
Hand Motion-Aware Surgical Tool Localization and Classification from an Egocentric Camera


Abstract
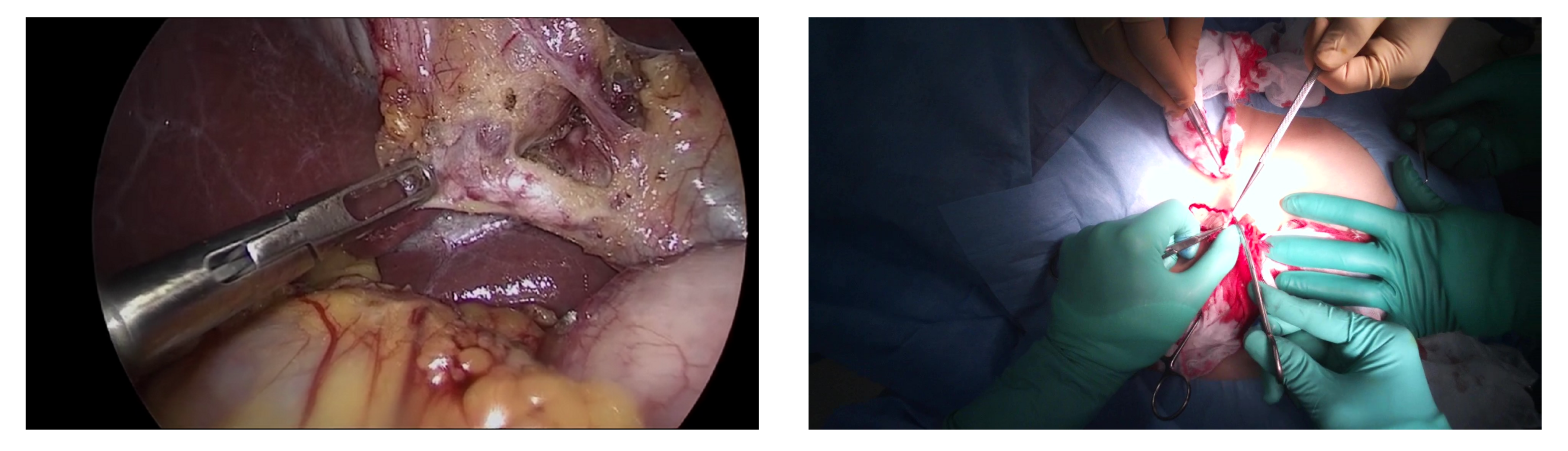
:1. Introduction
2. Related Work
2.1. Object Detection Using Hand Appearance
2.2. Surgery Video Analysis and Surgical Tool Detection
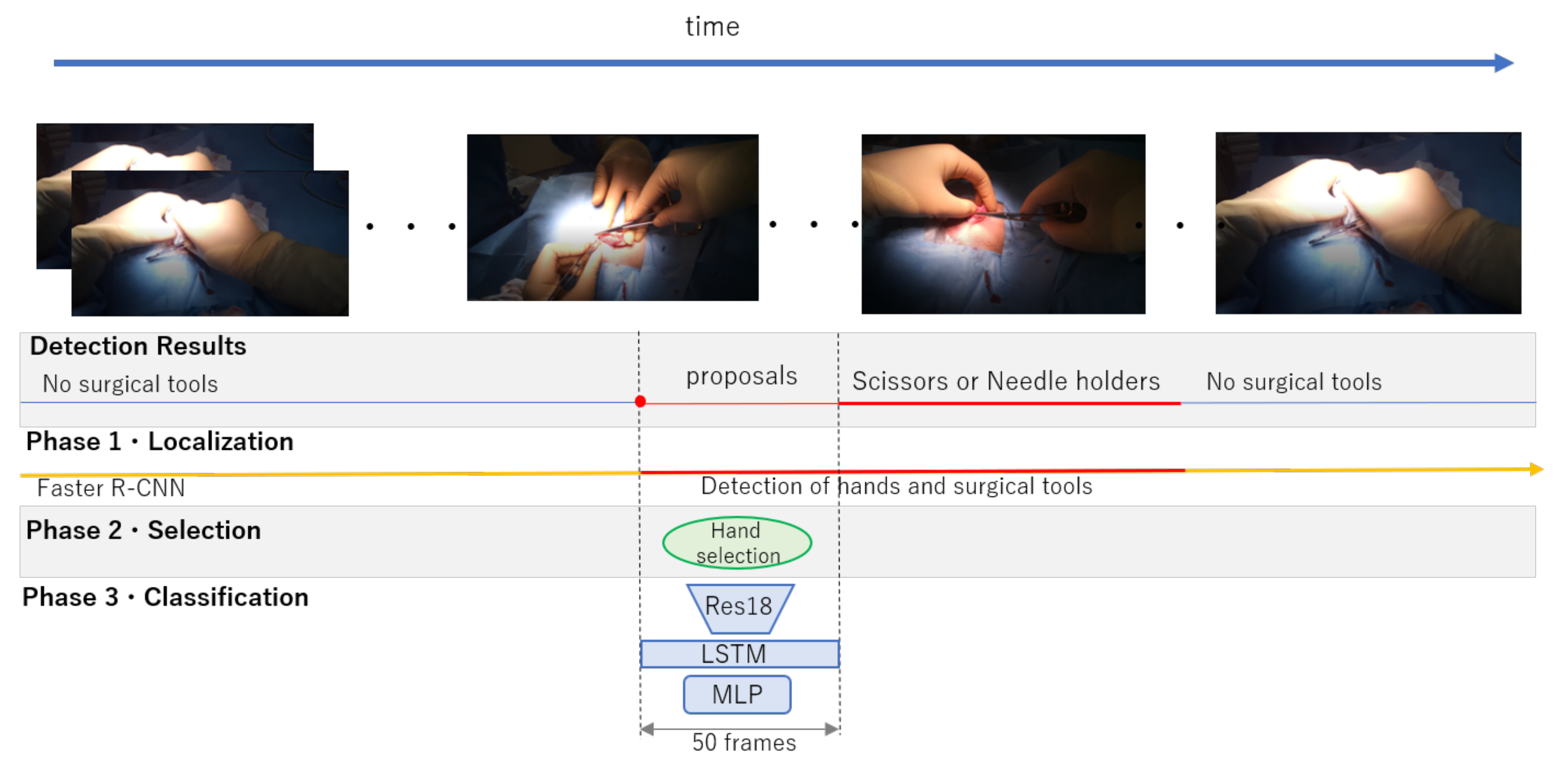
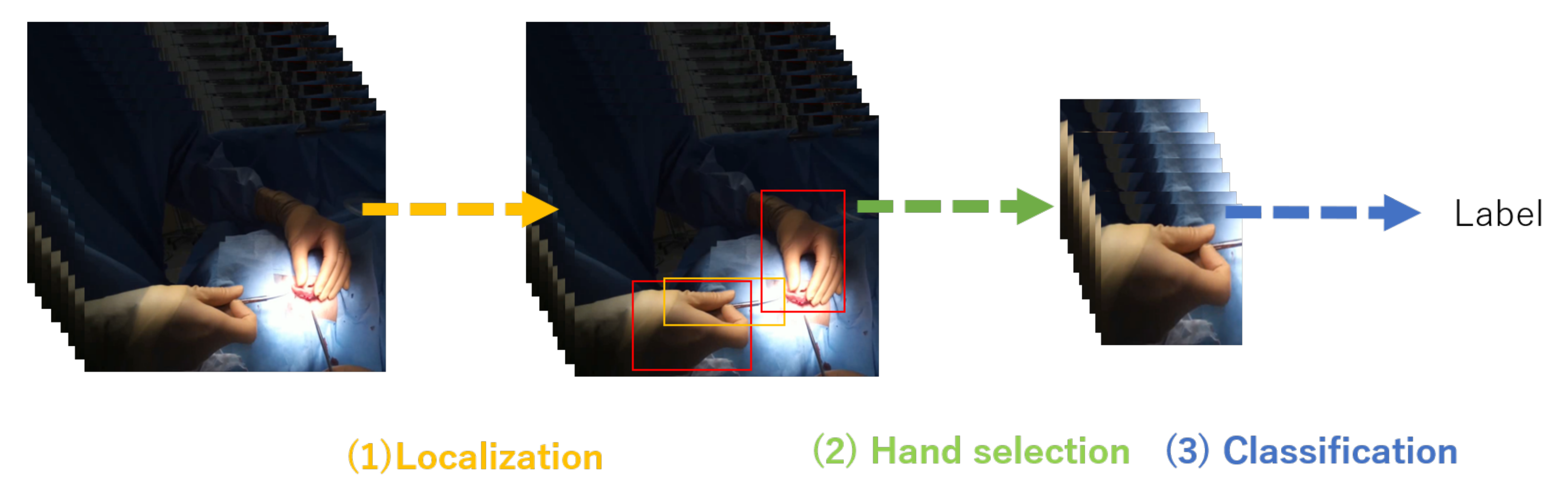
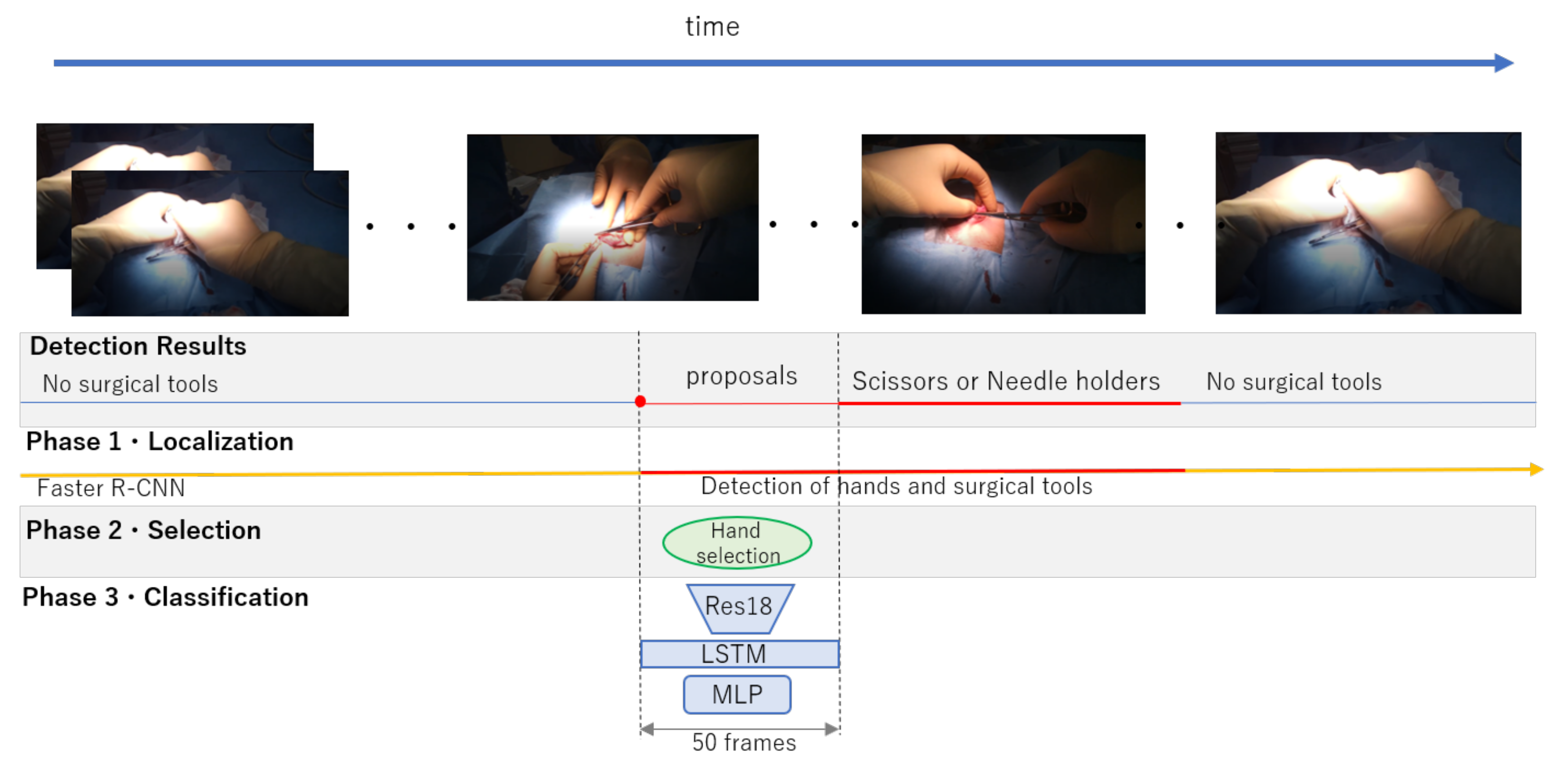
3. Proposed Framework for Surgical Tools Localization and Classification
3.1. Surgical Tool and Hand Localization
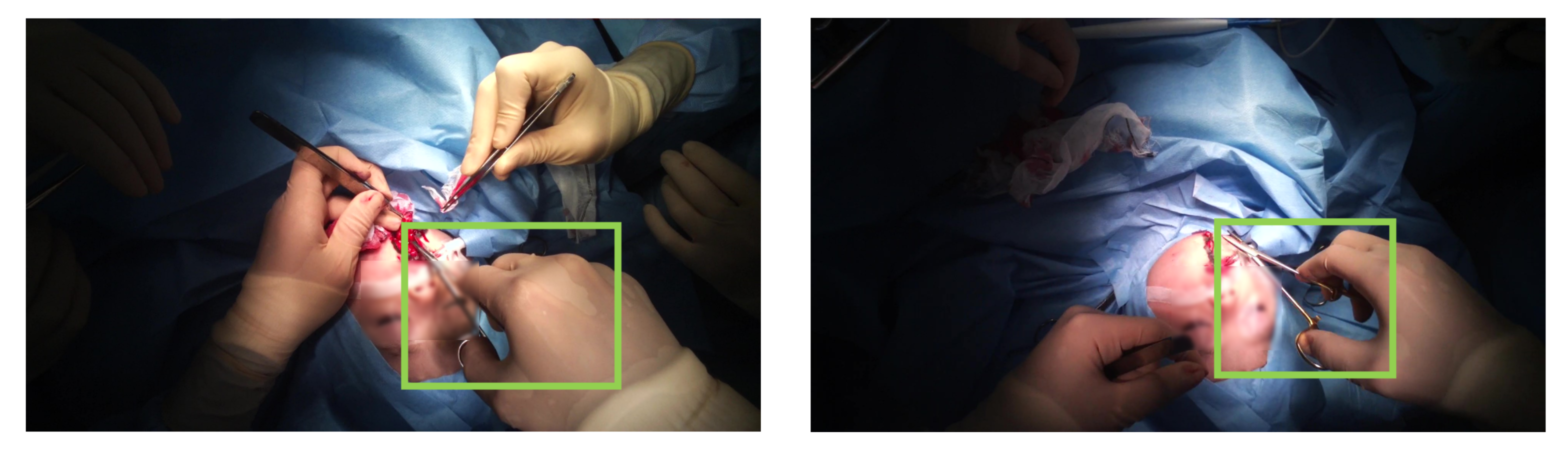
3.2. Target Hand Selection
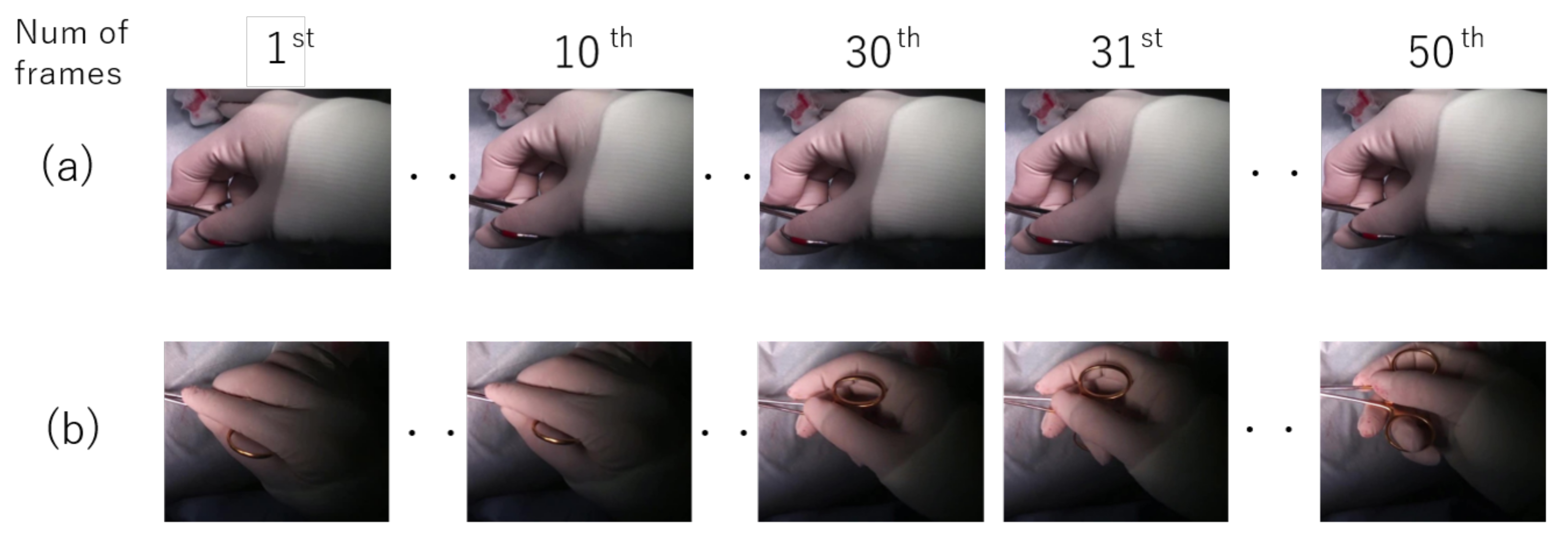
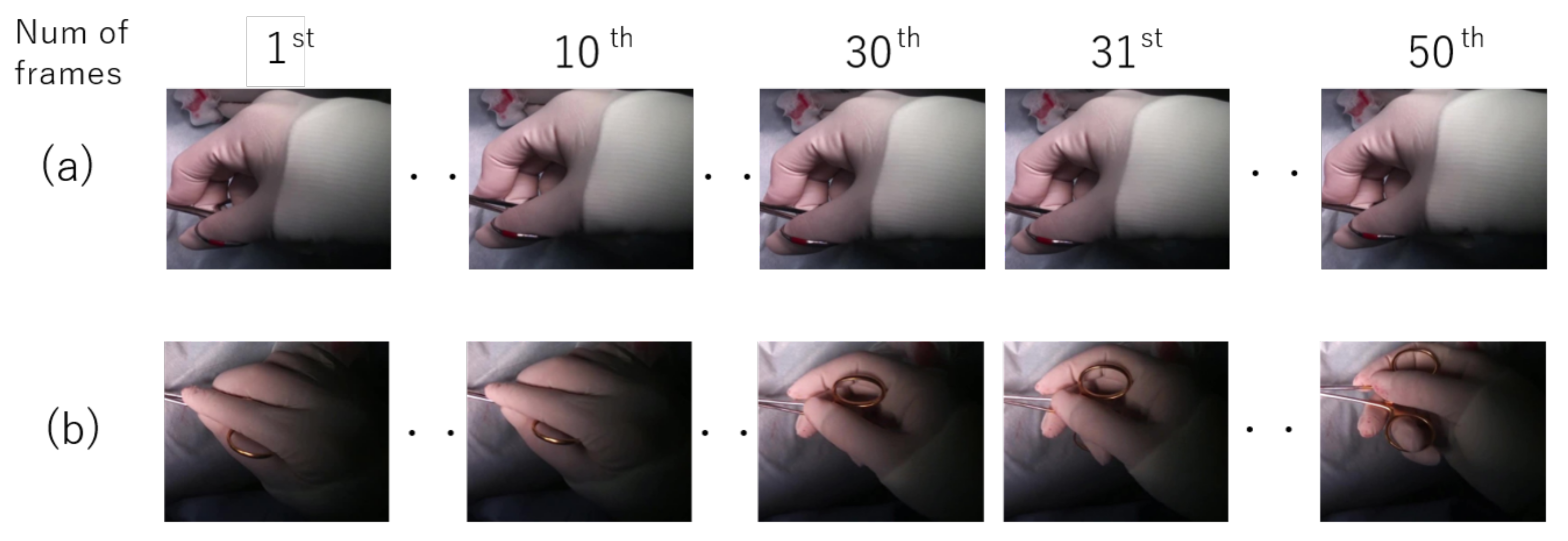
3.3. Surgical Tool Classification from Hand Motion
3.3.1. Network Architecture
3.3.2. Loss Function
4. Experiment
4.1. Dataset
4.2. Faster R-CNN Training
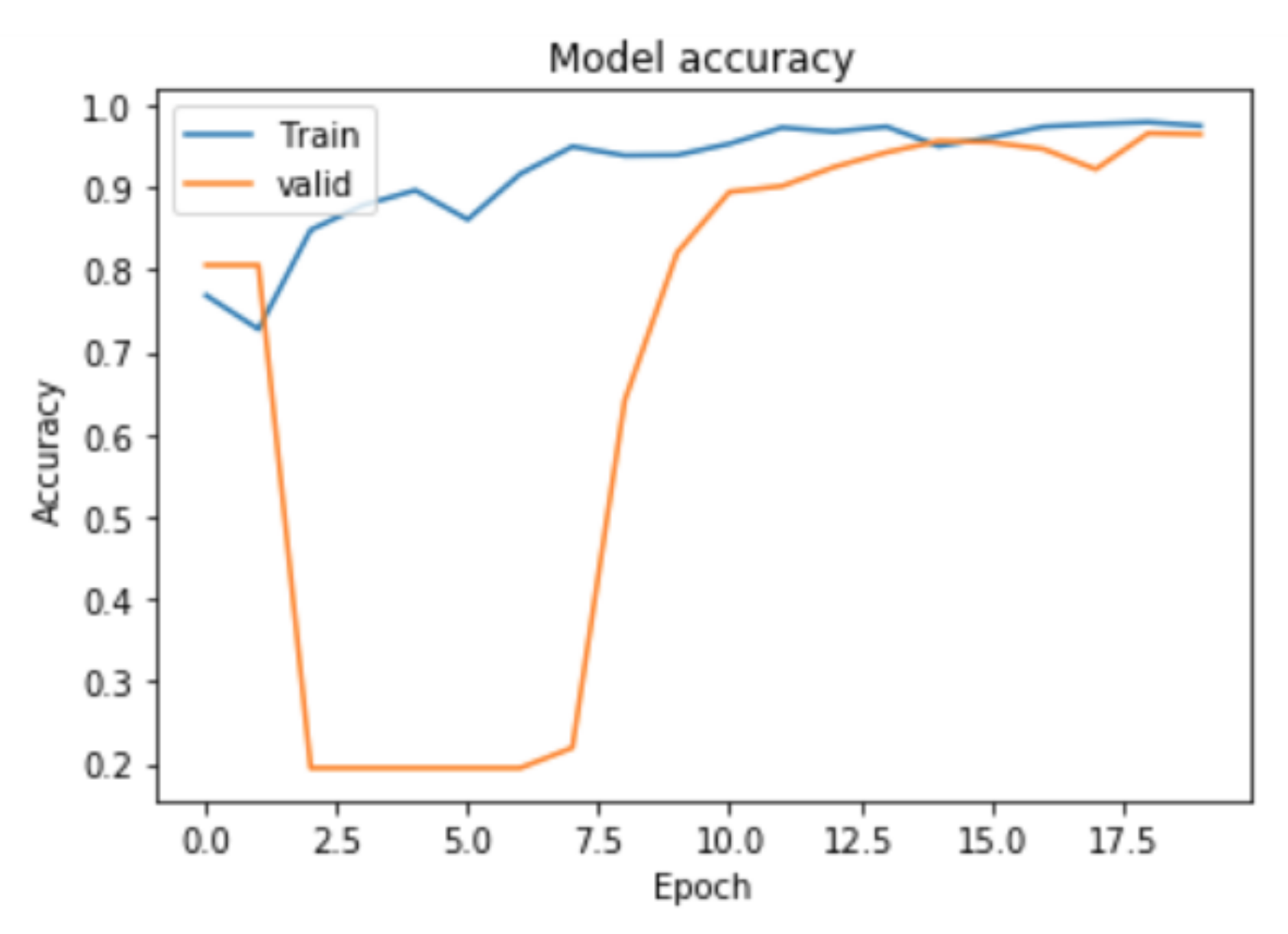
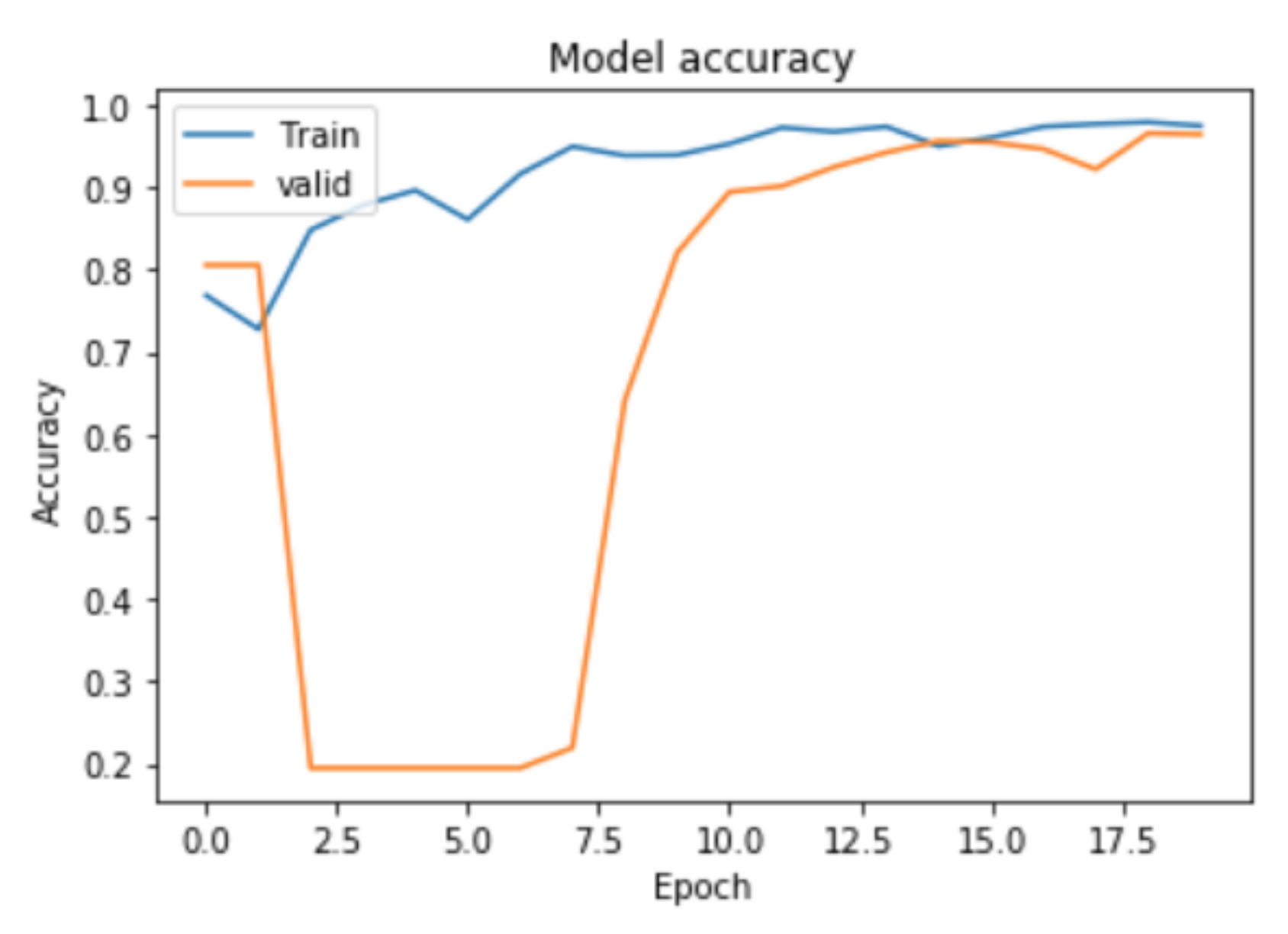
4.3. Network Training
4.4. Baseline
4.5. Procedure Lengths
5. Results and Discussion
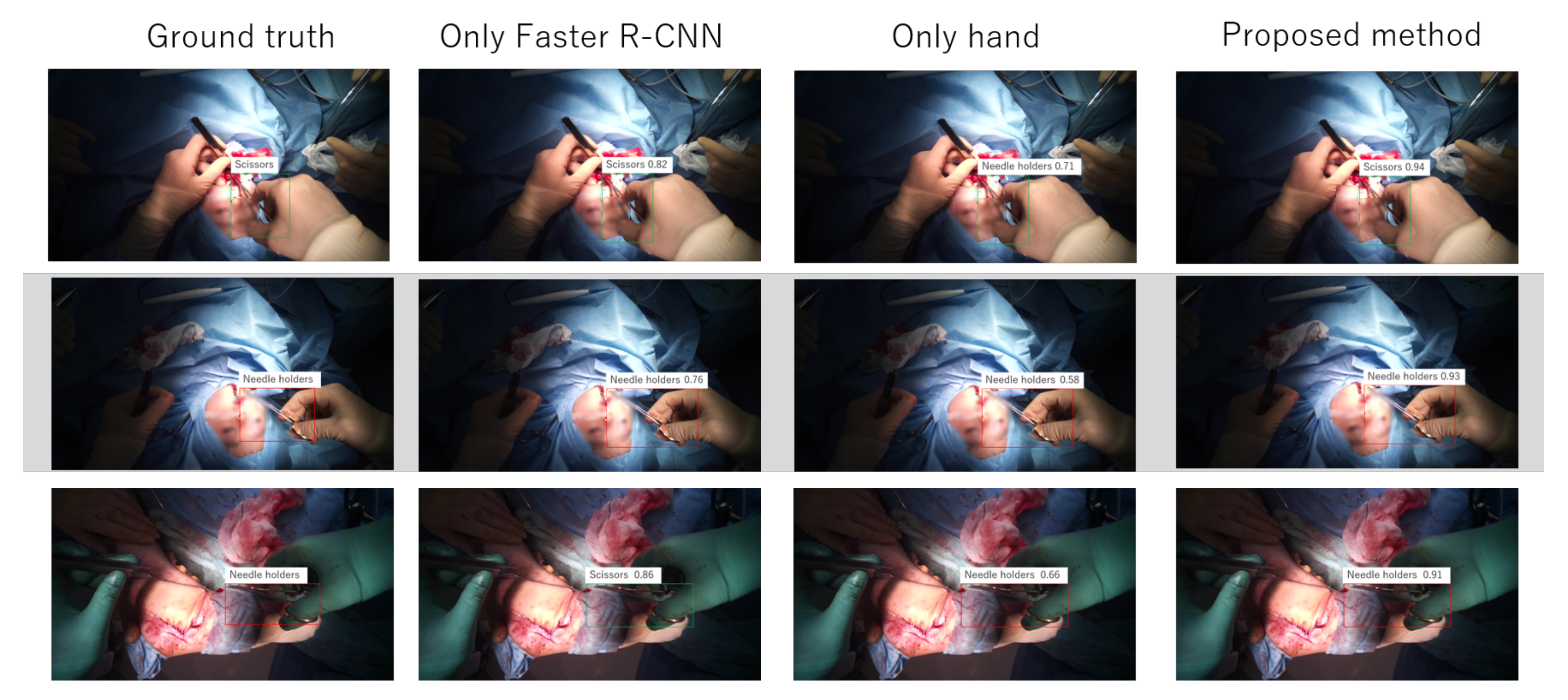
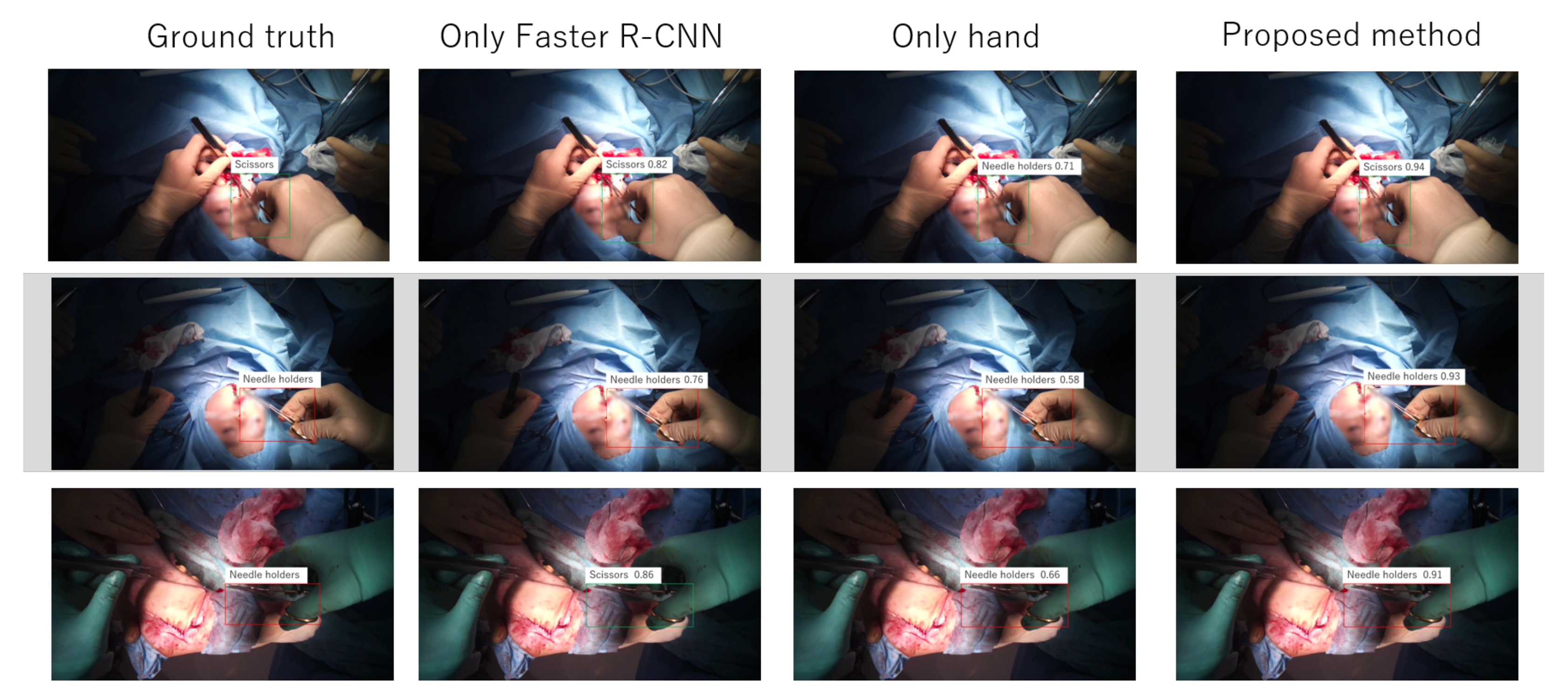
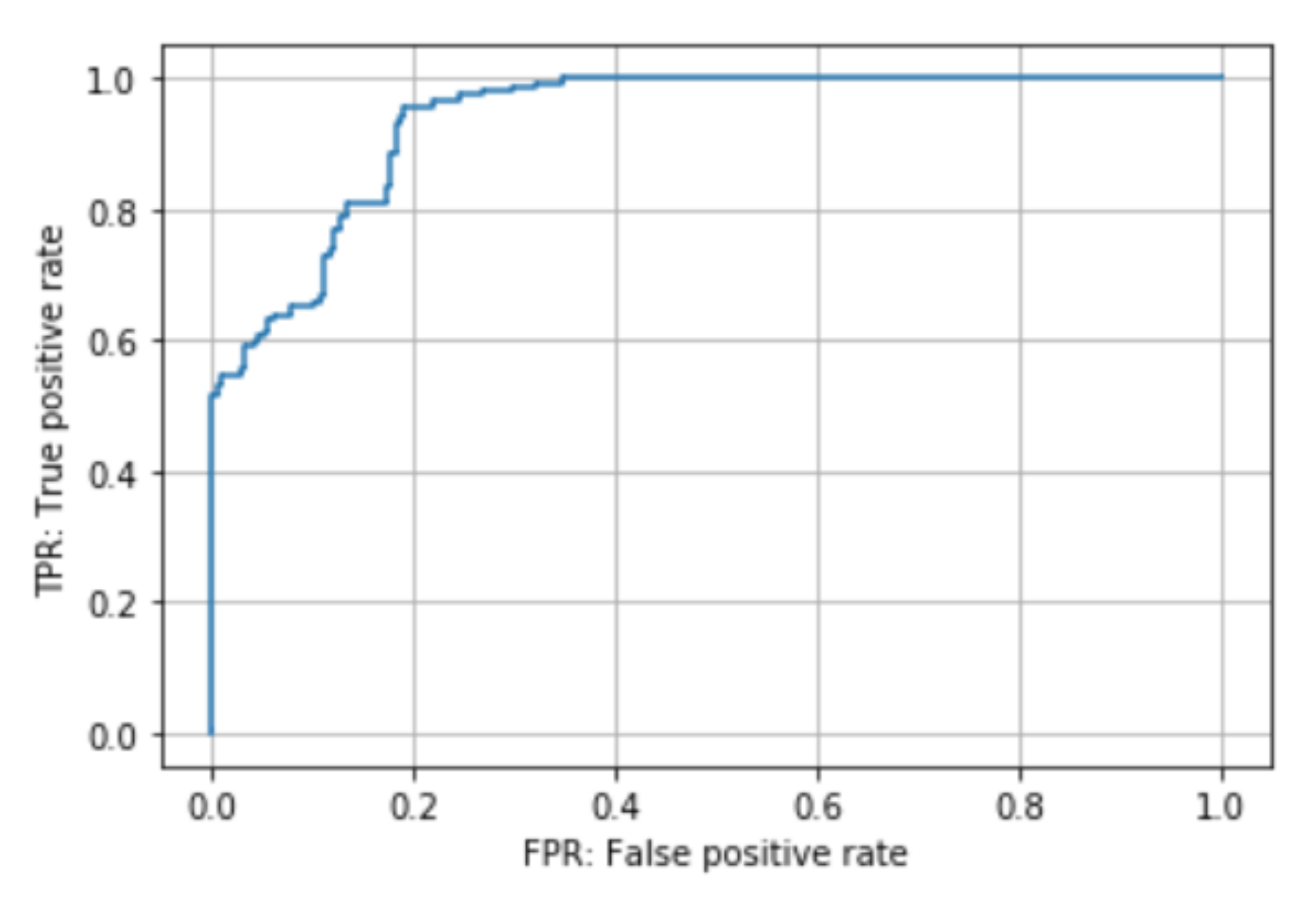
5.1. Localization and Selection Results
5.2. Proposed Method
5.3. Procedure Length
