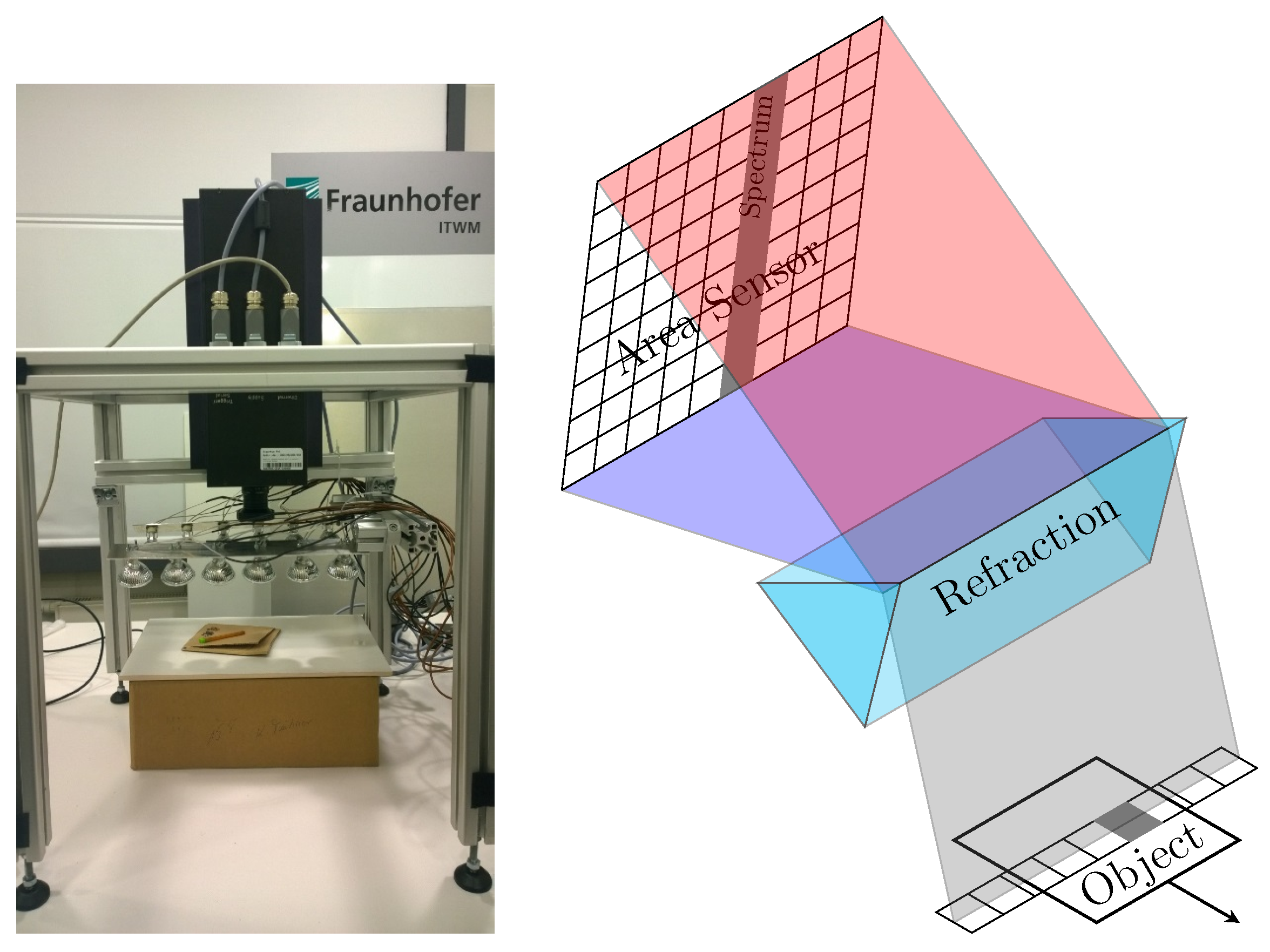
4.1. Hyperspectral Line Camera
A standard approach in hyperspectral image acquisition is to measure lines of the image one by one simultaneously at all wavelengths. In Earth observation, this is referred to as push-broom scanning. The method is also used in industrial applications, such as plastics sorting for recycling purposes. A typical camera is shown in
Figure 1 (left).
