Abstract
The hyperspectral remote sensing images of agricultural crops contain rich spectral information, which can provide important details about crop growth status, diseases, and pests. However, existing crop classification methods face several key limitations when processing hyperspectral remote sensing images, primarily in the following aspects. First, the complex background in the images. Various elements in the background may have similar spectral characteristics to the crops, and this spectral similarity makes the classification model susceptible to background interference, thus reducing classification accuracy. Second, the differences in crop scales increase the difficulty of feature extraction. In different image regions, the scale of crops can vary significantly, and traditional classification methods often struggle to effectively capture this information. Additionally, due to the limitations of spectral information, especially under multi-scale variation backgrounds, the extraction of crop information becomes even more challenging, leading to instability in the classification results. To address these issues, a semantic-guided transformer network (SGTN) is proposed, which aims to effectively overcome the limitations of these deep learning methods and improve crop classification accuracy and robustness. First, a multi-scale spatial–spectral information extraction (MSIE) module is designed that effectively handle the variations of crops at different scales in the image, thereby extracting richer and more accurate features, and reducing the impact of scale changes. Second, a semantic-guided attention (SGA) module is proposed, which enhances the model’s sensitivity to crop semantic information, further reducing background interference and improving the accuracy of crop area recognition. By combining the MSIE and SGA modules, the SGTN can focus on the semantic features of crops at multiple scales, thus generating more accurate classification results. Finally, a two-stage feature extraction structure is employed to further optimize the extraction of crop semantic features and enhance classification accuracy. The results show that on the Indian Pines, Pavia University, and Salinas benchmark datasets, the overall accuracies of the proposed model are 98.24%, 98.34%, and 97.89%, respectively. Compared with other methods, the model achieves better classification accuracy and generalization performance. In the future, the SGTN is expected to be applied to more agricultural remote sensing tasks, such as crop disease detection and yield prediction, providing more reliable technical support for precision agriculture and agricultural monitoring.
1. Introduction
Crop classification is an important application of hyperspectral remote sensing technology [1]. Thanks to the numerous narrow spectral bands, hyperspectral imaging has been widely applied in various fields such as environmental monitoring, agriculture, mineral exploration, and urban planning [2,3,4,5]. Hyperspectral images capture continuous spectral information of target objects across a wide spectral range, enabling the detection of subtle spectral reflectance differences on material surfaces [6,7,8]. However, due to the high morphological and color similarity of crops, as well as the complexity of the background (e.g., the mixture of weeds and crops), fine-grained crop classification becomes a significant challenge.
In recent years, with the advancement of computational power and the development of machine learning algorithms [9,10], particularly deep learning methods, the rapid progress of crop hyperspectral image classification technology has been facilitated [11,12,13]. These technological advancements have not only improved classification accuracy but also made significant strides in handling high-dimensional data and reducing computational complexity [14,15]. Deep learning-based methods can automatically extract deep abstract features of ground objects from hyperspectral images, which has led to widespread applications in the remote sensing field [16,17,18]. Among these, convolutional neural networks (CNNs) can effectively capture local details and deep semantic features in images through convolution operations [19]. Zhang et al. [20] used 2D CNNs to effectively extract complex features of desert grasslands. Falaschetti et al. [21] utilized CNNs for pest and disease recognition in plant leaf images. Although CNNs have achieved remarkable results in extracting image features, they face certain limitations in handling long-range dependencies and capturing global features, which restricts their application in hyperspectral image classification [22]. This is especially true in crop hyperspectral images, where the high color similarity between crops and weeds makes it difficult to accurately distinguish between different crop types.
Recently, image classification methods based on the transformer model have garnered widespread attention from researchers [23]. The transformer model, through its self-attention mechanism, can directly model global dependencies and capture richer feature representations, making it particularly suitable for handling the spatial complexity and high-dimensional spectral characteristics of hyperspectral data [24]. Unlike CNNs, which rely on convolution operations, transformers aggregate features from different scales and spatial locations through self-attention and multi-head attention mechanisms, demonstrating stronger expressiveness and flexibility in hyperspectral image classification [25]. This novel approach has provided new ideas and tools for hyperspectral image classification, driving further advancements in the field. Yang et al. [26] demonstrated superior classification performance by applying the transformer model to hyperspectral images compared to CNNs. Additionally, some studies have shown that combining CNNs’ local feature extraction capability with the transformer’s ability to capture long-range dependencies can further improve hyperspectral image classification performance. For example, Zhang et al. [27] introduced convolution operations within the multi-head self-attention mechanism to better capture local–global spectral features of hyperspectral images. Wang et al. [28] improved the ResNet-34 network to extract features from hyperspectral images and then passed these features into a transformer to capture global dependencies, thus enhancing classification performance. Although the combination of CNNs and transformers effectively improves hyperspectral image classification performance, these methods overlook the issue of spatial information loss due to the serialization processing of transformer models.
To address the learning deficiencies of transformer models in spatial information, researchers have proposed several effective solutions that combine CNNs and transformers to improve model performance. For example, Zhao et al. [29] achieved feature fusion across different layers by interactively combining CNNs and transformers. This approach effectively combines CNNs’ advantages in local feature extraction with transformers’ capabilities in global feature modeling, thereby enhancing the learning of spatial information. However, this fusion method still faces challenges such as increased model complexity and reduced training efficiency. Li et al. [30] proposed a hierarchical feature fusion strategy based on 3D-CNNs, aimed at joint learning of spatial–spectral features. This method captures spatial and spectral information in hyperspectral images more comprehensively through 3D convolution operations. However, in practical applications, the fixed-size image sampling strategy still introduces a large amount of background heterogeneous information, which may interfere with the model’s ability to predict crop labels. Additionally, due to the spectral similarity between the background and crops, this background interference becomes especially pronounced in various scenarios, leading to a decline in classification performance.
To better address these challenges, this paper proposes a semantic-guided transformer network (SGTN) for the fine-grained classification of crop hyperspectral images. SGTN introduces a multi-scale spatial–spectral information extraction (MSIE) module, specifically designed to effectively model crop variations at different scales, thereby reducing the impact of background information. This module not only captures the changing characteristics of crops at multiple scales but also enhances the richness and accuracy of features, laying a solid foundation for subsequent classification tasks. Furthermore, SGTN includes a semantic-guided attention (SGA) module, which improves the model’s sensitivity to crop semantic information. By precisely focusing on crop regions, this module effectively reduces background interference and improves classification accuracy. Through the integrated use of the MSIE and SGA modules, SGTN excels in feature extraction and fusion, significantly addressing the limitations encountered by existing methods in hyperspectral image classification tasks. This paper aims to enhance the fine-grained classification accuracy of crops, providing technical support for the development of precision agriculture. The main contributions of this article are as follows:
- (1)
- The SGTN model is proposed for hyperspectral image crop classification, achieving a balance between accuracy and speed.
- (2)
- The MSIE and SGA modules are designed, where MSIE is aimed at extracting multi-scale information of crops, while SGA enhances the semantic representation of the crops.
- (3)
- Extensive experiments are conducted on three benchmark datasets, and the proposed model achieves state-of-the-art performance compared to the most advanced methods.
2. Methodology
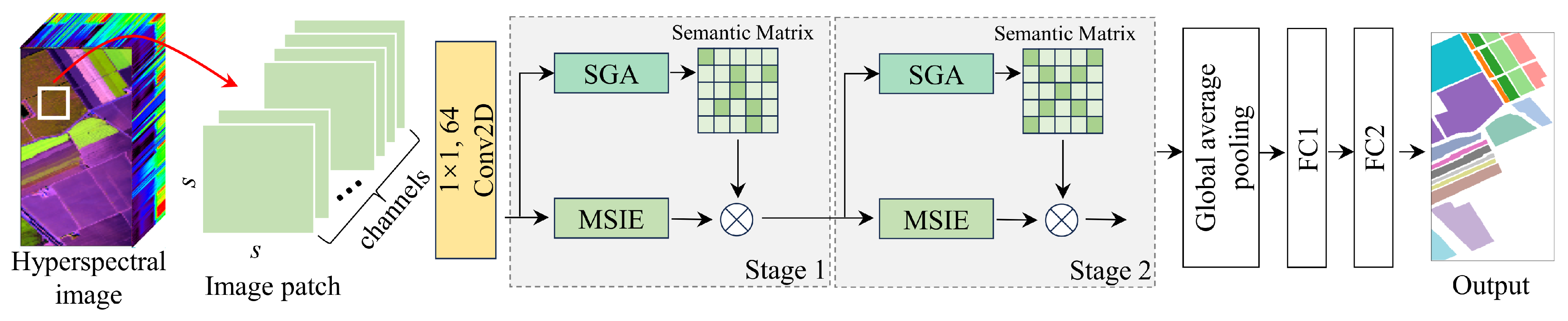
The SGTN structure proposed in this study is shown in Figure 1. The network consists of two stages of feature extraction layers. Each stage includes the MSIE and SGA modules, where the MSIE module is primarily used to extract spatial information of crops at different scales, and the SGA module guides the model to learn more semantically relevant features. After feature extraction, a global average pooling function is applied to aggregate the spatial information. This is followed by two fully connected layers that output the crop categories. It is important to note that 64 convolution filters of size 1 × 1 are used to reduce the spectral dimensionality. In the fully connected (FC) layers, the number of neurons in the layers is distributed as 32 and the corresponding number of crop categories. Overall, the feature extraction layer of the model can be divided into two branches. The main branch is the MSIE module, which is primarily responsible for learning crop features, while the other branch is the SGA module, which focuses on semantic guidance to improve the feature learning of the main branch. Notably, the model’s input patches are sampled using a sliding window approach with a fixed spatial size, aimed at better capturing spatial information. In general, the label of the central pixel of the patch is typically considered the classification label of the entire patch, representing the category of the most representative pixel within the patch. Specifically, if the spatial size of a patch is , the label of the central pixel is usually assigned as the label for the entire patch, ensuring an effective representation of the region’s features and its category.
