
Concealed Weapon Detection Using Thermal Cameras




Abstract
1. Introduction
2. Previous Work
3. Materials and Methods
3.1. Datasets
3.2. Proposed Method
- Preprocessing. To initiate the process, a frame from the thermal camera feed is first extracted. We tested our method in two configurations: one using the described datasets and another by integrating it into an Android app. For the datasets, images were converted to grayscale. Aside from this conversion, no additional preprocessing, such as contrast adjustment, was applied. For the Android app implementation, the camera outputs grayscale images directly, making further preprocessing unnecessary. Taking heed of the conversion of the images of the datasets to grayscale (the only preprocessing operation carried out), this was only needed in the case of the “UCLM Thermal Imaging Dataset”, as the “Concealed Pistol Detection Dataset” images were already in grayscale. The conversion was performed in Python in its 3.10 version [20] with the OpenCV library [21]. After loading the original images, which had a hot colormap applied [22] to them, we used the cv2.COLOR_BGR2GRAY option to convert them into grayscale. COLOR_BGR2GRAY color mode applies the Equation (1) to convert from any three-channel image to a one-channel image. See Figure 5 as an example of the conversion operation of a frame from the “UCLM Thermal Imaging Dataset”.
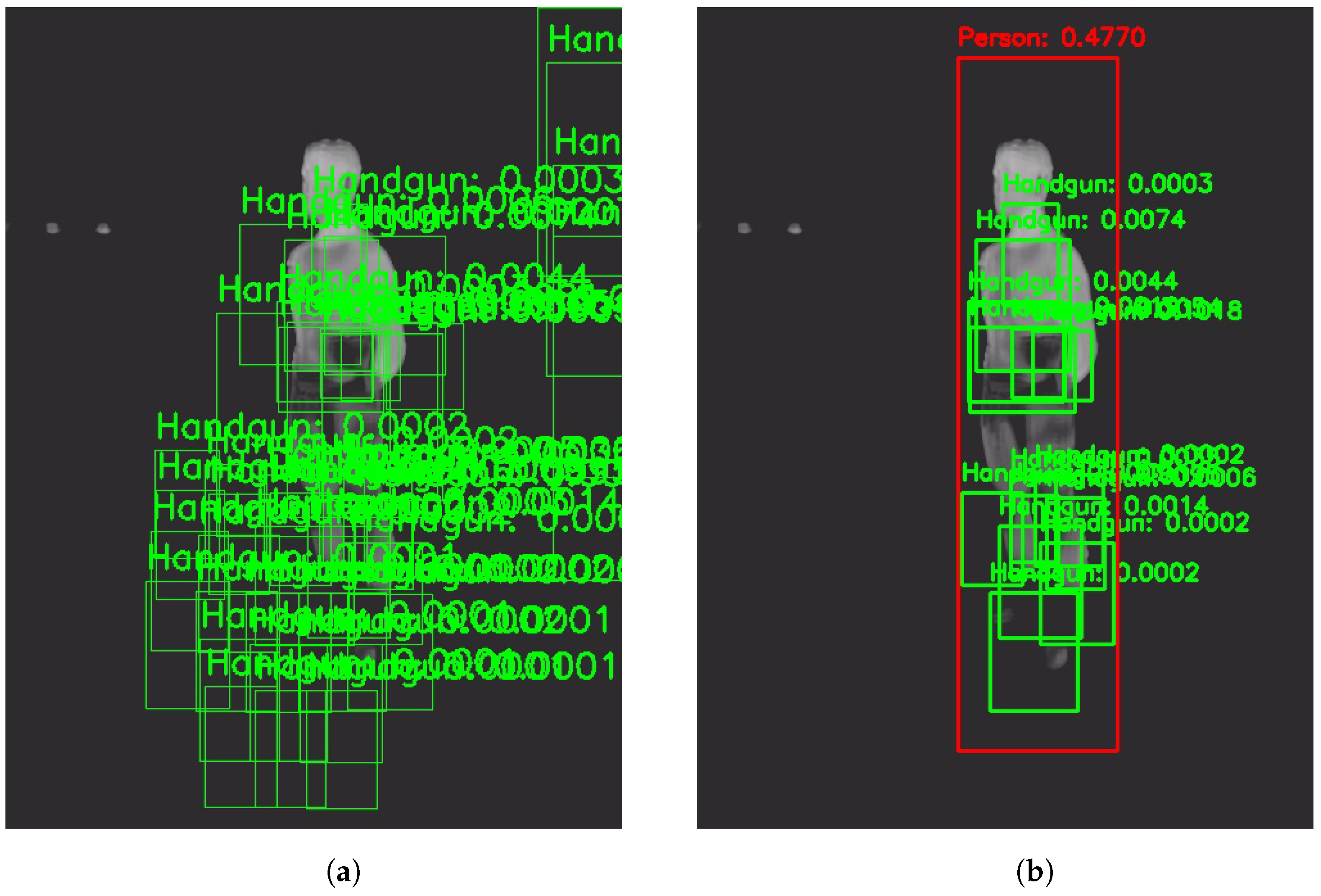
- Handgun detection. Once the image is obtained, we perform frame-level handgun detection using a trained object detection model. This step confirms the presence of a concealed handgun within the frame. If a handgun is detected, the bounding box coordinates of each detected concealed handgun are recorded for further analysis. If no handgun is detected, the current frame is discarded, and the next frame is processed.
- The chosen architecture to perform this task was a YOLOv3 [15], more specifically the YOLOv3u version (YOLOv3u architecture in Figure 6), which is an updated version of YOLOv3-Ultralytics that incorporates the anchor-free, objectness-free split head used in YOLOv8 [23] models (YOLOv8 version x architecture in Figure 7). YOLOv3u maintains the same backbone (Darknet53 [24]) and neck architecture as YOLOv3 but with the updated detection head from YOLOv8.
