
Surreptitious Adversarial Examples through Functioning QR Code


Abstract
:1. Introduction
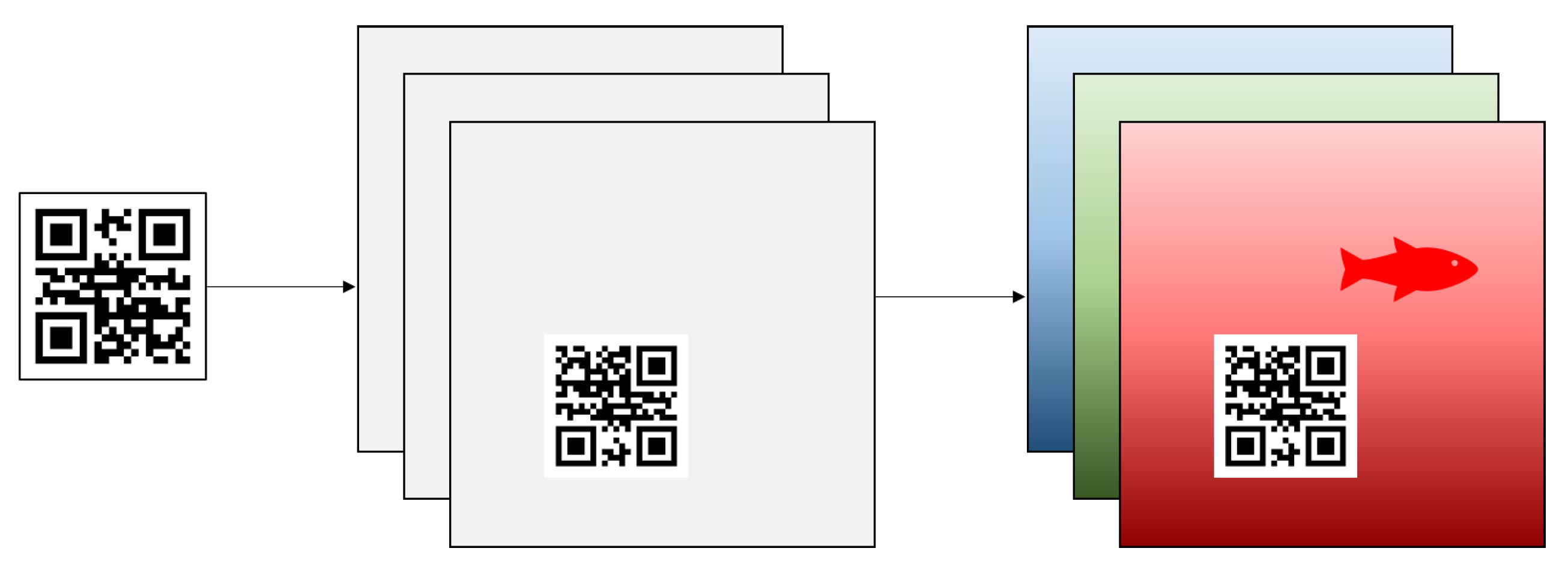
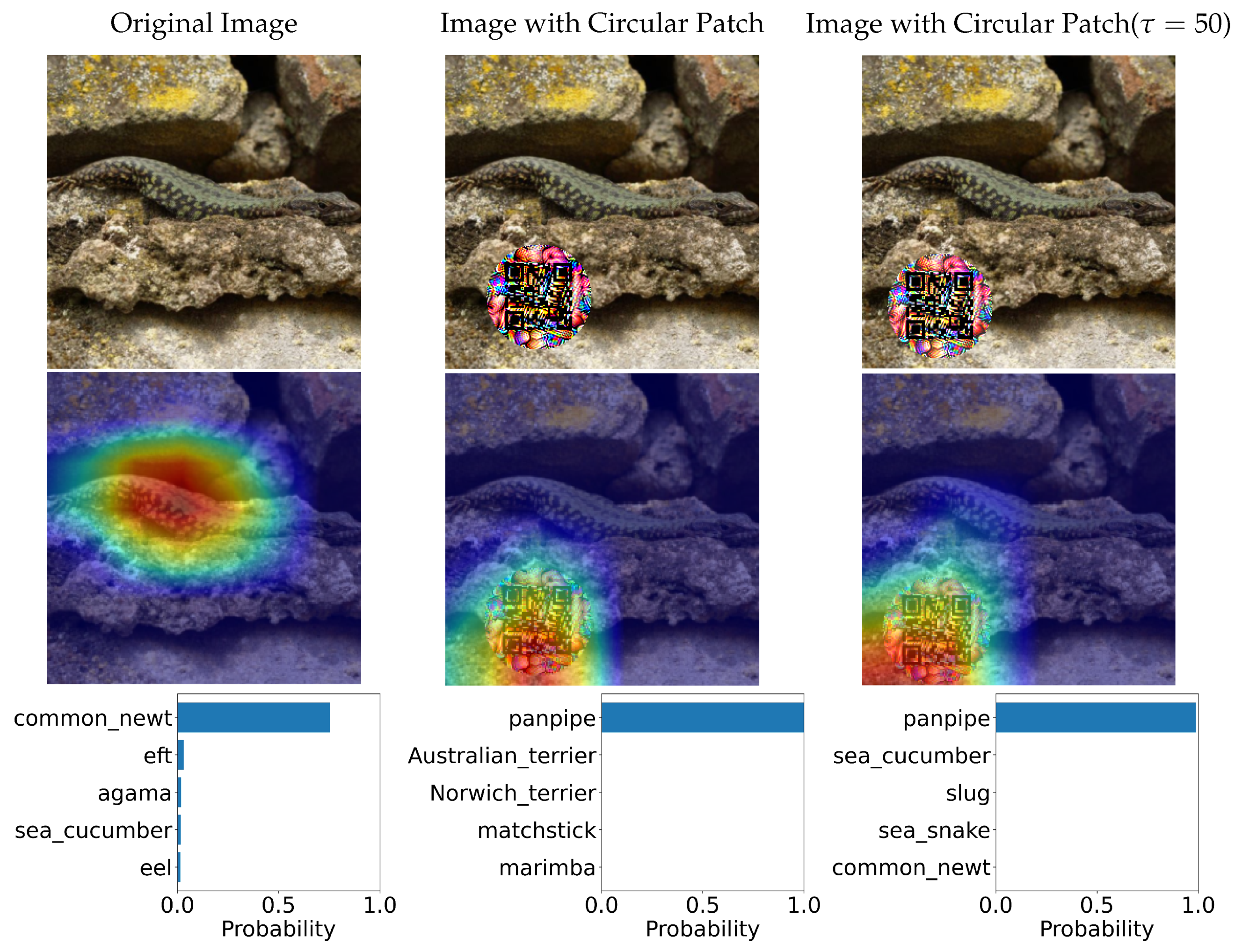
- Expand the adversarial patch concept by implementing the patch with a scan-ready QR code, in which this approach has yet to be explored to our knowledge.
- Utilize the QR code pattern to improve the feasibility and robustness of physical adversarial examples.
