3.2. Dual-Energy Projection Pre-Processing
X-ray imaging can be used to create a projection of the studied sample. The value of every pixel in such resulting projections depends on the integral absorption of the object’s matter across the corresponding trajectory. The main object and a foreign object absorb radiation differently, and this leads to differences in pixel intensities. However, the shape of the studied sample is not known in advance. Thus, the pixels in the object region do not have constant pixel intensities, as their values depend on the sample thickness. Two images acquired under different voltages provide additional information since material absorption depends on the X-ray photon energy.
A dual-energy projection of a sample with a defect can be segmented as a two-channel image. The X-ray absorption rate in a pixel depends on both material attenuation properties and the thickness of the object. The absorption rate is given by
where
is the absorption rate computed for the detector pixel
x,
P and
F are projection and flatfield pixel intensities,
is a spectrum of the X-ray tube,
is a material absorption curve, and
is a profile of thickness along the ray. The argument
x refers to a detector pixel, and every pixel has a corresponding X-ray beam trajectory from the source to this pixel. The absorption curve
does not depend on
x since the material is assumed to be homogeneous. If scattering is not considered, attenuation properties of the material are defined by X-ray absorption, and the attenuation rate can be calculated according to Equation (
1).
If the tube spectrum is monochromatic, then
, where
is a Dirac delta function. Equation (
1) can be simplified:
In this case, the two channels of the dual-energy image are linearly correlated. If a homogeneous material is scanned with two monochromatic beams of energies and , the corresponding absorption rates are and . The ratio between and is constant, does not depend on the thickness, and is defined by the ratio of attenuation coefficients for two X-ray energies. As a result, two different materials can be easily separated using a dual-energy projection.
In most CT applications, a beam is usually polychromatic since it is produced by conventional X-ray tubes. In this case, the attenuation rate depends on material thickness according to Equation (
1). If the thickness
is small, an effective attenuation coefficient
can be computed as a first-order approximation [
21]:
However, the attenuation rate does not linearly depend on in general. Thus, a ratio of attenuation rates is no longer a material characteristic and it depends on the thickness .
A nonlinear dependency of attenuation rate on material thickness is visible in the simulated data. For the simulation, the main object is assumed to be a skeletal muscle with an attenuation curve taken from the NIST database (ICRU-44 report [
22]). The tungsten tube spectrum for the voltages of 40 and 90 kV is computed according to the TASMIP data [
23].
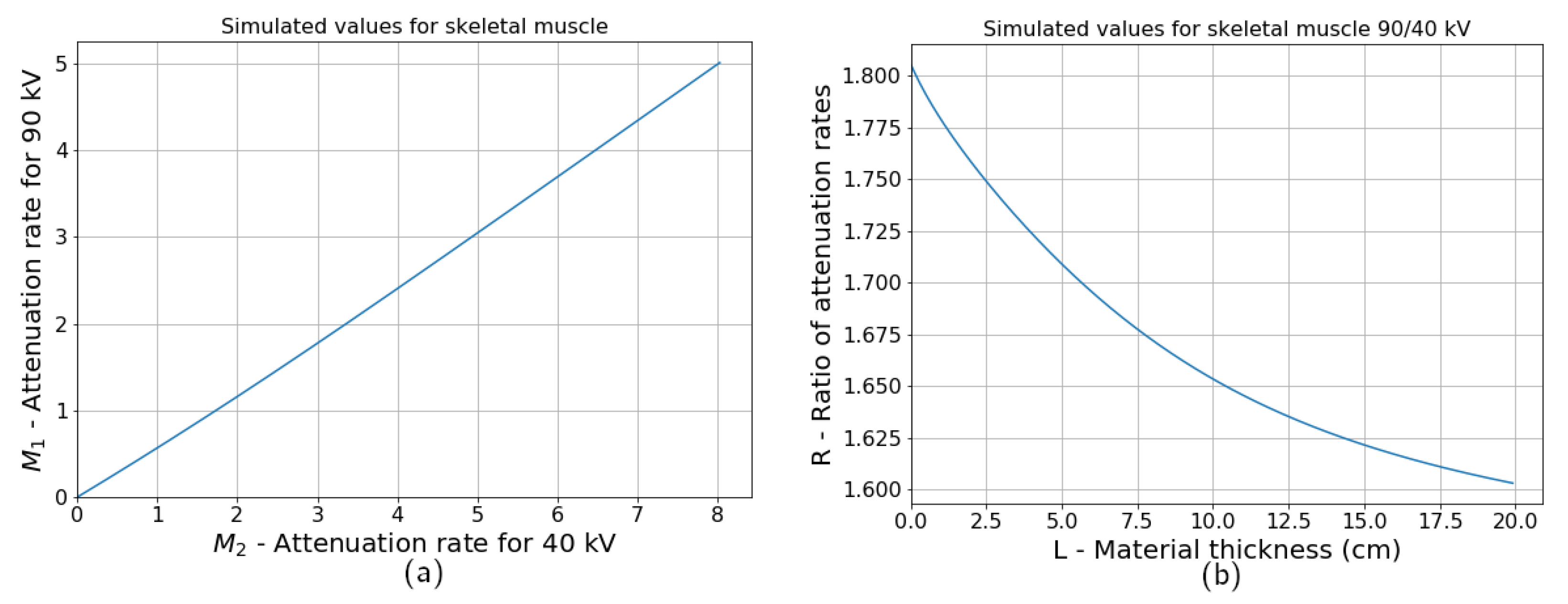
Figure 2a shows how attenuation rates for two different voltages of the tube correspond to each other. On this plot, thickness changes from 0.1 mm to 20 cm, and the attenuation rates are calculated according to Equation (
1). The correlation between the two values is almost linear as if both of them depend linearly on thickness. However, the ratio of two attenuation rates changes with thickness, as shown in