- Person detection. Upon confirming the presence of a concealed handgun within the frame, the person detection process is initiated. The person detection model identifies individuals within the image and selects the bounding box the model is most confident in (considering only one person for simplicity). Using the coordinates of the detected handgun(s) from the prior step, the system checks whether the detected handgun is located within the bounding box of the identified person. To ensure a more reliable assessment and reduce the risk of false positives, the sides of the person’s bounding box are initially expanded by 15%, allowing a margin for detection. Following this adjustment, a straightforward comparison is made between the coordinates to verify whether a handgun lies within the person’s bounding box. However, in the absence of any detected persons, the firearm with the highest confidence score (reflecting the model’s highest level of certainty) shall still be considered valid, provided that the handgun detector has identified at least one firearm.
- In this case, we used a pretrained YOLOv8, specifically the YOLOv8x version, which is the best Ultralytics version; it is also the one that requires the most capacity but works better than the others. The model was pretrained to detect 80 classes, but only the “Person” class was considered to carry out the experiments.
- Alarm. Finally, if at least one handgun detection meets the criteria (either located within the expanded bounds of a person’s bounding box or detected independently of a person), the system triggers an alarm.
3.3. Setup
- Experimental setup. Training and testing were performed on an Xeon(R) CPU E5-2620 (produced by Intel) computer with a NVIDIA Quadro P4000 GPU (produced by NVIDIA). We chose to use the TOPDON TC001 thermal camera [17], which was selected due to its small size and reduced cost. The camera was directly connected to a HUAWEI P30 Lite Android smartphone (produced by HUAWEI) and videos for the “UCLM Thermal Imaging Dataset” were collected (later, images were extracted from these) using the TC001’s official Android app. Later, the same thermal camera and the same smartphone were used in order to test the Android app.
