Abstract
This paper is concerned with the reconstruction of relaxation time distributions in Nuclear Magnetic Resonance (NMR) relaxometry. This is a large-scale and ill-posed inverse problem with many potential applications in biology, medicine, chemistry, and other disciplines. However, the large amount of data and the consequently long inversion times, together with the high sensitivity of the solution to the value of the regularization parameter, still represent a major issue in the applicability of the NMR relaxometry. We present a method for two-dimensional data inversion (2DNMR) which combines Truncated Singular Value Decomposition and Tikhonov regularization in order to accelerate the inversion time and to reduce the sensitivity to the value of the regularization parameter. The Discrete Picard condition is used to jointly select the SVD truncation and Tikhonov regularization parameters. We evaluate the performance of the proposed method on both simulated and real NMR measurements.
1. Introduction
Nuclear Magnetic Resonance (NMR) relaxometry has become an important tool to study the molecular structure and properties of materials. A typical NMR experiment consists of measuring the relaxation process due to the re-establishment of the nuclear system into its equilibrium state, after the application of a short magnetic pulse parameterized with a predefined flip angle. The relaxation process is described by longitudinal and transversal dynamics, characterized by distributions of longitudinal () and transversal () relaxation times [1]. The computation of the relaxation times distribution requires the numerical solution of a Fredholm integral equation with separable Laplace-type kernels. In particular, we focus on the inversion of 2D NMR relaxation data, acquired using a conventional Inversion-Recovery (IR) experiment detected by a Carr-Purcell-Meiboom-Gill (CPMG) pulse train [2]. Then, the evolution time in IR and the evolution time in CPMG are two independent variables, and the 2D NMR relaxation data can be expressed as:
where the unknown is the distribution of and relaxation times, represents Gaussian additive noise and , are Laplace-type kernels given by:
whose singular values quickly decay to zero. Since the unknown function F corresponds to distribution of the values of the relaxation times , we can assume for all and . Experimental data is usually collected at discrete values of times; therefore by considering samples of the times and , and samples of the relaxation times and , problem (1) is discretized as:
where , are the discretized exponential kernels, , , is the discrete vector of the measured noisy data (which can have negative values), , , is the vector reordering of the unknown distribution and is the vector with the discretized noise.
The inversion of (3) is severely ill-conditioned and several direct and iterative methods have been deeply discussed both in NMR [3,4,5] and mathematical [6,7,8] literature. Direct regularization includes Truncated Singular Value Decomposition (TSVD) and Tikhonov methods. TSVD replaces by a matrix of reduced rank thus avoiding noise amplification in the inversion procedure. This is usually obtained by removing the singular values smaller than a given tolerance . Tikhonov-like regularization substitutes (3) with a more stable optimization problem whose objective function includes a data-fitting term and a regularization term imposing some a priori knowledge about the solution. In NMR, Tikhonov-like regularization is usually employed. It requires the solution of a non-negative least squares (NNLS) problem of the form
where is the regularization parameter. In the sequel, will denote the Euclidean norm of a vector or the Frobenius norm of a matrix. It is well-known that controls the smoothness in and makes the inversion less ill-conditioned but, if wrongly chosen, it may cause a bias to the result. For this reason, many parameter selection techniques have been proposed such as Generalized Cross Validation (GCV), the L-curve and U-curve methods and methods based on the Discrepancy Principle (DP) (see [6] and references therein). In NMR, the Butler, Reed, and Dawson (BRD) method [9] or the S-curve method [10] are usually applied for the selection of the regularization parameter.
Another critical issue when solving NMR problems is that the amount of data collected for one measurement can be very large, with typical sizes –150 and –50,000. If a grid used for the estimated distribution has elements, then the matrix can have up to elements and the computational cost of the data inversion may be extremely high.
The separable kernel structure of has been widely exploited in the NMR literature to perform data compression using independent SVDs of and and reduce computational complexity. The method proposed in [4], in the sequel referred to as Venkataramanan–Song–Hürlimann (VSH) algorithm, is considered a reference method for NMR data inversion and it is widely used both in academia and industrial world. Given the TSVD of and :
where is the number of considered singular values, the VSH method approximates the original problem (4) with the better conditioned one
where . The data is then projected onto the column subspace of in order to obtain a NNLS problem with compressed data and kernel of significantly smaller dimensions. A method adapted from the BRD algorithm is then used to solve the optimization problem.
Other methods have been proposed in the literature for the inversion of 2DNMR data. The algorithm of Chouzenoux et al. [11] uses a primal-dual optimization strategy coupled with an iterative minimization in order to jointly account for the non-negativity constraint in (4) and introduce a regularization term. A preconditioning strategy is used to reduce the computational cost of the algorithm. In [12], an algorithm for 2DNMR inversion from limited data is presented. Such algorithm uses compressive sensing-like techniques to fill in missing measurements and the resulting regularized minimization problem is solved using the method of [4]. The Discrete Picard Condition (DPC) [13] is used to choose the truncation parameters. The 2DUPEN algorithm [14] uses multiparameter Tikhonov regularization with automatic choice of the regularization parameters. Without any a-priori information about the noise norm, 2DUPEN automatically computes the locally adapted regularization parameters and the distribution of the unknown NMR parameters by using variable smoothing. In [15], an improvement of 2DUPEN (I2DUPEN), obtained by applying data windowing and SVD filtering, is presented. The SVD filtering is applied to reduce the problem size as in [4].