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matsumoto, S.; Sekine, K.; Yamazaki, M.; Funabiki, T.; Orita, T.; Shimizu, M.; Kitano, M. Digital video recording in trauma surgery using commercially available equipment. Scand. J. Trauma Resusc. Emerg. Med. 2013, 21, 27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadri, A.; Hunt, D.; Rhobaye, S.; Juma, A. Video recording of surgery to improve training in plastic surgery. J. Plast. Reconstr. Aesthetic Surg. 2013, 66, 122–123. [Google Scholar] [CrossRef]
- Graves, S.N.; Shenaq, D.S.; Langerman, A.J.; Song, D.H. Video capture of plastic surgery procedures using the GoPro HERO 3+. Plast. Reconstr. Surg. Glob. Open 2015, 3, e312. [Google Scholar] [CrossRef] [PubMed]
- Olsen, A. The Tobii I-VT Fixation Filter; Tobii Technology: Danderyd, Sweden, 2012; pp. 1–21. [Google Scholar]
- Li, Y.; Ye, Z.; Rehg, J.M. Delving Into Egocentric Actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines. arXiv 2020, arXiv:2005.00343. [Google Scholar] [CrossRef] [PubMed]
- Primus, M.J.; Putzgruber-Adamitsch, D.; Taschwer, M.; Münzer, B.; El-Shabrawi, Y.; Böszörmenyi, L.; Schoeffmann, K. Frame-based classification of operation phases in cataract surgery videos. In Proceedings of the International Conference on Multimedia Modeling, Bangkok, Thailand, 5–7 February 2018; pp. 241–253. [Google Scholar]