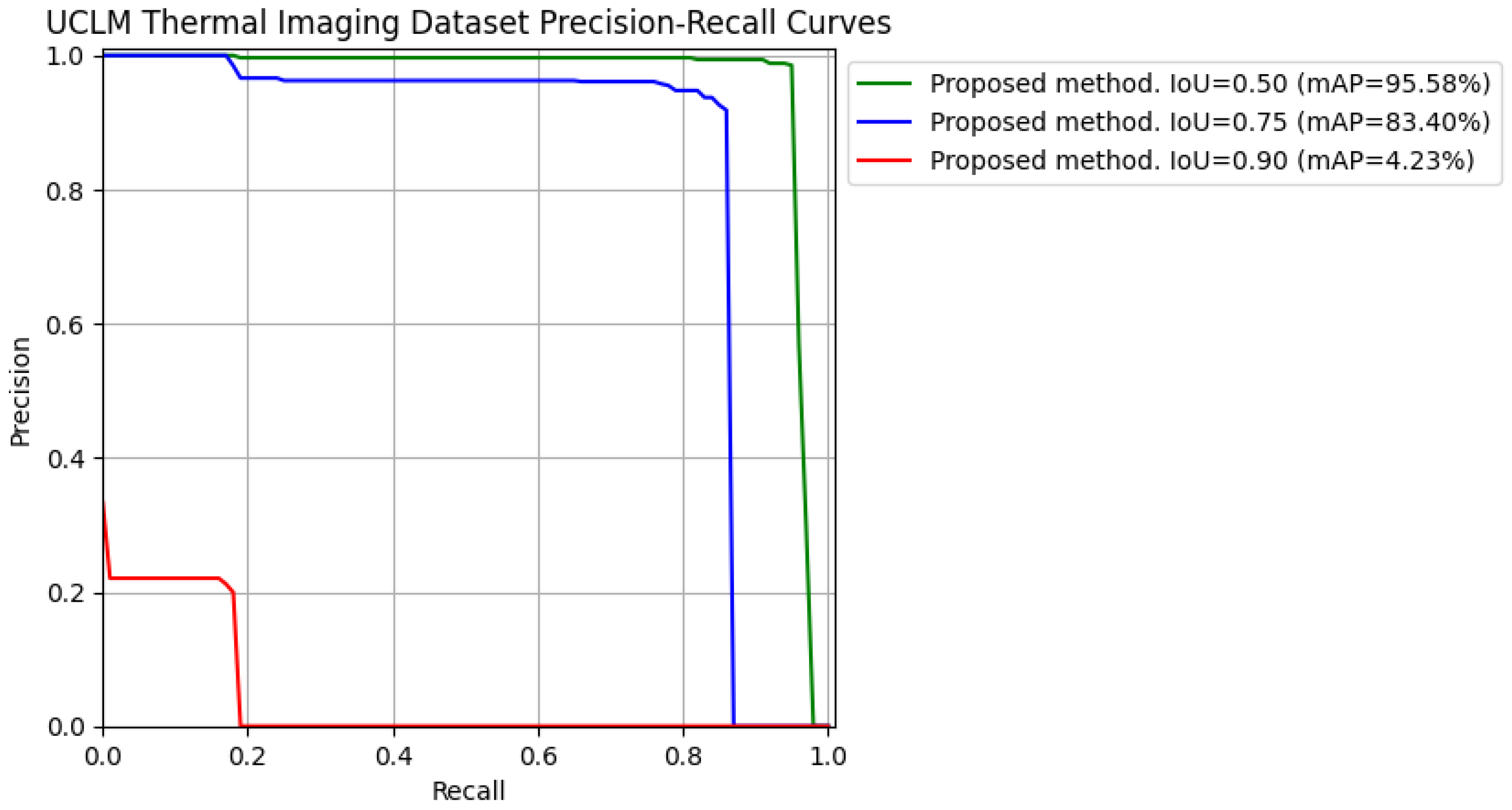
- Metrics. To evaluate the methods, considering that they are primarily detectors, the mean Average Precision (mAP) [27] has been extracted, which is a widely used metric to evaluate the performance of object detection models, such as YOLO or Faster R-CNN. To fully understand mAP, we need to break down the fundamental concepts it builds upon [28]: true positives (TPs), false positives (FPs), false negatives (FNs), true negatives (TNs), precision, recall, Intersection over Union (IoU), and finally, Average Precision (AP) and mAP. In object detection, predictions are evaluated based on their alignment with ground truth (information that is known to be real or true) objects. This is done using the following definitions:
- True Positive (TP). A detection is considered a true positive when the predicted bounding box correctly identifies an object and sufficiently overlaps with the ground truth bounding box. Before explaining the next concepts, it is key to understand what “overlapping” means in this context, and that is the Intersection over Union (IoU). In the object detection scope, the IoU measures the overlapping area between the predicted bounding box B_p and the ground truth bounding box B_gt divided by the area of union between them (see Equation (2)). By comparing the IoU with a given threshold t, we can classify a detection as being correct or incorrect. If then the detection is considered as correct. If the detection is considered as incorrect. For a better understanding, the IoU concept is graphically described in Figure 9.
