A Contrast-Guided Approach for the Enhancement of Low-Lighting Underwater Images

Abstract
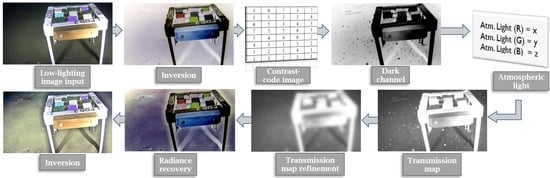
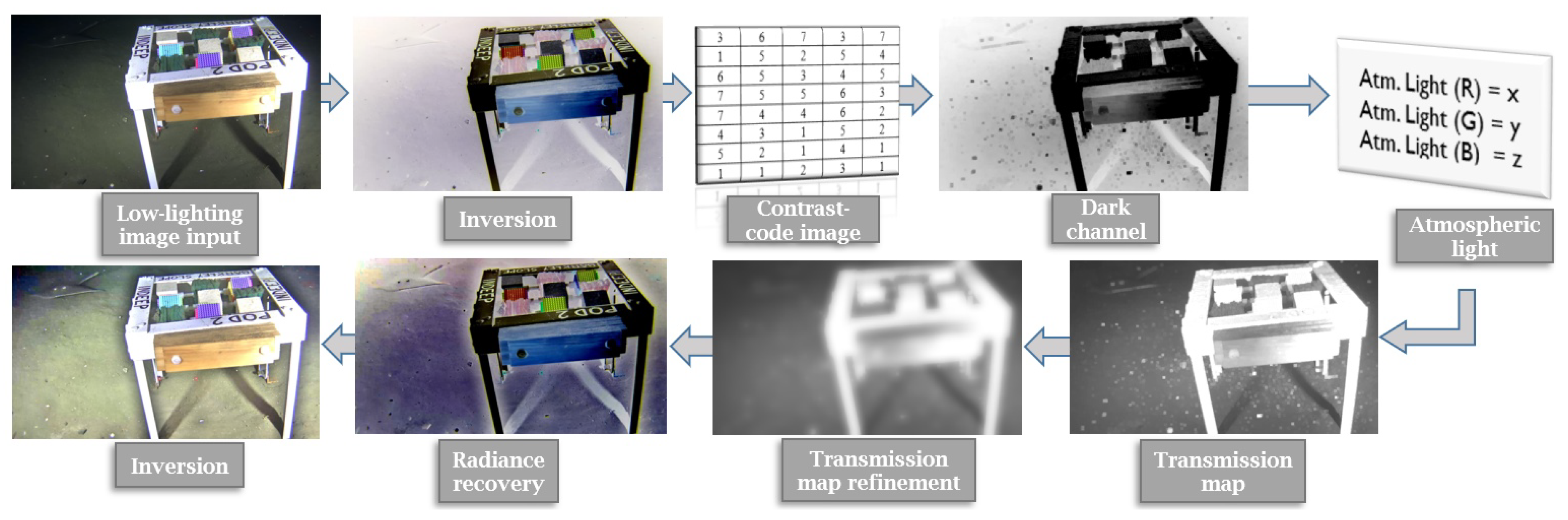
:
1. Introduction
1.1. Background
1.2. Contributions
2. Proposed Approach
2.1. Dcp-Based Dehazing of Single Images
2.2. Transmission Map Refinement
2.3. Disadvantages of the Use of Single-Sized Patches
- Hazy regions in the image: The pixel intensities do not drastically change in these regions, because of their more homogeneous color distribution. Therefore, patches of different sizes (i.e., ranging from up to ) will likely capture a pixel that is closely-valued to the mean intensity inside the patch, correctly representing the transmission of this sub-region. In this case, bigger patch sizes are preferred given that they will strengthen the DCP by creating darker dark channels.
- Regions with complex content: In these regions, selecting a big patch size will oversimplify the dark channel and transmission map, creating halos in the dehazed image. Since there are multiple intensity changes (gradients) and the transmission is not constant in these regions, a more careful analysis on the local characteristics of such regions is desired, thus the need for smaller patch sizes.
2.4. A Novel Contrast-Guided Approach for the Calculation of Dark Channels and Transmission Maps Using Patches of Varying Sizes
| Algorithm 1: Calculation of the contrast code image () for the proposed approach. |
 |
3. Experimental Results
3.1. The Oceandark Dataset
- Low-lighting underwater images with artificial lighting sources: Sites located deep into the ocean usually contain dark regions that hide valuable information in the images.
