
Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices?

 ,
, 
 , ,
, , 
 ,
, 
Abstract
:1. Introduction
Background and Related Work
2. Materials and Methods
2.1. Visor Magnification
2.2. Liquid Lens Lookup Table Calibration
2.3. Testing Set Up
2.3.1. Quantitative Test
2.3.2. Qualitative Usability Tests
3. Results
3.1. Quantitative Test Results
3.2. Qualitative Test Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Schoeffl, H.; Lazzeri, D.; Schnelzer, R.; Froschauer, S.M.; Huemer, G.M. Optical magnification should be mandatory for microsurgery: Scientific basis and clinical data contributing to quality assurance. Arch. Plast. Surg. 2013, 40, 104–108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wells, T.S.; Yang, S.; MacLachlan, R.A.; Handa, J.T.; Gehlbach, P.; Riviere, C. Comparison of Baseline Tremor under Various Microsurgical Conditions. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 1482–1487. [Google Scholar] [CrossRef] [Green Version]
- Condino, S.; Carbone, M.; Piazza, R.; Ferrari, M.; Ferrari, V. Perceptual Limits of Optical See-Through Visors for Augmented Reality Guidance of Manual Tasks. IEEE Trans. Biomed. Eng. 2019, 67, 411–419. [Google Scholar] [CrossRef]
- Campbell, F.W. The Depth of Field of the Human Eye. Opt. Acta Int. J. Opt. 1957, 4, 157–164. [Google Scholar] [CrossRef]
- James, T.; Gilmour, A.S. Magnifying Loupes in Modern Dental Practice: An Update. Dent. Update 2010, 37, 633–636. [Google Scholar] [CrossRef] [PubMed]
- Baker, J.M.; Meals, R.A. A practical guide to surgical loupes. J. Hand Surg. 1997, 22, 967–974. [Google Scholar] [CrossRef]
- Rolland, J.P.; Fuchs, H. Optical Versus Video See-Through Head-Mounted Displays in Medical Visualization. Presence 2000, 9, 287–309. [Google Scholar] [CrossRef]
- Birkfellner, W.; Figl, M.; Huber, K.; Watzinger, F.; Wanschitz, F.; Hanel, R.; Wagner, A.; Rafolt, D.; Ewers, R.; Bergmann, H. The Varioscope AR—A Head-Mounted Operating Microscope for Augmented Reality. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2000, Pittsburgh, PA, USA, 11–14 October 2000; pp. 869–877. [Google Scholar]
- Faulhaber. Stepper Motors Bring Surgical Microscope into Focus. 4 March 2020. Available online: https://www.micromo.com/applications/optics-photonic-applications/life-optics-vario (accessed on 23 April 2020).
- Martin-Gonzalez, A.; Heining, S.M.; Navab, N. Head-Mounted Virtual Loupe with Sight-based Activation for Surgical Applications. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 207–208. [Google Scholar] [CrossRef]
- Fincham, E.F.; Walton, J. The reciprocal actions of accommodation and convergence. J. Physiol. 1957, 137, 488–508. [Google Scholar] [CrossRef]
- Lockhart, T.E.; Shi, W. Effects of age on dynamic accommodation. Ergonomics 2010, 53, 892–903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bharadwaj, S.R.; Schor, C.M. Acceleration characteristics of human ocular accommodation. Vis. Res. 2005, 45, 17–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Plainis, S.; Charman, W.N.; Pallikaris, I.G. The physiologic mechanism of accommodation. Cataract Refract. Surg. Today Eur. 2014, 40, 23–28. [Google Scholar]
- Zhang, Y.P.; Liu, L.Y.; Gong, W.T.; Yu, H.H.; Wang, W.; Zhao, C.Y.; Wang, P.; Ueda, T. Autofocus System and Evaluation Methodologies: A Literature Review. Sens. Mater. 2018, 30, 1165–1174. [Google Scholar] [CrossRef]
- Han, J.W.; Kim, J.H.; Lee, H.T.; Ko, S.J. A Novel Training Based Auto-Focus for Mobile-Phone Cameras. IEEE Trans. Consum. Electron. 2011, 57, 232–238. [Google Scholar]
- Chen, C.M.; Hong, C.M.; Chuang, H.C. Efficient auto-focus algorithm utilizing discrete difference equation prediction model for digital still cameras. IEEE Trans. Consum. Electron. 2006, 52, 1135–1143. [Google Scholar] [CrossRef]
- Rahman, M.T.; Kehtarnavaz, N. Real-Time Face-Priority Auto Focus for Digital and Cell-Phone Cameras. IEEE Trans. Consum. Electron. 2008, 54, 1506–1513. [Google Scholar] [CrossRef]
- Chen, C.Y.; Hwang, R.C.; Chen, Y.J. A passive auto-focus camera control system. Appl. Soft Comput. 2010, 10, 296–303. [Google Scholar] [CrossRef]
- Wang, Y.R.; Feng, H.J.; Xu, Z.H.; Li, Q.; Chen, Y.T.; Cen, M. Fast auto-focus scheme based on optical defocus fitting model. J. Mod. Opt. 2018, 65, 858–868. [Google Scholar] [CrossRef]
- Chan, C.C.; Huang, S.K.; Chen, H.H. Enhancement of Phase Detection for Autofocus. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 41–45. [Google Scholar]
- Giffgaff. How Does Autofocus Work on Your Smartphone? Available online: https://www.giffgaff.com/blog/how-does-auto-focus-work-on-your-smartphone/ (accessed on 17 March 2020).
