
A Review of Detection and Removal of Raindrops in Automotive Vision Systems


Abstract
:1. Introduction
2. Raindrop Detection and Rain Intensity Estimation
2.1. Near-Infrared Sensor Rain Detection
2.2. Camera-Based Rain Detection
2.3. HSV Camera-Based Rain Classifier
- Train three different classifiers (Sunny-Rainy, Sunny-Cloudy, and Cloudy-Rainy).
- Check if the test sample belongs to Sunny-Rainy class.
- If the sample is classified as Sunny, test it with the Sunny-Cloudy classifier.
- If the sample is classified as Rainy, pass it with the Cloudy-Rainy classifier, which classifies it as either Cloudy or Rainy.
- Else, test it with the Cloudy-Rainy classifier, which will classify it as either Cloudy or Rainy, as the final classification result.
2.4. Feature Histogram Rain Classifier
2.5. Intensity Gradient-Based Rain Classifier
- 1-
- Gradient and threshold images are compared and pixels’ strongest gradients are selected to create a strong gradient image.
- 2-
- Regions from the previous step are tested for size range, height-to-width ratio, and eccentricity. Regions that satisfy raindrop threshold ranges are picked as Potential raindrops.
- 3-
- Potential raindrops are tracked in the image series and the ones that are detected at least 6 times in 8 consecutive images are identified as raindrops.
- 4-
- The gradient amplitude image is calculated as a number between 0 (no rain) to 255 (very high density).
3. Adherent Raindrop Models
3.1. Eigendrops Model
- 1-
- A total of K rectangular sections, each surrounding one raindrop are selected from a windshield image.
- 2-
- Rescaling, reshaping, and normalizing processes are applied, to create a one-dimensional unit vector with zero mean:
- 3-
- A total of k randomly selected vectors is used to create the matrix
- 4-
- and its covariance matrix is calculated
- 5-
- Eigenvalues are calculated for the covariance matrix and the r largest ones are selected and their corresponding eigenvectors calculated , to create the Eigendrops subspace.
- 6-
- For testing, the Eigenvectors of potential raindrops are calculated and the ones with eigenvectors closest to the Eigendrops are identified as actual raindrops.
3.2. Declivity-Based Model
- 1-
- Gaussian filter is applied on the windshield image with rain, to eliminate noise.
- 2-
- Raindrops are selected from the image and declivity calculation is applied in the horizontal, vertical, and two diagonal directions (Figure 5c).
- 3-
- The declivity descriptor matrix is constructed from the amplitude and width of each raindrop (Figure 5d).
- 4-
- The descriptor is then used to check potential raindrops and identify real ones.
3.3. Raindrop (RIGSEC) Model
3.4. Realistic Waterdrops CGI Model
3.5. Bézier Curves Raindrop Model
4. Raindrop Removal Techniques for Surveillance Applications
4.1. Multiple Fixed-Camera Approach
- 1-
- Acquire two simultaneous images of the environment and use an algorithm to match the two images.
- 2-
- Apply image restoration and chromatic registration on the transformed image, to match the original image.
- 3-
- Take the absolute difference in intensity of the two images and assign the “potential raindrops” label to noise patches with an intensity difference greater than a preset threshold. Figure 11 shows the intensity variance for raindrop and background patches, both in a simple and rich texture environment and Table 1 is a truth table that explains the logic of determining raindrop and background regions.
- 4-
- Potential raindrops are analyzed to determine true raindrops according to the table below.
4.2. Pan-Tilt Camera Approach
4.3. Enhanced Pan-Tilt Camera Approach
4.4. Stereo-Vision Cameras Approach
- 1-
- Use normalized cross-correlation (NCC) similarity measure to match the images from both cameras. NCC value R is given by:
- 2-
- Then, one-on-one matching is applied to the remaining pixels, and the distance between best-matched pixels is used to calculate disparity map .
- 3-
- The disparity of the raindrop pixels on the windshield can be easily calculated by:
- 4-
- A pixel at () is considered a raindrop pixel if , where is a threshold.
- 5-
- The image inpainting algorithm described by Bertalmio et al. [32] was then used to recover rainy segments to form the two images.
4.5. Spatio-Temporal Trajectory Approach
- 1-
- A sequence of images is captured using a pan-tilt camera rotating at a fixed speed.
- 2-
- Radial distortion rectification, followed by projective transformation, is applied to the image set.
- 3-
- A shown in Figure 14, the captured images are stacked in chronological order, to form the spatiotemporal image I(u, v, t).
- 1-
- Cross-sectional image S(u, t) = I(u, v1, t) is taken of the image stack at level v1. As shown in Figure 15, trajectories of a stationary object in S(u, t) are straight lines whereas those of adherent noise are curves.
- 2-
- Median image M(u, t) is then generated which causes adherent noise to disappear, due to its small size compared to other image elements (Figure 15b).
- 3-
- 4-
- Judgment image H(u, t) that shows candidate noise regions is given by:
- 5-
- The trajectory of each noise candidate curve is tracked in u dimension (since v = v1) and is deemed noise region if the total pixels with H(u, t) = 1 is greater than a threshold Tn.
- 6-
- Steps 4–9 are repeated with new levels vi until the whole image space is covered. Rainy regions are generated from information gathered from all images generated.
5. Raindrop Removal Techniques in the Automotive Domain
5.1. Saliency Maps Approach
- 1-
- Color Saliency Map Generation
- A five-level Gaussian pyramid is created for each color channel (X, Y, and Z) of the image XYZ color map.
