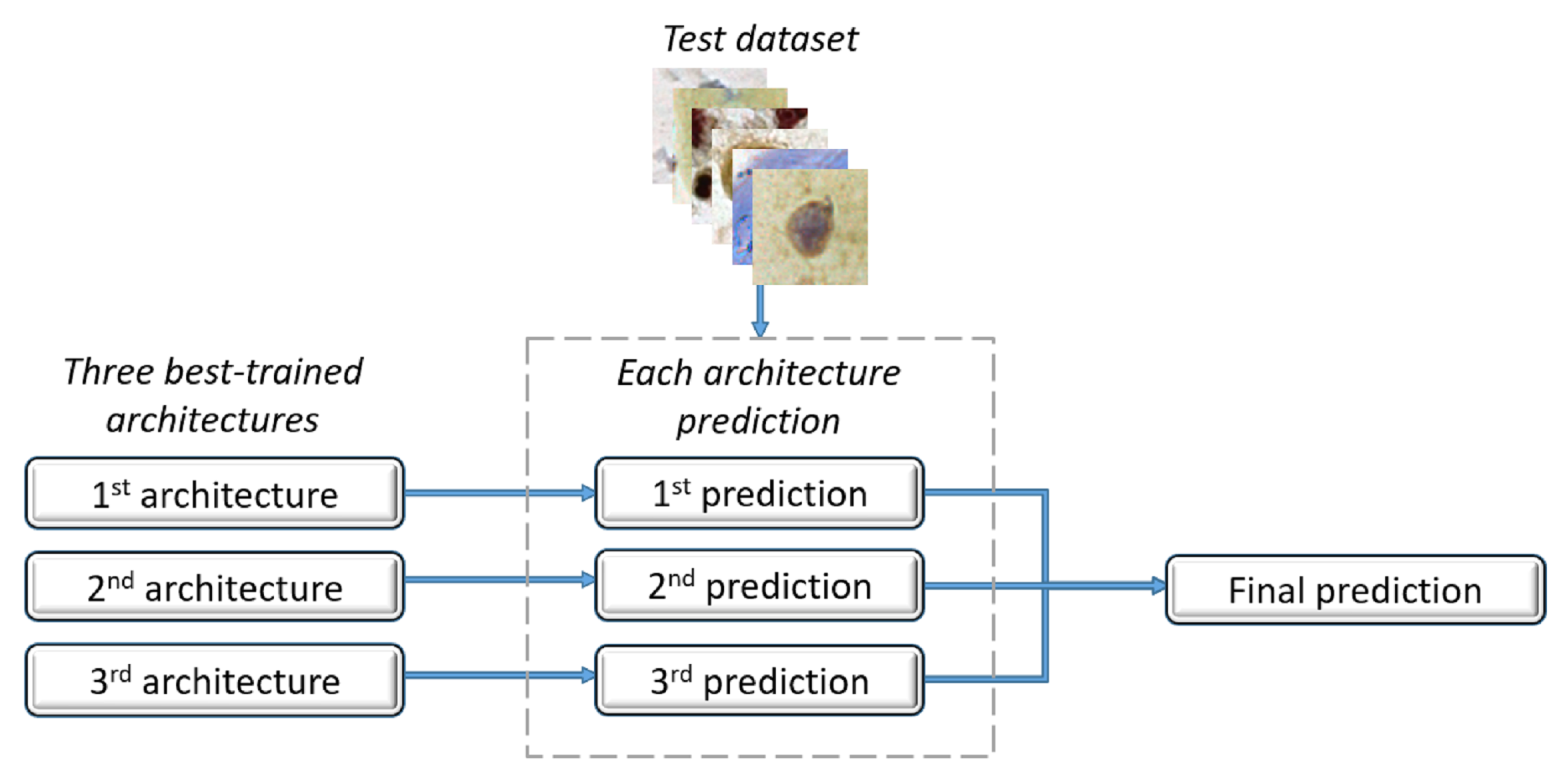
This section shows and discusses the experiments that were developed to evaluate the proposed methodology. The experiments were performed on a computer with an Intel Core i7-9700F processor with a GPU GeForce RTX 2080, 3 GHz CPU, and 16 GB of RAM, which ran on the Windows 64-bit operating system. The proposed methodology used the Python programming language, version 3.7.9, and the Tensorflow/Keras framework.
4.1. Metrics
We used five metrics to measure the proposed methodology’s quality: precision, recall, F1-score, accuracy, and specificity. To calculate them, it was necessary to define the values of true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs). There were two situations: one in which the test result indicated that the woman had a lesion and another in which she did not. In the first (a result that had a lesion), we defined it as a true positive if the woman had a lesion. However, if she did not have a lesion, we found a false positive. In the second situation (a result that did not have cancer), if the woman had a lesion, the result was a false negative, and if she did not have a lesion, it was a true negative.