- Zisimopoulos, O.; Flouty, E.; Luengo, I.; Giataganas, P.; Nehme, J.; Chow, A.; Stoyanov, D. Deepphase: Surgical phase recognition in cataracts videos. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 265–272. [Google Scholar]
- Volkov, M.; Hashimoto, D.A.; Rosman, G.; Meireles, O.R.; Rus, D. Machine learning and coresets for automated real-time video segmentation of laparoscopic and robot-assisted surgery. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 754–759. [Google Scholar] [CrossRef]
- Jin, A.; Yeung, S.; Jopling, J.; Krause, J.; Azagury, D.; Milstein, A.; Fei-Fei, L. Tool detection and operative skill assessment in surgical videos using region-based convolutional neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 691–699. [Google Scholar]
- Liu, T.; Meng, Q.; Vlontzos, A.; Tan, J.; Rueckert, D.; Kainz, B. Ultrasound Video Summarization Using Deep Reinforcement Learning. In Medical Image Computing and Computer Assisted Intervention; Martel, A.L., Abolmaesumi, P., Stoyanov, D., Mateus, D., Zuluaga, M.A., Zhou, S.K., Racoceanu, D., Joskowicz, L., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 483–492. [Google Scholar]
- DiPietro, R.; Lea, C.; Malpani, A.; Ahmidi, N.; Vedula, S.S.; Lee, G.I.; Lee, M.R.; Hager, G.D. Recognizing Surgical Activities with Recurrent Neural Networks. arXiv 2016, arXiv:1606.06329. [Google Scholar]