- The center-surround method is implemented between different scales. This produces six difference maps (0,2), (0,3) (0, 4), (1, 3), (1, 4) and (2, 4).
- An across-scale sum of the six different maps and over all three color-channels is then performed to create a color saliency map.
- 2-
- Texture Saliency Map Generation
- 3-
- Shape Saliency Map Generation
- 4-
- AdaBoost is used to create a raindrop saliency map, from the three different feature saliency maps. Small noise regions are then removed with the help of morphological operations, as shown in Figure 16.
5.2. Scene Segmentation Approach
5.3. Daytime Texture-Based and Nighttime Intensity-Thresholding Algorithms
- 1-
- An N × M image is divided into grid blocks B(u, v) and Sobel edge detector is used to calculate edge strength E(u, v) for each block.
- 2-
- B(u, v) is classified as a textured block if E(u, v) > TE, where TE is selected so that the road surface is classified as a non-textured block.
- 3-
- Is applied in an image I with two variance values, σ1 and σ2 (σ2 > σ1), resulting in two images, and .
- 4-
- The degree of blur is given by:
- , where is the edge strength for image , calculated using a Sobel edge detector.
- 5-
- A pixel (i, j) is chosen as a raindrop candidate as follows:
- In a non-textured block, if there exist one or more pixels (k, l), such that , where is a threshold, then (i, j) is a raindrop pixel candidate.
- In textured block, if there exist one or more pixels (k, l), such that , where is another threshold, then (i, j) is a raindrop pixel candidate.
- 6-
- The histogram of optical flow is finally measured over 15 frames of the potential raindrop pixels. If the histogram of optical flow is consistent, then it belongs to the background. If it has various directions, then the pixel belongs to a real raindrop.
- 1-
- Pixels representing light sources and neighboring areas can be estimated by simple binarization and eliminated from the detection process.
- 2-
- Differential image is generated from images in frames t and t − 1:where and are experimental thresholds. This step eliminates pixels that are too dark and defines them as candidate raindrop pixels the ones whose intensity did not change much ().
- 3-
- Integration image is created by adding the last m frames. This image is then and small regions are discarded since they are not likely to represent raindrops. The remaining regions represent adherent raindrops.
5.4. Background Subtraction and Watershed Algorithms
- 1-
- Segment the image into bright and dark regions and apply detection on the dark regions only. This is done by applying erosion of the image, followed by morphological reconstruction of the original image with the eroded one. and applying Ostu’s method [39] to segment the image into dark and bright regions.
- 2-
- To identify raindrop candidates, one of the two approaches are used:
- Background Subtraction: For each channel of the RGB image, a large Gaussian filter is applied to eliminate (mask) raindrops. The difference between filtered and original image is then taken which exposes the potential raindrop regions. Morphological operations are then applied and the masks from the three RGB channels are added to the mask in step 1 to produce the candidate raindrop regions.
- Watershed: Gaussian filtering is applied to the grayscale image then watershed is used to segment the image and extract potential raindrop regions.
- 3-
- Raindrop candidates are then compared with an ellipsoid model of similar size, and regions that do not match are eliminated.
- 4-
- Temporal information is used to eliminate regions that show up less than two times in the last three successive frames.
5.5. Blurriness-Based Approach
- 1-
- Image pixels that satisfy the following intensity inequality are chosen as potential rain pixels are extracted through segmentation, using three constraints on pixels intensity and noise region roundness:
- , where and are chosen to pick the brightest pixels, while reducing the intensity variations introduced by fast-moving objects in the background.
- 2-
- Smaller regions are combined with larger ones, using an 8-connectivity extractor. The resultant regions that pass the roundness test below are considered candidate raindrops: , where CC represents the tested noise region.
- 3-
- Contours of candidate raindrops are summed on two consecutive frames and subtracted from the candidate raindrop regions. The Canny filter is used to detect edges of the resultant regions, which now are considered raindrop regions.
5.6. Raindrop Detection Algorithm Using RIGSEC Model
5.7. Raindrop Detection Using Enhanced RIGSEC (fastRIGSEC) Model
- The original image is bandpass-filtered using the Difference of Gaussian algorithm (DOG).
- The resultant image was segmented and small segments were combined using a connected component algorithm.
- Eigenvalues are calculated and used to filter out non-raindrops, based on convexity ratio, dominant orientation, and aspect ratios of the potential raindrop blobs.
- To identify actual raindrops, the remaining candidates are compared to the artificially created raindrop, using two similarity metrics; intensity Correlation coefficient (CCintensity) and Correlation coefficient of their first derivative (CCgradient).
- 1-
- Define , a 6D vector that represents rotational and translational parameters between frames and :
- 2-
- The road plane is initially wrapped from frame to , using prior estimates of and bilinear interpolation.
- 3-
- 4-
- To refine the parameter set , a MAP solution of the equation below is required (N is the total number of frames):
- 5-
- After parameters are estimated, the multi-band blending process is used to reconstruct raindrop-covered areas of the image.
5.8. Raindrop Detection Using Extended Maximally Stable External Regions
- 1-
- Candidate raindrops are fitted to the nearest ellipse, using the least square method.
- 2-
- Ellipse orientation and long and short axes are measured and flattening values are calculated.
- 3-
- Raindrop candidates are identified as real raindrops if their flattening value satisfied:
- , where and are the lower and upper limits for true raindrop ellipsoid, respectively.