Thus, precision (Prec.) measures the test’s capability to detect altered cells only in patients with lesions. Equation (
1) presents the formula for precision.
The recall (Rec.), which was calculated using Equation (
2), measures the test’s ability to detect altered cells when they were present.
The F1-score measure, which is presented in Equation (
3), takes the harmonic mean between the precision and recall, indicating the general quality of the proposed methodology.
Accuracy (Acc.) measures the proportion of all tests that gave the results correctly (whether positive or negative) compared to all of the results obtained. The formula used to calculate the accuracy is presented in Equation (
4).
Finally, specificity (Spec.), which is presented in Equation (
5), measures the test’s ability to identify not cell lesions when absent; that is, it returns the proportion of people without lesions who had negative test results.
4.2. Results
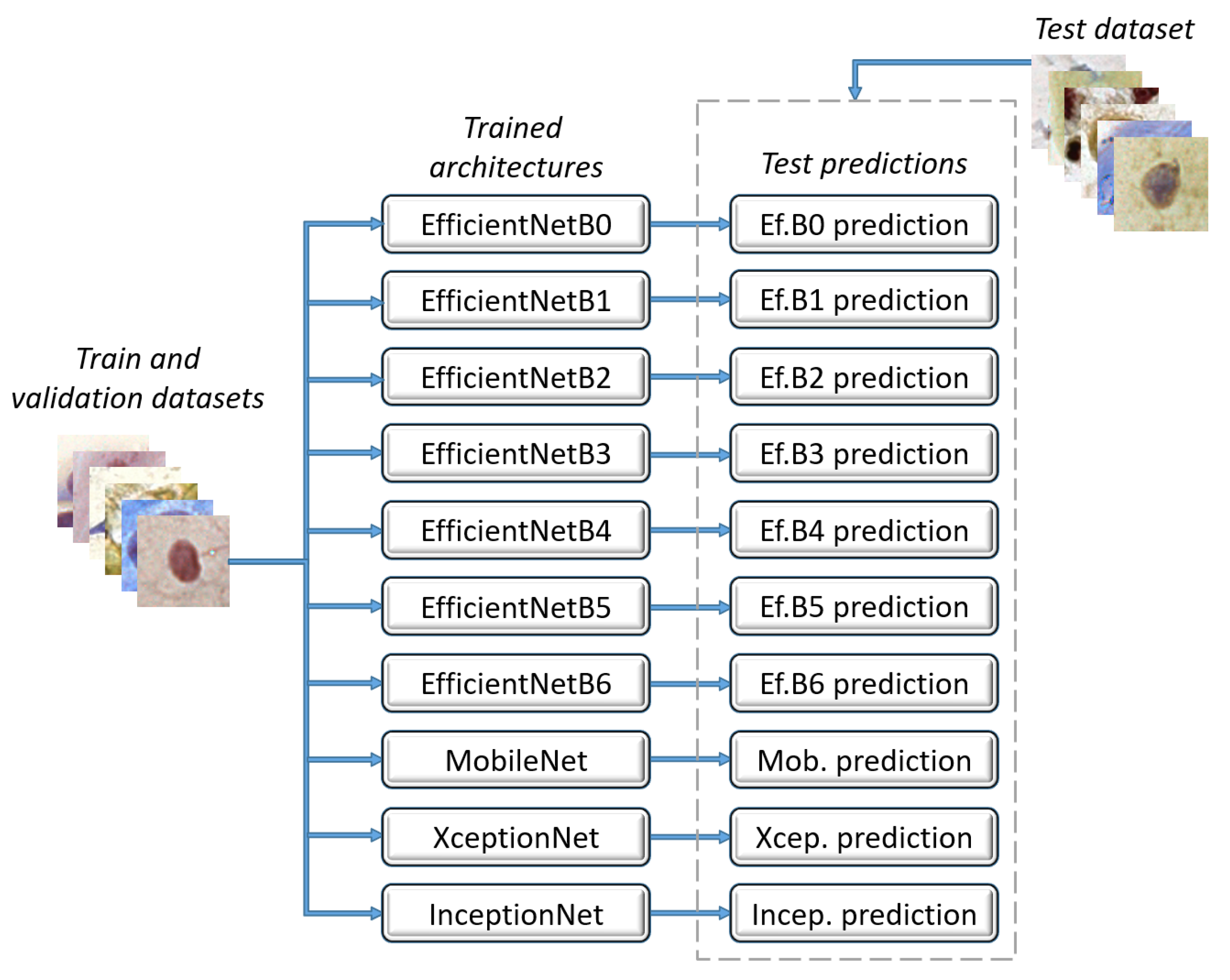
Table 5 presents the mean results for the precision, recall, F1-score, accuracy, and specificity obtained using cross-validation. These results correspond to the two-class classification of the individual architectures and the proposed ensemble. The best results for each metric are highlighted in bold in this table and in the others. For images classified into two classes, the six individual architectures achieved the same performance: EfficientNetB0, EfficientNetB1, EfficientNetB2, EfficientNetB4, EfficientNetB6, XceptionNet. EfficientNetB1, EfficientNetB2, and EfficientNetB6 were randomly selected as the five best models for performing the ensemble method, and EfficientNetB2 was the tiebreaker decision. Results (Source code available at
https://github.com/debnasser/deep-learning-ensemble-jimaging, accessed on 6 July 2021) show that the proposed ensemble outperformed all architectures concerning the five metrics.
