1. Introduction
Human action recognition (HAR) is a challenging field. This is due to a number of reasons. One important reason is the large variations in how actions are performed. It can also include variations in appearances of people, objects in their environment and the environment (scene). Deficiency in the availability of data resources, vague definitions of an action and drift in dynamic environments can all be sources of difficulty (see, e.g., [
1]). This topic has been utilised in numerous applications such as surveillance based event detection, human–computer interaction and video retrieval [
2].
Different conditions can also make HAR a difficult and challenging issue. There are issues such as occlusions, multiple viewpoints, action speed variations or even differences in illumination. Fortunately, depth cameras have enabled and provided a great push for HAR. They can provide both colour data as well as depth data. Depth is less sensitive to light intensity variances [
3]. Depth is also more distinct than other derived appearance based features from, e.g., segmentation and detection [
4]. Another aspect that can help make action recognition achieve better predictability is if data are taken as groups [
1]. This is because groups of depth data for a single type of action can be more easily generalised to other instances.
In general, HAR can be classified into two categories: Hand crafted versus automatic learning methods. Hand-crafted feature based methods often consist of three stages. These are: Feature extraction, feature description and classification. Different kinds of hand-crafted features can be extracted from source sequences. Then, different descriptor techniques can be derived from extracted features. Finally, a classification process is usually employed to classify actions into different classes. Hand crafted features are useful because they enable some important aspects of the data to be emphasised. However, it is often difficult to make handcrafted features generally applicable. They can be sensitive to changes in a scene or even need to be re-designed for each application or scene [