6. Neural Networks and Deep-Learning Techniques
6.1. Dirt and Rain Noise Removal
6.1.1. Overview
6.1.2. Network Architecture
6.1.3. Baseline Methods and Training
6.1.4 Experimental Results
- Synthetic dirt results showed that the proposed system and the MLP system outperformed the other three baseline methods. Testing with other types of sensitized noise, namely snow, and scratches on the image surface resulted in the system described by Eigen et al. producing near-zero PSNR (peak signal to noise ratio) which demonstrates that the system learned to remove dirt noise only.
- Real-life dirt results showed that the proposed system removed most dirt noise in the images, while the MLP left many more unremoved. The other three methods caused much degradation to non-dirt areas of the images. The proposed system failed to recognize large dirt noises and the ones that are out of shape, as well as dirt over areas that were not represented in the training set (e.g., bright orange cones).
- Synthesized rain that the proposed system outperformed the MLP system, in terms of removing more rain droplets and maintain non-rain areas of the image intact. The median filter needed to blur the image substantially before it was able to reduce raindrops.
- Real rain results showed that the proposed system successfully removed real raindrops from the captured images, but it started failing with the accumulation of water on the glass plate.
6.2 Attention GAN Raindrop Removal Algorithm
6.2.1. Overview
6.2.2. Network Architecture
- 1-
- Generative Network
- 2-
- Discriminative Network
6.2.3. Baseline Methods and Training
6.2.4. Experimental Results
- A: contextual autoencoder alone,
- A + D: autoencoder plus discriminator,
- A + AD: autoencoder plus attentive discriminator.
6.3. Joint Shape-Channel Attention GAN Raindrop Removal Algorithm
6.3.1. Overview
6.3.2. Network Architecture
6.3.3. Baseline Methods and Training
6.3.4. Experimental Results
6.4. Improved Raindrop Removal with Synthetic Raindrop Supervised Learning
6.4.1. Overview
6.4.2. Network Architecture
- (a)
- Raindrop Detection Network
- (b)
- Raindrop Region Reconstruction Network
- (c)
- Refine Network
6.4.3. Baseline Methods and Training
6.4.4. Experimental Results
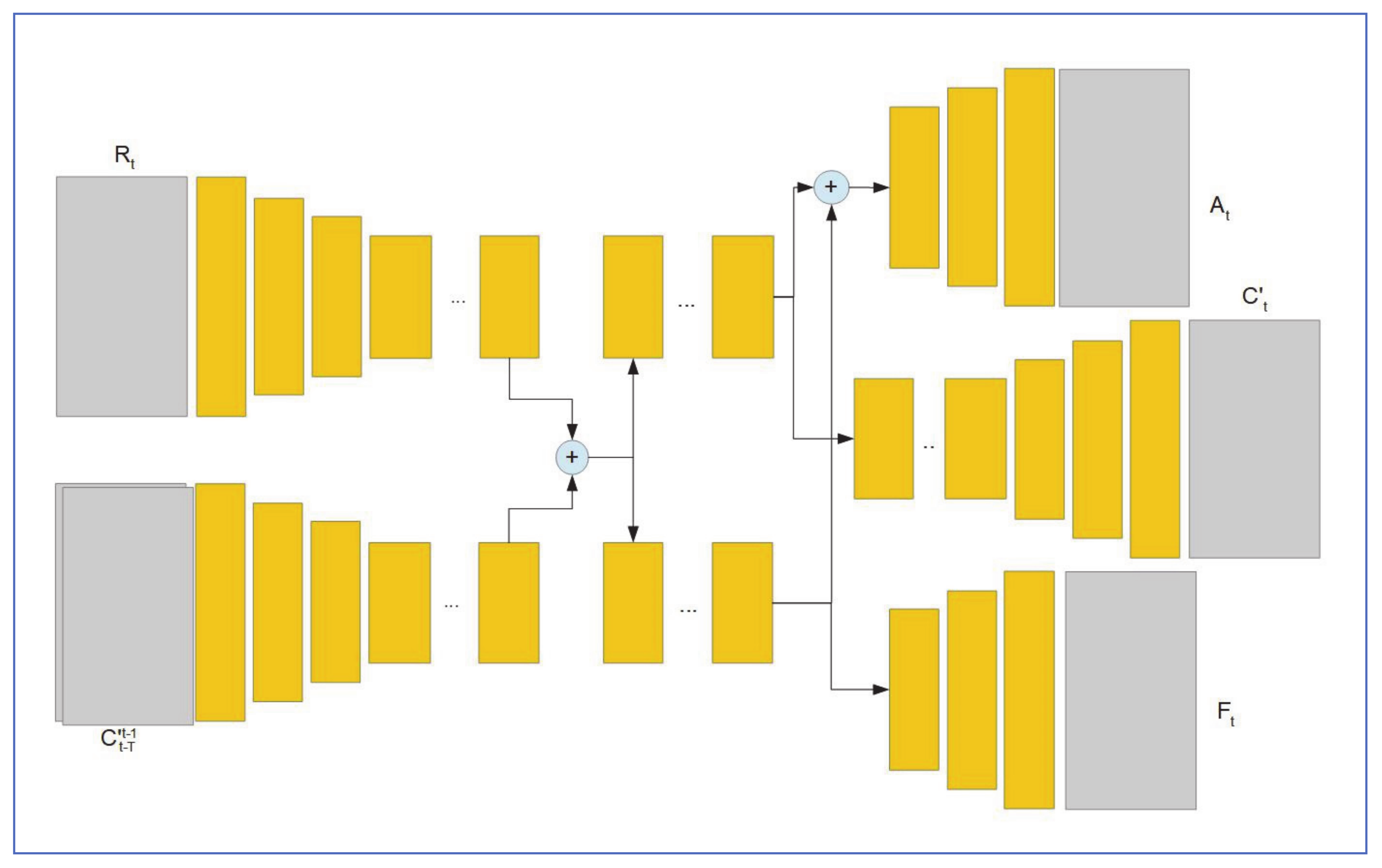
6.5. Raindrop-Aware GAN for Coastal Video Enhancement
6.5.1. Overview
6.5.2. Network Architecture
- (a)
- Scene Generator
- (b) The Discriminator
6.5.3. Baseline Methods and Training
6.5.4. Experimental Results
6.6. Self-Supervised Attention Maps with Spatio-Temporal GAN
6.6.1. Overview
6.6.2. Network Architecture
- (a)
- Single-Image Removal
- (b) Spatio-Temporal Raindrop Removal
6.6.3. Baseline Methods and Training
6.6.4. Experimental Results
6.7. Concurrent Channel-Spatial Attention and Long-Short Skip Connections
6.7.1. Overview
6.7.2. Network Architecture
- (a)
- Overview
- (b)
- Channel Attention
- (c)
- Spatial Attention
- (d)
- Concurrent Attention
6.7.3. Baseline Methods and Training
6.7.4. Experimental Results
6.8. Separation-Restoration-Fusion Network for Image Raindrop Removal
6.8.1. Overview
6.8.2. Network Architecture
- (a)
- Region Separation Module
- (b)
- Region Restoration Module
- (c)
- Region Fusion Module
6.8.3. Baseline Methods and Training
6.8.4. Experimental Results
7. Summary
8. Conclusions
- 1-
- Adherent raindrop detection and removal is a more challenging problem than falling rain detection and removal, due to the persistence of adherent raindrops over many image frames and the irregularity of raindrop shapes and sizes.
- 2-
- Due to the closeness to the image plane, adherent raindrops look blurry and occlude larger areas of the captured image.
- 3-
- Due to the above, most reviewed algorithms performed poorly under heavy rain conditions or fast-changing scenes with many moving objects.
- 4-
- Simple detection algorithms were based on observed optical or physical characteristics of adherent raindrops and performed well if the presumed conditions were met. Performance is degraded quickly for any deviation from these conditions, including change of background image texture or illumination and the introduction of moving objects in the scene background.
- 5-