- Images with meaningful structures: To evaluate cases where the proposed enhancement framework is most useful, all samples in the dataset contain large objects, either biological or artificial, that suffer from sub-optimal illumination, e.g., skates, crabs, fish, urchins, scientific apparatus, etc.
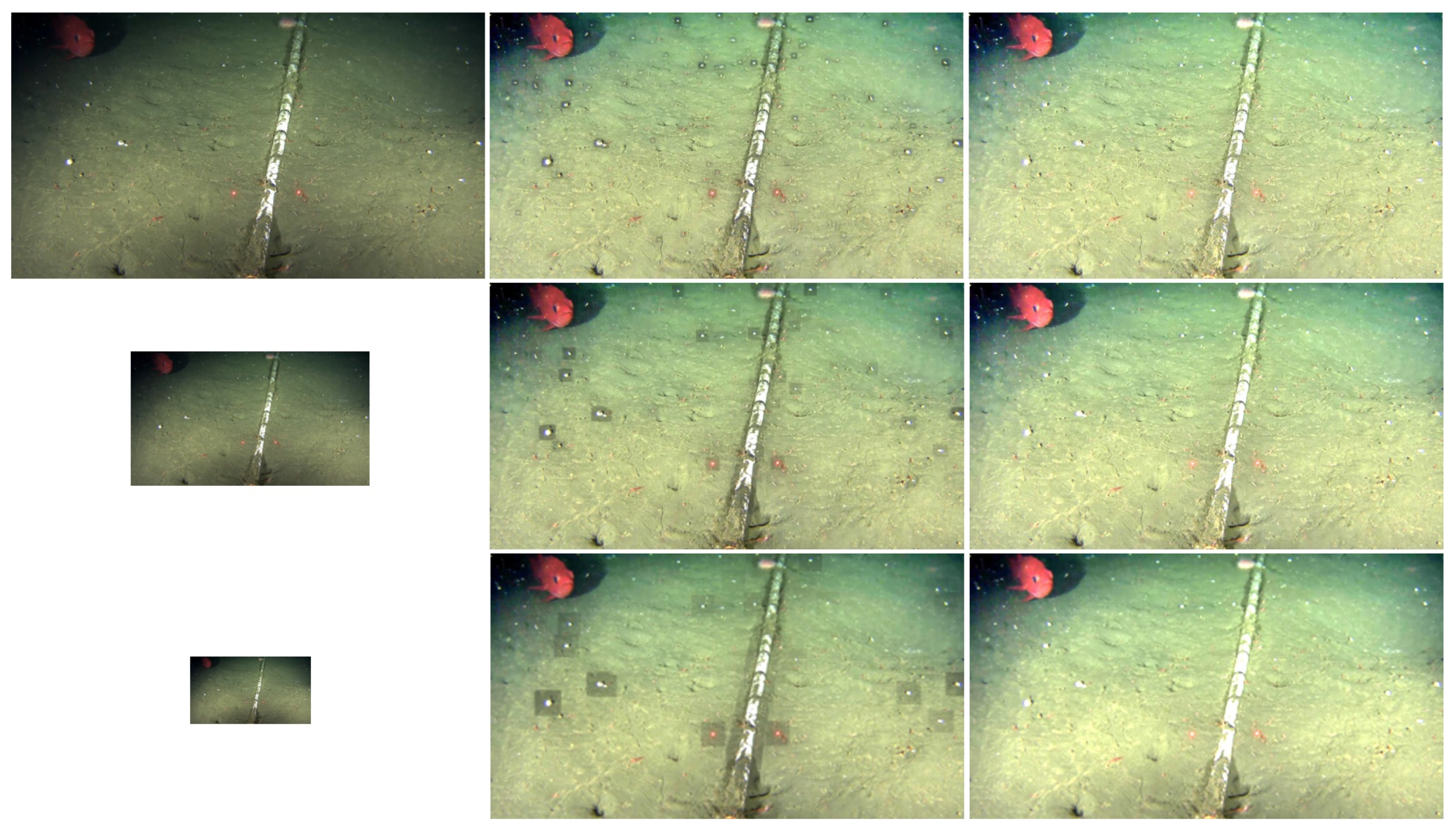
3.2. Contrast-Guided Approach Evaluation
3.2.1. Case Study
3.2.2. Comparison between the Usage of Dynamic and Static Patch Sizes
3.3. Enhancement Framework Evaluation with Low-Lighting Underwater Images
- SURF features [48]: As discussed in Section 3.2.2, the increase in number for these features indicate a boost in usefulness of the underwater images.