1]. These models are often not able to overcome challenging environments. On the other hand, automatically learned feature models can help overcome some of these shortcomings. Thus, one of the most important aims of this paper is to utilise both automatically and manually learned feature models for HAR.
In 2006, Hinton et al. proposed a solution for the training problem using a layer-wise training method based on deep learning [
5]. Deep learning has been based on different techniques such as convolution [
6], deep belief networks [
5], auto-encoders [
7] and recurrent neural networks [
8]. These have all been used for learning of features, see, e.g., [
9,
10]. These kinds of approaches, in many cases, have been found to outperform hand-crafted features. Since then, much research has relied on deep learning techniques. It has been applied to various topics such as image classification [
11], speech recognition [
12] and object recognition [
13]. In addition, many studies on HAR have used deep learning, either with colour image sequences or depth sequences [
14,
15,
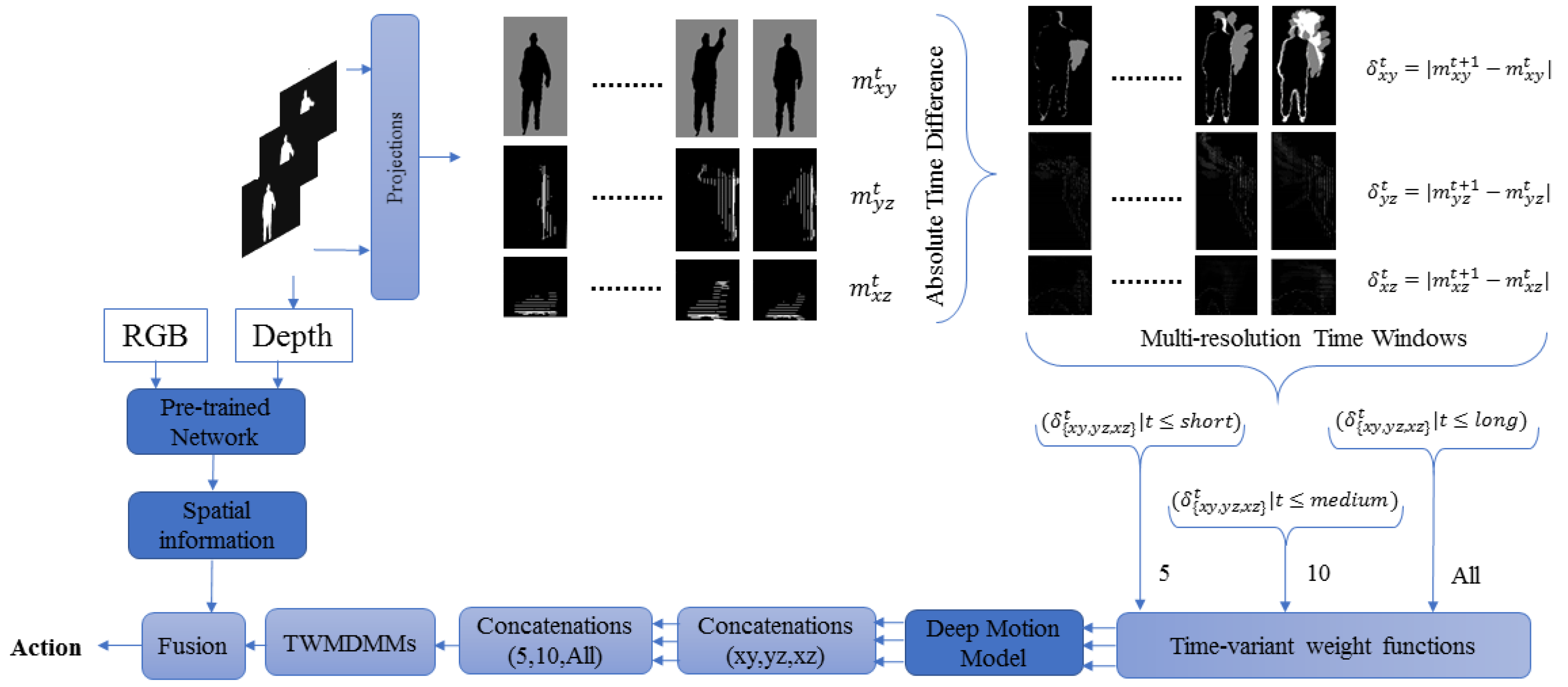
16]. However, most of these deep networks are based on either pre-extracted hand-crafted features or raw colour/depth sequences as inputs. This paper proposes a novel improvement on hand-crafted features based on fuzzy weighted multi-resolution depth motion maps (FWMDMMs). These help to characterise different important aspects of the depth motion data across multiple time resolutions. Then, deep learning is applied to automatically learn distinctive and compact features from the improved depth motion features. Important spatial information is learnt using the RGB and depth data using transfer learning. Finally, various fusion techniques are considered to suitably classify actions into appropriate classes. The proposed framework is illustrated in
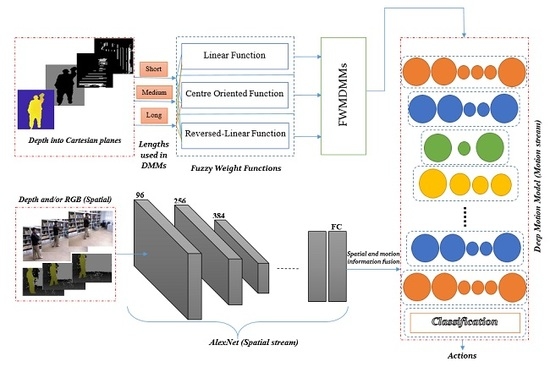
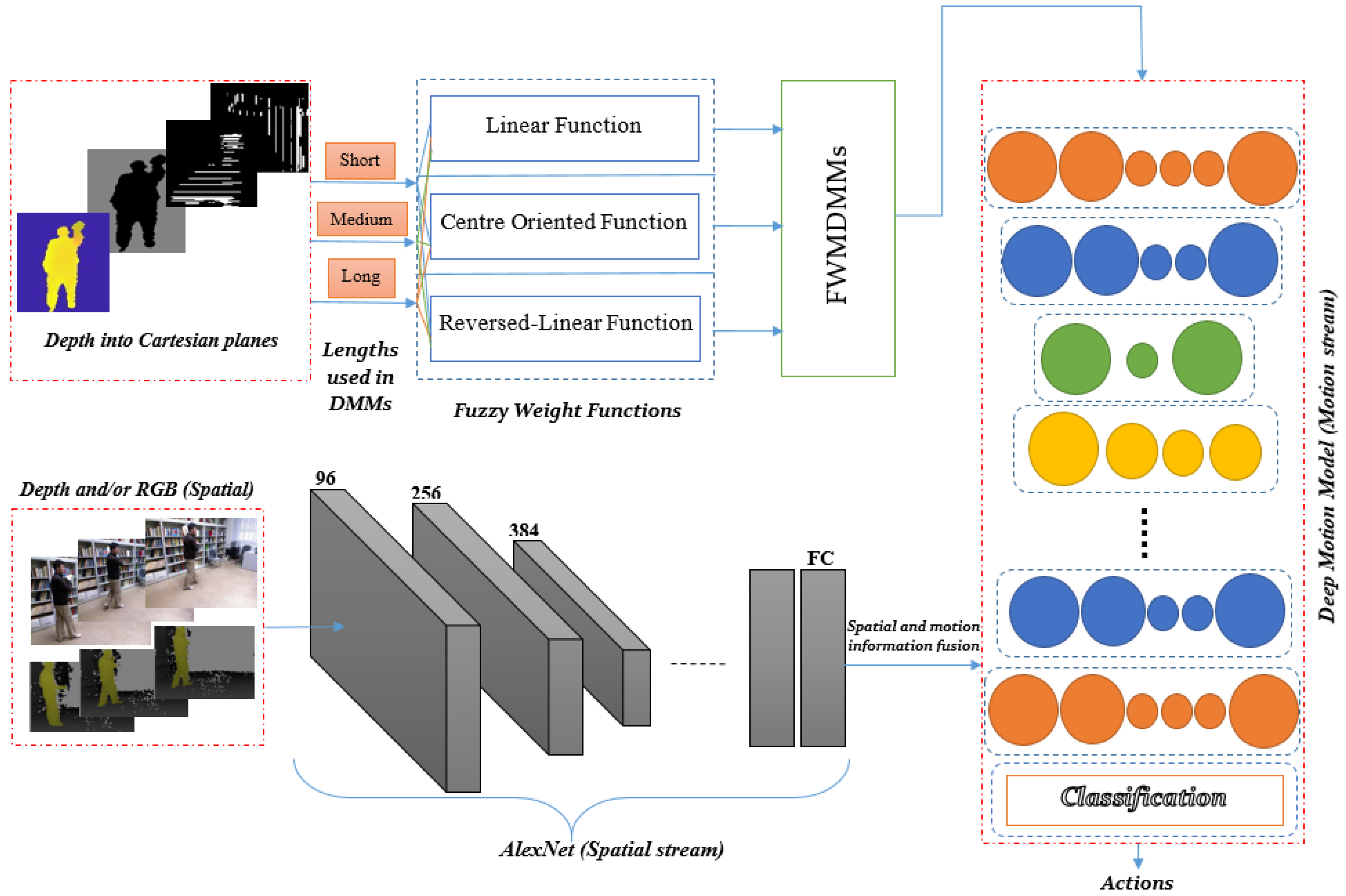
Figure 1.