- Complex detection algorithms performed very well under low and medium rain conditions. The added complexity, however, can introduce unacceptable latencies in real-time applications for processing rained images and removing adherent rain.
- 6-
- Compromises were discussed to improve processing time that included limiting the ROI, reducing the number of model templates, and dimension reduction, among other things.
- 7-
- The application of Deep-learning and CNN seems to be a very promising approach for solving the raindrop detection and rain removal problems.
- 8-
- The use of PSNR and SSIM metrics may not be the best choice for performance evaluation and benchmarking among different CNN-based algorithms. Results reported by different researchers showed marginal improvement in PSNR and SSIM scores which may very much be within the statistical margin of error.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garg, K.; Nayar, S.K. Vision and rain. Int. J. Comput. Vis. 2007, 75, 3–27. [Google Scholar] [CrossRef]
- Shi, Z.; Long, J.; Tang, W.; Zhang, C. Single image dehazing in inhomogeneous atmosphere. Optik 2014, 125, 3868–3875. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. Single image dehazing using color attenuation prior. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Chia, W.C.; Yeong, L.S.; Ch’Ng, S.I.; Seng, K.P.; Ang, L.-M. The effect of rainfall on feature points extraction and image stitching. In Proceedings of the 2014 International Conference on Information Science, Electronics and Electrical Engineering, Sapporo, Japan, 26–28 April 2014. [Google Scholar]
- Barnum, P.; Kanade, T.; Narasimhan, S.G. Spatio-temporal frequency analysis for removing rain and snow from videos. In Proceedings of the Workshop on Photometric Analysis for Computer Vision (PACV), in Conjunction with ICCV, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Garg, K.; Nayar, S.K. Photometric Model of a Raindrop; Columbia University: New York, NY, USA, 2003. [Google Scholar]
- Rousseau, P.; Jolivet, V.; Ghazanfarpour, D. Realistic real-time rain rendering. Comput. Graph. 2006, 30, 507–518. [Google Scholar] [CrossRef]
- Garg, K.; Nayar, S.K. Detection and removal of rain from videos. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Brewer, N.; Liu, N. Using the Shape Characteristics of Rain to Identify and Remove Rain from Video. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Tripathi, A.K.; Mukhopadhyay, S. Removal of rain from videos: A review. Signal Image Video Process. 2012, 8, 1421–1430. [Google Scholar] [CrossRef]
- Fouad, E.; Salma, A.; Abdelhak, E. Modelisation of raindrops based on declivity principle. In Proceedings of the 2016 13th International Conference on Computer Graphics, Imaging and Visualization (CGiV), Beni Mellal, Morocco, 29 March–1 April 2016. [Google Scholar]
- Halimeh, J.C.; Roser, M. Raindrop detection on car windshields using geometric-photometric environment construction and intensity-based correlation. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009. [Google Scholar]
- Gormer, S.; Kummert, A.; Park, S.-B.; Egbert, P. Vision-based rain sensing with an in-vehicle camera. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 279–284. [Google Scholar]
- Yan, X.; Luo, Y.; Zheng, X. Weather recognition based on images captured by vision system in vehicle. In Proceedings of the Advances in Neural Networks—6th International Symposium on Neural Networks (ISNN 2009), Wuhan, China, 26–29 May 2009. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996. [Google Scholar]
- Röser, M.; Moosmann, F. Classification of weather situations on single color images. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008. [Google Scholar]
- Cord, A.; Aubert, D. Towards rain detection through use of in-vehicle multipurpose cameras. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011. [Google Scholar]
- Kurihata, H.; Takahashi, T.; Ide, I.; Mekada, Y.; Murase, H.; Tamatsu, Y.; Miyahara, T. Rainy weather recognition from in-vehicle camera images for driver assistance. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005. [Google Scholar]
- Wikipedia. Snell’s Law. Available online: https://en.wikipedia.org/wiki/Snell%27s_law (accessed on 24 November 2020).