At any time, one line of the image is measured at all wavelengths simultaneously. The incoming light from the current line is diffracted by an optical grid onto the area sensor of the camera (see
Figure 1 (right)) and recorded as one “sensor frame”. The full 2D object is measured by moving the object relative to the camera. While the lines add up to the full 2D object, the sensor frames with spectral and along-the-line directions are stacked along the second image direction to form the full 3D hypercube.
The snapshot of the area sensor taken for the line
of the object yields a section
of the hypercube
as depicted in
Figure 2 (right), where the
z-axis is the spectral direction.
Figure 1.
Hyperspectral line camera (left) and principle of measuring a line simultaneously at all wavelengths (right).
Figure 1.
Hyperspectral line camera (left) and principle of measuring a line simultaneously at all wavelengths (right).
Figure 2.
Measured object region (left) and sensor frames of the hypercube measured each in one sensor snapshot (right); they correspond to one line of the object.
Figure 2.
Measured object region (left) and sensor frames of the hypercube measured each in one sensor snapshot (right); they correspond to one line of the object.
The manufacturing process of the sensor commonly produces some defect pixels. For push-broom scanning, each sensor frame has the same pattern of missing pixels. One missing pixel thus creates a missing line, and a cluster of missing pixels creates a cylinder of missing entries in the hypercube.
4.2. Numerical Results for Real Data
In this section, we present results for a hyperspectral image measured at the Fraunhofer Institute for Industrial Mathematics ITWM with the line camera shown in
Figure 1, comparing the restoration obtained as a by-product of our unmixing to a traditional inpainting.
We have measured the marked region in
Figure 2 (left), in the wavelength range 1073–2300 nm, at a spectral resolution of