Main Contributions
In this paper, we propose a novel framework for learning of action models by combining together a deep and handcrafted hybrid feature model to get discriminative information. The key contribution of this paper is as follows:
In order to learn information in the temporal dimension with diverse applicability, we develop a novel spatial temporal deep learning model. It includes a new method that improves traditional depth motion maps (DMMs) [
17,
18] called fuzzy weighted multi-resolution depth motion maps (FWMDMMs). The FWMDMM includes a number of different temporal model instances. These are used to help overcome the inherent variability in time associated for each individual action. Furthermore it can help overcome difficulties with self-occlusions and actions that might have similar types of movements.
The work differs from work in (e.g., [
19,
20]). For instance, for the DMM computation, overlapped segments were used in the calculation of a Multi-resolution DMM (MDMM). This means redundant information is included. For the work presented here, non-overlapped segments are used. This saves processing time for the MDMM calculation. Moreover, the weight functions of paper [
19] are just incremental weights. For the work here, different weight functions are used. These enhance a number of different important aspects of an action sequence including incremental, decremented and middle weight functions.
In addition, the work presented here enhances the recognition system performance by including deep learning. This is used to process the DMM features and to provide more discriminative information for each action. Moreover, different streams of depth and appearance information are merged with the DMM information. This is performed with the use of different fusion techniques to produce the final spatio-temporal information.
The remainder of this paper is organised as follows:
Section 2 reviews the related work.
Section 3 presents the overall structure of the proposed framework and the detail of FWMDMM, fusion and deeper models. The experimental results and discussions are described in
Section 4. Finally,
Section 5 concludes the paper.
2. Related Work
HAR has been a popular area of research in the computer vision field. The performance of a HAR system depends on the quality of the features of a scene and of the actors themselves. Hence, many researchers have focused on designing superior scene descriptors. This has included using traditional approaches based on hand-crafted features to summarise and encapsulate local appearance and motion information effectively and efficiently. However, it has also included extension to include 3D information as well as the traditional appearance based RGB data.
Fortunately, cost effective depth sensors have been developed and have received increasing attention. Sensors such as Kinect [
21] and Xtion [
22] can provide depth information as an input. According to [
23,
24] an important advantage of depth based HAR, is in terms of the availability of 3D information. The 3D information of an object structure is useful in itself. However, it also helps to provide invariance to lighting and to help overcome other potential problems with, e.g., scale.
An effective HAR method, presented in [
17], projected depth onto the three planes: Front, side and top views. Then, DMMs were generated encapsulating the motion information for entire video sequences for each DMM. In addition, Histograms of Oriented Gradients were computed from the resulting DMMs for use as descriptors. In [
18], DMMs were used for HAR together with an
-regularised collaborative representation classifier with a distance-weighted Tikhonov matrix was also used. Chen et al. [
25] calculated motion cues and local binary patterns (LBPs) from the DMMs. Two fusion levels were also considered including feature-fusion level and decision-fusion level. The DMM based results showed reasonable HAR performance.
Different levels of the same data sequence have been used with DMM computations to create a hierarchical DMM in [
20]. A LBP based descriptor was used to characterise local rotation invariant texture information. Then a Fisher kernel was employed to create patch descriptors. These were then fed into a kernel-based extreme learning machine classifier. A similar approach was followed by [
26]. A histogram of oriented gradients (HOGs) descriptor was used along with kernel entropy component analysis for dimensionality reduction. Finally a linear support vector machine was used in the classification. For both hierarchical DMM based approaches, the results demonstrated a significant performance improvement. DMMs can express the variation of a subject’s motions during the performance of an action. However, difficulties can potentially arise between actions that have the same type of movements but over different temporal periods. To tackle this issue, fuzzy weighted multi-resolution depth motion maps are proposed here in this work, explained in the next section.
Some other researchers have used skeleton joint information for depth based HAR such as [
27]. The skeleton joint information aided in finding the relationship between different body parts. A combination of various interest point detectors were used in [
28]. These formed different space time interest points (STIPs) features. The experiments demonstrated that the recognition rate could be improved by combining skeleton joint information and spatio-temporal features. However, it is dependent on deriving an accurate skeleton representation. Other methods have been proposed to represent depth sequence information without the need to derive the skeleton information. This has included learning an actionlet ensemble [
29], spatio-temporal depth cuboid features [
30] and super normal vectors [
31].
Deep learning has successfully been used for HAR [
32,
33,
34]. Deep learning models have the ability to learn features in a hierarchical way starting from low level features reaching to high level ones. convolution neural networks (CNNs), were proposed in [
6]. CNNs use trainable filters and local neighbourhood pooling processes to obtain a hierarchy of complex features. CNNs can be made invariant to variations in pose, lighting and surrounding clutter [
35]. In addition, CNNs can achieve great performance on visual field tasks when trained with proper regularisation [
36,
37]. convolutional neural network models have been used to build deep learning based HAR systems such as [
38]. Video based spatial and temporal information was learned. A deep two-stream model was constructed based on transfer learning using a modified RestNets-101. A stream is a series of layers trained on a set of features. RGB and a volume of stacked optical flow data were taken as inputs for the spatial and temporal network streams, respectively. The proposed strategy was able to achieve competitive results for HAR.
For a fixed orientation, a spatio-temporal convolutional network based HAR was proposed in [
39]. This used spatio-temporal features. Moreover, in [
40], a HAR system was proposed based on a two stream deep CNN model. The two streams consisted of a spatial stream which learned appearance features and a temporal stream which learned motion information. The motion information was based on stacked optical flow frames. An extension of this two stream network approach was proposed in [
41] using dense trajectories. This resulted in more effective learning of motion information. A fusion of two stream networks was proposed in [
42] by applying several combinations between them. This helped to take further advantage of the spatio-temporal features.