- Wikipedia. Fresnel Equations. Available online: https://en.wikipedia.org/wiki/Fresnel_equations (accessed on 20 April 2019).
- Roser, M.; Geiger, A. Video-based raindrop detection for improved image registration. In Proceedings of the in 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Stuppacher, I.; Supan, P. Rendering of Water Drops in Real-Time. In Proceedings of the Central European Seminar on Computer Graphics for Students. 2007. Available online: https://old.cescg.org/CESCG-2007/papers/Hagenberg-Stuppacher-Ines/cescg_StuppacherInes.pdf (accessed on 24 November 2020).
- Sousa, T. Chapter generic refraction simulation. In GPU Gems 2: Programming Techniques for High-Performance Graphics and General-Purpose Computation; Addison-Wesley Professional: Boston, MA, USA, 2005. [Google Scholar]
- Roser, M.; Kurz, J.; Geiger, A. Realistic modeling of water droplets for monocular adherent raindrop recognition using Bézier curves. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Yu, M.; Ma, G. 360° surround view system with parking guidance. SAE Int. J. Commer. Veh. 2014, 7, 19–24. [Google Scholar] [CrossRef]
- Zhou, J.; Gao, D.; Zhang, D. Moving vehicle detection for automatic traffic monitoring. IEEE Trans. Veh. Technol. 2007, 56, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Yamazato, T. V2X communications with an image sensor. J. Commun. Inf. Netw. 2017, 2, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Yamashita, A.; Kuramoto, M.; Kaneko, T.; Miura, K.T. A virtual wiper—Restoration of deteriorated images by using multiple cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003), Las Vegas, NV, USA, 27–31 October 2003. [Google Scholar]
- Yamashita, A.; Kaneko, T.; Miura, K. A virtual wiper-restoration of deteriorated images by using a pan-tilt camera. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- Yamashita, A.; Harada, T.; Kaneko, T.; Miura, K.T. Removal of adherent noises from images of dynamic scenes by using a pan-tilt camera. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Tanaka, Y.; Yamashita, A.; Kaneko, T.; Miura, K.T. Removal of adherent waterdrops from images acquired with a stereo camera system. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image Inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000. [Google Scholar]
- Yamashita, A.; Fukuchi, I.; Kaneko, T.; Miura, K.T. Removal of adherent noises from image sequences by spatio-temporal image processing. In Proceedings of the IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008. [Google Scholar]
- Efros, A.A.; Leung, T.K. Texture synthesis by non-parametric sampling. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; p. 1033. [Google Scholar]
- Wu, Q.; Zhang, W.; Kumar, B.V. Raindrop detection and removal using salient visual features. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar]
- Liao, H.-C.; Wang, D.-Y.; Yang, C.-L.; Shin, J. Video-based water drop detection and removal method for a moving vehicle. Inf. Technol. J. 2013, 12, 569–583. [Google Scholar] [CrossRef] [Green Version]
- Ishizuka, J.; Onoguchi, K. Detection of raindrop with various shapes on a windshield. In Proceedings of the 5th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2016), Roma, Italy, 24–26 February 2016. [Google Scholar]
- Cord, A.; Gimonet, N. Detecting unfocused raindrops: In-vehicle multipurpose cameras. IEEE Robot. Autom. Mag. 2014, 21, 49–56. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Nashashibi, F.; De Charrette, R.; Lia, A. Detection of unfocused raindrops on a windscreen using low level image processing. In Proceedings of the International Conference on Control Automation, Robotics and Vision: ICARV’2010, Singapore, 7–10 December 2010. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Read. Comput. Vis. 1987, 24, 726–740. [Google Scholar] [CrossRef]
- Sugimoto, M.; Kakiuchi, N.; Ozaki, N.; Sugawara, R. A novel technique for raindrop detection on a car windshield using geometric-photometric model. In Proceedings of the 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Yang, D.; Sun, J. BM3D-Net: A convolutional neural network for transform-domain collaborative filtering. IEEE Signal Process. Lett. 2018, 25, 55–59. [Google Scholar] [CrossRef]
- Eigen, D.; Krishnan, D.; Fergus, R. Restoring an Image Taken through a Window Covered with Dirt or Rain. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising with block-matching and 3D filtering. In Proceedings of the SPIE—The International Society for Optical Engineering, San Jose, CA, USA, 25–26 January 2006. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2015. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Quan, Y.; Deng, S.; Chen, Y.; Ji, H. Deep learning for seeing through window with raindrops. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- You, S.; Tan, R.T.; Kawakami, R.; Mukaigawa, Y.; Ikeuchi, K. Adherent raindrop modeling, detection and removal in video. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1721–1733. [Google Scholar] [CrossRef] [PubMed]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. rui1996/DeRaindrop. Available online: https://github.com/rui1996/DeRaindrop (accessed on 20 January 2021).
