---|---|
| Split 1 | Split 2 | Average | |||
| Baseline [17] | ResNet50 | ImageNet | 51.65 | 64.37 | 58.01 |
| TSM-ConvNeXt | ConvNeXt-B | ImageNet | 56.18 | 74.46 | 65.32 |
| Shift Proportion Parameter | Accuracy/% | ||
|---|---|---|---|
| Split 1 | Split 2 | Average | |
| 1/8 | 56.18 | 74.46 | 65.32 |
| 1/4 | 59.69 | 76.42 | 68.06 |
| 1/2 | 45.72 | 67.27 | 56.50 |
| Method | Backbone | Pre-Train | Accuracy/% | ||
|---|---|---|---|---|---|
| Split 1 | Split 2 | Average | |||
| ConvNeXt | ConvNeXt-B | ImageNet | 57.28 | 75.76 | 66.52 |
| TSM-ConvNeXt | ConvNeXt-B | ImageNet | 59.69 | 76.42 | 68.06 |
| Parameter | TimeSformer [12] | VideoSwin [13] | VideoMAE [14] | AIM [15] |
|---|---|---|---|---|
| Optimizer | SGD | AdamW | AdamW | AdamW |
| Optimizer momentum | 0.9 | = 0.9, = 0.999 | = 0.9, = 0.999 | = 0.9, = 0.999 |
| Weight decay | 1 × 10−4 | 0.05 | 0.05 | 0.05 |
| Learning rate | 5 × 10−3 | 1 × 10−3 | 5 × 10−4 | 3 × 10−4 |
| Batch size | 8 | 2 | 4 | 4 |
| Method | Backbone | Pre-Train | Parameter/M | Epoch | Frames | Accuracy/% | ||
|---|---|---|---|---|---|---|---|---|
| Split 1 | Split 2 | Average | ||||||
| TimeSformer [12] | ViT-B | ImageNet-21K | 86 | 50 | 8 | 56.40 | 75.91 | 65.16 |
| VideoSwin [13] | Swin-B | ImageNet | 88 | 50 | 32 | 54.50 | 75.98 | 65.24 |
| VideoMAE [14] | ViT-B | Kinetics-400 | 88 | 300 | 16 | 38.45 | 60.23 | 49.34 |
| AIM [15] | ViT-B | CLIP | 97 | 50 | 16 | 51.50 | 77.36 | 64.43 |
| TSM-ConvNeXt8 | ConvNeXt-B | ImageNet | 88 | 50 | 8 | 59.69 | 76.42 | 68.06 |
| TSM-ConvNeXt16 | ConvNeXt-B | ImageNet | 88 | 50 | 16 | 62.69 | 80.12 | 71.41 |
| Method | Backbone | Pre-Train | Accuracy/% |
|---|---|---|---|
| CAMA-Net [40] | ResNet101 | ImageNet | 76.9 |
| STC [41] | ResNet50 | ImageNet | 77.9 |
| AIA(TSM) [42] | ResNet50 | ImageNet | 79.4 |
| TimeSformer-L [12] | ViT-B | ImageNet | 81.0 |
| TQN [43] | S3D [44] | Kinetics-400 | 81.8 |
| RPE-STDT [45] | ViT-B | ImageNet | 81.8 |
| RSANet-R50 [46] | ResNet50 | ImageNet | 84.2 |
| TSM-ConvNeXt | ConvNeXt-B | ImageNet | 85.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, C.; Yi, Y.; Wang, H.; Zhou, J.; Tian, T. FineTea: A Novel Fine-Grained Action Recognition Video Dataset for Tea Ceremony Actions. J. Imaging 2024, 10, 216. https://doi.org/10.3390/jimaging10090216
Ouyang C, Yi Y, Wang H, Zhou J, Tian T. FineTea: A Novel Fine-Grained Action Recognition Video Dataset for Tea Ceremony Actions. Journal of Imaging. 2024; 10(9):216. https://doi.org/10.3390/jimaging10090216
Chicago/Turabian StyleOuyang, Changwei, Yun Yi, Hanli Wang, Jin Zhou, and Tao Tian. 2024. "FineTea: A Novel Fine-Grained Action Recognition Video Dataset for Tea Ceremony Actions" Journal of Imaging 10, no. 9: 216. https://doi.org/10.3390/jimaging10090216
APA StyleOuyang, C., Yi, Y., Wang, H., Zhou, J., & Tian, T. (2024). FineTea: A Novel Fine-Grained Action Recognition Video Dataset for Tea Ceremony Actions. Journal of Imaging, 10(9), 216. https://doi.org/10.3390/jimaging10090216