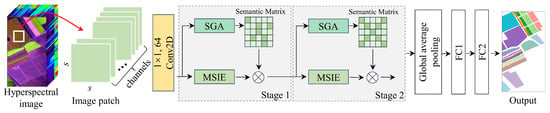
Figure 1.
The SGTN model framework, where the symbol ⊗ represents element-wise multiplication.
2.1. Multi-Scale Spatial–Spectral Information Extraction
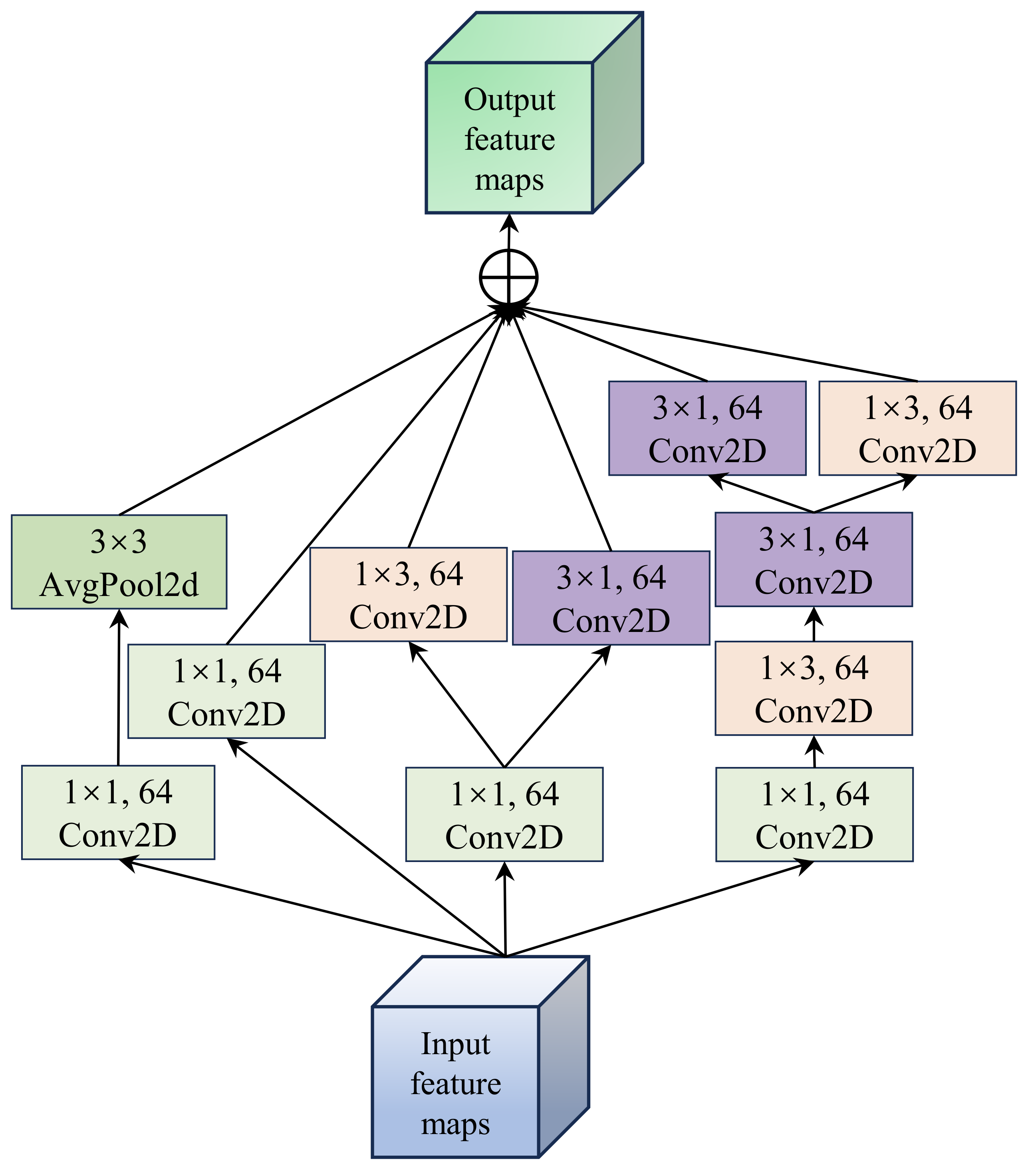
The MSIE module, as the primary feature extraction structure of the model, effectively captures the spatial information of crops, as shown in Figure 2. This module extracts features through parallel multiple branches and then aggregates and outputs the corresponding feature maps from each branch. In the first branch, a 1 × 1 convolution kernel is first used to extract spectral details from the image, followed by a 3 × 3 2D average pooling function to aggregate the spatial information. To ensure spatial scale invariance, zero padding is applied to the 2D pooling function. For the second branch, a 1 × 1 convolution kernel is employed to better capture the nonlinear spectral variation details. The third branch follows a similar structure to the first branch, where a 1 × 1 convolution kernel is used for spectral feature learning, followed by 1 × 3 and 3 × 1 convolution kernels to capture edge detail features while reducing model parameters. In contrast to the third branch, the fourth branch considers the impact of series and parallel connections on model learning. Therefore, it uses concatenated 1 × 3 and 3 × 1 convolution kernels to further enhance the model’s learning capability. Specifically, a 1 × 1 convolution kernel is first applied, followed by concatenated 1 × 3 and 3 × 1 convolution kernels, and then parallel feature extraction from both convolution kernels. It is important to note that, to ensure the feature maps from different branches can be correctly aggregated, the number of filters in all convolution kernels is set to 64.
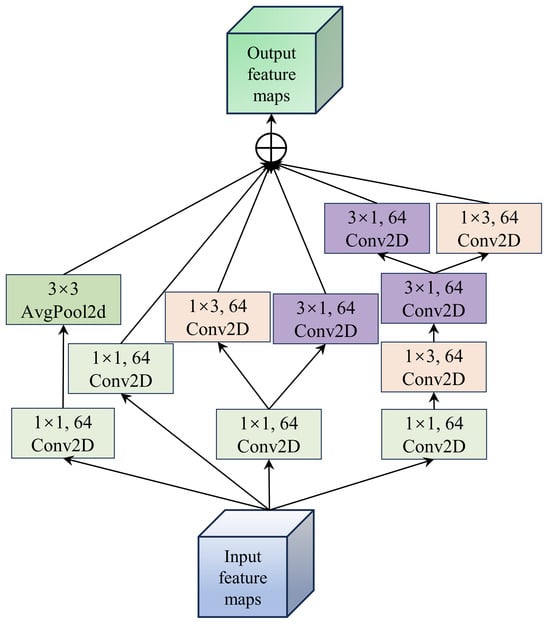
Figure 2.
Illustration of the MSIE module, where the symbol ⊕ denotes element-wise summation.
Overall, the MSIE module is designed to achieve efficient feature representation through multi-scale feature extraction and computational optimization. This module utilizes multiple parallel branches to extract features at different scales, combining 1 × 1 convolutions to capture local details and 3 × 3 convolutions to extract local spatial information, thereby realizing the fusion of multi-scale features. Notably, the use of parallel branches allows for the processing of different types of features, adapting to the diverse patterns and scale variations within the image. Additionally, the traditional 3 × 3 convolution is decomposed into two unidirectional convolutions (i.e., 1 × 3 and 3 × 1 convolutions) to achieve the same effect while reducing the number of parameters to improve efficiency. Furthermore, performing convolution operations in both horizontal and vertical directions enhances the boundary feature information of the crops.