- False Positive (FP). A detection is considered a false positive when the model predicts a bounding box that does not correspond to any actual object, or when the bounding box overlaps insufficiently with a ground truth box.
- False Negative (FN). A false negative occurs when the model fails to detect an object that is present in the image.
- True Negative (TN). This term is less relevant in object detection as it refers to correctly identifying the absence of objects, which is not explicitly evaluated.
- Detection Task. Once the datasets, the proposed method, the experimental setup, and the evaluation metrics are defined, the question arises regarding the objective to be achieved. On one hand, the proposed method has been developed with the aim of minimizing false positives, as weapons are encapsulated within the person. On the other hand, the primary and most critical objective is to ensure that no detection is missed, as detecting hidden weapons is of utmost importance. Therefore, a balance is sought between avoiding missed detections while filtering out unnecessary ones. For this reason, in cases where no person is detected, the method triggers an alarm regardless, provided a weapon has been detected at the frame level.
- Training Process. Once the architectures and the metrics used have been explained, before the testing process they had to be trained. The chosen YOLOv8x to perform the person detection task was pretrained, so only the YOLOv3u needed to be trained. It is important to note that, when training a YOLO model, it internally resizes image data to a range by dividing each pixel value by 255 to work more efficiently. Moreover, a default data augmentation is performed during the YOLO training, which helps the architecture in detecting better in difficult situations. This default data augmentation consists of the following: color augmentations involve random adjustments to hue (), saturation (up to ), and brightness (up to ); geometric transformations include random translation (), scaling (up to ), and horizontal flipping with a probability; mosaic augmentation, a key feature in YOLO models that combines four images into one, is enabled; random erasing with a probability is applied to improve robustness, and auto-augment with the RandAugment policy introduces further random transformations; and the crop fraction is set to , ensuring no cropping is applied.
4. Results
4.1. Complete Method Results
4.2. Ablation Experiment
4.3. Classification Metrics
4.4. Comparison with State-of-the-Art Method
4.5. Demo
5. Discussion
5.1. Strengths of the Proposed Method
5.2. Weaknesses of the Proposed Method
5.3. Future Improvements and Conclusions
- Expanding the dataset with more diverse scenarios, including variations in clothing, lighting, and environments, can improve generalization and adaptability. This would help the model better handle challenging and unseen situations, ensuring robustness across diverse settings.
- Incorporating multi-person detection capabilities will increase the system’s applicability in crowded spaces, enabling it to process more complex scenarios involving multiple individuals. Such an enhancement could make the method more practical for environments like airports, train stations, and large public gatherings.
- Improving the algorithm’s computational efficiency can significantly enhance its FPS, supporting faster real-time processing. This optimization would enable smoother operation in high-traffic areas where rapid decision-making is crucial.
- To address limitations in detecting objects under thick clothing, advanced thermal imaging techniques, such as multi-spectral imaging, can be integrated. These techniques can enhance detection performance by leveraging additional spectral data, making the system more reliable under challenging conditions.
- Adaptive thresholding, which dynamically adjusts detection parameters based on environmental conditions, can further balance precision and recall. This approach could ensure optimal performance even in varying lighting and thermal environments.
- Expanding the detection scope to include other concealed weapons or objects, such as knives and explosives, will enhance the system’s versatility and broaden its range of applications. This improvement would increase its utility in various security scenarios beyond handgun detection.
- Improving embedded system performance through hardware upgrades or algorithm optimizations can enhance usability, particularly for real-time applications. Faster hardware and more efficient algorithms would make the method more responsive and scalable.