- r-score [56]: This score compares the visibility level of both original and enhanced images. Thus, an increase in r-score represents a successful contrast-enhancing procedure.
- Fog Aware Density Evaluator (FADE) score [58]: This is a no-reference score based on the perceptual fog density observed in an image. As discussed in Section 2.1, the low-lighting regions of an image are considered as haze in its inverted version. Therefore, the images are inverted before this score is measured, allowing for the study of their fog (or haze) levels. Smaller scores represent less fog (for our case study, darkness), which is desired.
3.4. Comparison with State-of-the-Art Underwater-Specific Enhancement Frameworks
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mallet, D.; Pelletier, D. Underwater video techniques for observing coastal marine biodiversity: A review of sixty years of publications (1952–2012). Fish. Res. 2014, 154, 44–62. [Google Scholar] [CrossRef]
- Gomes-Pereira, J.N.; Auger, V.; Beisiegel, K.; Benjamin, R.; Bergmann, M.; Bowden, D.; Buhl-Mortensen, P.; De Leo, F.C.; Dionísio, G.; Durden, J.M.; et al. Current and future trends in marine image annotation software. Prog. Oceanogr. 2016, 149, 106–120. [Google Scholar] [CrossRef]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast Efficient Algorithm for Enhancement of Low Lighting Video. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011. [Google Scholar]
- Schettini, R.; Corchs, S. Underwater image processing: State of the art of restoration and image enhancement methods. EURASIP J. Adv. Signal Process. 2010, 2010, 746052. [Google Scholar] [CrossRef]
- Jaffe, J.S. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- McGlamery, B. A Computer Model for Underwater Camera Systems. In Proceedings of the Ocean Optics VI. International Society for Optics and Photonics, Monterey, CA, USA, 26 March 1980; Volume 208, pp. 221–232. [Google Scholar]
- Hou, W.; Gray, D.J.; Weidemann, A.D.; Fournier, G.R.; Forand, J. Automated Underwater Image Restoration and Retrieval of Related Optical Properties. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 1889–1892. [Google Scholar]
- Trucco, E.; Olmos-Antillon, A.T. Self-tuning underwater image restoration. IEEE J. Ocean. Eng. 2006, 31, 511–519. [Google Scholar] [CrossRef]
- Bazeille, S.; Quidu, I.; Jaulin, L.; Malkasse, J.P. Automatic Underwater Image Pre-Processing. In Proceedings of the CMM’06, Brest, France, 16–19 Octobre 2006. [Google Scholar]
- Chambah, M.; Semani, D.; Renouf, A.; Courtellemont, P.; Rizzi, A. Underwater Color Constancy: Enhancement of Automatic Live Fish Recognition. In Proceedings of the SPIE—The International Society for Optical Engineering, San Jose, CA, USA, 18 December 2003; Volume 5293, pp. 157–169. [Google Scholar]
- Iqbal, K.; Salam, R.A.; Osman, A.; Talib, A.Z. Underwater Image Enhancement Using an Integrated Colour Model. IAENG Int. J. Comput. Sci. 2007, 34. [Google Scholar]
- Hitam, M.S.; Awalludin, E.A.; Yussof, W.N.J.H.W.; Bachok, Z. Mixture Contrast Limited Adaptive Histogram Equalization for Underwater Image Enhancement. In Proceedings of the 2013 International Conference on Computer Applications Technology (ICCAT), Sousse, Tunisia, 20–22 January 2013; pp. 1–5. [Google Scholar]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar] [CrossRef]
- Yang, H.Y.; Chen, P.Y.; Huang, C.C.; Zhuang, Y.Z.; Shiau, Y.H. Low Complexity Underwater Image Enhancement Based on Dark Channel Prior. In Proceedings of the Second International Conference on Innovations in Bio-inspired Computing and Applications (IBICA), Shenzhan, China, 16–18 December 2011; pp. 17–20. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C.; Garcia, R.; Bovik, A.C. Multi-Scale Underwater Descattering. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 4202–4207. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Neumann, L.; Garcia, R. Color Transfer for Underwater Dehazing and Depth Estimation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 695–699. [Google Scholar]