- Explore methods to allow adversarial examples to carry out additional information for usage in other applications, in addition to its primary purpose as an adversarial attack tool.
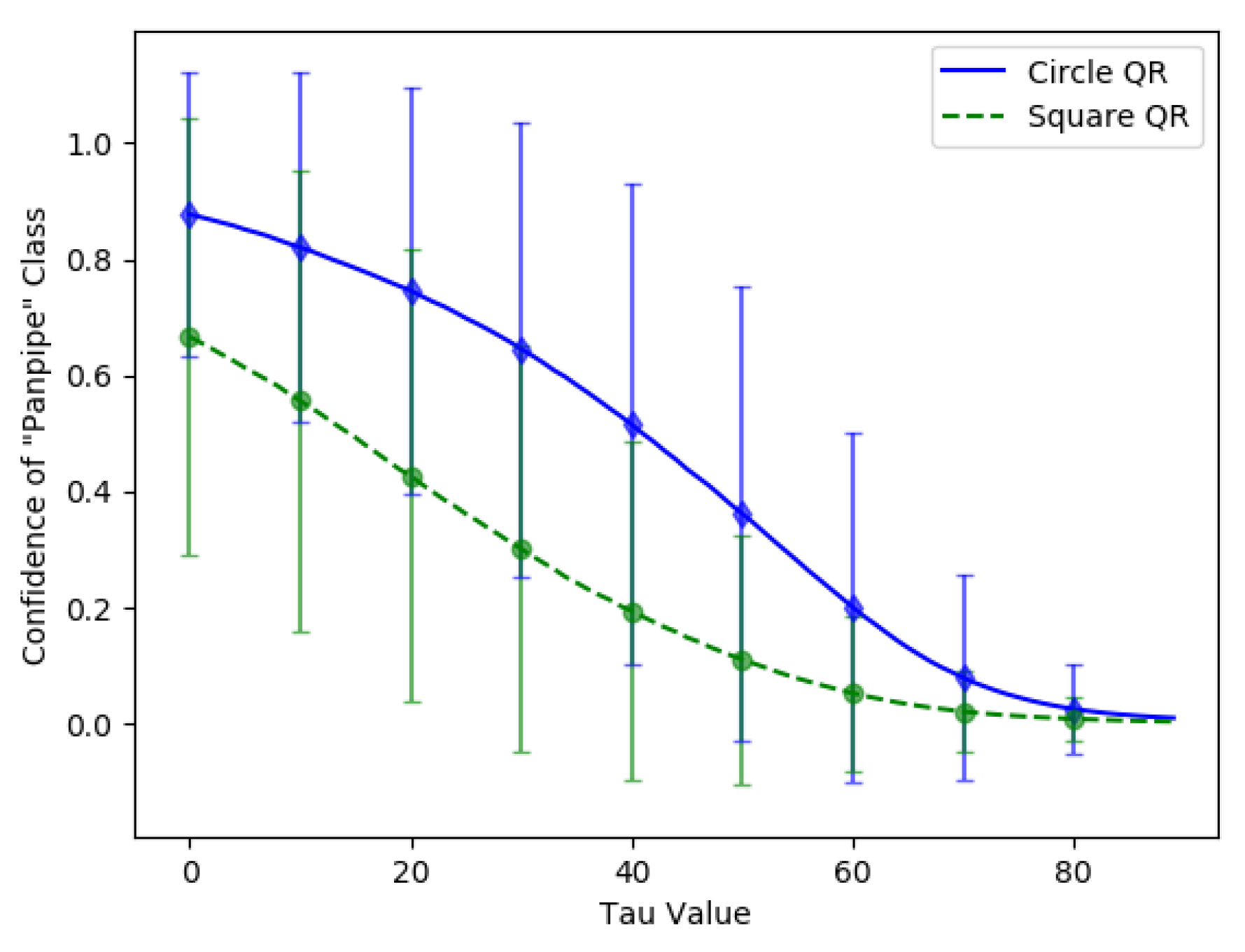
- Study possible differences between square-shaped and circular-shaped adversarial QR patches in terms of adversarial efficacy.
