
Deeply Supervised UNet for Semantic Segmentation to Assist Dermatopathological Assessment of Basal Cell Carcinoma

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Methods
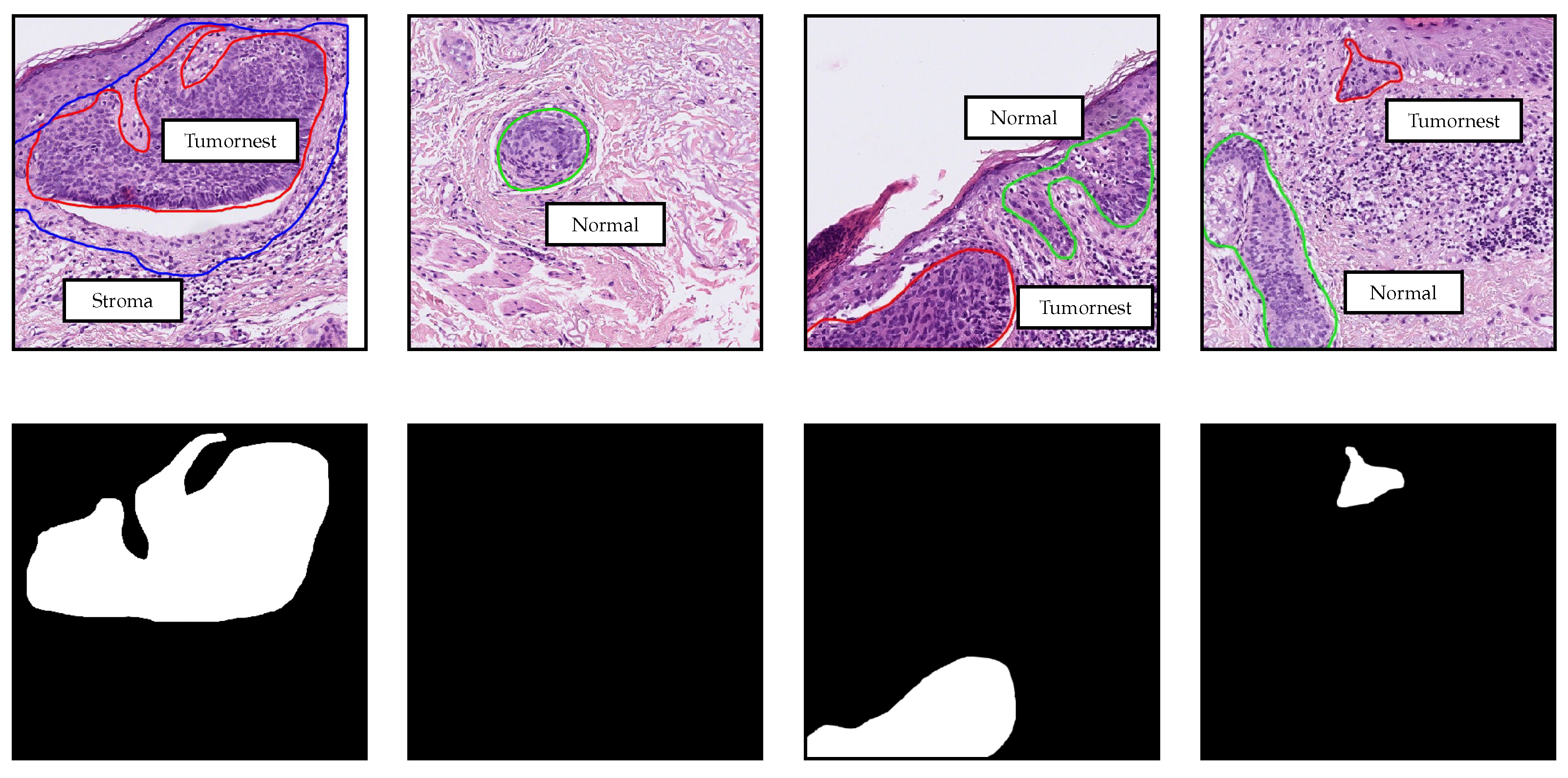
2.1. Data Collection and Data Parts
2.2. Blind Study and Web Application
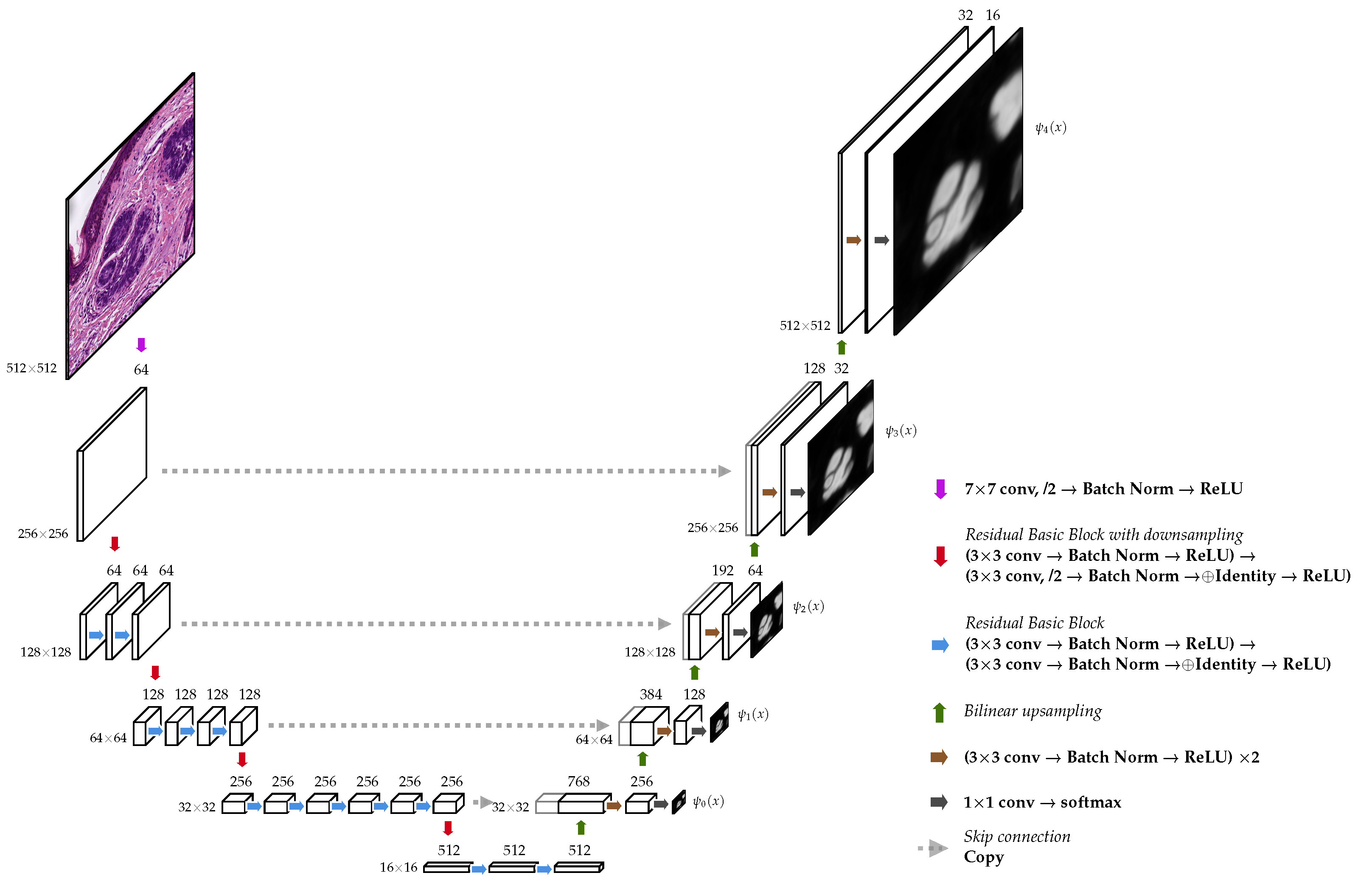
2.3. Model Architecture
2.3.1. Encoder
2.3.2. Decoder
2.4. Model Training
2.4.1. Deep Supervision
2.4.2. Linear Merge
2.5. Sectionwise Classification
2.6. Model Selection
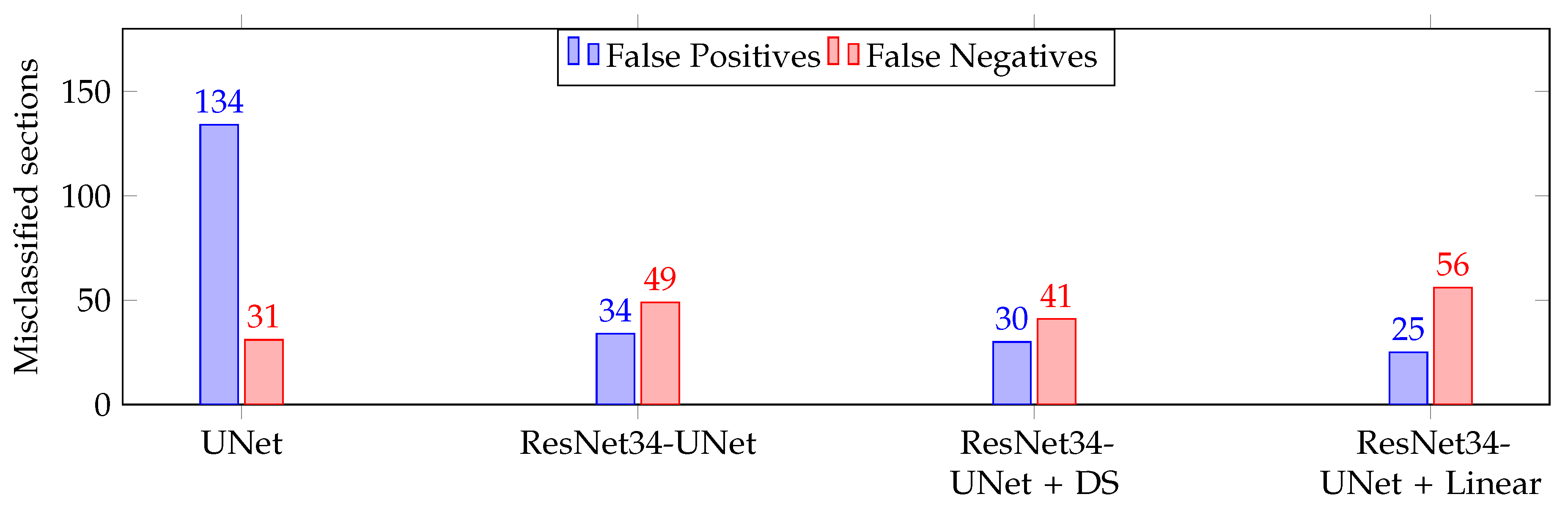
3. Results
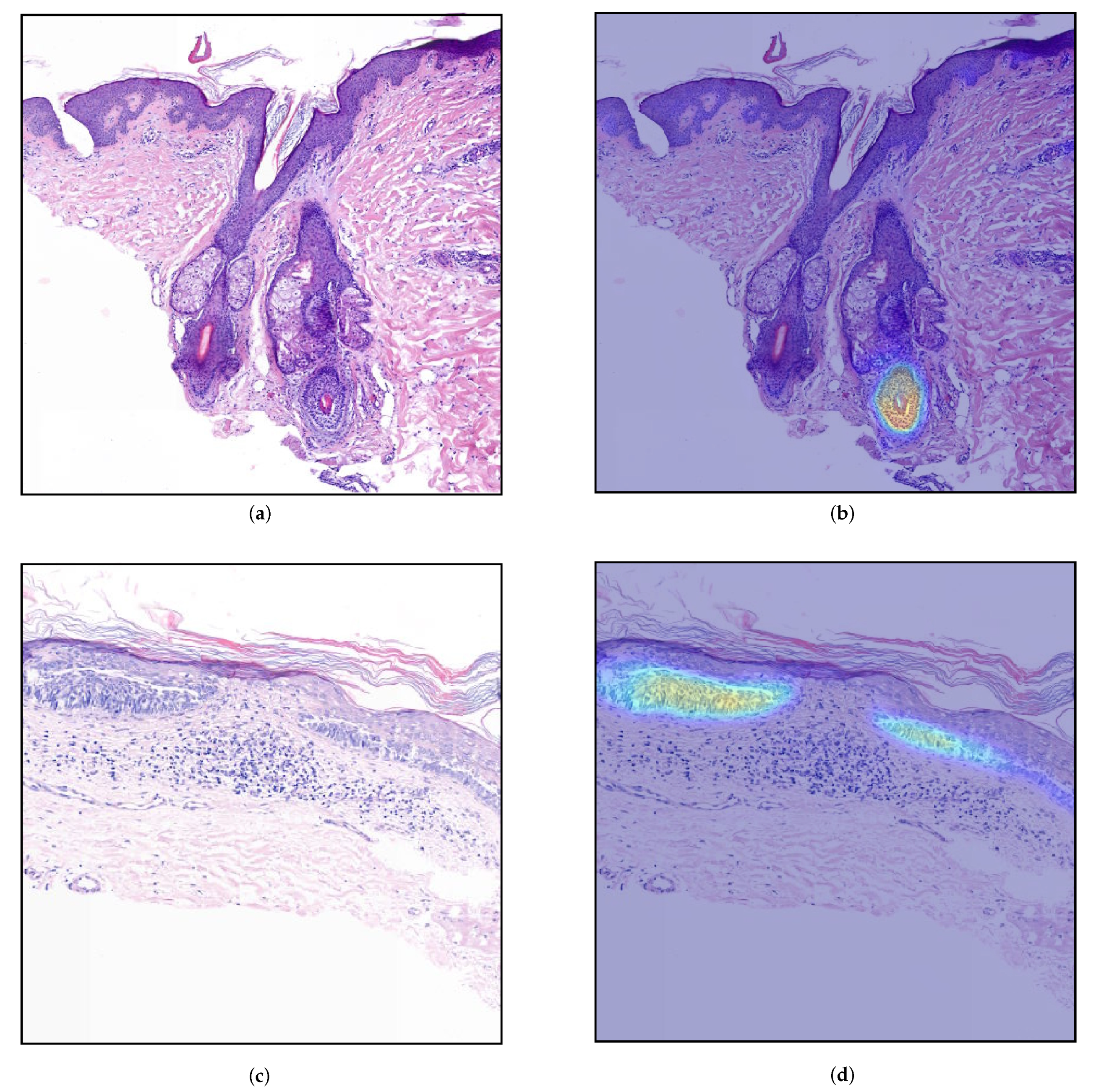
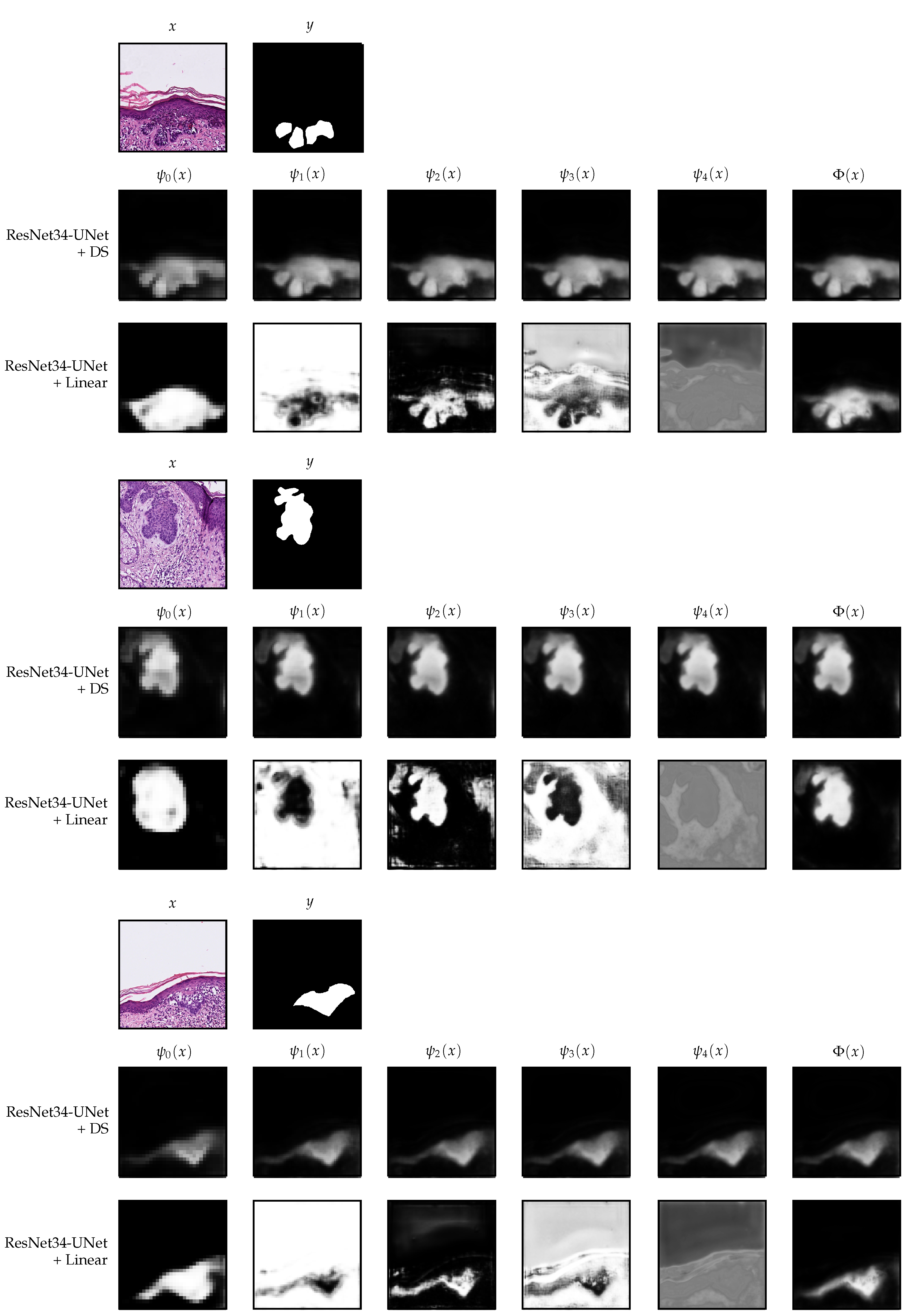
4. Discussion and Interpretability
5. Conclusions
6. Limitations and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Etmann, C.; Schmidt, M.; Behrmann, J.; Boskamp, T.; Hauberg-Lotte, L.; Peter, A.; Casadonte, R.; Kriegsmann, J.; Maass, P. Deep Relevance Regularization: Interpretable and Robust Tumor Typing of Imaging Mass Spectrometry Data. arXiv 2019, arXiv:1912.05459. [Google Scholar]