Since the matrices and have typically small sizes, it is possible to compute the exact SVD of by exploiting its Kronecker product structure. In fact, if is the SVD of , then
However, the TSVD of cannot be computed as a Kronecker product. For this reason, different approximation of the TSVD can be found in the literature such as the matrix of the VSH method or the randomized SVD (RSVD) [16,17] where randomized algorithms are used to approximate the dominant singular values of . In this work, we show that it is possible to compute the exact TSVD of efficiently, avoiding approximations and suitably using properties of the Kronecker product structure. Let be the TSVD of where k is the number of considered singular values; we propose to solve the following Tikhonov-like problem:
Moreover, we propose and test an automatic rule, based on the DPC, for the automatic selection of both the TSVD truncation index and the Tikhonov parameter. Finally, we analyze the filtering properties of our method compared to TSVD, Tikhonov and VSH methods. Therefore, our approach can be consideredt o be a hybrid inversion method that combines TSVD and Tikhonov regularization: Tikhonov regularization prevents from discontinuities and artificial peaks and TSVD acts as a preconditioning strategy and reduces the computational cost. Actually, other approaches do exist in the literature combining RTSVD and Tikhonov regularization [16,17]. Such techniques apply randomized algorithms to reduce large-scale problems to much smaller-scale ones and find a regularized solution by applying some regularization method to the small-scale problems in combination with some parameter choice rule. The key point of these randomized algorithms is that the SVD of the original linear operator is never computed.
Concerning the solution of (8), in the present paper we apply the Newton Projection (NP) method [18] where the Conjugate Gradient (CG) method is used to solve the inner linear systems. This technique guarantees the desired high accuracy and it has been successfully applied in the NMR context [14,15]. Gradient projection methods with acceleration techniques such those discussed in [19] required more computational effort to solve (8) with the required accuracy. However, the typical sparse structure of the solution, represented by nonzero peaks over flat regions, could possibly be taken into account in solving (8), for example by adding penalties [20].
Summarizing, the contribution of this paper is twofold; first, the paper shows that times distribution of improved quality can be obtained by using instead of the separate TSVDs of and without a significant increase in the computational complexity. In fact, the computational cost of our approach is slightly greater than the cost of VSH and considerably smaller than the cost of RSVD. Second, the paper describes an efficient method for jointly selecting the SVD truncation index k and the Tikhonov regularization parameter and for solving the NMR data inversion problem.
The remainder of this paper is organized as follows. In Section 2 we introduce our method and, in Section 3, we analyze its filtering properties. In Section 4, we provide implementation details and discuss numerical results. Some conclusions are reported in Section 5. Finally, the VSH method is described in Appendix C.
2. The Proposed Hybrid Algorithm
In this section we illustrate the details of our approach and formalize our proposed Hybrid Algorithm 1. We first propose to approximate problem (4) with
where is the TSVD of . By projecting the data vector onto the column subspace of and by neglecting constant terms, we obtain the equivalent formulation:
which can be written as:
with compressed data and kernel . We observe that the solution of (11) lies in a subspace of the column space of . In the following paragraphs we develop the solution steps of problem (11), the rule for the choice of the TSVD truncation index k, and of the Tikhonov parameter . Finally, we illustrate the filtering properties of our new method and compare it to Tikhonov, TSVD and VSH methods.
2.1. Solution of the Minimization Problem
We use the Newton Projection (NP) method [18] to solve the constrained minimization problem (11); for a detailed description of NP we refer the reader to Appendix B. We apply the Conjugate Gradient (CG) method to solve the inner linear systems. To this purpose, it is necessary to perform several matrix-vector products involving the matrices and . Although and are parts of the matrices and , they do not inherit the Kronecker product structure. However, we can show that matrix-vector products can be performed efficiently by exploiting the structure of and .
Given a vector , let be the vector obtained by zeroing the last components of :
Using the Kronecker products property:
From Equation (7) we have
and
where is the matrix of the measured data s.t. and represents the computed distribution s.t. . Thus, matrix-vector products involving and can be efficiently performed by using the Kronecker product structure of and and by setting to zero the last components of the resulting vector.
2.2. Choice of the Parameters k and
The quality of the restored distribution strongly depends on the values of both the truncation parameter k and the Tikhonov parameter . We propose to choose both these values by using the Discrete Picard Condition (DPC) [6]. This condition, for ill-conditioned inverse problems, guarantees that a good solution is obtained by keeping in the SVD expansion for the solution only the coefficients such that the Fourier coefficients decrease on average faster than the singular values . A truncation parameter k satisfying the DPC can be selected by visual inspection of the so-called Picard plot (i.e., a plot of the quantities and versus i). Alternatively, an index k satisfying the DPC can also be selected by using automatic techniques such as those described in [21,22].
Once the value for k has been fixed by using the DPC, the value for is set as
since, as explained in [6], the value represents the breakpoint at which the ith filter factor changes nature for the Tikhonov method [6]. Therefore this choice is motivated by the low-pass filtering properties of both TSVD and Tikhonov methods.
Summarizing the previous considerations, we outline the steps of our proposed Hybrid Algorithm 1.
| Algorithm 1: Hybrid algorithm |
| 1: compute the SVDs of and |
| 2: compute |
| 3: choose k by using the DPC |
| 4: choose |
| 5: Apply the Newton projection method to solve the constrained problem
|
3. Analysis of the Filtering Properties
In this section we prove that our Hybrid algorithm acts as a low-pass filtering method, similarly to TSVD and Tikhonov methods, and we compare it to the filtering properties of VSH. Let us first report some basic properties of the solution of the NNLS problem:
Once defined the active set of by
we can define the diagonal matrix as
Then, using the relation , we obtain from (18)
which are the normal equations of the following LS problem
The following result characterises the minimum norm solution of (22).
