
Tangent-Based Binary Image Abstraction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
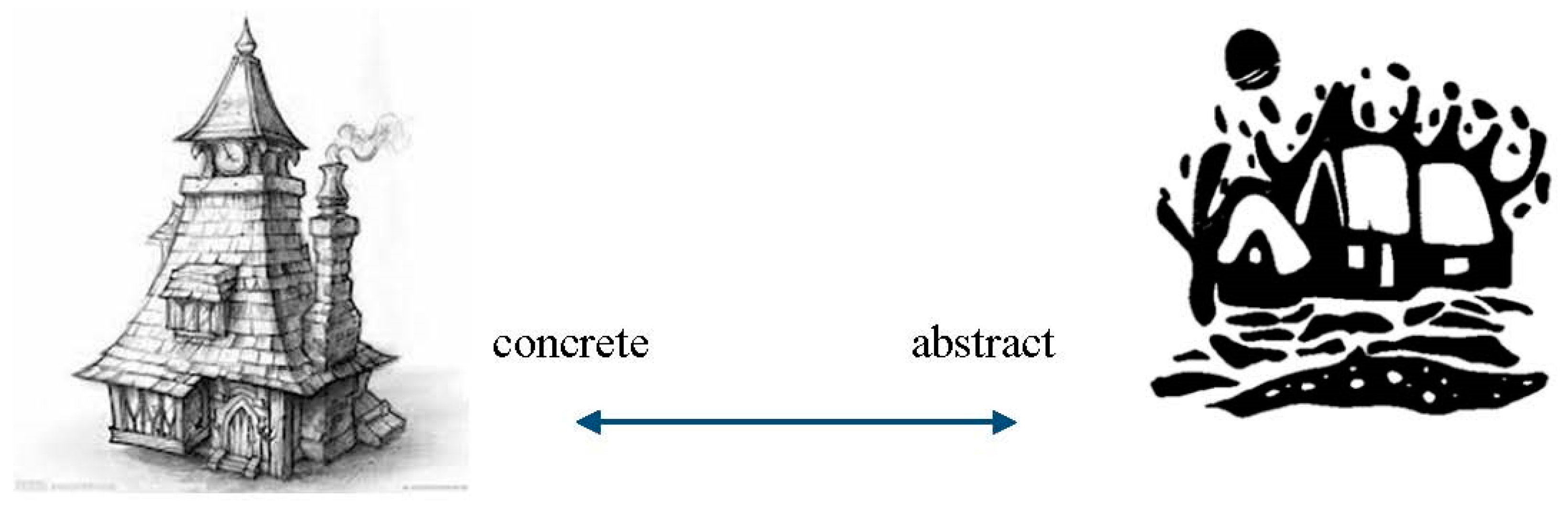
:1. Introduction
2. Related Work
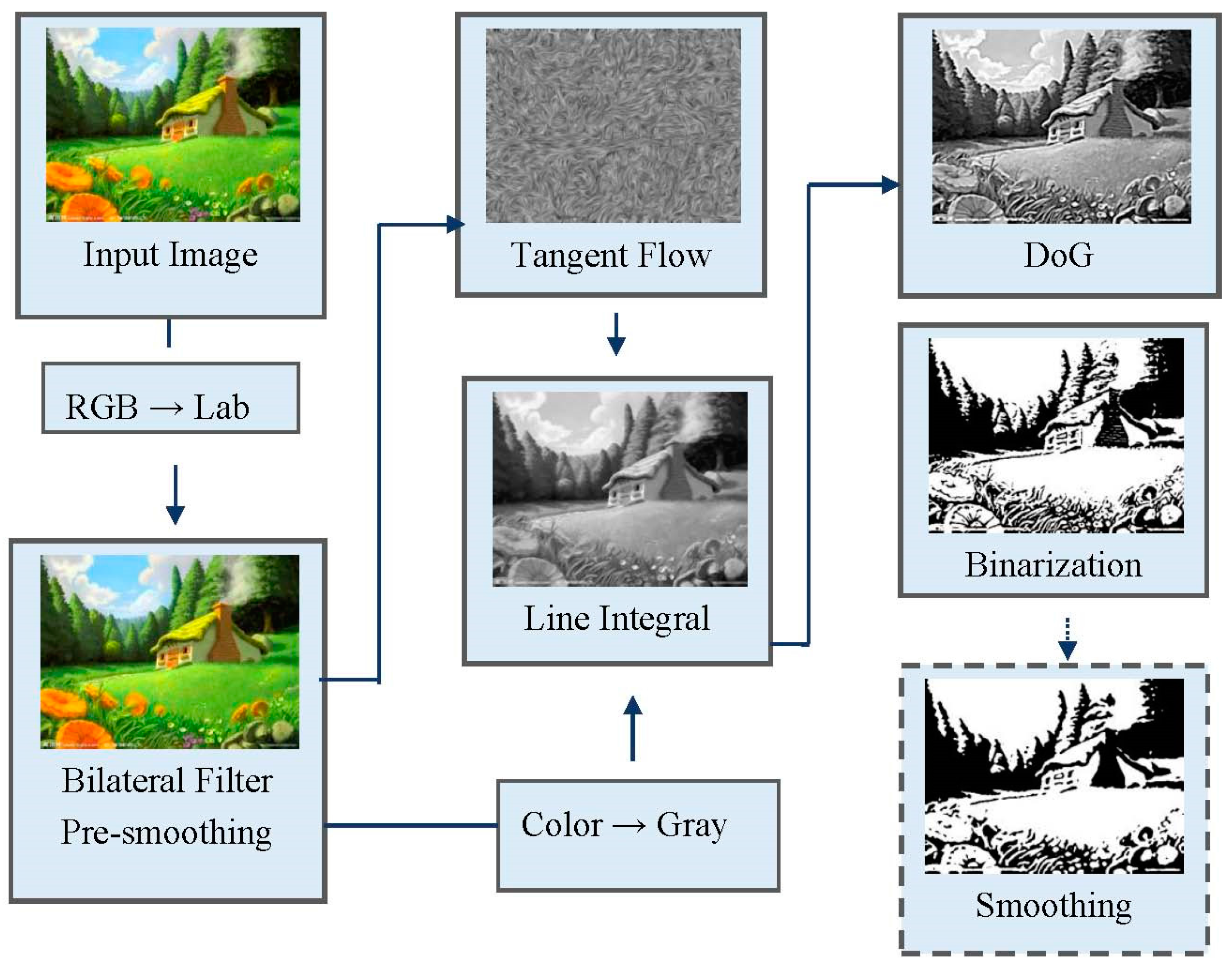
3. Method
3.1. Pre-Smoothing
3.2. Image Tangent Flow
3.3. Line Integral Convolution

3.4. Difference-of-Gaussians Enhancement
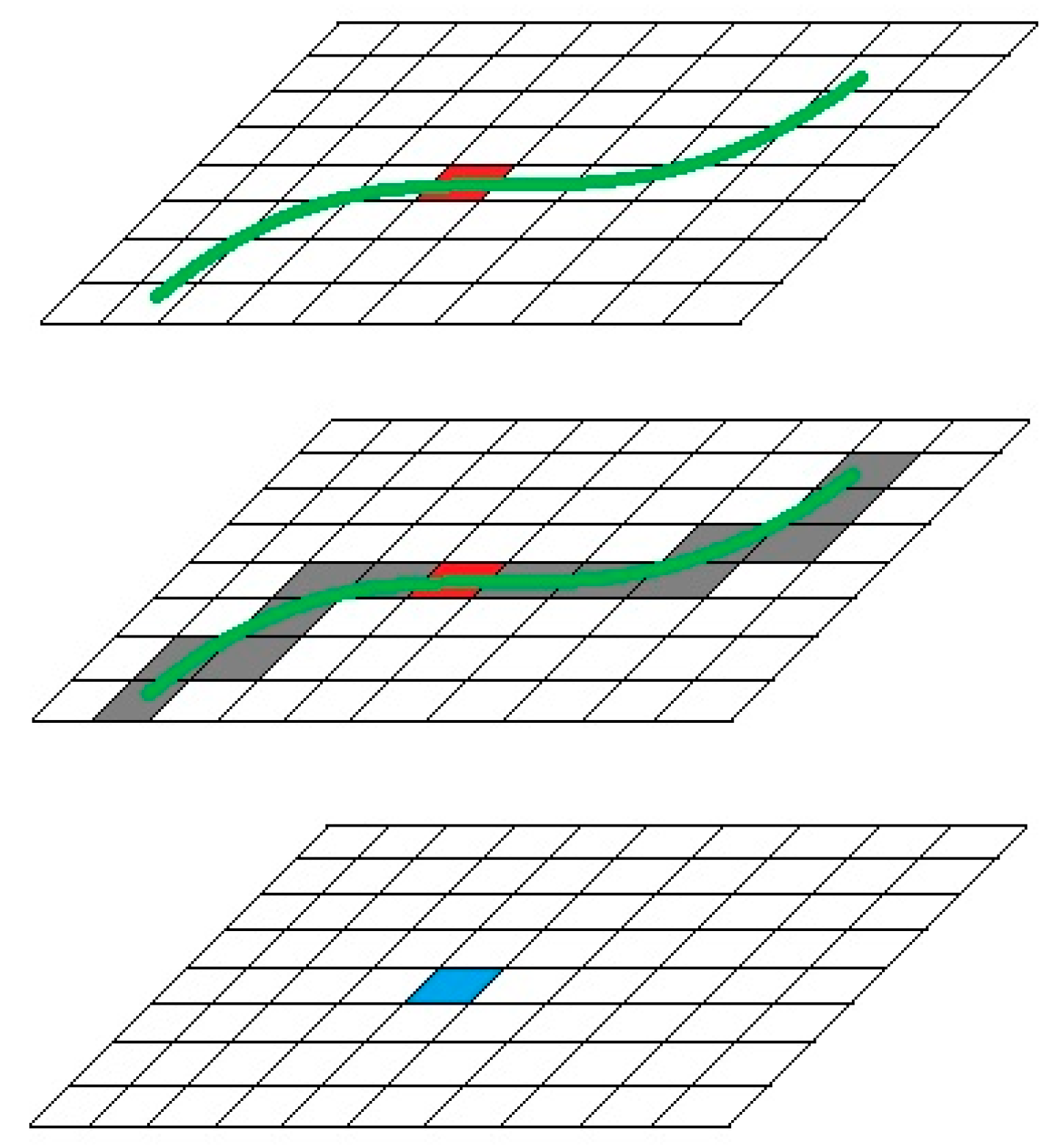
3.5. Binarization
3.6. Optional Smoothing Process
4. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tufte, E.R. Envisioning information. Optom. Vis. Sci. 1991, 68, 322–324. [Google Scholar] [CrossRef]
- Doug, D.; Santella, A. Stylization and Abstraction of Photographs. ACM Trans. Graph. (TOG) 2002, 21, 769–776. [Google Scholar]
- Winnemöller, H.; Olsen, S.C.; Gooch, B. Real-Time Video Abstraction. ACM Trans. Graph. (TOG) 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Kyprianidis, J.E.; Jürgen, D. Image Abstraction by Structure Adaptive Filtering. Available online: https://hpi.de/fileadmin/user_upload/fachgebiete/doellner/publications/2008/KD08b/jkyprian-tpcg2008.pdf (accessed on 17 April 2017).
- Chan, F.H.Y.; Lam, F.K.; Zhu, H. Adaptive Thresholding by Variational Method. IEEE Trans. Image Process. 1998, 7, 468–473. [Google Scholar] [CrossRef] [PubMed]