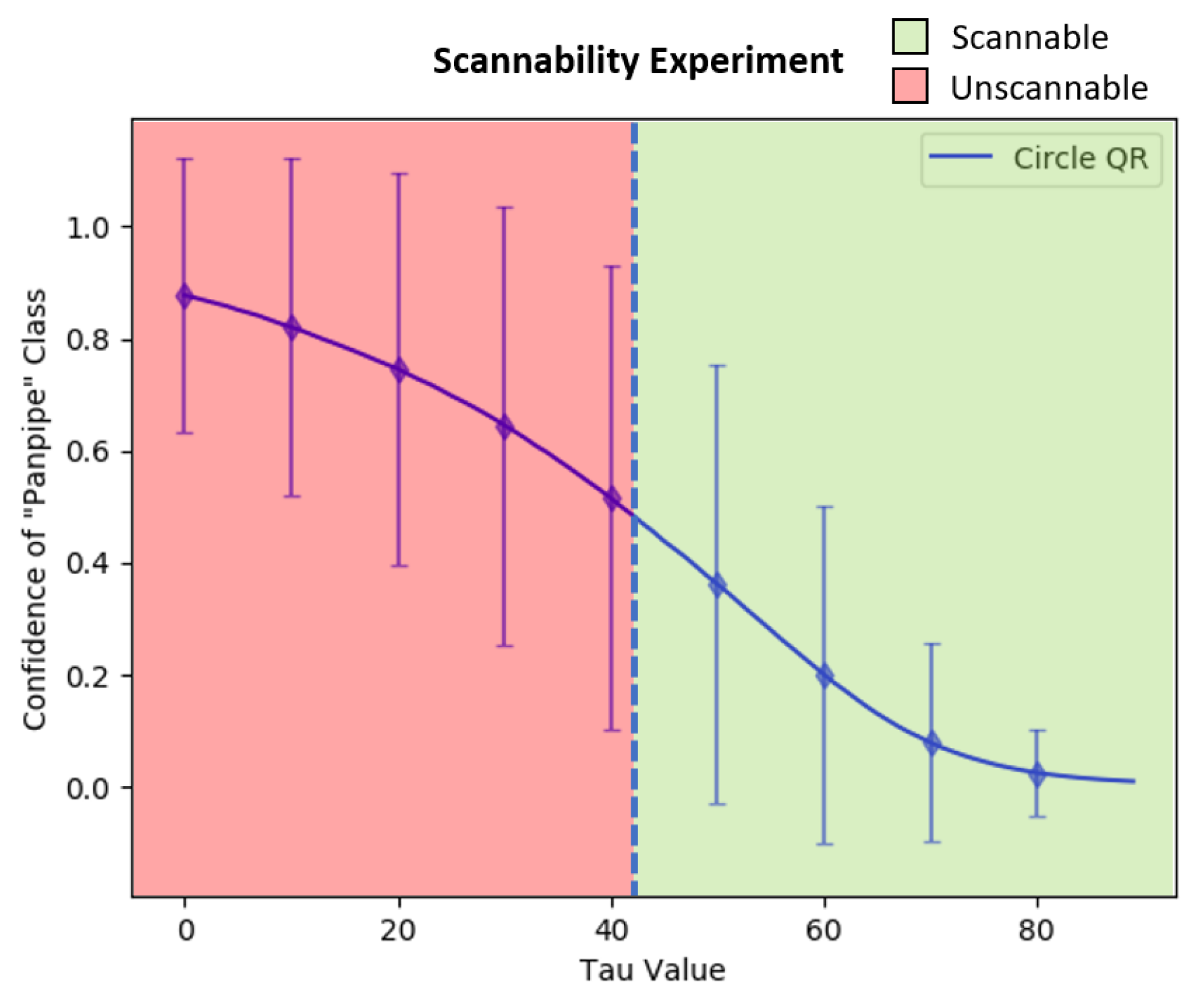
- Investigate the optimal brightness values for the adversarial QR patch’s dark parts in order to maximize the adversarial efficacy and the patch’s scannability toward a QR scanner.