Theorem 1.
To prove this result, we first need the following lemma whose proof is given, for the reader’s convenience, in Appendix A.
Lemma 1.
Letbe the SVD ofand letbe the diagonal matrix defined in (20). Then, the pseudo-inverse ofis given by
We are now in the position to prove Theorem 1.
Proof.
Theorem 1 shows that the solution of the constrained problem (17) can be written in terms of the SVD of matrix as follows:
Obviously, the vectors may be linear dependent if lies in a subspace of . It is well known that TSVD and Tikhonov methods both compute a filtered solution of problem (22) with different filter functions [6]. Using the result of Theorem 1, we can express the nonnegatively constrained TSVD solution as
where is the diagonal matrix (20) and the filter factors are
Analogously, the non negative Tikhonov solution is given by
where is the diagonal matrix (20) defined with respect to the active set of a local solution of (4) and the filter factors are
Equations (25) and (27) define a low-pass filter with vectors . The solution provided by the hybrid method is still a filtered solution whose filter factors depend on two parameters; i.e.,
where is the diagonal matrix (20) defined with respect to the active set of a local solution of (11) and the filter factors are
with and . By properly choosing the parameters k and , the filter factors for low-frequency components can be set close to one while filter factors for high-frequency components can be set close to zero. Figure 1 depicts the behaviour of the filter factors obtained for the value versus the singular values . The plotted on the abscissa axes are the singular values of the matrix of the experiment with simulated NMR data (see Section 4.3). We can observe that for singular values larger than the filter factors behave as (black dashdotted line) while for smaller values they are as (red dashed line).
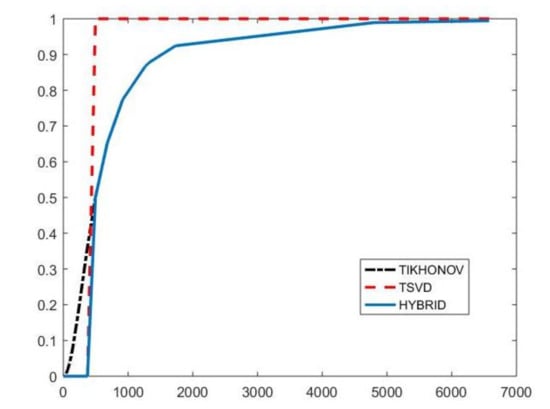
Figure 1.
The Hybrid (blue line), TSVD (red dashed line) and Tikhonov (black dashdotted line) filter factors versus for .
We observe that also the VSH solution can be expressed in terms of the SVD of (see algorithm details in Appendix C). We define the index subset including the indices of the singular values of which correspond to singular values of :
Thus, we have:
where is the diagonal matrix (20) defined with respect to the active set of a local solution of (6) and the filter factors are
with , and . However, it is almost impossible to determine values of the truncation parameters and such that the vectors for only correspond to low-frequency components including meaningful information about the unknown solution. An explanatory example will be further discussed in the numerical Section 4. For this reason, the VSH method cannot be considered a low-pass filtering method.
4. Numerical Results
In this section, we present some results obtained by our numerical tests with both simulated and real 2DNMR measurements. We have compared the proposed Hybrid method with the VSH method which is a reference method for 2DNMR data inversion. Moreover, in the case of real data, the UPEN method has been considered as a benchmark method. The considered methods have been implemented in Matlab R2018b on Windows 10 (64-bit edition), configured with Intel Core i5 3470 CPU running at 3.2GHz.
The relative error value, computed as , is used to measure the effectiveness of the compared methods, while the execution time in seconds is used to evaluate their efficiency (here, and respectively denote the exact and restored distributions). The reported values of the execution time are the mean over ten runs. Since both methods are iterative, in the following, we give some details about the implemented stopping criteria and parameters.
4.1. Hybrid Method
The NP method is used for the solution of problem (11); it is described in detail in the Appendix B. As initial iterate the constant distribution with values equal to one is chosen. The NP iterations have been stopped on the basis of the relative decrease in the objective function of (11); i.e., the method is arrested when an iterate has been determined such that
The inner linear system for the search direction computation is solved by the CG method with relative tolerance . The values and have been fixed in all the numerical experiments. A maximum of and iterations have been allowed for NP and CG, respectively.
4.2. VSH Method
The VSH method consists of three main steps. In the first step, the data is compressed using SVDs of the kernels; in the second step, the constrained optimization problem is transformed to an unconstrained one in a lower dimensional space, by using a method adapted from the BRD algorithm. In the third step, the optimal value of is selected by iteratively finding a solution with fit error similar to the known noise variance. The VSH method is described in detail in the Appendix C. Here we just report the values of the parameters required in our Matlab implementation of the VSH method.
Each iteration of the VSH method needs, for a fixed value of , the solution of a reduced-size optimization problem obtained from (6) by projecting the data onto the column subspace of . The Newton method is used for the subproblems solution; its iterations have been stopped on the basis of the relative decrease in the objective function. The values and have been fixed. The values and have been set for the CG method solving the inner linear system. The outer iterations of VSH have been terminated when two sufficiently close approximations of the unknown distribution have been determined or after a maximum of 100 iterations; the relative tolerance value has been set. As initial choice for the regularization parameter, the value has been chosen.
4.3. Simulated NMR Data
The considered simulated distribution , shown in Figure 2, is a mixture of three Gaussian functions located at given by , and ms with standard deviations , and ms. We have considered the Laplace-type kernels and of (2), we have sampled logarithmically between and 3, and linearly between and 1 with , . The 2D data have been obtained according to the 2D observation model (3) with , . A white Gaussian noise has been added to get a signal-to-noise ratio (SNR) equal to 23 dB. We remark that this environmental setting corresponds to a realistic – measurement.