- Burton, J.C.; Huisman, F.M.; Alison, P.; Rogerson, D.; Taborek, P. Experimental and Numerical Investigation of the Equilibrium Geometry of Liquid Lenses. Langmuir ACS J. Surf. Colloids 2010, 26, 15316–15324. [Google Scholar] [CrossRef]
- Berge, B. Liquid lens technology: Principle of electrowetting based lenses and applications to imaging. In Proceedings of the 18th IEEE International Conference on Micro Electro Mechanical Systems, Miami Beach, FL, USA, 30 January–3 February 2005; pp. 227–230. [Google Scholar] [CrossRef] [Green Version]
- Berge, B.; Peseux, J. Variable focal lens controlled by an external voltage: An application of electrowetting. Eur. Phys. J. E 2000, 3, 159–163. [Google Scholar] [CrossRef]
- Saurei, L.; Mathieu, G.; Berge, B. Design of an autofocus lens for VGA ¼-in. CCD and CMOS sensors. Proc. SPIE Int. Soc. Opt. Eng. 2004, 5249, 288–296. [Google Scholar] [CrossRef]
- Media, P. Cameras with Liquid Lens Control. Available online: https://www.photonics.com/Products/Cameras_with_Liquid_Lens_Control/pr63981 (accessed on 18 February 2020).
- Pixelink. Autofocus Cameras. Available online: https://pixelink.com/products/autofocus/usb-30/ (accessed on 19 February 2020).
- E-con System. See3CAM_30—Liquid Lens USB3.1 Gen1 Camera Board. Available online: https://www.e-consystems.com/ar0330-liquid-lens-usb-camera-board.asp (accessed on 18 February 2020).
- Jamieson, S. Likert scales: How to (ab)use them. Med. Educ. 2004, 38, 1217–1218. [Google Scholar] [CrossRef]
- Potter, M.C.; Wyble, B.; Hagmann, C.E.; McCourt, E.S. Detecting meaning in RSVP at 13 ms per picture. Atten. Percept. Psychophys. 2014, 76, 270–279. [Google Scholar] [CrossRef] [Green Version]
- van Krevelen, D.W.F.; Poelman, R. A Survey of Augmented Reality: Technologies, Applications, and Limitations. Int. J. Virtual Real. 2010, 9, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wang, Q.; Chen, H.; Song, X.; Tang, H.; Tian, M. An overview of augmented reality technology. J. Phys. Conf. Ser. 2019, 1237, 022082. [Google Scholar] [CrossRef]