channels. The four regions contain plastic mixtures with different spectral signatures, and the assembly has been covered with a plastic foil.
Figure 3c shows the mask of working pixels with a few circular regions of corruption artificially added, marked in violet as “simulated defects”. The small circle marked in red is a real defect, and a camera with such a defect is sold at a considerably reduced price.
Figure 3.
(a,b) Two sensor frames with the spectral direction along the z-axis and (c) the mask of working sensor pixels.
Figure 3.
(a,b) Two sensor frames with the spectral direction along the z-axis and (c) the mask of working sensor pixels.
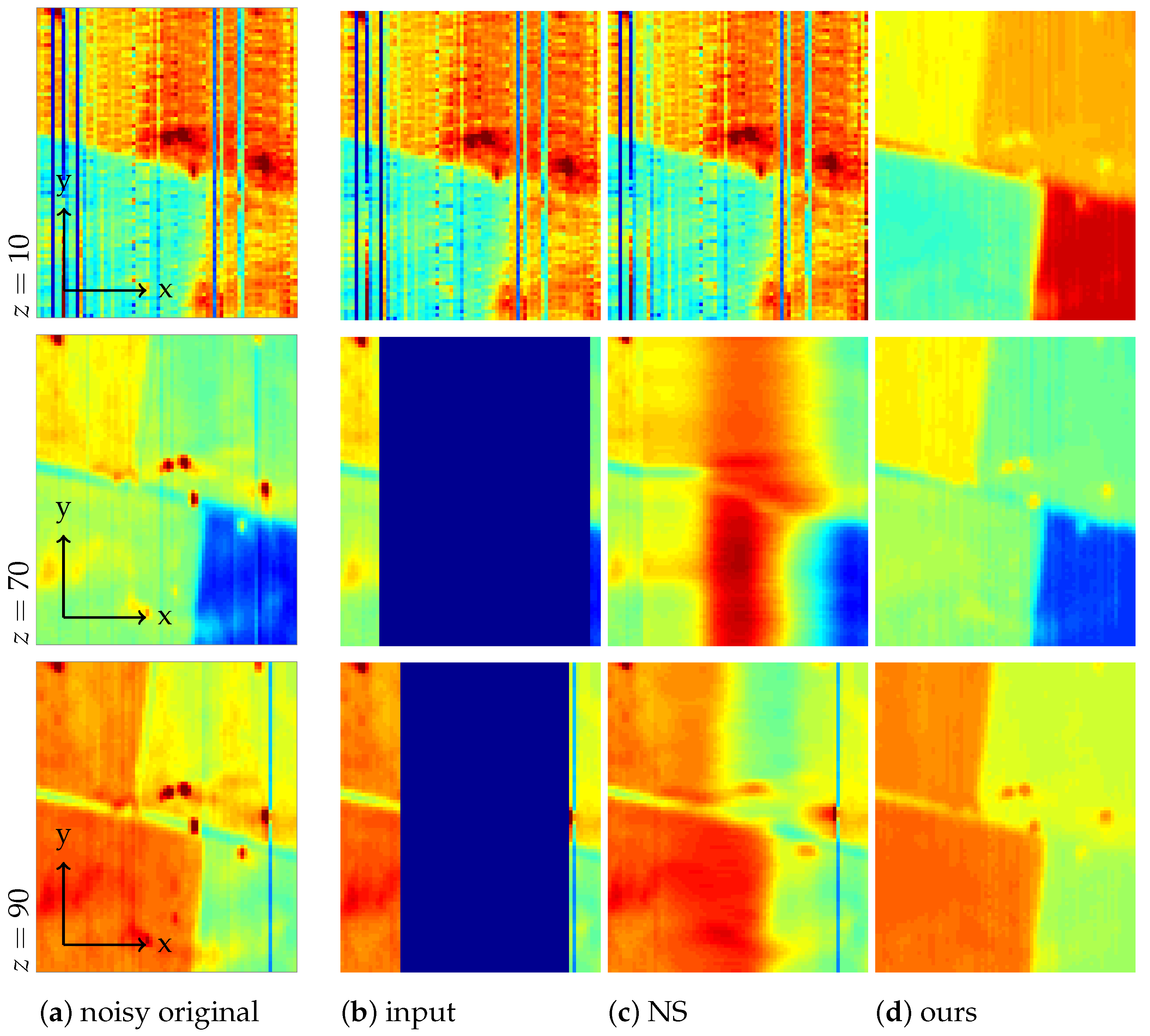
Figure 4.
Sensor frames of masked noisy original input and after inpainting by Navier–Stokes (NS) and our Model (
6), respectively; (
a–
c): sensor frame
, and (
d–
f):
.
Figure 4.
Sensor frames of masked noisy original input and after inpainting by Navier–Stokes (NS) and our Model (
6), respectively; (
a–
c): sensor frame
, and (
d–
f):
.
Figure 3a,b shows two sensor frames
of the measured hypercube. Being snapshots of the area sensor, they have the same pattern of missing pixels.
Figure 4a,d shows the same sections with the artificially added circular defects.
Slices
,
of the hypercube corresponding to a particular wavelength are called channels.
Figure 5a shows Channels
. Here, Channel 10 is noisy and affected by individual broken sensor pixels, each creating one missing line.
Figure 5b shows the same channels, after the artificial defects have been added,
i.e., masked, and while Channel 10 stays unchanged, we see that not much remains of Channels 70 and 90.
For the unmixing, we give to Algorithm 1 the hypercube together with the mask and the four pure spectra present in the scene,
i.e.,
, as columns of
K. These have been obtained from averaging spectra over manually selected rectangles and are shown in
Figure 6a.