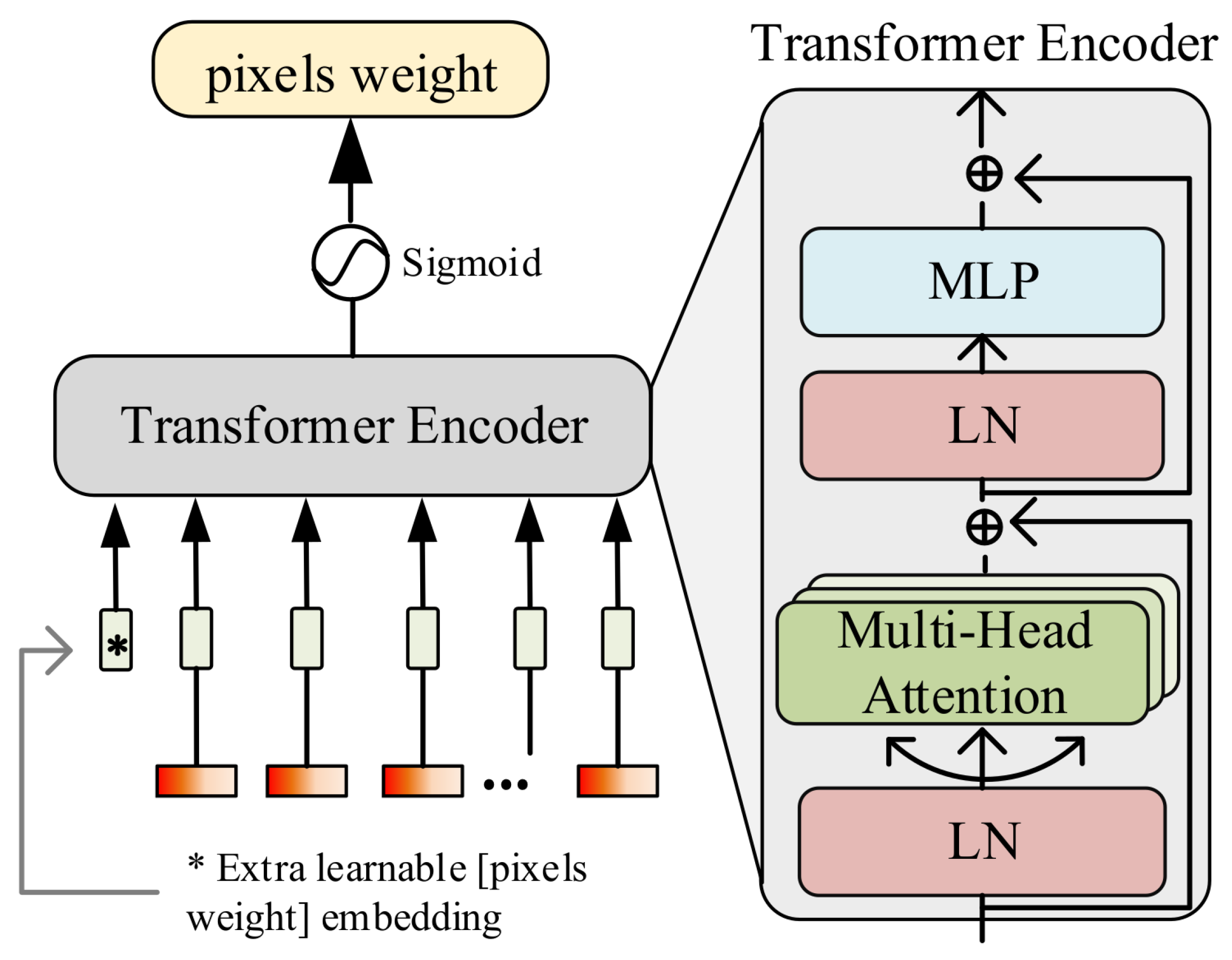
2.2. Semantically Guided Attention Module
The SGA module is designed by improving the transformer model, incorporating multi-head self-attention, multilayer perceptron (MLP), and layer normalization (LN), as shown in Figure 3. This module aims to guide the model in strengthening the semantic output for crops. In the SGA module, the original positional encoding function in the transformer is discarded, and a learnable pixel weight parameter is embedded along the channel dimension, where s denotes the spatial size. The mathematical representation is as follows:
where represents the concatenation of data along the specified dimension. x denotes the original input data to the model, and represents the concatenated result, with dimensions , where c is the number of channels in the data. Additionally, considering the feature redundancy caused by a large number of channels, this paper uses a learnable parameter to filter important spectral bands. The mathematical expression is as follows:
where represents the Sigmoid activation function.
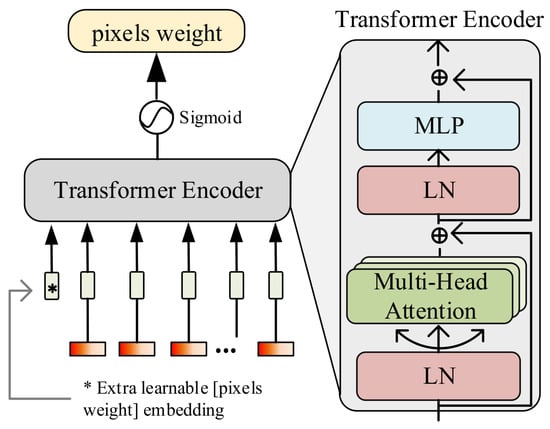
Figure 3.
Illustration of the SGA module.
In the transformer model, before the input is passed into the multi-head self-attention mechanism, it undergoes LN to reduce covariate shift during training and accelerate the convergence of training. In the self-attention layer, three different linear transformations are used to generate three new vector representations: the query vector (Q), the key vector (K), and the value vector (V). For each query vector, its dot product with all key vectors is calculated to measure the similarity between the query and each key. The attention weights are then computed based on the results of these dot products, and these weights are used in matrix multiplication with the value vectors to obtain the final output. The calculation formula for the attention weights is as follows:
where represents the dimensionality of the key vector, while Q, K, and V are the query matrix, key matrix, and value matrix, respectively. The softmax function is applied to the scaled dot product of Q and K to produce a set of attention weights, which are then used to compute the weighted sum of the value vectors. This process allows the model to focus on different parts of the input sequence when making predictions.
In multi-head self-attention, the attention mechanism is executed independently multiple times, with each attention head using different linear transformation parameters to generate distinct queries, keys, and values. These independent attention heads allow the model to focus on different parts or features of the input sequence simultaneously, capturing various relationships and patterns from multiple perspectives. The formula for multi-head self-attention is as follows:
where , where h is the number of heads, and is the linear transformation matrix used to transform the output of multiple heads back to the original dimensions after splicing. The function represents concatenating the results of each self-attention computation along the feature dimension c to obtain the final output of the multi-head self-attention mechanism.
After obtaining the output from the self-attention layer, the model’s nonlinear expressiveness is enhanced through the MLP. It is worth noting that a residual connection is used in the transformer encoder structure to facilitate feature reuse within the network, allowing the model to learn more efficiently. After the transformer encoding, the pixel weight parameter is extracted and reshaped to a spatial size of , resulting in weights with the same spatial dimensions as the input image. Notably, this weight is normalized using a Sigmoid activation function to obtain the weight size for each spatial pixel. Based on this weight , the network is continuously guided during the learning process to focus on the true semantic categories of the image, thereby minimizing background interference. Finally, this weight is element-wise multiplied with the main branch to enhance the model’s semantic output, which in turn improves crop recognition accuracy in complex background scenarios.
3. Results and Analysis
All experiments in this study were conducted on hardware consisting of an Intel(R) Xeon(R) CPU E5-2682 V4, an NVIDIA GeForce RTX 3060-12G GPU, and 30 GB of memory. The programming language used was Python 3.8, and the deep learning framework was PyTorch 1.12.1. To effectively evaluate the classification performance of the model, three evaluation metrics were selected: overall accuracy (OA), average accuracy (AA), and Kappa coefficient.
In the experiment, cross-entropy was selected as the loss function, the batch size was set to 64, Adam was used as the optimizer, the learning rate was 0.001, and the number of iterations was 100. The SGA module in the model was set to a depth of one layer, and the number of attention heads in the self-attention mechanism was set to one. To eliminate experimental variability, the results were averaged over five repeated experiments.