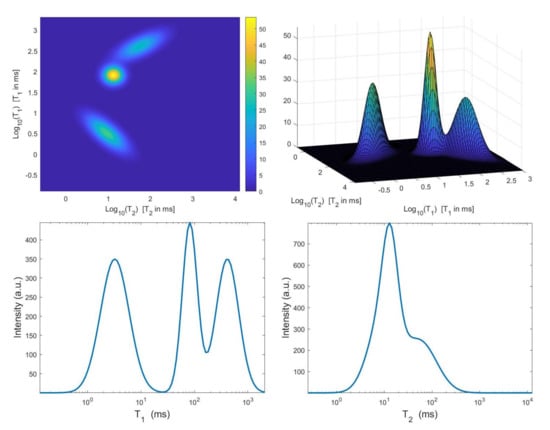
Figure 2.
Top: simulated – map and surface distribution. Bottom: projections along the and dimensions.
4.3.1. Models Comparison
We first compare the proposed hybrid inversion model (9) with the VSH model (6) and with classic Tikhonov model (4). Figure 3 depicts the singular values of , and . Clearly, the singular values of are obtained by reordering in non increasing order the diagonal elements of and they are different from the diagonal elements of . That is, some unwanted small singular values of may be included in , while some large singular values may be not considered. Figure 4 shows the singular values of the obtained for (blue line) and the singular values of for (blue dotted line), (black dashed line) and for (red dashdotted line). Observe that the singular values of are always different from those of . Considering the threshold value , we have that the number of singular values of is larger than that of , given by . Comparing, in Figure 4, the blue line and the black dashed one (obtained for ), we observe that the singular values of include a few elements smaller than , and miss some larger terms that should be included. Moreover, if , we have that the number of singular values of is which is closer to but there are many singular values smaller than . Finally, in the case , has only a few large singular values () and many relevant solution coefficients are missing. The plots in Figure 4 indicate that, when considering problem (6), it is highly probable to include in the solution also those components dominated by noise (if is slightly too small) or to discard those components dominated by the contributions from the exact right-hand side (if is too large).
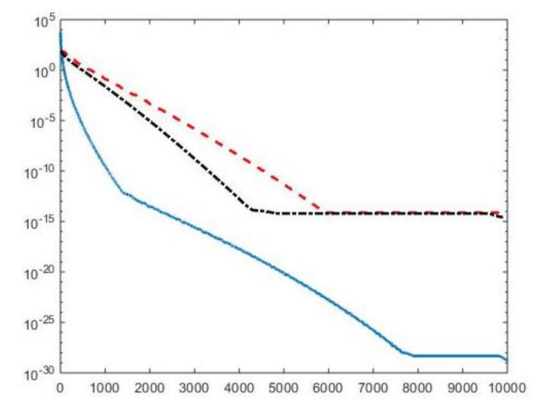
Figure 3.
The singular values of (blue line), (red dashed line) and (black dashdotted line). For easier visualization, the singular values of and are plotted versus the integers .
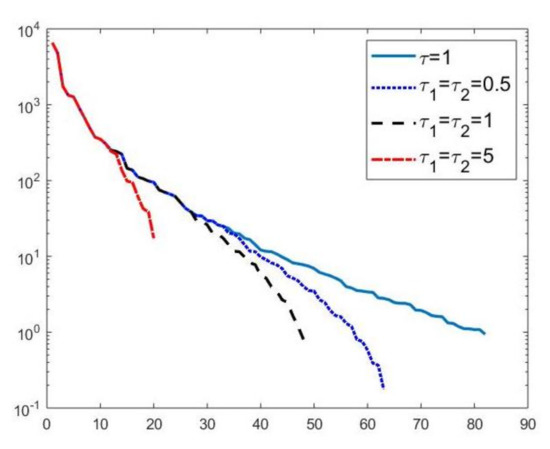
Figure 4.
Singular values of obtained for (blue line) and the singular values of for (blue dotted line), (black dashed line) and for (red dashdotted line).
A visual inspection of the Picard plot (Figure 5) indicates, for the hybrid method, the choice for the truncation tolerance giving the value of the truncation parameter. The previous considerations suggest to choose the values for the VSH method.
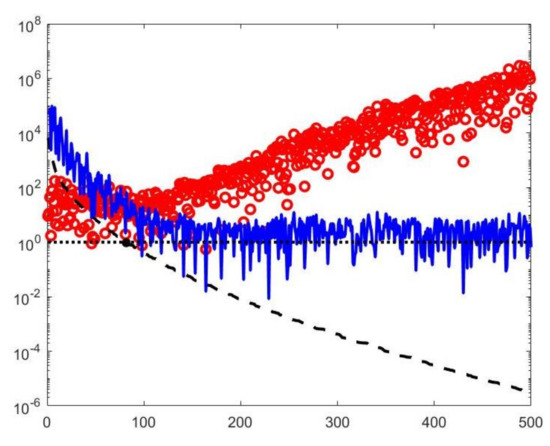
Figure 5.
The Picard plot for the simulated NMR data. Singular values (black dashed line), Fourier coefficients (blue continuous line) and solution coefficients (red circles) for .