Figure 5.
Channels of: (a) the noisy original hypercube; (b) the masked original known to the algorithm; (c) the restoration by Navier–Stokes; and (d) the restoration by our method.
Figure 5.
Channels of: (a) the noisy original hypercube; (b) the masked original known to the algorithm; (c) the restoration by Navier–Stokes; and (d) the restoration by our method.
For the comparison, we take the following approach: Starting from the unmixing coefficients
X obtained by minimizing Equation (
6) with Algorithm 1, we form the product
, which is an approximating restoration of the data matrix
Y. After reshaping, we compare this restoration to an inpainting of the hypercube
Ycube by [
20].
We have chosen the Navier–Stokes-based inpainting [
20] as representative of neighborhood-based inpainting methods. The Navier–Stokes inpainting is performed in each
x-
z-plane of the hypercube and estimates missing data looking at surrounding pixels in that plane. In contrast to the proposed method, such neighborhood-based inpainting of the data cube lacks the capacity of utilizing the provided information about pure spectra. Runtime is several minutes.
Figure 6.
(
a) The four endmember spectra (
) corresponding to each of the plastics blends in
Figure 2 (left); (
b) the eight endmember spectra (
) used in
Section 4.5.
Figure 6.
(
a) The four endmember spectra (
) corresponding to each of the plastics blends in
Figure 2 (left); (
b) the eight endmember spectra (
) used in
Section 4.5.
For Algorithm 1, we used the parameters from Remark 2 and . The relative primal step fell below after 111 iterations, which took s on an Intel Core i7 with GHz. The graphics shown are after 1000 iterations.
In
Figure 4 and
Figure 5, we compare the performance of Algorithm 1 to a Navier–Stokes inpainting of each
x-
z-plane of the hypercube.
For larger clusters of defect pixels, the inpainting of the hypercube by Navier–Stokes is not satisfactory: looking at
Figure 4, the large masked region could still be guessed from the images inpainted with Navier–Stokes. On the other hand, the inpainted sensor images obtained from our method in
Figure 4c,f agree well with the measured sensor frames in
Figure 3a,b, also removing some noise, which was not contained in the mask.
In
Figure 5, we see that the broader missing stripes in Channels 70 and 90 cannot be restored by Navier–Stokes inpainting and, hence, would introduce errors to any following unmixing step, whereas our joint unmixing remains unaffected and gives a satisfactory (denoised) restoration of the original, because the information from all intact channels is being used.