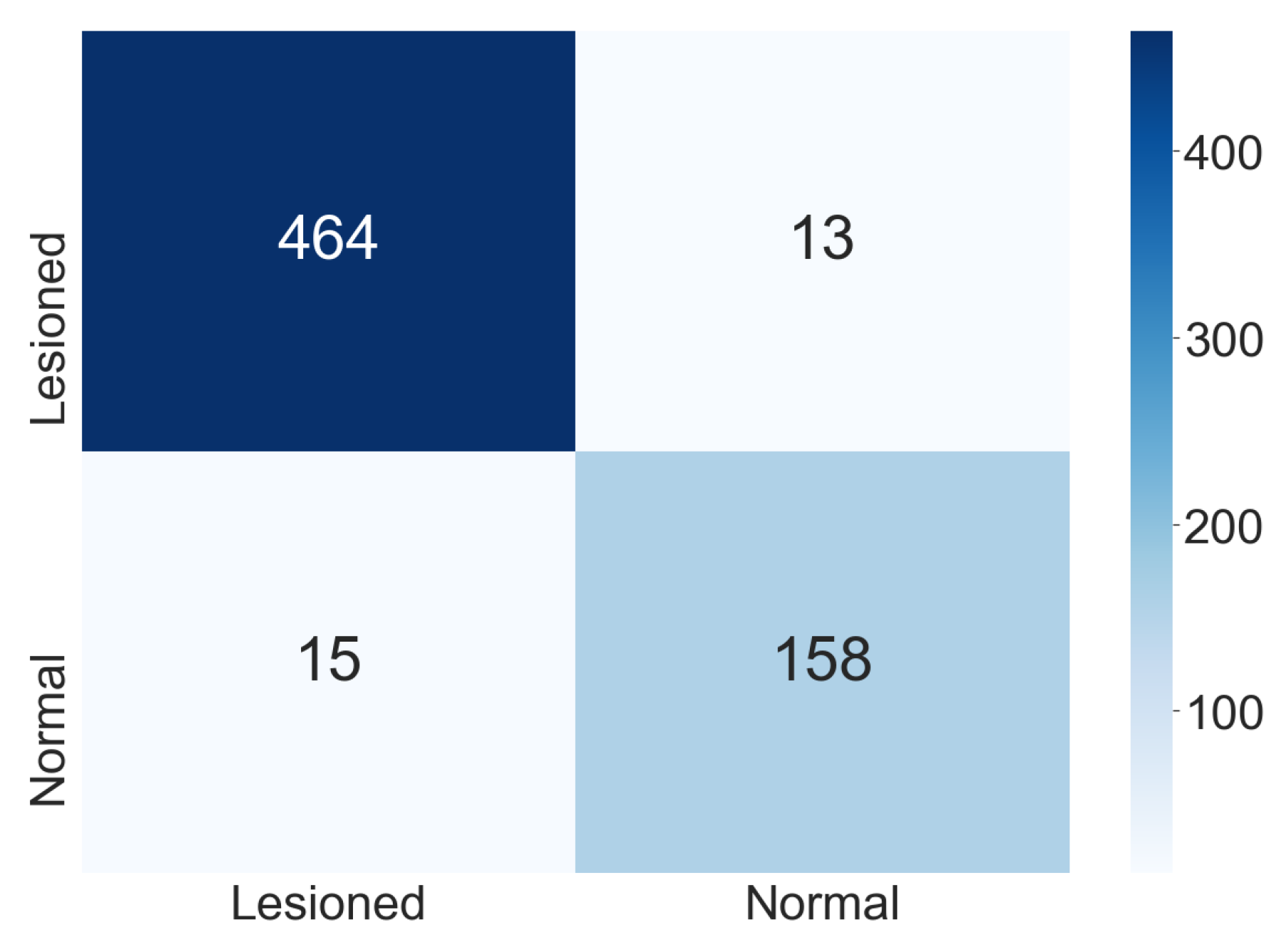
Figure 5 shows the confusion matrix found in one execution of the ensemble used for the two-class classification. We observed that the classes’ generalization did not change the classification with the confusion matrix and the results presented. Despite aiming the proposed methodology at creating a decision support tool for cytopathologists, the professional will confirm the final classification.