Once defined the projection subspaces for VSH and Hybrid methods, we solve the optimization problems (6) and (11) by applying the same numerical solver (Newton Projection method NP) and changing the values of the regularization parameters . In this way we want to investigate how the different subspace selections affect the solutions computed by the (6) and (11) models for different values of . Moreover, we apply the Tikhonov method (4) in which no subspace projection is applied. For this reason, we use NP to solve all the different optimization problems, since we aim at comparing the three different models for data inversion, independently from the numerical method used for their solution.
For each model and for ten values of , logarithmically distributed between and , Table 1 reports the relative error values (columns labeled Err), the number of NP iterations (columns labeled It), and the time in seconds required for solving the three inversion models (columns labeled Time). The numerical results of Table 1 are summarized in Figure 6 where the relative error behaviour (on the left) and the computational time in seconds (on the right) are shown versus the regularization parameter values. Figure 7 shows the distributions estimated from the three models, for (left column), (middle column) and (right column). Figure 8 and Figure 9 report the corresponding projections along the and dimensions. Figure 7, Figure 8 and Figure 9 shows the importance of the proper choice of the subspace where the computed solution is represented. Indeed, the distribution computed by our method lies in a subspace of the column space of while the distribution determined by the VSH method belongs to a subspace of the space spanned by the column vectors of .

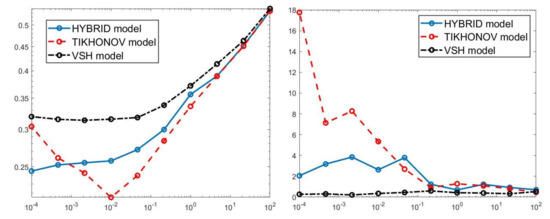
Figure 6.
Relative error behaviour (left) and the computational time in seconds (right) versus the regularization parameter values.
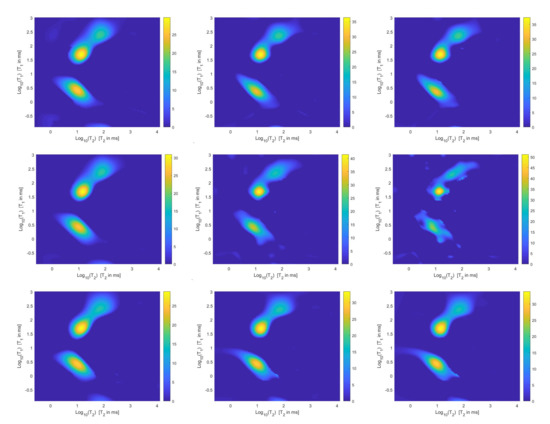
Figure 7.
Estimated distributions from the Hybrid (top row), Tikhonov (middle row) and VSH (bottom row) models for (left column), (middle column) and (right column).
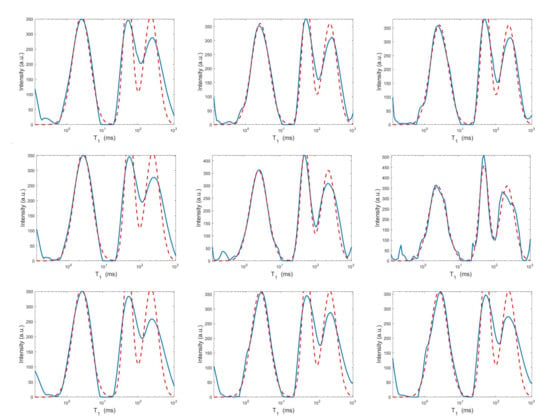
Figure 8.
Projections along the dimension from the Hybrid (top row), Tikhonov (middle row) and VSH (bottom row) models for (left column), (middle column) and (right column). The red dashed and blue continuous lines respectively represent the exact projections and the computed ones.
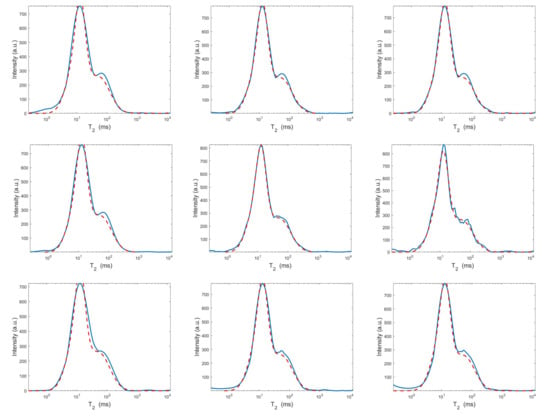
Figure 9.
Projections along the dimension from the Hybrid (top row), Tikhonov (middle row) and VSH (bottom row) models for (left column), (middle column) and (right column). The red dashed and blue continuous lines respectively represent the exact projections and the computed ones.
The results of Table 1 and the plot of Figure 6 and Figure 7 show that the Hybrid model (9) is less sensitive to small values of than the Tikhonov one, because the matrix is better conditioned than . When the value of is properly chosen the quality of distributions given by these two models is comparable, but the solution of (9) requires less computational effort. Also the VSH model is less sensitive to small values of , because is better conditioned than . Its solution has the least computational cost but the computed distributions exhibit artifacts which are due to subspace where they are represented (see Figure 7, Figure 8 and Figure 9).
4.3.2. Methods Comparison
We now compare the Hybrid and VSH algorithms on the simulated NMR data. Table 2 reports the relative error values and the required time in seconds for several values of the truncation parameter (Here, ). Moreover, the table shows the computed value for the regularization parameter , the number of performed Newton (or Newton Projection) and CG iterations (columns labeled It N and It CG, respectively) and it reports, only for VSH, the number of outer iterations (column labeled It). The numerical results show that the VSH method has the lowest computational complexity while the Hybrid method gives the most accurate distributions. The execution time of the Hybrid method is very low, although VSH is less time consuming. Figure 10 and Figure 11 depict the best distributions estimated by the Hybrid and VSH methods, i.e.,: the distribution obtained with and , respectively. By visually comparing Figure 10 and Figure 11, we observe some spurious small oscillations in the VSH distribution both in the boundary and in the flat region, while the distribution computed by the Hybrid method is less affected by such artefacts.