- Sauvola, J.; Pietikäinen, M. Adaptive Document Image Binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Bradley, D.; Gerhard, R. Adaptive Thresholding Using the Integral Image. J. Graph. GPU Game Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Pai, Y.T.; Chang, Y.F.; Ruan, S.J. Adaptive Thresholding Algorithm: Efficient Computation Technique Based on Intelligent Block Detection for Degraded Document Images. Pattern Recognit. 2010, 43, 3177–3187. [Google Scholar] [CrossRef]
- Singh, T.R.; Roy, S.; Singh, O.I.; Sinam, T.; Singh, K.M. A New Local Adaptive Thresholding Technique in Binarization. IJCSI Intern. J. Comput. Sci. Issues 2011, 8, 271–277. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar]
- Salisbury, M.P.; Anderson, S.E.; Barzel, R.; Salesin, D.H. Interactive Pen-And-Ink Illustration. In Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 24–29 July 1994; pp. 101–108. [Google Scholar]
- Meer, P.; Georgescu, B. Edge Detection with Embedded Confidence. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1351–1365. [Google Scholar] [CrossRef]
- Marr, D.; Ellen, H. Theory of Edge Detection. Proc. R. Soc. Lond. Ser. B 1980, 207, 187–217. [Google Scholar] [CrossRef]
- Gooch, B.; Reinhard, E.; Gooch, A. Human Facial Illustrations: Creation and Psychophysical Evaluation. ACM Trans. Graph. (TOG) 2004, 23, 27–44. [Google Scholar] [CrossRef]
- Kang, H.; Lee, S.; Chui, C.K. Coherent Line Drawing. In Proceedings of the 5th International Symposium on Non-Photorealistic Animation and Rendering, New York, NY, USA, 4–5 August 2007; pp. 43–50. [Google Scholar]