- Behrmann, J.; Etmann, C.; Boskamp, T.; Casadonte, R.; Kriegsmann, J.; Maass, P. Deep learning for tumor classification in imaging mass spectrometry. Bioinformatics 2017, 34, 1215–1223. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Echle, A.; Rindtorff, N.T.; Brinker, T.J.; Luedde, T.; Pearson, A.T.; Kather, J.N. Deep learning in cancer pathology: A new generation of clinical biomarkers. Br. J. Cancer 2021, 124, 686–696. [Google Scholar] [CrossRef]
- Wong, C.S.M.; Strange, R.C.; Lear, J.T. Basal cell carcinoma. BMJ 2003, 327, 794–798. [Google Scholar] [CrossRef]
- Sahl, W.J. Basal Cell Carcinoma: Influence of tumor size on mortality and morbidity. Int. J. Dermatol. 1995, 34, 319–321. [Google Scholar] [CrossRef] [PubMed]
- Crowson, A.N. Basal cell carcinoma: Biology, morphology and clinical implications. Mod. Pathol. 2006, 19, S127–S147. [Google Scholar] [CrossRef] [PubMed]
- Miller, S.J. Biology of basal cell carcinoma (Part I). J. Am. Acad. Dermatol. 1991, 24, 1–13. [Google Scholar] [CrossRef]
- Liersch, J.; Schaller, J. Das Basalzellkarzinom und seine seltenen Formvarianten. Der Pathol. 2014, 35, 433–442. [Google Scholar] [CrossRef] [PubMed]