Table 2.
Numerical results for the methods comparison on simulated NMR data.
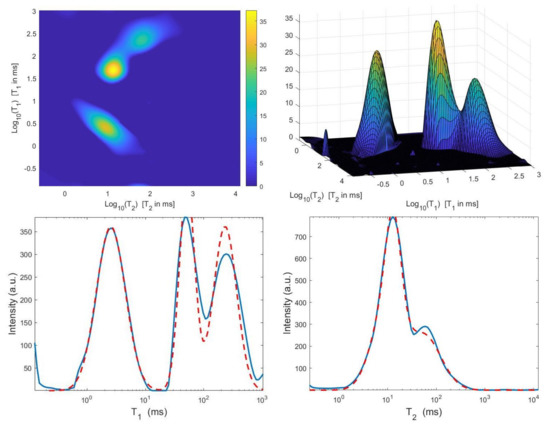
Figure 10.
Hybrid method: restored – distribution and projections along the T1 and T2 dimensions ().
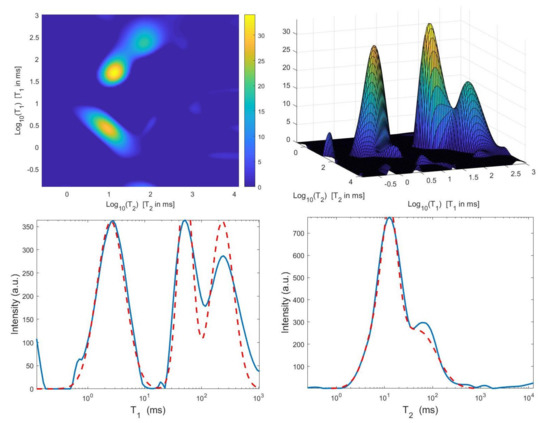
Figure 11.
VSH method: restored – distribution and projections along the T1 and T2 dimensions ().
4.4. Real NMR data
In this section we compare the Hybrid and VSH methods using real MR measurements obtained from the analysis of an egg yolk sample. The sample was prepared in NMR Laboratory at the Department of Physics and Astronomy of the University of Bologna, by filling a 10 mm external diameter glass NMR tube with 6 mm of egg yolk. The tube was sealed with Parafilm, and then at once measured. NMR measurements were performed at 25 °C by a homebuilt relaxometer based on a PC-NMR portable NMR console (Stelar, Mede, Italy) and a 0.47 T Joel electromagnet. All relaxation experimental curves were acquired using phase-cycling procedures. The pulse width was of 3.8µs and the relaxation delay (RD) was set to a value greater than 4 times the maximum of the sample. In all experiments RD was equal to 3.5 s. For the 2D measurements, longitudinal-transverse relaxation curve (-) was acquired by an IR-CPMG pulse sequence (RD----TE/2-[-TE/2-echo acquisition-TE/2]). The relaxation signal was acquired with 128 inversion times () chosen in geometrical progression from 1 ms up to 2.8 s, with (number of acquired echos, echo times µs) on each CPMG, and number of scans equal to 4. All curves were acquired using phase-cycling procedures.
The data acquisition step produces an ascii structured file (in the STELAR data format) including relaxation data in (3) where and , and the vectors ( inversion times), (CPMG echo times). The file is freely available upon email request to the authors. For the data inversion, in order to respect approximately the same ratio existing between and , we choose the values , and compute the vectors , in geometric progression in the ranges of predefined intervals obtained from the minimum and maximum values of the vectors respectively. Finally, using (2) we compute the matrices and .
We use the times distribution restored by the 2DUPEN method [14], shown in Figure 12 (top line), as benchmark distribution as the UPEN method uses multiparameter regularization and it is known to provide accurate results [3]. Obviously, 2DUPEN requires more computational effort since it involves the estimation of one regularization parameter for each pixel of the distribution.
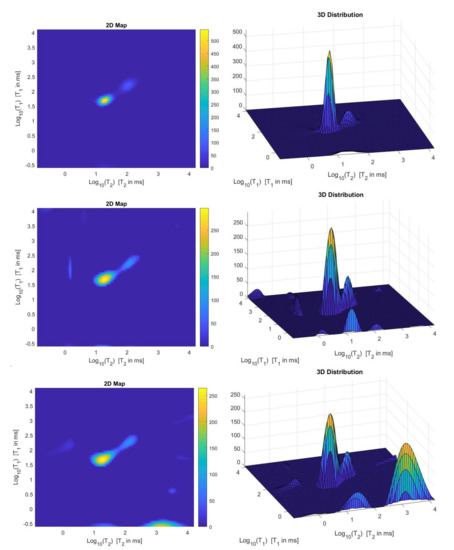
Figure 12.
From top to bottom: UPEN, Hybrid and VSH restored – maps (left) and surface distributions (right).
By visual inspection of the Picard plot (Figure 13) the value has been chosen for the hybrid method; the same value is fixed for the VSH method. Figure 13 shows the singular values of , and . For the VSH method, we report the results obtained at the first iteration since, in this case, they worsen as the iteration number increases. Table 3 reports the coordinates (in ) where a peak is located, its hight in a.u. (arbitrary unit) and the required computational time in seconds. Finally, Figure 12 and Figure 14 illustrate the distribution maps, the surfaces restored and the projections along the T1 and T2 dimensions; the results of the Hybrid method are more similar to those obtained by 2DUPEN, while the distribution provided by the VSH method seems to exhibits larger boundary artifacts.