However, when analyzing only the two-class classification, the methodology will not assist the professional by suggesting a diagnosis and an appropriate follow-up for a patient. For this reason, we also analyzed the three-class classification.
Table 6 presents the mean results obtained in the cross-validation of the individual architectures and the proposed ensemble for the three-class classification.
For the three-class classification, EfficientNetB2, EfficientNetB4, and EfficientNetB6 were selected to perform the ensemble method, and EfficientNetB6 was the tiebreaker decision. We observe in
Table 6 that the proposed ensemble overcame all architectures for the five metrics. EfficientNetB4 and EfficientNetB6 only had the same performance as the ensemble for the specificity metric.
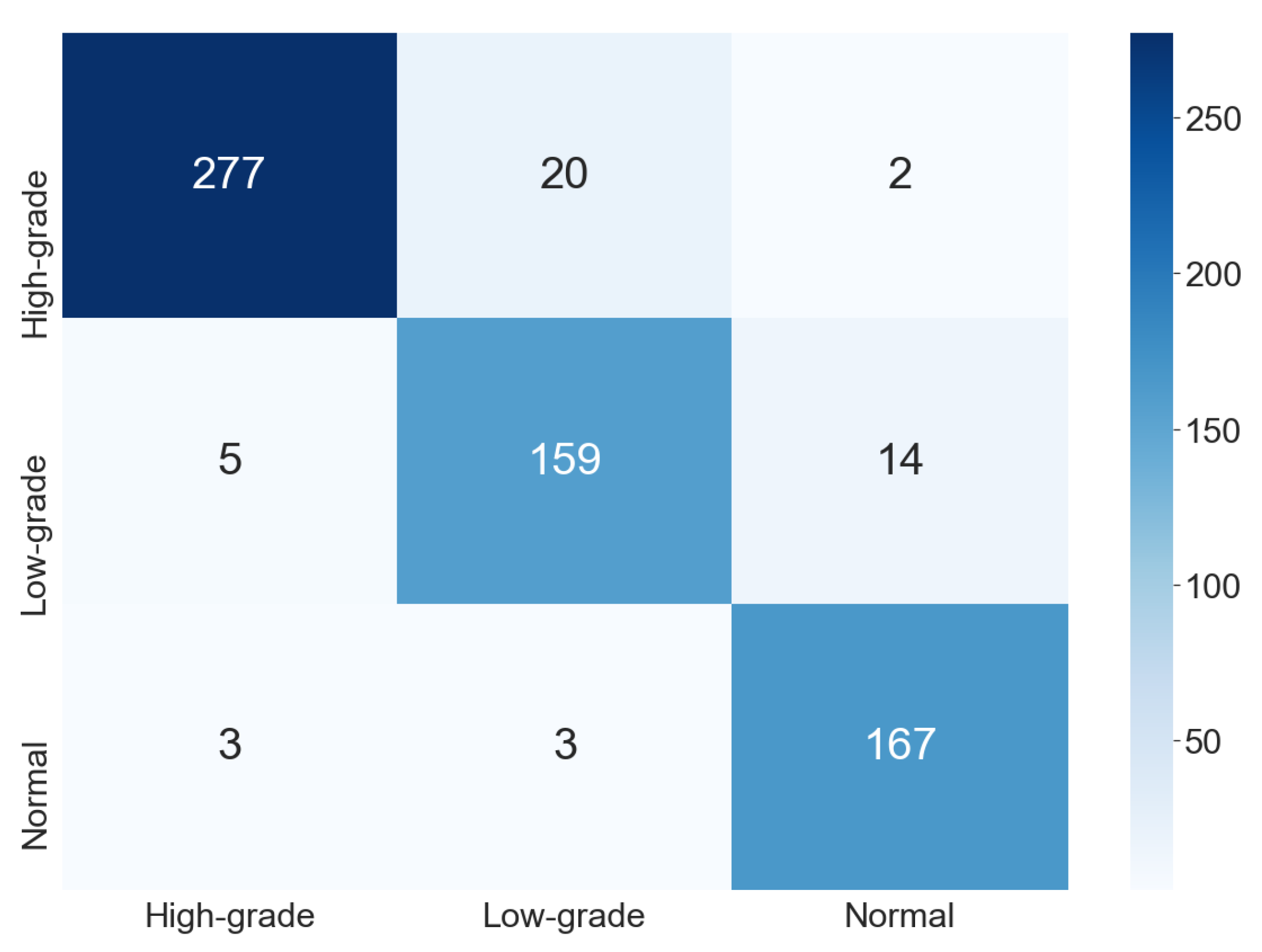
The confusion matrix shown in
Figure 6 refers to one execution of the ensemble for the three-class classification. In comparison with the result for the two-class classification, we can observe that the number of classes is directly related to the classification difficulty. Initially, this behavior was not clear because, despite the common assumption that a smaller number of classes implies an easier problem, the combination of different types of cells in the same class could generate a very distinct class. Thus, a hypothesis would be that this could disturb classification, which was not observed in our results.