- Lea, C.; Hager, G.D.; Vidal, R. An Improved Model for Segmentation and Recognition of Fine-Grained Activities with Application to Surgical Training Tasks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 6–9 January 2015; pp. 1123–1129. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Stauder, R.; Ostler, D.; Kranzfelder, M.; Koller, S.; Feußner, H.; Navab, N. The TUM LapChole dataset for the M2CAI 2016 workflow challenge. arXiv 2017, arXiv:1610.09278. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lee, K.; Kacorri, H. Hands holding clues for object recognition in teachable machines. In Proceedings of the Conference on Human Factors in Computing Systems, Scotland, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Ren, X.; Gu, C. Figure-ground segmentation improves handled object recognition in egocentric video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3137–3144. [Google Scholar] [CrossRef]
- Twinanda, A.P.; Shehata, S.; Mutter, D.; Marescaux, J.; De Mathelin, M.; Padoy, N. Endonet: A deep architecture for recognition tasks on laparoscopic videos. IEEE Trans. Med. Imaging 2016, 36, 86–97. [Google Scholar] [CrossRef] [Green Version]
- Schoeffmann, K.; Husslein, H.; Kletz, S.; Petscharnig, S.; Muenzer, B.; Beecks, C. Video retrieval in laparoscopic video recordings with dynamic content descriptors. Multimed. Tools Appl. 2018, 77, 16813–16832. [Google Scholar] [CrossRef] [Green Version]
- Al Hajj, H.; Lamard, M.; Conze, P.H.; Cochener, B.; Quellec, G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Med. Image Anal. 2018, 47, 203–218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colleoni, E.; Moccia, S.; Du, X.; De Momi, E.; Stoyanov, D. Deep learning based robotic tool detection and articulation estimation with spatio-temporal layers. IEEE Robot. Autom. Lett. 2019, 4, 2714–2721. [Google Scholar] [CrossRef] [Green Version]
- Du, X.; Kurmann, T.; Chang, P.L.; Allan, M.; Ourselin, S.; Sznitman, R.; Kelly, J.D.; Stoyanov, D. Articulated multi-instrument 2-D pose estimation using fully convolutional networks. IEEE Trans. Med. Imaging 2018, 37, 1276–1287. [Google Scholar] [CrossRef] [Green Version]
- Sarikaya, D.; Corso, J.J.; Guru, K.A. Detection and Localization of Robotic Tools in Robot-Assisted Surgery Videos Using Deep Neural Networks for Region Proposal and Detection. IEEE Trans. Med. Imaging 2017, 36, 1542–1549. [Google Scholar] [CrossRef]
- Wang, S.; Xu, Z.; Yan, C.; Huang, J. Graph Convolutional Nets for Tool Presence Detection in Surgical Videos. In Information Processing in Medical Imaging; Chung, A.C.S., Gee, J.C., Yushkevich, P.A., Bao, S., Eds.; Springer International Publishing: Cham, Swizterland, 2019; pp. 467–478. [Google Scholar]