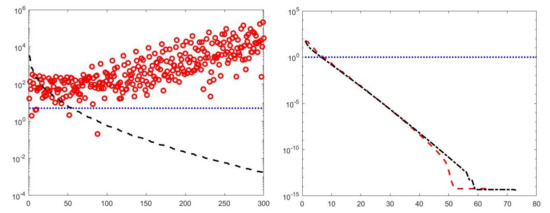
Figure 13.
Left: singular values (black dashed line) of and solution coefficients (red circles). Only the first 300 singular values are depicted. Right: Singular values of (red dashed line) and (black dashdotted line). The horizontal line corresponds to the value .
Table 3.
Location and height of the peak in the restored distribution and required execution time in seconds.
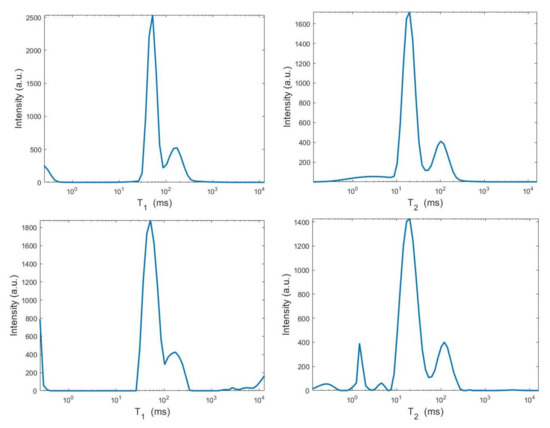
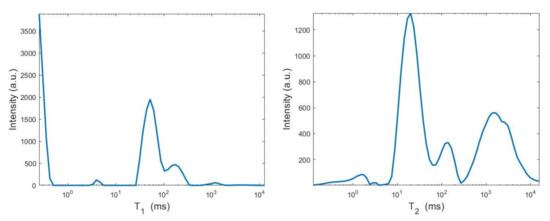
Figure 14.
From top to bottom: UPEN, Hybrid and VSH projections along the T1 (left) and T2 (right) dimensions.
5. Conclusions
In this paper, we have presented a hybrid approach to the inversion of 2DNMR measurements. This approach combines main features of Tikhonov and TSVD regularization in order to jointly select a suitable approximation subspace for the restored distribution and to reduce the computational cost of the inversion. The Picard condition is used to select, at the same time, the Tikhonov regularization parameter and the SVD truncation parameter. The numerical results show that the proposed hybrid method is effective, efficient and robust. In our future work, we intend to complement the presented hybrid approach in the 2DUPEN method.
Author Contributions
Conceptualization, G.L. and F.Z.; methodology, G.L. and F.Z.; software, G.L.; validation, G.L., F.Z. and V.B.; formal analysis, G.L. investigation, G.L. and F.Z.; resources, V.B.; data curation, V.B.; writing—original draft preparation, G.L., F.Z. and V.B.; writing—review and editing, F.Z. and V.B. All authors have read and agreed to the published version of the manuscript.
Funding
GNCS-INdAM.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
This work was partially supported by Gruppo Nazionale per il Calcolo Scientifico—Istituto Nazionale di Alta Matematica (GNCS-INdAM). We thank Leonardo Brizi of DIFA University of Bologna.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof.
(Lemma 1) The thesis is obtained if we verify that meets the four Moore-Penrose conditions which define the pseudo-inverse of as the unique matrix satisfying
- ;
- ;
- ;
- .
By substituting for and for in the first condition, we have:
since , , and . Analogously, we can prove the second condition:
We have that
The last condition follows analogously. □
Appendix B. The Newton Projection Method
Let us now denote by the objective function of (11):
and by the set of indices defined as [24]
where is a small positive parameter and denotes the projection on the positive orthant. Finally, let and denote the diagonal matrices [24] such that
The NPCG method for the minimization of under nonnegativity constraints is formally stated in Algorithm A1.
| Algorithm A1: NP (Newton-Projection) algorithm |
| 1: choose and set |
| 2: for do |
| 3: compute the index subset and the matrices and ; |
| 4: etermine the search direction by solving, with the CG method, the linear system
|
| 5: determine a step-length satisfying the Armijo rule along the projection arc [23]; |
| 6: compute ; |
| 7: end for |
Appendix C. The Venkataramanan-Song-Hürlimann Algorithm
Let be the SVD of , and let be the number of considered singular values; for example, can be the last index of the singular values than a given tolerance , . Given the TSVD matrices and of and , and defined their Kroenecker product :
problem (4) can be approximated as
or equivalently
The first step of the VSH algorithm consists of projecting the data onto the column subspace of :
that is
Hence, by neglecting constant terms, problem (A6) can now be equivalently rewritten as
which becomes
or, equivalently
where
This results in compressed data and kernels and of significantly smaller dimensions, thus avoiding large memory requirements and reducing computational effort.
The second step of VSH consists of solving the optimization problem (A9) for a specific value of . In [4], this is done by using a method adapted from the Butler-Reeds-Dawson (BRD) algorithm [9] which maps the constrained optimization problem (A9) onto an unconstrained one. Let us define a vector implicitly from by
is the Heaviside function and is the identity matrix. The Newton method is then used for solving problem (A12). The Conjugate Gradient (CG) method is employed for the solution of the inner linear system.