- Retamero, J.A.; Aneiros-Fernandez, J.; del Moral, R.G. Complete Digital Pathology for Routine Histopathology Diagnosis in a Multicenter Hospital Network. Arch. Pathol. Lab. Med. 2019, 144, 221–228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steiner, D.F.; MacDonald, R.; Liu, Y.; Truszkowski, P.; Hipp, J.D.; Gammage, C.; Thng, F.; Peng, L.; Stumpe, M.C. Impact of Deep Learning Assistance on the Histopathologic Review of Lymph Nodes for Metastatic Breast Cancer. Am. J. Surg. Pathol. 2018, 42. [Google Scholar] [CrossRef] [PubMed]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef] [PubMed]
- Bándi, P.; Geessink, O.; Manson, Q.; Van Dijk, M.; Balkenhol, M.; Hermsen, M.; Ehteshami Bejnordi, B.; Lee, B.; Paeng, K.; Zhong, A.; et al. From Detection of Individual Metastases to Classification of Lymph Node Status at the Patient Level: The CAMELYON17 Challenge. IEEE Trans. Med. Imaging 2019, 38, 550–560. [Google Scholar] [CrossRef] [Green Version]
- Iizuka, O.; Kanavati, F.; Kanavati, F.; Kato, K.; Rambeau, M.; Arihiro, K.; Tsuneki, M. Deep Learning Models for Histopathological Classification of Gastric and Colonic Epithelial Tumours. Sci. Rep. 2020, 10. [Google Scholar] [CrossRef] [Green Version]