- Hao, Z.; You, S.; Li, Y.; Li, K.; Lu, F. Learning from synthetic photorealistic raindrop for single image raindrop removal. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Fan, Q.; Yang, J.; Hua, G.; Chen, B.; Wipf, D. A generic deep architecture for single image reflection removal and image smoothing. In Proceedings of the ICCV’17 (International Conference on Computer Vision), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kim, J.; Huh, D.; Kim, T.; Kim, J.; Yoo, J.; Shim, J.-S. Raindrop-aware GAN: Unsupervised learning for raindrop-contaminated coastal video enhancement. Remote Sens. 2020, 12, 3461. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Piscataway, NJ, USA, 7–13 December 2015. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 3, 209–212. [Google Scholar] [CrossRef]
- Alletto, S.; Carlin, C.; Rigazio, L.; Ishii, Y.; Tsukizawa, S. Adherent raindrop removal with self-supervised attention maps and spatio-temporal generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wikipedia. Bokeh. Available online: https://en.wikipedia.org/wiki/Bokeh#:~:text=In%20photography%2C%20bokeh%20(%2F%CB%88,%2Dfocus%20points%20of%20light%22 (accessed on 24 November 2020).
- Palazzi, A.; Abati, D.; Calderara, S.; Solera, F.; Cucchiara, R. Predicting the driver’s focus of attention: The DR(eye)VE Project. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1720–1733. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-video synthesis. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Liu, J.; Yang, W.; Yang, S.; Guo, Z. Erase or fill? Deep joint recurrent rain removal and reconstruction in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wikipedia. Fréchet Inception Distance. Available online: https://en.wikipedia.org/wiki/Fr%C3%A9chet_inception_distance (accessed on 24 November 2020).
- Peng, J.; Xu, Y.; Chen, T.; Huang, Y. Single-image raindrop removal using concurrent channel-spatial attention and long-short skip connections. Pattern Recognit. Lett. 2020, 131, 121–127. [Google Scholar] [CrossRef]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, D.; Li, J.; Han, M.; Shu, M. Not all areas are equal: A novel separation-restoration-fusion network for image raindrop removal. Comput. Graph. Forum 2020, 39, 495–505. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17–23 June 2018. [Google Scholar]
- Seif, G. Understanding the 3 Most Common Loss Functions for Machine Learning Regression. Available online: https://towardsdatascience.com/understanding-the-3-most-common-loss-functions-for-machine-learning-regression-23e0ef3e14d3 (accessed on 24 November 2020).
- Li, R.; Tan, R.T.; Cheong, L.-F. All in one bad weather removal using architectural search. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–19 June 2020; pp. 3172–3182. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Texture Complexity | Intensity Variance (Edge) | Intensity Variance (Inner) | Type |
|---|---|---|---|
| Simple | Large | Small | Raindrop |
| Small | Large | Background | |
| Rich | Large | Small | Raindrop |
| Large | Large | Background |
| Method | Metric | |
|---|---|---|
| PSNR | SSIM | |
| Eigen [46] | 28.59 | 0.6726 |
| Pix2Pix [52] | 30.14 | 0.8299 |
| A | 29.25 | 0.7853 |
| A + D | 30.88 | 0.8670 |
| A + AD | 30.60 | 0.8710 |
| AA + AD | 31.57 | 0.9023 |
| ID | Basic Idea | Potential Limitations |
|---|---|---|
| Cord et al. [38] | Assume elliptical shape for raindrops and use axes aspect ratio, size, and brightness constraints as a model for raindrops. | It May not account for irregular raindrop shapes and the effect of background texture on raindrop appearance. |
| Kurihata et al. [18] | Used a PCA algorithm to generate eigendrop templates. | Does not account for the effect of texture on raindrop appearance. |
| Fouad et al. [11] | Use a declivity operator to describe raindrops as a sequence of peaks and valleys. | Do not consider the background composition role in the appearance of raindrops. |
| Halimeh et al. [12] | Developed a complex model (RIGSEC) for a raindrop, based on its geometric and photometric properties. | Assuming part of a sphere for a raindrop and ignoring the blurring effect of a raindrop may limit model accuracy. |
| Roser et al. [21] | Added blurriness effect to RIGSEC and limited the rendering of raindrop models to certain regions of the image to reduce rendering time. | Generating raindrop models at specific regions in the image may lower the rate of matching with real raindrops. |
| Sugimoto et al. [43] | Used MSER to improve the initial detection of potential raindrops and spheroid for raindrop approximation. | Added complexity may make the model less appropriate for real-time applications. |
| Stuppacher et al. [22] | Modeled raindrops using height maps, considering raindrop dynamics and water content losses and gains for moving raindrops. | The model is more suitable for CGI applications to generate realistic raindrop effects. |
| Roser et al. [24] | Modeled raindrops using Bézier Curves. | Reliance on approximations of raindrop size from correlations between 2D ratios and tilt angles reduces model accuracy. |
| ID | Application | Approach | Potential Limitations |
|---|---|---|---|
| Yan et al. [14] | Weather classification in the automotive domain | Use AdaBoost to combine two weak classifiers, HGA and HSV. Classifies weather as Rainy, Cloudy or Sunny | Applications of weather classifiers are limited in the automotive domain to ADAS warnings and windshield wiper triggers. |
| Wu et al. [35] | Raindrop detection in the automotive domain | Use AdaBoost to combine color, shape, and texture saliency maps. Create a raindrop visual descriptor and use SVM to classify the weather. | Assumes circular 2D shape of a raindrop and fails under heavy rain conditions |