Once (A9) has been solved for a specific , the BRD method is used for updating the value of as
This procedure is sketched in Algorithm A2.
| Algorithm A2: VSH (Venkataramanan–Song–Hürlimann) algorithm |
| 1: choose and |
| 2: compute the TSVD of and |
| 3: compute the kernel and the projected data as in (A10) |
| 4: choose |
| 5: for do |
| 6: compute with the Newton method a solution to the unconstrained problem
|
| 7: compute |
| 8: update |
| 9: end for |
References
- Ernst, R.; Bodenhausen, G.; Wokaun, A. Principles of Nuclear Magnetic Resonance in One and Two Dimensions, 2nd ed.; International Series of Monographs on Chemistry; Oxford University Press: Oxford, NY, USA, 1997. [Google Scholar]
- Blümich, B. Essential NMR; Springer: Berlin, Germany, 2005. [Google Scholar]
- Borgia, G.; Brown, R.; Fantazzini, P. Uniform-Penalty Inversion of Multiexponential Decay Data. J. Magn. Reson. 1998, 132, 65–77. [Google Scholar] [CrossRef] [PubMed]
- Venkataramanan, L.; Song, Y.; Hurlimann, M. Solving Fredholm integrals of the first kind with tensor product structure in 2 and 2.5 dimensions. IEEE Trans. Signal Process. 2002, 50, 1017–1026. [Google Scholar] [CrossRef]
- Kroeker, R.; Henkelman, R. Analysis of biological NMR relaxation data with continuous distributions of relaxation times. J. Magn. Reson. 1986, 69, 218. [Google Scholar] [CrossRef]
- Hansen, P. Rank-Deficient and Discrete Ill-Posed Problems; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1998. [Google Scholar] [CrossRef]
- Engl, H.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems; Mathematics and Its Applications; Springer: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Eldèn, L. Algorithms for the regularization of ill-conditioned least squares problems. Behav. Inf. Technol. 1977, 17, 134–145. [Google Scholar] [CrossRef]
- Butler, J.; Reeds, J.; Dawson, S. Estimating solutions of the first kind integral equations with nonnegative constraints and optimal smoothing. SIAM J. Numer. Anal. 1981, 18, 381. [Google Scholar] [CrossRef]
- Fordham, E.; Sezginer, A.; Hall, L. Imaging multiexponential relaxation in the (y, logT1) plane, with application to clay filtration in rock cores. J. Magn. Reson. Ser. A 1995, 113, 139–150. [Google Scholar] [CrossRef]
- Chouzenoux, E.; Moussaoui, S.; Idier, J.; Mariette, F. Primal-Dual Interior Point Optimization for a Regularized Reconstruction of NMR Relaxation Time Distributions. In Proceedings of the 38th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 8747–8750. [Google Scholar]
- Cloninger, A.; Czaja, W.; Bai, R.; Basser, P. Solving 2D Fredholm Integral from Incomplete Measurements Using Compressive Sensing. SIAM J. Imaging Sci. 2014, 7, 1775–1798. [Google Scholar] [CrossRef]
- Hansen, P. The discrete Picard condition for discrete ill-posed problems. BIT Numer. Math. 1990, 30, 658–672. [Google Scholar] [CrossRef]
- Bortolotti, V.; Brown, R.; Fantazzini, P.; Landi, G.; Zama, F. Uniform Penalty inversion of two-dimensional NMR relaxation data. Inverse Probl. 2016, 33, 015003. [Google Scholar] [CrossRef]
- Bortolotti, V.; Brown, R.; Fantazzini, P.; Landi, G.; Zama, F. I2DUPEN: Improved 2DUPEN algorithm for inversion of two-dimensional NMR data. Microporous Mesoporous Mater. 2017, 269, 195–198. [Google Scholar] [CrossRef]
- Xiang, H.; Zou, J. Regularization with randomized SVD for large-scale discrete inverse problems. Inverse Probl. 2013, 29, 085008. [Google Scholar] [CrossRef]
- Xiang, H.; Zou, J. Randomized algorithms for large-scale inverse problems with general Tikhonov regularizations. Inverse Probl. 2015, 31, 085008. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Projected Newton method for optimization with simple constraints. SIAM J. Control Optim. 1982, 20, 221–246. [Google Scholar] [CrossRef]
- Bonettini, S.; Landi, G.; Loli Piccolomini, E.; Zanni, L. Scaling techniques for gradient projection-type methods in astronomical image deblurring. Int. J. Comput. Math. 2013, 90, 9–29. [Google Scholar] [CrossRef]
- Bortolotti, V.; Landi, G.; Zama, F. 2DNMR data inversion using locally adapted multi-penalty regularization. arXiv 2020, arXiv:math.NA/2007.01268. [Google Scholar]
- Levin, E.; Meltzer, A.Y. Estimation of the Regularization Parameter in Linear Discrete Ill-Posed Problems Using the Picard Parameter. SIAM J. Sci. Comput. 2017, 39, A2741–A2762. [Google Scholar] [CrossRef][Green Version]
- Landi, G.; Piccolomini, E.L.; Tomba, I. A stopping criterion for iterative regularization methods. Appl. Numer. Math. 2016, 106, 53–68. [Google Scholar] [CrossRef]
- Bertsekas, D. Nonlinear Programming, 2nd ed.; Athena Scientific: Nashua, NH, USA, 1999. [Google Scholar]
- Vogel, C.R. Computational Methods for Inverse Problems; SIAM: Philadelphia, PA, USA, 2002. [Google Scholar]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).