4.3. Numerical Results for Artificial Data (Pure Regions)
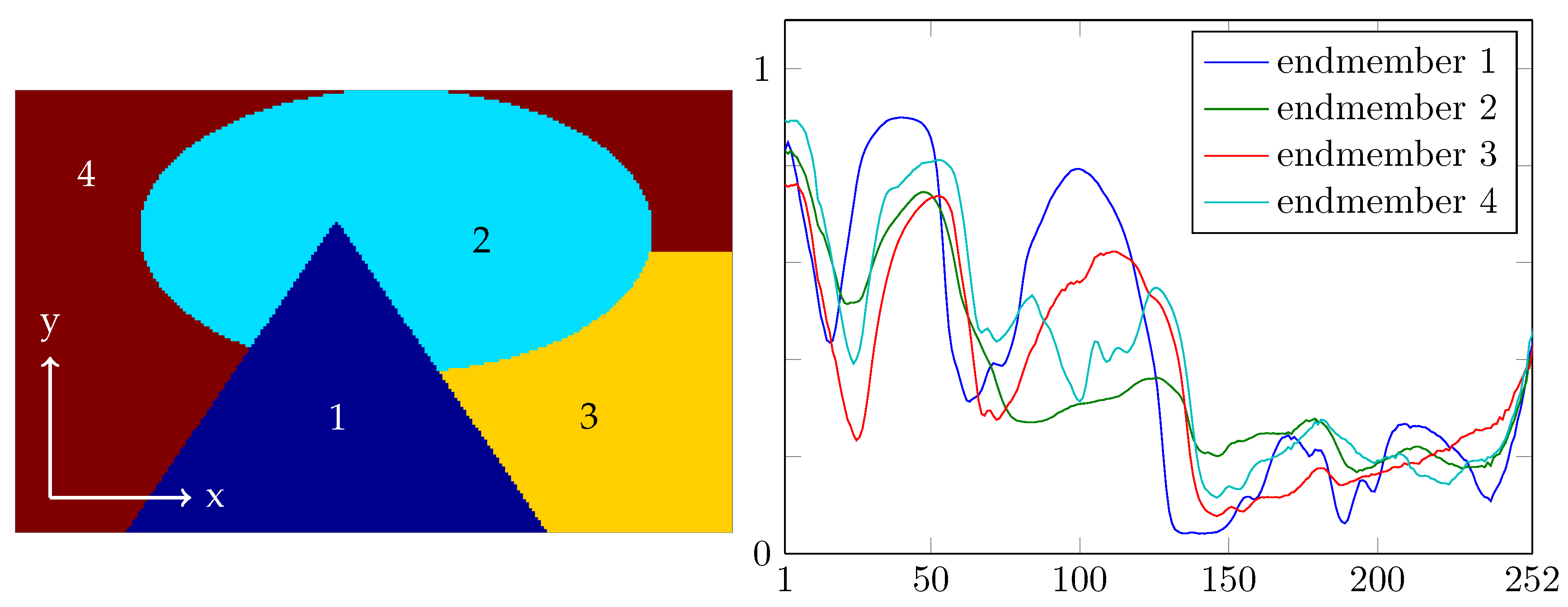
We have seen that our unmixing model performs well even if large parts of the hypercube are missing. To analyze which percentage of sensor pixels can be missing, i.e., to quantify the unmixing results in some way, in this section, we use an artificial input image with a small level of noise added.
The artificial image is constructed as follows. The
j-th of the four regions of the piecewise constant
ground truth image in
Figure 7 (left), is filled with copies of the
j-th endmember spectrum. The four endmember spectra, which form the
columns of the matrix
K, are shown in
Figure 7 (right). The spectra come from our measurements of common plastic blends. The resulting hypercube
belongs to
. We add independent zero-mean Gaussian noise to each entry
, obtaining the hypercube
. Here, the standard deviation was taken slightly larger than 1% of the maximal entry of
.
Figure 7.
The artificial image is constructed by filling region j of the image on the left with the j-th endmember spectrum on the right ().
Figure 7.
The artificial image is constructed by filling region j of the image on the left with the j-th endmember spectrum on the right ().
For several percentages from 100% down to
%, we randomly generate sensor masks of size
with approximately this percentage of working pixels, by flipping a biased coin for each pixel.
Figure 8a shows the upper left quarter of the sensor mask for 3% working pixels. Note that the percentage of known sensor pixels and the percentage of entries of
which are known to the unmixing algorithm, are the same, because each masked sensor pixel corresponds to one line in the hypercube along the
y-axis.
For each percentage and corresponding mask applied to
, we find the minimizer
X of Equation (
6) by Algorithm 1 with
and other parameters as in Remark 2; running 300 iterations took an average of
s per image. Then, we reshape
X into the cube
of unmixing coefficients. To quantify the quality of
, we assign to each image pixel
the endmember corresponding to the largest of the four unmixing coefficients
at that image pixel. Some of the resulting label images are shown in
Figure 8b.
Table 1 lists the percentages of correctly assigned pixels depending on the percentage of known sensor pixels. For more than 10% working sensor pixels, the algorithm found the largest material abundance at the correct material for 100% of the image pixels.
Figure 8.
(a) Upper left corner of the mask for 3% working sensor pixels; (b) label maps obtained from the unmixing by assigning to pixel the index r of the largest coefficient at that location.