- Finally, enhancing the Android app’s user interface by adding features such as cloud storage, remote monitoring, and integration with security networks can increase operational effectiveness. These upgrades would provide a more seamless experience for security personnel, enabling better data management and situational awareness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wikipedia Contributors. Columbine High School Massacre—Wikipedia, The Free Encyclopedia. 2025. Available online: https://en.wikipedia.org/w/index.php?title=Columbine_High_School_massacre&oldid=1272859494 (accessed on 30 January 2025).
- Blank, R. Radiation from Airport Security Scanners: Know Your Rights—SYB. Available online: https://www.shieldyourbody.com/radiation-airport-security-scanners/ (accessed on 13 December 2024).
- Jasim Hussein, N.; Hu, F.; He, F. Multisensor of thermal and visual images to detect concealed weapon using harmony search image fusion approach. Pattern Recognit. Lett. 2017, 94, 219–227. [Google Scholar] [CrossRef]
- Kastek, M.; Dulski, R.; Trzaskawka, P.; Bieszczad, G. Sniper detection using infrared camera: Technical possibilities and limitations. In Proceedings of the Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security and Homeland Defense IX; Carapezza, E.M., Ed.; International Society for Optics and Photonics; SPIE: Orlando, FL, USA, 2010; Volume 7666, p. 76662E. [Google Scholar] [CrossRef]
- Jedrasiak, K.; Nawrat, A.; Daniec, K.; Koteras, R.; Mikulski, M.; Grzejszczak, T. A Prototype Device for Concealed Weapon Detection Using IR and CMOS Cameras Fast Image Fusion. In Proceedings of the Computer Vision and Graphics; Bolc, L., Tadeusiewicz, R., Chmielewski, L.J., Wojciechowski, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 423–432. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support vector machines: Theory and applications. In Advanced Course on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 1999; pp. 249–257. [Google Scholar] [CrossRef]
- Raturi, G.; Rani, P.; Madan, S.; Dosanjh, S. ADoCW: An Automated method for Detection of Concealed Weapon. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 181–186. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Hema, R.; Subramanian, G. Infrared-Imaging Enabled Drone for the Detection of Infiltrators and Concealed Weapons. In Proceedings of the 2022 Interdisciplinary Research in Technology and Management (IRTM), Kolkata, India, 24–26 February 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Veranyurt, O.; Sakar, C.O. Concealed pistol detection from thermal images with deep neural networks. Multimed. Tools Appl. 2023, 82, 44259–44275. [Google Scholar] [CrossRef]
- Veranyurt, O.; Şakar, C.O. Concealed Pistol Detection Dataset Figshare. 2022. Available online: https://doi.org/10.6084/m9.figshare.20105600.v1 (accessed on 20 September 2024).
- Palmero, C.; Clapés, A.; Holmberg Bahnsen, C.; Møgelmose, A.; Moeslund, T.; Escalera, S. Multi-modal RGB–Depth–Thermal Human Body Segmentation. Int. J. Comput. Vis. 2016, 118, 217–239. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J.; Felsberg, M. A Thermal Object Tracking Benchmark. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar] [CrossRef]
- Muñoz, J.D.; Ruiz-Santaquiteria, J.; Deniz, O. Thermal Image Dataset for Concealed Handgun Detection. Mendeley Data. 2024. Available online: https://doi.org/10.17632/B6RPGR6NRH.1 (accessed on 17 October 2024).
- TOPDON. TOPDON Thermal Infrared Camera TC001. Available online: https://www.topdon.com/products/tc001 (accessed on 7 October 2024).
- Manovich, N. CVAT: Open Data Annotation Platform. Available online: https://www.cvat.ai/ (accessed on 13 December 2024).
- The MathWorks, Inc. Image Labeler. Available online: https://es.mathworks.com/help/vision/ref/imagelabeler-app.html (accessed on 13 December 2024).