| Liao et al. [36] | Raindrop detection in the automotive domain | Segment the scene into the roadway and building areas. Identify raindrop candidates through edge detection and binarization and compare their dimensions to the closest ellipse. | The detection algorithm might be slow for real-time automotive applications and it fails to handle background noise and large raindrops. |
| Ishizuka et al. [37] | Raindrop detection in the automotive domain | Daytime Detector uses Sobel for initial identification, then texture information, and optical flow to detect real raindrop pixels. Nighttime Detector eliminates light source pixels, then uses a temporal intensity change feature to identify raindrop pixels. | The optical flow approach used assumes straight-line driving and may fail on winding roads. It may also cause incorrect classification as raindrops, objects that are moving at the same speed as the test vehicle. (e.g., other vehicles). |
| Kurihata et al. [18] | Raindrop detection in the automotive domain | Use similarity degree between potential raindrops and eigendrop template to identify raindrop regions | Does not account for the effect of background variations on raindrop characteristics (texture, brightness). |
| Yamashita et al. [28] | Raindrop detection in surveillance applications | Match images from different cameras, then analyze intensity variance under low and high texture image background to detect raindrops. | Requires multiple cameras which reduces the common FOV, and assumes raindrops do not occlude the same section of the restored image |
| Yamashita et al. [29] | Raindrop detection in surveillance applications | Capture successive image frames and identify them as raindrop segments, those that are detected near the expected location and satisfy size ratio constraint. | Requires precise knowledge of rotation angle and assumes idle raindrops between frames which is true only under light rain conditions. |
| Yamashita et al. [30] | Raindrop detection in surveillance applications | Similar to [29] but rotation angle is estimated and raindrop decision is made on a pixel base, by measuring the noise existence rates in the original and rotated image. | Assumes idle raindrops between frames which is true only under light rain conditions. |
| Yamashita et al. [31] | Raindrop detection in surveillance applications | Match stereo image pixels using NCC and apply one-on-one matching to eliminate noise. Compare measured to the expected disparity of raindrops to determine true raindrops. | Raindrops are blurry and may not result in good disparity measurements. Additionally, the long computational time is observed as a result of pixel-based calculations. |
| Yamashita et al. [33] | Raindrop detection in surveillance applications | Create a compound image from the temporal image sequence and select raindrop pixels that show “often” in the noise candidate trajectory curve. | Requires many frames and involves many pixel projections. |
| Roser et al. [16] | Weather classification in the automotive domain | Use feature histogram to create a bag of features, and use SVM to classify weather as Clear, Light rain, or Heavy rain. | Relatively slow, due to the large descriptor. Error rate increases with background complexity increase. |
| Cord et al. [17] | Weather classification in the automotive domain | Compare the intensity gradient image to the threshold image and pick the strongest candidates. Pick raindrop regions based on dimensions and eccentricity constraints and through temporal analysis. | System Requires focused raindrops (camera needs to be attached far away from the windshield). Raindrop size is relatively small (3–10 pixels) which may cause reduced accuracy. |
| Cord et al. [38] | Raindrop detection in the automotive domain | Segment the image then uses either watershed or background subtraction to identify potential drops. Use size, shape, and temporal constraints to identify real raindrops. | The algorithm runs slow due to implementation in MATLAB. Adding more frames improves performance but adds delay to the overall system operation time. |
| Nashashibi et al. [40] | Raindrop detection in the automotive domain | Detect potential raindrops through temporal intensity change and shape roundness. Use a lack of clear contour as a raindrop characteristic, then verify selection by spatially matching raindrop regions in consecutive frames. | Detection of unfocused is challenging and the algorithm fails under bright background conditions. |
| ID | Approach | Potential Limitations |
|---|---|---|
| Liao et al. [36] | For buildings ROI, replace the raindrop area with the closest non-rain area (using an 8-connected area template). For road ROI, use inpainting or morphological operations. | Removal time is long (0.44 to 0.68 s per frame) and it is proportional to rain density. The restoration of the road mark sections of the image is not perfect, due to the limitations of the inpainting method. |
| Wu et al. [35] | Use the inpainting technique through smooth propagation in the equal intensity line direction. | Limited to low and medium rain intensity. Inpainting based on intensity does not preserve or recover the textural characteristics of the recovered regions. |
| Yamashita et al. [29] | Create a composite image of the original and rotated one, with a parameter that controls how much each image is contributing to the final composite one. | Chromatic variations between original and rotated images may still exist, even with correction. This affects the quality of the recovered image. The algorithm fails if the difference between original and rotated images is large. |
| Yamashita et al. [33] | Decompose the image into structure and texture images. Apply inpainting process on structure image and texture synthesis process on the other. | The Spatio-temporal analysis may be needed to improve texture recovery but this, in turn, may add delay to the processing time. |