- Condino, S.; Fida, B.; Carbone, M.; Cercenelli, L.; Badiali, G.; Ferrari, V.; Cutolo, A.F. Wearable Augmented Reality Platform for Aiding Complex 3D Trajectory Tracing. Sensors 2020, 20, 1612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cercenelli, L.; Carbone, M.; Condino, S.; Cutolo, F.; Marcelli, E.; Tarsitano, A.; Marchetti, C.; Ferrari, V.; Badiali, G. The Wearable VOSTARS System for Augmented Reality-Guided Surgery: Preclinical Phantom Evaluation for High-Precision Maxillofacial Tasks. J. Clin. Med. 2020, 9, 3562. [Google Scholar] [CrossRef] [PubMed]
- Umebayashi, D.; Yamamoto, Y.; Nakajima, Y.; Fukaya, N.; Hara, M. Augmented Reality Visualization-guided Microscopic Spine Surgery: Transvertebral Anterior Cervical Foraminotomy and Posterior Foraminotomy. J. Am. Acad. Orthop. Surg. Glob. Res. Rev. 2018, 2, e008. [Google Scholar] [CrossRef]
- Qian, L.; Song, T.; Unberath, M.; Kazanzides, P. AR-Loupe: Magnified Augmented Reality by Combining an Optical See-Through Head-Mounted Display and a Loupe. IEEE Trans. Vis. Comput. Graph. 2020, 1. [Google Scholar] [CrossRef]




{kind=link}
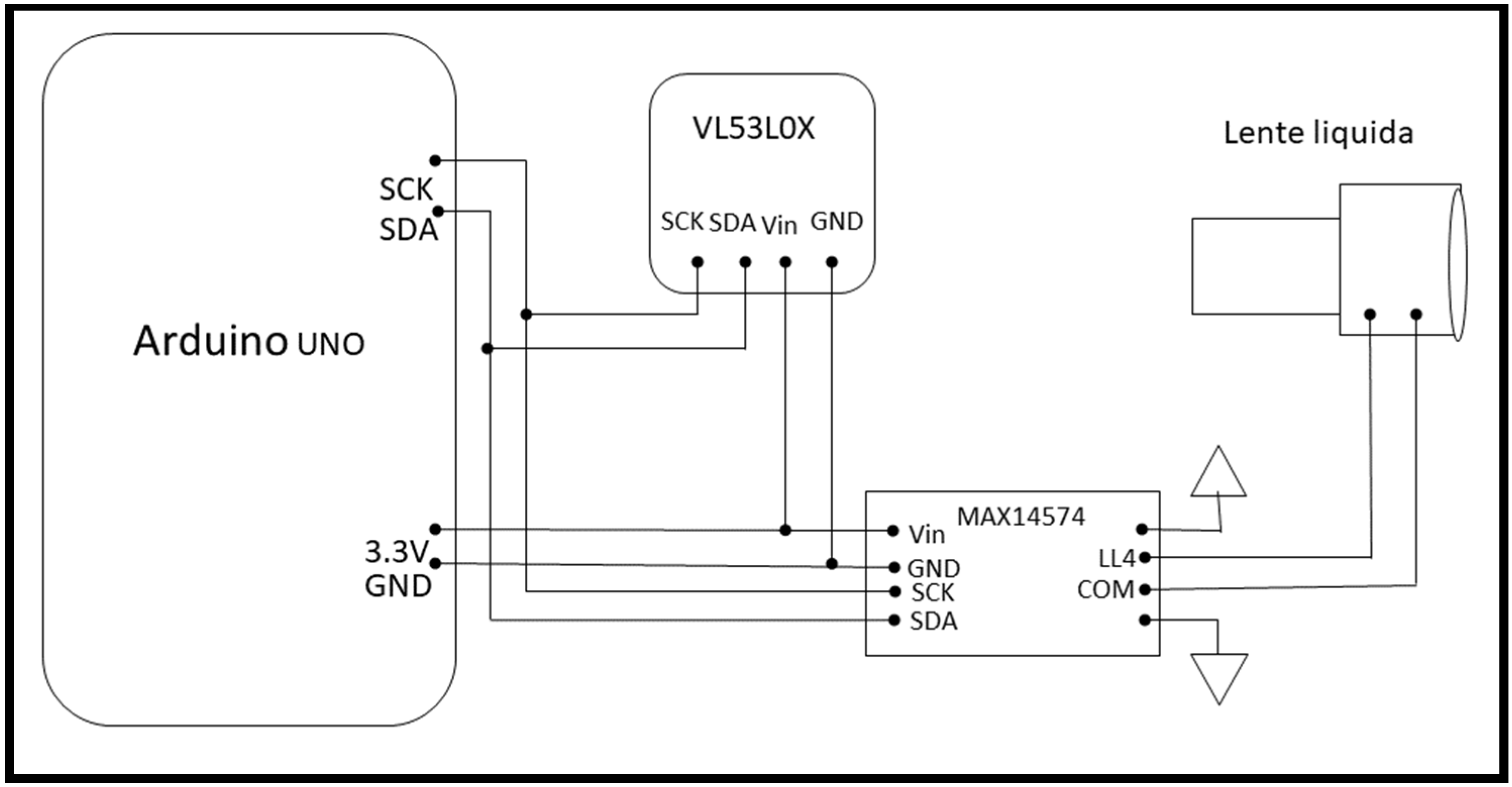{kind=link}
{kind=link}
| Near to Far | Far to Near | |||
|---|---|---|---|---|
| Time (ms) | Frame | Time (ms) | Frame | |
| Mean * | 130 | 11 | 131 | 11 |
| Median | 129 | 11 | 128 | 11 |
| 25°–75° | 116–140 | 10–12 | 117–148.5 | 10–12.75 |
| Range | 93–175 | 8–15 | 93–175 | 8–18 |
| First Task | Third Task | ||||
|---|---|---|---|---|---|
| # | Statements | Median IQR (25°–75°) | p-Value | Median IQR (25°–75°) | p-Value |
| 1 | The object in the scene is always in focus. | 4 (4–5) | 0.003 | 4 (2–4) | 0.157 |
| 2 | There is no latency during the focusing. | 4 (4–5) | 0.000 | 4 (4–4) | 0.018 |
| 3 | I do not perceive any distortion of the scene (i.e., double vision). | 2 (2–4) | 0.637 | 4 (2–4) | 0.059 |
| 4 | The image resolution and quality of the. HMD device is suitable for surgical practice. | 3 (3–3) | 1.000 | 3 (3–3) | 0.020 |
| 5 | The latency between the real image and the image on the display is suitable for surgical practice. | 4 (3–4) | 0.001 | 4 (3–4) | 0.001 |
| 6 | If the HMD device’s zoom was greater (i.e., 2.5× or more), I would use it in the surgical practice (surgeons only). | 4 (3.5–4.5) | 0.046 | 4 (3.75–4) | 0.025 |
| 7 | The HMD device provides a stereoscopic view. | 4 (4–4) | 0.001 | 4 (4–5) | 0.000 |
| First Task | Third Task | ||
|---|---|---|---|
| # | Statements | p-Value | p-Value |
| 1 | The object in the scene is always in focus. | 0.481 | 1.000 |