- Wang, S.; Wu, E.; Liu, Y.; Liu, X.; Chen, Y. Abstract Line Drawings from Photographs Using Flow-Based Filters. Comput. Graph. 2012, 36, 224–231. [Google Scholar] [CrossRef]
- Floyd, R.W.; Steinberg, L. An Adaptive Algorithm for Spatial Grey Scale. Proc. Soc. Inf. Disp. 1976, 17, 75–77. [Google Scholar]
- Jarvis, J.F.; Judice, C.N.; Ninke, W.H. A Survey of Techniques for the Display of Continuous Tone Pictures on Bi-level Displays. Comput. Graph. Image Process. 1976, 5, 13–40. [Google Scholar] [CrossRef]
- Stucki, P. MECCA—A multiple error correcting computation algorithm for bi-level image hard copy reproduction. Research report RZ1060. IBM Research Laboratory: Zurich, Switzerland, 1981. [Google Scholar]
- Ostromoukhov, V. A Simple and Efficient Error-Diffusion Algorithm. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001. [Google Scholar]
- Pang, W.M.; Qu, Y.; Wong, T.T.; Cohen-Or, D.; Heng, P.A. Structure-Aware Halftoning. ACM Trans. Graph. (TOG) 2008, 27, 89. [Google Scholar] [CrossRef]
- Chang, J.; Benoît, A.; Victor, O. Structure-Aware Error Diffusion. ACM Trans. Graph. (TOG) 2009, 28, 162. [Google Scholar] [CrossRef]
- Li, H.; Mould, D. Contrast Aware Halftoning. Comput. Graph. Forum 2010, 29, 273–280. [Google Scholar] [CrossRef]
- Mould, D.; Grant, K. Stylized Black and White Images from Photographs. In NPAR ’08 Proceedings of the 6th International Symposium on Non-Photorealistic Animation and Rendering, Annecy, France, 9–18 June 2008; ACM: New York, NY, USA; pp. 49–58.