A general residual network architecture for HAR was presented in [
43]. Here cross-stream residual connections in the form of multiplicative interaction between appearance and motion streams were used. The motion information was exploited using stacked inputs of horizontal and vertical optical flow. A fusion study was presented in [
44] for HAR. Two streams of the pre-trained visual geometry group (VGG) network model were used to compute spatio-temporal information combining RGB and stacked optical flow data. Various fusion mechanisms at different positions of the two streams were evaluated to determine the best possible recognition performance.
All of the above approaches suffer from a shortage of long term temporal information. For example, the number of frames used in the optical flow stacking ranged between 7 and 15 frames. For example, 7, 10 and 15 frames were used by [
35,
42,
45], respectively. Often people will perform the same action over different periods of time depending on many factors and particularly for different people. Consequently, multi-resolution hand-crafted features computed over different durations of time are used here in this work. This helps to avoid this problem. Furthermore, different weight phases are applied using a fuzzy algorithm in the computation process of the DMMs. Thus, enabling adaptation to different aspects of an action.
We take advantage of a deep learning method to learn discriminative features from both RGB and depth sequences. At the same time, we exploit some important aspects a priori by developing hand-crafted features in a deep motion model. These hand-crafted are referred to here as FWMDMMs. The FWMDMMs are extracted from depth sequence data and learned as part of the motion information. Two streams are considered here, including the deep motion model and a pre-trained AlexNet model to extract the motion and spatial features, respectively. Moreover, different fusion techniques are evaluated. These are used to merge the spatial and motion information to find the best way approach for HAR models proposed here.
3. Construction of Fuzzy Weighted Multi-Resolutions Depth Motion Map
3.1. Depth Motion Maps (DMMs)
Both RGB and depth for each frame are exploited in the framework proposed here. In addition, multi-resolution shape and motion information are also used here in the form of a modified DMM formulation. The basic DMM, (as used in, e.g., [
17,
18,
46]), includes projecting each depth frame onto three orthogonal Cartesian planes. The foreground is specified by a bounding box as a region of interest and then normalised to a particular size.
As a result, each depth frame will generate three 2D planes or maps xy, xz, yz indicating front, side and top views. The motion energy of each single map can be obtained by computing and thresholding the difference between two consecutive maps. This provides a superior clue for HAR by specifying motion regions and showing where the motion occurs in each temporal template.
The motion energy can then be stacked through a specific interval or through the entire sequence. This generates a DMM,
for each projection view,
where
{ xy, yz, xz } indicates the projection view;
is the projected map of frame
t under projection view
v;
N is the number of frames that indicates the length of the interval.
In general, DMMs are represented on each orthogonal Cartesian plane by combining projected maps of an entire depth sequence. Hence, important information of body shape and motion are emphasised.
3.2. Multi-Resolution Depth Motion Maps (MDMMs)
Traditional DMMs are formulated on 2D planes as described above by combining projected motion maps of an entire depth sequence. This formulation does not consider the higher order temporal links between frames of depth sequences. An enhancement is therefore applied here to improve on the traditional DMMs.
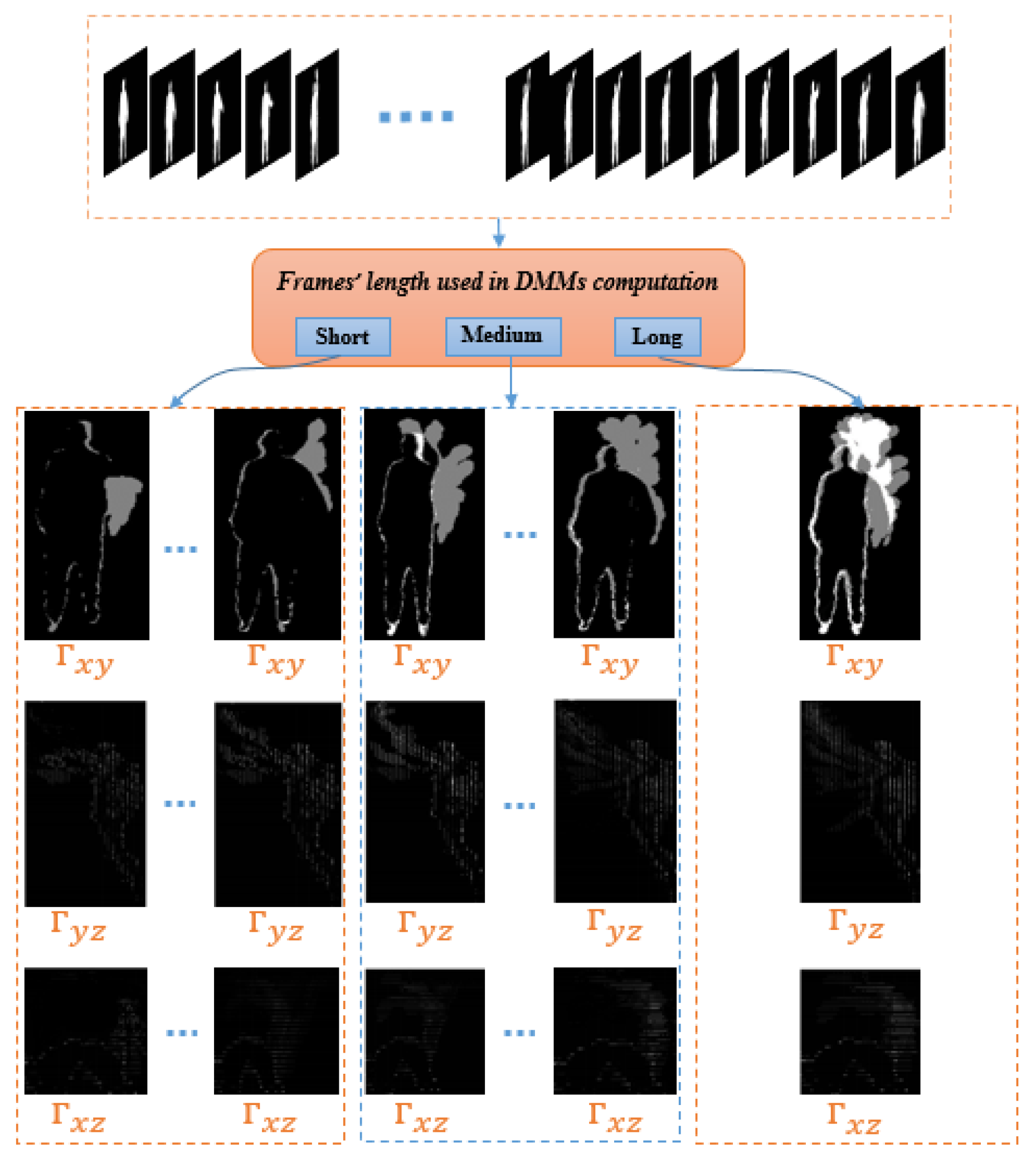
Mostly, a fixed number of frames have been used by other researchers or even the entire number of frames of an action sequence video. However, a length of an action is not known in advance. In addition, an action can be performed at different speeds by different people. Hence, MDMMs are used here to cover different temporal intervals and rates of an action.