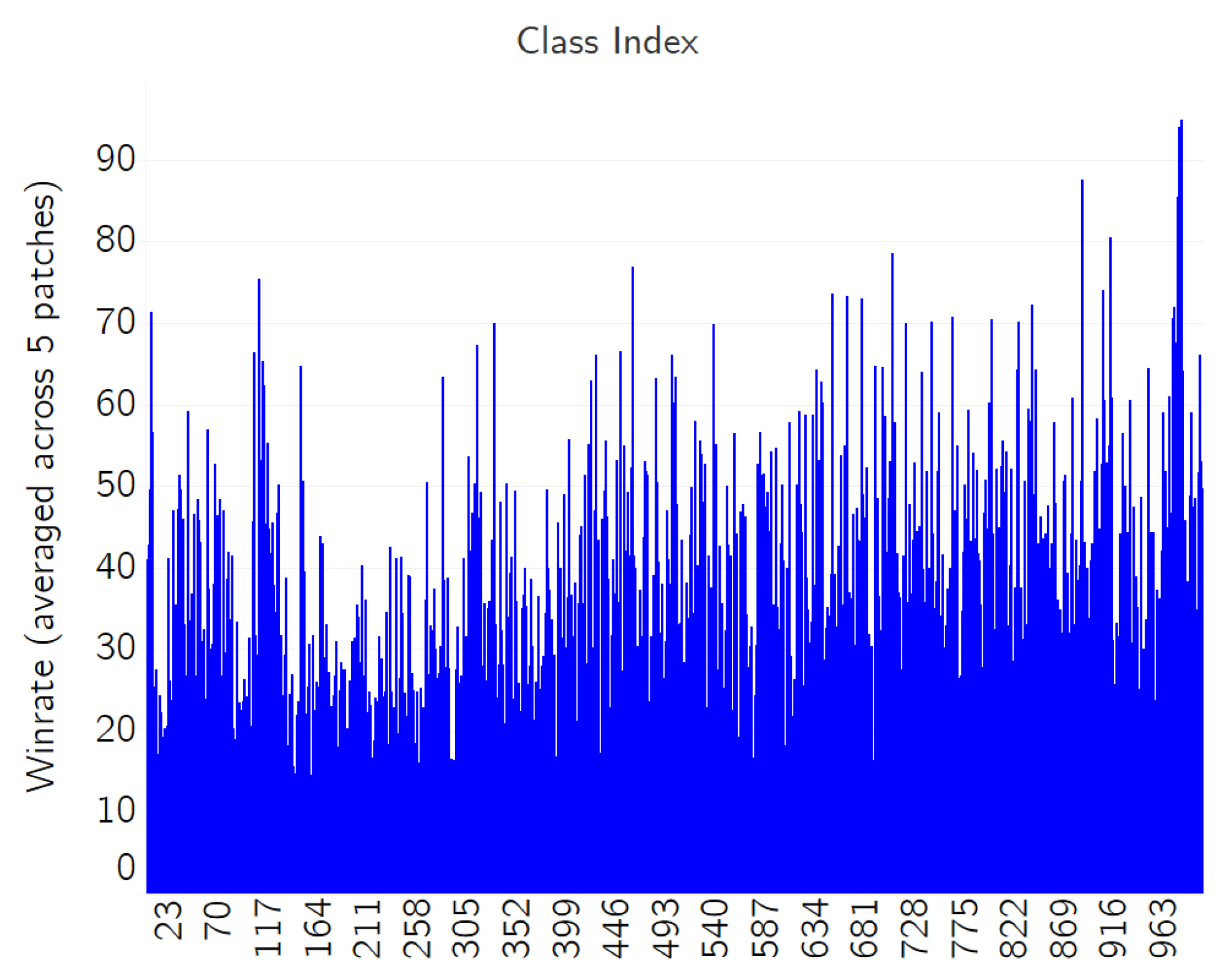
- Investigate whether particular classes of images are more resistant or vulnerable to the QR patch attacks.
- Investigate the transferability of QR patch attacks on various deep learning models.
2. Materials and Methods
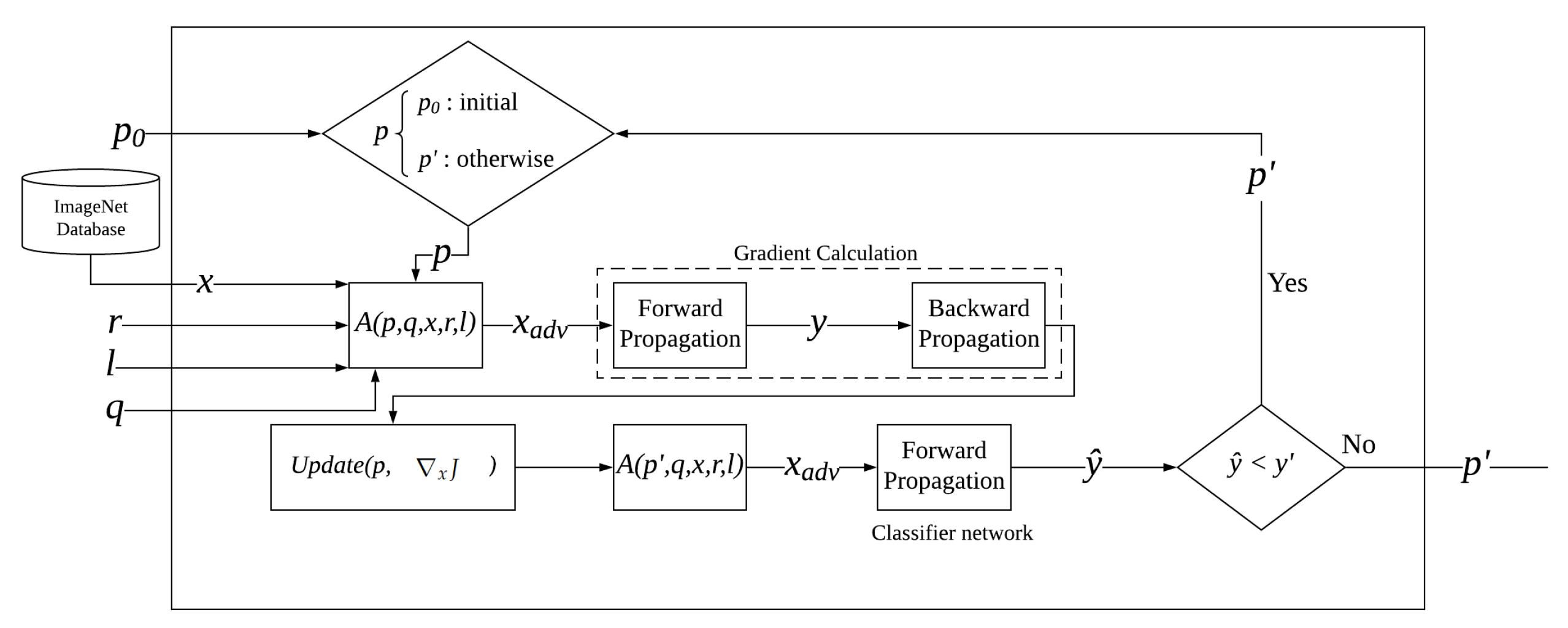
2.1. Masked Patch Creation
2.2. Patch Training Process
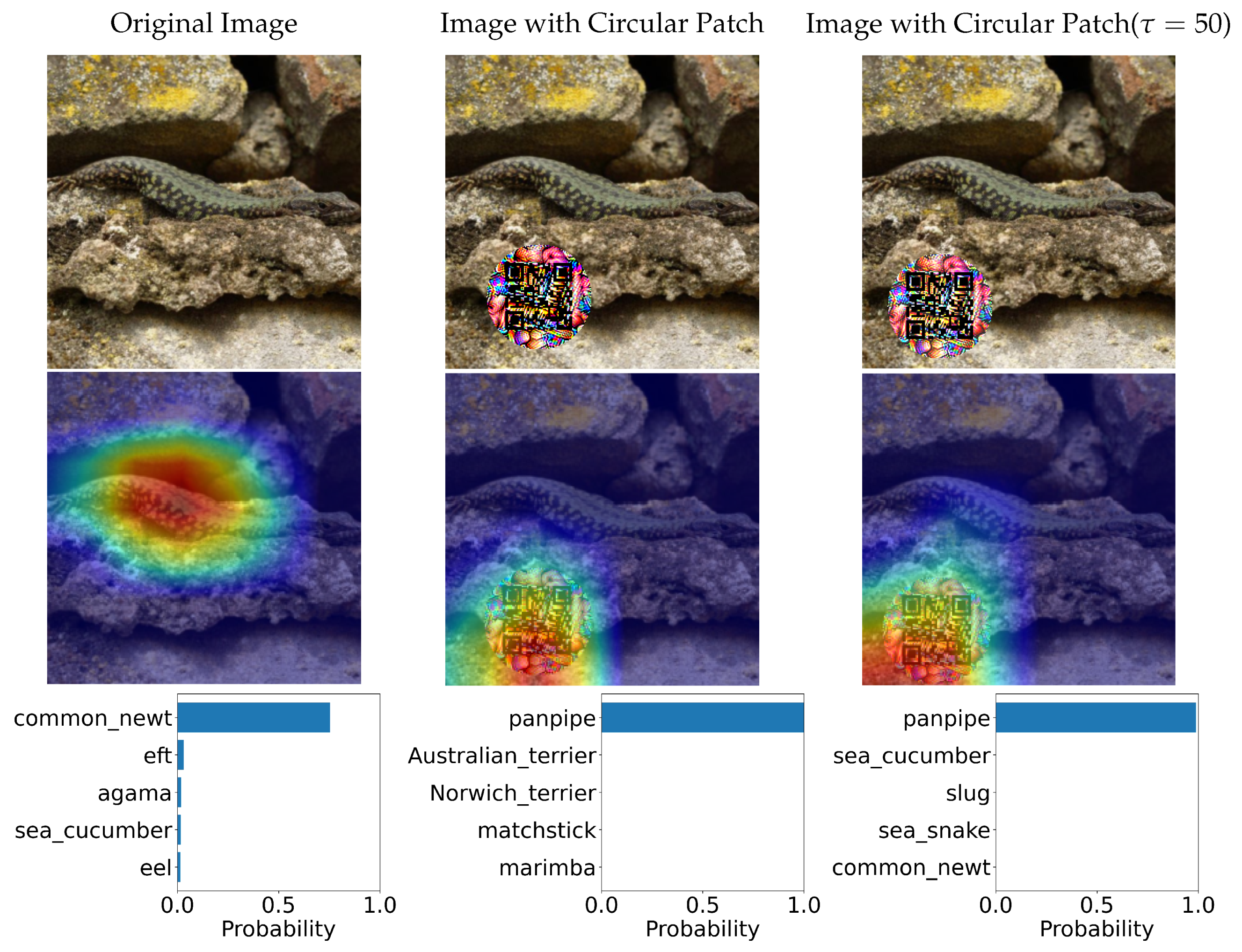
2.3. Circular-Shaped QR Adversarial Patch Implementation
2.4. QR Code Visibility Improvement by Color Intensity Adjustment
3. Results
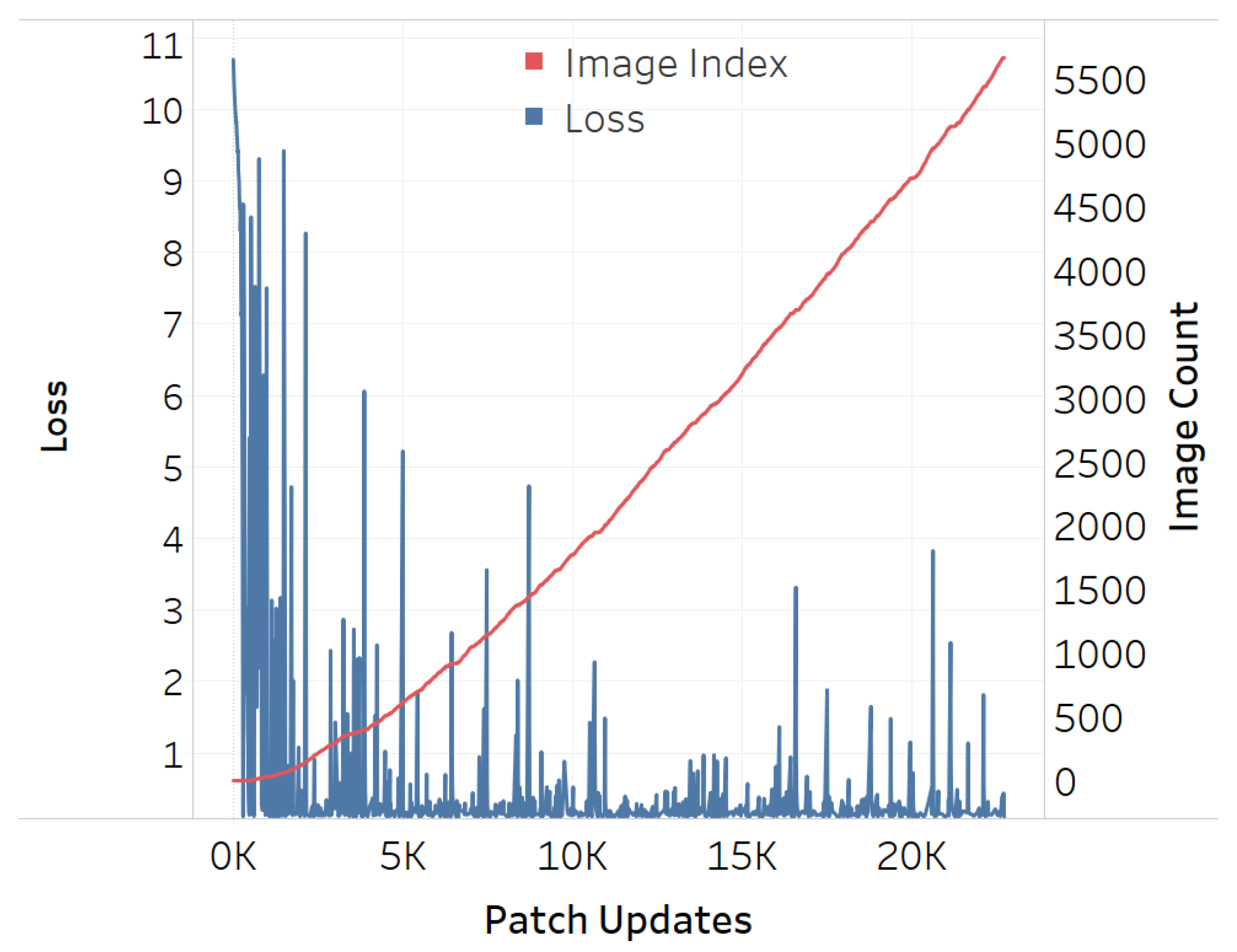
3.1. Initialization and Parameter Settings
3.2. Adversarial Efficacy of Advsersarial QR Patch