| Yamashita et al. [31] | Use disparity information to identify proper regions from the complementary image in the pair for raindrop pixel substitution. | Relies on imperfect disparity map data to select substation pixels. Additionally, the approach fails if raindrop noise is present in both images. |
| Roser et al. [21] | Estimate translational and rotational parameter vector h probabilistically, then use multi-band blending to recover rained regions. | While producing good results, this algorithm, both in its detection and recovery section seems to be too computationally expensive for automotive applications. |
| Raindrop Removal System | Network Architecture | Datasets and Testing | Potential Limitations |
|---|---|---|---|
| Dirt and Rain Noise Removal (Eigen et al. [46]) | multilayer convolutional network with two hidden layers with 512 units each. | Pictures of a glass plate with dirt and water drops were taken. Patches of size 64 × 64 for dirt and were paired with clear patches and used to train and test the rain and dirt remover system. | Restored images showed visible artifacts and were blurred where the raindrop/dirt particle was removed. |
| Attention GAN Raindrop Removal Algorithm (Qian et al. [49]) |
| 1119 pairs of images (rainy and clear), with various background scenes and raindrops. Raindrops are synthesized by spraying water on a glass plate. | Limited dataset for training and testing. Need for raindrop mask for supervised learning |
| Joint Shape-Channel Attention GAN Raindrop Removal Algorithm (Quan et al. [53]) | GAN-based on encoder-decoder architecture with ResBlocks in between and short and long skip connections. Joint physical and channel attention blocks | Used Qian et al. [49] dataset for training and testing. Uses PSNR and SSIM were used for evaluation and benchmarking. | Dataset limitations for training and testing. PSNR and SSIM scores were only marginally better than other algorithms evaluated. |
| Improved Raindrop Removal with Synthetic Raindrop Supervised Learning (Hoa et al. [56]) | The system consists of three sub-networks rain detection network, (I-CNNN with 5 conv layers + BN and ReLU activation, and 6 Resblocks reconstruction network, same as detection network with 8 ResBlocks refine network, 2 conv layers, and 2 ResBlocks | Synthesized rainy images and used them for training and testing. Adam optimizer was used for setting up training parameters. PSNR and SSIM were used for evaluation and benchmarking. | The quality of images generated by the Rain Synthesized needs more independent evaluation against real rainy images. |
| Raindrop-Aware GAN for Coastal Video Enhancement (Kim et al. [61]) | Encoder/decoder architecture with short and long skip connections. | Used Qian et al. [49] dataset as well as Anmok beach videos and paired image sets for training and testing. PSNR, NIQE, and SSIM were used for evaluation and benchmarking. | Though outperforming other methods in the coastal setup, for urban setup no clear improvement was observed over Qian et al. [49]. |
| Self-Supervised Attention Maps with Spatio-Temporal GAN (Alletto et al. [64]) | The system is made of two-stages. 1. Single-Image Removal, with location map estimator and raindrop remover networks. both constructed based on encoder/decoder architecture. 2. Spatio-temporal Raindrop Removal, flow estimator provides optical flow is learned from previous frames and concatenated with rainy image and estimated location map in a decoder/ encoder GAN architecture. | Used Qian et al. [49] dataset as well as data set of augmented videos from DR(eye)VE dataset with synthetically generated raindrops. PSNR and SSIM were used for evaluation and benchmarking. | The quality of images generated by the Rain Synthesized needs more independent evaluation against real rainy images. |
| Concurrent channel-spatial attention and long-short skip connections (Peng et al. [70]) | The system was built on the encoder/ decoder architecture, with channel and spatial attention blocks added. Short and long connections were also introduced. | Used Qian et al. [49] dataset for training and testing. Uses PSNR and SSIM were used for evaluation and benchmarking. | Dataset limitations for training and testing. The approach is similar to Quan et al. [53] with differences in network architecture. Would be interesting to compare the performance of one against the other. |
| Separation-Restoration-Fusion Network for Image Raindrop Removal (Ren et al. [73]) | the system consists of three modules. 1. Region separation module was implemented as an image pipeline with classical techniques 2. Region restoration module MFGAN built on pyramid topology was used. 3. region Fusion module IODNet connection network using DenseASPP was used to construct fusing module | Used Qian et al. [49] dataset for training and testing. Uses PSNR and SSIM were used for evaluation and benchmarking. | Images need preprocessing to classify regions of the image based on the severity of the raindrop. The classification was based on experimental results from a limited dataset and may not apply to other scenarios. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamzeh, Y.; Rawashdeh, S.A. A Review of Detection and Removal of Raindrops in Automotive Vision Systems. J. Imaging 2021, 7, 52. https://doi.org/10.3390/jimaging7030052
Hamzeh Y, Rawashdeh SA. A Review of Detection and Removal of Raindrops in Automotive Vision Systems. Journal of Imaging. 2021; 7(3):52. https://doi.org/10.3390/jimaging7030052
Chicago/Turabian StyleHamzeh, Yazan, and Samir A. Rawashdeh. 2021. "A Review of Detection and Removal of Raindrops in Automotive Vision Systems" Journal of Imaging 7, no. 3: 52. https://doi.org/10.3390/jimaging7030052
APA StyleHamzeh, Y., & Rawashdeh, S. A. (2021). A Review of Detection and Removal of Raindrops in Automotive Vision Systems. Journal of Imaging, 7(3), 52. https://doi.org/10.3390/jimaging7030052