- Marzullo, A.; Moccia, S.; Catellani, M.; Calimeri, F.; De Momi, E. Towards realistic laparoscopic image generation using image-domain translation. Comput. Methods Programs Biomed. 2020, 105834. [Google Scholar] [CrossRef]
- Bouget, D.; Benenson, R.; Omran, M.; Riffaud, L.; Schiele, B.; Jannin, P. Detecting Surgical Tools by Modelling Local Appearance and Global Shape. IEEE Trans. Med. Imaging 2015, 34, 2603–2617. [Google Scholar] [CrossRef] [PubMed]
- Voros, S.; Orvain, E.; Cinquin, P.; Long, J. Automatic detection of instruments in laparoscopic images: A first step towards high level command of robotized endoscopic holders. In Proceedings of the First IEEE/RAS-EMBS International Conference on Biomedical Robotics and Biomechatronics, Pisa, Italy, 20–22 February; 2006; pp. 1107–1112. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. Assoc. Comput. Mach. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Roychowdhury, S.; Bian, Z.; Vahdat, A.; Macready, W.G. Identification of Surgical Tools Using Deep Neural Networks; Technical Report; D-Wave Systems Inc.: Burnaby, BC, Canada, 2017. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Raju, A.; Wang, S.; Huang, J. M2CAI surgical tool detection challenge report. In Proceedings of the Workshop and Challenges on Modeling and Monitoring of Computer Assisted Intervention (M2CAI), Athens, Greece, 21 October 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cadene, R.; Robert, T.; Thome, N.; Cord, M. M2CAI workflow challenge: Convolutional neural networks with time smoothing and hidden markov model for video frames classification. arXiv 2016, arXiv:1610.05541. [Google Scholar]
- Mishra, K.; Sathish, R.; Sheet, D. Learning latent temporal connectionism of deep residual visual abstractions for identifying surgical tools in laparoscopy procedures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 58–65. [Google Scholar]
- Zhang, M.; Cheng, X.; Copeland, D.; Desai, A.; Guan, M.Y.; Brat, G.A.; Yeung, S. Using Computer Vision to Automate Hand Detection and Tracking of Surgeon Movements in Videos of Open Surgery. arXiv 2020, arXiv:2012.06948. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AP | |
|---|---|
| tools | 0.925 |
| hands | 0.713 |
| Method | Accuracy | Recall | Precision | F-Measure |
|---|---|---|---|---|
| target hand | 0.943 | 0.996 | 0.946 | 0.971 |
| Method | Accuracy | Recall | Precision | F-Measure |
|---|---|---|---|---|
| proposed method | 0.895 | 0.810 | 0.981 | 0.888 |