- Peng, Y.T.; Zhao, X.; Cosman, P.C. Single Underwater Image Enhancement Using Depth Estimation Based on Blurriness. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4952–4956. [Google Scholar]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission Estimation in Underwater Single Images. In Proceedings of the IEEE international conference on computer vision workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Diving Into Hazelines: Color Restoration of Underwater Images. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; Volume 1. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Cho, Y.; Kim, A. Visibility Enhancement for Underwater Visual SLAM Based on Underwater Light Scattering Model. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 710–717. [Google Scholar]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.P.; Ding, X. A Retinex-Based Enhancing Approach for Single Underwater Image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic Framework for Vision in Bad Weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Hilton Head Island, SC, USA, 15 June 2000; Volume 1, pp. 598–605. [Google Scholar]
- Tan, R.T. Visibility in Bad Weather from A Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C. D-Hazy: A Dataset to Evaluate Quantitatively Dehazing Algorithms. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2226–2230. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-Scale Convolutional Neural Networks. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 154–169. [Google Scholar]
- Alharbi, E.M.; Ge, P.; Wang, H. A Research on Single Image Dehazing Algorithms Based on Dark Channel Prior. J. Comput. Commun. 2016, 4, 47. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C.; Bovik, A.C. Night-Time Dehazing by Fusion. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2256–2260. [Google Scholar]
- Jiang, L.; Jing, Y.; Hu, S.; Ge, B.; Xiao, W. Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways. Symmetry 2018, 10, 491. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement without Paired Supervision. arXiv 2019, arXiv:1906.06972. [Google Scholar]
- Marques, T.P.; Albu, A.B.; Hoeberechts, M. Enhancement of Low-Lighting Underwater Images Using Dark Channel Prior and Fast Guided Filters. In Proceedings of the ICPR 3rd Workshop on Computer Vision for Analysis of Underwater Imagery (CVAUI), IAPR, Beijing, China, 20–24 August 2018. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J. Fast Guided Filter. arXiv 2015, arXiv:1505.00996. [Google Scholar]
- Fattal, R. Single image dehazing. ACM Trans. Graph. (TOG) 2008, 27, 72. [Google Scholar] [CrossRef]
- Xiao, C.; Gan, J. Fast image dehazing using guided joint bilateral filter. Vis. Comput. 2012, 28, 713–721. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral Filtering for Gray and Color Images. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference From Rgbd Images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Lee, S.; Yun, S.; Nam, J.H.; Won, C.S.; Jung, S.W. A review on dark channel prior based image dehazing algorithms. EURASIP J. Image Video Process. 2016, 2016, 4. [Google Scholar] [CrossRef]
- Cheng, Y.J.; Chen, B.H.; Huang, S.C.; Kuo, S.Y.; Kopylov, A.; Seredint, O.; Mestetskiy, L.; Vishnyakov, B.; Vizilter, Y.; Vygolov, O.; et al. Visibility Enhancement of Single Hazy Images Using Hybrid Dark Channel Prior. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Manchester, UK, 13–16 October 2013; pp. 3627–3632. [Google Scholar]
- Marques, T.P.; Albu, A.B.; Hoeberechts, M. OceanDark: Low-Lighting Underwater Images Dataset. Available online: https://sites.google.com/view/oceandark/home (accessed on 19 July 2019).
- Duarte, A.; Codevilla, F.; Gaya, J.D.O.; Botelho, S.S.C. A Dataset to Evaluate Underwater Image Restoration Methods. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016; pp. 1–6. [Google Scholar]
- National Oceanic and Athmospheric Administration. Example Datasets. Available online: https://www.st.nmfs.noaa.gov/aiasi/DataSets.html (accessed on 27 November 2018).
- Simetti, E.; Wanderlingh, F.; Torelli, S.; Bibuli, M.; Odetti, A.; Bruzzone, G.; Lodi Rizzini, D.; Aleotti, J.; Palli, G.; Moriello, L.; et al. Autonomous Underwater Intervention: Experimental Results of the MARIS Project. IEEE J. Ocean. Eng. (JOE) 2018, 43, 620–639. [Google Scholar] [CrossRef]
- Ocean Networks Canada. Seatube Pro. Available online: http://dmas.uvic.ca/SeaTube (accessed on 5 September 2018).
- Ocean Networks Canada. Oceans 2.0. Available online: https://data.oceannetworks.ca/ (accessed on 13 May 2019).