| 2 | There is no latency during the focusing. | 0.386 | 0.120 |
| 3 | I do not perceive any distortion of the scene (i.e., double vision). | 0.402 | 0.961 |
| 4 | The image resolution and quality of the HMD device is suitable for surgical practice. | 0.959 | 0.262 |
| 5 | The latency between the real image and the image on the display is suitable for surgical practice. | 0.106 | 0.146 |
| 6 | The HMD device provides a stereoscopic view. | 0.811 | 0.363 |
| First Task | Third Task | ||
|---|---|---|---|
| # | Statements | p-Value | p-Value |
| 1 | The object in the scene is always in focus | 0.646 | 0.467 |
| 2 | There is no latency during the focusing | 0.816 | 0.394 |
| 3 | I do not perceived any distortion of the scene (i.e., double vision) | 0.719 | 0.137 |
| 4 | The image resolution and quality of the HMD device is suitable for surgical practice | 0.238 | 0.576 |
| 5 | The latency between real image and the image on the display is suitable for surgical practice | 0.269 | 0.373 |
| 6 | The HMD device provide a stereoscopic view | 0.650 | 0.323 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carbone, M.; Domeneghetti, D.; Cutolo, F.; D’Amato, R.; Cigna, E.; Parchi, P.D.; Gesi, M.; Morelli, L.; Ferrari, M.; Ferrari, V. Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices? J. Imaging 2021, 7, 138. https://doi.org/10.3390/jimaging7080138
Carbone M, Domeneghetti D, Cutolo F, D’Amato R, Cigna E, Parchi PD, Gesi M, Morelli L, Ferrari M, Ferrari V. Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices? Journal of Imaging. 2021; 7(8):138. https://doi.org/10.3390/jimaging7080138
Chicago/Turabian StyleCarbone, Marina, Davide Domeneghetti, Fabrizio Cutolo, Renzo D’Amato, Emanuele Cigna, Paolo Domenico Parchi, Marco Gesi, Luca Morelli, Mauro Ferrari, and Vincenzo Ferrari. 2021. "Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices?" Journal of Imaging 7, no. 8: 138. https://doi.org/10.3390/jimaging7080138
APA StyleCarbone, M., Domeneghetti, D., Cutolo, F., D’Amato, R., Cigna, E., Parchi, P. D., Gesi, M., Morelli, L., Ferrari, M., & Ferrari, V. (2021). Can Liquid Lenses Increase Depth of Field in Head Mounted Video See-Through Devices? Journal of Imaging, 7(8), 138. https://doi.org/10.3390/jimaging7080138