Figure 8.
(a) Upper left corner of the mask for 3% working sensor pixels; (b) label maps obtained from the unmixing by assigning to pixel the index r of the largest coefficient at that location.
Furthermore, in
Table 1, we give the results from minimizing the model obtained by replacing isotropic TV in Model (
6) with anisotropic TV, as introduced in Remark 1. The results are slightly worse, though not much.
Table 1.
Percentage of image pixels, for which the largest of the material abundances found by the unmixing, correctly identifies the material at that pixel.
Table 1.
Percentage of image pixels, for which the largest of the material abundances found by the unmixing, correctly identifies the material at that pixel.
| sensor pixels known, in % | 30 | 10 | 3 | 1 | 0.3 | 0.1 |
| correctly assigned image pixels using TV, in % | 100 | 100 | 99.5 | 96.3 | 83.9 | 54.1 |
| correctly assigned image pixels using , in % | 100 | 100 | 99.4 | 95.5 | 82.8 | 52.7 |
4.4. Numerical Results for Artificial Data (Mixed Regions)
Next, we construct a test image comprising patches of linear mixtures of the endmembers, to meet the real-world scenario of mixed pixels. We take again the four endmembers shown in
Figure 7, hence again
. As shown in the false color visualization of the ground truth in
Figure 9 (left), the corners are filled with pure spectra, and along the sides of the image, we form linear mixtures. Then, a larger amount of noise, with a standard deviation of about 10% of the maximum, is added to the hypercube, and only about 10% of the pixels are retained. As in the previous section, we do this by first sampling a sensor mask under the assumption that each sensor pixel works with a probability of 10% and then simulating the line camera measurement. In
Figure 9, we plot Channel 40 of the hypercube, in the middle before masking, and on the right, as known to the algorithm.
Figure 9.
Ground truth in false colors (left); Channel 40 of the noisy hypercube (middle); Channel 40 noisy and masked (right); here, 10% are known.
Figure 9.
Ground truth in false colors (left); Channel 40 of the noisy hypercube (middle); Channel 40 noisy and masked (right); here, 10% are known.
Figure 10 shows the obtained abundances, for parameters as in Remark 2 and
after 918 iterations, which took
s on an Intel Core i7 with
GHz. The result is visually identical to the ground truth.
Figure 10.
Unmixing result, knowing 10% of the noisy hypercube. The images show the estimated abundances corresponding to the four pure spectra.
Figure 10.
Unmixing result, knowing 10% of the noisy hypercube. The images show the estimated abundances corresponding to the four pure spectra.
4.5. Numerical Results for Non-Occurring Endmembers
In applications, some of the expected materials might not be present in the image. We proceed as in the previous
Section 4.4, except that the endmember matrix
K now contains the eight spectra shown in
Figure 6b (
), of which four are chosen and mixed using the same abundances as in
Section 4.4. The abundances obtained from unmixing 10% of the hypercube are shown in
Figure 11.
Figure 11.
Unmixing result with eight endmembers of which four occur in the image; with 10% of the noisy hypercube known. The images show the estimated abundances corresponding to the eight pure spectra.
Figure 11.
Unmixing result with eight endmembers of which four occur in the image; with 10% of the noisy hypercube known. The images show the estimated abundances corresponding to the eight pure spectra.
Again, the true abundances are perfectly recovered.


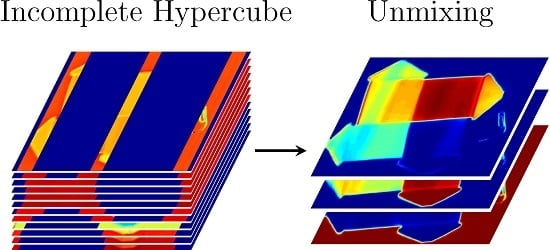










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