- Kriegsmann, M.; Haag, C.; Weis, C.A.; Steinbuss, G.; Warth, A.; Zgorzelski, C.; Muley, T.; Winter, H.; Eichhorn, M.E.; Eichhorn, F.; et al. Deep Learning for the Classification of Small-Cell and Non-Small-Cell Lung Cancer. Cancers 2020, 12, 1604. [Google Scholar] [CrossRef]
- Olsen, T.G.; Jackson, B.H.; Feeser, T.A.; Kent, M.N.; Moad, J.C.; Krishnamurthy, S.; Lunsford, D.D.; Soans, R.E. Diagnostic performance of deep learning algorithms applied to three common diagnoses in dermatopathology. J. Pathol. Inform. 2018, 9, 32. [Google Scholar] [PubMed]
- Kimeswenger, S.; Tschandl, P.; Noack, P.; Hofmarcher, M.; Rumetshofer, E.; Kindermann, H.; Silye, R.; Hochreiter, S.; Kaltenbrunner, M.; Guenova, E.; et al. Artificial neural networks and pathologists recognize basal cell carcinomas based on different histological patterns. Mod. Pathol. 2020. [Google Scholar] [CrossRef] [PubMed]
- Ianni, J.D.; Soans, R.E.; Sankarapandian, S.; Chamarthi, R.V.; Ayyagari, D.; Olsen, T.G.; Bonham, M.J.; Stavish, C.C.; Motaparthi, K.; Cockerell, C.J.; et al. Tailored for real-world: A whole slide image classification system validated on uncurated multi-site data emulating the prospective pathology workload. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oskal, K.R.J.; Risdal, M.; Janssen, E.A.M.; Undersrud, E.S.; Gulsrud, T.O. A U-net based approach to epidermal tissue segmentation in whole slide histopathological images. SN Appl. Sci. 2019, 1, 2523–3971. [Google Scholar] [CrossRef] [Green Version]
- Goode, A.; Gilbert, B.; Harkes, J.; Jukic, D.; Satyanarayanan, M. OpenSlide: A vendor-neutral software foundation for digital pathology. J. Pathol. Inform. 2013, 4, 27. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; Lebanon, G., Vishwanathan, S.V.N., Eds.; Proceedings of Machine Learning Research (PMLR): San Diego, CA, USA, 2015; Volume 38, pp. 562–570. [Google Scholar]
- Zhu, Q.; Du, B.; Turkbey, B.; Choyke, P.L.; Yan, P. Deeply-supervised CNN for prostate segmentation. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 178–184. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part | Slides | Detailed Annotations | Tumor Sections | Normal Sections |
|---|---|---|---|---|
| Training | 85 | ✓ | 188 | 209 |
| Validation I | 15 | ✓ | 53 | 31 |
| Validation II | 229 | 392 | 608 | |
| Test | 321 | 1119 | 843 |
| Before | After | |
|---|---|---|
| 175,771 | 175,771 | |
| 9537 | 30,000 | |
| 5528 | 10,000 | |