Figure 2b. This change is not significant; therefore, it is not visible on a correlation plot between two intensities for different voltages. The ratio dependency on thickness can be calculated as follows:
where
is the attenuation rate computed for the voltage of 40 keV,
corresponds to 90 kV, and
and
are the tube spectra for voltages of 40 and 90 kV
In the real scan, the nonlinear dependency is further complicated by the noise presence. A mass attenuation function is usually unknown for many food industry materials. Therefore, the thickness dependency of the ratio values cannot be predicted beforehand and should be extracted from the data. Experimental measurement produces distributions of
and
for two different tube voltages. The quotient distribution
can be computed as follows:
The thickness profile
is unknown. As shown in
Figure 2a, attenuation rate
is almost proportional to
. Thus, in a data-driven approach, the dependency of quotient values on thickness can be studied as a dependency of
on either
. Values of
are lower than
for the same
x since the voltage of
is higher. Therefore,
has a lower absolute value of the error and is used as an argument in the function
. The function
can be studied as well. The dependency
is further replaced by a polynomial approximation since a high noise level makes it impossible to recover true function from the data without any additional information.
The order of the polynomial chosen for a function approximation depends on the data quality. In the experimental data used in this work, a linear approximation of
is not sufficient and leads to significant discrepancies between the acquired data and the fit. High orders of the polynomial are prone to noise, and the fit does not always converge as a result. The quadratic approximation was chosen as a middle ground since it provides a sufficiently good representation of the data and has a low noise sensitivity. This approximation is given by
where
and
are pixel values in the respective channels of the experimentally acquired projection and where
a,
b, and
c are fit coefficients. The polynomial regression is performed for all pixels of the object simultaneously.
When the dependency of
on
is extracted from the data in the form of polynomial approximation, the effect of thickness dependency can be reduced. After a polynomial fit, the distribution of
can be computed as follows:
where
is a corrected quotient distribution. If the sample consists of a homogeneous material,
is close to zero regardless of the thickness. However, inclusion of a defect with different absorption properties affects both
and
.
is easier to use for defect detection since the form variation of the object does not significantly influence this distribution.
3.3. Pre-Processing of the Experimental Data
A sample of a chicken fillet containing a fan bone was scanned using a CMOS detector with a CsI(Tl) scintillator (Dexela1512NDT) [
24]. The X-ray source was a microfocus X-ray tube with voltages of 40 and 90 kV. The piece of fillet was wrapped in a plastic bag and placed on a holder. This experimental setup imitates a top view similar to the typical data from a conveyor belt.
The same sample was measured with different exposure times to illustrate the impact of the detector noise.