| only Faster R-CNN | 0.663 | 0.811 | 0.970 | 0.883 |
| only hand | 0.524 | 0.559 | 0.230 | 0.326 |
| Num of Frames | Accuracy | Recall | Precision | F-Measure |
|---|---|---|---|---|
| 25 | 0.728 | 0.956 | 0.703 | 0.810 |
| 50 | 0.895 | 0.810 | 0.981 | 0.888 |
| 100 | 0.563 | 0.903 | 0.500 | 0.644 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shimizu, T.; Hachiuma, R.; Kajita, H.; Takatsume, Y.; Saito, H. Hand Motion-Aware Surgical Tool Localization and Classification from an Egocentric Camera. J. Imaging 2021, 7, 15. https://doi.org/10.3390/jimaging7020015
Shimizu T, Hachiuma R, Kajita H, Takatsume Y, Saito H. Hand Motion-Aware Surgical Tool Localization and Classification from an Egocentric Camera. Journal of Imaging. 2021; 7(2):15. https://doi.org/10.3390/jimaging7020015
Chicago/Turabian StyleShimizu, Tomohiro, Ryo Hachiuma, Hiroki Kajita, Yoshifumi Takatsume, and Hideo Saito. 2021. "Hand Motion-Aware Surgical Tool Localization and Classification from an Egocentric Camera" Journal of Imaging 7, no. 2: 15. https://doi.org/10.3390/jimaging7020015
APA StyleShimizu, T., Hachiuma, R., Kajita, H., Takatsume, Y., & Saito, H. (2021). Hand Motion-Aware Surgical Tool Localization and Classification from an Egocentric Camera. Journal of Imaging, 7(2), 15. https://doi.org/10.3390/jimaging7020015