3.1. Datasets
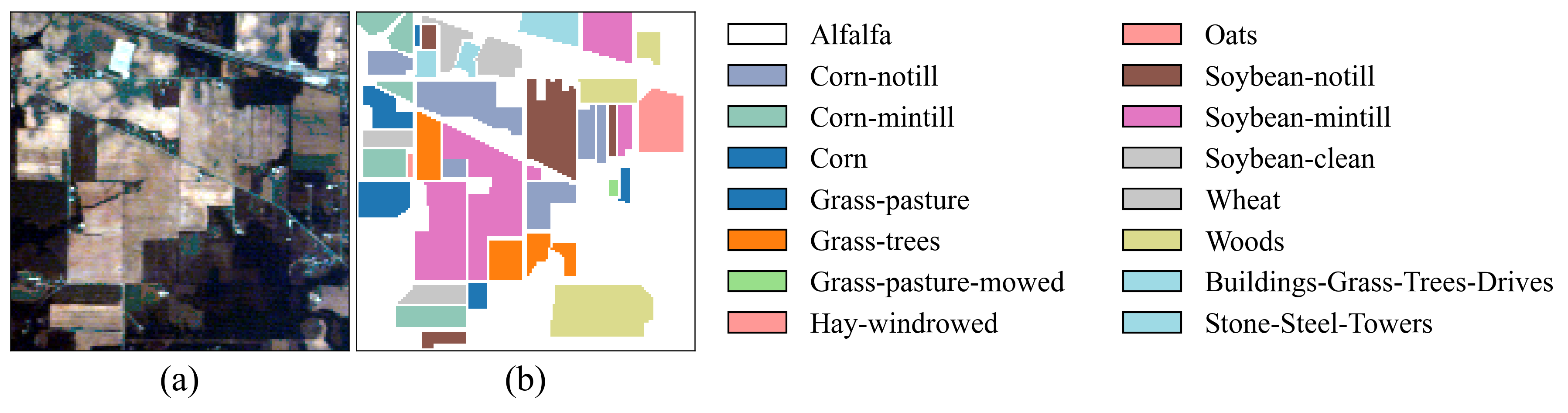
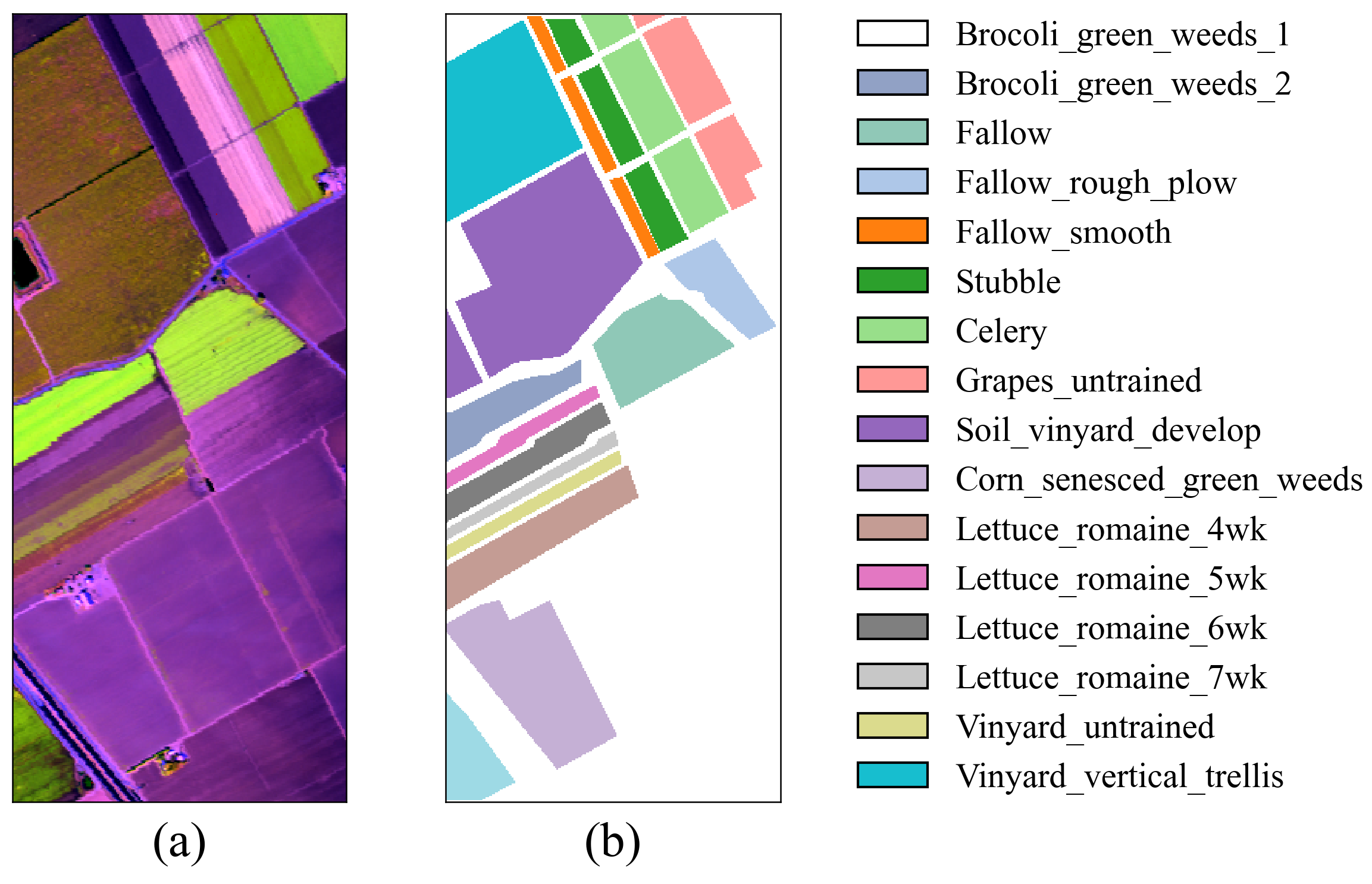
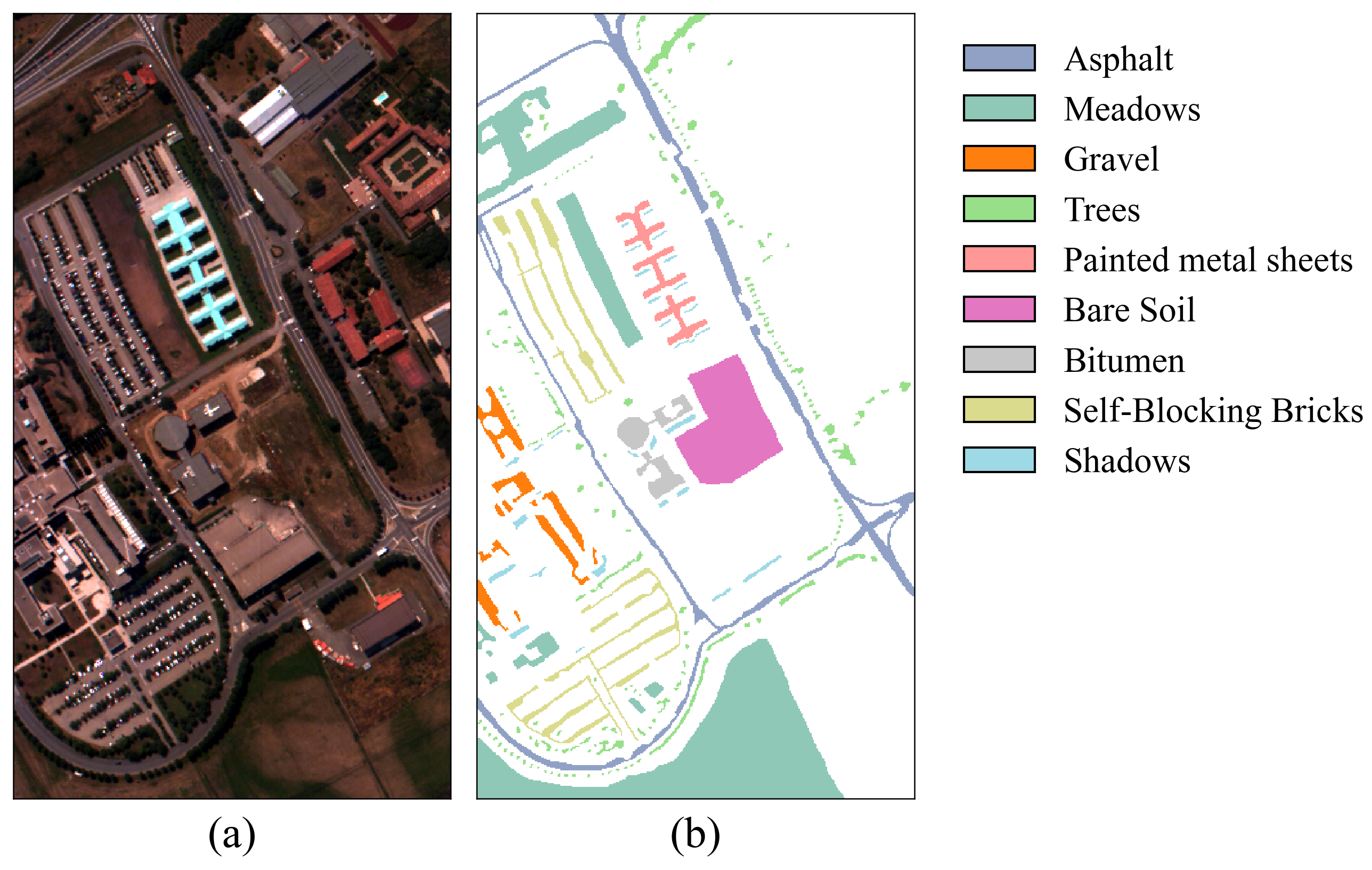
In the experiments, two crop hyperspectral image benchmark datasets were used: Indian Pines (IP) and Salinas (SA) [31]. Additionally, the Pavia University (PU) dataset was chosen to assess the model’s generalization capability. The IP dataset is a typical crop dataset collected from the Indian Pines test site in Northwest Indiana, USA, using the AVIRIS sensor (Jet Propulsion Laboratory, Pasadena, CA, USA). It has a spatial size of 145 × 145 and includes 220 spectral bands. After removing bands that cannot be reflected by water, 200 bands were retained for analysis. This dataset contains 16 crop categories and a total of 10,249 labeled samples. The SA dataset, also obtained by the AVIRIS sensor, was collected near Salinas, CA, USA. The image has a spatial size of 512 × 217, with an original 224 spectral bands. After removing noise-affected bands, 204 valid bands were retained for analysis. This dataset includes 16 crop categories and a total of 54,129 labeled samples. The PU dataset was obtained by the ROSIS sensor and collected near the University of Pavia, Italy. It has a spatial size of 610 × 340 and contains 103 spectral bands. This dataset includes nine categories and a total of 42,776 labeled samples. In the experiments, for the IP dataset, 10%, 10%, and 80% of the samples were randomly selected for the training set, validation set, and test set, respectively. For the PU and SA datasets, 1%, 1%, and 98% of the samples were randomly selected for the training set, validation set, and test set, respectively. The sample divisions for the three datasets are shown in Table 1, Table 2 and Table 3, and the false color images and ground truth are shown in Figure 4, Figure 5 and Figure 6.