In our work, the depth sequence is split into three different groups where each has a different time interval. This means, various values of the threshold,
, formulated to generate MDMMs for the same action (depth sequence). As
∈
in traditional DMMs, this can be improved by
∈
where
∈
. This extension enables different temporal windows to properly cover an action’s motion regardless of whether it carries important information over a short or long duration. Each of these three durations produce a different DMM. The values of
are selected to cover short, intermediate and long durations. For long, this would typically correspond to an entire depth sequence for the various video sequences considered here.
Figure 2 illustrates the computational procedure for MDMMs.
These MDMMs for each depth sequence can be calculated with:
where
,
∈
and, e.g.,
are the various lengths of depth sequence used to obtain a MDMM for each single frame.
Then, a single MDMM is created again via concatenation, but now across all time resolution windows ∈ after processing, i.e., , where represents concatenation.
3.3. Fuzzy Weighted Multi-Resolution DMMs (FWMDMMs)
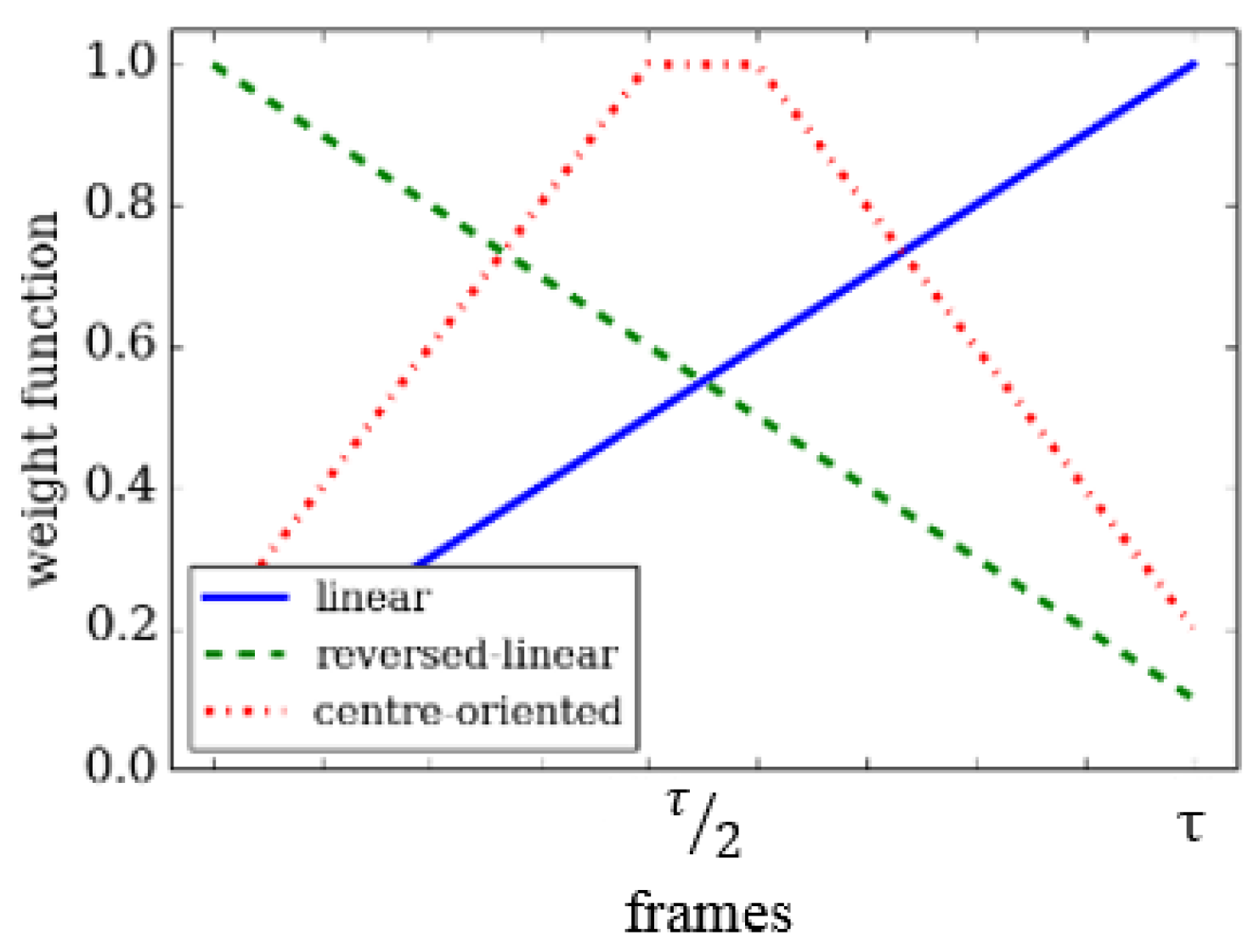
In order to identify significant motion, we take into consideration the motion history image based method. A linear weighting as a function of time is used to find historical motion information with high weight due to recent motion. Hence, after weight allocation for each frame, the recent moving pixels which have most recently shown some motion result in greater intensities. By proceeding with this approach, a fuzzy algorithm is used here to give each DMM various weights to assign dynamically ranging importance to the motion information.