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Bradski, G. The OpenCV library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Sibrel, S.C.; Rathore, R.; Lessard, L.; Schloss, K.B. The relation between color and spatial structure for interpreting colormap data visualizations. J. Vis. 2020, 20, 7. [Google Scholar] [CrossRef] [PubMed]
- Yaseen, M. What is YOLOv8: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector. arXiv 2024, arXiv:2408.15857. [Google Scholar] [CrossRef]
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck Target Recognition in Side-Scan Sonar Images by Improved YOLOv3 Model Based on Transfer Learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar] [CrossRef]
- Gansner, E.R.; North, S.C. An open graph visualization system and its applications to software engineering. Softw. Pract. Exp. 2000, 30, 1203–1233. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Schiele, B. Learning non-maximum suppression. arXiv 2017, arXiv:1705.02950. [Google Scholar] [CrossRef]
- Tan, R.J. Mean Average Precision (mAP) Explained. Available online: https://builtin.com/articles/mean-average-precision (accessed on 1 October 2024).
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Dataset | # Images | Classes | Train/Val/Test Images |
|---|---|---|---|---|
| YOLOv3u | UCLM Thermal Imaging Dataset | 2402 | “Handgun” | 1441/239/722 |
| Concealed Pistol Detection Dataset | 358 | “Handgun” | 214/35/109 |
| Dataset | Detections | Average Precision (IoU = 0.50:0.95, Area = All) | Standard Deviation |
|---|---|---|---|
| UCLM Thermal Imaging Dataset [16] | All | 64.52% | 0.0603 |
| Best score | 64.30% | 0.0606 | |
| Concealed Pistol Detection Dataset [11] | All | 27.78% | 0.0781 |
| Best score | 27.70% | 0.0843 |
| Dataset | Detections | Average Precision (IoU = 0.50:0.95, Area = All) | Standard Deviation |
|---|---|---|---|
| UCLM Thermal Imaging Dataset [16] | All | 64.38% | 0.0596 |
| Best score | 64.20% | 0.0601 | |
| Concealed Pistol Detection Dataset [11] | All | 27.57% | 0.0761 |
| Best score | 27.62% | 0.0838 |
| Classification Metrics: UCLM Thermal Imaging Dataset | ||||
|---|---|---|---|---|
| Confidence Value | 0.0001 | 0.1 | 0.5 | 0.75 |
| True Positives (TP) | 353 | 346 | 339 | 269 |
| False Positives (FP) | 252 | 42 | 15 | 4 |
| True Negatives (TN) | 117 | 327 | 354 | 365 |
| False Negatives (FN) | 0 | 7 | 14 | 84 |
| Accuracy (%) | 65.10 | 93.21 | 95.98 | 87.81 |
| Precision (%) | 58.35 | 89.18 | 95.76 | 98.53 |
| Recall (%) | 100.00 | 98.02 | 96.03 | 76.20 |
| F1-score | 0.74 | 0.93 | 0.96 | 0.86 |
| Classification Metrics: Concealed Pistol Detection Dataset | ||||
|---|---|---|---|---|
| Confidence Value | 0.0001 | 0.1 | 0.5 | 0.75 |
| True Positives (TP) | 52 | 45 | 7 | 0 |
| False Positives (FP) | 35 | 2 | 0 | 0 |
| True Negatives (TN) | 22 | 55 | 57 | 57 |
| False Negatives (FN) | 0 | 7 | 45 | 52 |
| Accuracy (%) | 67.89 | 91.74 | 58.72 | 52.29 |
| Precision (%) | 59.77 | 95.74 | 100.00 | 0 |
| Recall (%) | 100.00 | 86.57 | 13.46 | 0 |
| F1-score | 0.75 | 0.91 | 0.24 | 0 |
| Method | Dataset | Detections | Average Precision (IoU = 0.50:0.95, Area = All) | Standard Deviation |
|---|---|---|---|---|