Table 1.
Sample division results for the IP dataset.
Table 2.
Sample division results for the SA dataset.
Table 3.
Sample division results for the PU dataset.
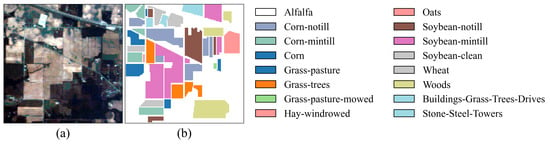
Figure 4.
False-color image and ground truth for the IP dataset. (a) False-color image. (b) Ground truth.
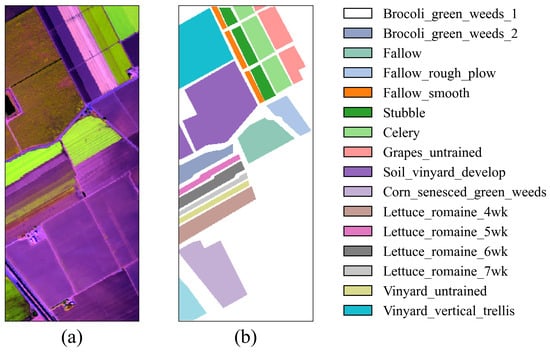
Figure 5.
False-color image and ground truth for the SA dataset. (a) False-color image. (b) Ground truth.
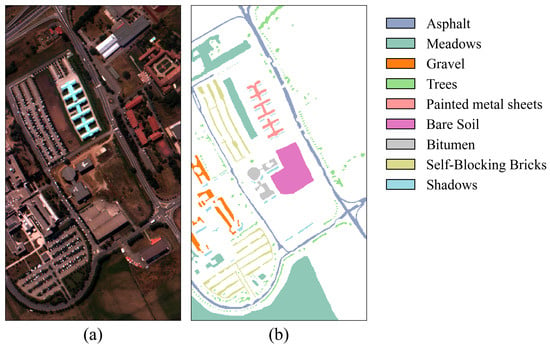
Figure 6.
False-color image and ground truth for the PU dataset. (a) False-color image. (b) Ground truth.
3.2. Impact of Space Size
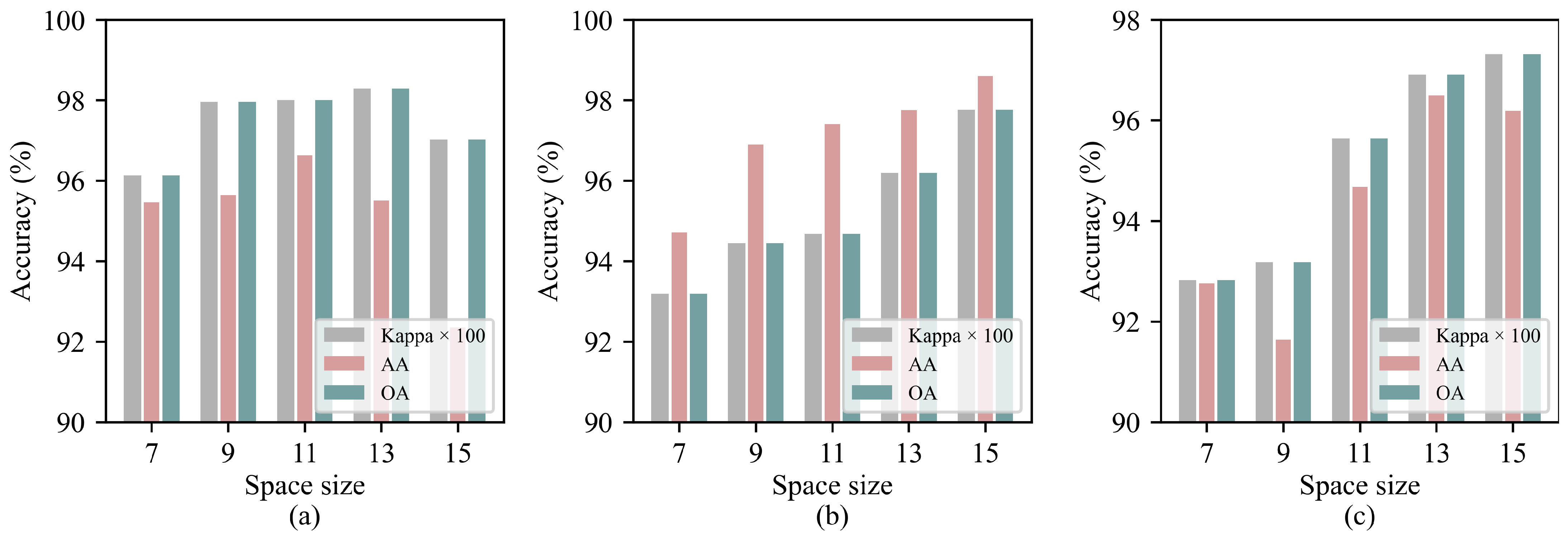
Different spatial sizes have a significant impact on the model’s classification performance. Generally, as the spatial size increases, the spatial information contained in the image becomes more abundant. However, this also introduces more redundant information, which may negatively affect the model’s classification performance. Therefore, to evaluate the impact of different spatial sizes on the proposed SGTN model, five spatial scales in the range of 7, 9, 11, 13, 15 were selected for experimentation. The results are shown in Figure 7. From the figure, it can be observed that for all three datasets, classification accuracy tends to increase as the spatial size grows. For the IP dataset, the impact of different spatial sizes on the model accuracy is relatively small, with the classification accuracy reaching its maximum when the spatial size is 13. The PU and SA datasets are more sensitive to different input spatial sizes, with smaller spatial sizes resulting in lower classification accuracy. When the spatial size reaches 15, the classification accuracy of both datasets reaches its peak.
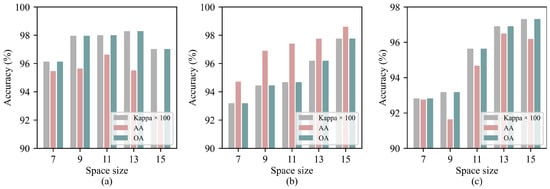
Figure 7.
Experimental results for different spatial sizes on the three datasets: (a) IP. (b) SA. (c) PU.
3.3. Ablation Experiment
To evaluate the impact of the SGA module on crop classification performance, ablation experiments were conducted, as shown in Table 4. From the table, it is evident that the classification accuracy has improved on all three datasets after the introduction of the SGA module. This demonstrates that the module can enhance the semantic relationships of crops in the image, thereby improving the model’s ability to capture the semantic features of each crop. On the IP dataset, the AA accuracy increased by 4.04% after introducing the SGA module, indicating a significant improvement, further validating the effectiveness of the SGA module. In addition, to verify the effectiveness of the MSIE module, it was replaced with a two-layer standard convolution for feature extraction. According to the experimental results, when the MSIE module was replaced with standard convolution, the accuracy significantly decreased on all three datasets, further demonstrating the effectiveness of the MSIE module. Overall, the SGTN model improves classification performance with only a slight increase in training time, effectively balancing the classification accuracy across all categories.
Table 4.
Experimental results of ablation experiments on three datasets. Please note that “√” and “×” represent whether the module is selected and not selected in the model, respectively.
3.4. Classification Results
To validate the effectiveness of the proposed algorithm, six state-of-the-art hyperspectral image classification models were selected for comparison: DFFN [32], HSST [33], SSAN [34], SSFTTnet [24], MASSFormer [35], and MSSTT [36].
- DFFN (Deep Feature Fusion Network): This model optimizes convolutional layers, multilayer feature fusion, and PCA dimensionality reduction through residual learning, effectively enhancing classification accuracy, particularly excelling in small sample scenarios.
- HSST (Hierarchical Spatial–Spectral Transformer): An end-to-end hierarchical spatial–spectral transformer model that effectively extracts spatial–spectral features from hyperspectral data using multi-head self-attention (MHSA), while employing a hierarchical architecture to reduce the number of parameters.
- SSAN (Spectral–Spatial Attention Network): This model combines spectral and spatial modules and introduces an attention mechanism to suppress the influence of noisy pixels, effectively extracting discriminative spectral-spatial features from hyperspectral data.
- SSFTTnet (Spectral–Spatial Feature Tokenization Transformer): This model combines spectral-spatial feature extraction modules with a transformer architecture, utilizing a Gaussian-weighted feature tokenization module to convert shallow features into semantic features.