| 9096 | 20,000 | |
| 9458 | 20,000 | |
| Total patches | 209,390 | 255,771 |
| Pixel unbalance | 78.48 | 16.81 |
| Setting | Prediction Threshold | Tumor-Area Threshold () | Accuracy | |
|---|---|---|---|---|
| UNet | 0.45 | 8960 | 0.985 | 0.989 |
| ResNet34-UNet | 0.60 | 3840 | 0.993 | 0.994 |
| ResNet34-UNet + DS | 0.60 | 5120 | 0.994 | 0.993 |
| ResNet34-UNet + Linear | 0.65 | 2560 | 0.996 | 0.997 |
| Setting | Accuracy | Sensitivity | Specificity | |
|---|---|---|---|---|
| UNet | 0.916 | 0.972 | 0.842 | 0.945 |
| ResNet34-UNet | 0.958 | 0.956 | 0.960 | 0.960 |
| ResNet34-UNet + DS | 0.964 | 0.963 | 0.965 | 0.966 |
| ResNet34-UNet + Linear | 0.959 | 0.950 | 0.970 | 0.958 |
| Block | Accuracy | Sensitivity | Specificity | |
|---|---|---|---|---|
| 0.9612 | 0.961 | 0.961 | 0.964 | |
| 0.9633 | 0.963 | 0.963 | 0.966 | |
| 0.9633 | 0.963 | 0.963 | 0.966 | |
| 0.964 | 0.963 | 0.965 | 0.966 | |
| 0.964 | 0.963 | 0.965 | 0.966 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le’Clerc Arrastia, J.; Heilenkötter, N.; Otero Baguer, D.; Hauberg-Lotte, L.; Boskamp, T.; Hetzer, S.; Duschner, N.; Schaller, J.; Maass, P. Deeply Supervised UNet for Semantic Segmentation to Assist Dermatopathological Assessment of Basal Cell Carcinoma. J. Imaging 2021, 7, 71. https://doi.org/10.3390/jimaging7040071