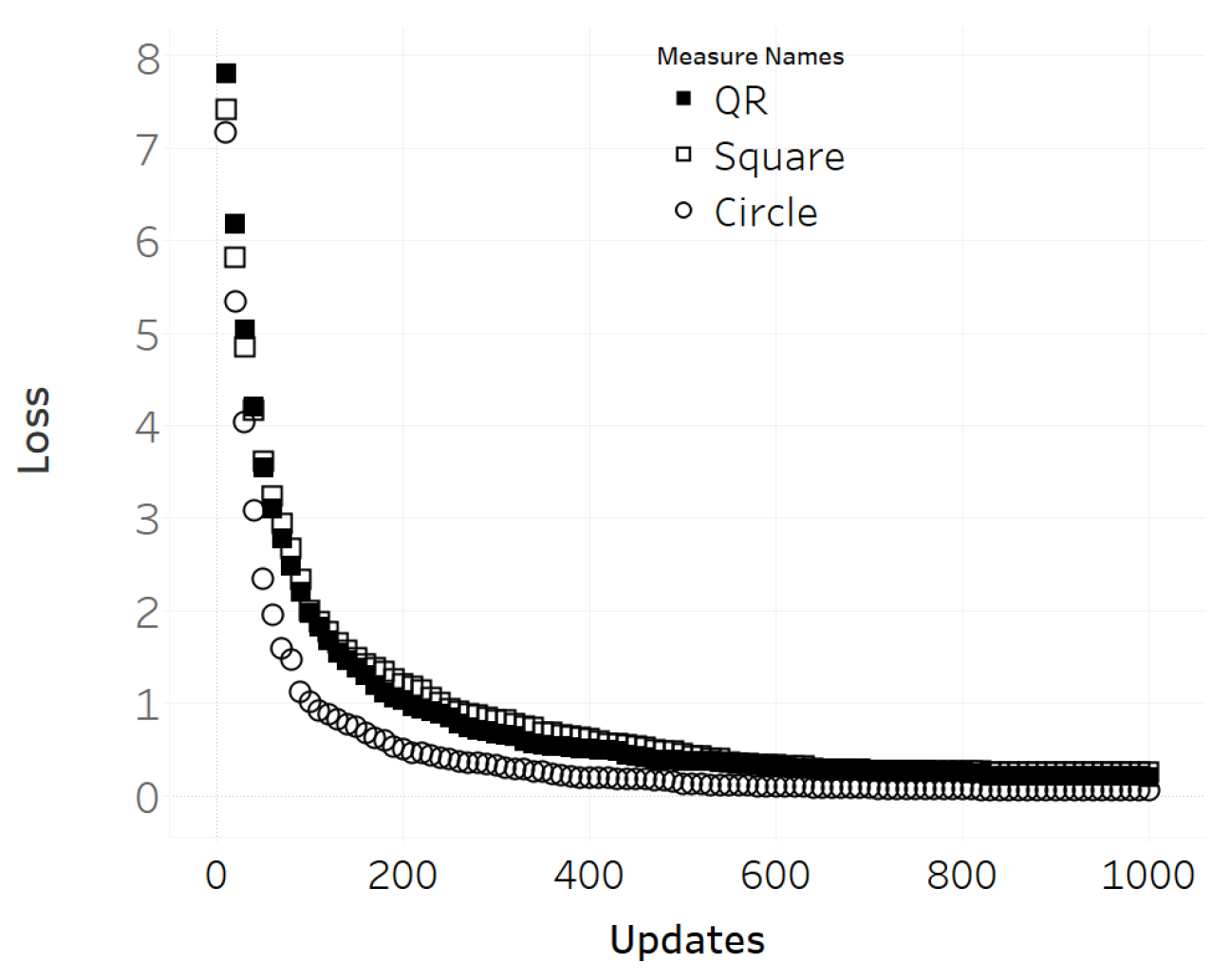
3.3. Variation of Adversarial QR Patch Conditions
3.4. Trade-Off between Adversarial Efficacy and Scannability
3.5. Class-Specific Adversarial Performance
3.6. Adversarial Performance Comparison against Other Learning Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Suciu, O.; Marginean, R.; Kaya, Y.; Daume, H., III; Dumitras, T. When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; USENIX Association: Baltimore, MD, USA, 2018; pp. 1299–1316. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Storcheus, D.; Rostamizadeh, A.; Kumar, S. A Survey of Modern Questions and Challenges in Feature Extraction. In Proceedings of the