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Matkovic, K.; Neumann, L.; Neumann, A.; Psik, T.; Purgathofer, W. Global Contrast Factor-a New Approach to Image Contrast. Comput. Aesthet. 2005, 2005, 159–168. [Google Scholar]
- Khan, A.; Ali, S.S.A.; Malik, A.S.; Anwer, A.; Meriaudeau, F. Underwater Image Enhancement by Wavelet Based Fusion. In Proceedings of the IEEE International Conference on Underwater System Technology: Theory and Applications (USYS), Penang, Malaysia, 13–14 December 2016; pp. 83–88. [Google Scholar]
- Tarel, J.P.; Hautière, N. Fast Visibility Restoration from a Single Color or Gray Level Image. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2201–2208. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- Valeriano, L.C.; Thomas, J.B.; Benoit, A. Deep Learning for Dehazing: Comparison and Analysis. In Proceedings of the 2018 Colour and Visual Computing Symposium (CVCS), Gjøvik, Norway, 19–20 September 2018; pp. 1–6. [Google Scholar]
- Hautiere, N.; Tarel, J.P.; Aubert, D.; Dumont, E. Blind contrast enhancement assessment by gradient ratioing at visible edges. Image Anal. Stereol. 2011, 27, 87–95. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Choi, L.K.; You, J.; Bovik, A.C. Referenceless prediction of perceptual fog density and perceptual image defogging. IEEE Trans. Image Process. 2015, 24, 3888–3901. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| for | for | -Sized Patches | Non--Sized Patches | |
|---|---|---|---|---|
| Sub-region of Figure 6b | 12.70 | 49.55 | N/A | N/A |
| Sub-region of Figure 6c | 1.80 | 1.76 | N/A | N/A |
| Whole Figure 6a with | N/A | N/A | 704,622 (76.4%) | 216,378 (23.6%) |
| Whole Figure 6a with | N/A | N/A | 554,534 (60.21%) | 366,466 (39.79%) |
| Patches Used | Patches Used | DC Mean Pixel Intensity | DC References (/) | DC Improvement | GCF Score | BLIINDS-II Score | SURF Features | |
|---|---|---|---|---|---|---|---|---|
| OceanDark 1 with CGA | 474,201 (51.45%) | 265,663 (28.82%) | 77.89 | 80.80/71.28 | 29.01% | 0.1985 | 77.5 | 582 |
| OceanDark 1 with SA | 921,600 (100%) | 0 | 80.80 | 80.80/71.28 | N/A | 0.1792 | 76.5 | 560 |
| OceanDark 2 with CGA | 587,982 (63.80%) | 177,824 (19.29%) | 95.89 | 98.11/87.04 | 20.01% | 0.1928 | 73 | 530 |
| OceanDark 2 with SA | 921,600 (100%) | 0 | 98.11 | 98.11/87.04 | N/A | 0.1757 | 71.5 | 495 |
| OceanDark 3 with CGA | 622,323 (67.52%) | 154,447 (16.76%) | 97.07 | 98.55/90.86 | 19.22% | 0.1794 | 72 | 185 |
| OceanDark 3 with SA | 921,600 (100%) | 0 | 98.55 | 98.55/90.86 | N/A | 0.1738 | 71 | 172 |
| Increase in SURF Features | Increase in e-Score | Increase in r-Score | Decrease in FADE Score (Darkness) | |
|---|---|---|---|---|
| Enhanced images | 106.84% | 28% | 175% | 75.92% |
| Original | Proposed | Drews [18] | Berman [19] | Fu [22] | Cho [21] | |
|---|---|---|---|---|---|---|
| GCF [50] | ||||||
| e-score [56] | N/A | |||||
| r-score [56] | N/A | |||||
| FADE [58] | ||||||
| SURF [48] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Porto Marques, T.; Branzan Albu, A.; Hoeberechts, M. A Contrast-Guided Approach for the Enhancement of Low-Lighting Underwater Images. J. Imaging 2019, 5, 79. https://doi.org/10.3390/jimaging5100079
Porto Marques T, Branzan Albu A, Hoeberechts M. A Contrast-Guided Approach for the Enhancement of Low-Lighting Underwater Images. Journal of Imaging. 2019; 5(10):79. https://doi.org/10.3390/jimaging5100079
Chicago/Turabian StylePorto Marques, Tunai, Alexandra Branzan Albu, and Maia Hoeberechts. 2019. "A Contrast-Guided Approach for the Enhancement of Low-Lighting Underwater Images" Journal of Imaging 5, no. 10: 79. https://doi.org/10.3390/jimaging5100079
APA StylePorto Marques, T., Branzan Albu, A., & Hoeberechts, M. (2019). A Contrast-Guided Approach for the Enhancement of Low-Lighting Underwater Images. Journal of Imaging, 5(10), 79. https://doi.org/10.3390/jimaging5100079