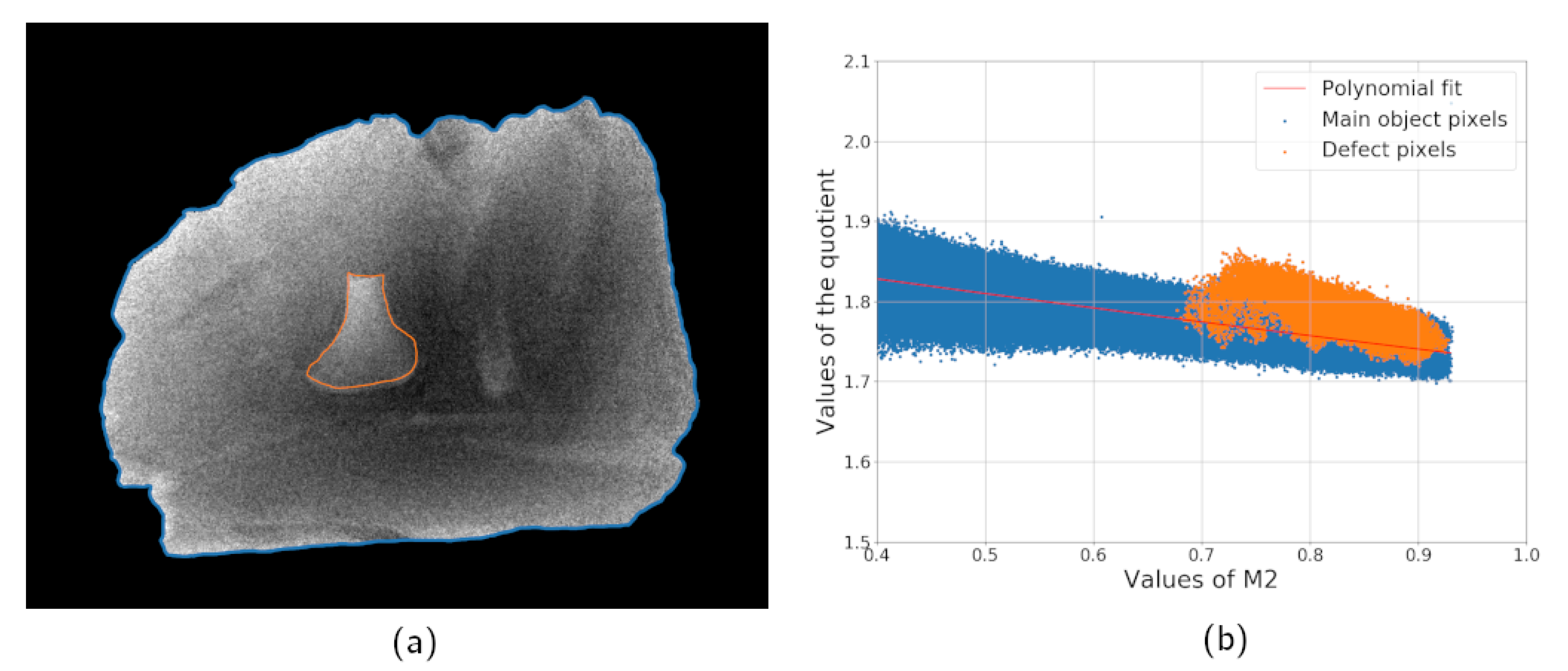
Figure 3a shows a combined image computed according to the Equation (
5) with two projections acquired with the exposure time of 0.5 s.
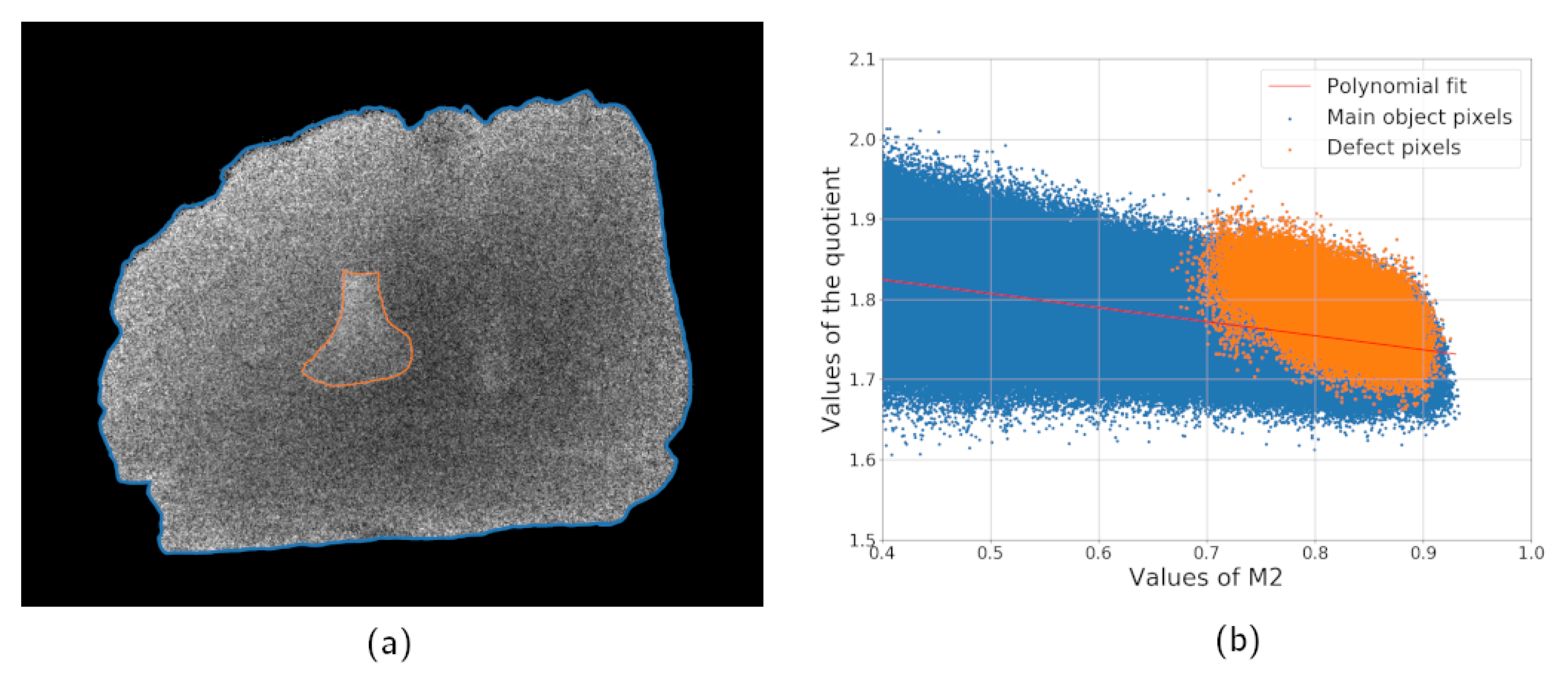
Figure 3b is a plot of thickness dependency of quotient values based on the experimental data corresponding to
Figure 2b for the simulated data. Values of
are used instead of
since the thickness profile of the object is unknown. Pixels of the defect are marked with a different color to highlight that the noise variance is bigger than a difference between the sample and defect in spectral properties. Nevertheless, the bone can be located by a human expert based on the
distribution since the defect pixels are located near each other and form a region. If the same product is scanned with a higher exposure time, the level of statistical noise becomes lower and the foreign object is easier to locate.
Figure 4a,b shows the quotient image and quotient plot for the measurement with an exposure time of 5 s. The high noise case is more difficult, and it is the main focus of the next subsections.
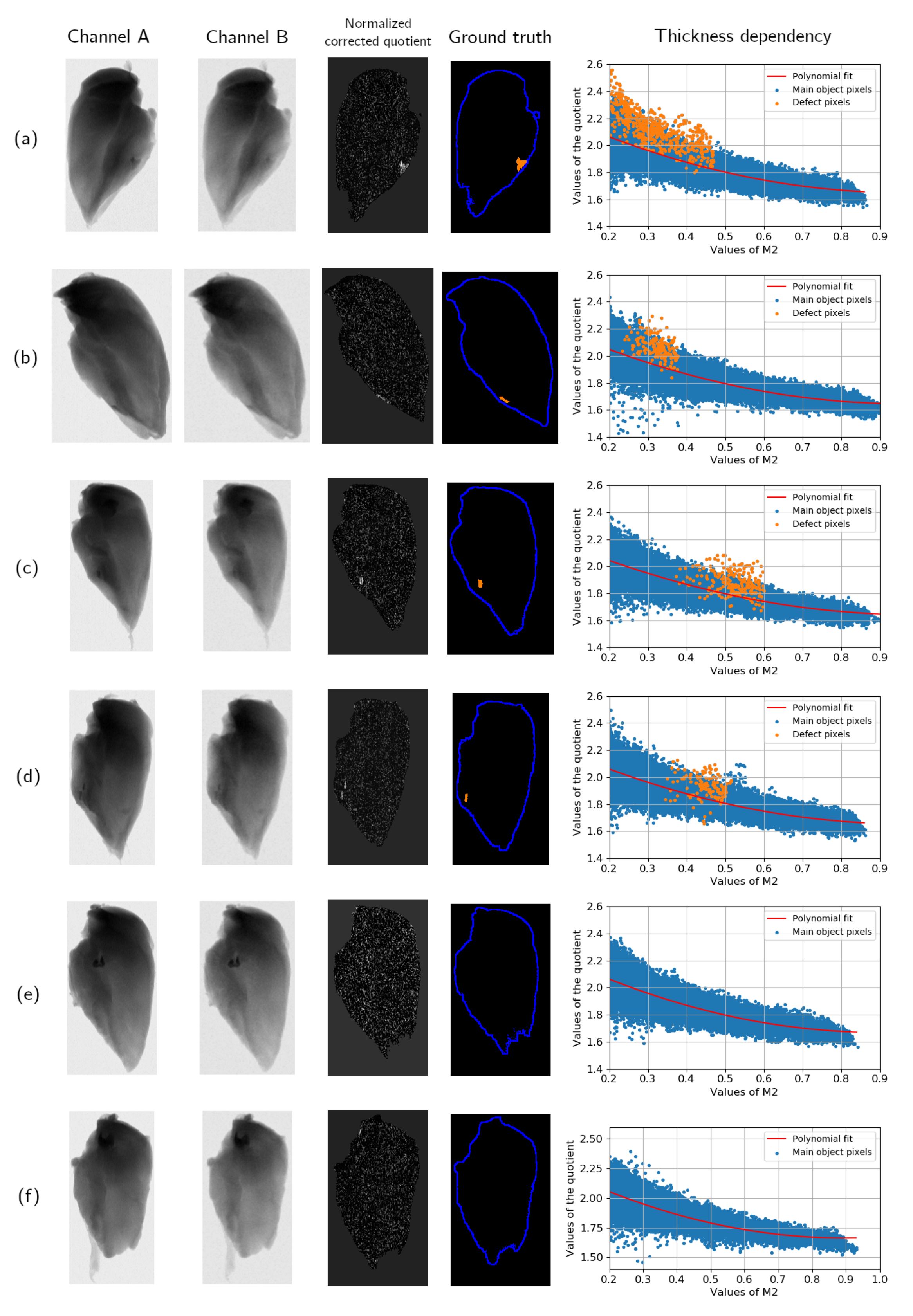
Even if the foreign object is visible to a human expert, its detection might still be non-trivial for a classical algorithm. Thickness dependency of the ratio values leads to natural gradients in the
. The introduction of the corrected quotient
helps to reduce this effect and makes the image easier to segment. The thickness correction is shown in