International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS, Montreal, QC, Canada, 11–12 December 2015; Volume 44, pp. 1–18. [Google Scholar]
- Bengio, Y.; Lecun, Y. Scaling Learning Algorithms toward AI. In Large-Scale Kernel Machines; Bottou, L., Chapelle, O., DeCoste, D., Weston, J., Eds.; MIT Press: Cambridge, MA, USA, 2007; pp. 321–359. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Le, Q.V.; Ranzato, M.; Monga, R.; Devin, M.; Chen, K.; Corrado, G.S.; Dean, J.; Ng, A.Y. Building high-level features using large scale unsupervised learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Doha, Qatar, 12–15 November 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report TR-2009; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Dalvi, N.; Domingos, P.; Mausam; Sanghai, S.; Verma, D. Adversarial classification. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Seattle, WA, USA, 22–2August 2004; pp. 99–108. [Google Scholar] [CrossRef] [Green Version]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security; ACM: New York, NY, USA, 2016; pp. 1528–1540. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Zhang, G.; Liu, S.; Fan, Q.; Sun, M.; Chen, H.; Chen, P.Y.; Wang, Y.; Lin, X. Evading Real-Time Person Detectors by Adversarial T-Shirt. 2019. Available online: http://xxx.lanl.gov/abs/1910.11099 (accessed on 27 February 2022).