| Proposed Method | UCLM Thermal Imaging Dataset | All | 64.52% | 0.0603 |
| Best score | 64.30% | 0.0606 | ||
| Concealed Pistol Detection Dataset | All | 27.78% | 0.0781 | |
| Best score | 27.70% | 0.0843 | ||
| Veranyurt et al. [10] | UCLM Thermal Imaging Dataset | All | 64.32% | 0.0604 |
| Best score | 64.10% | 0.0601 | ||
| Concealed Pistol Detection Dataset | All | 27.18% | 0.0737 | |
| Best score | 27.32% | 0.0806 |
| Classification Metrics: UCLM Thermal Imaging Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Confidence Value | 0.0001 | 0.1 | 0.5 | 0.75 | ||||
| Method | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed |
| True Positives (TP) | 353 | 353 | 346 | 346 | 333 | 339 | 254 | 269 |
| False Positives (FP) | 343 | 252 | 6 | 42 | 0 | 15 | 0 | 4 |
| True Negatives (TN) | 26 | 117 | 363 | 327 | 369 | 354 | 369 | 365 |
| False Negatives (FN) | 0 | 0 | 7 | 7 | 20 | 14 | 99 | 84 |
| Accuracy (%) | 52.49 | 65.10 | 98.20 | 93.21 | 97.23 | 95.98 | 86.29 | 87.81 |
| Precision (%) | 50.72 | 58.35 | 98.30 | 89.18 | 100.00 | 95.76 | 100.00 | 98.53 |
| Recall (%) | 100.00 | 100.00 | 98.02 | 98.02 | 94.33 | 96.03 | 71.85 | 76.20 |
| F1-score | 0.67 | 0.74 | 0.98 | 0.93 | 0.97 | 0.96 | 0.84 | 0.86 |
| Classification Metrics: Concealed Pistol Detection Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Confidence Value | 0.0001 | 0.1 | 0.5 | 0.75 | ||||
| Method | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed | Veranyurt et al. [10] | Proposed |
| True Positives (TP) | 52 | 52 | 45 | 45 | 7 | 7 | 0 | 0 |
| False Positives (FP) | 57 | 35 | 2 | 2 | 0 | 0 | 0 | 0 |
| True Negatives (TN) | 0 | 22 | 55 | 55 | 57 | 57 | 57 | 57 |
| False Negatives (FN) | 0 | 0 | 7 | 7 | 45 | 45 | 52 | 52 |
| Accuracy (%) | 47.71 | 67.89 | 91.74 | 91.74 | 58.72 | 58.72 | 52.29 | 52.29 |
| Precision (%) | 47.71 | 59.77 | 95.74 | 95.74 | 100.00 | 100.00 | 0 | 0 |
| Recall (%) | 100.00 | 100.00 | 86.57 | 86.57 | 13.46 | 13.46 | 0 | 0 |
| F1-score | 0.65 | 0.75 | 0.91 | 0.91 | 0.24 | 0.24 | 0 | 0 |
| Architecture | Dataset | # Images | Classes | Train/Val/Test Images | Epoch | Input Size | Optimizer | Learning Rate |
|---|---|---|---|---|---|---|---|---|
| YOLOv8n | Ours (UCLM Thermal Imaging Dataset) | 12,006 | “Handgun”, “Person” | 10,805/1201/0 | 5 | 640 × 640 | AdamW (0.9 momentum) | 0.001667 (initial) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muñoz, J.D.; Ruiz-Santaquiteria, J.; Deniz, O.; Bueno, G. Concealed Weapon Detection Using Thermal Cameras. J. Imaging 2025, 11, 72. https://doi.org/10.3390/jimaging11030072
Muñoz JD, Ruiz-Santaquiteria J, Deniz O, Bueno G. Concealed Weapon Detection Using Thermal Cameras. Journal of Imaging. 2025; 11(3):72. https://doi.org/10.3390/jimaging11030072
Chicago/Turabian StyleMuñoz, Juan D., Jesus Ruiz-Santaquiteria, Oscar Deniz, and Gloria Bueno. 2025. "Concealed Weapon Detection Using Thermal Cameras" Journal of Imaging 11, no. 3: 72. https://doi.org/10.3390/jimaging11030072
APA StyleMuñoz, J. D., Ruiz-Santaquiteria, J., Deniz, O., & Bueno, G. (2025). Concealed Weapon Detection Using Thermal Cameras. Journal of Imaging, 11(3), 72. https://doi.org/10.3390/jimaging11030072