- Xu, J.; Kaplan, C.S. Artistic Thresholding. In Proceedings of the NPAR ’08 6th International Symposium on Non-Photorealistic Animation and Rendering, Annecy, France, 9–11 June 2008. [Google Scholar]
- Qu, Y.; Pang, W.M.; Wong, T.T.; Heng, P.A. Richness-Preserving Manga Screening. ACM Trans. Graph. (TOG) 2008, 27, 155. [Google Scholar] [CrossRef]
- Herr, C. M.; Gu, N.; Roudavski, S.; Schenabel, M.A. Digital Manga Depiction. 2011. Available online: http://papers.cumincad.org/data/works/att/caadria2011_070.content.pdf (accessed on 17 April 2017).
- Mitra, N.J.; Chu, H.K.; Lee, T.Y.; Lior, W.; Hezy, Y.; Cohen-Or, D. Emerging Images. ACM Trans. Graph. (TOG) 2009, 28, 163. [Google Scholar] [CrossRef]
- Kang, H.; Lee, S.; Chui, C.K. Flow based Image Abstraction. IEEE Tran. Vis. Comp. Graph. 2009, 15, 62–78. [Google Scholar] [CrossRef] [PubMed]
- Tomasi, C.; Manduchi, R. Bilateral Filtering for Gray and Color Images. In Proceedings of the 1998 6th IEEE International Conference on Computer Vision, Bombay, India, 7 January 1998. [Google Scholar]
- Silvano, D.Z. A Note on the Gradient of a Multi-Image. Comput. Vis. Graph. Image Process. 1986, 33, 116–125. [Google Scholar]
- Cumani, A. Edge Detection in Multispectral Images. CVGIP Graph. Models Image Process. 1991, 53, 40–51. [Google Scholar] [CrossRef]
- Cabral, B.; Leith, C.L. Imaging Vector Fields Using Line Integral Convolution. In Proceedings of the 20th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 2–6 August 1993. [Google Scholar]
- Berger, I.; Shamir, A.; Mahler, M.; Carter, E.; Hodgins, J. Style and Abstraction in Portrait Sketching. ACM Trans. Graph. (TOG) 2013, 32, 55. [Google Scholar] [CrossRef]
- Nieuwenhuis, C.; Toeppe, E.; Lena, G.; Veksler, O.; Boykov, Y. Efficient Squared Curvature. 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Available online: http://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Nieuwenhuis_Efficient_Squared_Curvature_2014_CVPR_paper.pdf (accessed on 17 April 2017).








© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.-T.; Yeh, J.-S.; Wu, F.-C.; Chuang, Y.-Y. Tangent-Based Binary Image Abstraction. J. Imaging 2017, 3, 16. https://doi.org/10.3390/jimaging3020016
Wu Y-T, Yeh J-S, Wu F-C, Chuang Y-Y. Tangent-Based Binary Image Abstraction. Journal of Imaging. 2017; 3(2):16. https://doi.org/10.3390/jimaging3020016
Chicago/Turabian StyleWu, Yi-Ta, Jeng-Sheng Yeh, Fu-Che Wu, and Yung-Yu Chuang. 2017. "Tangent-Based Binary Image Abstraction" Journal of Imaging 3, no. 2: 16. https://doi.org/10.3390/jimaging3020016
APA StyleWu, Y.-T., Yeh, J.-S., Wu, F.-C., & Chuang, Y.-Y. (2017). Tangent-Based Binary Image Abstraction. Journal of Imaging, 3(2), 16. https://doi.org/10.3390/jimaging3020016