Figure 5a,b, which represent
and
distributions. After this procedure,
is close to zero in most pixels corresponding to the main object. A deviation from zero might be caused by detector noise, systematic errors of the experimental setup, and different defects. The presence of a foreign object changes a pixel value, and the difference depends on its thickness. The main task of the segmentation algorithm applied to
Figure 5b is to locate big clusters of nonzero pixels excluding noisy outliers. With a significant noise influence, foreign object location is difficult to perform on a pixel level. Thus, it is important to use spatial information.
The largest noise level in the
distribution is usually found near the edges of the main object. In those regions, a quotient intensity is calculated as a ratio between two small numbers that leads to the high relative error. This effect can be reduced to improve detection accuracy. It can be assumed that the variance of the image values is mainly defined by the statistical noise and depends on the thickness. Therefore, a standard deviation for different thickness values should be computed from the data. The simplest approach to solve this problem is to divide the image into regions with similar
intensity and to compute mean value and standard deviation for every subset. Each region is defined as a set of image points with the intensity values
belonging to a certain closed interval of values. If values of
start from a threshold value
and size of the interval is
, the intensity interval corresponding to
ith region can be written as
. Therefore, the region is a set of points
x where
. Then, the normalized corrected quotient
can be calculated as follows:
where
and
are mean value and standard deviation of intensity values
computed for
ith region.
3.4. Segmentation of the Combined Image
Thickness correction pre-processing described in the previous section transforms two-channel dual-energy projections into a single image. In this work, an active contour model without edges is used to achieve good segmentation quality with a high noise level. The Chan–Vese method [
19] is a variational segmentation algorithm inspired by the Mumford–Shah model [
25]. It separates two homogeneous phases in the image by minimizing the energy functional over the phase boundary and their average values:
where
and
are regions segmented as an object and backgound,
and
are average pixel values in these regions,
is the boundary length of
, and
is the area of
. In the case of a foreign object location problem, the background refers to the main object and the object refers to the foreign object. The minimization problem is solved by applying the level-set technique: phase boundary is defined as a zero-level of a level-set function. The values of
and
are recalculated on every step depending on the current phase boundary.