Le’Clerc Arrastia J, Heilenkötter N, Otero Baguer D, Hauberg-Lotte L, Boskamp T, Hetzer S, Duschner N, Schaller J, Maass P. Deeply Supervised UNet for Semantic Segmentation to Assist Dermatopathological Assessment of Basal Cell Carcinoma. Journal of Imaging. 2021; 7(4):71. https://doi.org/10.3390/jimaging7040071
Chicago/Turabian StyleLe’Clerc Arrastia, Jean, Nick Heilenkötter, Daniel Otero Baguer, Lena Hauberg-Lotte, Tobias Boskamp, Sonja Hetzer, Nicole Duschner, Jörg Schaller, and Peter Maass. 2021. "Deeply Supervised UNet for Semantic Segmentation to Assist Dermatopathological Assessment of Basal Cell Carcinoma" Journal of Imaging 7, no. 4: 71. https://doi.org/10.3390/jimaging7040071
APA StyleLe’Clerc Arrastia, J., Heilenkötter, N., Otero Baguer, D., Hauberg-Lotte, L., Boskamp, T., Hetzer, S., Duschner, N., Schaller, J., & Maass, P. (2021). Deeply Supervised UNet for Semantic Segmentation to Assist Dermatopathological Assessment of Basal Cell Carcinoma. Journal of Imaging, 7(4), 71. https://doi.org/10.3390/jimaging7040071