- MASSFormer (Memory-Augmented Spectral–Spatial Transformer): This model introduces a memory tokenizer (MT) and a memory-augmented transformer encoder (MATE) module to convert spectral–spatial features into memory tokens that store prior knowledge while extending multi-head self-attention (MHSA) operations to achieve more comprehensive information fusion.
- MSSTT (Multi-Scale Super-Token Transformer): This model includes a multi-scale convolution (MSConv) branch and a multi-scale super-token attention (MSSTA) branch to achieve both local and global feature extraction.
All models used the same structural parameters as those in the original papers, and experiments were conducted in the same experimental environment.
3.4.1. Classification Results for the IP Dataset
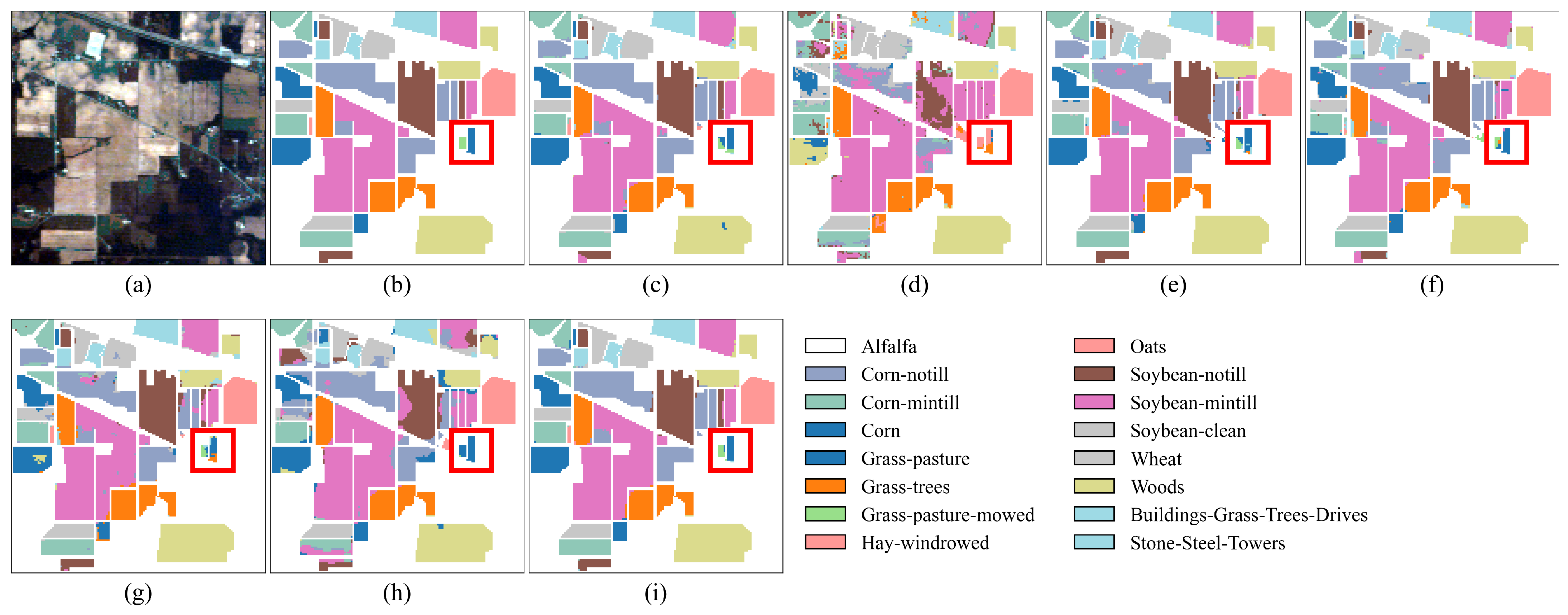
As shown in Table 5, the proposed SGTN achieves the highest classification accuracy among all comparison models, with OA, AA, and Kappa coefficients of 98.24%, 94.64%, and 0.9799, respectively. Specifically, compared to the model with the lowest accuracy, HSST, SGTN improves OA by 25.58%, showing a significant enhancement. Compared to the model with the highest classification accuracy, DFFN, SGTN improves OA, AA, and Kappa coefficients by 1.02%, 2.27%, and 1.16%, respectively, further demonstrating its excellent performance in crop classification. Additionally, from the perspective of AA, SGTN shows an improvement of up to 41.86%, with the smallest increase being 2.27%. This indicates that SGTN can effectively balance the classification accuracy across different crop categories. The primary reason for this performance is the ability of the SGA module to effectively extract semantic information, thereby enhancing the model’s semantic representation. Except for the crops “Alfalfa” and “Grass-pasture-mowed”, SGTN achieves over 90% classification accuracy for all other crop types. Furthermore, as observed in Figure 8, the classification results of SGTN are relatively smooth, and the model is capable of accurately identifying the spatial distribution of crops.
Table 5.
Classification accuracy results of different models on the IP dataset. Please note that bold indicates the highest classification accuracy.
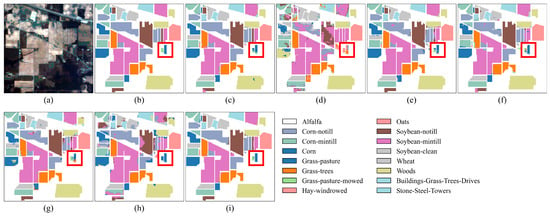
Figure 8.
Classification result maps of different models on the IP dataset. (a) False-color image. (b) Ground truth. (c) DFFN. (d) HSST. (e) SSAN. (f) SSFTTnet. (g) MASSFormer. (h) MSSTT. (i) SGTN.
3.4.2. Classification Results for the SA Dataset
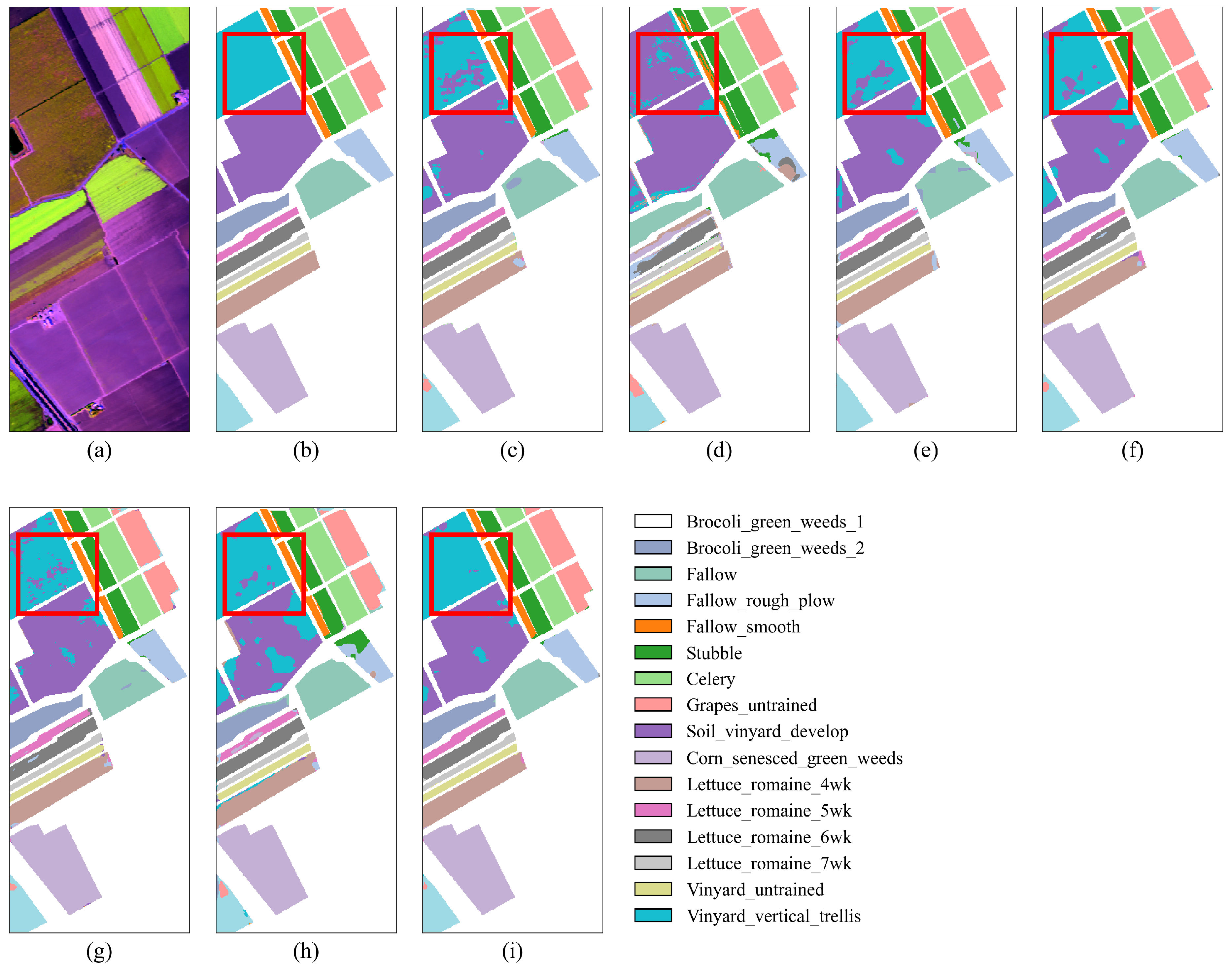
As shown in Figure 9, “Grapes_untrained” and “Vinyard_untrained” exhibit significant salt-and-pepper noise, particularly in the classification results of DFFN and HSST, as seen in Figure 9d,h. This misclassification is primarily due to the similarity in spectral and visual color information between these two grape-related categories, which makes them prone to confusion. In contrast, SGTN exhibits fewer misclassifications, attributed to the SGA module’s semantic guidance, which enhances the model’s semantic outputs. From Table 6, under the condition of only 1% training samples, SGTN achieved the highest classification performance, with OA, AA, and Kappa scores reaching 97.89%, 98.44%, and 0.9765, respectively. Compared to the other models, SGTN achieved improvements in OA, AA, and Kappa by 2.24–22.82%, 1.73–28.64%, and 2.49–25.80%, respectively. Observing the experimental results on the SA dataset, it can be seen that among the comparative models, the HSST model performs the worst, while the SSRN model shows better results. However, the overall classification performance of SSRN still falls short of SGTN.