The segmentation outcome is implicitly controlled by the ratios between
,
,
, and
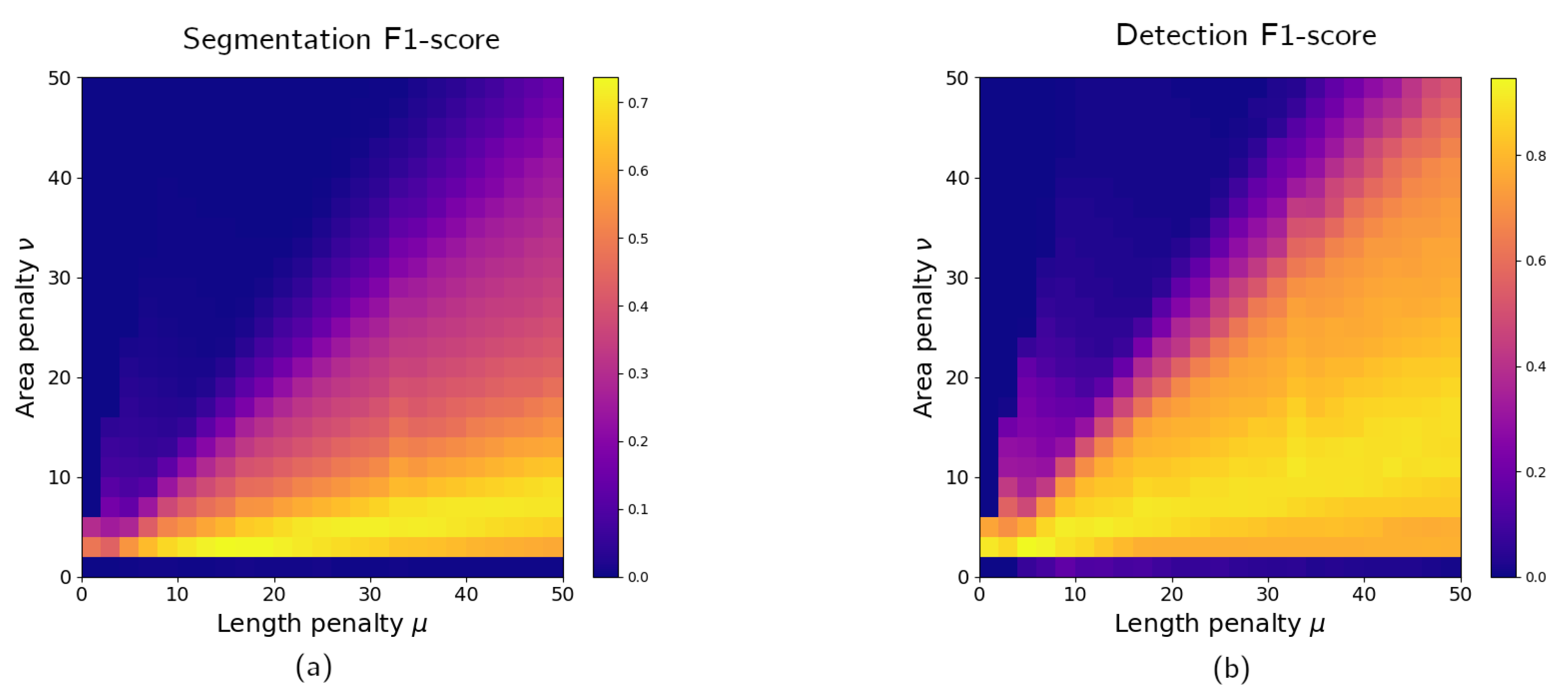
. The first two terms favor a similarity between pixel value and region average intensity regardless of the spatial properties. The last two terms mitigate the effect of noisy pixels on the segmentation. Low values of
and
transform the segmentation into thresholding with minimal removal of outliers (
Figure 6a). Different values of penalty weights lead to different boundary detections, noise sensitivities, and overall accuracies of the algorithm. Examples of such effects are shown on
Figure 6b,c. The biggest strength of the active contour approach is that parameters have an interpretation and can be related to the image properties, such as object intensities and noise distribution.