- Bhowmik, P.; Pantho, M.J.H.; Bobda, C. Bio-inspired smart vision sensor: Toward a reconfigurable hardware modeling of the hierarchical processing in the brain. J. Real-Time Image Process. 2021, 18, 157–174. [Google Scholar] [CrossRef]
- Bhowmik, P.; Hossain Pantho, J.; Mandebi Mbongue, J.; Bobda, C. ESCA: Event-Based Split-CNN Architecture with Data-Level Parallelism on UltraScale+ FPGA. In Proceedings of the 2021 IEEE 29th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Orlando, FL, USA, 9–12 May 2021; pp. 176–180. [Google Scholar] [CrossRef]
- Hayes, J. On Visible Adversarial Perturbations & Digital Watermarking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chindaudom, A.; Sumongkayothin, K.; Siritanawan, P.; Kotani, K. AdversarialQR: An adversarial patch in QR code format. In Proceedings of the Proceedings of Imaging, Vision & Pattern Recognition, Fukuoka, Japan, 26–29 August 2020. [Google Scholar]
- Chindaudom, A.; Sukasem, P.; Benjasirimonkol, P.; Sumonkayothin, K.; Siritanawan, P.; Kotani, K. AdversarialQR Revisited: Improving the Adversarial Efficacy. In Proceedings of the Neural Information Processing—27th International Conference, ICONIP, Bangkok, Thailand, 18–22 November 2020; Proceedings, Part IV; Communications in Computer and Information Science. Yang, H., Pasupa, K., Leung, A.C., Kwok, J.T., Chan, J.H., King, I., Eds.; Springer: Berlin, Germany, 2020; Volume 1332, pp. 799–806. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patch | Class Index: Label | Sample Images |
|---|---|---|
 | 365: Orangutan |  |
 | 404: Airliner |  |
 | 405: Airship |  |
 | 602: High bar |  |
 | 605: iPod |  |
| Index | Class | Winrate (%) | Sample Images |
|---|---|---|---|
| 979 | Valley | 95 |  |
| 976 | Foreland | 94 |  |
| 978 | Seashore | 89.30 |  |
| 885 | Velvet | 87.65 |  |
| 975 | Lakeside | 85.45 |  |
| .. | .. | .. | .. |
| .. | .. | .. | .. |
| .. | .. | .. | .. |
| 181 | Bedlington terrier | 7.06 |  |
| 779 | School bus | 6.55 |  |
| 251 | Dalmatian | 5.97 |  |
| 323 | Monarch | 5.25 |  |
| 685 | Odometer | 4.86 |  |
| Rank | Index | Name | ResNet50 | VGG16 | InceptionV3 | Average | Sample Images |
|---|---|---|---|---|---|---|---|
| 1 | 996 | Maitake | 92.59 | 100.00 | 71.43 | 88.01 |  |
| 2 | 979 | Valley | 80.00 | 96.30 | 85.94 | 87.41 |  |
| 3 | 976 | Foreland | 78.05 | 90.63 | 93.10 | 87.26 |  |
| 4 | 147 | Grey Whale | 85.19 | 93.10 | 78.72 | 85.67 |  |
| 5 | 536 | Docking | 85.71 | 100.00 | 70.21 | 85.31 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 9 | 885 | Velvet | 80.00 | 100.00 | 68.18 | 82.73 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 20 | 975 | Lakeside | 83.33 | 77.42 | 72.00 | 77.58 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 45 | 978 | Seashore | 79.17 | 55.56 | 82.69 | 72.47 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 665 | 251 | Dalmatian | 65.31 | 44.44 | 12.31 | 40.69 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 879 | 323 | Monarch | 46.67 | 30.16 | 10.00 | 28.94 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 946 | 685 | Odometer | 38.10 | 29.17 | 2.74 | 23.33 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 957 | 779 | School Bus | 28.30 | 30.77 | 6.90 | 21.99 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 974 | 181 | Bedlington Terrier | 24.19 | 28.21 | 4.48 | 18.96 |  |
| .. | .. | .. | .. | .. | .. | .. | .. |
| 996 | 411 | Apron | 9.62 | 6.25 | 8.20 | 8.02 |  |
| 997 | 549 | Envelope | 3.28 | 3.45 | 16.39 | 7.71 |  |
| 998 | 610 | T-Shirt | 12.07 | 5.56 | 2.08 | 6.57 |  |
| 999 | 741 | Prayer Mat | 0.00 | 0.00 | 18.97 | 6.32 |  |
| 1000 | 721 | Pillow | 4.65 | 0.00 | 3.03 | 2.56 |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chindaudom, A.; Siritanawan, P.; Sumongkayothin, K.; Kotani, K. Surreptitious Adversarial Examples through Functioning QR Code. J. Imaging 2022, 8, 122. https://doi.org/10.3390/jimaging8050122
Chindaudom A, Siritanawan P, Sumongkayothin K, Kotani K. Surreptitious Adversarial Examples through Functioning QR Code. Journal of Imaging. 2022; 8(5):122. https://doi.org/10.3390/jimaging8050122
Chicago/Turabian StyleChindaudom, Aran, Prarinya Siritanawan, Karin Sumongkayothin, and Kazunori Kotani. 2022. "Surreptitious Adversarial Examples through Functioning QR Code" Journal of Imaging 8, no. 5: 122. https://doi.org/10.3390/jimaging8050122
APA StyleChindaudom, A., Siritanawan, P., Sumongkayothin, K., & Kotani, K. (2022). Surreptitious Adversarial Examples through Functioning QR Code. Journal of Imaging, 8(5), 122. https://doi.org/10.3390/jimaging8050122