Let
be the linear weight that is given to frame
t with values in the range between
. This can be improved for DMMs by replacing the
with three fuzzy weight functions. Each has the same range based weighting approach. This helps to emphasise salient aspects in time of an action sequence. The three weight functions provide three different weight formulations for frames in the same DMM template. The result is three different DMM representations. These fuzzy functions can assign importance to the motion information in frame
t using three linearly varying functions. The functions are: linear function, reversed linear function and central-oriented function.
Figure 3 and
Figure 4 illustrate the fuzzy weight functions and the resulting effects on the DMMs (
is considered in the figure).
The weighting function is combined with the MDMM like so:
The final version of improved DMMs are generated using three temporal templates based on the intervals . These are weighted with fuzzy functions to produce fuzzy weighted DMM templates. Concatenation is used after processing to produce a FWMDMM, based on a particular weighting function.
4. Deep Convolutional Neural Networks
Convolutional neural networks (CNNs) are a type of multi-layer Perceptrons that can be considered to follow the same principles as the visual mechanisms in organism. At the most basic level there are cells combined together in the form of various complexities assigned to sub-regions of a visual scene. A similar although considerably simplified kind of processing can be achieved by using convolutional filters or CNNs over a given data.
CNNs can automatically achieve feature extraction directly from input data. This can help solve the exhaustive search of hand-crafted methods. Furthermore, CNN operations include the local receptive field, shared weights and pooling. These processes are adopted to attain shift, scale and distortion invariance that can improve recognition accuracy.
4.1. Transfer Learning of Spatial Information
A pre-trained AlexNet model proposed in [
47] containing eight pre-trained layers is used here for initialisation. Two parallel AlexNet networks are used here to compute features of the RGB and depth information. In addition, extra CNNs are used for the motion model to fuse and learn the information of the two parallel networks and DMM hand-crafted features.
Figure 5 shows all stages of the recognition system proposed here. While there are many better options of pre-trained networks, AlexNet was used in transfer learning due to its moderate trainable parameters that can meet our processing limitations. AlexNet has been widely used for HAR in many research studies due to its reasonable trainable parameters in comparison to other pre-trained network models see, e.g., [
48].
Network architecture is very important because it plays a significant role in the performance of the deep learning model. Common deep network architectures usually have alternating convolutional layers and auxiliary layers, e.g., pooling, rectified or dropout layers and terminated by a few fully connected (FC) layers.
Originally in [
47], the output of the third fully connected layer was delivered by using a 1000 softmax functions which assigns the distribution over 1000 class labels. In our case, the last fully connected layer is delivered in a different way using softmax functions based on the number of existing class labels of the validation datasets.
The input image of the first convolution layer is filtered with 96 kernels of size 11 × 11 × 3 and a stride of 4 pixels. Next, the output of the first convolution layer is taken as input to the second convolution layer and filtered with 256 kernels of size 5 × 5 × 48. The following layers are connected one to another with 384 kernels of size 3 × 3 × 256, 384 kernels of size 3 × 3 × 192 and 256 kernels of size 3 × 3 × 192 in terms of the third, fourth and fifth convolutional layers, respectively.
4.2. Fusing the Spatial Networks
For more reliable recognition, it is preferable to utilise diverse information sources combined using fusion to achieve better performance. This can be done using either concatenation of features or via an average of several decision scores [
42]. Fusion can be utilised to combine any given set of deep networks. An easier way to combine multiple networks is to add an extra fully connected layer to combine outputs of the networks. The advantage of using different features at the same time is to help improve the recognition model and hence recognition performance.
In our work, we propose multiple different fusion techniques at different positions of the spatial two-stream networks. Information fusion is implemented partially between the RGB and depth stream networks combining multiple layers of two trained parallel networks including several CNN architectures such as early, middle and late fusion. This helps to find the best position and technique for RGB and depth fusion that can optimise the recognition rate. In addition, hand-crafted features are exploited in the deep motion model using improved DMMs as an auxiliary source of features that represent motion information of an action. Fusion position via motion model is specified based on the best recognition result of the fused spatial two-stream networks. Then, fused spatial information is utilised with the motion information in the deep motion model using the same fusion position. By adding hand-crafted features, our approach can incorporate two explicitly different types of features such as spatial and temporal information into the classification process.
In this section we consider different architectures for fusing the spatial two-stream networks for RGB and depth. Spatial fusion can be achieved between the two networks when the networks have the same spatial resolution at the fused layers by adding, multiplying or concatenating layers from one network to another. Later, the subsequent layers can suitably learn the correspondence between these channels to recognise the action.