As a variational algorithm, the Chan–Vese method has a few implicit parameters that influence the iterative process. The initial state of the level-set function in the described implementation is defined by a simple thresholding
where
corresponds to a significant deviation from zero. Thus, pixels with values higher than the threshold are likely to be part of the defect region. On every iteration of the segmentation algorithm, the level-set is recalculated to better minimize the segmentation energy. If the increment norm is smaller than a certain tolerance value, the algorithm converged. The iterative process is also stopped if it takes more iterations than a certain maximal number. These parameters mainly influence the speed and convergence of the method and define the final segmentation in case there are multiple local minima.
Accuracy of the segmentation can be evaluated if a ground truth (correct segmentation of the input) is known for every sample. In this paper, F1-score is chosen as an accuracy metrics and is calculated according to the following formula:
where TP is the number of True Positive pixels (pixels of the defect that were correctly identified), FP—False Positive (pixels of the main object that were falsely classified as a defect), and FN—False Negative (pixels of the defect which were missed). This metric is commonly used in papers about foreign object segmentation. However, it does not evaluate performance on the samples without a foreign object.
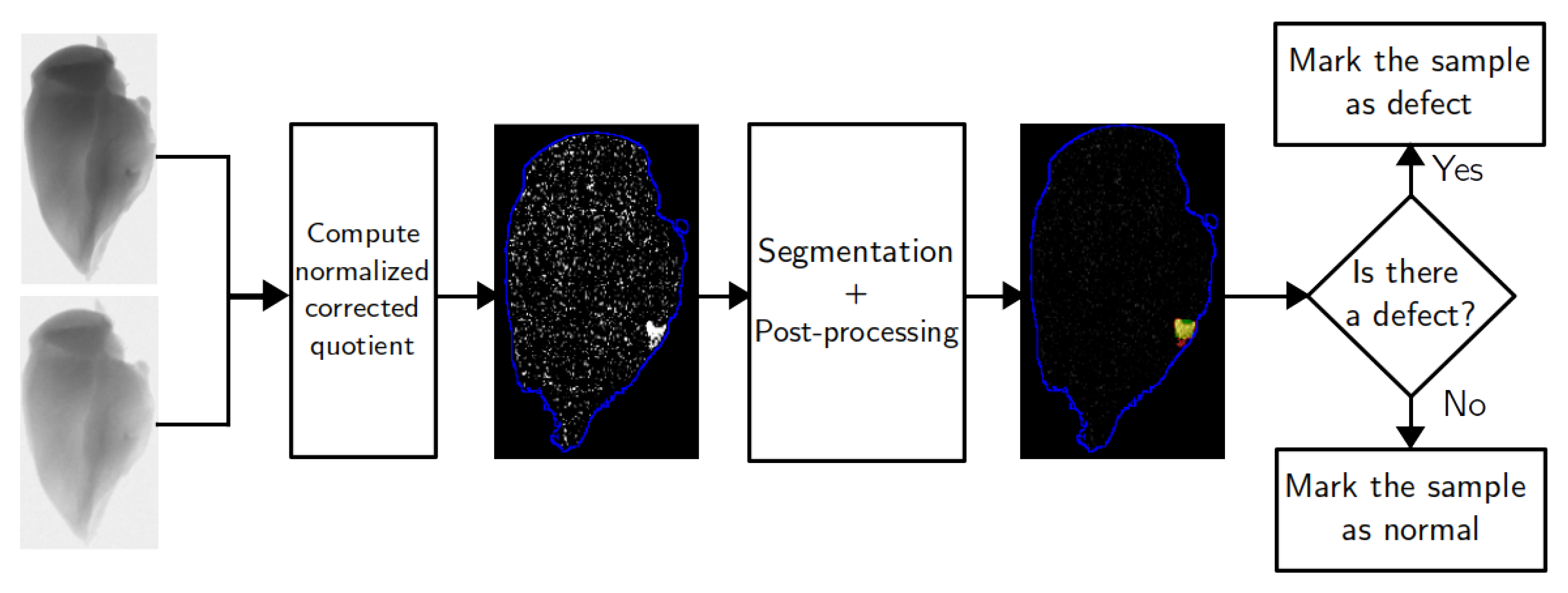
3.5. Post-Processing and Foreign Object Detection
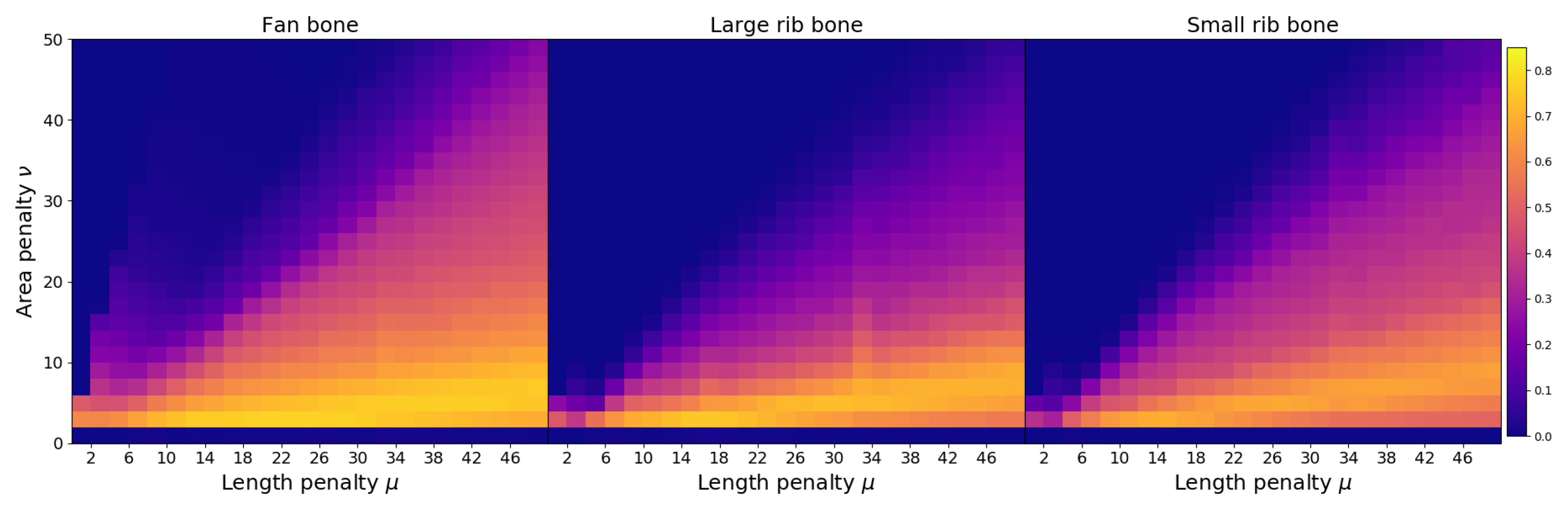
The main challenge for the active contour segmentation lies in images without defects. The neighborhood of a noisy pixel with a significant deviation from zero can be considered part of the defect region, even if there is no foreign object in the sample. This problem can be solved by adjusting penalty weighting coefficients and . If a region with mean intensity is considered part of the main object, the energy is increased by since the mean intensities are different. This energy increment can be avoided if this region is classified as a foreign object. In this case, the energy is modified by penalty terms . The decision about including or excluding the region is based on the ratio between these