An advantage of making the three-class classification is that it suggests the patient’s conduct (in the case of a positive result) and the diagnosis to the cytopathologist. Again, it is relevant to consider that the outcome of the proposed methodology is only a suggestion. The patient’s final diagnosis and follow-up are the responsibility of the cytopathologist; the proposed methodology is only a tool to support their decisions.
We also analyzed the six-class classification. With this classification, we determine the type of lesion presented in an image.
Table 7 reports the mean results of the 10 executions of the cross-validation. For this task, we used EfficientNetB1, EfficientNetB2, and EfficientNetB3 to perform the ensemble method. This ensemble method also used EfficientNetB2 as the tiebreaker method because it was one of the architectures that produced the best results in all evaluation metrics. According to our experiments, the proposed ensemble also outperformed all individual architectures. Only EfficientNets B2 and B3 had the same performance as the ensemble for specificity.
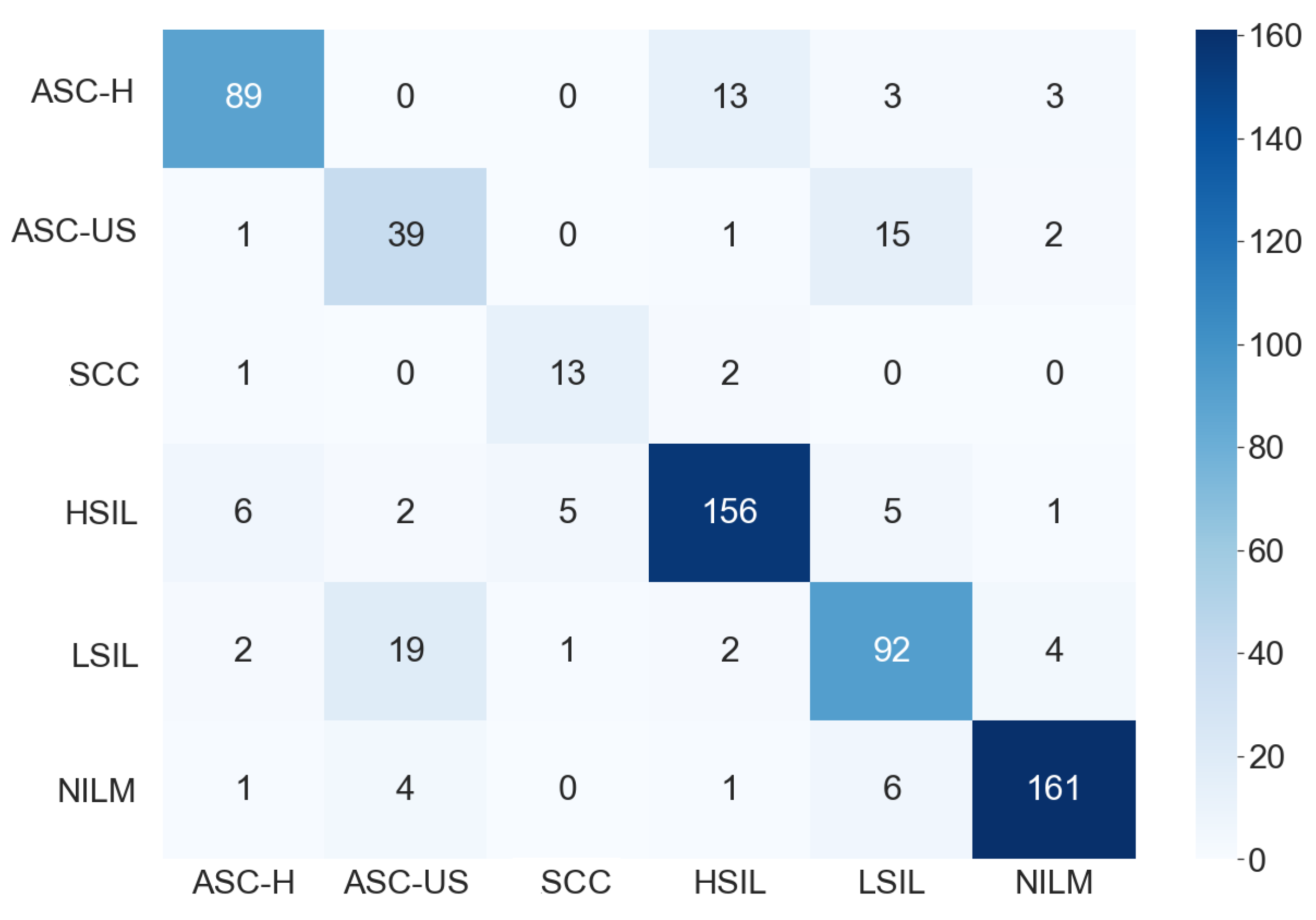
Figure 7 shows the confusion matrix found by one proposed ensemble for the six-class classification. In this case, we observe that the classes ASC-US and LSIL were quite confused. A relevant feature for differentiate them is the number of occurrences in the smear. When many occurrences are observed, the cells are classified as LSIL; otherwise, they are classified as ASC-US [
48]. As this work evaluated cell images individually, it was not possible to use this approach to improve the results, as this would involve evaluating a whole smear. The methodology also disregards relationships between the cropped images. However, both classes (ASC-US and LSIL) lead to the same patient conduct: follow-up and repeating the exam in six months or one year, depending on the patient’s age.