A number of fusion techniques that are used between the two spatial networks are described here. Moreover, the consequences of each technique are highlighted in the experiments section. Let be a fusion function which fuses two feature maps and that belong to two different networks to produce an output , where H, W and D are the height, width and number of channels of the feature maps, respectively. The number of feature maps are based on the specific architecture of the network (in our case, there are for convolutional layer 5). Function f can be employed at various stages in the networks to achieve early, mid or late fusion.
Sum fusion is employed to compute the sum of the elements of two feature maps where each has the same spatial location and feature channels. Let
d be the number of feature channels, then:
where
,
,
.
Multiplicative fusion computes the multiplication of the two feature maps at each pixel location:
Concatenation fusion concatenates the two feature maps at the same spatial location and cross feature channels:
The proposed method is implemented with the various fusion techniques to fuse the RGB and depth spatial networks. These are applied at different positions between the spatial networks such as at the convolutional, max-pooling or fully connected layers. The output of the spatial fusion can be used to train a supervised classifier (KNN) to find the best position of fusion. Then, spatial (fused RGB and depth) and motion information are fused. Finally this is used to train a classification layer trained with standard back-propagation and stochastic gradient descent based algorithms.
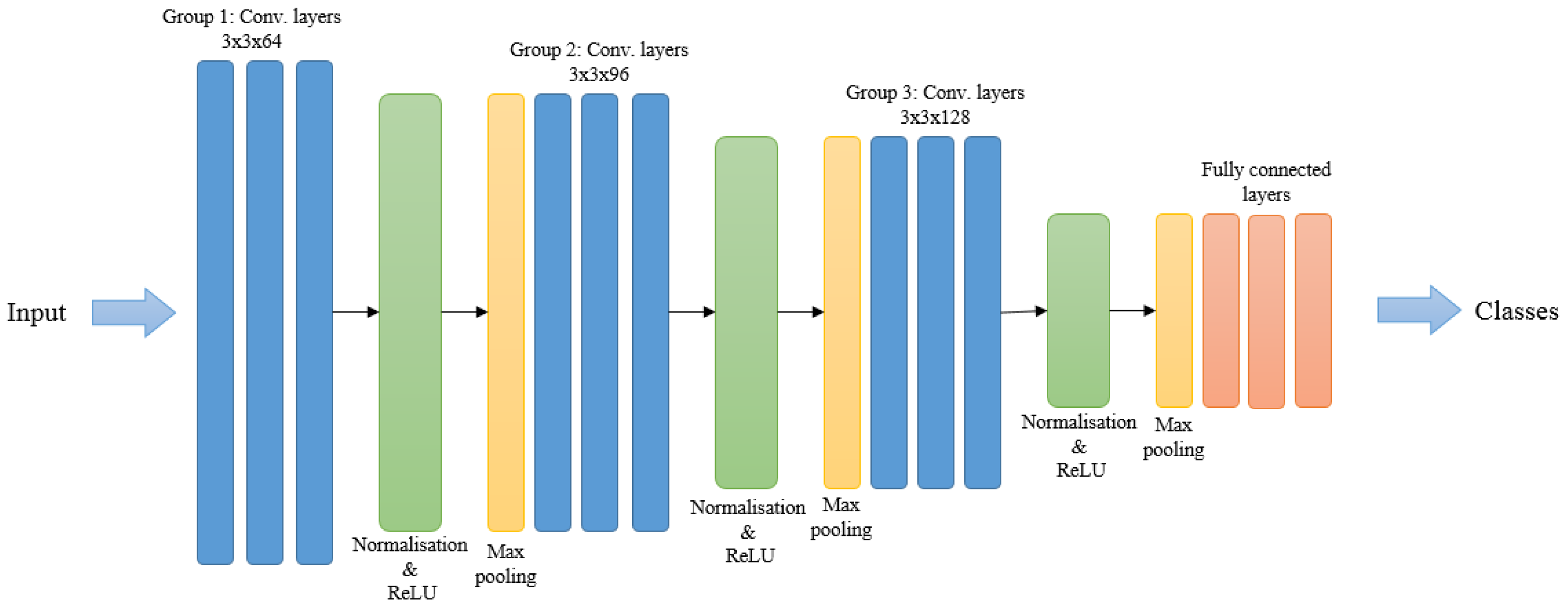
4.3. Deep Motion Model
After spatial fusion stages, we propose to go deeper to represent the temporal information in a proper way to help utilise the highly discriminative motion features. Our deeper motion model consists of a CNN based architecture that employs multiple distinct convolution operations to help identify discriminative features. It contains eleven learned layers including nine convolutional layers and two fully connected layers. We have designed various CNN architectures based on the deep temporal information but the results show that this architecture achieves the best performance. A brief description of the network architecture is shown in
Figure 6.
The convolutional layers constitute three groups in the network. Each has three convolutional layers, separated by normalisation, ReLu and max-pooling layers. The specifications of the later three layers are the same after each single group in the network. The specification of the convolutional layers are varied according to group stage. The hand-crafted (FWMDMMs) information proposed in
Section 3.1 forms the input to the motion model. This starts at the first group of convolutional layers and filtered with 64 kernels of size 3 × 3 each. Next, the output of the third convolutional layer in the first group is fed into the normalisation and max-pooling layers. These have pool size [2, 2] and stride [2, 2].
The output is then fed to the second group of three convolutional layers. These filter with 96 kernels of size 3 × 3 each. The output is then normalised and down-sampled again by the normalisation and max-pooling layers with the same specifications.
The final convolutional group consists of three convolutional layers. These filter the output of the previous layer with 128 kernels of size 3 × 3 each. The normalisation and down-sampling implemented layers then feed the information to the fully connected layers. These are separated by a dropout layer to give a significant boost to the performance of our model.