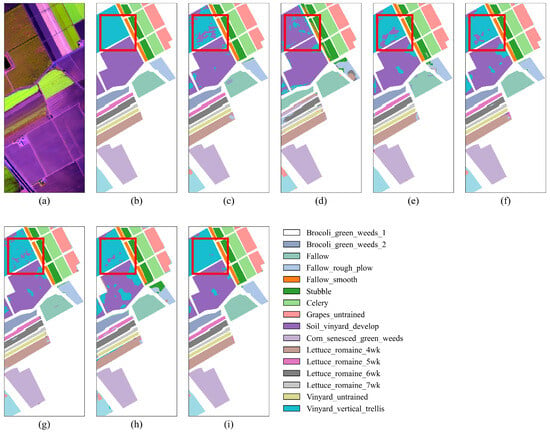
Figure 9.
Classification result maps of different models on the SA dataset. (a) False-color image. (b) Ground truth. (c) DFFN. (d) HSST. (e) SSAN. (f) SSFTTnet. (g) MASSFormer. (h) MSSTT. (i) SGTN.
Table 6.
Classification accuracy results of different models on the SA dataset. Please note that bold indicates the highest classification accuracy.
3.4.3. Classification Results for the PU Dataset
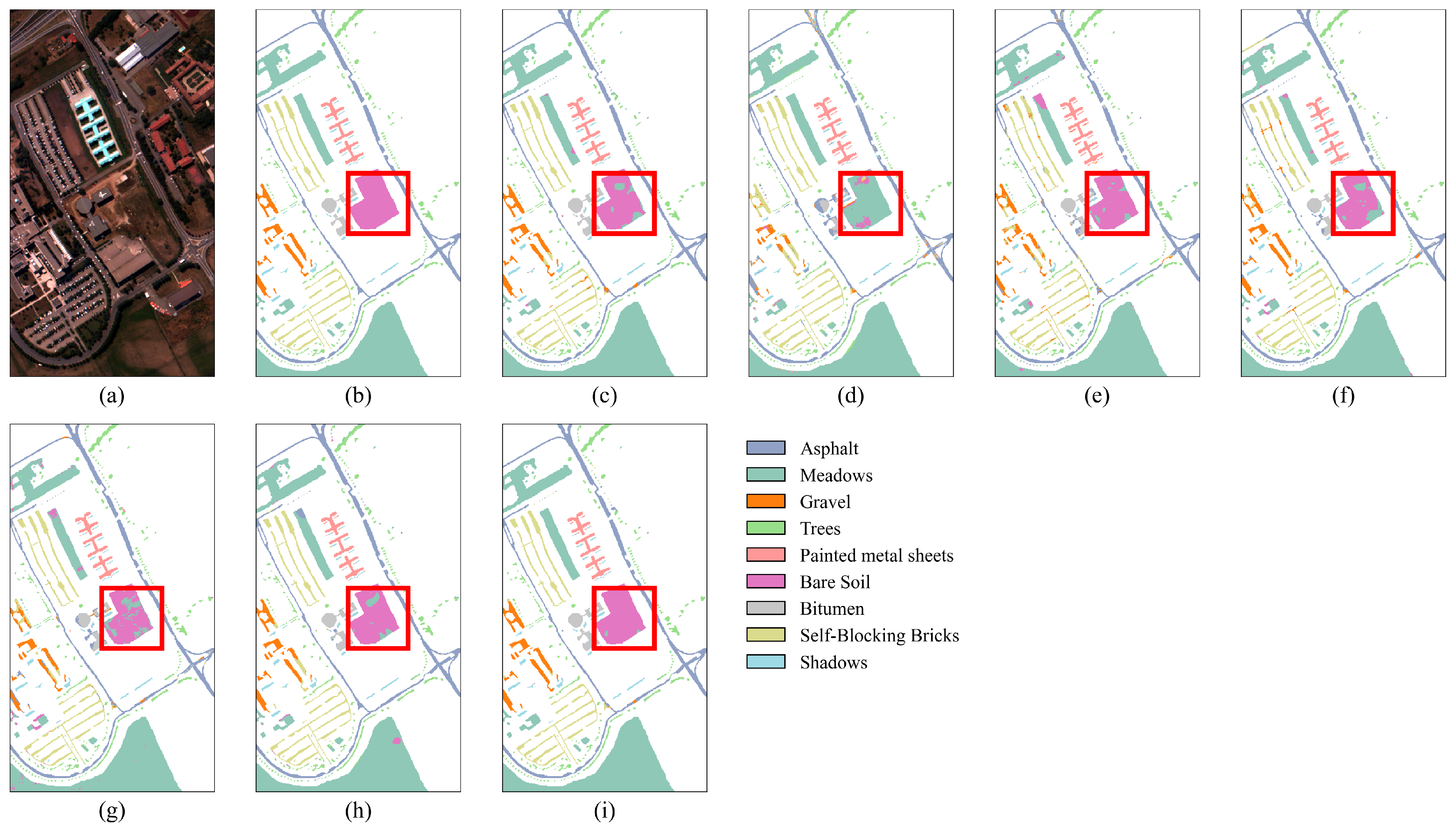
The results in Table 7 show that, with only 1% of the training samples, the proposed SGTN achieves the best classification accuracy, with OA, AA, and Kappa coefficients of 98.34%, 96.82%, and 0.9780, respectively. Additionally, the classification accuracy for all categories, except “Trees” and “Shadows”, exceeds 95%. Furthermore, as observed in Figure 10, for the recognition of “Bare Soil”, SGTN achieves better classification results with fewer misclassifications. Specifically, in Figure 10d, the HSST method performs poorly in recognizing “Bare Soil”. Compared to the other models, the SGTN model shows significant improvements in OA, AA, and Kappa, with accuracy gains ranging from 1.99% to 16.26%, 1.99% to 21.43%, and 2.64% to 22.23%, respectively. Overall, the classification results of the proposed SGTN are closer to the true ground truth of the dataset. These results further demonstrate the advanced generalization ability of SGTN.
Table 7.
Classification accuracy results of different models on the PU dataset. Please note that bold indicates the highest classification accuracy.
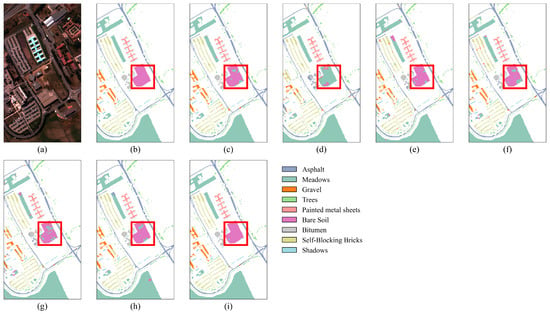
Figure 10.
Classification result maps of different models on the PU dataset. (a) False-color image. (b) Ground truth. (c) DFFN. (d) HSST. (e) SSAN. (f) SSFTTnet. (g) MASSFormer. (h) MSSTT. (i) SGTN.
3.5. Runtime Analysis
To assess the computational efficiency of the model, this section presents an analysis of the parameters and prediction time on three datasets, as shown in Table 8. The results indicate that SSAN has significantly more parameters than other models, while SSFTTnet has the fewest parameters. In terms of prediction time, except for MSSTT and HSST, the prediction time differences across the three datasets for the other methods are not significant, especially for the IP dataset. In contrast, the proposed SGTN model shows moderate performance in both parameters and prediction time, falling within the medium range. The model utilizes a self-attention mechanism to capture the semantic relationships in the image, which increases computational complexity but also leads to a significant improvement in classification accuracy. Overall, SGTN not only achieves the best classification results but also maintains a reasonable level of computational complexity, demonstrating balanced overall performance.
Table 8.
Analysis of parameters and testing time for different models on three datasets.