According to these experiments, the EfficientNets stood out among other methods. These neural networks are likely efficient for the problem in question due to their ability to stack multiple layers of the mobile inverted bottleneck (MBConv) blocks combined with squeeze-and-excitation optimization.
To compare the results obtained here with those of other methods found in the literature, the articles proposed by Silva et al. [
5] and Isidoro et al. [
6] were selected because they used the same dataset as that used in this work.
Table 8 compares the results using the precision, recall, F1-score, accuracy, and specificity metrics according to the number of classes covered. According to Equation (
1) of the work proposed by Isidoro et al. [
6], the authors used precision instead of accuracy. Therefore, we changed the value to the correct one. We inferred the accuracy based on the recall and F1-score. In this table, we also present the classification results for the six-class classification.
In
Table 8, we verify that the proposed method outperformed the one presented by Silva et al. [
5] in terms of the recall values for the two-class classification. For all of the analyzed metrics, the proposed method was also superior to the method proposed by Isidoro et al. [
6] for the two- and three-class classifications.
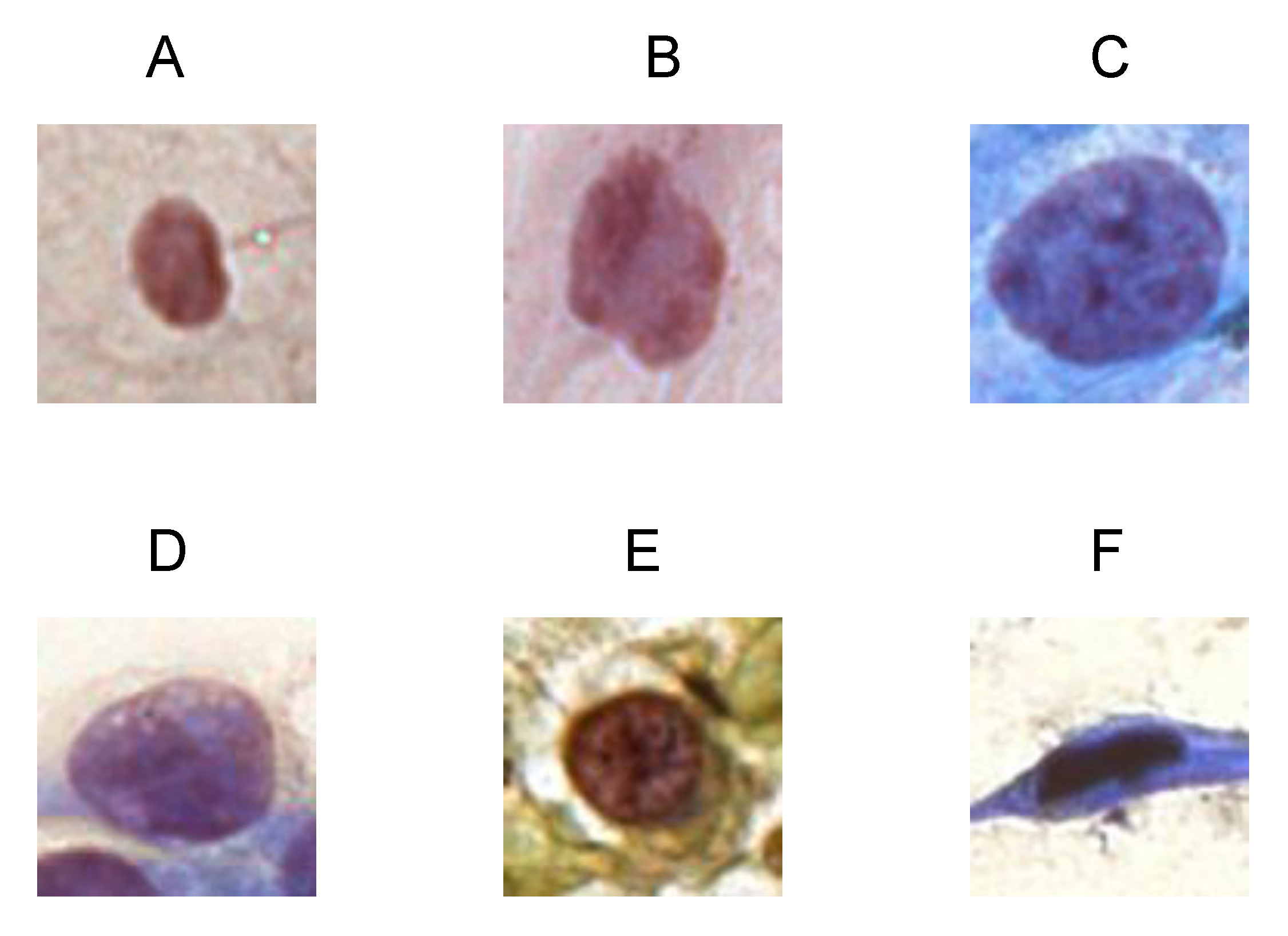
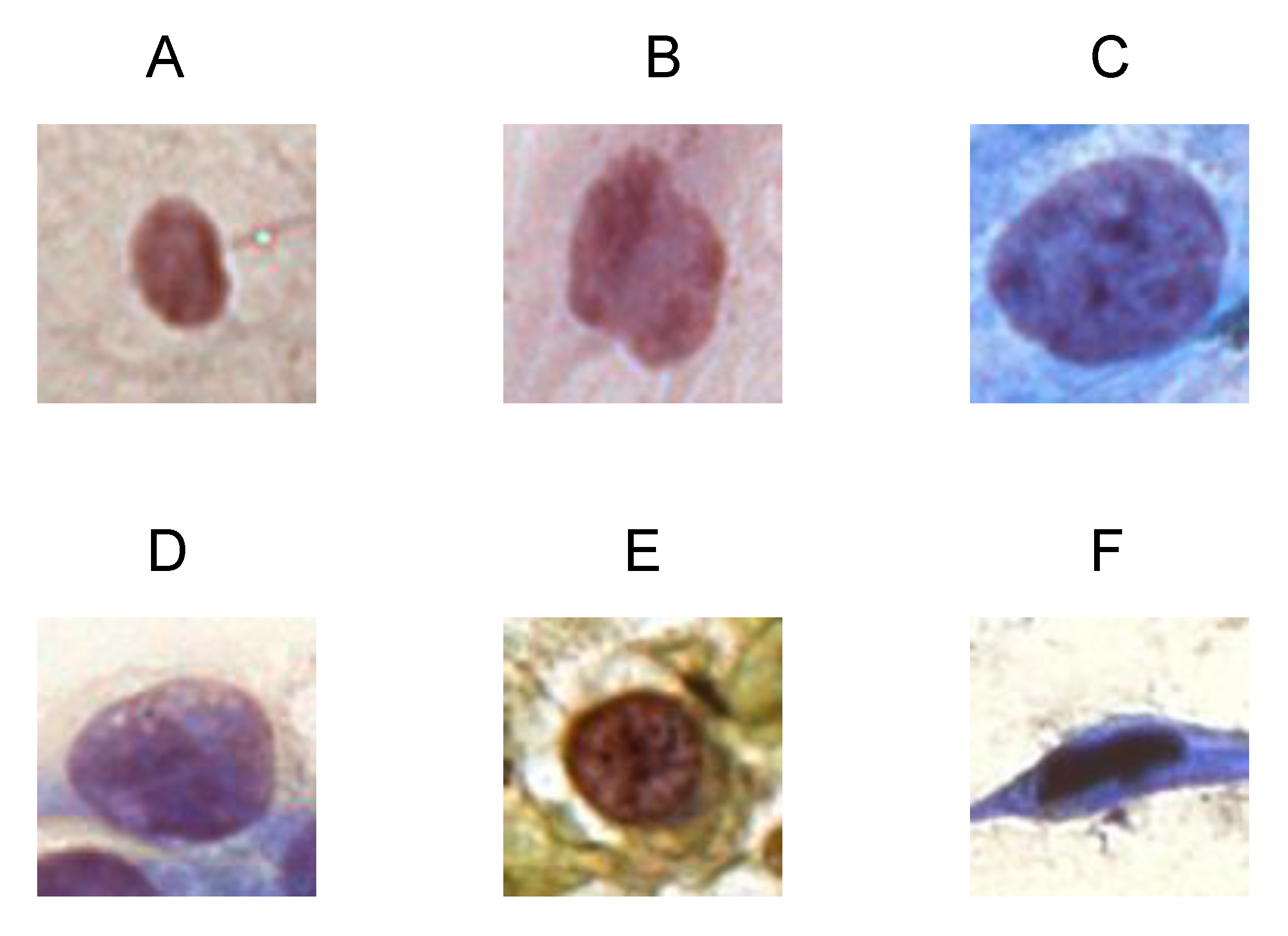
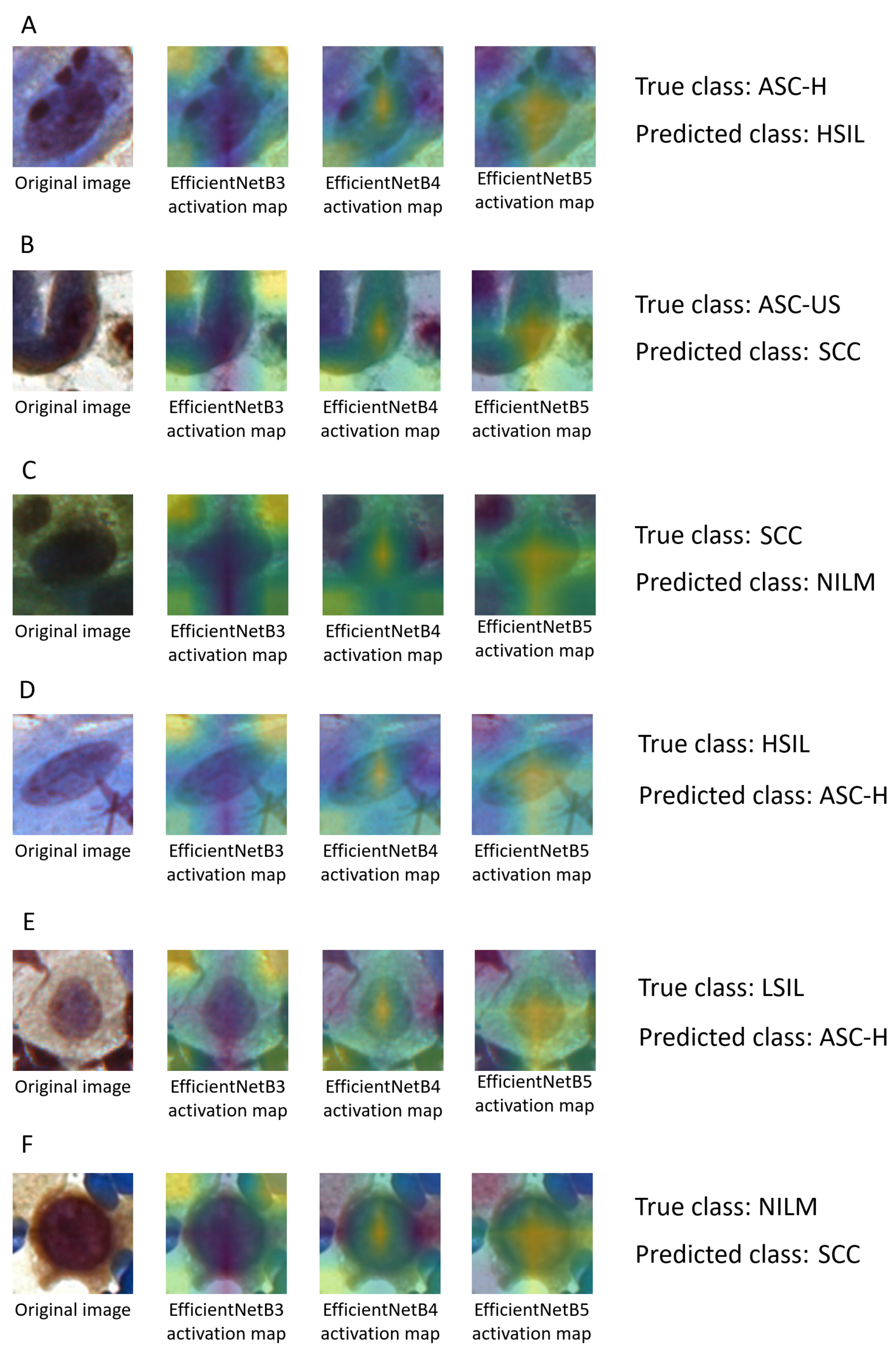
Figure 8 presents the original images and their activation maps according to each architecture used in the ensemble for the six-class classification. All images are examples of incorrect predictions of the classifier.
Figure 8 also presents the true and predicted classes.
The cytopathologists of our team performed an analysis of these erroneous classifications. They realized that the information that could contribute to a more assertive classification is related to the morphology of the cytoplasm, such as its area, circularity, and the nuclear-to-cytoplasmic ratio. Therefore, when the selected regions were presented to the cytopathologists, the final diagnoses tended to be precise.
In addition, notice that routine laboratory smear analysis is based on all images and not on isolated images. In real cases, a cytopathologist analyzes several characteristics present in the smear; thus, a set of altered cells is usually necessary to reach a diagnostic decision. Therefore, not identifying a few cells will not jeopardize the result because others will still be identified and will support the cytopathologist’s decision. Thus, as the number of false negatives in this work is relatively low, we expect that the proposed method would be even more helpful for a general analysis of a smear.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}