5. Implementation
The parameters of the fuzzy weight functions in Equations (
3)–(
5) are wholly dependent on the lengths of the weighted sequence
as utilised by Equation (
6). The length of the weighted sequence is varied as part of the multi-resolution approach, i.e.,
. This removes dependence on a single window length and consequently the underlying parameter settings too.
The system was implemented using Matlab. An NVidia 2GB Quadro Pro GPU was used to speed up the implementation process and to facilitate the deep learning techniques.
The AlexNet model was fine-tuned using stochastic gradient descent with batch size equal to 100, momentum 0.9 and weight decay 0.0005. The update rule for weight
w is
for iteration
i with momentum variable:
where
is the learning rate and
is the average over batch
i of
of the derivative of the objective with respect to
w, evaluated at
.
The biases in AlexNet are initialised with constant 1 in the second, fourth and fifth convolution layers in addition to the fully connected layers. The biases are set to constant 0 for the remaining layers. The same learning rate was used for the early layers and increased for the latter layers in order to accelerate the training. The learning rate was initialised at 0.001 [
47].
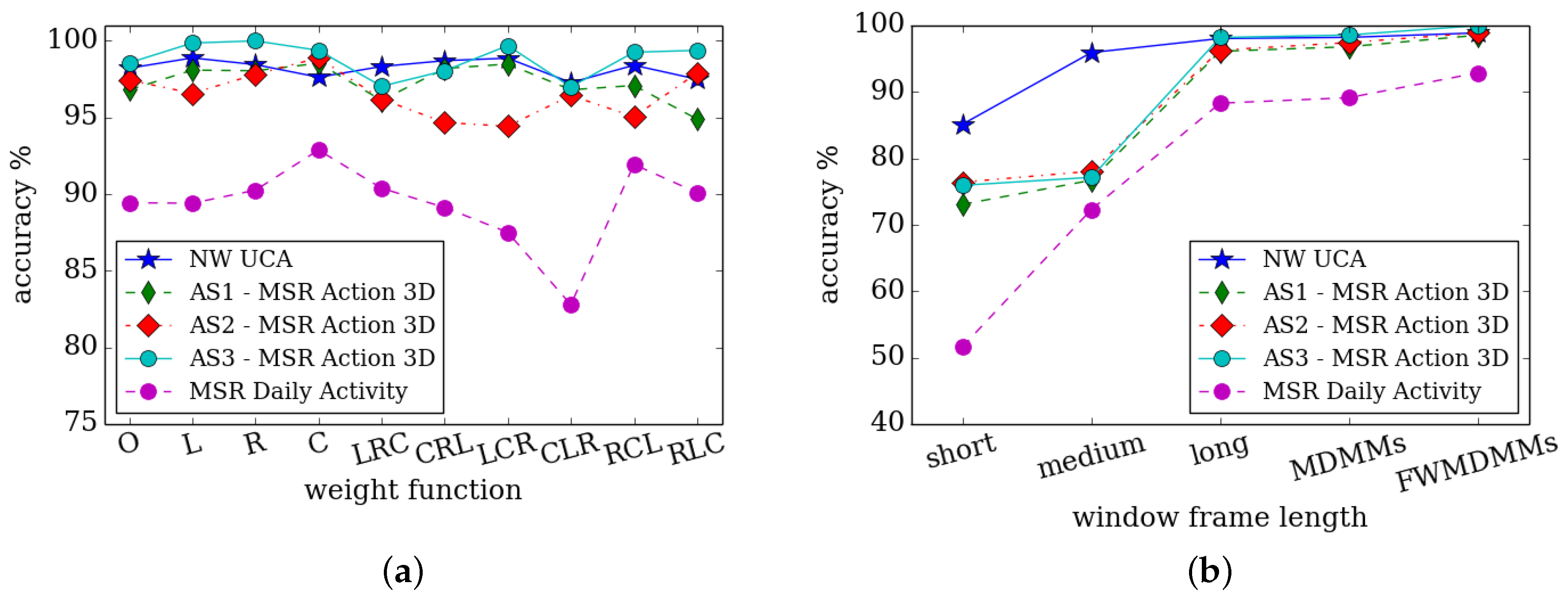
The time complexity of the DMM stream is two frames per second in the training section. While the testing time is 11 frames per second. It is difficult to make a like for like comparison with other state-of-the-art methods due to differences in hardware and software. However, the proposed system is able to run in real-time or close to real-time with relatively modest compute hardware.
7. Conclusions
This paper presents the novel FWMDMM for HAR. It appears to utilise the temporal motion information available in depth sequences more effectively compared to traditional DMMs. The feature representation is designed to help provide invariance to variations in action speed. This is important because the same type of action could be performed as different speeds by different people or even the same person. Fuzzy weight functions are employed to help emphasise multiple aspects of an action at different time points. This can help to exploit the most important moments in each action. As a result it can contribute to helping to provide improved differentiation between similar actions. Compact and discriminative features are extracted from FWMDMMs by utilising a CNN based deep motion model. In addition, the spatial and appearance based information in the RGB data and single frame depth data are also utilised. Transfer deep learning from the spatially trained AlexNet CNN is used to effectively represent the spatial information. Different fusion techniques have also been investigated between the spatial and motion information to find the most suitable approach.
The proposed method is able to classify human actions even with small differences in actions. This is in addition to providing excellent performance on actions that partly depend on human–object interactions. The results also appear to show invariance to noisy environments, errors in the depth maps and temporal misalignments.
The proposed approach has been validated on three publicly available benchmark datasets: MSR 3D actions, NUCLA multi-view actions and MSR daily activities. The experiments show that the results from the proposed method are equal if not competitive in comparison to state-of-the-art approaches.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}