4. Conclusions
This paper proposes the SGTN model to enhance crop recognition accuracy. The model consists of two feature extraction layers and a classification layer. The feature extraction layers are composed of the MSIE and SGA modules, where the MSIE module extracts multi-scale information about crops, while the SGA module focuses on the semantic information of crops. To validate the effectiveness of the proposed algorithm, extensive experiments were conducted on the IP and SA crop benchmark datasets, with PU used to evaluate the model’s generalization ability. The results demonstrate that, compared to the state-of-the-art classification models, the proposed SGTN model achieves higher classification accuracy and generalization ability, showing the model’s significant potential in crop classification. Although this study achieved good results in crop classification, the quadratic complexity of the self-attention mechanism increased the model inference time. Therefore, future research will focus on improving the structure of the transformer model and utilizing various learning strategies to further enhance crop classification performance while reducing model complexity.
Author Contributions
Conceptualization, W.P. and T.Z.; methodology, W.P.; software, W.P. and R.W.; validation, G.M., Y.W. and J.D.; formal analysis, J.D.; investigation, G.M. and J.D.; data curation, R.W., G.M. and Y.W.; writing—original draft preparation, W.P.; writing—review and editing, T.Z.; visualization, Y.W.; supervision, T.Z.; project administration, T.Z.; funding acquisition, T.Z., R.W. and J.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (31660137 and 52105283) and the Huzhou Science and Technology Commissioner Fund (2023KT31).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets used within this study are available upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, T.; Xuan, C.; Ma, Y.; Tang, Z.; Gao, X. An efficient and precise dynamic neighbor graph network for crop mapping using unmanned aerial vehicle hyperspectral imagery. Comput. Electron. Agric. 2025, 230, 109838. [Google Scholar] [CrossRef]
- Tejasree, G.; Agilandeeswari, L. An extensive review of hyperspectral image classification and prediction: Techniques and challenges. Multimed. Tools Appl. 2024, 83, 80941–81038. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Koukiou, G.; Anastassopoulos, V. Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review. J. Imaging 2024, 10, 15. [Google Scholar] [CrossRef] [PubMed]
- Yadav, P.K.; Burks, T.; Qin, J.; Kim, M.; Frederick, Q.; Dewdney, M.; Ritenour, M. Automated classification of citrus disease on fruits and leaves using convolutional neural network generated features from hyperspectral images and machine learning classifiers. J. Appl. Remote Sens. 2024, 18, 014512. [Google Scholar] [CrossRef]
- Zhuang, H.; Yan, Y.; He, R.; Zeng, Z. Class incremental learning with analytic learning for hyperspectral image classification. J. Frankl. Inst. 2024, 361, 107285. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, H.; Ma, X.; Wang, R.; Sima, H.; Wang, J. Spectral–Spatial Adaptive Weighted Fusion and Residual Dense Network for hyperspectral image classification. Egypt. J. Remote Sens. Space Sci. 2025, 28, 21–33. [Google Scholar] [CrossRef]
- Tao, Z.; Bi, Y.; Du, J.; Zhu, X.; Gao, X. Classification of desert grassland species based on a local-global feature enhancement network and UAV hyperspectral remote sensing. Ecol. Inform. 2022, 72, 101852. [Google Scholar] [CrossRef]
- Zhang, T.; Du, J.; Zhu, X.; Gao, X. Research on Grassland Rodent Infestation Monitoring Methods Based on Dense Residual Networks and Unmanned Aerial Vehicle Remote Sensing. J. Appl. Spectrosc. 2023, 89, 1220–1231. [Google Scholar] [CrossRef]
- Verma, S.; Sharma, N.; Singh, A.; Alharbi, A.; Alosaimi, W.; Alyami, H.; Gupta, D.; Goyal, N. DNNBoT: Deep Neural Network-Based Botnet Detection and Classification. Comput. Mater. Contin. 2022, 71, 1729–1750. [Google Scholar] [CrossRef]
- Merugu, S.; Tiwari, A.; Sharma, S.K. Spatial–Spectral Image Classification with Edge Preserving Method. J. Indian Soc. Remote Sens. 2021, 49, 703–711. [Google Scholar] [CrossRef]
- Arshad, T.; Zhang, J.; Ullah, I. A hybrid convolution transformer for hyperspectral image classification. Eur. J. Remote Sens. 2024, 57, 2330979. [Google Scholar] [CrossRef]
- Tu, C.; Liu, W.; Jiang, W.; Zhao, L.; Yan, T. A Multiscale Dilated Attention Network for Hyperspectral Image Classification. Adv. Space Res. 2024, 74, 5530–5547. [Google Scholar] [CrossRef]
- Zhang, Y.; Liang, J.; Niu, P.; Xu, W. Center-similarity spectral-spatial attention network for hyperspectral image classification. J. Appl. Remote Sens. 2024, 18, 016509. [Google Scholar] [CrossRef]
- Zhang, M.; Duan, Y.; Song, W.; Mei, H.; He, Q. An Effective Hyperspectral Image Classification Network Based on Multi-Head Self-Attention and Spectral-Coordinate Attention. J. Imaging 2023, 9, 141. [Google Scholar] [CrossRef]
- Merugu, S.; Jain, K.; Mittal, A.; Raman, B. Sub-scene Target Detection and Recognition Using Deep Learning Convolution Neural Networks. In ICDSMLA 2019, Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications, Hyderabad, India, 29–30 March 2019; Springer: Singapore, 2021; pp. 1082–1101. [Google Scholar]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Christilda, A.J.; Manoharan, R. Enhanced hyperspectral image segmentation and classification using K-means clustering with connectedness theorem and swarm intelligent-BiLSTM. Comput. Electr. Eng. 2023, 110, 108897. [Google Scholar] [CrossRef]
- Zhang, T.; Bi, Y.; Zhu, X.; Gao, X. Identification and Classification of Small Sample Desert Grassland Vegetation Communities Based on Dynamic Graph Convolution and UAV Hyperspectral Imagery. Sensors 2023, 23, 2856. [Google Scholar] [CrossRef]
- Li, J.; Wu, B.; Fu, W.; Zheng, W.; Lin, F.; Li, M. Robust dense graph structure based on graph convolutional network for hyperspectral image classification. J. Appl. Remote Sens. 2024, 18, 036507. [Google Scholar] [CrossRef]
- Zhang, T.; Du, J. Research on Micro-patch Identification of Desert Grassland Based on UAV Remote Sensing. J. Guangxi Norm. Univ. Nat. Sci. Ed. 2022, 40, 50–58. [Google Scholar] [CrossRef]
- Falaschetti, L.; Manoni, L.; Di Leo, D.; Pau, D.; Tomaselli, V.; Turchetti, C. A CNN-based image detector for plant leaf diseases classification. HardwareX 2022, 12, e00363. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, G.s.; Gao, H.; Ding, Y.; Hong, D.; Zhang, B. Local aggregation and global attention network for hyperspectral image classification with spectral-induced aligned superpixel segmentation. Expert Syst. Appl. 2023, 232, 120828. [Google Scholar] [CrossRef]
- Zhang, T.; Bi, Y.; Hao, F.; Du, J.; Zhu, X.; Gao, X. Transformer attention network and unmanned aerial vehicle hyperspectral remote sensing for grassland rodent pest monitoring research. J. Appl. Remote Sens. 2022, 16, 044525. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Zhang, T.; Bi, Y.; Xuan, C. Convolutional transformer attention network with few-shot learning for grassland degradation monitoring using UAV hyperspectral imagery. Int. J. Remote Sens. 2024, 45, 2109–2135. [Google Scholar] [CrossRef]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. Hyperspectral Image Transformer Classification Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528715. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Z.; Zhao, F.; Liu, H.; Chang, Z. Convolution Transformer Mixer for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6014205. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, H.; Zhang, M.; Zhu, Y. Hyperspectral Image Classification Based on Swin Transformer and 3D Residual Multilayer Fusion Network. Comput. Sci. 2023, 50, 155–160. [Google Scholar] [CrossRef]
- Zhao, F.; Geng, M.; Liu, H.; Zhang, J.; Yu, J. Convolutional Neural Network and Vision Transformer-driven Cross-layer Multi-scale Fusion Network for Hyperspectral Image Classification. J. Electron. Inf. Technol. 2024, 46, 2237–2248. [Google Scholar] [CrossRef]
- Li, S.; Liang, L.; Zhang, S.; Zhang, Y.; Plaza, A.; Wang, X. End-to-End Convolutional Network and Spectral-Spatial Transformer Architecture for Hyperspectral Image Classification. Remote Sens. 2024, 16, 325. [Google Scholar] [CrossRef]
- Atik, S.O. Dual-stream spectral-spatial convolutional neural network for hyperspectral image classification and optimal band selection. Adv. Space Res. 2024, 74, 2025–2041. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Song, C.; Mei, S.; Ma, M.; Xu, F.; Zhang, Y.; Du, Q. Hyperspectral Image Classification Using Hierarchical Spatial-Spectral Transformer. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3584–3587. [Google Scholar]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, H.; Zheng, Y.; Wu, Z.; Ye, Z.; Zhao, H. MASSFormer: Memory-Augmented Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5516415. [Google Scholar] [CrossRef]
- Meng, Z.; Zhang, T.; Zhao, F.; Chen, G.; Liang, M. Multiscale Super Token Transformer for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5508105. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).