two terms. It is important to note that the Chan–Vese algorithm is an iterative method. Therefore, the result depends not only on energy terms but on the initial level-set, regularization parameters, and convergence speed, among other things. Nevertheless, penalty weights should be raised to a certain level to exclude noisy clusters in most cases.
If a noise level is sufficiently high, fine-tuning parameters for all types of inputs is a challenging problem. Significant noise fluctuations in the samples without foreign objects require penalty weights to be high. On the other hand, the accuracy of defect segmentation becomes worse since many pixels on the foreign object boundary are included in the main object. A post-processing procedure is introduced as an additional way to exclude noisy pixels from the foreign object region and to make the algorithm more robust. A segmented defect region can be divided into clusters of neighboring pixels. For each cluster, the mean intensity and size can be computed. Segmentation quality can be enhanced if a certain threshold on the cluster size is set and small clusters are ignored. The main reason for employing this strategy is the existence of noisy pixels with an intensity that is several times higher than the average defect intensity. If penalty weights are adjusted to exclude such pixels, small foreign objects might be excluded as well.
In the proposed methodology, post-processing is the removal of segmented clusters with a size lower than a certain number of pixels. If there are no clusters after pre-processing, the sample is marked as normal. Otherwise, it is considered that the sample contains a defect. For every sample in the experimental dataset, it is known whether it contains a foreign object or not. Thus, it is possible to compute a confusion matrix and F1-score for the inspection procedure. In this case, accuracy is measured on a sample level, unlike segmentation precision. These metrics are more important for algorithm performance evaluation since they include all possible cases. If the segmentation is fine-tuned to achieve the best segmentation accuracy, it might become too sensitive to noise. Therefore, due to noise fluctuations, it classifies normal samples as containing a defect.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}